
Les contenus liés aux tags Nvidia et GTC
Afficher sous forme de : Titre | FluxGTC: Plus de détails sur le GK110
GTC: VGX: la virtualisation sur GPU pour les pro
GTC: Tesla passe à Kepler avec les K10 et K20
GTC: Nvidia lève le voile sur le GK110
GTC: Nsight évolue, s'ouvre à Linux et Mac OS
GTC: Le futur de Tegra: CUDA, Logan, Parker



Après la roadmap GeForce, Nvidia nous en a dit un peu plus sur la roadmap des SoC Tegra. Si certains ont été quelque peu déçus de ne pas retrouver un GPU plus moderne dans Tegra 4, cela est en passe de changer. Jen-Hsun Huang a ainsi confirmé que la prochaine architecture Tegra, Logan, intégrerait enfin une évolution GPU majeure qui fera le pont avec les technologies qui nous retrouvons dans la gamme GeForce traditionnelles.
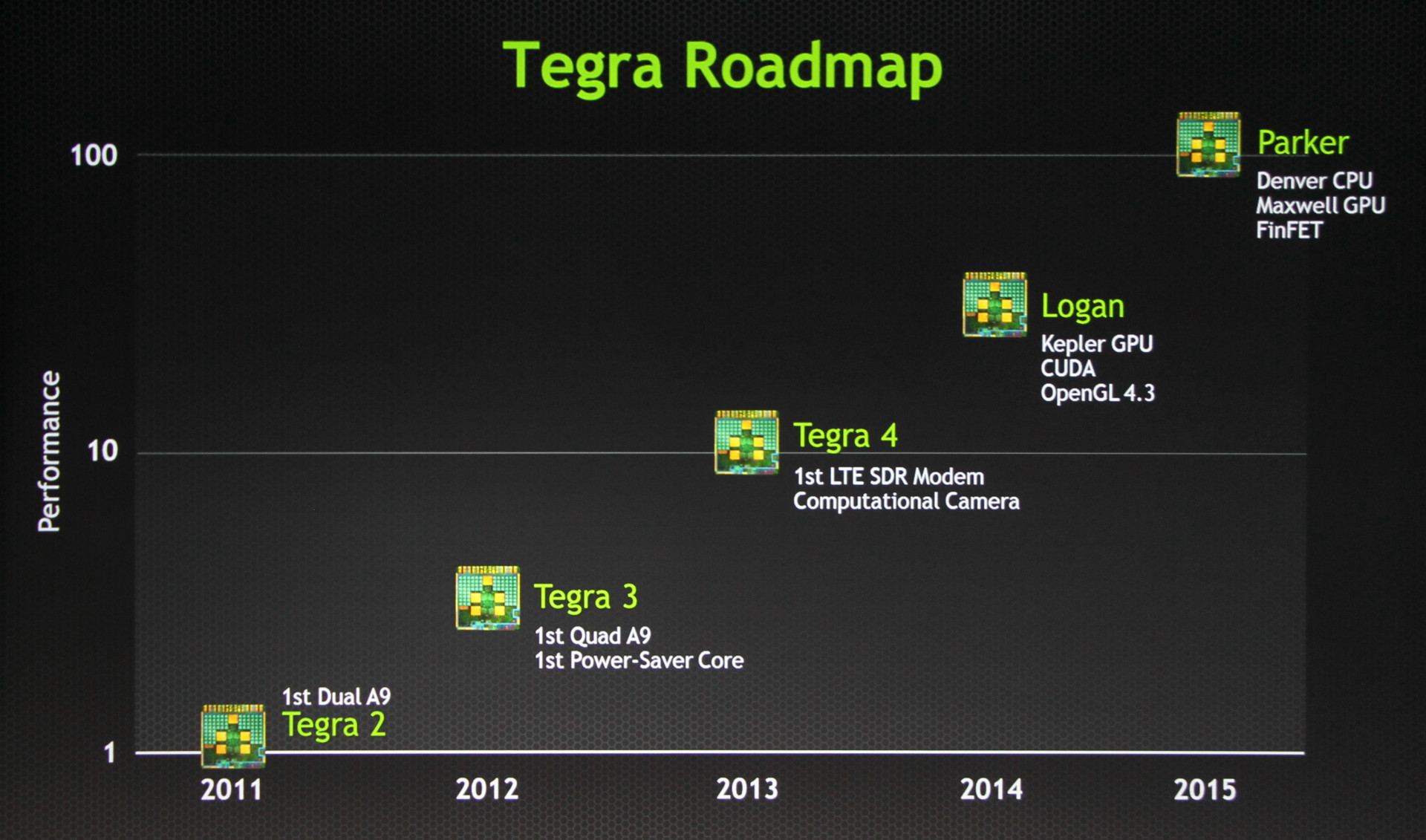
Ainsi, le GPU de Logan sera dérivé de l'architecture Kepler avec un support complet d'OpenGL 4.3 et surtout de CUDA 5 pour permettre d'exploiter la puissance de calcul du GPU d'une manière plus flexible, par exemple pour le traitement d'images. En plus de sa plateforme propriétaire CUDA, nul doute que Nvidia supportera également la plateforme ouverte OpenCL, qui, dernièrement, a enfin reçu un support clair de la part de Google en ce qui concerne Android.
Pour le reste, il est probable que Logan reprenne les mêmes cores Cortex-A15 que Tegra 4 et soit fabriqué en 20 nanomètres. Jen-Hsun Huang a précisé que si Tegra 4 est arrivé en retard, Tegra 4i est de son côté arrivé légèrement en avance alors que Logan devrait être à l'heure avec des premiers prototypes à la fin de l'année et une production qui débutera début 2014. Vous pouvez donc vous attendre à une annonce de Tegra 5 au CES 2014.
Tout ceci n'est cependant qu'une confirmation de ce que nous supposions déjà. La nouveauté est l'arrivée de quelques premières informations sur le successeur de Logan : Parker. Ce dernier arrivera en 2015 et intègrera les premiers cores ARM conçus en interne par Nvidia et basés sur l'architecture ARMv8 qui supporte le 64-bit, nom de code Denver. Au niveau du GPU, Parker passera à la génération Maxwell, avec seulement une année de décalage par rapport aux gros GPU dekstop, les architectures GPU étant dorénavant unifiées entre les différentes divisions de Nvidia.
Parker devrait également être la première puce conçue par Nvidia en vue de l'utilisation d'un procédé de fabrication de type FinFET ("transistors 3D) et nous pouvons supposer qu'il s'agira alors du 14nm.
GTC: GPU: Maxwell puis Volta et DRAM stacking
Jen-Hsun Huang a profité de la keynote d'ouverture de la GTC pour mettre à jour la roadmap GPU globale de Nvidia. Pour rappel, après la génération Kepler actuelle, c'est la génération Maxwell attendue pour 2014 et fabriquée en 20nm qui représentera la prochaine évolution majeure avec le support d'une mémoire virtuelle unifiée, attendue depuis longtemps dans le monde du GPU computing.

Nvidia dévoile aujourd'hui la prochaine étape, nom de code Volta, en évitant de s'avancer trop précisément sur le timing, il dépend de nombreux facteurs dont certains extérieurs tels que le process 14nm, mais en la situant plus ou moins vers 2016. Quelle sera l'évolution la plus importante introduite sur cette future génération ? La mémoire empilée, ou DRAM stacking, qui consistera à placer plusieurs dies de DRAM au-dessus du die du GPU avec une connexion directe vers ce dernier à travers des vias.

Au prix d'une complexification de la production du GPU et de son packaging, éviter ainsi de passer par le PCB permettra de conserver plus facilement un signal de qualité en montant en fréquence voir en élargissant le bus mémoire. Nvidia vise alors une bande passante mémoire de l'ordre du téraoctet par seconde, soit un quadruplement par rapport à ce dont dispose une carte graphique haut de gamme actuelle telle que la GeForce GTX Titan.
Comme à son habitude, Nvidia communique sur une estimation de l'efficacité énergétique de ses futures architectures en double précision : +/- 12 Gflops/W pour Maxwell et +/- 24 Gflops/W pour Volta contre 6 Gflops/W pour Kepler et 2 Gflops/W pour Fermi. 200W de Volta permettra ainsi une puissance de calcul quadruplée en DP par rapport à 200W de Kepler, ce qui est en accord avec l'évolution de la bande passante mémoire. Ces chiffres ne se transposent bien entendu pas directement en performances graphiques, mais laissent néanmoins penser que l'évolution à ce niveau restera substantielle.
GTC: CUDA s'ouvre officiellement à Python
Après le C, Fortran et le C++, c'est Python qui devient le quatrième langage officiel pour CUDA. Contrairement aux trois premiers langages, ce support ne provient pas directement de Nvidia mais profite de LLVM, une infrastructure de compilateur open source qui a été adoptée pour les compilateurs CUDA il y a un peu plus d'un an. Grossièrement, LLVM expose une représentation interne qui fait office d'intermédiaire entre l'architecture CUDA et les compilateurs, ce qui facilite l'ajout du support de l'accélération via GPU à la plupart des langages.
Si plusieurs variantes plus ou moins complètes de compilateurs Python pour CUDA existent depuis quelques temps, c'est le nouveau compilateur NumbaPro développé par Continuum Analytics qui a atteint le premier un niveau suffisamment avancé pour que Nvidia puisse annoncer Python en tant que quatrième langage officiel pour CUDA
Bien que la suite Anaconda Accelerate qui intègre NumbaPro ne soit pas disponible librement, elle coûte 129$ (mais devrait passer en open source à terme), le fait que Nvidia puisse valider de la sorte un compilateur Python mis au point par un développeur externe témoigne de l'intérêt de la stratégie qui a dicté le passage à LLVM.

Ce support de Python, très répandu dans l'industrie et le monde scientifique, devrait permettre à Nvidia de convaincre quelques développeurs réticents de plus de passer au GPU computing ou tout du moins de jeter un coup d'il aux possibilités qu'il pourrait offrir.
GTC: Nvidia GPU Technology Conference 2013
Depuis quelques années déjà, la GPU Technology Conference (GTC) est un forum mis en place par Nvidia pour promouvoir le GPU computing et l'écosystème CUDA à travers la présentation des dernières évolutions liées à ce domaine, des formations pour les développeurs, ou encore des cas pratiques et autres retours d'expérience d'industries qui ont fait le choix de cette technologie, profitant des avantages du GPU, par exemple en termes de consommation ou de coûts par unité de puissance de calcul.
L'édition 2013 se tient actuellement à San Jose en plein cur de la Silicon Valley, et comme chaque année, nous sommes sur place pour couvrir les nouveautés éventuelles qui seront dévoilées au cours de l'évènement et rester à jour au niveau de ce qui se fait dans le GPU computing.

Si le sujet vous intéresse, la keynote principale, sera diffusée en direct à 17h (heure française) ici-même ou à partir d'un lien qui sera actif sur cette page . Durant celle-ci Jen-Hsun Huang, CEO de Nvidia, fera le point sur l'impact des GPU dans différents domaines et dévoilera les grandes lignes d'éventuelles nouveautés à venir.
GTC: GeForce GRID: jouer depuis le cloud
Avec la famille de GPU Kepler, Nvidia vise un nouveau marché : cloud computing. Nous vous avons déjà parlé du pan professionnel de cette stratégie avec VGX dédié à la virtualisation et nous abordons aujourd'hui l'autre partie : le cloud gaming.

Jouer à travers le cloud revient à transformer n'importe quel périphérique connecté en une combinaison écran / contrôleur de jeu. Toutes les informations de contrôle sont envoyées vers un serveur distant sur lequel le jeu va en réalité tourner. Chaque image calculée par ce serveur est renvoyée vers le client à travers un flux H.264. Les avantages sont multiples : plus besoin d'une puissance de calcul importante du côté du joueur, plus besoin de mettre à jour son matériel pour les nouveaux jeux, possibilité de jouer facilement depuis n'importe quel endroit et périphérique. De quoi révolutionner le petit monde du jeu vidéo.
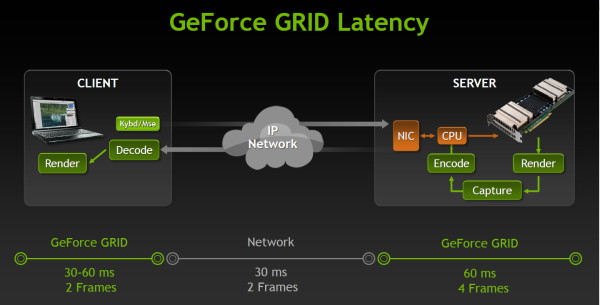
En contrepartie, cela demande une infrastructure importante du côté des fournisseurs de service et surtout, jouer depuis le cloud augmente significativement la latence. Deux points noirs auxquels Nvidia indique s'attaquer avec GeForce GRID.
Au niveau de l'infrastructure, il faut savoir qu'en règle générale, actuellement, il faut un système/serveur par joueur connecté. Nvidia donne ainsi un exemple actuel de plateforme dédiée au cloud gaming pour laquelle chaque baie accueille 28 serveurs (1 CPU + un GPU) et permet donc de gérer jusqu'à 28 flux de jeu. GeForce GRID permet de faire grimper cette densité en intégrant 4 GPU par serveur. Avec 21 de ces serveurs par baie il est ainsi possible de supporter jusqu'à 84 flux de jeu. Ce n'est pas tout puisque cette approche permet selon Nvidia de faire baisser la consommation typique de 150 à 75W par flux de jeu, un exemple probablement d'un jeu pas trop lourd rendu en 720p.
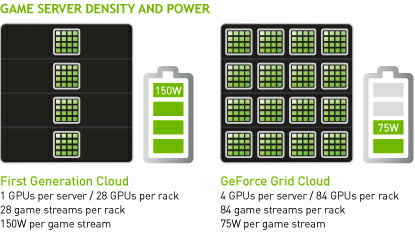
Comment cela est-il possible ? Tout d'abord au niveau matériel, Nvidia commercialise une carte GeForce GRID qui est en réalité identique à la Tesla K10. Il s'agit d'une version serveur de la GeForce GTX 690, avec des fréquences revues à la baisse pour tenir dans un TDP de 250W, configurable en 225W si nécessaire. Une seule de ces cartes peut ainsi gérer 2 flux de jeu. Nvidia propose d'en placer une seconde dans chaque serveur et probablement d'utiliser sa couche logicielle de virtualisation pour gérer efficacement jusqu'à 4 flux. La présence d'un encodeur H.264 dédié dans les GPU Kepler permet par ailleurs à GeForce GRID de gérer d'un bout à l'autre la récupération des images dans le framebuffer et leur encodage dans un flux H.264, déchargeant totalement le système de cette tâche et libérant le ou les CPU pour gérer ces flux de jeu supplémentaires.

Et pour la latence ? Nvidia nous donne ici aussi un exemple : 166ms pour une console, 286ms pour le cloud gaming actuel et 161ms pour GeForce GRID, en précisant que la latence typique d'un PC récent dans ce cas serait de 75ms.
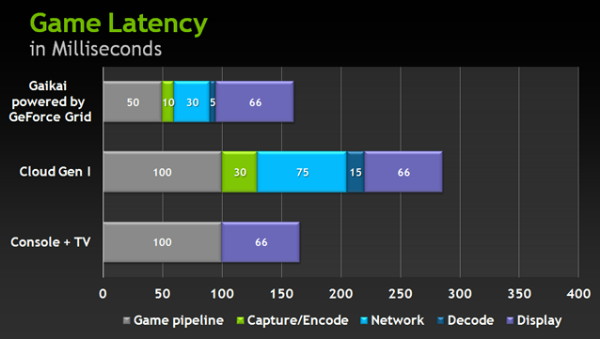
GeForce GRID gagne sur 3 points : le rendu, l'encodage et le réseau. Pour le rendu, Nvidia suppose qu'avec son GPU, les fournisseurs de service vont traiter les jeux à 60fps au lieu de 30fps, ce qui fait gagner 50ms de latence. Concernant l'encodage il passerait de 30 à 10ms alors que le décodage serait lui aussi plus rapide sur un composant Tegra.
Enfin, le réseau deviendrait lui aussi beaucoup plus rapide. En creusant un peu, Nvidia précise cependant ne rien pouvoir faire à ce niveau, mais supposer que GeForce GRID grâce à sa densité plus élevée et son attrait supérieur par rapport au cloud gaming actuel, va inciter les fournisseurs à mettre en place de plus en plus de serveurs. En d'autres termes, Nvidia présume que la probabilité d'en trouver un près de chez vous va augmenter et que la latence sera ainsi réduite.
Derrière ces affirmations se cache en réalité le fait que la latence du réseau est un problème et que Nvidia ne peut rien y faire actuellement, mais espère qu'elle se réduira à l'avenir. Ce ne sont cependant que des projections. Nvidia indique explorer d'autres voies telles que d'inciter les fabricants de TV à proposer une entrée ethernet à faible latence d'affichage, celle-ci étant en général relativement très élevée sur les TV, notamment à cause des différents traitements d'image.
Lors d'une démonstration sur TV, un autre problème saute aux yeux : la qualité de l'encodage H.264. Comme nous l'avons expliqué dans cet article dédié, NVENC, l'encodeur matériel de Kepler, s'il est très rapide, ne brille pas spécialement par sa qualité en comparaison de solutions CPU. Dans une scène de combat très rapide cela donne rapidement une bouillie de pixel passable sur un smartphone mais indigne d'un grand écran.
Vous l'aurez compris, nous ne sommes pas encore convaincus par le cloud gaming, en dehors du jeu occasionnel sur petit écran. Latence et qualité sont encore loin de pouvoir concurrencer ce bon vieux PC et Nvidia doit utiliser quelques artifices pour mettre en avant sa solution GeForce GRID : comparaison à des consoles qui commencent à dater et suppositions sur une amélioration future de la latence des réseaux.
Les mauvaises langues diront que faute d'avoir pu obtenir une place dans une des futures consoles pour l'un de ses GPU, Nvidia tente une autre approche pour ne pas être exclu de votre TV. D'autres, plus optimistes, insisteront sur le fait qu'il ne s'agit que d'un premier pas, qui a l'intérêt de trouver un nouveau débouché pour les GPU haut de gamme qui en ont bien besoin. De quoi pérenniser leur existence sur PC ?
Pour vous faire une idée sur le cloug gaming actuel, Gaikai propose gratuitement l'accès à des démos de quelques jeux PC, exécutées sur ses serveurs (classiques, sans GeForce GRID) et visualisées à travers un plugin pour votre navigateur internet. Le but étant à terme de proposer des jeux complets et de migrer vers des solutions plus efficaces telles que ce que promet Nvidia avec GeForce GRID.