
Les contenus liés au tag DirectX 12
Afficher sous forme de : Titre | FluxGDC: D3D12: Ashes of the Singularity et la BP mémoire
GDC: D3D12: des feature levels 12_0 et 12_1
GDC: Le test D3D12 de Futuremark en démo chez Microsoft
GDC: Mantle a rempli son rôle et est réorienté par AMD
GDC: Direct3D12: premiers conseils aux devs
DirectX 12 supportera un mix de GPU



Microsoft avait réservé pour sa conférence Build 2015 les détails concernant une énième nouvelle fonctionnalité de Direct3D 12 : le support explicite du multi-GPU. Il ouvre en théorie la voie aux combinaisons de tous types de GPU, y compris de marques différentes, mais la pratique ne sera pas aussi simple.
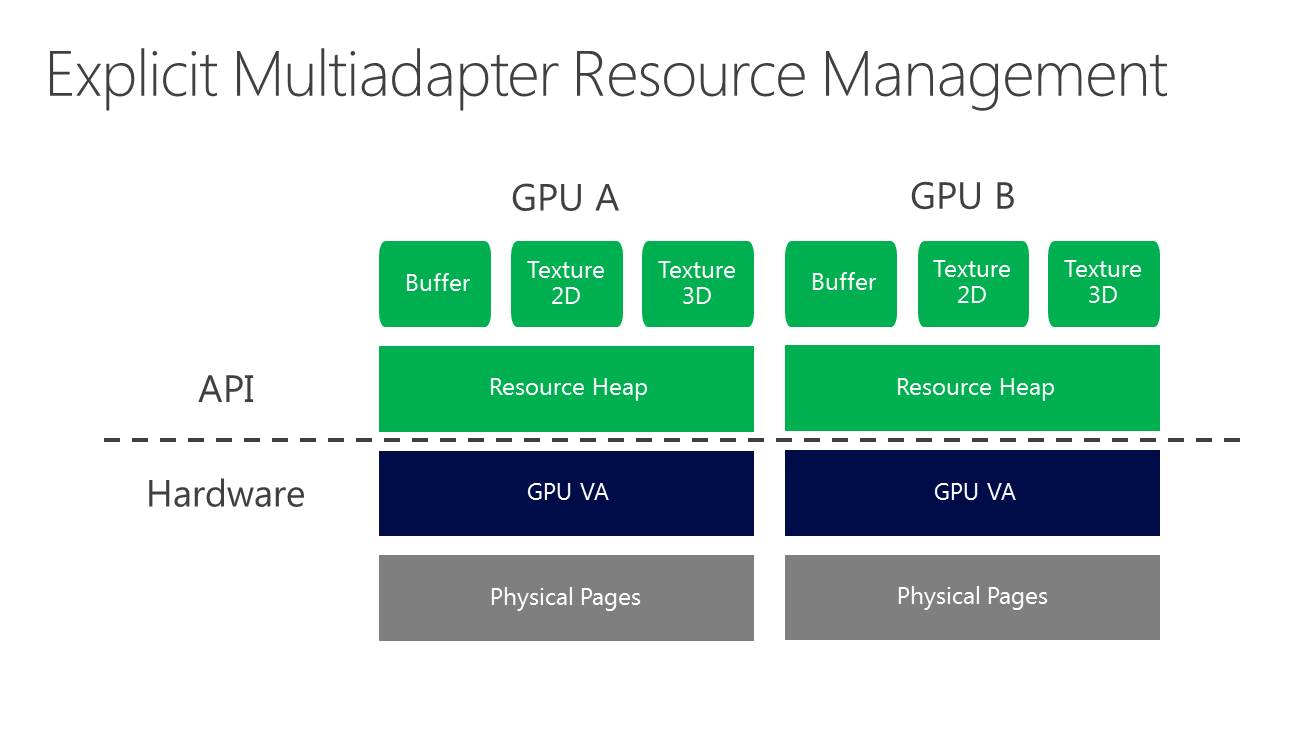
Direct3D 12, la composante graphique du prochain DirectX, supportera plusieurs modes de multi-GPU (multiadapter). Le premier est un mode de multi-GPU implicite, similaire à ce qui est utilisé actuellement par AMD et Nvidia sous Direct3D 11 ou OpenGL pour supporter le CrossFire et le SLI. Avec ce mode, les développeurs n'ont pas trop à se soucier du multi-GPU, les pilotes se chargeant de son support de façon à peu près transparente, même s'ils doivent faire en sorte qu'il n'y ait pas de dépendance entre les images, puisqu'il s'agit en général d'un rendu des images en alternance (AFR).

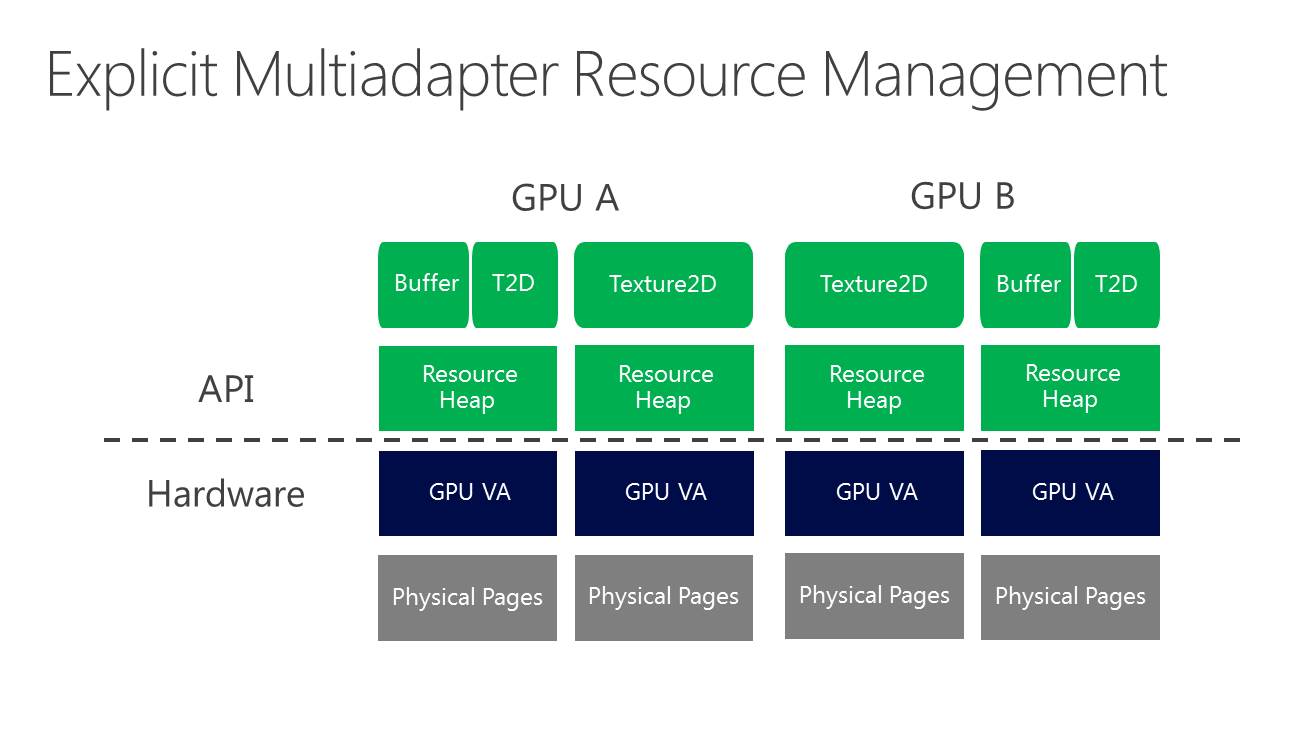
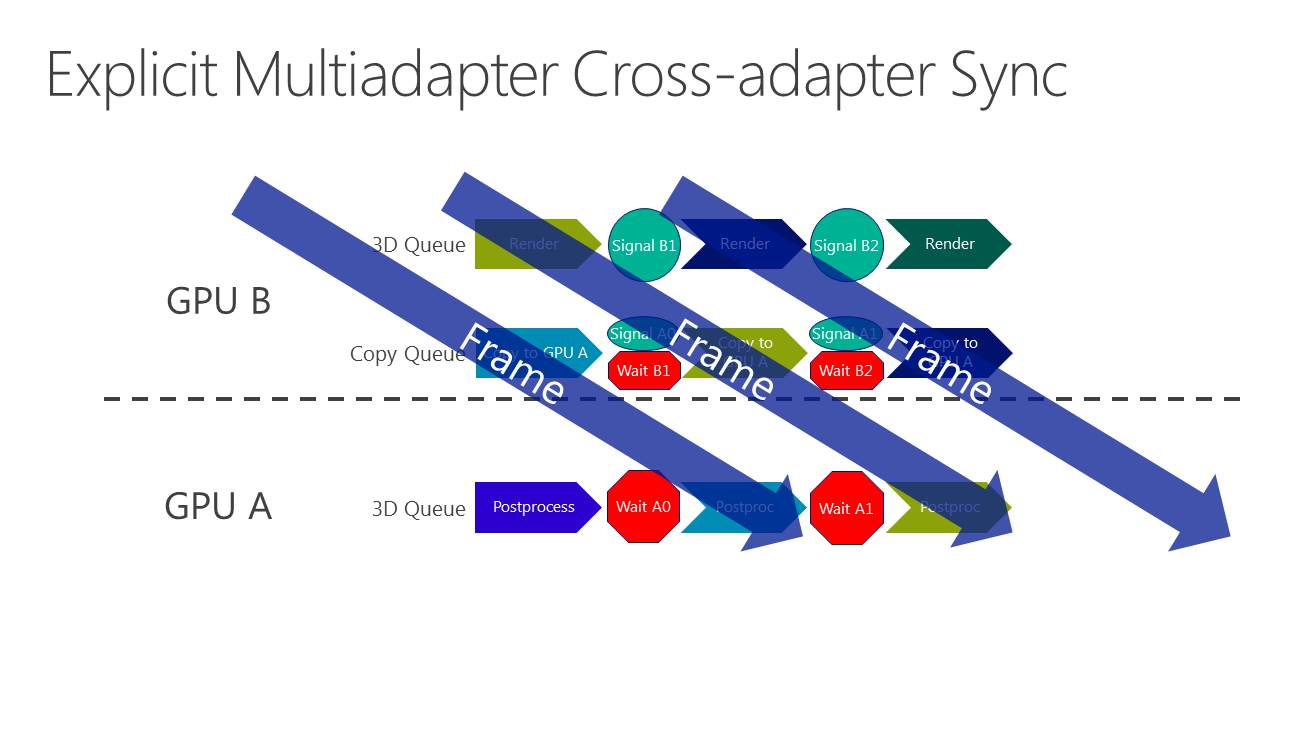
La nouveauté c'est le support du mode multi-GPU explicite, ou plutôt des modes explicites. Dans ces cas de figures, le contrôle du multi-GPU revient aux développeurs qui pourront en faire à peu près tout ce qu'ils veulent. Ce support est basé sur l'extension de la gestion par Direct3D de différents moteurs pour piloter un GPU (graphics, compute, copy), fonctionnalité qui permet pour rappel de profiter du parallélisme entre différents types de tâches, comme expliqué ici. En multi-GPU explicite, ces différents moteurs seront exposés pour chaque GPU.
A partir de là, deux sous modes peuvent être exploités. Le multi-GPU explicite lié (linked) est proche des CrossFire et SLI actuels (il en exploite le moteur de composition), si ce n'est que les développeurs prennent le contrôle. L'ensemble est vu comme un seul gros GPU qui dispose de plus de moteurs de types graphics, compute et copy. Ce mode pourrait par exemple permettre de supporter plus facilement un rendu de type AFR malgré certaines dépendances entre images. Microsoft n'est pas rentré dans les détails à ce niveau et s'est contenté d'indiquer qu'ils seraient communiqués plus tard. Nous ne savons pas non plus si AMD et Nvidia conserveront la mains sur les combinaisons supportées (par exemple 2 GTX 980 et pas GTX 980 + GTX 970).
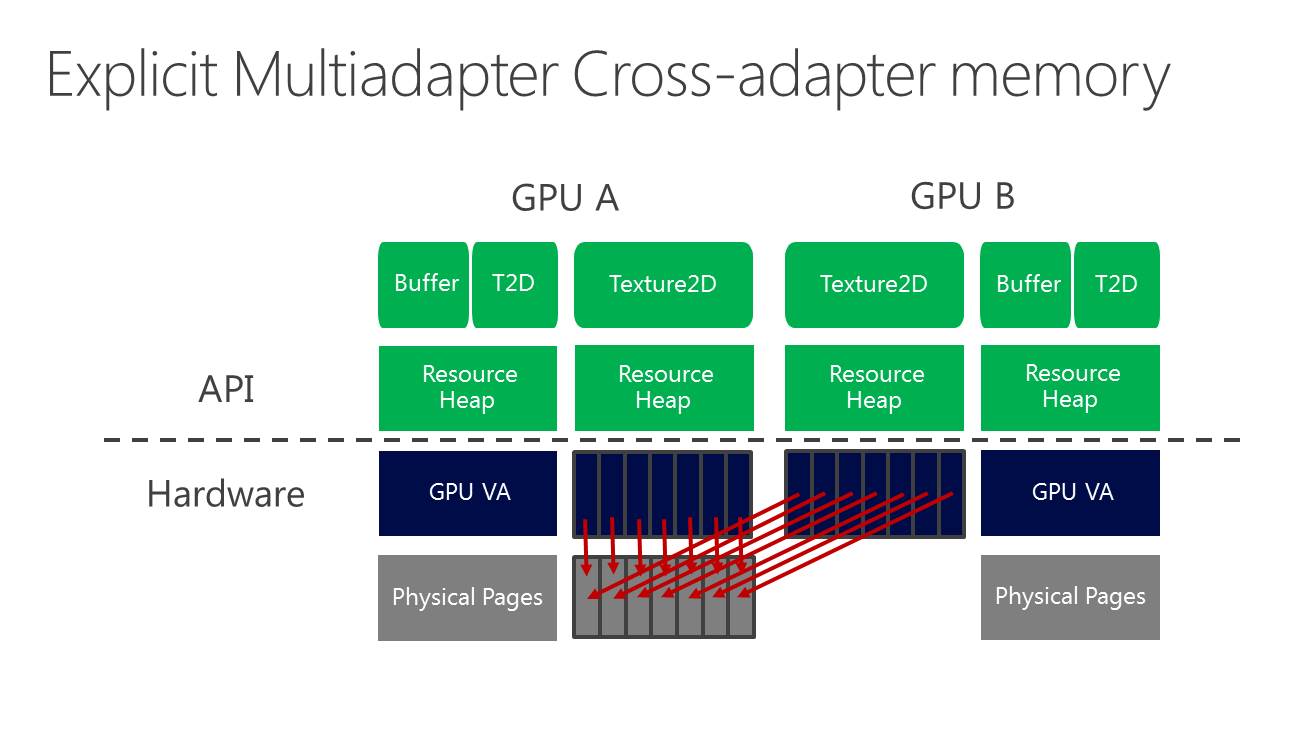
Enfin, le multi-GPU explicite non-lié (unlinked) est le mode qui autorise tout type de combinaisons de GPU. Direct3D 12 est très flexible et permet aux développeurs de gérer les synchronisations entre GPU, leurs mémoires respectives, des buffers distincts ou partagés, les transferts entre GPU Bref de quoi faire à peu près tout ce qui peut leur passer par la tête pour exploiter tous les GPU du système.
De quoi imaginer la combinaison d'une GeForce avec une Radeon ? Oui et non. C'est théoriquement possible, mais en pratique différents problèmes vont se poser, que ce soit en termes de performances via les optimisations spécifiques des pilotes, ou en termes de qualité avec de petites différences dans le rendu des images (notamment au niveau du filtrage des textures ou de l'antialiasing) qui vont entraîner un clignotement. Des modes de types AFR ou SFR avec un mix de GPU ne sont donc pas réalistes, tout du moins pour l'instant.
Rappelons cependant que dans la documentation de Mantle, nous avons pu découvrir qu'AMD avait prévu un mécanisme pour demander à ses cartes graphiques de rentrer dans un mode "neutre" en terme de qualité de manière à uniformiser le rendu autant que possible entre des GPU Radeon différents. Dans le futur ce principe pourrait être étendu à Intel et Nvidia, mais mettre tout le monde d'accord ne sera pas simple, d'autant plus que l'intérêt commercial sera limité.
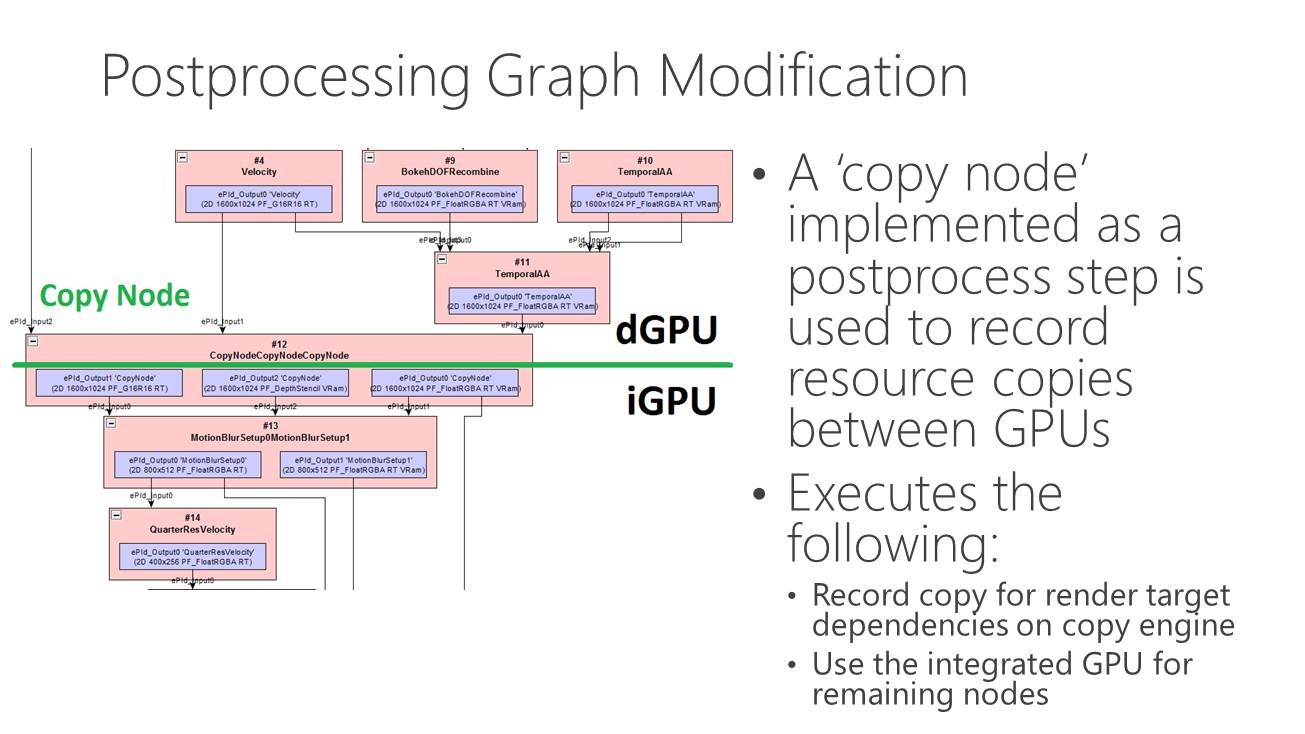
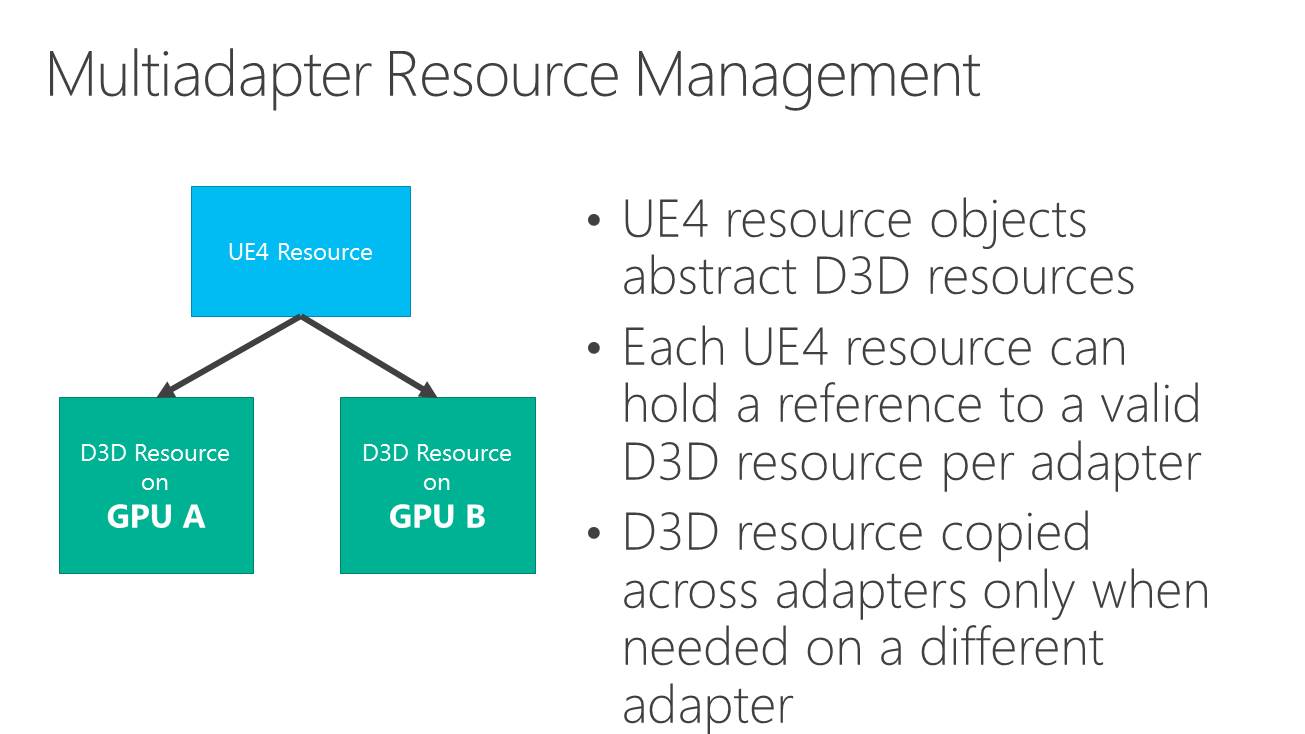
Dans l'immédiat, l'utilisation réaliste du multi-GPU explicite non-lié est différente. Il s'agit plutôt de faire traiter par chaque GPU différentes étapes du rendu, ce qui évite tout souci de qualité et de clignotement. C'est d'ailleurs ce qu'a choisi d'illustrer Microsoft qui a pour l'occasion modifié quelque peu l'Unreal Engine 4 de manière à déporter certaines tâches d'une carte graphique Nvidia vers un GPU intégré Intel.

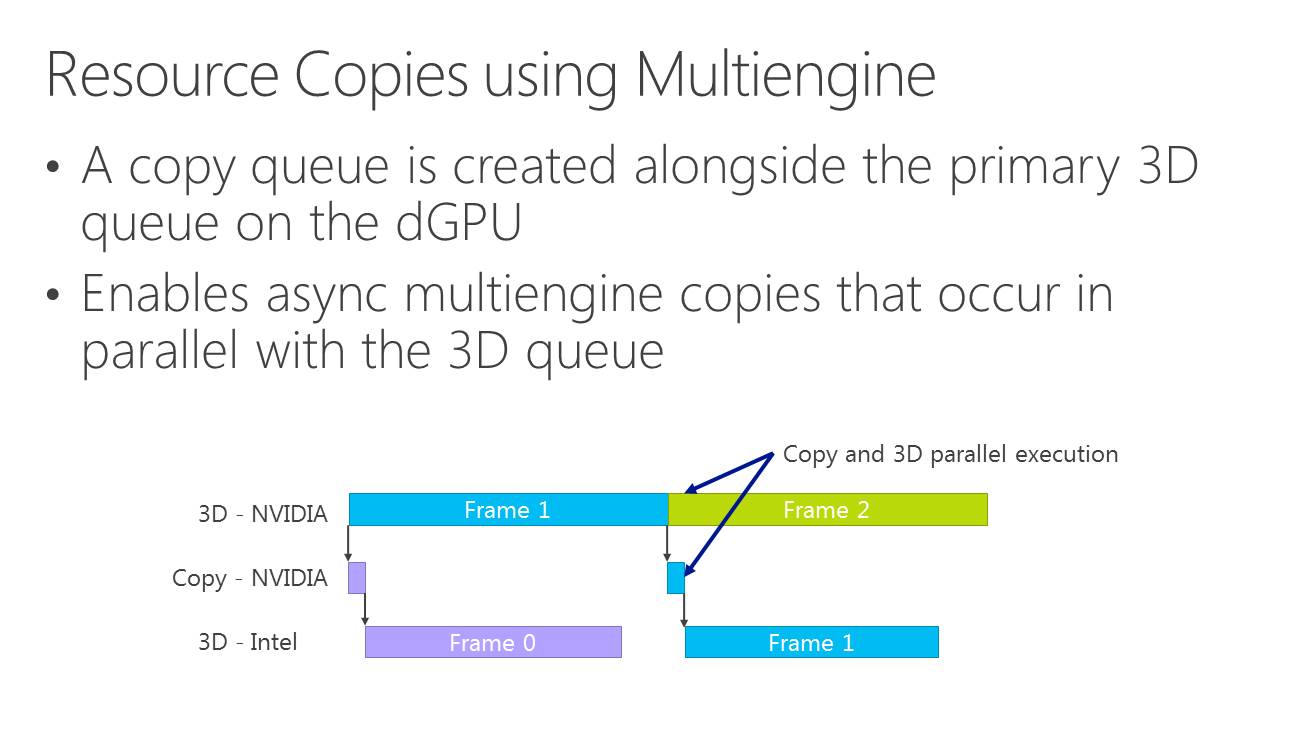
Dans cette démonstration, le plus gros du rendu est traité par la carte graphique mais la fin du post processing est traitée par le GPU Intel qui se charge ensuite de l'affichage. Travailler de la sorte au niveau du post processing permet d'exploiter toute la puissance de calcul disponible en minimisant les échanges de données via le bus PCI Express puisqu'il suffit en gros de transférer le frame buffer et le Z-Buffer.
Choisir où scinder le rendu est essentiel pour s'assurer qu'il y ait bel et bien un gain de performances. Microsoft explique à ce sujet avoir fait en sorte que le GPU intégré prenne toujours moins de temps à faire son travail que la carte graphique. Celle-ci reçoit un coup de boost mais reste l'élément qui définit les performances.
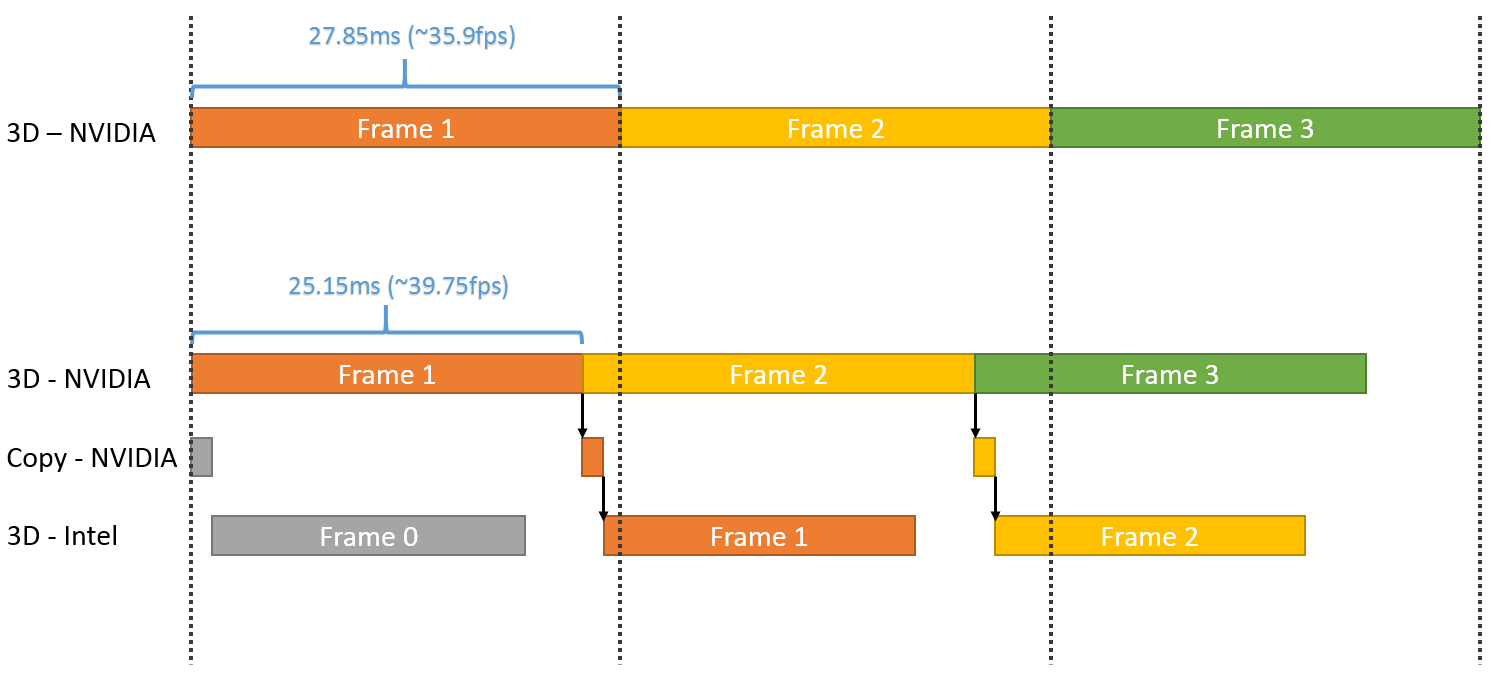
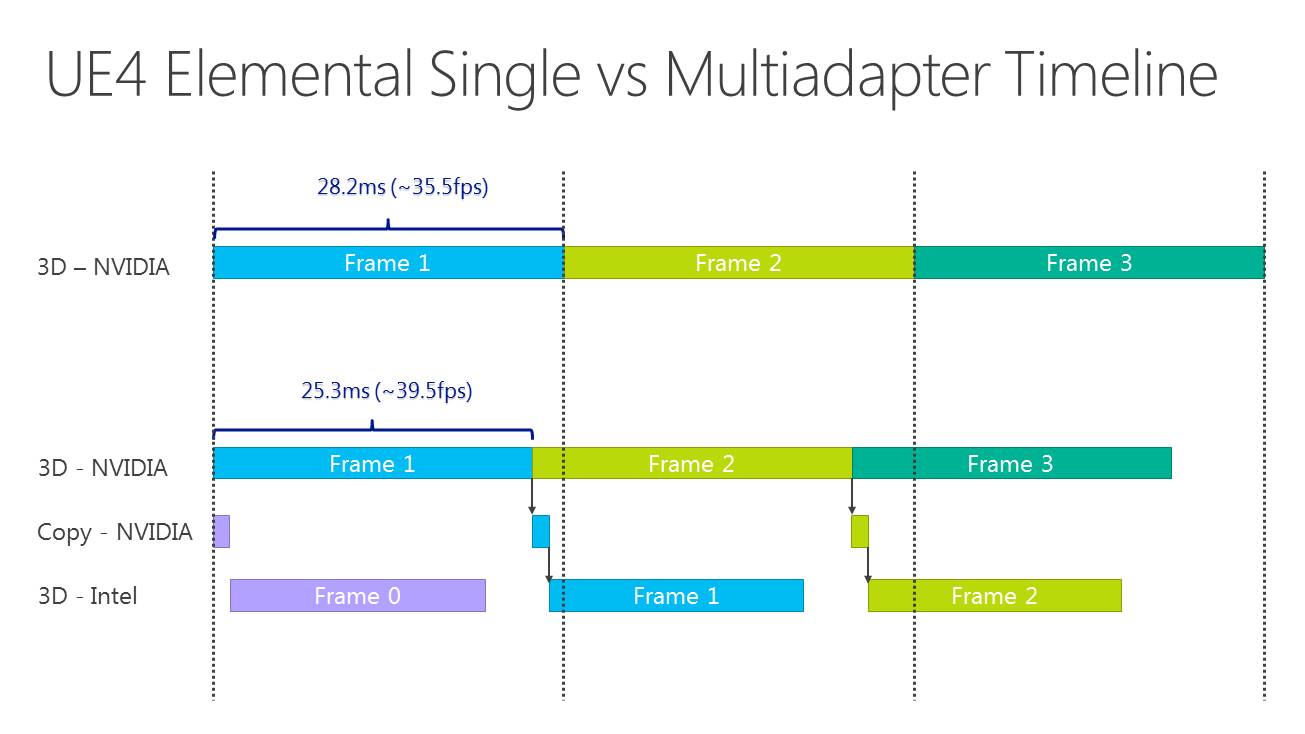
Plus spécifiquement, l'opération permet de passer de 35.9 à 39.7 fps, soit un gain de 10%. En observant de plus près cet exemple, il apparaît que le GPU intégré prend beaucoup plus de temps pour traiter la partie finale du post processing que la carte graphique, mais ce dernier n'ayant rien d'autre à faire, cela permet un gain de performances. C'est probablement surtout vrai pour les GPU d'entrée voire de milieu de gamme (Microsoft ne précise pas la configuration) alors qu'il serait peut-être contreproductif de vouloir aider une GeForce GTX Titan X avec un GPU intégré.
Par contre, il y a un désavantage évident à cette technique qui apparaît sur ce graphique : elle augmente la latence. Dans l'exemple de Microsoft, la partie de la latence liée au rendu passe de 28ms à plus ou moins 45ms quand le GPU intégré entre en action. Suivant le mode d'affichage, cela peut correspondre à l'ajout de l'équivalent d'une image de latence, ce qui ne plaira pas aux joueurs exigeants sur ce point.
Du coup est-ce bien utile pour les développeurs de jeux vidéo d'essayer de proposer ce type d'optimisations ? Une démonstration telle que celle de Microsoft est relativement facile à mettre en place grâce à Direct3D 12, mais dans la pratique, sur PC, il y a un nombre énorme de combinaisons possibles à prendre en compte pour que l'opération ne soit pas contre-productive. Et mettre en place un système de load balancing automatique dans les moteurs est loin d'être simple, même si ce n'est pas impossible.
Dans l'immédiat, il nous semble donc probable que cette possibilité de mélanger différents types de GPU reste avant tout dans la zone d'expérimentation pour les développeurs de jeux vidéo, même si les gros moteurs graphiques pourraient la supporter rapidement. Un peu plus tard, la première utilisation commerciale pourrait concerner certains PC d'entrée de gamme. Nous pensons par exemple aux plateformes Dual Graphics d'AMD (APU + GPU) ou encore aux portables Optimus de Nvidia (GeForce associée à un GPU Intel). Avec un petit effort de la part des développeurs de jeux vidéo, AMD et Nvidia pourraient prendre le relais avec des profils adaptés pour booster certaines de leurs plateformes.
Vous pourrez retrouver ci-dessous l'ensemble des slides de la présentation de Microsoft effectuée lors de la Build 2015 (section multiadapter à partir de la page 11) :


























[MAJ] GDC: D3D12: AMD parle des gains GPU
En bas de page, nous avons mis à jour cette actualité initialement publiée le 16 mars. AMD nous a transmis une nouvelle présentation sur le sujet et Nvidia nous a précisé ce dont étaient également capables ses GPU en terme de traitement simultané des tâches.
De nombreuses sessions dédiées à Direct3D 12 étaient organisées à la GDC. Après celle de Microsoft consacrée à Direct3D, lors de laquelle les niveaux de fonctionnalités ont été mentionnés et des démonstrations ont été faites sur du matériel Nvidia, nous avons assisté à la session d'AMD. Lors de celle-ci, il a été question d'une nouvelle opportunité d'optimisation : améliorer les performances GPU en profitant du traitement simultané de certaines tâches liées au rendu 3D.
Si l'intérêt des API de plus bas niveau est avant tout d'optimiser les performances au niveau du CPU, en réduisant le surcoût des commandes des rendus et en profitant mieux de tous les curs, des gains peuvent également être obtenus au niveau du GPU. Dans la plupart des démonstrations auxquelles nous avons pu assister jusqu'ici, les gains mis en avant concernaient avant tout les GPU intégrés dont l'enveloppe thermique limite les performances. Si la charge CPU est réduite, le GPU a plus de marge au niveau de sa fréquence turbo et c'est ce qui permet de faire grimper ses performances.
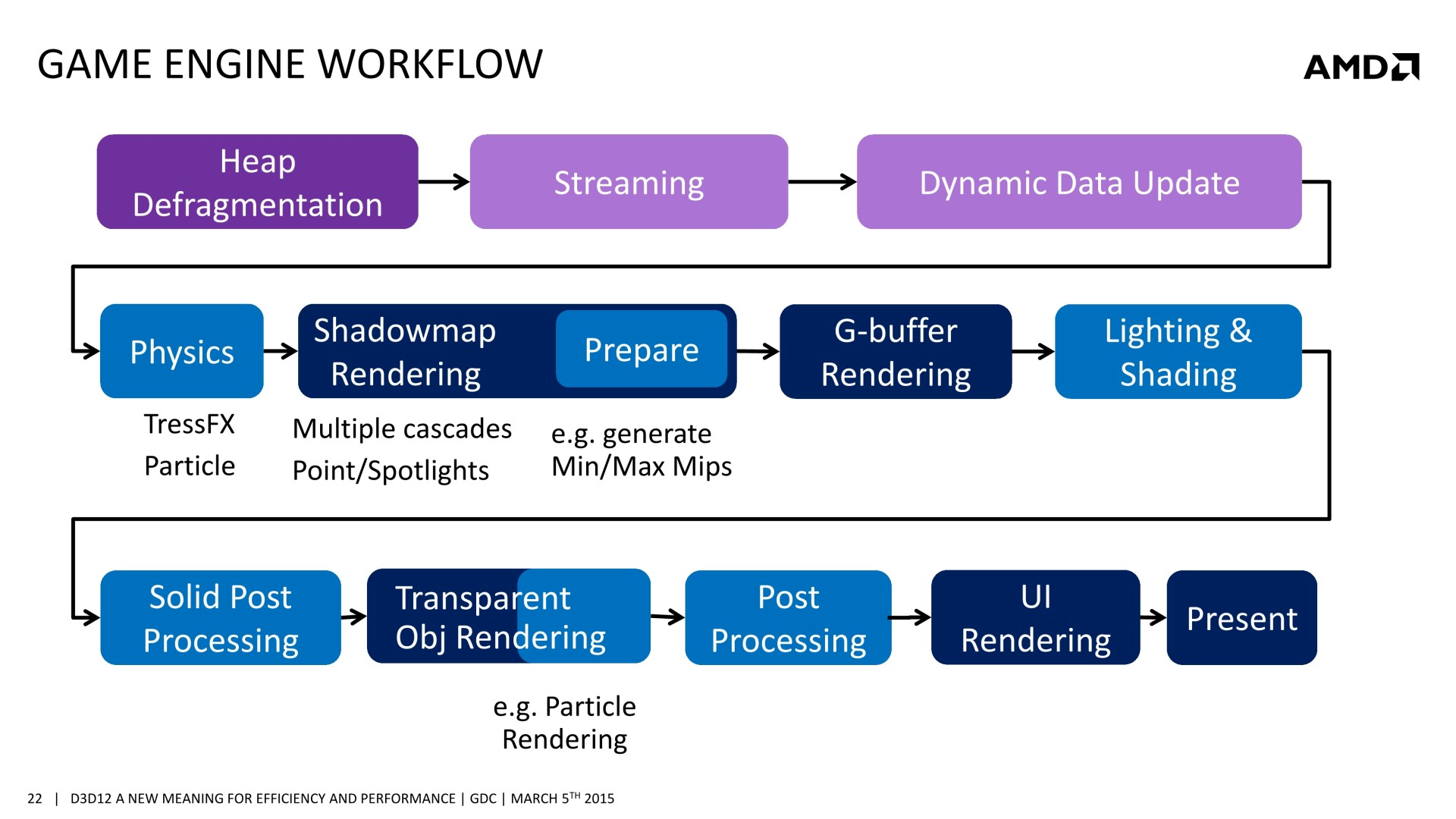
Mais il y a d'autres possibilités au potentiel important. AMD a ainsi mis en avant l'opportunité d'améliorer les performances GPU en profitant du traitement concomitant de certaines tâches. Avec les API classiques, toutes les étapes du rendu sont traitées en série par le GPU. Par exemple, le calcul de la physique, la préparation des ombres dynamiques, le remplissage du G-Buffer, l'éclairage et le post processing sont traités l'un après l'autre, aussi vite que possible par les GPU, mais en série.
Chacune de ces tâches n'exploite cependant pas la totalité des capacités d'un GPU. Par exemple, la préparation des ombres et le remplissage du G-Buffer vont plutôt saturer le sous-système mémoire alors que la physique, l'éclairage et le post processing ont plutôt tendance à saturer les unités de calcul. Il semble ainsi logique que traiter en même temps certaines de ces tâches représente une optimisation intéressante pour mieux exploiter les GPU.

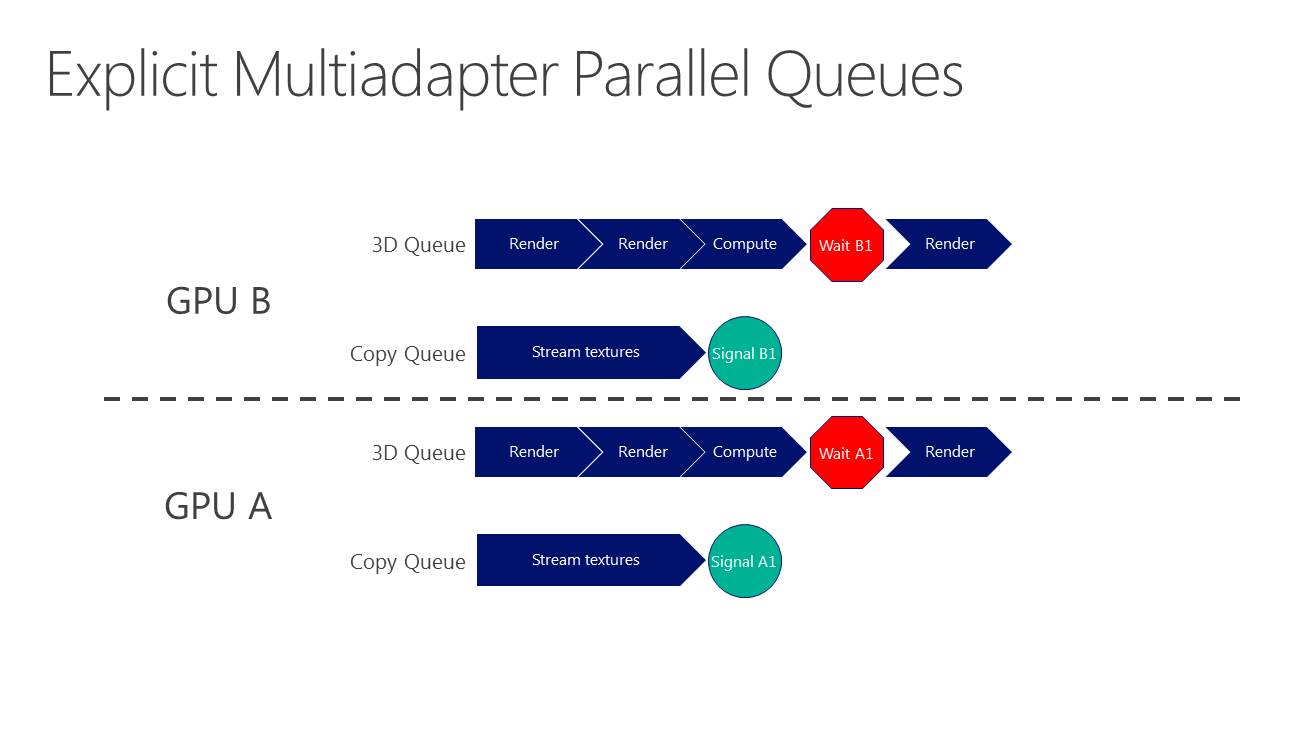
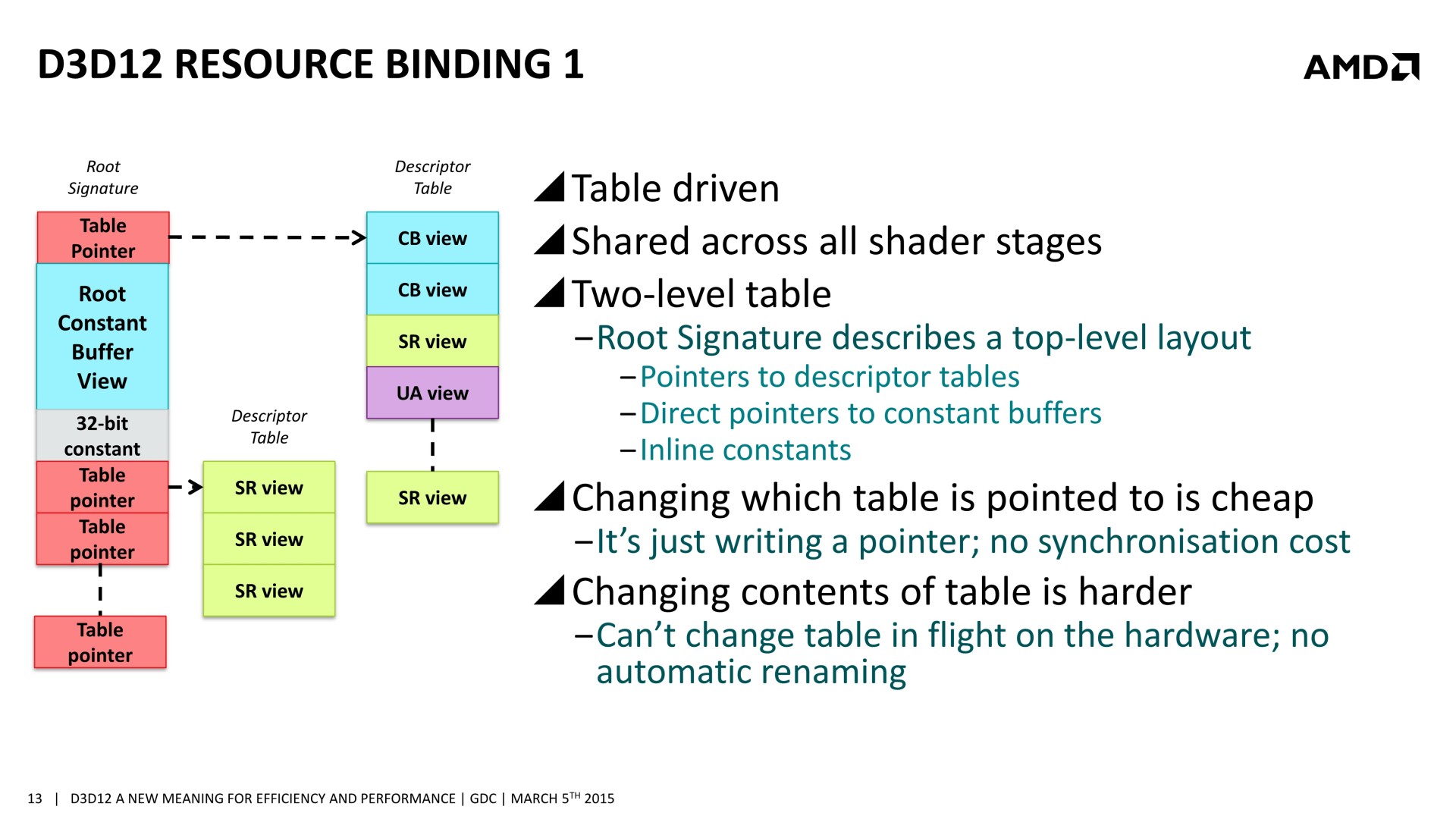
Et ça tombe bien, Direct3D 12, l'autorise. L'API de Microsoft semble reprendre exactement la base de Mantle sur ce point et prévoit 3 types de files d'attentes, également appelées "moteurs", dont les tâches peuvent être traitées en concomitance : Graphics, Compute et Copy. Au niveau des fonctionnalités prises en charge, Graphics est un superset de Compute qui est un superset de Copy. Cela veut dire que par défaut seul le moteur Graphics peut être exploité, puisqu'il est polyvalent. Il revient aux développeurs de spécifier l'utilisation des autres moteurs pour potentiellement optimiser les performances.
Il faut noter que ce type d'optimisation permet d'exploiter les ACE (Asynchronous Compute Engines) des GPU Radeon de la génération GCN. Pour rappel, AMD a implémenté ces processeurs de commandes secondaires justement pour pouvoir exécuter efficacement des tâches de type Compute en même temps que des tâches de type Graphics. D'autres GPU ne disposent pas de files d'attentes spécifiques au niveau matériel pour tous ces types de tâches et doivent alors les traiter de manière classique, en série. Ainsi, il n'est pas certain que les GPU Nvidia puissent profiter autant que ceux d'AMD de ce type d'optimisation.

Une bonne compréhension des architectures GPU et un profilage avancé des demandes de chaque tâche sont nécessaires. Il est également crucial de mettre en place correctement les barrières de synchronisation nécessaires, sans quoi des tâches dépendantes l'une de l'autre pourraient être exécutées en parallèle et causer des problèmes. AMD a insisté lourdement sur ce point, précisant que l'absence de barrières de synchronisation adéquates pourra passer inaperçue dans l'immédiat, sans bug visible, mais être source de gros problèmes avec de futurs GPU dont l'augmentation des performances profitera plus à certaines tâches qu'à d'autres. Comme le sait très bien AMD, les développeurs seront peu enclins à proposer un patch 2 ou 3 ans après la sortie d'un jeu, et appliquer un correctif au niveau des pilotes sera alors un véritable casse-tête, voire impossible dans certains cas.
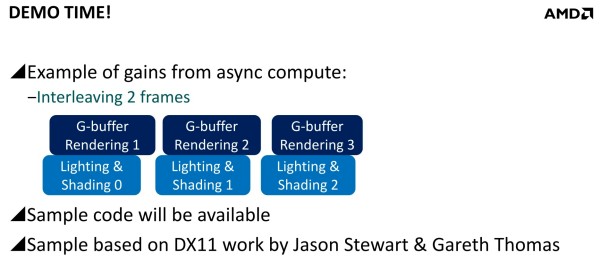
Mais avec un code robuste et un bon profilage, les gains peuvent être conséquents. Il est question de 20 à 25% dans des situations réalistes et avec des GPU capables d'en profiter. Deux exemples ont été mentionnés. Le premier, accompagné d'une démonstration, découple le remplissage du G-Buffer du calcul de l'éclairage qui est réalisé à travers un compute shader. Au lieu de traiter ces 2 opérations l'une après l'autre, elles sont effectuées en parallèle et de manière asynchrone : pendant que l'éclairage est calculé pour l'image 1, les opérations sur le G-Buffer sont traitées pour l'image 2 et ainsi de suite.
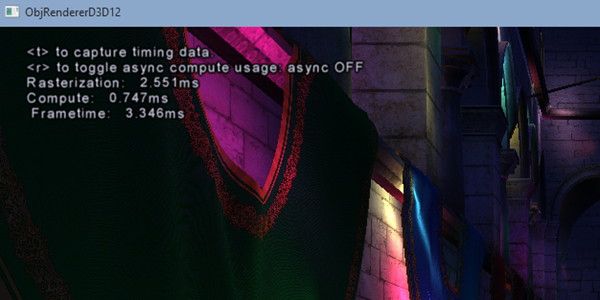
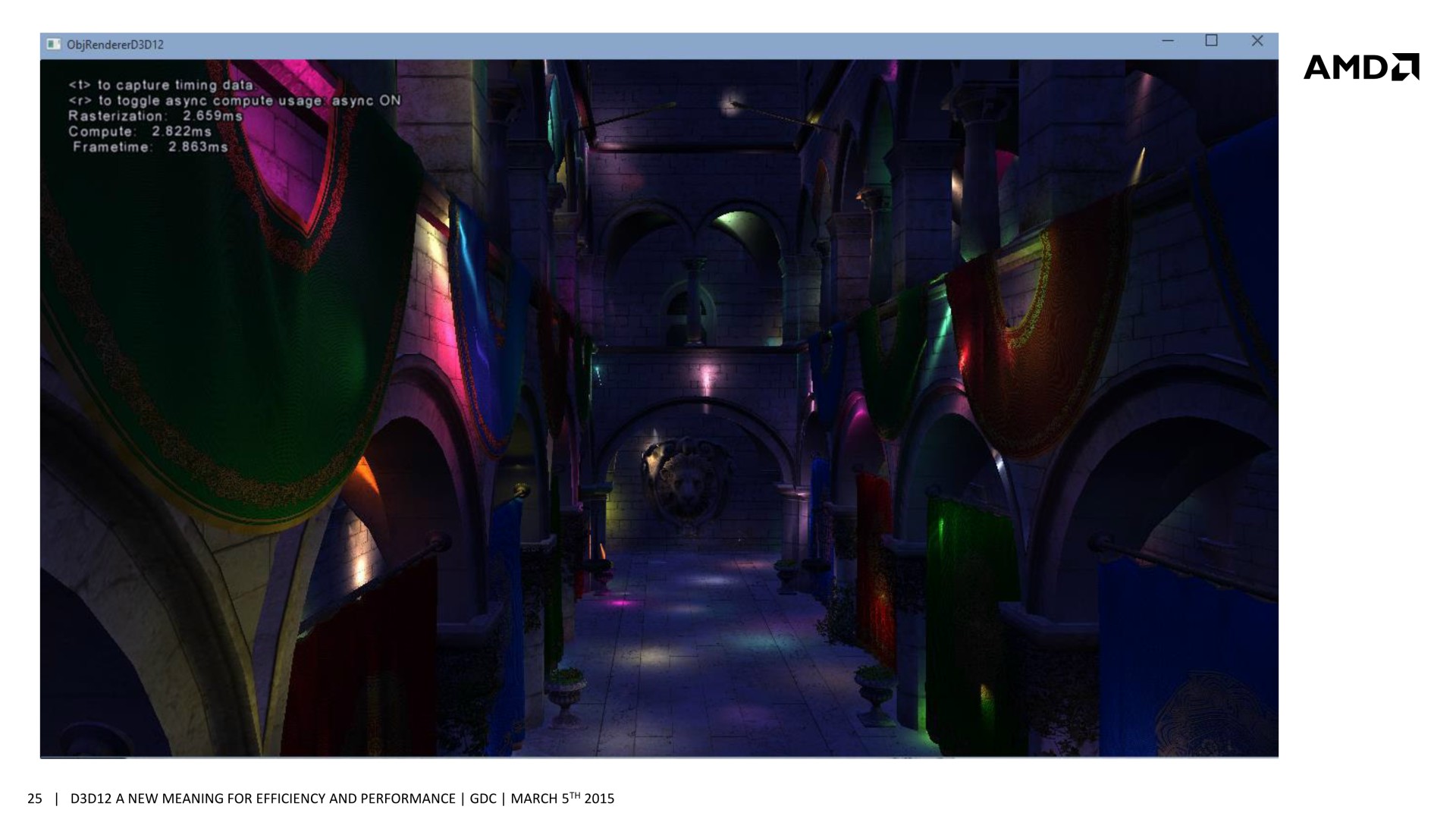
[ Concomitance OFF ] [ Concomitance ON ]
Sans traitement concomitant des tâches Graphics et Compute, le temps de rendu total prend 3.346ms (299 fps), ce qui est la somme des 2.551ms de la partie Graphics (remplissage du G-Buffer) et des 0.747ms de la partie Compute (calcul de l'éclairage). En activant le traitement concomitant dans cette démonstration, le remplissage du G-Buffer prend 2.659ms, et le calcul de l'éclairage 2.822ms. Ces deux tâches prennent plus de temps à être traitées, mais elles le sont en même temps et le rendu total ne prend plus que 2.863ms (349 fps), ce qui représente un gain de 17%. La latence peut par contre être légèrement plus élevée.
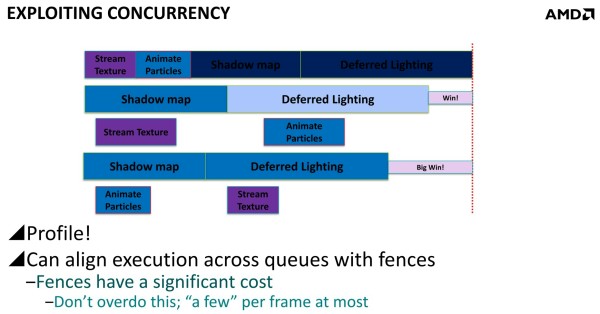
Dans un autre exemple, AMD explique que streamer les textures et animer les particules via les moteurs Copy et Compute permet un petit gain puisque ces opérations sont alors traitées en concomitance avec les ombres et l'éclairage. Mais il est possible d'aller plus loin en constatant qu'il est plus efficace d'animer les particules en même temps que la préparation des ombres et de streamer les textures en même temps que le calcul de l'éclairage que de faire l'inverse. En évitant d'exécuter en même temps des tâches qui ont des demandes similaires en termes de ressources GPU, les gains sont plus importants. D3D12 offre des mécanismes aux développeurs pour pouvoir gérer cela.
Les GPU modernes doivent en général faire face à des limites de consommation directes ou indirectes (via la température) et mieux exploiter la totalité de leurs capacités revient bien entendu à les pousser plus souvent ou plus loin dans ces limites. La fréquence GPU des cartes graphiques est alors réduite quelque peu, ce qui impacte les performances, mais dans des proportions bien moins élevées que les gains liés à ce type d'optimisations. Elles restent donc totalement légitimes. A voir par contre si de tels moteurs graphiques seront qualifiés de "power virus" par AMD et Nvidia, comme c'est le cas de Furmark et d'OCCT qui font également en sorte de saturer toutes les unités des GPU
Le set de slides de la session d'AMD à la GDC : (nous avons profité de la mise à jour pour remplacer nos clichés par des screenshots plus propres)























Mise à jour du 31/03 :
Quelques semaines après la GDC, AMD a décidé de mettre en avant ces possibilités d'optimisations auprès de la presse technique. Une présentation simplifiée nous a ainsi été distribuée il y a quelques jours. A noter que, bizarrement, elle était par contre accompagnée d'un embargo qui prenait fin ce matin alors même que la présentation plus complète, dont nous vous avions parlé ci-dessus, est publique depuis la GDC. Peu de médias s'y étaient cependant intéressés et le département de marketing technique d'AMD a probablement voulu mettre en place une communication synchronisée sur le sujet.






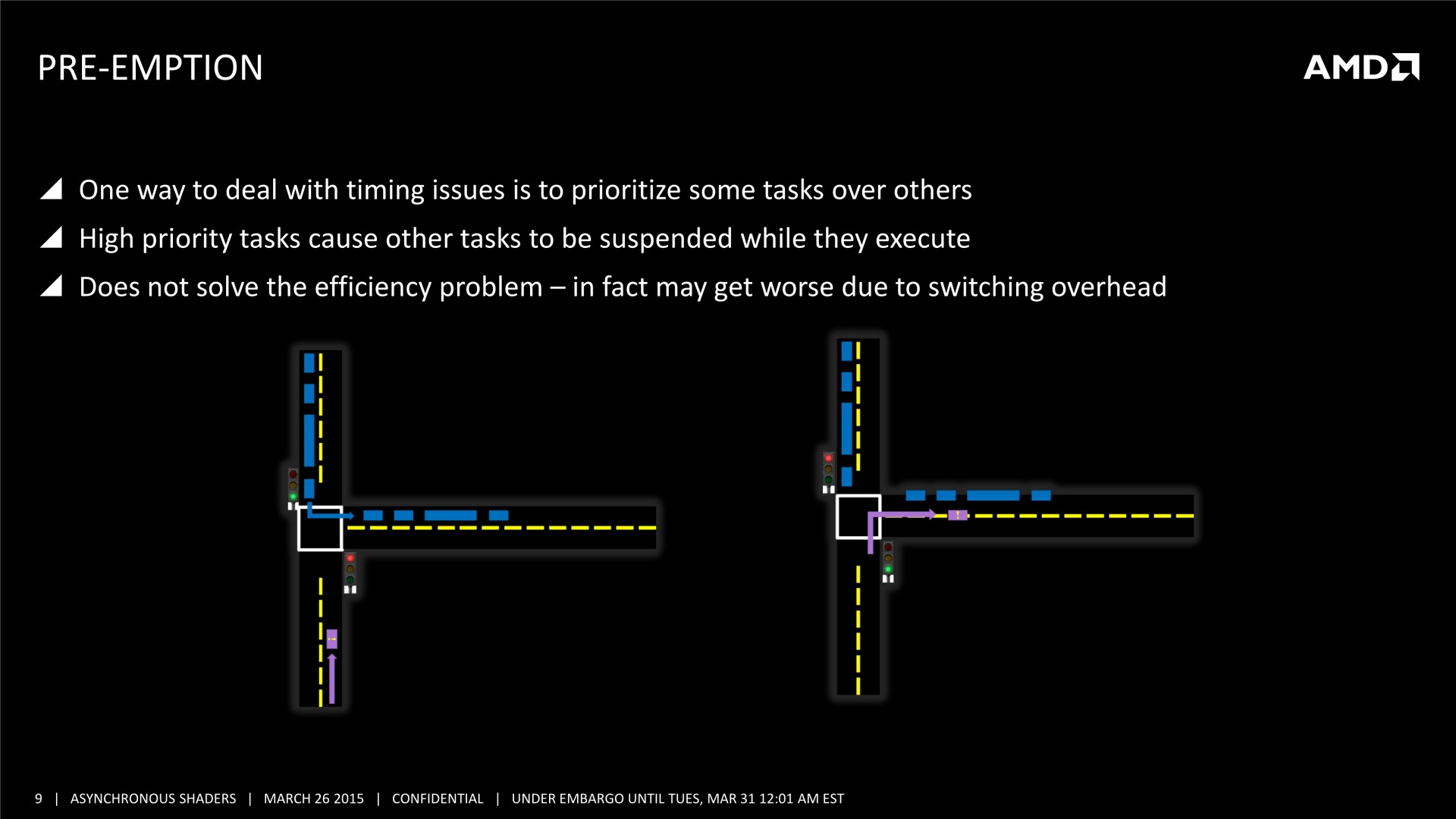

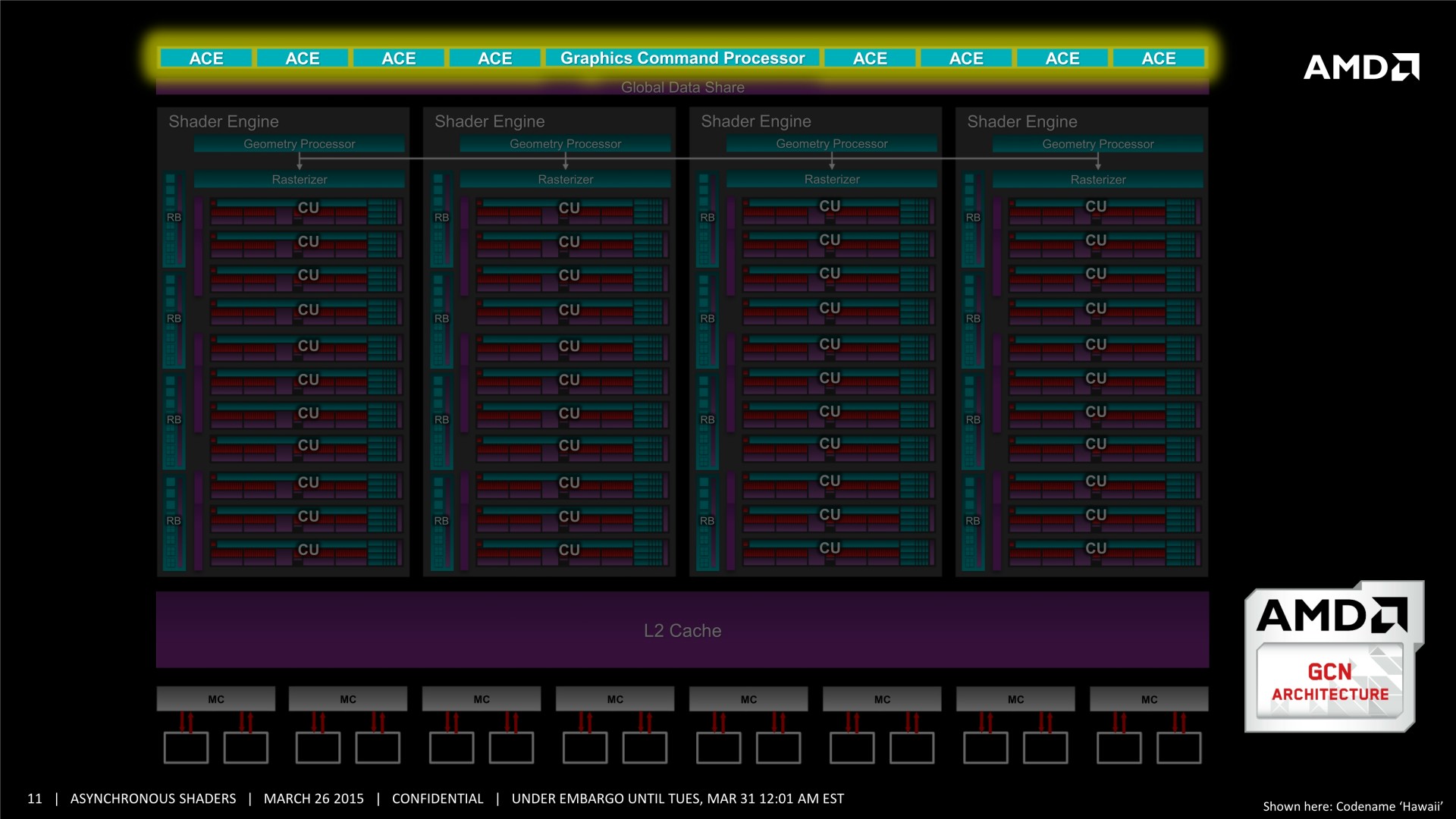
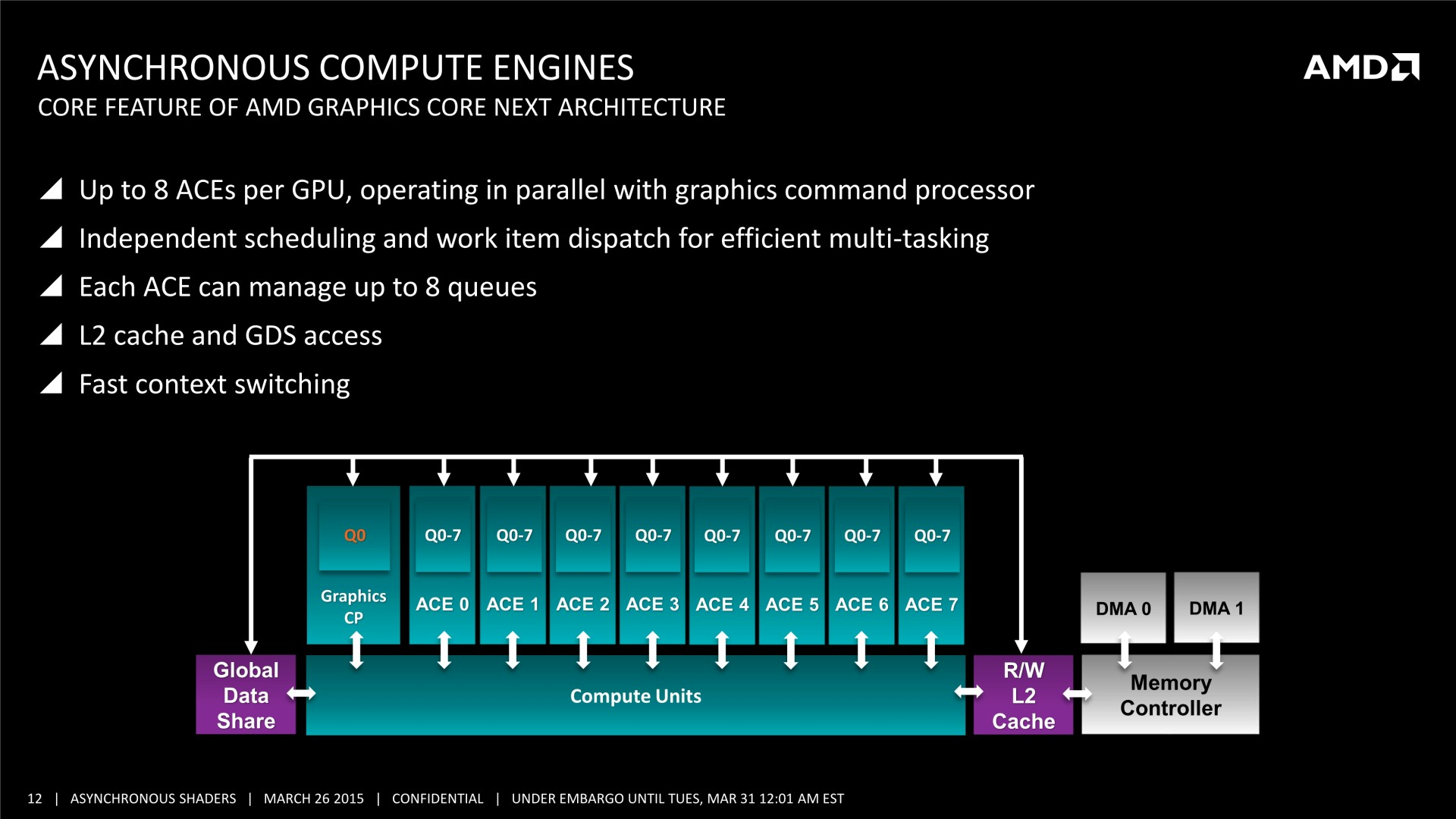
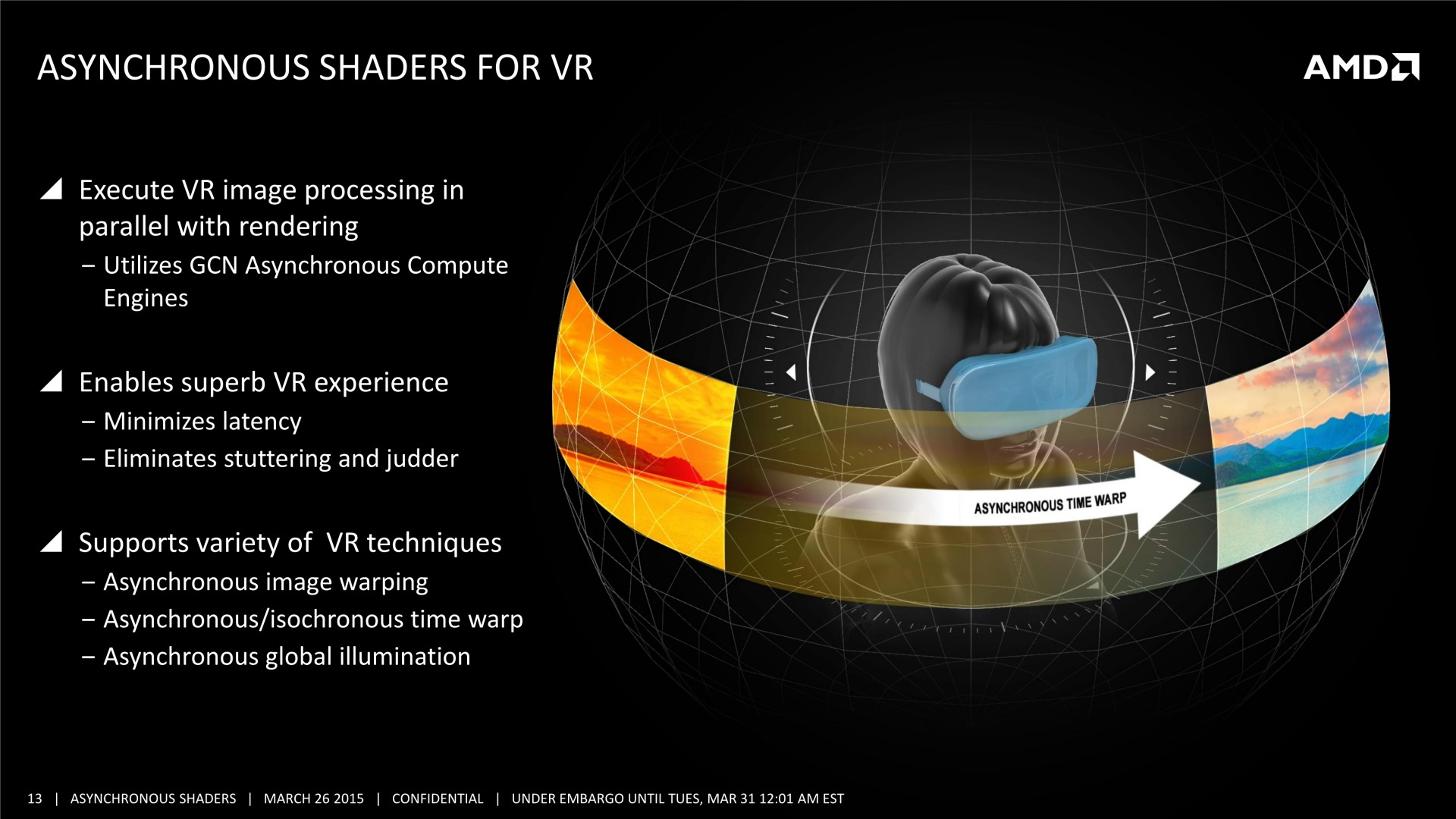





Il n'y pas pas d'information supplémentaire dans cette présentation, mais elle est plus simple à comprendre et mieux finie que celle adressée aux développeurs, nous l'avons donc ajoutée à cette longue actualité. A noter que le marketing technique d'AMD parle d'Asynchronous Shaders pour faire référence à l'exécution concomitante de différentes tâches (même si les opérations de type Copy ne sont pas des shaders). Vous pourrez également observer le résultat obtenu sous une autre démo, que nous avions pu observer également pendant la GDC durant la présentation de LiquidVR. L'utilisation du traitement concomitant du rendu (Graphics) et du post processing (Compute) y permet un gain de performances de 46%.
Si cette stratégie de communication d'AMD ne nous en a pas appris plus, elle a par contre eu le mérite de pousser Nvidia à enfin communiquer sur le même sujet. L'occasion de faire le point sur ce dont sont capables tous les GPU récents, notre première supposition n'étant pas tout à fait correcte concernant les derniers GPU Maxwell.
Du côté d'AMD :
Tous les GPU de type GCN supportent le traitement concomitant des tâches Graphics/Compute/Copy. En plus d'un processeur de commande principal polyvalent, ils disposent au moins de 2 ACE (Asynchronous Compute Engine), dédiés aux tâches de type Compute, et de 2 DMA Engines dédiés aux tâches de type Copy.
Il y a par contre des limitations pour les GPU GCN 1.0 (Tahiti, Pitcairn, Cape Verde, Oland). Leurs DMA engines ne supportent pas toutes les fonctions de synchronisation avec le CPU, ce qui impose probablement des limites au niveau du traitement concomitant des tâches de type Copy. Ensuite, les GPU plus récents, GCN 1.1, supportent plus de files d'attente par ACE (8 au lieu de 1), qui peuvent par ailleurs être présents en plus grand nombre. Ils sont ainsi adaptés au traitement concomitant de nombreuses petites tâches de type Compute (par exemple pour la physique ?), contrairement à leurs prédécesseurs.
AMD a implémenté dans ses pilotes Direct3D 12 un support complet de traitement concomitant de tous les types de tâches, exactement comme c'est le cas sous Mantle. Par contre, nous ne savons pas si les pilotes AMD sont capables de profiter de certaines de ces possibilités pour apporter des optimisations sous certains jeux Direct3D 11.
Du côté de Nvidia :
Les GPU Fermi et Kepler se contentent d'un seul processeur de commandes qui ne peut pas prendre en charge simultanément des commandes de type Graphics et de type Compute. Soit il est dans un mode, soit dans l'autre, un changement d'état relativement lourd à opérer.
Par ailleurs, à l'exception des GK110/GK210, ces anciens GPU ne disposent que d'une seule file d'attente au niveau de leur processeur de commande qui doit traiter les tâches dans l'ordre dans lequel elles sont soumises. Cela limite fortement la possibilité d'en traiter plusieurs simultanément à l'intérieur du mode Compute lorsqu'il y a des dépendances entre elles.
Avec le GK110, Nvidia a introduit un processeur de commandes plus évolué, qui supporte une technologie baptisée Hyper-Q. Elle représente la capacité de prendre en charge jusqu'à 32 files d'attente, mais uniquement en mode Compute. Ce GPU, et les GM107/GM108 qui reprennent cette spécificité, sont ainsi adaptés au traitement concomitant de nombreuses petites tâches de type Compute (par exemple pour la physique ?). Le GK110 a également introduit un second DMA Engine, mais il est réservé aux déclinaisons Tesla et Quadro.
Enfin, avec les GPU Maxwell 2 (GM200/GM204/GM206), Nvidia a fait sauter toutes ces limitations, contrairement à ce que nous pensions. Tout d'abord, le second DMA Engine est bien actif sur les déclinaisons GeForce. Mais surtout, quand Hyper-Q est actif, une des 32 files d'attente peut être de type Graphics.
Au niveau de l'implémentation logicielle, un traitement concomitant complet de tous les types de tâches est supporté sous Direct3D 12 pour les GPU Maxwell 2. Il n'est par contre pas possible d'effectuer une exécution concomitante entre Direct3D 12 et CUDA, qui repose sur un pilote différent.
Nvidia a également implémenté dans ses pilotés un support limité de l'exécution concomitante sous Direct3D 11, pour les tâches compute uniquement. L'API ne permet pas d'y accéder explicitement, mais quelques astuces permettent aux pilotes d'activer un tel mode pour optimiser les performances (dans le cas de GPU PhysX ?). Nvidia nous a précisé que la question d'y ajouter le support d'un traitement concomitant complet de tous les types de tâches, comme sous Direct3D 12, restait en suspens. Ce n'est pas impossible si cela avait une utilité, mais aucun jeu Direct3D 11 actuel n'est prévu pour en profiter. Sans support explicité dans l'API il est très difficile pour les développeurs de faire en sorte que cela puisse fonctionner.
En résumé :
HD 7000 & Rx 240/250/270/280 : processeur de commandes x1 queue + 2 ACE x1 queue + 2 DMA engines
->Graphics/Compute/Copy avec limitations
HD 7790 & R7 260 : processeur de commandes x1 queue + 2 ACE x8 queues + 2 DMA engines
->Graphics/Compute/Copy
R9 285/290 : processeur de commandes x1 queue + 8 ACE x8 queues + 2 DMA engines
->Graphics/Compute/Copy
GTX 400/500/600/700 : processeur de commandes x1 queue + 1 DMA engine
->Pas de support
GTX 750/780/Titan : processeur de commandes x32 queues (limité) + 1 DMA engine
->Compute/Compute
GTX 900/Titan X : processeur de commandes x32 queues + 2 DMA engines
->Graphics/Compute/Copy
Au final, c'est surtout au niveau des anciens GPU que se différencient AMD et Nvidia, le premier ayant un support en place au niveau matériel depuis plus longtemps. Au niveau des cartes graphiques plus récentes, les GeForce GTX 900 pourront profiter pleinement des optimisations liées au traitement concomitant des tâches, tout comme le feront les Radeon R9 290 par exemple.
Par contre, il reste à voir ce qu'en feront les développeurs. Les gains ne seront pas automatiques et il faudra que les différentes étapes du rendu 3D s'y prêtent. Ce n'était de toute évidence pas le cas pour Battlefield 4 et le Frostbite Engine par exemple, dont la version Mantle ne profite pas réellement de ce type d'optimisation.
Le test DirectX 12 de 3DMark est disponible
Futuremark vient de rendre disponible son premier outil de test DirectX 12. Il s'agit d'un test synthétique, et non d'une scène complète, dont le but est de mesurer les performances de différentes API ainsi que des pilotes au niveau du surcoût CPU.
Rappelons d'une part que les API classiques, telles que DirectX 11 ou OpenGL, affichent un surcoût très élevé pour chaque commande, notamment parce qu'elles effectuent de nombreuses vérifications à la place du développeur. D'autre part, elles n'autorisent qu'un contrôle très limité sur le parallélisme au niveau de ces commandes, ce qui limite fortement la capacité des développeurs à exploiter tous les curs CPU.
Les API récentes, dites de bas niveau, telles que Mantle, DirectX 12 ou encore Vulkan, font exploser ces barrières en transférant presque tout l'aspect "contrôle" vers les développeurs. Si ceux-ci font en sorte de proposer un code à la fois robuste et efficace, les performances peuvent faire un bond au niveau du CPU, grâce à un surcoût réduit et à une meilleure utilisation de tous les coeurs.

C'est ce que permet de mesurer l'API Overhead Feature Test de 3DMark. Ce test, très léger au niveau du GPU, consiste à augmenter progressivement le nombre d'objets affichés dans la scène, et donc la charge CPU, jusqu'à se stabiliser à 30 fps. Plus l'API et le pilote graphique sont performants, plus il sera possible d'aller loin dans le test et donc d'afficher plus d'objets.
L'API Overhead Feature Test est compatible avec DirectX 11, DirectX 12 et Mantle. Dans le cas de DirectX 12, Windows 10 Technical Preview build 10041 ou supérieur sera nécessaire, et dans le cas de Mantle, le système devra bien entendu être équipé d'une Radeon compatible.
Nos confrères de PCPer ont pu effectuer quelques premiers tests avec des pilotes beta fournis par AMD et Nvidia. Dans ces premiers résultats, si les GeForce et leurs pilotes ont un avantage sensible sous DirectX 11, surtout en mode multithreading (basique), ce sont les Radeon et leurs pilotes qui prennent l'avantage sous DirectX 12. Les gains observés peuvent dans les deux cas être supérieurs à 10x entre DirectX 11 et DirectX 12. Des gains qui signifient qu'à charge égale il est possible de se contenter de plus petits CPU, ou qu'il sera possible pour les développeurs de décupler la complexité des mondes qu'ils créent.
Si vous disposez déjà de 3DMark (Advanced ou Professional), la mise à jour v1.5.884 devrait vous être proposée au prochain lancement. Quant à la course aux pilotes optimisés, elle ne devrait pas tarder.
GDC: Quelle API de bas niveau va s'imposer ?
Au cours de la semaine de la GDC, nous avons demandé à la plupart de nos interlocuteurs quel était leur pronostic officiel dans la bataille qui s'annonce entre les différentes API de bas niveau. Vulkan va-t-il avoir une chance sous Windows ? La réponse a été quasi unanime : non. Explications.
Avec Mantle, AMD et Frostbite ont démontré qu'exploiter des API graphiques de plus bas niveau dans les moteurs de jeu PC était tout à fait réaliste et n'avait pas de raison d'être une exclusivité des consoles. Depuis, la liste de ces API s'est allongée :
- Mantle supporté par les Radeon sous Windows 7/8/10
- Direct3D 12 supporté par tous les GPU sous Windows 10 et par la Xbox One
- Metal supporté par les SoC Apple sous iOS
- Vulkan supporté par tout type de GPU sous tout type de plateforme
- et nous pouvons y ajouter GNM, l'API de la PS4
Sur le papier, Vulkan a un avantage important puisqu'il va permettre à un moteur graphique de supporter de nombreuses plateformes et notamment Android et Linux/SteamOS. Pourquoi ne pas supporter Windows au passage ? Si les spécialistes du moteur de jeu prévoiront probablement cette possibilité, personne ne s'attend à ce qu'elle soit exploitée.
Microsoft ne compte pas proposer de support de Vulkan pour la Xbox One, ce qui va forcer les développeurs à exploiter Direct3D 12. Vu la proximité avec la plateforme Windows, il n'y aura pas d'intérêt à y proposer Vulkan sur PC.
Mais ce n'est pas tout. Vulkan pourrait avoir des difficultés sur d'autres fronts. Alors que nous l'imaginions en bonne position sous Android, la plupart de nos interlocuteurs ont émis un avis plus mitigé. A la question de savoir pourquoi, nous avons en général reçu un sourire gêné en guise de réponse car une autre API est embusquée. C'est un secret de polichinelle dans le milieu des spécialistes de la 3D : Google prépare sa propre API graphique de bas niveau. Une annonce qui pourrait avoir lieu fin mai lors de la conférence Google I/O ou un peu plus tard cette année.
Cette API devrait être ouverte dans le sens où ses spécifications seront fixées par Google, mais son implémentation pourra se faire sur d'autres plateformes. De quoi venir concurrencer directement Vulkan, par exemple si elle était portée sous Linux et SteamOS.
Cela ne veut pas dire pour autant que Vulkan est mort-née. Il y aura vraisemblablement toujours des développeurs qui voudront profiter de son support multiplateformes, surtout dans le monde mobile. Mais à terme, il semble évident que chaque plateforme voudra contrôler sa propre API graphique de bas niveau, ce qui est naturel pour les acteurs concernés. Les spécialistes des moteurs graphiques, tels que l'Unreal Engine, l'Unity, le Cry Engine ou encore le Frostbite, y trouveront probablement leur compte, mais le développement de moteurs "indépendants" risque de devenir difficile à supporter pour de plus en plus de studios.
GDC: D3D12: Une guerre des specs en vue ?
Comme nous l'expliquions il y a peu, Microsoft a dévoilé à la GDC les 2 nouveaux niveaux de fonctionnalités de Direct3D 12 : 12_0 et 12_1. Mais d'autres segmentations plus subtiles existent, de quoi nous laisser penser que les départements communications d'AMD et de Nvidia pourraient se battre à coups de niveaux de support de DirectX 12.
De toute évidence, Microsoft avait demandé à AMD et Nvidia de ne pas lancer de polémique à la GDC sur le niveau de support des spécifications de Direct3D 12 de leurs GPU. Il n'y a ainsi eu aucune communication officielle à ce sujet mais nous avons pu gratter quelques détails lors de discussions informelles ou en posant des questions à la fin des différentes sessions.

Tout d'abord, nous pouvons confirmer que les GeForce Maxwell de seconde génération (GTX Titan X, 980, 970 et 960) supportent bien le niveau de fonctionnalité le plus élevé : 12_1. Il a de toute évidence été modelé d'après les spécifications de l'architecture de Nvidia. Nous ne savons par contre toujours pas s'il existe des GPU actuellement commercialisés de niveau 12_0.
Cela ne veut pas dire pour autant que les dernières GeForce GTX supportent la totalité des possibilités de Direct3D 12. Ainsi, en plus des niveaux de fonctionnalités, des niveaux de support appelés Tiers existent pour différents points.
Le principal concerne les capacités de gestion des différentes ressources (Resource Binding) qui augmente en passant du Tier 1 au Tier 2 et atteint un niveau presqu'illimité au Tier 3. Microsoft a précisé que sur base des dernières statistiques de Steam, et en ne prenant en compte que le matériel compatible avec Direct3D 12, 39% du parc installé est limité au Tier 1, 44% au Tier 2 et 17% supporte le Tier 3. Mais quel GPU supporte quel Tier ?

Selon nos informations, les GPU Maxwell sont en fait limités au Tier 2, qui est nécessaire au support des niveaux 12_0 et 12_1 et qui a probablement lui aussi été modelé autour de leurs capacités. Une des différences les plus importantes avec le Tier 3 concerne la gestion des Constant Buffer Views (CBV) : ceux-ci ne sont pas virtualisés et sont limités en nombre à 14. Il est probable que l'architecture Maxwell soit capable de virtualiser les CBV, mais que l'implémentation logicielle/matérielle de Nvidia profite d'un mode plus performant avec une gestion "fixe" des Constant Buffers. Un compromis qui limite quelque peu la flexibilité accordée aux développeurs pour s'assurer que les GPU GeForce restent dans un mode optimal sur le plan des performances.
Mais alors à qui correspond les 17% de GPU compatibles Tier 3 ? Toujours selon nos informations, il s'agit des Radeon de type GCN qui profitent d'une architecture très flexible à ce niveau. D'un côté les GeForce GTX 900 supportent le niveau 12_1, d'un autre les Radeon R9 200 supportent le Resource Binding Tier 3. Un combat de spécifications en perspective ? Difficile pour AMD d'attaquer les GTX 900 sur base de cela pour l'instant mais cela risque de changer avec Fiji. Si ce futur GPU supporte le niveau 12_1 et le Tier 3, nul doute que vous en entendrez parler ! Si par contre Fiji est limité au niveau 12_0 et Tier 3, chacun devra préparer ses arguments.
Au final, voici comment le support des Resource Binding Tiers est de toute évidence réparti sur PC :
Tier 1 : Nvidia Fermi, Intel Haswell et Broadwell
Tier 2 : Nvidia Kepler et Maxwell 1/2
Tier 3 : AMD GCN
A noter que pour les fonctionnalités spécifiques au niveau 12_1, les Raster Ordered Views et la Conservative Rasterization, il existe également des Tiers 1 et 2 dont les spécificités nous sont pour l'heure inconnues. L'implémentation de Nvidia se limiterait au Tier 1 et il pourrait être possible là aussi pour AMD d'essayer de se démarquer. Affaire à suivre.