
Radeon X1900 XTX, X1900 XT et X1900 CrossFire en test
Publié le 24/01/2006 par Damien Triolet



En octobre dernier, ATI lançait avec plusieurs mois de retard le Radeon X1800 XT. Ses retards ne s´arrêtaient cependant pas là puisqu´il n´a été réellement disponible qu´à partir de novembre et décembre. En cause un problème de fabrication qui empêchait son fonctionnement aux fréquences visées et nécessaires pour devancer le GeForce 7800 de Nvidia. Parallèlement à la résolution de ces problèmes, son successeur était déjà en phase de finalisation sans connaître de réel souci ce qui lui permet d´arriver à l´heure.
Enfin presque à l´heure puisqu´il était prévu pour fin 2005, mais étant donné qu´ATI s´est focalisé sur le X1800 ce petit retard n´a rien d´étonnant. Ce Radeon X1900, qui a déjà fait couler beaucoup d´encre, pourrait être vu comme une réponse au GeForce 7800 GTX 512 Mo lancé par Nvidia pour faire un pied de nez à ATI en novembre dernier. Mais en ce qui concerne ce GPU, ATI suit une roadmap planifiée il y a longtemps, même si elle entraîne le renouvellement du haut de gamme moins de 3 mois après son arrivée réelle sur le marché.

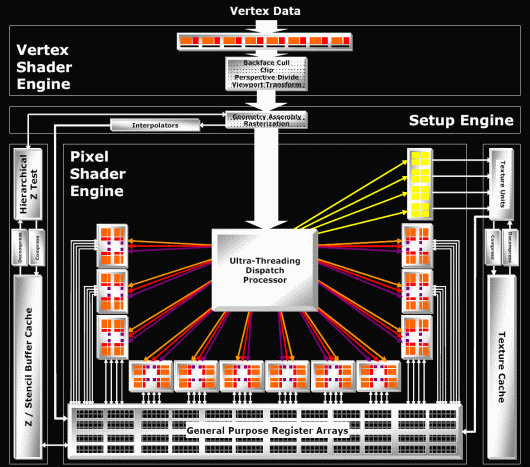
A l´origine, lorsque l´on parlait de pixel pipeline, ou de pipeline tout court, on décrivait la chaîne de fabrication de pixels la plus basique qu´il soit : une unité de texturing raccordée à un ROP qui se charge, lui, de placer le fragment (qui est un candidat pixel) dans l´image, c´est-à-dire au bon endroit dans la mémoire vidéo.
Avec l´évolution des GPUs, ceux-ci se sont vus adjoindre d´autres unités que l´unité de texturing pour arriver à un long pipeline qui contenait une ou deux unités de texturing, des unités de calcul et un ROP devenu plus complexe puisque capable de gérer les transparences (blending) et l´antialiasing de type multisample. Il est alors apparu que le ROP pouvait être dissocié du reste, ce qui fait que quand on parle de pipeline, c´est de ce reste que l´on parle. Les ROPs définissent le fillrate, c´est-à-dire le nombre de pixels qui peuvent être écrit en mémoire chaque seconde. Cette écriture consomme de la bande passante (64 bits par pixel, 96 bits en FP16/HDR, 160 bits en FP32, plus le blending...) et il apparaît évident que les 512 bits que peut transporter le bus mémoire chaque cycle (256 bits DDR), même avec les technologies de compression des données, ne peuvent pas recevoir les données d´un nombre très élevé de ROPs. 16 ROPs représentent le maximum raisonnable sur un bus mémoire 256 bits. La séparation des ROPs du reste permet d´augmenter ce reste à moindre coût sans ajouter de ROPs inutiles.
Chez Nvidia, ce reste est une longue chaîne de fabrication de pixel (ou fragment), qui contient plusieurs unités de calcul en série dont l´une pilote l´unité de texturing. Cette longue chaîne est nécessaire pour masquer la latence requise par l´accès aux textures. La fabrication d´un pixel consiste à calculer un pixel shader et étant donné que celui-ci peut-être très long, il requiert en général plusieurs passages dans le pipeline, qu´il est logique de qualifier de pipeline de pixel shading.
Chez ATI, le fonctionnement est un petit peu différent puisque les Radeon disposent de pipelines de pixel shading et de pipelines de texturing dissociés. Etant donné que la longueur du pipeline est utilisée pour masquer la latence du texturing, il est possible de n´utiliser qu´un très court pipeline pour la partie pixel shading. Par contre le système de gestion doit être plus complexe puisqu´il doit envoyer les pixels dans le bon pipeline au bon moment. Ainsi un pixel va faire un ou plusieurs allers-retours entre le pipeline de pixel shading et le pipeline de texturing. Les Radeon 9700 à X850 disposaient déjà d´une telle architecture, mais pas d´un système de gestion évolué ce qui fait qu´ATI ne pouvait pas en exploiter toute la flexibilité. Les Radeon X1000 en sont, elles, capables.
 Avec le Radeon X1900, ATI a décidé d´augmenter le nombre de pipelines de pixel shading. Par contre les pipelines de texturing restent, eux, à 16. Le choix d´ATI est basé sur le fait que le nombre d´instructions mathématique dans un shader augmente beaucoup plus vite que celui des accès aux textures, ce qui est tout à fait vrai. Nvidia pense la même chose puisque les pipelines de pixel shading des GeForce 6 et 7 disposent chacun de 2 unités de calcul. Le but est le même que celui d´ATI, mais la stratégie est différente. Pour Nvidia, étant donné que la partie destinée à masquer la latence du texturing est intégrée dans le pipeline de pixel shading, il représente un grand nombre de transistors et en placer plus est très coûteux alors qu´ajouter une unité de calcul supplémentaire en série est relativement aisé. Chez ATI un pipeline de pixel shading est très petit ce qui fait qu´il est peu coûteux à ajouter.
Avec le Radeon X1900, ATI a décidé d´augmenter le nombre de pipelines de pixel shading. Par contre les pipelines de texturing restent, eux, à 16. Le choix d´ATI est basé sur le fait que le nombre d´instructions mathématique dans un shader augmente beaucoup plus vite que celui des accès aux textures, ce qui est tout à fait vrai. Nvidia pense la même chose puisque les pipelines de pixel shading des GeForce 6 et 7 disposent chacun de 2 unités de calcul. Le but est le même que celui d´ATI, mais la stratégie est différente. Pour Nvidia, étant donné que la partie destinée à masquer la latence du texturing est intégrée dans le pipeline de pixel shading, il représente un grand nombre de transistors et en placer plus est très coûteux alors qu´ajouter une unité de calcul supplémentaire en série est relativement aisé. Chez ATI un pipeline de pixel shading est très petit ce qui fait qu´il est peu coûteux à ajouter.
Tout ceci est relativement complexe et il faut trouver un moyen simple de le décrire. Auparavant, on parlait de pixel pipeline et d´unité de texturing, notés par exemple 4 x 2 ce qui signifiait 4 pipelines avec 2 unités de texturing chacun. Comment décrire en 2 chiffres une architecture actuelle ? Selon nous, la meilleure solution (ou la moins pire) est de le faire de la même manière ! A une petite nuance près : il faut parler de pipeline de pixel shading au lieu de pixel pipeline. Reste que le nombre d´unités de calcul n´est pas précisé, mais même indiquer ce nombre ne serait pas suffisant puisque l´efficacité des unités est aussi très importante. Au lieu de parler d´un certain nombre d´unités de calcul avec une certaine efficacité il est plus simple d´en faire abstraction et de parler simplement d´un pipeline de pixel shading capable d´une certaine efficacité. Ce paramètre étant variable il n´y a pas de moyen de l´indiquer d´une manière globale. Autrement dit selon nous, le plus simple reste de parler d´un GeForce 7800 GTX comme d´une architecture 24 x 1 et du X1800 comme une architecture 16 x 1.
ATI est cependant réticent à qualifier lui-même son GPU d´une architecture à 48 pipelines, plus que probablement par peur d´être critiqué par une attente non comblée de performances triplées par rapport à une architecture 16 pipelines. Mais aurait-il fallu parler de 2 GHz au lieu de 3 GHz pour un Pentium 4 simplement parce que l´Athlon a un meilleur rendement à fréquence égale ?
Ce changement fait passer le nombre de transistors de 321 millions à 384 millions soit une augmentation de 20%.
Enfin presque à l´heure puisqu´il était prévu pour fin 2005, mais étant donné qu´ATI s´est focalisé sur le X1800 ce petit retard n´a rien d´étonnant. Ce Radeon X1900, qui a déjà fait couler beaucoup d´encre, pourrait être vu comme une réponse au GeForce 7800 GTX 512 Mo lancé par Nvidia pour faire un pied de nez à ATI en novembre dernier. Mais en ce qui concerne ce GPU, ATI suit une roadmap planifiée il y a longtemps, même si elle entraîne le renouvellement du haut de gamme moins de 3 mois après son arrivée réelle sur le marché.
PipelinesLes rumeurs, discussions et interprétations sur les spécifications de ce GPU ont été nombreuses. Qu´en est-il réellement ? 16 pipelines ? 48 pipelines ? Mais qu´est-ce que c´est un pipeline ?
A l´origine, lorsque l´on parlait de pixel pipeline, ou de pipeline tout court, on décrivait la chaîne de fabrication de pixels la plus basique qu´il soit : une unité de texturing raccordée à un ROP qui se charge, lui, de placer le fragment (qui est un candidat pixel) dans l´image, c´est-à-dire au bon endroit dans la mémoire vidéo.
Avec l´évolution des GPUs, ceux-ci se sont vus adjoindre d´autres unités que l´unité de texturing pour arriver à un long pipeline qui contenait une ou deux unités de texturing, des unités de calcul et un ROP devenu plus complexe puisque capable de gérer les transparences (blending) et l´antialiasing de type multisample. Il est alors apparu que le ROP pouvait être dissocié du reste, ce qui fait que quand on parle de pipeline, c´est de ce reste que l´on parle. Les ROPs définissent le fillrate, c´est-à-dire le nombre de pixels qui peuvent être écrit en mémoire chaque seconde. Cette écriture consomme de la bande passante (64 bits par pixel, 96 bits en FP16/HDR, 160 bits en FP32, plus le blending...) et il apparaît évident que les 512 bits que peut transporter le bus mémoire chaque cycle (256 bits DDR), même avec les technologies de compression des données, ne peuvent pas recevoir les données d´un nombre très élevé de ROPs. 16 ROPs représentent le maximum raisonnable sur un bus mémoire 256 bits. La séparation des ROPs du reste permet d´augmenter ce reste à moindre coût sans ajouter de ROPs inutiles.
Chez Nvidia, ce reste est une longue chaîne de fabrication de pixel (ou fragment), qui contient plusieurs unités de calcul en série dont l´une pilote l´unité de texturing. Cette longue chaîne est nécessaire pour masquer la latence requise par l´accès aux textures. La fabrication d´un pixel consiste à calculer un pixel shader et étant donné que celui-ci peut-être très long, il requiert en général plusieurs passages dans le pipeline, qu´il est logique de qualifier de pipeline de pixel shading.
Chez ATI, le fonctionnement est un petit peu différent puisque les Radeon disposent de pipelines de pixel shading et de pipelines de texturing dissociés. Etant donné que la longueur du pipeline est utilisée pour masquer la latence du texturing, il est possible de n´utiliser qu´un très court pipeline pour la partie pixel shading. Par contre le système de gestion doit être plus complexe puisqu´il doit envoyer les pixels dans le bon pipeline au bon moment. Ainsi un pixel va faire un ou plusieurs allers-retours entre le pipeline de pixel shading et le pipeline de texturing. Les Radeon 9700 à X850 disposaient déjà d´une telle architecture, mais pas d´un système de gestion évolué ce qui fait qu´ATI ne pouvait pas en exploiter toute la flexibilité. Les Radeon X1000 en sont, elles, capables.
 Avec le Radeon X1900, ATI a décidé d´augmenter le nombre de pipelines de pixel shading. Par contre les pipelines de texturing restent, eux, à 16. Le choix d´ATI est basé sur le fait que le nombre d´instructions mathématique dans un shader augmente beaucoup plus vite que celui des accès aux textures, ce qui est tout à fait vrai. Nvidia pense la même chose puisque les pipelines de pixel shading des GeForce 6 et 7 disposent chacun de 2 unités de calcul. Le but est le même que celui d´ATI, mais la stratégie est différente. Pour Nvidia, étant donné que la partie destinée à masquer la latence du texturing est intégrée dans le pipeline de pixel shading, il représente un grand nombre de transistors et en placer plus est très coûteux alors qu´ajouter une unité de calcul supplémentaire en série est relativement aisé. Chez ATI un pipeline de pixel shading est très petit ce qui fait qu´il est peu coûteux à ajouter.
Avec le Radeon X1900, ATI a décidé d´augmenter le nombre de pipelines de pixel shading. Par contre les pipelines de texturing restent, eux, à 16. Le choix d´ATI est basé sur le fait que le nombre d´instructions mathématique dans un shader augmente beaucoup plus vite que celui des accès aux textures, ce qui est tout à fait vrai. Nvidia pense la même chose puisque les pipelines de pixel shading des GeForce 6 et 7 disposent chacun de 2 unités de calcul. Le but est le même que celui d´ATI, mais la stratégie est différente. Pour Nvidia, étant donné que la partie destinée à masquer la latence du texturing est intégrée dans le pipeline de pixel shading, il représente un grand nombre de transistors et en placer plus est très coûteux alors qu´ajouter une unité de calcul supplémentaire en série est relativement aisé. Chez ATI un pipeline de pixel shading est très petit ce qui fait qu´il est peu coûteux à ajouter.Tout ceci est relativement complexe et il faut trouver un moyen simple de le décrire. Auparavant, on parlait de pixel pipeline et d´unité de texturing, notés par exemple 4 x 2 ce qui signifiait 4 pipelines avec 2 unités de texturing chacun. Comment décrire en 2 chiffres une architecture actuelle ? Selon nous, la meilleure solution (ou la moins pire) est de le faire de la même manière ! A une petite nuance près : il faut parler de pipeline de pixel shading au lieu de pixel pipeline. Reste que le nombre d´unités de calcul n´est pas précisé, mais même indiquer ce nombre ne serait pas suffisant puisque l´efficacité des unités est aussi très importante. Au lieu de parler d´un certain nombre d´unités de calcul avec une certaine efficacité il est plus simple d´en faire abstraction et de parler simplement d´un pipeline de pixel shading capable d´une certaine efficacité. Ce paramètre étant variable il n´y a pas de moyen de l´indiquer d´une manière globale. Autrement dit selon nous, le plus simple reste de parler d´un GeForce 7800 GTX comme d´une architecture 24 x 1 et du X1800 comme une architecture 16 x 1.
48 pipelines pour le X1900, c´est vraiSuivant cela, qu´en est-il du Radeon X1900 ? La situation se complique puisqu´ATI y a intégré pas moins de 48 pipelines de pixel shading, ce qui donne, avec les 16 pipelines de texturing, 64 pipelines en tout. Parler de 64 pipelines amènerait de la confusion et ne correspondrait au modèle classique que l´on a l´habitude d´utiliser. Le plus simple est donc de parler d´une architecture 48 x 0.33, ce qui indique une puissance de calcul globale élevée mais réduite au niveau du texturing. Bien entendu, comme toute notation simple, elle est sujet à discussion. Si l´on veut décrire l´architecture plus fidèlement, il faut alors parler de 24 pipelines de pixel shading complexes pour le 7800 GTX, capables de traiter 2 instructions (dont éventuellement une de texturing) et de 64 pipelines de pixel shading simples pour le Radeon X1900 (dont 48 sont capables de traiter les instructions mathématiques et 16 celles de texturing).
ATI est cependant réticent à qualifier lui-même son GPU d´une architecture à 48 pipelines, plus que probablement par peur d´être critiqué par une attente non comblée de performances triplées par rapport à une architecture 16 pipelines. Mais aurait-il fallu parler de 2 GHz au lieu de 3 GHz pour un Pentium 4 simplement parce que l´Athlon a un meilleur rendement à fréquence égale ?
Ce changement fait passer le nombre de transistors de 321 millions à 384 millions soit une augmentation de 20%.
Spécifications, Pixel shaders

Sommaire
Vos réactions
Contenus relatifs
- [+] 04/05: Nvidia abandonne son GeForce Partne...
- [+] 27/04: AMD Vega 7nm en labo, Zen 2 échanti...
- [+] 18/04: ASUS AREZ, l'effet GeForce Partner ...
- [+] 10/04: Nvidia : fin du support Fermi et 32...
- [+] 27/03: Pilotes Radeon et GeForce pour Far ...
- [+] 20/03: Pilotes GeForce 391.24 pour Sea of ...
- [+] 20/03: Microsoft annonce DirectX Raytracin...
- [+] 20/03: Radeon Software 18.3.3 beta avec Vu...
- [+] 08/03: 3 millions de GPU vendus pour le mi...
- [+] 08/03: Radeon Software 18.3.1 optimisé pou...