
Nvidia CUDA : aperçu
Publié le 02/03/2007 par Damien Triolet



L'API CUDACUDA qui signifie Compute Unified Device Architecture est l'architecture qui permet d'exploiter les capacités de calcul des GPUs, à partir des GeForce 8, en leur faisant traiter des kernels (programmes) sur un certain nombre de threads. Si CUDA englobe également en partie le GPU puisque celui-ci dispose de plus en plus d'optimisations destinées à faciliter le calcul non graphique, il s'agit en pratique principalement de la partie logicielle. CUDA est donc représenté par un driver, un runtime, des librairies (une implémentation de BLAS notamment), une API basée sur une extension du langage C et le compilateur qui va avec (qui redirige la partie non-exécutée sur le GPU vers le compilateur classique par défaut du système).
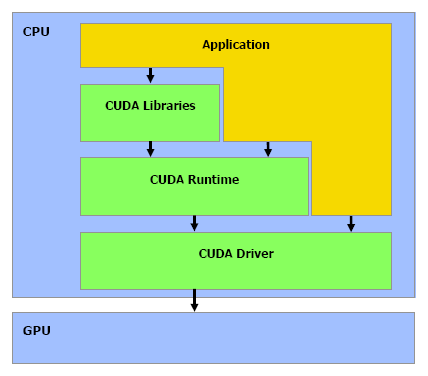
L'API CUDA est de type haut niveau, c'est-à-dire qu'elle fait globalement abstraction du matériel bien que prendre en compte ses spécificités soit requis pour obtenir un rendement intéressant. De son côté, avec la CTM, AMD propose une API de bas niveau. Grossièrement CUDA permet donc de développer plus facilement alors que CTM permet de mieux optimiser le code.
Le driver CUDA se charge du rôle d'intermédiaire entre le code compilé et le GPU. Le runtime CUDA est lui un intermédiaire entre le développeur et le driver qui facilite le développement en masquant certains détails. CUDA propose soit de passer par l'API runtime soit d'accéder directement à l'API driver. Il est possible de voir l'API runtime comme le langage de haut niveau et l'API driver comme un intermédiaire entre le haut et le bas niveau qui permet d'optimiser manuellement le code plus en profondeur. Dans le sens opposé, AMD permet d'écrire les kernels en HLSL au lieu d'un langage machine, de manière à faciliter le développement. Tant Nvidia que AMD essayent donc sur base de leur choix premier d'aller un petit peu dans l'autre direction.
Lors de cette première approche de CUDA nous nous sommes concentrés sur l'API runtime, mais le mode driver n'est pas fortement différent, il dispose de plus d'options mais de moins d'automatismes.
Cette API consiste en quelques extensions au langage C, un composant destiné au système qui permet de contrôler le ou les GPUs, un composant qui tourne sur le GPU et un composant commun qui contient des types de vecteurs et un ensemble de fonctions de la librairie standard C qui peuvent être exécutées aussi bien sur le système que sur le GPU.
Sans exposer tous les détails des extensions apportées, nous allons donner les principaux qui permettent d'expliquer comment CUDA fonctionne. Le premier point est un jeu de qualificatif des fonctions qui permet de spécifier sur quel composant elles sont destinées à être exécutées : le CPU ou le GPU. Un kernel, soit une fonction appelée par le CPU et exécutée par le GPU sera référencée par __GLOBAL__, une fonction utilisée dans un kernel sera référencée par __DEVICE__ et une fonction classique par __HOST__ qu'il n'est pas obligatoire de mentionner puisqu'il représente le comportement par défaut.
Le second point est la manière d'appeler un kernel. Une fonction classique s'appelle de cette manière :
Fonction(paramètres);Un kernel s'appelle d'une manière légèrement différente :
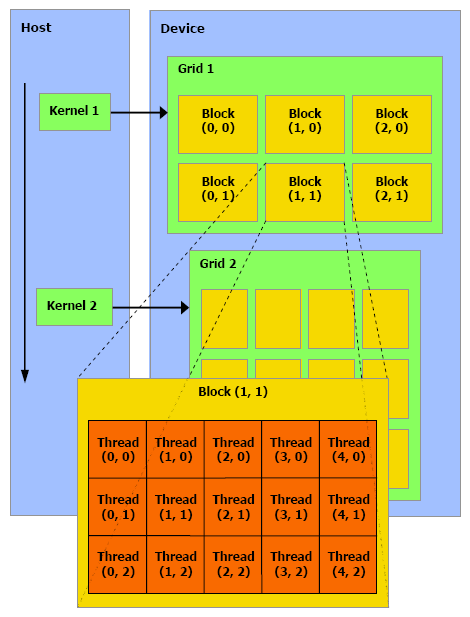
Fonction<<< blocks, threads, memory >>>(paramètres);Où blocks représente le nombre de blocks de threads à traiter, threads représente le nombre de threads par block et memory un espace mémoire optionnel dynamiquement alloué dans la mémoire partagée. Blocks * threads représente alors le nombre de threads total qui vont être traités par le kernel.
Ensuite, un jeu de variables intégrées permet d'identifier le thread au milieu de cet enchevêtrement de blocks. Un jeu de fonctions permet de contrôler le GPU, c'est-à-dire d'allouer des zones mémoires, de récupérer les détails sur le ou les GPUs présents dans le système, de sélectionner celui sur lequel le kernel sera exécuté etc.
Enfin, un ensemble de fonctions mathématiques supportées par le GPU et une fonction de synchronisation (__synchthreads() ) qui permet de bloquer l'exécution d'un kernel dans un multiprocesseur tant que tous les threads ne sont pas arrivés à ce point, de manière à éviter les problèmes de type lecture après écriture (il faut être sûr que la bonne information ait été écrite avant de pouvoir la lire).
Ces quelques extensions permettent de contrôler le GPU et n'importe qui maîtrisant le C les prendra en main très facilement. Pour exploiter correctement le GPU, il est primordial de répartir le travail en grilles de blocks dont la taille doit être adaptée au cas par cas pour maximiser l'utilisation des unités de calcul.
Interopérabilité API 3DCUDA dispose d'un certain nombre de fonctions qui permettent une interopérabilité avec les API 3D, via les buffer objets en OpenGL et via les vertex buffers en Direct3D. CUDA peut donc être utilisé pour traiter des données qui seront directement exploitées par le rendu 3D. De quoi par exemple traiter la physique avec CUDA et injecter ces résultats pour le rendu.
Sommaire
Vos réactions
Contenus relatifs
- [+] 09/02: Nvidia lance les Quadro Pascal dont...
- [+] 05/04: GTC: Nvidia Tesla P100: 10 Tflops, ...
- [+] 15/12: GPUOpen, la réponse d'AMD à GameWor...
- [+] 16/11: AMD et HPC: nouveaux outils, suppor...
- [+] 09/07: AMD lance la FirePro S9170: Hawaii ...
- [+] 08/12: Nvidia lance la Tesla K80: double G...
- [+] 02/12: IBM Power9 et Nvidia Volta : 100+ p...
- [+] 25/11: Nvidia annonce la Tesla K40 et CUDA...
- [+] 13/11: APU13: HSA: nouveaux membres, Oracl...
- [+] 06/05: AMD hUMA: la mémoire unifiée trouve...