
Les derniers contenus liés aux tags Nvidia et DirectX
GDC: Nvidia met en avant son pilote Direct3D 11
GDC: DirectX 12: 'Mantle' standardisé en 2015
Le futur Direct3D dévoilé en mars, l'effet Mantle?
Microsoft annonce DirectX Raytracing



Microsoft a profité de l'ouverture de la GDC pour annoncer une nouvelle API, DirectX Raytracing (DXR) . Comme son nom l'indique, il s'agit d'une nouvelle API qui vient s'ajouter aux autres API DirectX pour standardiser l'utilisation de certaines techniques dites de raytracing. Le raytracing tente pour rappel de représenter de manière plus exacte le parcours de la lumière pour proposer des rendus réalistes. L'inconvénient de la technique étant son coût généralement prohibitif, même si des approximations existent.
A l'inverse, le rendu 3D dans les jeux actuel est basé sur la rasterisation, la projection d'une scène 3D en 2D avant d'y appliquer les traitements pour obtenir la couleur des pixels, avec des techniques plus ou moins avancées de gestion de lumière (les premiers jeux 3D se contentant d'imiter les effets de lumière en les dessinant directement dans les textures, tandis qu'aujourd'hui les pixel shaders s'appliquent sur l'image 2D ce qui limite les possibilités même si les développeurs sont extrêmement créatifs). Comme le rappelle le sous titre de l'annonce de Microsoft, "3D Graphics is a lie" (le rendu 3D est un mensonge) !
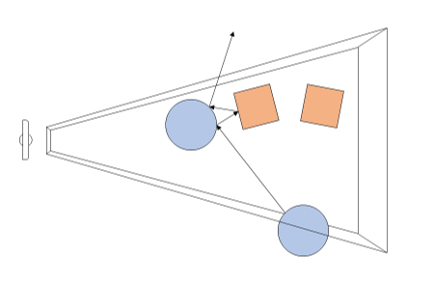
Avec DXR, Microsoft souhaite donc ajouter un peu de "réalisme" avec une petite dose de raytracing. Dans le détail, il s'agit d'une API complémentaire qui ajoute de nouvelles possibilités pour utiliser le raytracing par dessus les pipelines actuels de rasterisation. En pratique, DXR s'appuie sur une représentation de la géométrie pour lancer des rayons. Par dessus cette représentation, chaque objet ou groupe d'objet pourra définir des "raytracing shaders" et des textures spécifiques à utiliser. Une fois ceci crée, le lancé de rayons est appliqué, l'API définie les cas d'intersection, de non intersection, et de "presque" intersection (near miss), en gérant les cas ou les rayons rebondissent sur plusieurs surfaces (multi bounce).
Techniquement, le lancer de rayon est effectué a partir de la "caméra" dans la variante utilisée par DirectX, et peut se faire pour une sélection de pixels de l'écran ou la totalité (Microsoft prend l'exemple de ne le faire uniquement que pour les objets dont la surface est réfléchissante).

Un exemple de rendu DXR avec le moteur SEED d'EA, Project PICA
D'un point de vue compatibilité avec le matériel existant, Microsoft renvoi simplement vers les constructeurs pour les détails. Certains matériels sur le marché disposeraient déjà d'un support de DXR (on ne sait pas lesquels), et Microsoft semble proposer un mode de rendu alternatif s'appuyant sur Direct Compute pour fonctionner sur tout le matériel existant aujourd'hui (avec un niveau de performances on l'imagine réduit).
AMD nous a indiqué qu'ils collaboraient "étroitement" avec Microsoft "pour les aider à définir, améliorer et prendre en charge l'avenir de DirectX 12 et du ray tracing", un propos qui évite soigneusement de prononcer l'acronyme DXR. AMD dispose déjà d'une API de ce type utilisable sur de multiples plateformes avec Radeon Rays . Interrogé sur la question spécifique de l'accélération matérielle, AMD nous a indiqué qu'ils proposeraient, à un moment non défini, un pilote qui proposera une accélération DXR (au delà du mode "fallback" utilisant Direct Compute et qui lui marche sur tous les GPU, mais probablement en étant peu utilisable). Ce qui sera accéléré, et quelles cartes seront concernées n'est pas encore défini non plus selon le constructeur. On semble sentir une certaine précaution pour ne pas dire frilosité de la part de la société sur sa communication, il nous est difficile de savoir s'il s'agit d'un manque de préparation sur le sujet, d'un désaccord avec Microsoft sur certains choix effectués, ou d'autre chose.
Nvidia de son côté a évoqué son implémentation sous le nom de RTX, cette dernière ne s'appliquera qu'à compter des GPU Volta et ultérieurs (soit uniquement la Titan V dans les GPU "joueurs" actuels de la gamme du constructeur). Nvidia présente la technologie là aussi de manière assez vague, sous entendant que leur implémentation sera utilisable "via" DXR, mettant son API en avant sans que l'on sache si c'est simplement dans un but de démarcation compétitive ou autre chose. Là encore à l'image d'AMD, la communication des deux principaux constructeurs ne va pas exactement dans le même sens que celle de Microsoft (les relations entre Microsoft et les responsables GPU ont toujours été particulières, chacun tentant de tirer la couverture de son côté et de créer un avantage compétitif, que ce soit les constructeurs de GPU l'un face à l'autre, ou Microsoft à proposer une API et des fonctionnalités qui ne soient pas cross-platform).
Du côté des développeurs, Microsoft annonce que les moteurs Frostbite, SEED (plus haut), Unity et Unreal Engine proposeront une forme de support de DXR. Futuremark devrait également proposer un test de ce type pour une version de 3D Mark.
Focus : Ashes of the Singularity et DirectX 12 : AMD vs Nvidia
Après deux années de gestation, DirectX 12 s'apprête enfin à devenir réalité avec l'arrivée des premiers jeux développés pour cette nouvelle API graphique plus efficace. A la clé, des gains de performances potentiellement significatifs autant du côté CPU que du côté GPU et la dernière version beta d'Ashes of the Singularity est l'occasion d'observer tout cela de plus près à travers un premier match AMD vs Nvidia sous DirectX 12.
Libérer le CPU
Ashes of the Singularity est un jeu de stratégie en temps réel développé par Oxide Games et Stardock Entertainment. La particularité de ce...
[+] Lire la suite

[MAJ] GDC: D3D12: AMD parle des gains GPU
En bas de page, nous avons mis à jour cette actualité initialement publiée le 16 mars. AMD nous a transmis une nouvelle présentation sur le sujet et Nvidia nous a précisé ce dont étaient également capables ses GPU en terme de traitement simultané des tâches.
De nombreuses sessions dédiées à Direct3D 12 étaient organisées à la GDC. Après celle de Microsoft consacrée à Direct3D, lors de laquelle les niveaux de fonctionnalités ont été mentionnés et des démonstrations ont été faites sur du matériel Nvidia, nous avons assisté à la session d'AMD. Lors de celle-ci, il a été question d'une nouvelle opportunité d'optimisation : améliorer les performances GPU en profitant du traitement simultané de certaines tâches liées au rendu 3D.
Si l'intérêt des API de plus bas niveau est avant tout d'optimiser les performances au niveau du CPU, en réduisant le surcoût des commandes des rendus et en profitant mieux de tous les curs, des gains peuvent également être obtenus au niveau du GPU. Dans la plupart des démonstrations auxquelles nous avons pu assister jusqu'ici, les gains mis en avant concernaient avant tout les GPU intégrés dont l'enveloppe thermique limite les performances. Si la charge CPU est réduite, le GPU a plus de marge au niveau de sa fréquence turbo et c'est ce qui permet de faire grimper ses performances.
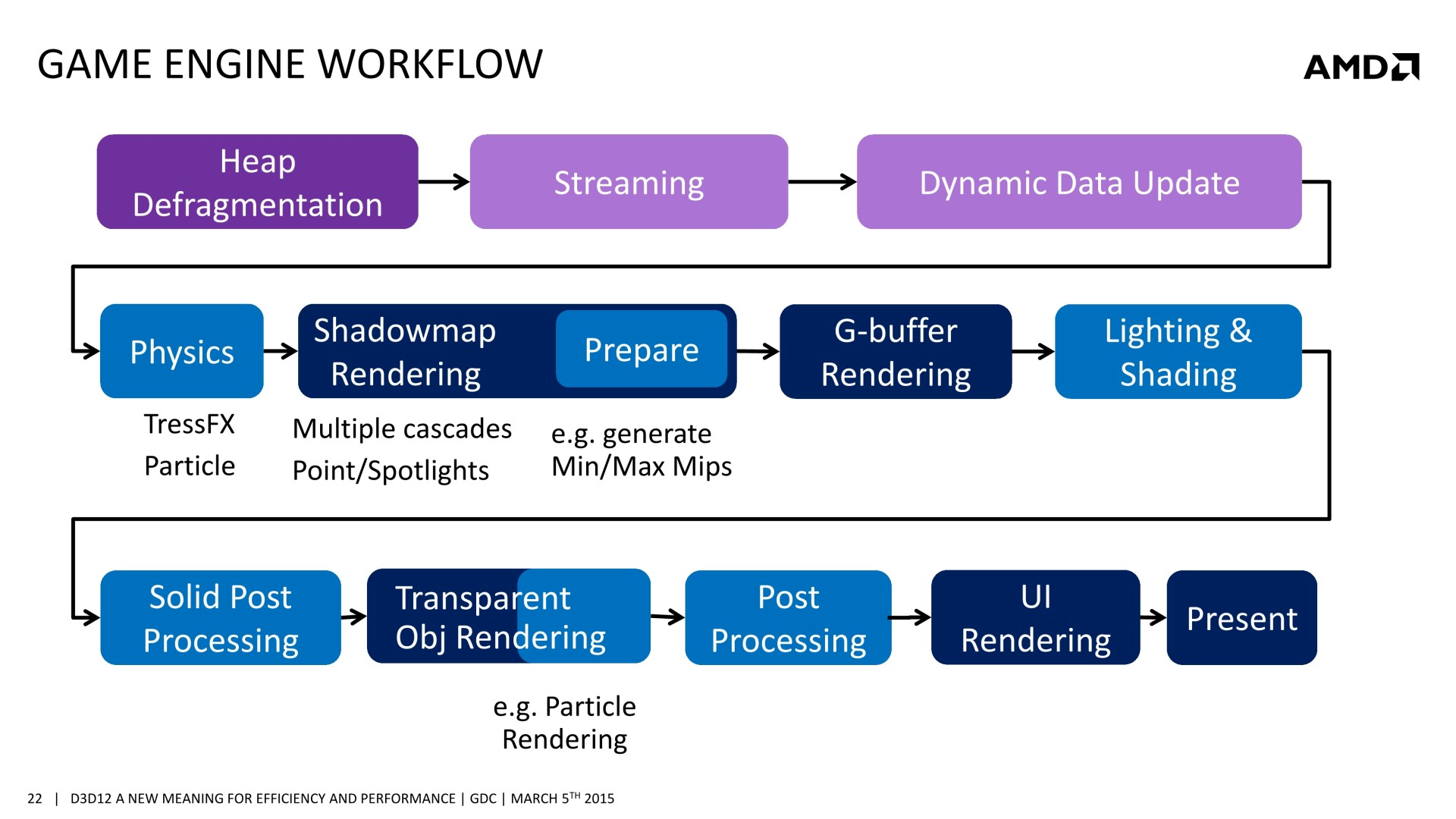
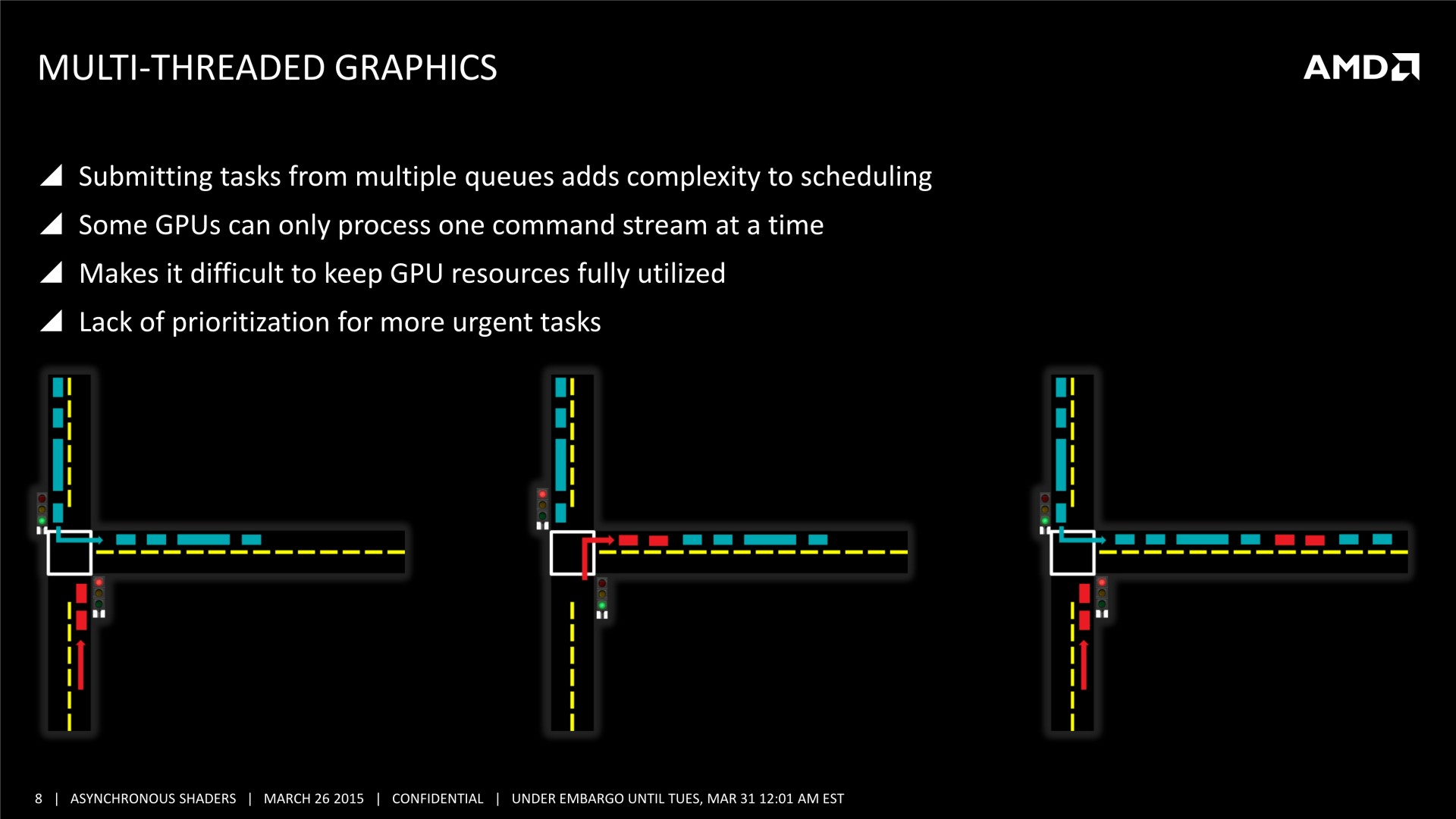
Mais il y a d'autres possibilités au potentiel important. AMD a ainsi mis en avant l'opportunité d'améliorer les performances GPU en profitant du traitement concomitant de certaines tâches. Avec les API classiques, toutes les étapes du rendu sont traitées en série par le GPU. Par exemple, le calcul de la physique, la préparation des ombres dynamiques, le remplissage du G-Buffer, l'éclairage et le post processing sont traités l'un après l'autre, aussi vite que possible par les GPU, mais en série.
Chacune de ces tâches n'exploite cependant pas la totalité des capacités d'un GPU. Par exemple, la préparation des ombres et le remplissage du G-Buffer vont plutôt saturer le sous-système mémoire alors que la physique, l'éclairage et le post processing ont plutôt tendance à saturer les unités de calcul. Il semble ainsi logique que traiter en même temps certaines de ces tâches représente une optimisation intéressante pour mieux exploiter les GPU.

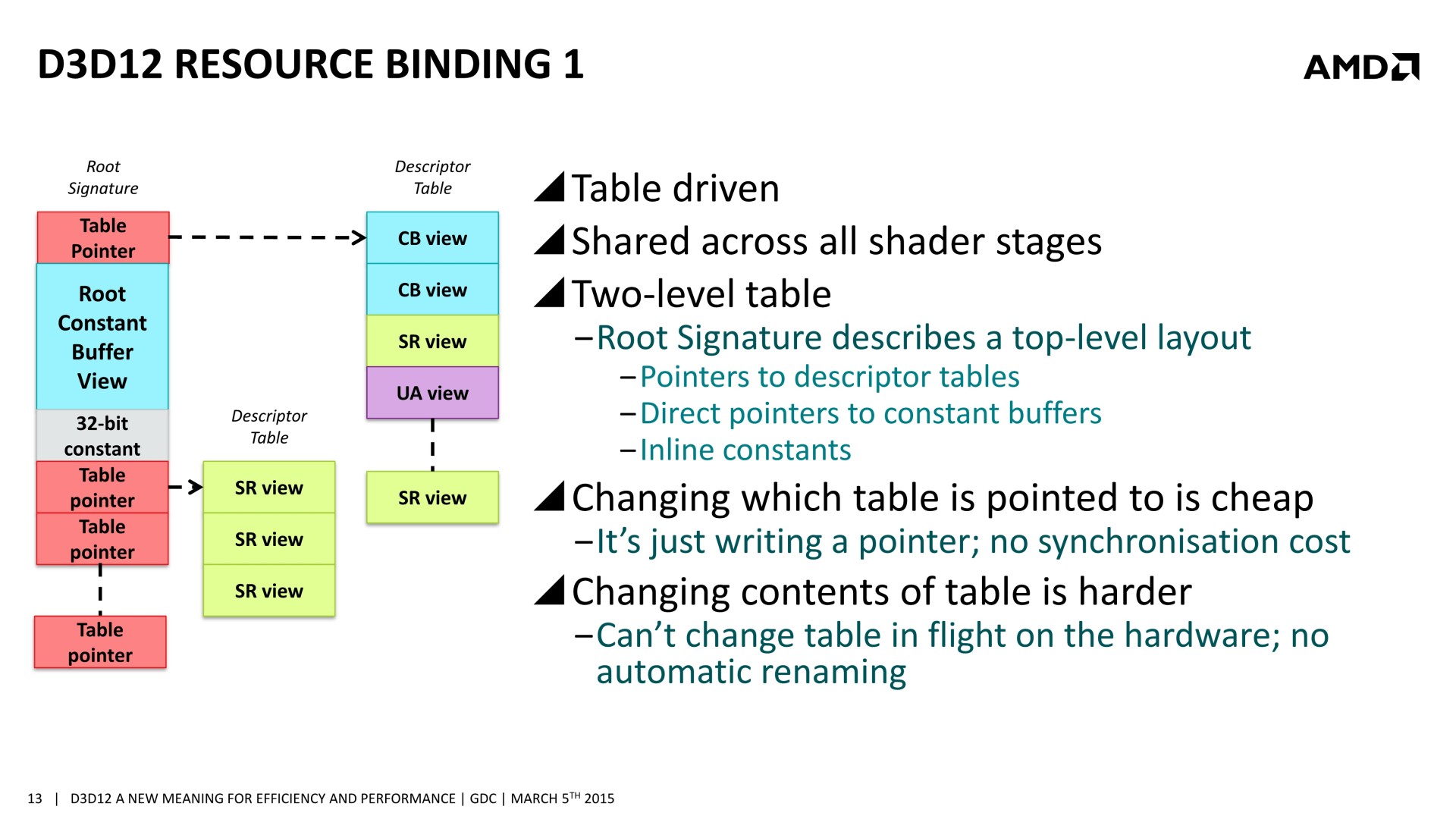
Et ça tombe bien, Direct3D 12, l'autorise. L'API de Microsoft semble reprendre exactement la base de Mantle sur ce point et prévoit 3 types de files d'attentes, également appelées "moteurs", dont les tâches peuvent être traitées en concomitance : Graphics, Compute et Copy. Au niveau des fonctionnalités prises en charge, Graphics est un superset de Compute qui est un superset de Copy. Cela veut dire que par défaut seul le moteur Graphics peut être exploité, puisqu'il est polyvalent. Il revient aux développeurs de spécifier l'utilisation des autres moteurs pour potentiellement optimiser les performances.
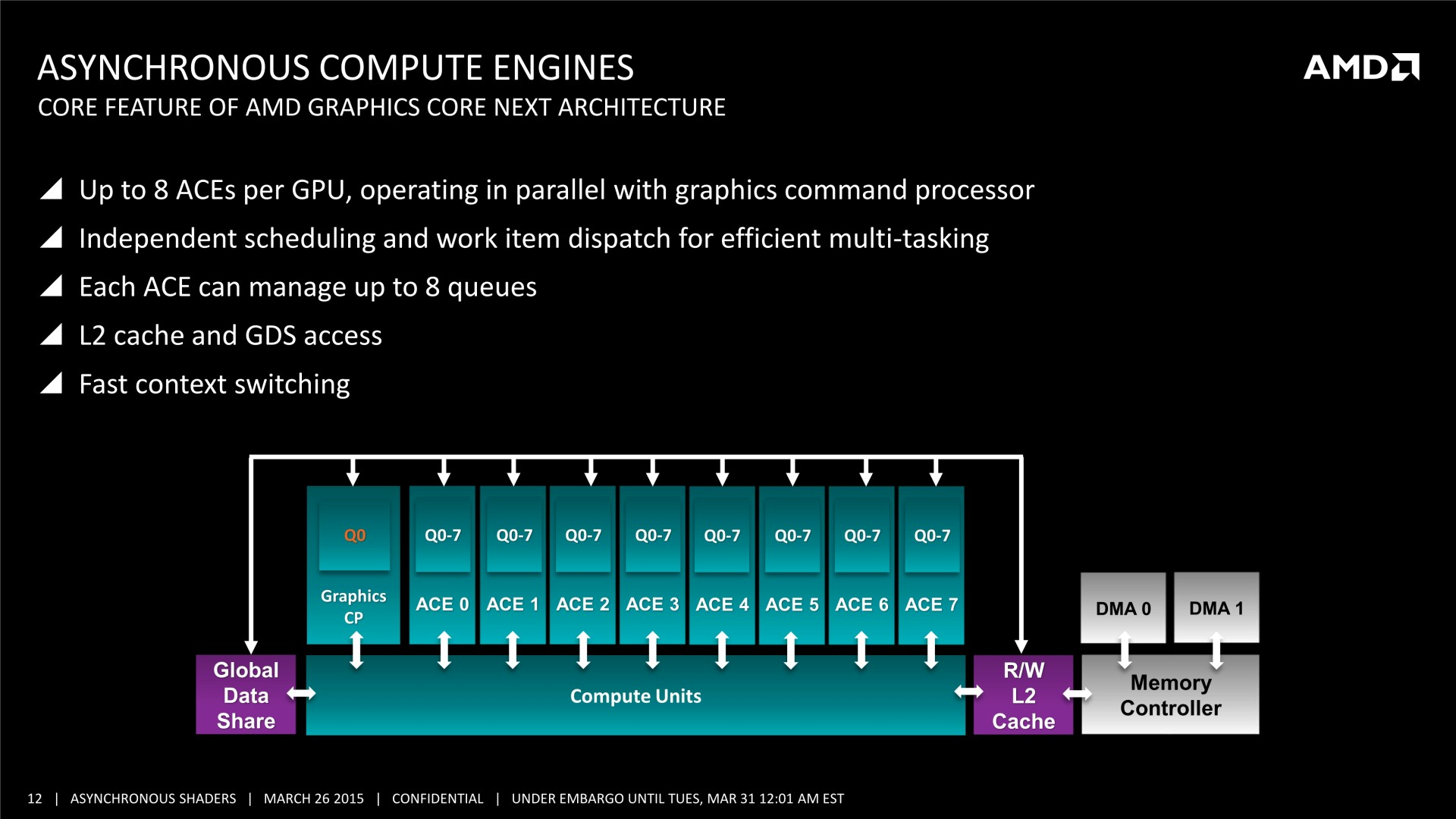
Il faut noter que ce type d'optimisation permet d'exploiter les ACE (Asynchronous Compute Engines) des GPU Radeon de la génération GCN. Pour rappel, AMD a implémenté ces processeurs de commandes secondaires justement pour pouvoir exécuter efficacement des tâches de type Compute en même temps que des tâches de type Graphics. D'autres GPU ne disposent pas de files d'attentes spécifiques au niveau matériel pour tous ces types de tâches et doivent alors les traiter de manière classique, en série. Ainsi, il n'est pas certain que les GPU Nvidia puissent profiter autant que ceux d'AMD de ce type d'optimisation.

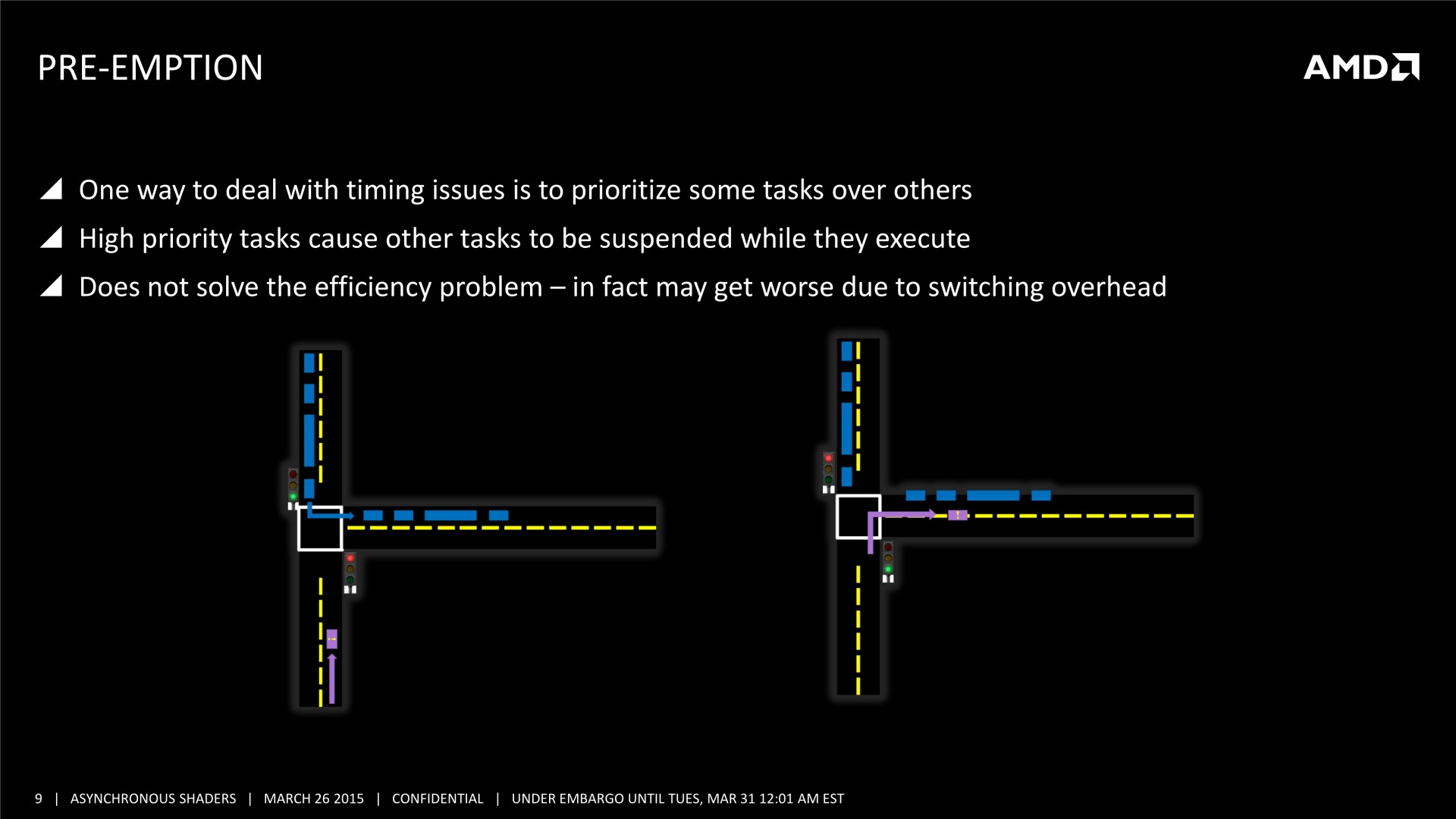
Une bonne compréhension des architectures GPU et un profilage avancé des demandes de chaque tâche sont nécessaires. Il est également crucial de mettre en place correctement les barrières de synchronisation nécessaires, sans quoi des tâches dépendantes l'une de l'autre pourraient être exécutées en parallèle et causer des problèmes. AMD a insisté lourdement sur ce point, précisant que l'absence de barrières de synchronisation adéquates pourra passer inaperçue dans l'immédiat, sans bug visible, mais être source de gros problèmes avec de futurs GPU dont l'augmentation des performances profitera plus à certaines tâches qu'à d'autres. Comme le sait très bien AMD, les développeurs seront peu enclins à proposer un patch 2 ou 3 ans après la sortie d'un jeu, et appliquer un correctif au niveau des pilotes sera alors un véritable casse-tête, voire impossible dans certains cas.
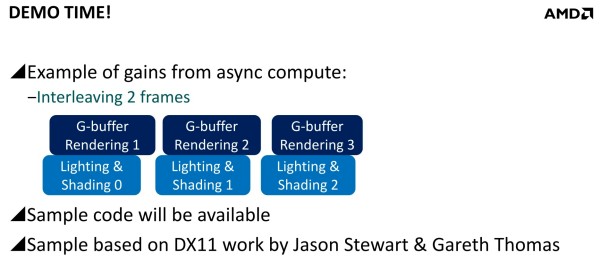
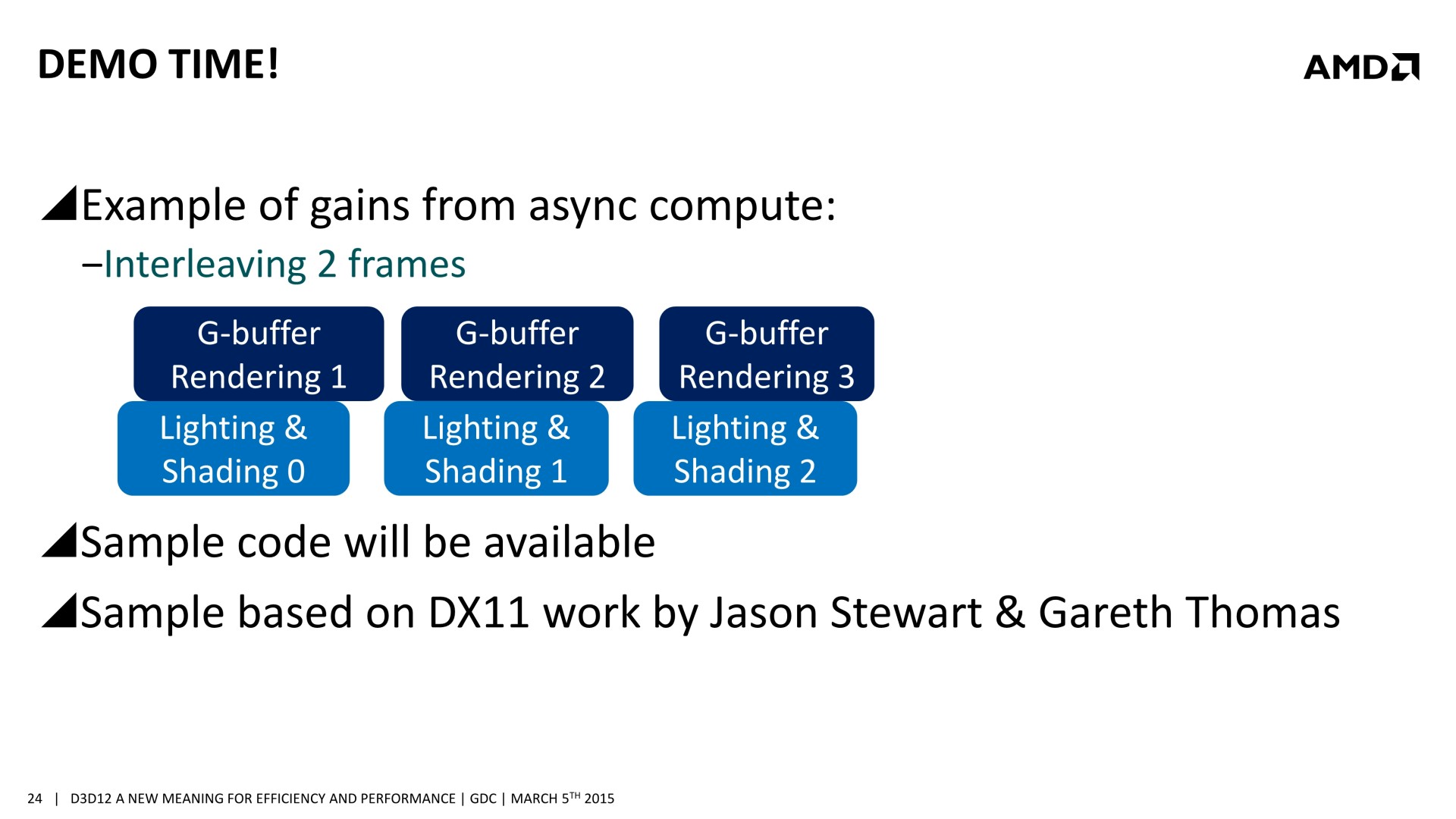
Mais avec un code robuste et un bon profilage, les gains peuvent être conséquents. Il est question de 20 à 25% dans des situations réalistes et avec des GPU capables d'en profiter. Deux exemples ont été mentionnés. Le premier, accompagné d'une démonstration, découple le remplissage du G-Buffer du calcul de l'éclairage qui est réalisé à travers un compute shader. Au lieu de traiter ces 2 opérations l'une après l'autre, elles sont effectuées en parallèle et de manière asynchrone : pendant que l'éclairage est calculé pour l'image 1, les opérations sur le G-Buffer sont traitées pour l'image 2 et ainsi de suite.
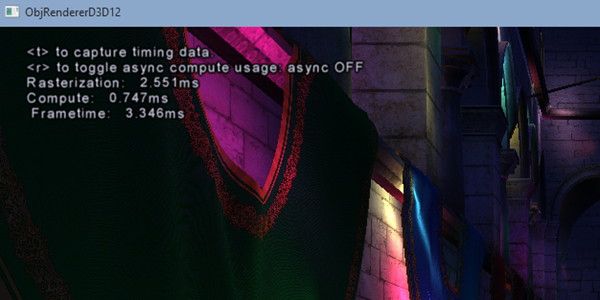
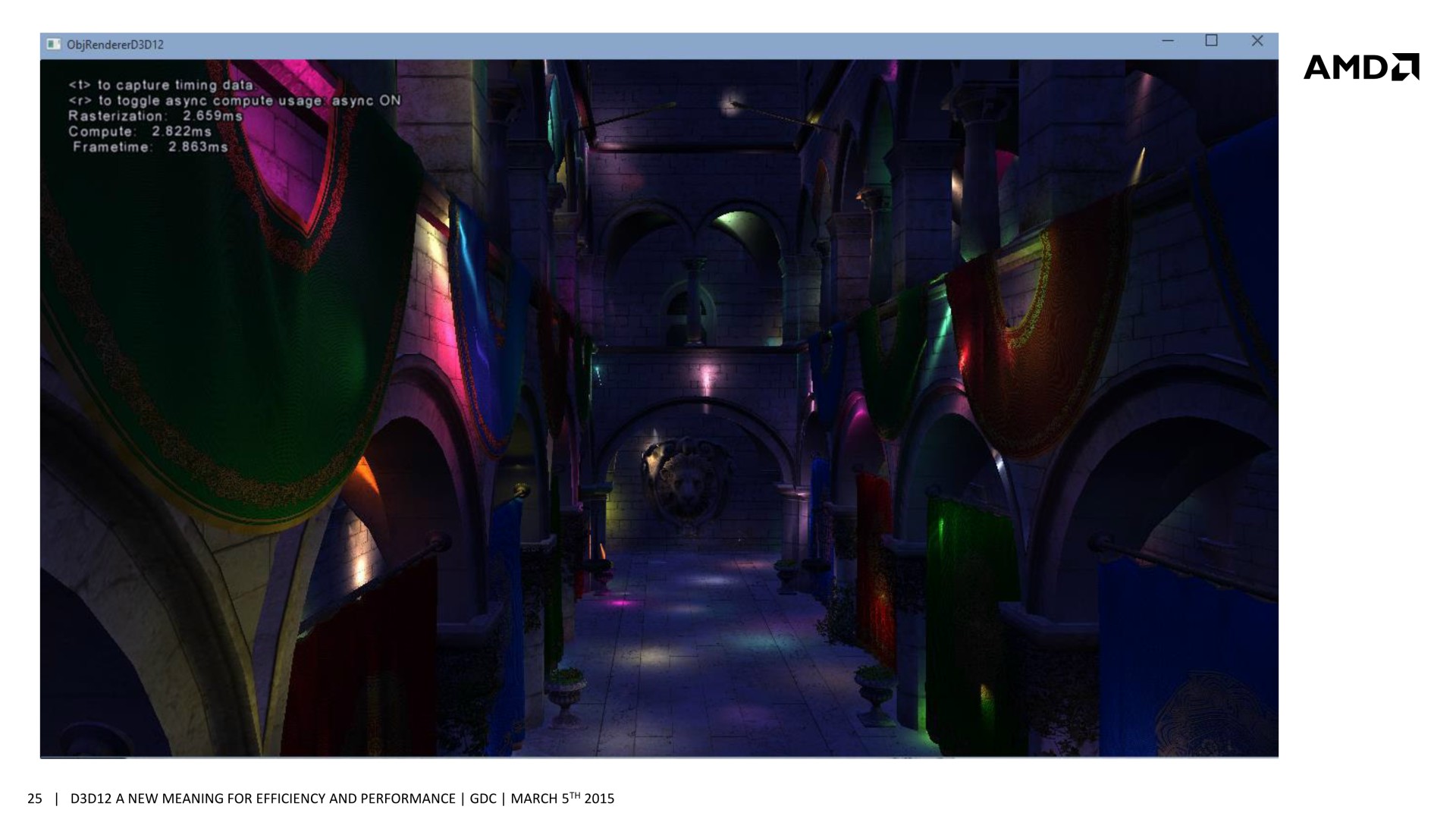
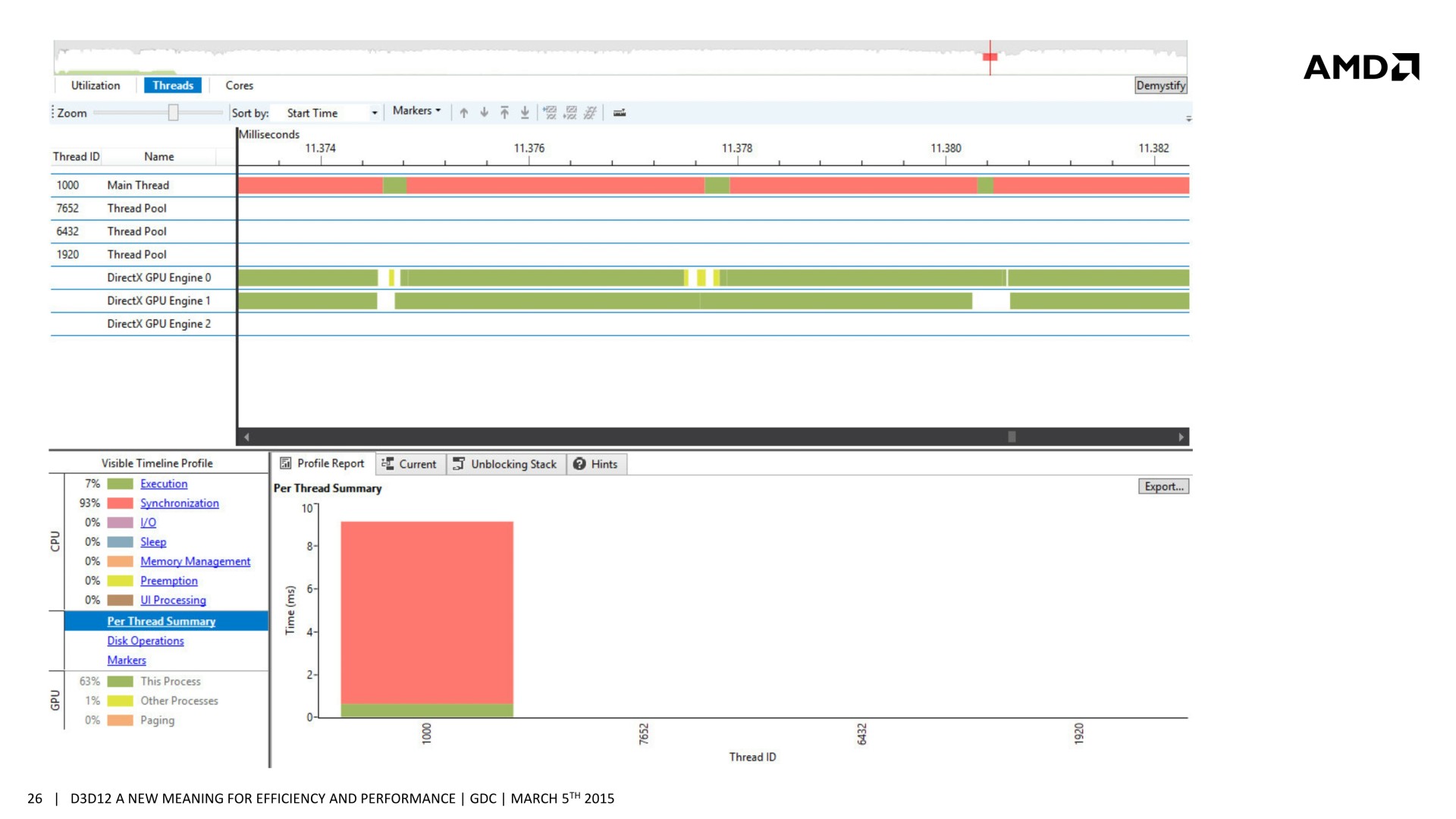
[ Concomitance OFF ] [ Concomitance ON ]
Sans traitement concomitant des tâches Graphics et Compute, le temps de rendu total prend 3.346ms (299 fps), ce qui est la somme des 2.551ms de la partie Graphics (remplissage du G-Buffer) et des 0.747ms de la partie Compute (calcul de l'éclairage). En activant le traitement concomitant dans cette démonstration, le remplissage du G-Buffer prend 2.659ms, et le calcul de l'éclairage 2.822ms. Ces deux tâches prennent plus de temps à être traitées, mais elles le sont en même temps et le rendu total ne prend plus que 2.863ms (349 fps), ce qui représente un gain de 17%. La latence peut par contre être légèrement plus élevée.
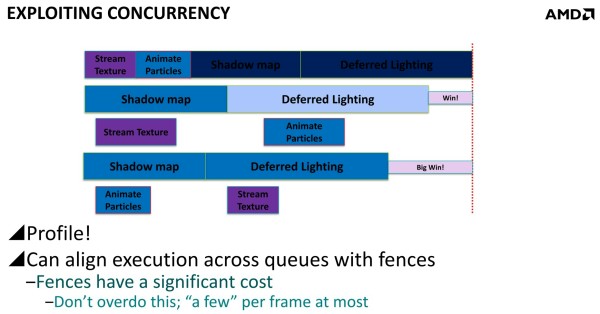
Dans un autre exemple, AMD explique que streamer les textures et animer les particules via les moteurs Copy et Compute permet un petit gain puisque ces opérations sont alors traitées en concomitance avec les ombres et l'éclairage. Mais il est possible d'aller plus loin en constatant qu'il est plus efficace d'animer les particules en même temps que la préparation des ombres et de streamer les textures en même temps que le calcul de l'éclairage que de faire l'inverse. En évitant d'exécuter en même temps des tâches qui ont des demandes similaires en termes de ressources GPU, les gains sont plus importants. D3D12 offre des mécanismes aux développeurs pour pouvoir gérer cela.
Les GPU modernes doivent en général faire face à des limites de consommation directes ou indirectes (via la température) et mieux exploiter la totalité de leurs capacités revient bien entendu à les pousser plus souvent ou plus loin dans ces limites. La fréquence GPU des cartes graphiques est alors réduite quelque peu, ce qui impacte les performances, mais dans des proportions bien moins élevées que les gains liés à ce type d'optimisations. Elles restent donc totalement légitimes. A voir par contre si de tels moteurs graphiques seront qualifiés de "power virus" par AMD et Nvidia, comme c'est le cas de Furmark et d'OCCT qui font également en sorte de saturer toutes les unités des GPU
Le set de slides de la session d'AMD à la GDC : (nous avons profité de la mise à jour pour remplacer nos clichés par des screenshots plus propres)























Mise à jour du 31/03 :
Quelques semaines après la GDC, AMD a décidé de mettre en avant ces possibilités d'optimisations auprès de la presse technique. Une présentation simplifiée nous a ainsi été distribuée il y a quelques jours. A noter que, bizarrement, elle était par contre accompagnée d'un embargo qui prenait fin ce matin alors même que la présentation plus complète, dont nous vous avions parlé ci-dessus, est publique depuis la GDC. Peu de médias s'y étaient cependant intéressés et le département de marketing technique d'AMD a probablement voulu mettre en place une communication synchronisée sur le sujet.







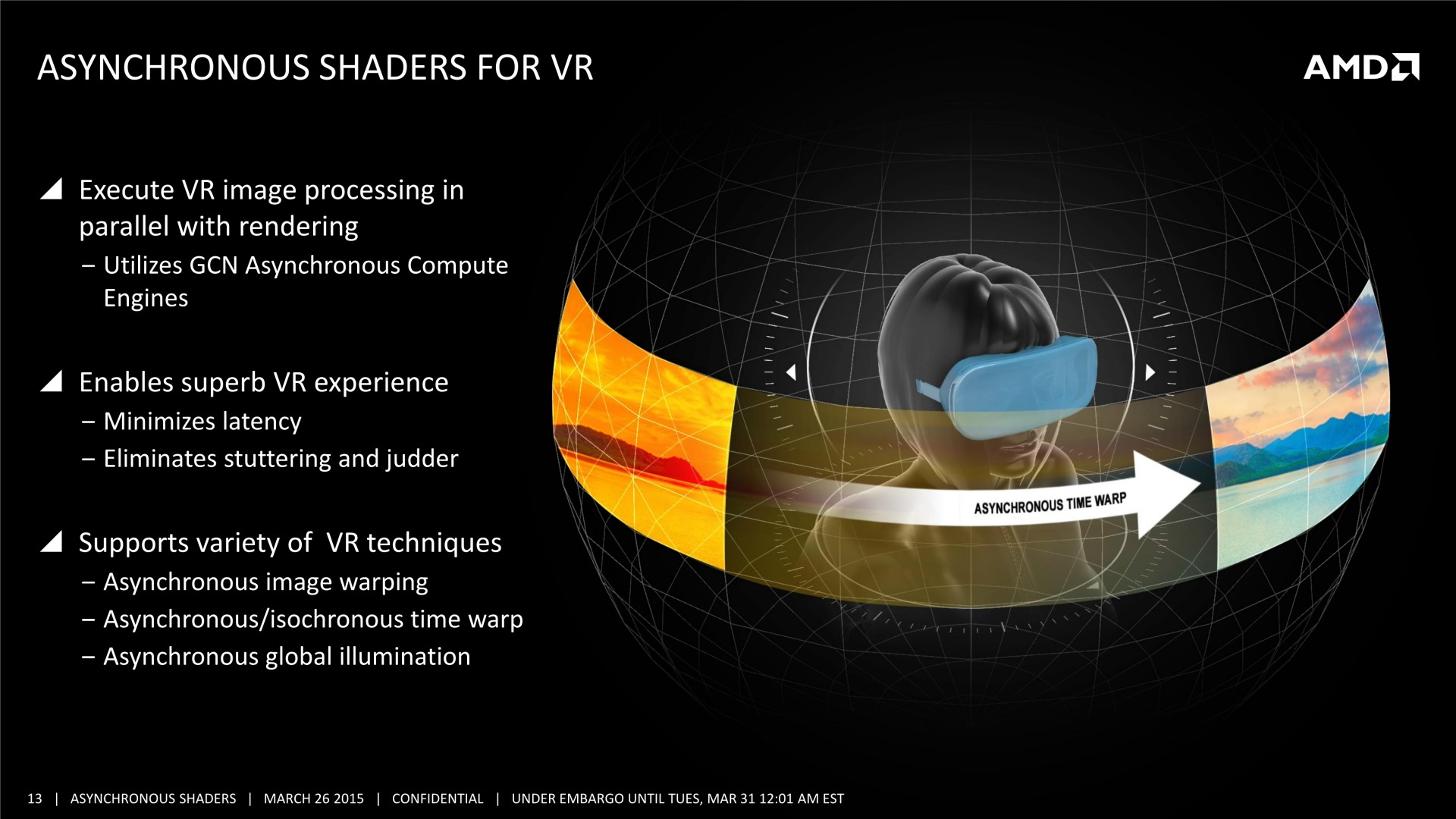





Il n'y pas pas d'information supplémentaire dans cette présentation, mais elle est plus simple à comprendre et mieux finie que celle adressée aux développeurs, nous l'avons donc ajoutée à cette longue actualité. A noter que le marketing technique d'AMD parle d'Asynchronous Shaders pour faire référence à l'exécution concomitante de différentes tâches (même si les opérations de type Copy ne sont pas des shaders). Vous pourrez également observer le résultat obtenu sous une autre démo, que nous avions pu observer également pendant la GDC durant la présentation de LiquidVR. L'utilisation du traitement concomitant du rendu (Graphics) et du post processing (Compute) y permet un gain de performances de 46%.
Si cette stratégie de communication d'AMD ne nous en a pas appris plus, elle a par contre eu le mérite de pousser Nvidia à enfin communiquer sur le même sujet. L'occasion de faire le point sur ce dont sont capables tous les GPU récents, notre première supposition n'étant pas tout à fait correcte concernant les derniers GPU Maxwell.
Du côté d'AMD :
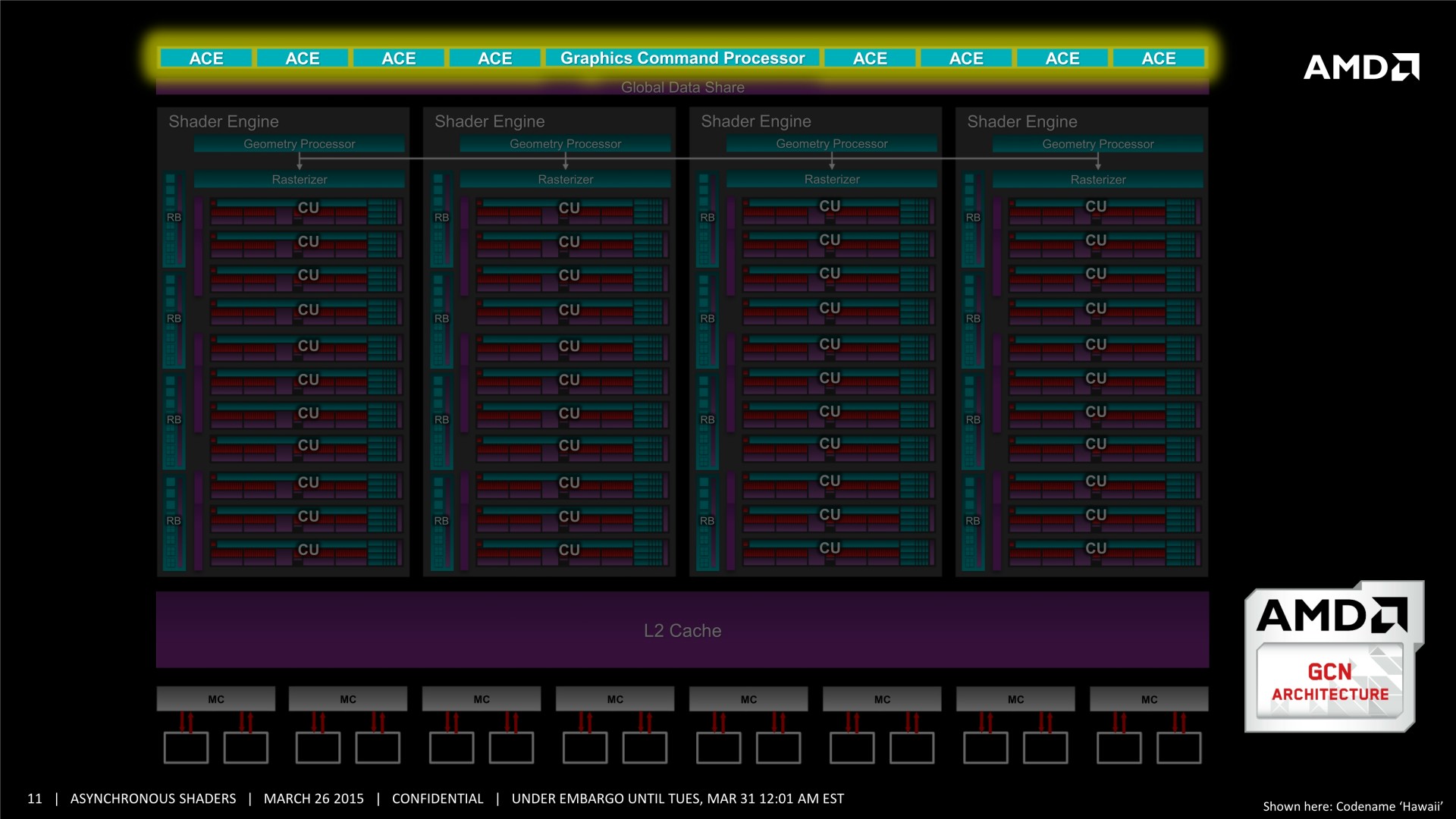
Tous les GPU de type GCN supportent le traitement concomitant des tâches Graphics/Compute/Copy. En plus d'un processeur de commande principal polyvalent, ils disposent au moins de 2 ACE (Asynchronous Compute Engine), dédiés aux tâches de type Compute, et de 2 DMA Engines dédiés aux tâches de type Copy.
Il y a par contre des limitations pour les GPU GCN 1.0 (Tahiti, Pitcairn, Cape Verde, Oland). Leurs DMA engines ne supportent pas toutes les fonctions de synchronisation avec le CPU, ce qui impose probablement des limites au niveau du traitement concomitant des tâches de type Copy. Ensuite, les GPU plus récents, GCN 1.1, supportent plus de files d'attente par ACE (8 au lieu de 1), qui peuvent par ailleurs être présents en plus grand nombre. Ils sont ainsi adaptés au traitement concomitant de nombreuses petites tâches de type Compute (par exemple pour la physique ?), contrairement à leurs prédécesseurs.
AMD a implémenté dans ses pilotes Direct3D 12 un support complet de traitement concomitant de tous les types de tâches, exactement comme c'est le cas sous Mantle. Par contre, nous ne savons pas si les pilotes AMD sont capables de profiter de certaines de ces possibilités pour apporter des optimisations sous certains jeux Direct3D 11.
Du côté de Nvidia :
Les GPU Fermi et Kepler se contentent d'un seul processeur de commandes qui ne peut pas prendre en charge simultanément des commandes de type Graphics et de type Compute. Soit il est dans un mode, soit dans l'autre, un changement d'état relativement lourd à opérer.
Par ailleurs, à l'exception des GK110/GK210, ces anciens GPU ne disposent que d'une seule file d'attente au niveau de leur processeur de commande qui doit traiter les tâches dans l'ordre dans lequel elles sont soumises. Cela limite fortement la possibilité d'en traiter plusieurs simultanément à l'intérieur du mode Compute lorsqu'il y a des dépendances entre elles.
Avec le GK110, Nvidia a introduit un processeur de commandes plus évolué, qui supporte une technologie baptisée Hyper-Q. Elle représente la capacité de prendre en charge jusqu'à 32 files d'attente, mais uniquement en mode Compute. Ce GPU, et les GM107/GM108 qui reprennent cette spécificité, sont ainsi adaptés au traitement concomitant de nombreuses petites tâches de type Compute (par exemple pour la physique ?). Le GK110 a également introduit un second DMA Engine, mais il est réservé aux déclinaisons Tesla et Quadro.
Enfin, avec les GPU Maxwell 2 (GM200/GM204/GM206), Nvidia a fait sauter toutes ces limitations, contrairement à ce que nous pensions. Tout d'abord, le second DMA Engine est bien actif sur les déclinaisons GeForce. Mais surtout, quand Hyper-Q est actif, une des 32 files d'attente peut être de type Graphics.
Au niveau de l'implémentation logicielle, un traitement concomitant complet de tous les types de tâches est supporté sous Direct3D 12 pour les GPU Maxwell 2. Il n'est par contre pas possible d'effectuer une exécution concomitante entre Direct3D 12 et CUDA, qui repose sur un pilote différent.
Nvidia a également implémenté dans ses pilotés un support limité de l'exécution concomitante sous Direct3D 11, pour les tâches compute uniquement. L'API ne permet pas d'y accéder explicitement, mais quelques astuces permettent aux pilotes d'activer un tel mode pour optimiser les performances (dans le cas de GPU PhysX ?). Nvidia nous a précisé que la question d'y ajouter le support d'un traitement concomitant complet de tous les types de tâches, comme sous Direct3D 12, restait en suspens. Ce n'est pas impossible si cela avait une utilité, mais aucun jeu Direct3D 11 actuel n'est prévu pour en profiter. Sans support explicité dans l'API il est très difficile pour les développeurs de faire en sorte que cela puisse fonctionner.
En résumé :
HD 7000 & Rx 240/250/270/280 : processeur de commandes x1 queue + 2 ACE x1 queue + 2 DMA engines
->Graphics/Compute/Copy avec limitations
HD 7790 & R7 260 : processeur de commandes x1 queue + 2 ACE x8 queues + 2 DMA engines
->Graphics/Compute/Copy
R9 285/290 : processeur de commandes x1 queue + 8 ACE x8 queues + 2 DMA engines
->Graphics/Compute/Copy
GTX 400/500/600/700 : processeur de commandes x1 queue + 1 DMA engine
->Pas de support
GTX 750/780/Titan : processeur de commandes x32 queues (limité) + 1 DMA engine
->Compute/Compute
GTX 900/Titan X : processeur de commandes x32 queues + 2 DMA engines
->Graphics/Compute/Copy
Au final, c'est surtout au niveau des anciens GPU que se différencient AMD et Nvidia, le premier ayant un support en place au niveau matériel depuis plus longtemps. Au niveau des cartes graphiques plus récentes, les GeForce GTX 900 pourront profiter pleinement des optimisations liées au traitement concomitant des tâches, tout comme le feront les Radeon R9 290 par exemple.
Par contre, il reste à voir ce qu'en feront les développeurs. Les gains ne seront pas automatiques et il faudra que les différentes étapes du rendu 3D s'y prêtent. Ce n'était de toute évidence pas le cas pour Battlefield 4 et le Frostbite Engine par exemple, dont la version Mantle ne profite pas réellement de ce type d'optimisation.
DirectX 12 : Benchmarks et exclusivité Windows 10
AnandTech a publié un article consacré à DirectX 12 se concentrant principalement sur des benchmarks obtenus sous Windows 10 Technical Preview 2 sous une version Direct3D 12 de Star Swarm Stress Test fournie par Oxide et Microsoft. Ce nom ne devrait pas vous être inconnu puisque cette démo dispose d'une version Mantle utilisée par AMD pour démontrer les bienfaits de son API à son lancement, mais elle a aussi déjà été utilisée en août dernier en version DX12 par Intel et Microsoft pour montrer les avantages du futur Direct3D.

Avant de passer aux résultats, nos confrères ont eu la confirmation par Microsoft que DirectX 12 ne sera disponible que sous Windows 10. Sachant que la mise à jour sera gratuite si effectuée durant la première année du lancement, cette annonce n'est pas problématique. Pour supporter DirectX 12, Windows 10 intègre la version 2 du WDDM. Côté GPU AMD et Nvidia disposent bien sûr de pilotes beta WDDM 2.0 et DX12, ce sont les versions 394.56 et 15.200 qui ont été fournies à nos confrères. A l'heure actuelle les pilotes AMD supportent les GPU GCN 1.0, 1.1 et 1.2, mais pour le moment Star Swarm Stress affiche des bugs de texture sur GCN 1.0. Côté Nvidia le support des Kepler et Maxwell est fonctionnel, mais les Fermi ne sont pas encore gérés.
Côté benchmark c'est donc sans grande surprise que les résultats obtenus sont très bons dans ce test très lourd en termes de draw calls. Ainsi une GeForce GTX 980 passe de 26,7 fps en D3D11 à 66,8 fps en D3D12, alors qu'une Radeon R9 290X est à 8,3 fps en D3D11, 42,9 fps en D3D12 et 45,6 fps sous Mantle. On note ici un avantage à Mantle sur ce test effectué avec 4 curs et confirmé avec 6 curs, mais avec 2 curs seulement c'est D3D12 qui reprend l'avantage avec 42,9 fps au lieu de 37,6 fps. Ces écarts sont en partie liés à un temps de traitement des lots de commande plus important sous Mantle du fait d'une optimisation du moteur effectuant une seconde passe côté CPU pour les optimiser, ce qui permet d'alléger la charge GPU au dépend de la charge CPU. Une fois celle-ci désactivée le temps de traitement des lots de commande est équivalent entre les deux API, par contre D3D12 repasse devant puisque sur 4 coeurs Mantle passe à 39,3 fps.
Pour rappel, pour contrer l'offensive Mantle, Nvidia a optimisé tant que possible les performances des commandes D3D11 via des optimisations génériques mais aussi spécifiques à certaines applications dont Star Warm. C'est ce qui explique que la version D3D11 soit 3,2 fois plus rapide sur GTX 980 que sur R9 290X, alors qu'AMD a orienté ses ressources sur Mantle qui reste 71% plus rapide. En Direct3D 12, l'avantage du dernier GPU Nvidia est probablement lié à des performances supérieures dans le traitement de la géométrie et/ou des commandes dans ce cas extrême.

DirectX 12 est donc toujours sur la bonne voie pour tenir les promesses d'une API bas niveau en termes d'allègement et de meilleure répartition entre les curs CPU de la charge liée aux commandes de rendu. Des bons résultats qui ont déjà été démontrés par AMD avec l'API Mantle qui a heureusement enfin fait bouger les lignes. Microsoft a encore beaucoup de choses à dévoiler sur DirectX 12, ce qui devrait se faire à l'occasion de la GDC 2015 en mars on pense notamment au nouveau niveau de fonctionnalité 11_3 ou 12_0. Reste qu'au-delà de l'API et des démos technologiques, il faudra bien sûr voir ce que les développeurs de jeux en feront !
GDC: Mantle, Direct3D 12, l'uf et la poule
S'il y a bien un mot qui était tabou lors de toutes les sessions de la GDC consacrées à Direct3D 12, c'était Mantle. Microsoft, Nvidia et même AMD ont tout fait pour éviter de devoir mentionner cette autre API de bas niveau. Direct3D 12 est-il le résultat de la sortie de Mantle ? Voici ce qui nous semble être la meilleure actuelle théorie sur le sujet

Durant la GDC, seul Oxide a osé un timide acte de rébellion en déclarant que "porter leur moteur depuis d'autres API modernes était plus simple que de porter de Direct3D 11 vers Direct3D 12". A chacune de ces sessions pourtant, la première question qui était posée était systématiquement la suivante : "comment se compare Direct3D 12 à Mantle ?". Eclats de rire assurés dans la salle mais aucune réponse en retour.

Nvidia, de son côté, explique travailler avec Microsoft sur DirectX 12 depuis plus de 4 ans et en collaboration rapprochée depuis un an. C'est sans aucun doute autant la réalité qu'un baratin énorme pour éviter d'admettre avoir été poussé dans cette direction par l'API Mantle d'AMD.
Microsoft travaille constamment avec ses partenaires au sujet de possibles évolutions de ses API. La machine ne s'arrête pas quand DirectX 11 sort, les discussions et autres phases de recherche continuent. Quand Nvidia indique travailler depuis plus de 4 ans avec Microsoft sur DirectX 12, cela veut simplement dire que Nvidia a poursuivi sa collaboration avec Microsoft au-delà de DirectX 11, comme tous les autres fabricants de GPU. Cela ne veut pas dire que Nvidia travaille depuis 4 ans sur le Direct3D 12 qui est présenté aujourd'hui.
Nous ne pensons pas que le fait que la démonstration de Microsoft d'un prototype de portage vers Direct3D 12 de Forza Motorsport ait été réalisée sur un GPU Nvidia, la GeForce GTX Titan Black, soit un élément significatif. Il est logique que Microsoft opte pour un GPU Nvidia pour mettre en avant l'aspect universel de sa solution. Une démonstration sur un GPU AMD aurait entraîné plus de liens vers Mantle et l'architecture d'AMD puisque le code de base de Forza Motorsport provient de la Xbox One équipée en GPU AMD.
Après de très nombreuses discussions avec tous les acteurs impliqués, à la GDC mais également auparavant, nous sommes convaincus que Mantle a été le déclencheur et l'accélérateur de la direction retenue pour Direct3D 12, quoi qu'en dise Nvidia. Cela ne veut pas dire que Direct3D 12 est un clone de Mantle, mais qu'il semble bel et bien avoir été bâti sur les mêmes bases ou tout du moins fortement tiré dans la même direction. Des bases qui impliquent de transférer une partie significative de la responsabilité des performances et des optimisations du pilote vers le moteur du jeu. Bien sûr, ce n'est pas un monde en noir et blanc, tout le pouvoir ne passe du pilote au moteur de jeu, les deux restent importants mais l'équilibre est modifié en faveur du second.
C'est selon nous la clé pour comprendre la position de chacun et la chronologie des évènements. Il ne faut pas être naïfs, AMD et Nvidia n'opèrent pas de virage important par pure conviction technologique, tous ces choix se font également avec une bonne dose de politique et de stratégie.
Pourquoi AMD a-t-il sorti Mantle ? Parce que Nvidia dispose de la meilleure équipe de développement des pilotes. Pourquoi Nvidia aurait-il été réticent jusqu'alors à faire évoluer Direct3D vers un niveau d'abstraction plus bas ? Parce que Nvidia dispose de la meilleure équipe de développement des pilotes.
Plus une API graphique est complexe, prend des chemins torturés et accuse un surcoût ou overhead élevé, plus les fabricants de GPU ont d'opportunités de se démarquer de la concurrence via leurs pilotes. Cela ne veut pas spécialement dire qu'AMD et Nvidia font ou ont fait volontairement en sorte de complexifier les API, mais que les simplifier et transférer une plus grosse part de la responsabilité de l'optimisation vers les développeurs pose des questions stratégiques importantes qui peuvent les inciter à trainer des pieds face à certaines évolutions.

Les avantages d'une API de plus haut niveau, selon Nvidia.
Le travail important nécessaire pour obtenir des performances de premier plan, que ce soit globalement au niveau des pilotes ou spécifiquement au cas par cas pour chaque application, a permis à AMD et Nvidia de bénéficier de la sécurité d'un marché difficilement accessible à d'autres acteurs. Des sociétés telles que S3, Matrox, XGI etc. s'y sont cassé les dents, en partie pour cette raison. C'est également ce qui a permis à AMD et Nvidia de tenir Intel à l'écart.
Au cours de ses années les plus difficiles, AMD a dû se séparer de nombreux ingénieurs qui travaillaient sur ses pilotes alors même que Nvidia renforçait ses rangs. Même si AMD a récemment revu à la hausse ses investissements auprès du support des développeurs, il est évident que Nvidia dispose d'une force de frappe nettement plus importante sur le plan du développement des pilotes. AMD a probablement fini par prendre conscience du danger que cela pouvait représenter et revu sa stratégie en conséquence. Le réflexe qui pouvait être de trainer des pieds par rapport à un transfert de pouvoir des pilotes vers l'application n'avait plus lieu d'être. Au contraire, il a fini par devenir évident que pousser le marché dans cette direction serait utile pour la compétitivité de la société.
Pas facile cependant de convaincre tout le monde de bouger dans ce sens... Il nous semble évident que stratégiquement Nvidia n'avait au premier abord aucune raison d'abonder dans le sens d'AMD, et préférait opter pour d'autres approches de réduction du surcoût CPU, peut-être moins ambitieuses, qui lui auraient évité d'abandonner autant de contrôle sur les optimisations. Du côté de Microsoft il y avait probablement du pour et du contre, pas mal d'hésitation et d'avis contradictoires.
En développant et en concrétisant Mantle, avec le support de développeurs très enthousiastes, nous pouvons supposer qu'AMD a décidé de donner un coup de pied dans cette fourmilière. Le risque était limité. Dans le pire des cas, AMD pourrait bénéficier d'un mode spécifique dans quelques jeux, et dans le meilleur des cas, en profiter pour forcer la main des acteurs réticents de manière à pousser l'industrie dans une direction plus intéressante pour la société d'un point de vue compétitif.
De premiers résultats encourageants, l'engouement instantané de plusieurs développeurs pour les principes de Mantle (pas spécialement pour l'utilisation d'une API propriétaire !), la position délicate de la Xbox One, la menace de Steam OS, , tout cela a mis en place une atmosphère qui a permis à tout le monde d'accepter d'aller vers un changement plus radical que certains ne le voulaient au départ pour Direct3D 12. Au final, avec Mantle, AMD a pu influencer significativement Direct3D 12, en plus d'apporter un bonus dans quelques jeux pour les utilisateurs de Radeon, ce qui est toujours bienvenu sur le plan commercial.
Sur la base de la même réflexion, nous pouvons supposer qu'OpenGL ES va évoluer rapidement vers une version à overhead réduit, alors qu'il sera beaucoup plus lent et difficile de faire évoluer OpenGL dont l'importance dans le monde professionnel en fait un élément stratégique crucial. Un responsable du développement d'un des moteurs de jeux majeurs nous a d'ailleurs confirmé qu'un tel OpenGL ES était déjà sur la table.
Nous pouvons par contre supposer que Nvidia sera extrêmement prudent par rapport à une évolution d'OpenGL qui pourrait impacter son très rentable marché professionnel. Même si la tendance va de plus en plus vers une exploitation de toute la puissance des GPU, de nombreuses applications professionnelles liées à la 3D restent fortement limitées par le CPU et les performances du pilote. Une caractéristique qui, comme vous pourrez l'imaginer, fait bien les affaires de Nvidia.