
Nvidia CUDA : plus en pratique
Publié le 09/08/2007 par Damien Triolet



 Depuis notre première analyse de CUDA, de nombreux éléments ont évolués. Nvidia a lancé une gamme de produits dédiés, l'API s'est améliorée, nous avons eu l'occasion de nous entretenir avec les responsables principaux de ces technologies et avons pu tester avec une application pratique ce dont sont capables les GPUs face aux CPUs. Il était donc temps de proposer une suite à ce premier article que vous pouvez retrouver ici puisque nous ne reviendrons pas sur les détails qui ont déjà été expliqués en long et en large.
Depuis notre première analyse de CUDA, de nombreux éléments ont évolués. Nvidia a lancé une gamme de produits dédiés, l'API s'est améliorée, nous avons eu l'occasion de nous entretenir avec les responsables principaux de ces technologies et avons pu tester avec une application pratique ce dont sont capables les GPUs face aux CPUs. Il était donc temps de proposer une suite à ce premier article que vous pouvez retrouver ici puisque nous ne reviendrons pas sur les détails qui ont déjà été expliqués en long et en large.Nous rappellerons simplement que derrière CUDA se cache une couche logicielle destinée au stream computing et une extension au langage de programmation C qui permet d'identifier certaines fonctions comme destinées à être traitée par le GPU au lieu du CPU. Ces fonctions sont alors compilées par un compilateur spécifique à CUDA ce qui leur permet d'être exécutées par les nombreuses unités de calcul des GPUs de classe GeForce 8 et supérieurs. Le GPU est ainsi vu comme un coprocesseur massivement parallèle qui est donc très bien adapté au traitement d'algorithme qui se parallélisent bien et très mal adapté aux autres.
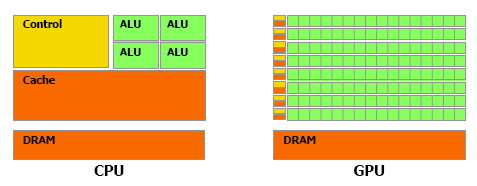
Une énorme proportion du GPU est dédiée à l'exécution, contrairement au CPU
Contrairement à un CPU, un GPU dédie une part importante de ses transistors aux unités de calcul et très peu à la logique de contrôle. Autre différence significative, que nous avions trop négligée lors de notre précédent article (comme le montrerons les tests GPU vs CPU publiés dans cet article) : la bande passante mémoire. Un GPU moderne dispose ainsi de +/- 100 Go/s contre +/- 10 Go/s pour un CPU.
Assemblages de processeursAutre rappel, la manière de nommer ce qui se passe dans un GPU à la façon de Nvidia. Un GeForce 8 est ainsi un assemblage de multiprocesseurs indépendants équipés chacun de 8 processeurs généralistes (appelés SP), qui effectuent toujours une même opération à la manière d'une unité SIMD, et de 2 processeurs spécialisés (appelés SFU). Un multiprocesseur se sert de ces 2 types de processeurs pour exécuter des instructions sur des groupes de 32 éléments. Chacun de ces éléments est appelé thread (à ne pas confondre avec un thread CPU!) et les groupes de 32 sont appelés warps.
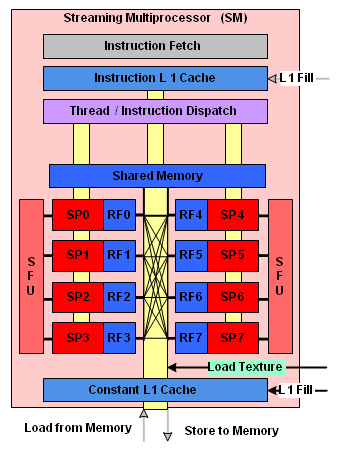
La représentation d'un multiprocesseur, le G80 en possède 16.
Les unités de calcul (SP et SFU) fonctionnent à une fréquence double de la logique de gestion et atteignent 1.5 GHz avec la GeForce 8800 Ultra. Pour une opération simple qui ne nécessite qu'un seul cycle du point de vue de l'unité de calcul (et donc 0.5 cycles du point de vue du reste du multiprocesseur), il faudra donc 2 cycles pour qu'elle soit exécutée sur l'ensemble d'un warp.
Un programme, appelé kernel, est exécuté dans un multiprocesseur sur un assemblage de blocs de warps qui peuvent en contenir jusqu'à 16 soit l'équivalent de 512 threads. Les threads d'un même bloc peuvent communiquer entre eux via une mémoire partagée.
Exploiter le GeForce 8

Sommaire
Vos réactions
Contenus relatifs
- [+] 09/02: Nvidia lance les Quadro Pascal dont...
- [+] 05/04: GTC: Nvidia Tesla P100: 10 Tflops, ...
- [+] 15/12: GPUOpen, la réponse d'AMD à GameWor...
- [+] 16/11: AMD et HPC: nouveaux outils, suppor...
- [+] 09/07: AMD lance la FirePro S9170: Hawaii ...
- [+] 08/12: Nvidia lance la Tesla K80: double G...
- [+] 02/12: IBM Power9 et Nvidia Volta : 100+ p...
- [+] 25/11: Nvidia annonce la Tesla K40 et CUDA...
- [+] 13/11: APU13: HSA: nouveaux membres, Oracl...
- [+] 06/05: AMD hUMA: la mémoire unifiée trouve...