| |
| |
| Nvidia CUDA : aperçu Cartes Graphiques Publié le Vendredi 2 Mars 2007 par Damien Triolet URL: /articles/659-1/nvidia-cuda-apercu.html Page 1 - CPU/GPU, BrookGPU  Les processeurs graphiques ou GPUs ont changé en l'espace de quelques années. Aujourd'hui ils sont capables de bien plus que de calculer des pixels dans les jeux vidéo, mais encore faut-il pouvoir les utiliser d'une manière efficace pour d'autres tâches. Si AMD a été le premier à présenter une solution concrète à ce problème, Nvidia est le premier à rendre disponible une telle solution dont nous avons décidé de vous parler dans cet article. Les processeurs graphiques ou GPUs ont changé en l'espace de quelques années. Aujourd'hui ils sont capables de bien plus que de calculer des pixels dans les jeux vidéo, mais encore faut-il pouvoir les utiliser d'une manière efficace pour d'autres tâches. Si AMD a été le premier à présenter une solution concrète à ce problème, Nvidia est le premier à rendre disponible une telle solution dont nous avons décidé de vous parler dans cet article.(nous déclinons tout responsabilité quant à l'apparition de maux de tête suite à la lecture de cet article) CPU et GPU : quelle différence ?Depuis quelques années, la puissance de calcul des GPUs a évolué exponentiellement, bien plus rapidement que celle des CPUs. Ceci ne veut bien entendu pas dire que les GPUs évoluent plus que les CPUs, il s'agirait là d'un raccourci trop facile. Ces 2 composants s'attaquent à des problèmes très différents, ce qui les a fait évoluer dans des directions également différentes.  En simplifiant, on attend d'un CPU qu'il exécute une tâche le plus rapidement possible alors que l'on attend d'un GPU de pouvoir traiter un maximum de tâches, ou plutôt une tâche sur un maximum de données, dans un temps réduit. Bien entendu un GPU doit également aller vite et un CPU doit traiter plusieurs tâches, mais l'évolution de leurs architectures, tout du moins jusqu'à ce point, a reflété cette priorité. Cela signifie dans le cas d'un GPU une multiplication des unités de traitement et dans le cas du CPU une complexification des unités de contrôle ainsi qu'une augmentation régulière de la mémoire cache embarquée. 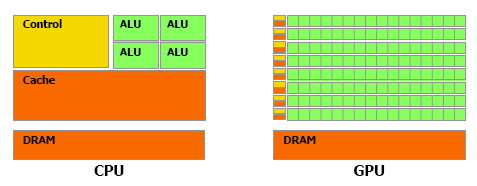 Une énorme proportion du GPU est dédiée à l'exécution, contrairement au CPU Le CPU est ainsi capable de traiter rapidement tout type de tâches alors que le GPU est capable de traiter extrêmement rapidement un certain type de tâches. Celles-ci doivent pouvoir s'exprimer sous forme d'un problème qui se décompose en éléments indépendants puisqu'il s'agit d'exploiter la parallèlisation massive des GPUs. C'est en réalité un problème similaire à celui rencontré par les CPUs dont la puissance de calcul repose en partie sur les unités vectorielles (SSE etc.). Reste que là où le Core 2 Duo peut être vu comme un ensemble de 8 unités, le GeForce 8800 est vu comme un ensemble de 128 de ces unités ! Nous sommes donc à un tout autre niveau ce qui implique que la manière d'aborder un problème doit être vue en conséquence sous peine de ne pas pouvoir exploiter cette puissance de calcul. BrookGPU : les prémicesL'idée d'utiliser un GPU comme unité de calcul complémentaire n'est pas nouvelle et à commencer à germer avec l'arrivée des GeForce FX, premiers GPUs à supporter le format de calcul flottant simple précision (FP32). Il y a plus de 3 ans, lors des premières publications officielles autour de BrookGPU, un langage de programmation destiné à faciliter l'accès à la puissance de calcul des GPUs, nous écrivions ceci : " Autrement dit, les ingénieurs de NVIDIA et ATI devront encore travailler un petit peu avant que ceci ne soit réellement utilisable. Car se servir d'un GPU actuel pour du calcul général revient un petit peu à essayer de s'éclairer grâce au courant tiré d'une pomme de terre. Ceci dit, l'évolution des GPUs étant fulgurante, il n'est pas trop tôt pour commencer à y travailler. Pour avoir quelques chose d'utilisable lors de la sortie des NV50 et R500 ? Nous pouvons même imaginer que ceci pourrait permettre dans le futur à ATI et NVIDIA de proposer leurs puces sur des marchés très différents. "Ces prévisions étaient donc plutôt proches de la réalité puisque ATI/AMD a introduit la CTM, une API de bas niveau pour utiliser le cur de calcul des Radeon X1000 (R5xx) ainsi qu'une gamme de produits dédiés à ce type d'utilisation et que Nvidia a introduit CUDA, un langage de programmation proche du C qui permet d'exploiter le cur du GeForce 8800 (G80 qui est le nouveau nom de code du NV50). Se servir d'un GPU comme unité de calcul relève-t-il toujours aujourd'hui de l'éclairage à la pomme de terre ? La réponse est non bien que nous soyons toujours aux débuts de ce type d'utilisation. Les progrès ont été nombreux tant au niveau du hardware que du software. Nous vous avons déjà parlé à plusieurs reprises de la CTM mais sans pouvoir rentrer dans trop de détails, celle-ci n'étant toujours pas publique. Nvidia a par contre rendu publique une version beta de CUDA il y a peu, l'occasion de nous y attarder quelque peu. Page 2 - Le GeForce 8800 L'architecture GeForce 8800 plus en détailBien que contrairement à AMD, Nvidia ait décidé de ne pas proposer de langage de bas niveau accompagné d'une documentation détaillée du hardware, CUDA requiert malgré tout une bonne connaissance du GPU qui est donc décrit par Nvidia dans des termes moins marketing. L'occasion au passage d'apprendre quelques détails de plus sur ce GPU. Grossièrement le GeForce 8800 a été décrit comme un GPU équipé de 128 processeurs scalaires répartir en 8 partitions de 16 et fonctionnant à très haute fréquence : 1350 MHz. Ces partitions traitent des groupes de 32 pixels ou de 16 vertices. En réalité les 8 partitions contiennent chacune 2 groupes de 8 processeurs scalaires, ce qui fait du GeForce 8800 GTX une puce équipée de 16 groupes de processeurs. Nvidia appelle ces groupes les multiprocesseurs. Le fait que les multiprocesseurs soient composés de 8 processeurs et non de 16 ne fait pas de différence en termes de performances, il s'agit simplement d'une implémentation destinée à faciliter le fonctionnement à très haute fréquence des unités de calcul. En contrepartie elle requiert plus de transistors. 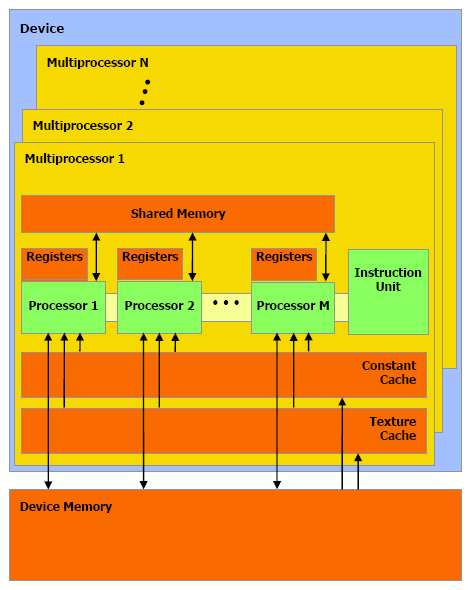 L'architecture GeForce 8 est constituée d'un assemblage de multiprocesseurs qui représentent une unité SIMD composée d'un certain nombre de processeurs. Dans les documentations de CUDA, les multiprocesseurs ne sont pas décrits comme fonctionnant à 1350 MHz mais bien à 675 MHz avec des unités d'exécution de type "double pumped", c'est-à-dire qui fonctionnent à une fréquence double comme c'était le cas des ALU du Pentium 4. Ces multiprocesseurs traitent des blocs de 64 à 512 éléments appelés threads et répartis en sous-groupes de 32 threads, les warps. Il faut 2 cycles (4x 0.5 cycles étant donné le fonctionnement en mode "double pumped") à un multiprocesseurs pour exécuter une instruction flottante courante sur un warps. Débiter une instruction tous les 2 cycles est plus aisé que de le faire à chaque cycle, ce qui explique le choix de l'utilisation de 2 multiprocesseurs composés de 8 processeurs par partition au lieu d'un seul mais composé de 16 comme supposé à la lecture des documentations initiales sur le GeForce 8800. Comme nous vous l'avions indiqué dans l'article consacré aux GeForce 8800, il dispose également d'unités de calcul dédiées aux instructions plus complexes (exp, log, sin, cos, rcp, rsq). 2 de ces unités se retrouvent dans chaque multiprocesseurs, en plus de 8 processeurs qui traitent les instructions courantes, les instructions spéciales sont donc 4x plus lentes et il faut 8 cycles pour les exécuter sur un warps entier. Notez que contrairement à ce que l'on retrouve dans les pixels et vertex shaders, les instructions sin, cos et exp sont 2x plus lentes que les 3 autres et prennent donc 16 cycles pour s'exécuter sur les 32 threads des warps. La raison est probablement que dans le cas du rendu 3D ces instructions sont exécutées avec moins de précision mais plus rapidement. Nvidia précise d'ailleurs que la plupart des instructions peuvent être exécutées dans un mode de précision plus réduit mais plus rapide. Les multiplications entières sont elles aussi traitées par ces 2 unités et prennent donc 8 cycles. Une version de moindre précision (24 bits au lieu de 32 bits) peut par contre s'exécuter sur les 8 processeurs classiques soit en 2 cycles du point de vue du multiprocesseur. En résumé, le GeForce 8800 GTX peut être vu comme une grosse unité de calcul divisée en 16 multiprocesseurs qui traitent des groupes de warps de 32 threads à travers 8 processeurs généraux et 2 processeurs spécialisés. Ces 16 multiprocesseurs cadencés à 675 MHz permettent ensemble de traiter tous les 2 cycles 1 instruction courante sur 512 threads, soit un débit de 256 opérations par cycle (512 opérations flottantes dans le cas des FMAD/FMAC qui représentent une multiplication + une addition), ce à quoi il faut ajouter jusqu'à 64 opérations spéciales. Un Core 2 Duo, vu à travers les unités SSE de ses 2 cores est capable de traiter 16 opérations par cycle (8 additions et 8 multiplications). Par contre il fonctionne à une fréquence bien plus élevée que 675 MHz mais ne traite pas les opérations FMAD/FMAC à pleine vitesse puisqu'il doit avoir recours à 2 unités pour traiter une opération de ce type. Le tableau suivant représente la puissance de calcul des GeForce 8800 et des 2 Core 2 Extreme d'Intel dans 4 cas : multiplication flottante, addition flottante, la moitié de chaque (le meilleur cas pour les Core 2) et multiplication-addition flottante (le meilleur cas pour les GPUs puisque toutes ses unités gèrent cette instruction).  Les GeForce 8800 disposent donc clairement d'une puissance de calcul supérieure à celles des Core 2, y compris le quadcore. Néanmoins, la différence n'est pas toujours énorme. Entendez par là que ces chiffres laissent penser qu'il faut réellement exploiter efficacement un GeForce 8800 pour qu'il surpasse un processeur quadcore. Ceci étant dit il faut garder en tête que les GeForce 8800 peuvent traiter en plus et relativement rapidement des opérations plus complexes et également utiliser leurs unités de filtrage des textures pour accélérer certaines opérations. Si un algorithme permet d'exploiter les capacités tierces des GPUs les performances peuvent s'envoler par rapport au CPU. Page 3 - Précision, mémoires PrécisionLorsqu'il s'agit de calcul général, la précision et le comportement détaillé des unités de calcul doivent être connus et pour bien faire conformes aux standards IEEE. Le GeForce 8800, tout comme tous les autres GPUs actuels, n'est pas complètement conforme puisqu'il ne gère pas les nombres dénormalisés et propose une précision moindre sur certaines opérations. Nvidia documente en détail le comportement de ses unités de calcul, ce qui permet de savoir quand celui-ci s'écarte de ce que l'on retrouve sur un CPU :  Par ailleurs, les unités sont limitées à la simple précision (FP32), mais il est probable que la prochaine génération supporte les doubles (FP64) comme c'est le cas sur les CPUs. Mémoire localeLes processeurs du GeForce 8800 supportent le gathering et le scattering soit la capacité de lire et d'écrire n'importe où en mémoire locale (sur la carte graphique) ou globale (étendue à une partie de la mémoire du système). 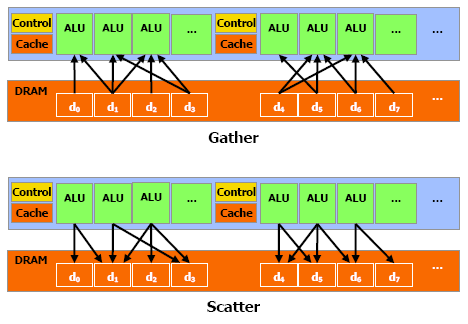 Cependant, ces mémoires ne sont pas cachées et le GeForce 8800 paye donc le prix fort de la latence de ces lectures/écritures qui varie entre 200 et 300 cycles ! Dans le cas où de nombreuses instructions mathématiques à traiter ne dépendent pas d'une lecture, elles serviront à masquer cette latence. Mémoire partagéeNéanmoins, il faudra éviter au maximum ces lectures et écritures en mémoire locale ou globale. Pour ce faire, chaque multiprocesseur dispose d'une petite mémoire dédiée de 16 Ko appelée mémoire partagée. Celle-ci permet de rompre en partie les limitations imposées par un traitement parallèle des threads en leur permettant de communiquer et donc d'interagir entre eux rapidement, sans passer par la mémoire de la carte graphique. 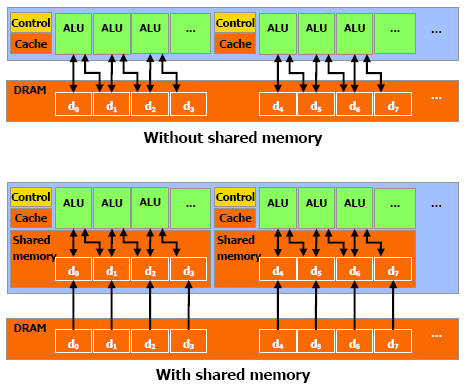 La mémoire partagée, en plus d'éviter l'énorme latence de la mémoire locale ou globale permet d'économiser de la bande passante mémoire, en réduisant les accès à celle-ci de 33% dans cet exemple. Cette mémoire partagée ne l'est cependant que pour les éléments d'un même block ! Autrement dit, plus de threads par block signifie moins de mémoire par thread et moins de threads par block signifie que moins de thread vont pouvoir communiquer. Qui plus est, il est en général conseillé de permettre à chaque multiprocesseur de travailler sur plusieurs blocks de manière à pouvoir traiter un second block quand le premier est en pause et ainsi éviter de gaspiller des ressources. Ce qui réduit encore la taille relative de cette mémoire partagée. Elle sera ainsi de 8 Ko par block dans le cas classique et conseillé où 2 blocks se trouvent dans chaque multiprocesseur. L'utilisation de cette mémoire partagée est très réglementée. Pour illustrer cet état de fait voici quelques détails pour les plus courageux. Elle est divisée en 16 banques mémoire. A chaque cycle il est possible d'accéder à chacune de ces banques via 16 bus internes de 32 bits (soit 512 bits en tout!). Etant donné qu'une instruction d'accès à cette mémoire est traitée par warps soit par groupe de 32 threads, ce sont 32 accès à la mémoire en 2 cycles qui doivent être traités. Pour les 16 premiers threads ce sera fait pendant le premier cycle et pour les 16 suivant pendant le second cycle. 2 accès simultanés à la même banque mémoire ne peuvent pas être traités lors d'un même cycle. Les 16 premiers (ou derniers) threads doivent donc tous accéder à une banque différente sans quoi plusieurs cycles sont nécessaires. Notez qu'il est cependant autorisé que tous les threads accèdent à la même banque. Cela exprime bien la complexité de l'utilisation de cette mémoire partagée si l'on veut maximiser les performances. Il ne s'agit pas d'une mémoire cache comme c'est le cas sur un CPU, elle est plus proche de la mémoire locale des SPEs du Cell par exemple. Mémoire cache, registres et constantesLe GPU dispose d'une mémoire cache au niveau des unités de texturing. Celles-ci peuvent donc être utilisées, lorsque les accès sont bien alignés, pour lire (mais pas écrire) efficacement des données. Cette mémoire cache est de 8 Ko par multiprocesseur. Chaque multiprocesseur dispose d'un certain nombre (non dévoilé) de registres généraux. Les threads en cours de traitement doivent se les partager. Plus il y a de threads, mieux la latence de certains opérations est masquée mais moins ils disposent de registres. C'est un paramètre important qui peut avoir une forte influence sur les performances. CUDA permet de le contrôler. Le GeForce 8800 dispose d'une mémoire supplémentaire de 64 Ko qui stocke les constantes. Cette mémoire est cachée à hauteur de 8 Ko par multiprocesseur. Mémoire locale, mémoire globale, mémoire partagée, mémoire cache des unités de texturing, mémoire cache des constantes et registres : de quoi entraîner quelques calvities chez les développeurs qui essayeront d'en tirer le meilleur parti ! Page 4 - L'API CUDA L'API CUDACUDA qui signifie Compute Unified Device Architecture est l'architecture qui permet d'exploiter les capacités de calcul des GPUs, à partir des GeForce 8, en leur faisant traiter des kernels (programmes) sur un certain nombre de threads. Si CUDA englobe également en partie le GPU puisque celui-ci dispose de plus en plus d'optimisations destinées à faciliter le calcul non graphique, il s'agit en pratique principalement de la partie logicielle. CUDA est donc représenté par un driver, un runtime, des librairies (une implémentation de BLAS notamment), une API basée sur une extension du langage C et le compilateur qui va avec (qui redirige la partie non-exécutée sur le GPU vers le compilateur classique par défaut du système). 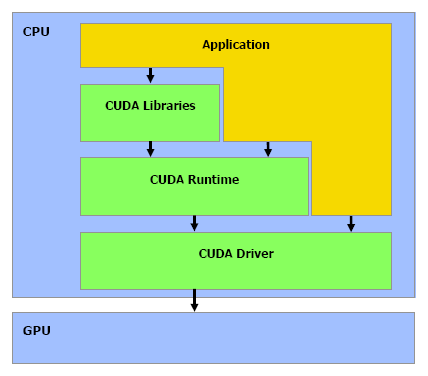 L'API CUDA est de type haut niveau, c'est-à-dire qu'elle fait globalement abstraction du matériel bien que prendre en compte ses spécificités soit requis pour obtenir un rendement intéressant. De son côté, avec la CTM, AMD propose une API de bas niveau. Grossièrement CUDA permet donc de développer plus facilement alors que CTM permet de mieux optimiser le code. Le driver CUDA se charge du rôle d'intermédiaire entre le code compilé et le GPU. Le runtime CUDA est lui un intermédiaire entre le développeur et le driver qui facilite le développement en masquant certains détails. CUDA propose soit de passer par l'API runtime soit d'accéder directement à l'API driver. Il est possible de voir l'API runtime comme le langage de haut niveau et l'API driver comme un intermédiaire entre le haut et le bas niveau qui permet d'optimiser manuellement le code plus en profondeur. Dans le sens opposé, AMD permet d'écrire les kernels en HLSL au lieu d'un langage machine, de manière à faciliter le développement. Tant Nvidia que AMD essayent donc sur base de leur choix premier d'aller un petit peu dans l'autre direction. Lors de cette première approche de CUDA nous nous sommes concentrés sur l'API runtime, mais le mode driver n'est pas fortement différent, il dispose de plus d'options mais de moins d'automatismes. Cette API consiste en quelques extensions au langage C, un composant destiné au système qui permet de contrôler le ou les GPUs, un composant qui tourne sur le GPU et un composant commun qui contient des types de vecteurs et un ensemble de fonctions de la librairie standard C qui peuvent être exécutées aussi bien sur le système que sur le GPU. Sans exposer tous les détails des extensions apportées, nous allons donner les principaux qui permettent d'expliquer comment CUDA fonctionne. Le premier point est un jeu de qualificatif des fonctions qui permet de spécifier sur quel composant elles sont destinées à être exécutées : le CPU ou le GPU. Un kernel, soit une fonction appelée par le CPU et exécutée par le GPU sera référencée par __GLOBAL__, une fonction utilisée dans un kernel sera référencée par __DEVICE__ et une fonction classique par __HOST__ qu'il n'est pas obligatoire de mentionner puisqu'il représente le comportement par défaut. Le second point est la manière d'appeler un kernel. Une fonction classique s'appelle de cette manière : Fonction(paramètres);Un kernel s'appelle d'une manière légèrement différente : Fonction<<< blocks, threads, memory >>>(paramètres);Où blocks représente le nombre de blocks de threads à traiter, threads représente le nombre de threads par block et memory un espace mémoire optionnel dynamiquement alloué dans la mémoire partagée. Blocks * threads représente alors le nombre de threads total qui vont être traités par le kernel. Ensuite, un jeu de variables intégrées permet d'identifier le thread au milieu de cet enchevêtrement de blocks. Un jeu de fonctions permet de contrôler le GPU, c'est-à-dire d'allouer des zones mémoires, de récupérer les détails sur le ou les GPUs présents dans le système, de sélectionner celui sur lequel le kernel sera exécuté etc. Enfin, un ensemble de fonctions mathématiques supportées par le GPU et une fonction de synchronisation (__synchthreads() ) qui permet de bloquer l'exécution d'un kernel dans un multiprocesseur tant que tous les threads ne sont pas arrivés à ce point, de manière à éviter les problèmes de type lecture après écriture (il faut être sûr que la bonne information ait été écrite avant de pouvoir la lire). Ces quelques extensions permettent de contrôler le GPU et n'importe qui maîtrisant le C les prendra en main très facilement. Pour exploiter correctement le GPU, il est primordial de répartir le travail en grilles de blocks dont la taille doit être adaptée au cas par cas pour maximiser l'utilisation des unités de calcul. 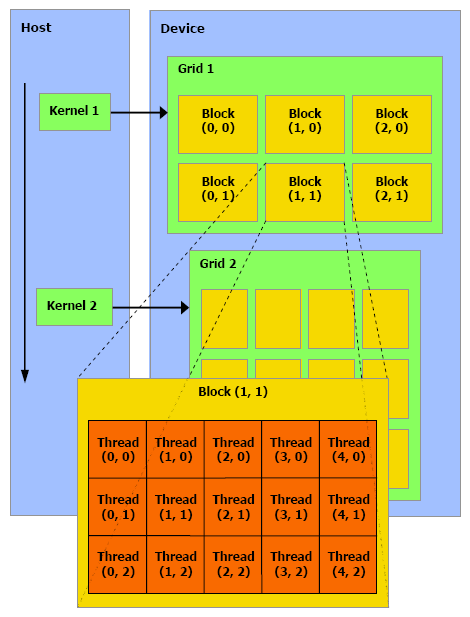 Interopérabilité API 3DCUDA dispose d'un certain nombre de fonctions qui permettent une interopérabilité avec les API 3D, via les buffer objets en OpenGL et via les vertex buffers en Direct3D. CUDA peut donc être utilisé pour traiter des données qui seront directement exploitées par le rendu 3D. De quoi par exemple traiter la physique avec CUDA et injecter ces résultats pour le rendu. Page 5 - En pratique En pratiqueNous avons pu jouer pendant quelques temps avec CUDA, de quoi se faire une petite idée de ce qu'il permet. Commençons par ce qu'il ne permet pas : profiter simplement d'un système SLI pour doubler la puissance de calcul. Chaque GPU est vu indépendamment des autres et un kernel est exécuté sur un seul GPU. Il faut donc lancer un kernel différent sur chaque GPU pour profiter des systèmes multi-GPU ce qui complique la bonne exploitation de toute la puissance de calcul. Qui plus est, l'exécution d'un kernel est synchrone ce qui veut dire qu'une fois que le CPU a demandé l'exécution du kernel au GPU, le thread et donc le core qui l'exécute va être bloqué jusqu'à ce que le GPU ait terminé son travail. La puissance CPU peut donc être facilement gaspillée en attente au lieu d'être utilisée en complément du GPU. Un point que Nvidia devra améliorer dans le futur sans quoi il faudra autant de cores CPU dans le système (utilisé à ne rien faire !) qu'il y a de GPUs. Nous avions au départ envisagé de comparer plusieurs algorithmes sur GPU et sur CPU de manière à juger des écarts de performances. Nous sommes cependant rapidement revenus sur cet objectif pour différentes raisons, la principale est que nous n'avons pas la prétention de pouvoir affirmer avoir développer une fonction qui a autant d'efficacité d'un côté comme de l'autre. Autrement dit, si le GPU est plus rapide est-ce parce qu'il est plus performant ou parce que la même fonction a été moins bien optimisée sur le CPU et vice versa. Ensuite, il est facile de prendre un exemple qui sera beaucoup plus rapide sur le CPU et vice versa également. Autrement dit, à moins de passer des semaines voire plus à mettre au point des tests relativement objectifs, ce que nous ne pouvons malheureusement pas nous permettre de faire, il est difficile de comparer directement les performances entre CPU et GPU. Néanmoins nous avons décidé de publier 2 graphes de performances. S'ils représentent le GPU et le CPU, ils ne sont pas destinés à être comparés directement, mais plutôt à montrer comment se comportent les performances d'un côté comme de l'autre avec un paramètre qui varie. Il convient bien entendu de garder à l'esprit qu'il s'agit ici d'une version beta de CUDA qui verra ses performances progresser avec de nouvelles révisions. Le premier paramètre que nous avons fait varier est le nombre de blocks. Le nombre total de threads soit d'éléments traités reste identique mais ils sont soit regroupés un 1 seul gros block soit en plusieurs plus petits blocks. Dans le cas du CPU chaque block peut être vu comme un thread et donc être exécuté sur un core différent. Le kernel consiste à effectuer une série d'opérations sur des données et à en écrire le résultat dans une table. 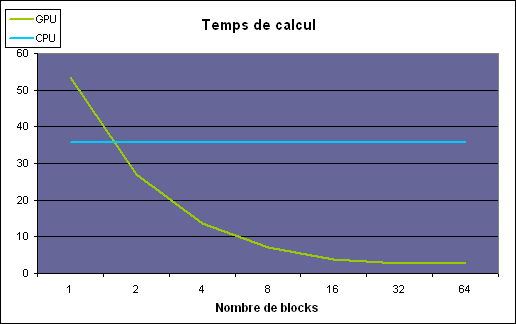 Sur le CPU simple core, peu importe l'organisation, les performances sont identiques. Un CPU quadcore permettrait par contre par exemple de traiter ce type de kernel 4x plus vite à partir de 4 blocks. Dans le cas du GeForce 8800 GTX, il faut au moins 16 blocks pour que les 16 multiprocesseurs soient exploités, et 32 pour qu'ils le soient efficacement. Plus de travail lors du développement mais le gain en performances est conséquent. Le second test consiste à augmenter la complexité du kernel (soit le nombre d'opérations), le nombre de blocks étant fixé à 32. 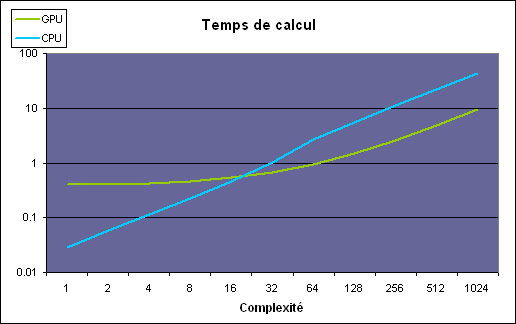 Alors que le temps de calcul augmente linéairement avec le CPU, ce n'est pas le cas sur le GPU en dessous d'une certaine complexité, ce qui indique que le coût de gestion reste élevé et doit donc être amorti sur des opérations complexes. Il ne suffit donc pas de traiter un nombre élevé de données, il faut que ce traitement soit suffisamment complexe pour que le jeu en vaille la chandelle. Page 6 - Conclusion ConclusionCette première prise en main de CUDA nous a été relativement agréable. Agréable puisque nous avons été surpris par la facilité avec laquelle il est maintenant possible d'accéder aux unités de calcul du GeForce 8800. Relativement parce qu'il y a un monde entre faire tourner quelques fonctions sur un GPU et l'exploiter efficacement. Nous avons, pour l'exercice de style, décidé de porter sur GPU (presque totalement) une version basique de pacman écrite en C. Il ne nous a fallu que quelques heures pour disposer d'un code fonctionnel (bien que peu performant et d'une robustesse approximative). Le but était ici d'observer avec quelle facilité il était possible de faire ses premiers pas avec CUDA. Examen réussi donc, approcher CUDA n'est pas réservé aux ingénieurs de Nvidia et à quelques chercheurs, à l'inverse de la solution d'AMD. Bien que nous n'ayons pas accès à la CTM, la documentation publique nous a rapidement permis de nous rendre compte de la difficulté de réaliser un tel portage, une idée que nous aurions donc abandonné directement quand bien même nous aurions eu accès à la CTM.  Ceci étant dit exploiter pleinement un GPU tel que le GeForce 8800 à travers CUDA n'est pas une tâche aisée, bien au contraire. Optimiser en profondeur est complexe quelle que soit la méthode. A partir d'un certain niveau d'efficacité, il est probable que la CTM reprenne les devants sur CUDA mais probablement au prix d'un temps de développement bien plus long. Si au départ nous avions une préférence pour l'approche d'AMD qui permet de connaître le GPU en détail et de l'exploiter d'une manière plus efficace, au fil de notre analyse de CUDA et de la CTM, notre avis a changé. D'une part à cause de la complexité importante du côté de la CTM. A temps de développement identique, il nous paraît évident que CUDA permettra d'obtenir de meilleurs résultats. Et d'autre part parce que nous avons constaté que l'écart entre la puissance de calcul des GPUs et des CPUs n'est pas aussi gigantesque qu'on pourrait le penser. Aussi puissant que soit le G80, les CPUs ont eux aussi fortement progressés avec l'apparition successive du dualcore puis du quadcore. Attention, les GPUs disposent d'une puissance de calcul supérieure, c'est un fait, mais il n'est pas question ici d'un ordre de grandeur de type x20 ou x100. Un x10 est péniblement atteint dans certains cas et ce sans compter l'efficacité moindre en pratique. Bien entendu dans certains cas le GPU peut prendre une avance plus importante mais globalement le GPU n'offre pas encore assez pour justifier ses désavantages. Cette génération nous apparaît avant tout comme une première base de travail intéressante pour le développement d'applications pratiques, le GeForce 8800 associé a CUDA représentant la solution GPGPU la plus aboutie du moment. Autrement dit, si les GPUs s'imposent comme unités de calcul dans des domaines variés, en dehors de quelques exceptions, ce sont des GPUs futurs qui seront utilisés. Contrairement à la CTM, la force de CUDA est de ne pas être spécifique à un GPU et donc de permettre aujourd'hui le développement d'applications qui tourneront sur des GPUs de la prochaine génération, voire de la suivante. Nvidia conseille d'ailleurs aux développeurs de viser le traitement de 100 voire de 1000 blocks au lieu de 32 sur un GeForce 8800 GTX, de manière à profiter directement des futures générations de GPUs, ce qui annonce clairement la couleur concernant leur évolution.  Bien entendu, rien n'est tout noir ou tout blanc et CUDA est lui aussi en partie dépendant des capacités des GPUs, qu'il permet d'ailleurs de reporter, la GeForce 8800 représentant une capacité 1.0. De futurs GPUs, par exemple en version 1.1, pourraient supporter les opérations flottantes en double précision (FP64) ou des mémoires différentes ce qui pourra changer significativement la manière d'optimiser le code. Mais celui-ci restera fonctionnel, via une recompilation si nécessaire. Selon nous, le succès de l'utilisation des GPUs en tant qu'unités de calcul dépendra avant tout de la capacité de ceux-ci à continuer à évoluer plus vite que les CPUs de manière à pouvoir s'installer sur ce nouveau marché avant que le massivement multicore débarque chez le numéro un du processeur, c'est-à-dire Intel. Après ce sera trop tard. Pour les simples utilisateurs que nous sommes, tout ceci ne devrait pas avoir de grande importance, tout du moins à court terme. Il faudra du temps avant de voir débarquer des applications utiles. Quant à la possibilité de voire CUDA utilisé pour traiter la physique dans les jeux, nous ne nous y attendons pas pour le moment, ces développeurs ayant déjà fort à faire avec l'exploitation des CPU multicores. Pour plus d'informations : CUDA : http://developer.nvidia.com/object/cuda.html CTM : http://ati.amd.com/companyinfo/researcher/Documents.html Copyright © 1997-2024 HardWare.fr. Tous droits réservés. |