Les contenus liés au tag AFDS
Afficher sous forme de : Titre | FluxAFDS: +50% pour Trinity et 10 Tflops en 2020
AFDS: OpenCL gagne du terrain ?
AFDS: AMD Fusion 11 Developer Summit
AFDS: Microsoft annonce C++ AMP



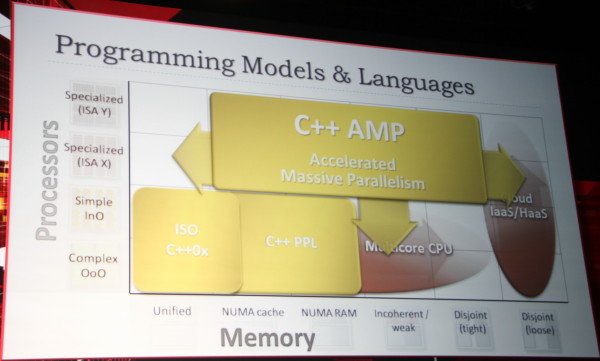
Microsoft a choisi l'AFDS pour présenter une nouvelle version de C++ optimisée pour l'exploitation des GPUs, et potentiellement de tout autre accélérateur. Baptisée AMP pour Accelerated Massive Parallelism, cette extension vient compléter C++0x et la Parrallel Patterns Library (PPL) pour faciliter l'écriture du code qui va inclure des fonctions destinées à être accélérées par le GPU.
Herb Sutter, Software Architect chez Microsoft et guru du C++, a insisté sur l'importance de ne pas complexifier le langage et de se contenter d'ajouts aussi simples que possibles en profitant de la signification implicite qu'ils peuvent amener pour laisser le compilateur se charger de toute la lourdeur qui est liée à l'utilisation de tels accélérateurs.
Seules deux nouveautés font ainsi leur apparition au niveau du langage. La première, array_view, permet de représenter une mémoire non uniforme, incohérente et/ou disjointe sans avoir à spécifier explicitement des .copy()/.sync(). Un niveau d'abstraction qui simplifiera nettement le code.
La seconde se nomme restrict(). Comme son nom l'indique, elle permet de spécifier des restrictions liées à une certaines architecture pour certaines fonctions. Celles-ci concernent les limitations inhérentes aux accélérateurs actuels et indiquent implicitement qu'il s'agit d'un morceau de code au parallélisme important qui pourra être exécuté sur le GPU. Dans la première version de C++ AMP préparée par Microsoft, il est question de viser l'API maison DirectCompute 11 en utilisant simplement restrict(direct3d), restrict(cpu) étant le mode par défaut implicite. Dans le futur Microsoft envisage un restrict(pure) qui n'aurait aucune restriction mais permettrait de déclarer le parallélisme au compilateur.


A gauche du code classique, à droite en version C++ AMP.
Aucun autre élément de langage ne sera introduit, tout le reste étant implicite. Par exemple attacher une variable à "const" sera interprété comme du "read only". Microsoft précise cependant à ce sujet qu'il n'y a actuellement aucun moyen similaire pour spécifier que des éléments sont "write only", ce qui pourrait être utile dans le futur.

Une démonstration réalisée par Microsoft a mis en avant la possibilité, avec un seul exécutable, de profiter de tout type de matériel : CPU, GPU, APU, APU + GPU, double GPU
Tout ceci devrait faire son apparition dans la prochaine version de Visual Studio. Par ailleurs Microsoft entend faire de C++ AMP un standard ouvert de manière à ce qu'il puisse être exploité sur différentes plateformes, que ce soit au niveau de l'interface compute ou du système d'exploitation. Herb Sutter a ainsi directement annoncé travailler avec AMD de manière à ce que ce dernier puisse en proposer une version FSA. ARM semble également intéressé par cette évolution. De son côté, Nvidia semble avoir été surpris par cette annonce et s'est empressé de publier sur son blog accueillir toute évolution qui facilite l'exploitation de la puissance de calcul des GPUs en précisant que la version d'AMP initiale visant DirectCompute11, ses GPUs en profiteraient également. Pas un mot sur une version CUDA d'AMP par contre
AFDS: Retour sur le futur GPU d'AMD

Lors du dernier keynote de l'AFDS, Eric Demers, Chief Technology Officer pour la partie GPU chez AMD, est revenu sur la future architecture GPU qui a été présentée avec de très nombreux détails cette semaine, de manière à en mettre en avant les grandes lignes d'une manière simplifiée. Il a également été confirmé qu'AMD espérait lancer cette architecture à la fin de l'année, si le procédé de fabrication 28nm n'entrave pas ces plans.
Eric a rappelé que l'évolution des GPUs ATI/AMD nous a fait passer d'une architecture au comportement vec4 + 1 vers une architecture vec5 à partir des Radeon HD 2900 puis enfin vers une architecture vec4 avec les Radeon HD 6900 qui sera déclinée dans de futurs GPUs milieu et bas de gamme ainsi que dans Trinity. Ces choix architecturaux s'expliquent par la présence de nombreuses opérations vec4 mais aussi scalaires dans le rendu graphique qui reste la tâche principale des GPUs. La flexibilité des unités de calcul de type MIMD/VLIW des derniers GPUs a permis de se passer du canal scalaire et de laisser le compilateur se charger de mixer toutes les opérations dans les 5 ou 4 canaux disponibles.
Avec sa future architecture, AMD a voulu conserver une organisation similaire. Si le modèle VLIW est abandonné, les blocs fondamentaux de ces GPUs vont garder ces 4 canaux, non pas pour exécuter des opérations vec4 mais pour conserver un ratio similaire et vu comme le plus adapté pour le graphique. Les tâches de type "compute" devenant de plus en plus importantes et affichant souvent une utilisation moindre des unités vec5 ou vec4, il fallait revenir à un modèle scalaire du point de vue du programmeur.
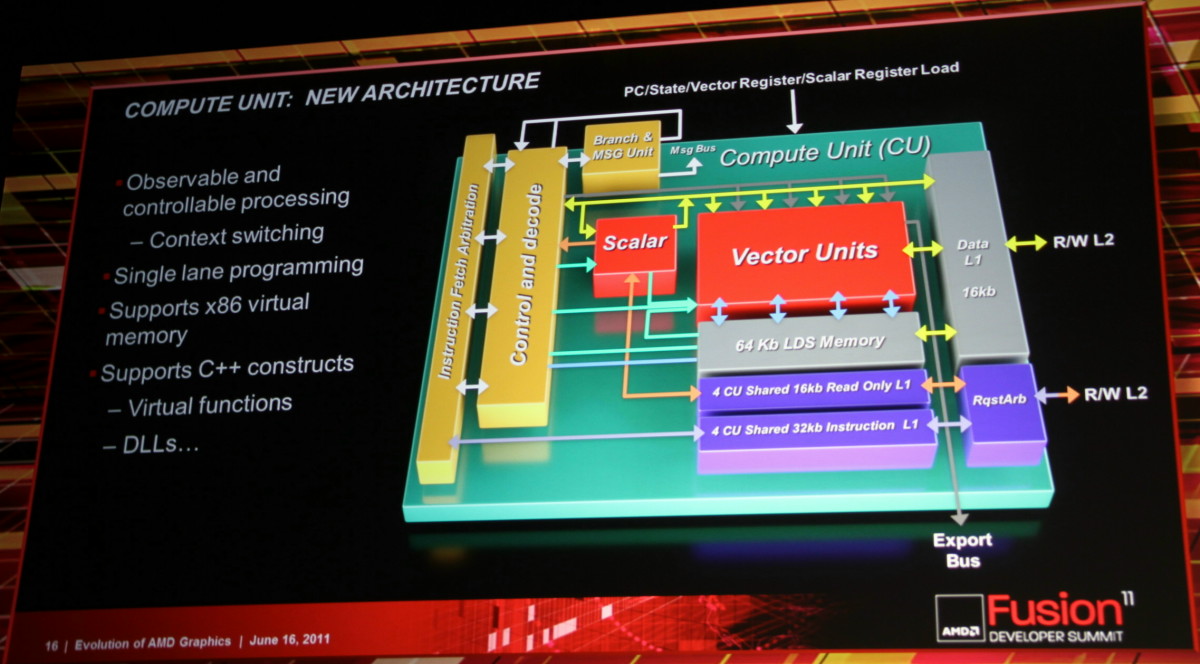
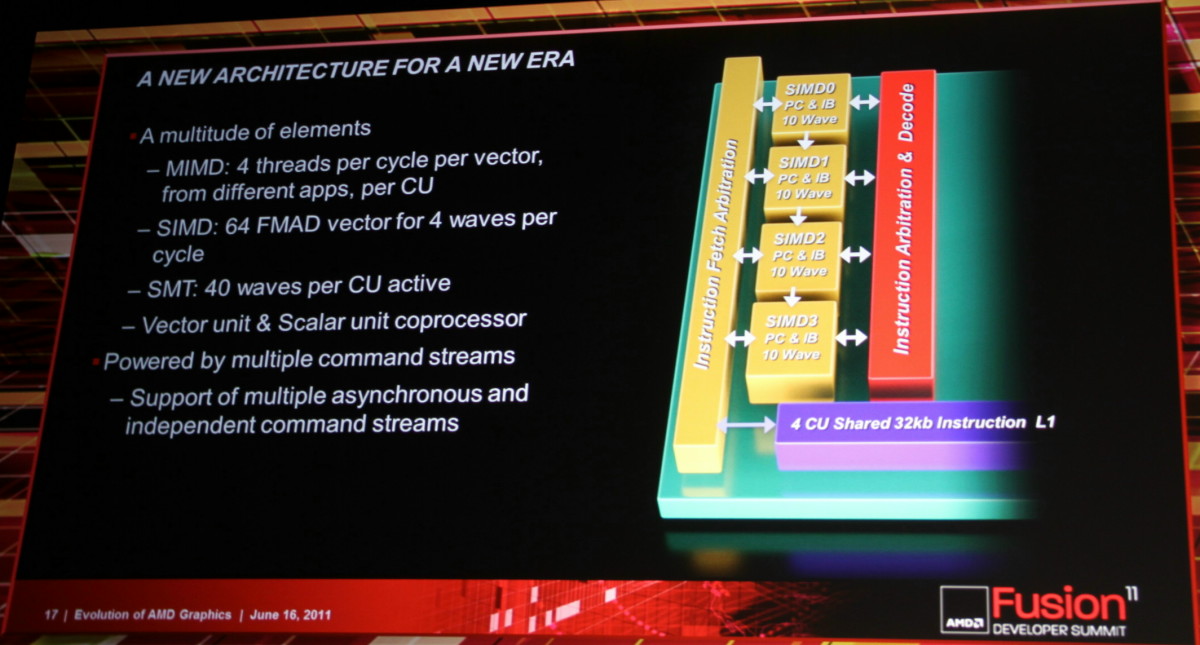

L'architecture proposée par AMD permet de combiner ces deux aspects en plaçant dans chaque Compute Unit non pas une grosse unité MIMD mais 4 plus petites unités SIMD indépendantes. Par ailleurs, AMD leur adjoint une unité scalaire qui sera destinée à éviter de monopoliser la puissance de calcul vectorielle par des opérations simples. Comme pour les blocs fondamentaux des GPUs actuels, chaque CU recevra 4 unités de texturing. Une CU est donc, sur le plan des unités d'exécution, très proche de ce qu'AMD appelle actuellement les SIMDs. C'est au niveau de l'exploitation de ces unités d'exécution que le changement est radical. Le GPU Cayman des Radeon HD 6900 peut d'ailleurs être vu comme une étape intermédiaire vers cette nouvelle architecture. Un côté hybride/prototype qui explique probablement son efficacité discutable.
Un autre aspect important de la nouvelle architecture est le multitâche puisque ces nouveaux GPUs seront capables de gérer différentes commandes simultanément ainsi que la priorité à donner à chacune d'elles. Tout ceci se passera au niveau du GPU et non au niveau du système d'exploitation.
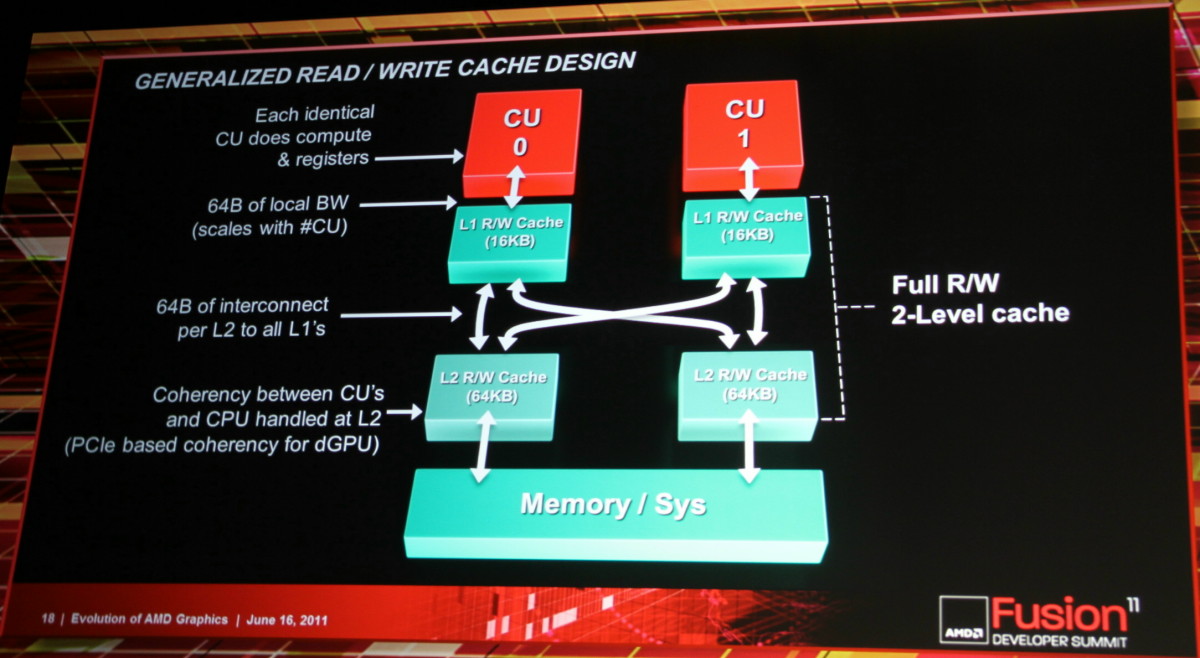
Le cache L2 utilisable en lecture et en écriture est la troisième grosse évolution. Il permet également l'existence d'un espace cohérent entre toutes les CUs ainsi qu'avec le CPU, que ce soit à l'intérieur d'un APU ou avec une carte graphique dédiée.
Ce cache L2 généralisé, le fonctionnement scalaire des unités de calcul, le support de l'espace mémoire virtuel x86 et du C++ vont faire exploser l'intérêt du GPU computing. Notez cependant que sur certains de ces points, AMD ne fait que rattraper le retard pris sur Nvidia.



Une interrogation importante que nous avons par rapport à cette nouvelle architecture est son efficacité énergétique. Comme nous avons pu le voir avec les Radeon HD 6970, elle était quelque peu en baisse. Augmenter le rendement d'une Compute Unit va donc faire progresser sa consommation relative. Si le procédé de fabrication 28nm permettra d'en faire baisser la consommation absolue, la question reste importante.
Nous avons pu nous entretenir avec Eric Demers à ce sujet et selon lui il s'agit d'un faux problème. Dans l'architecture actuelle, quand certaines lignes des unités vec4 ou vec5 ne sont pas utilisées, elles restent alimentées. Leur consommation est moindre que quand elles sont exploitées, mais elles gaspillent malgré tout beaucoup d'énergie. Ce gaspillage va disparaître avec la future architecture. En d'autres termes, nous nous approcherons probablement plus souvent de la consommation maximale des Compute Units, mais leur rendement énergétique serait dans tous les cas supérieur.
Enfin, nous avons demandé au CTO d'AMD s'il envisageait d'inclure à l'avenir dans les GPUs plus de CUs que ne le permet le TDP, tout en sachant qu'ils ne pourraient pas tous être exploités en rendu 3D (limités par PowerTune par exemple), mais en supposant qu'ils pourraient l'être dans le mode compute qui n'exploite pas certaines parties du GPU très gourmandes telles que les unités de texturing. Eric Demers nous a répondu qu'AMD envisageait effectivement cela et qu'une telle possibilité pourrait éventuellement être retenue à l'avenir, si les simulations le justifiaient, notamment pour un GPU qui viserait le HPC.
AFDS: Le GPU de Trinity dérivé des HD 6900
Lors de la présentation de sa future architecture, AMD a accidentellement divulgué un détail important sur le GPU de sa future APU Trinity : il sera dérivé de l'architecture des Radeon HD 6900. Pour rappel, cette architecture repose sur des unités de calcul vec4 au lieu de vec5 au rendement par unité de surface quelque peu plus élevé, ce qui facilite l'augmentation de leur nombre.

Un prototype de portable équipé de Trinity.
Si nous supposions il y a quelques jours que le GPU de Trinity pourrait intégrer 640 "cores" nous estimions alors qu'il s'agirait de 128 unités de calcul vec5. Etant donné l'utilisation confirmée d'unités vec4, s'il est possible que Trinity en intègre 160, nous estimons dorénavant plus probable qu'il s'agisse de 128 unités vec4 soit de 512 "cores", ce qui devrait suffire à proposer un gain de 50% au niveau de la partie GPU.
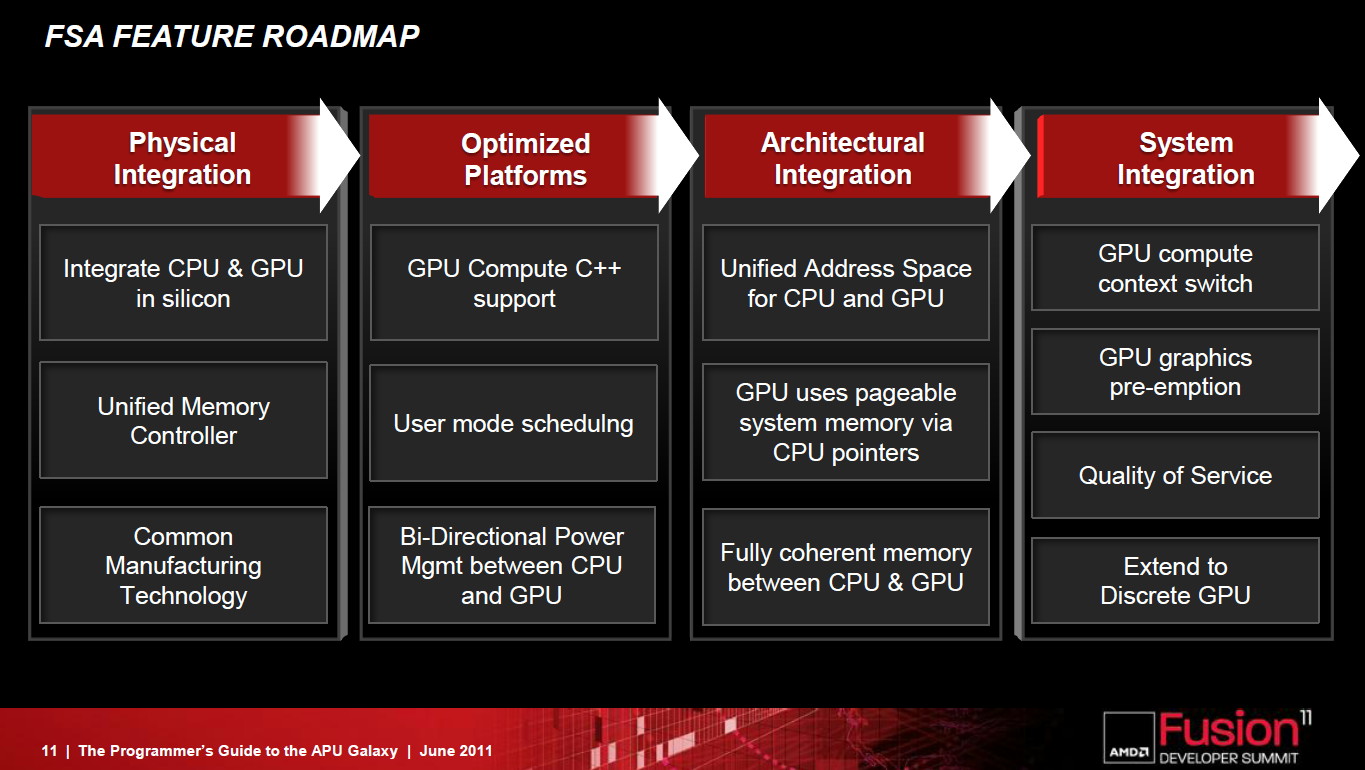
AFDS: AMD dévoile la FSA pour OpenCL
Ce qui est probablement l'annonce la plus importante de l'AFDS a été quelque peu éclipsée hier compte tenu des détails dévoilés sur la future architecture des GPUs AMD : la FSA.

Phil Rogers, AMD Corporate Fellow, dévoile les évolutions à venir dans le calcul hétérogène.
Un frein à l'utilisation du GPU computing réside dans l'overhead énorme lié à son exploitation, un point qu'AMD entend bien faire disparaître avec la Fusion System Architecture, une combinaison hardware et software destinée à simplifier le GPU computing et son utilisation combinée avec les cores CPUs.
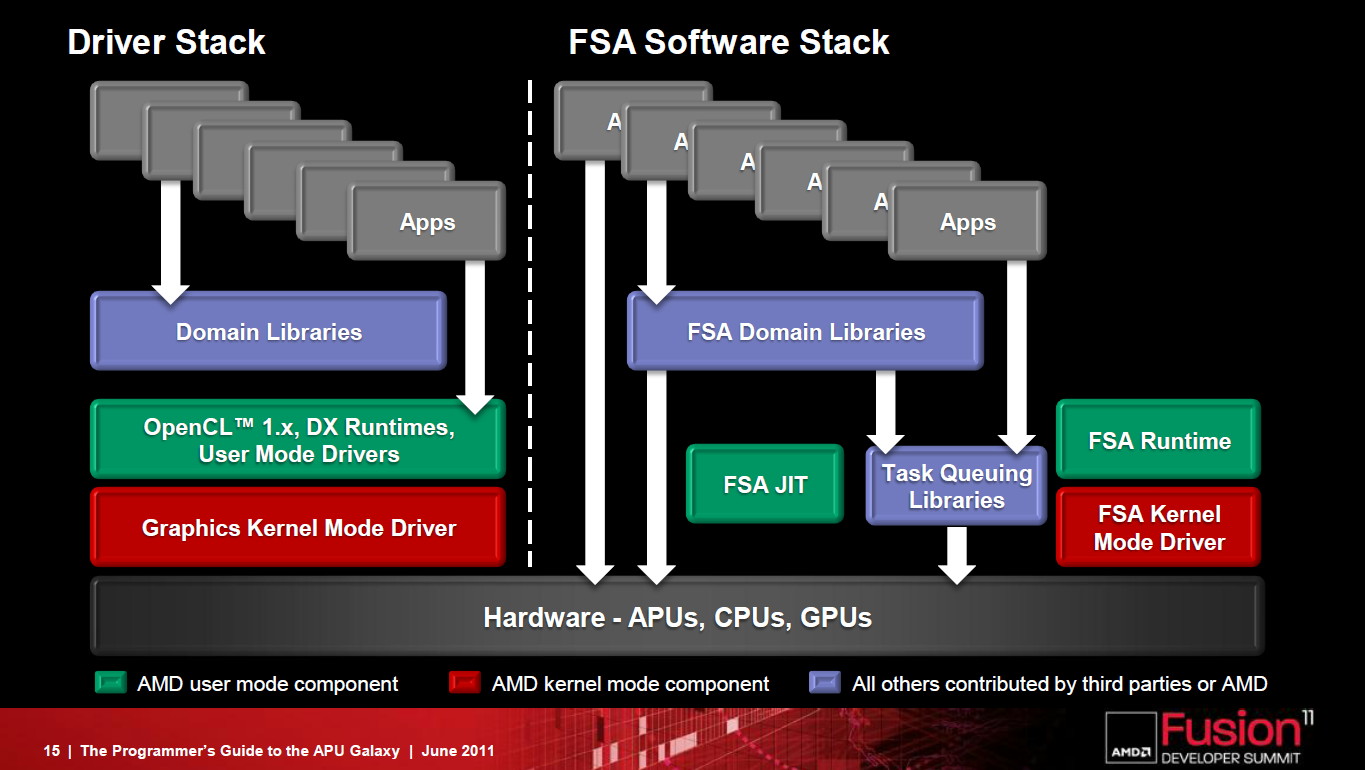
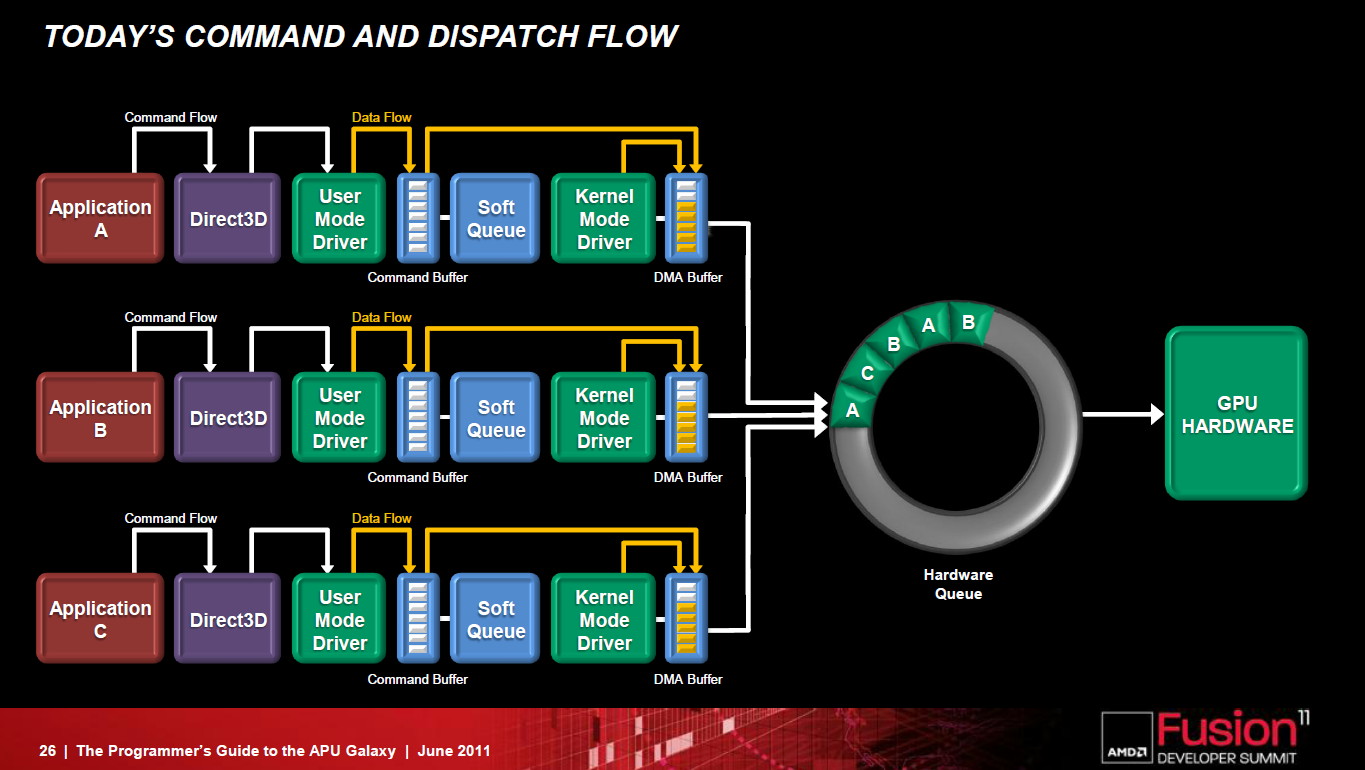

La FSA fait disparaître la lourdeur de la plateforme GPU compute actuelle.
Comme son nom l'indique, la FSA est avant tout pensée pour les APUs dans lesquels cores CPU et GPU sont proches l'un de l'autre, ce qui implique une communication simplifiée entre eux et une gestion d'un espace mémoire unifié plus simple à mettre en place. AMD compte cependant faire profiter les GPUs présents sur les cartes graphiques de tout ceci, grâce au PCI Express 3.0 qui offrira une bande passante supérieure ainsi qu'un espace unifié cohérent.

Cores CPU et GPU travaillent main dans la main plus efficacement grâce à la FSA.
La FSA n'est pas une nouvelle API mais une plateforme optimisée pour OpenCL et destinée à remettre à plat l'utilisation du GPU computing. Latence réduite, fin des copies de données inutiles entre les espaces CPU et GPU, pointeurs partagés entre CPU et GPU, possibilité d'un accès bas niveau au hardware pour des librairies hyper optimisées, modèle de queues hardware repris du SMP
L'arrivée complète de la FSA se fera dans les 3 ans selon AMD, dont une partie (le dispatching optimisé) introduite en principe cette année avec la nouvelle architecture GPU dévoilée à l'AFDS également. AMD entend rendre la FSA ouverte à la concurrence, reste à voir si cet appel trouvera un écho chez Intel et Nvidia !
Dans tous les cas il est intéressant d'observer qu'AMD, vu comme plutôt passif dans le domaine du GPU computing ces dernières années, à décidé de prendre à bras le corps les challenges que représentent son exploitation. Il faut dire que le fabricant n'a pas d'autre choix, les APUs ayant un besoin criant de telles évolutions pour montrer tout leur intérêt. La documentation complète de la FSA devrait être publiée avant la fin de l'année de manière à permettre aux développeurs de s'y préparer.







AFDS: L'architecture des futurs GPUs AMD!
La première journée du Fusion Summit s'est terminée par une session surprenante durant laquelle Michael Mantor, Senior Fellow Architect, et Mike Houston, Fellow Architect, ont dévoilé la future architecture GPU d'AMD avec de très nombreux détails, ne laissant que quelques éléments spécifiques au rendu 3D de côté.

Michael Mantor, AMD Senior Fellow Architect.
AMD travaille sur cette nouvelle architecture depuis près de 5 ans déjà et a pour objectif principal d'en simplifier le modèle de programmation pour convaincre un maximum de développeurs de se pencher sur la puissance de calcul offerte par les GPUs. Il s'agit également de la première architecture a avoir été influencée en profondeur par l'intégration d'ATI dans AMD et par le projet Fusion.

Cette architecture marque ainsi une rupture significative par rapport aux GPUs actuels en se débarrassant du modèle VLIW, qui repose sur l'exécution simultanée de plusieurs instructions indépendantes, au profit d'un fonctionnement scalaire du point de vue du programmeur. Le front-end, les processeurs de commandes et la structure des caches ont par ailleurs été entièrement revus pour proposer un mode compute plus performant et plus flexible ainsi que pour traiter efficacement le multitâche qui va devenir de plus en plus importants pour les GPUs.
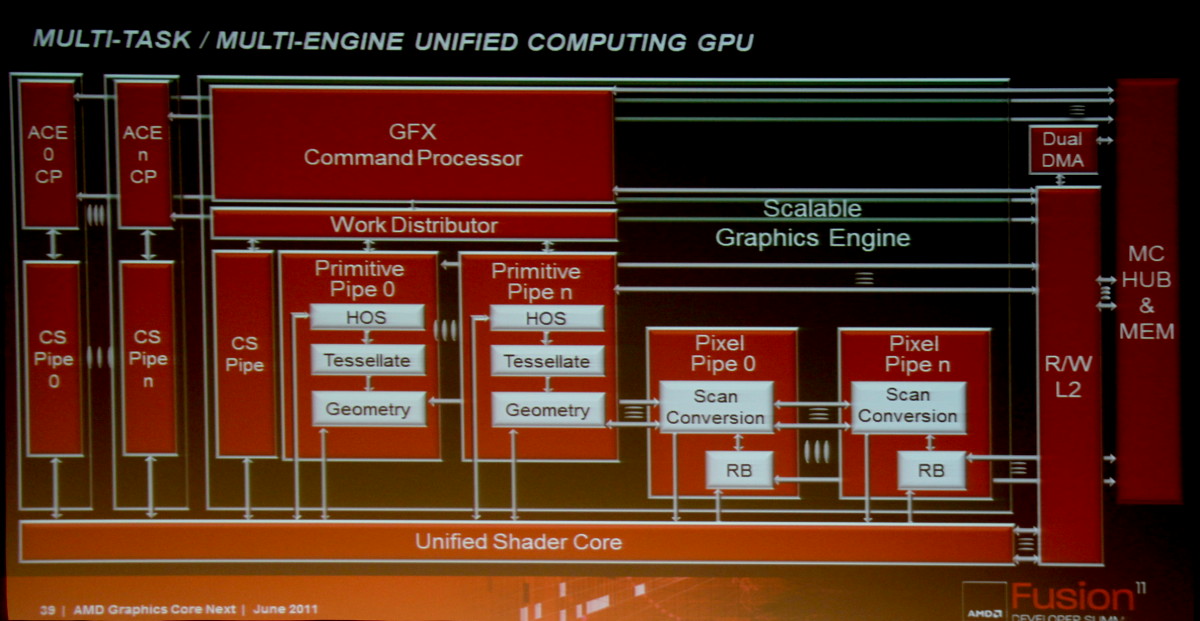
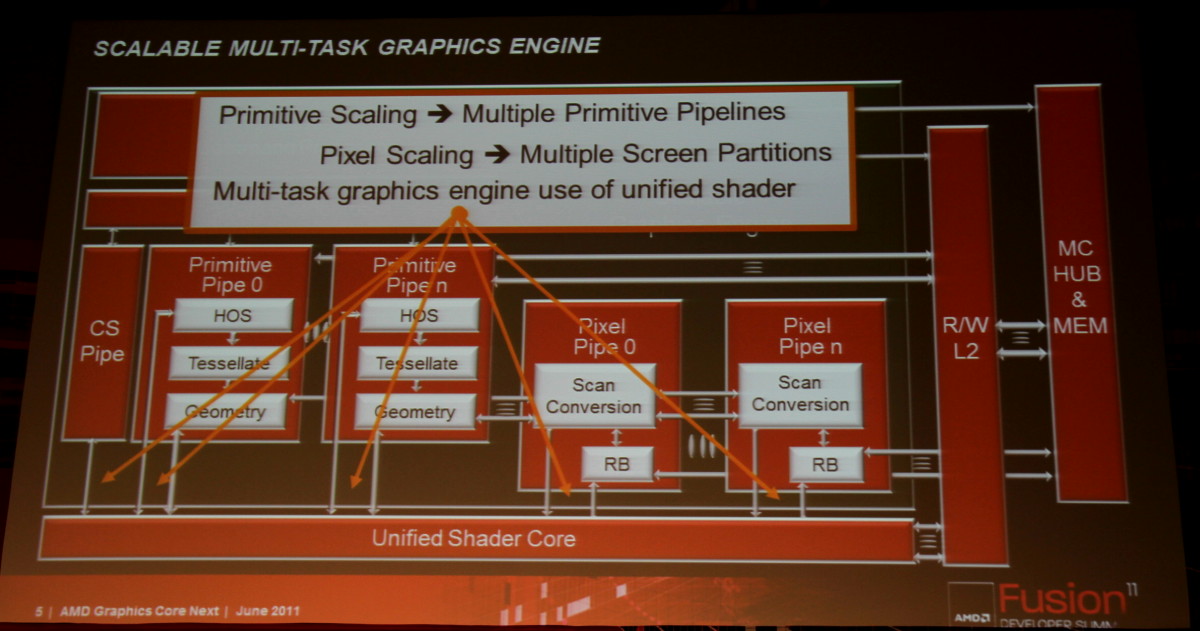
Des Asynchronous Compute Engines (ACE) font ainsi leur apparition pour prendre en charge les tâches compute sans passer par la partie graphique. Cette dernière n'est cependant pas en reste puisque les unités de gestion de la géométrie et des pixels sont parallélisées, ce qui profitera à la tessellation. Contrairement à l'approche de Nvidia, la prise en charge de la géométrie n'est pas distribuée au niveau des blocs d'unités de calcul, mais reste découplée de celles-ci.
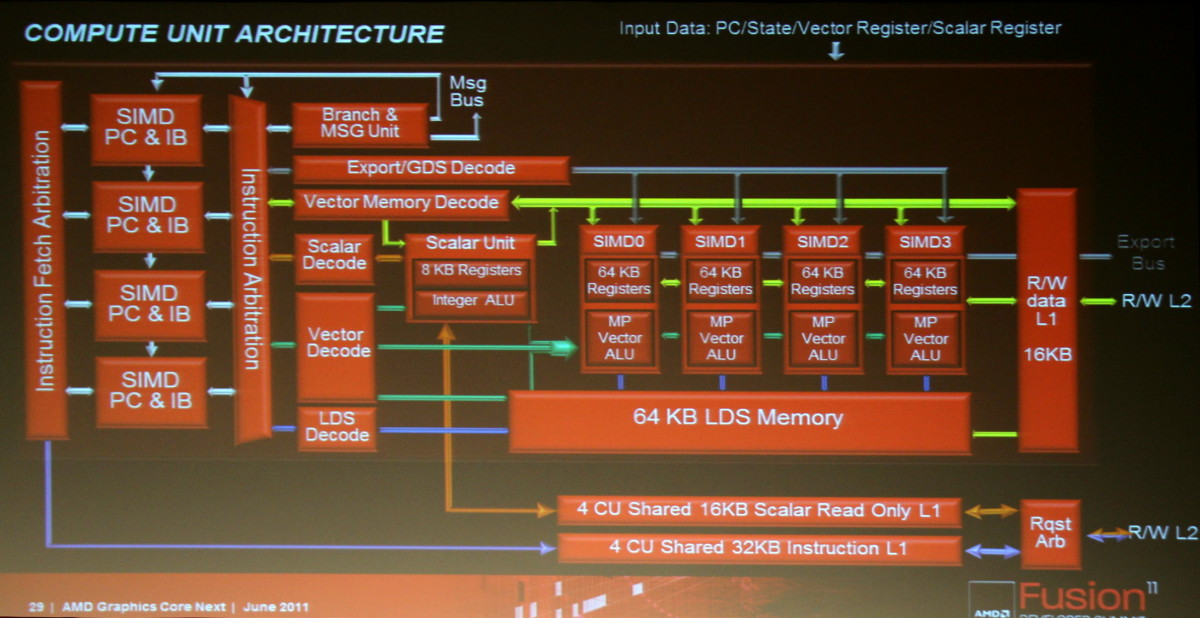
Les SIMDs actuels disparaissent au profit de Compute Units. Chaque CU dispose dorénavant d'une unité scalaire et de 4 petits SIMDs indépendants similaires à ceux des GPUs Nvidia. Grossièrement, un SIMD de Cayman peut exécuter une instruction vec4 sur 16 éléments à chaque cycle alors que chaque CU est capable d'exécuter 4 instructions sur 16 éléments issus de 4 groupes différents plus une instruction scalaire. La puissance de calcul d'une CU est donc similaire à celle d'un SIMD actuel mais devrait gagner nettement en efficacité.
AMD n'a pas voulu préciser quand cette architecture devrait être introduite et s'est contenté d'indiquer que le GPU de Trinity ne serait pas basé sur celle-ci mais bien sur l'architecture vec4 des Radeon HD 6900. Les bruits de couloir nous font cependant état d'une arrivée prévue dès cette année, voire même d'une démonstration du GPU qui l'inaugurera lors du keynote de clôture du Fusion Summit !
Il ne faudrait donc attendre que quelques mois pour voir ce qu'apportera en pratique cette nouvelle architecture prometteuse sur le papier. Si elle facilitera à terme l'optimisation du compilateur GPU, elle demandera cependant un effort important aux équipes chargées des pilotes compte tenu de la rupture avec les GPUs actuels. Concernant le coût de cette nouvelle architecture, AMD nous a indiqué qu'il n'était que légèrement plus élevé que celui des architectures actuelles, certaines parties étant plus complexe mais d'autres simplifiées. Elle ne devrait donc pas être un frein à l'augmentation du nombre d'unités de calcul.
Notez que cette architecture proposera plus de modularité qu'auparavant puisqu'en plus du nombre de CUs, AMD pourra faire varier le nombre d'ACEs, le nombre de pipelines dédiées à la géométrie ou aux pixels, la puissance de calcul en double précision (de 1/2 à 1/16) De toute évidence, la première implémentation devrait être un GPU haut de gamme avec au moins 30 CUs, plusieurs ACEs et un calcul en double précision à demi-vitesse.
Voici donc les grandes lignes de cette future architecture, sur laquelle nous essaierons de revenir plus en détails après le Fusion Summit.
Nous avons publié quelques informations de plus dans une seconde actualité et voici tous les détails dévoilés par AMD sur cette architecture :














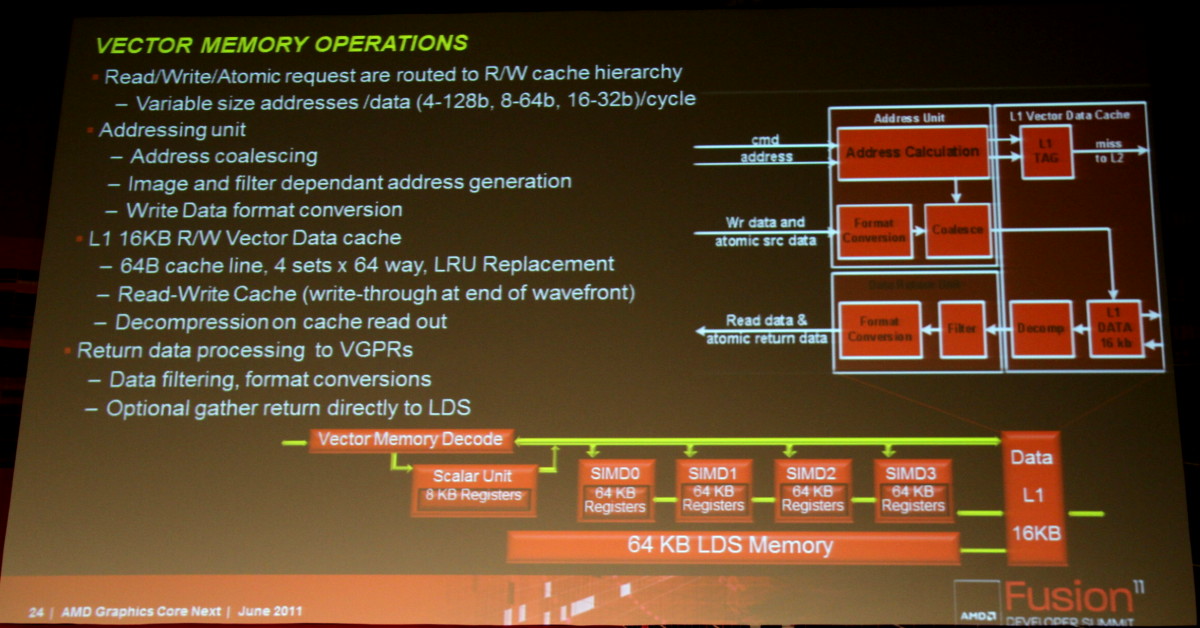






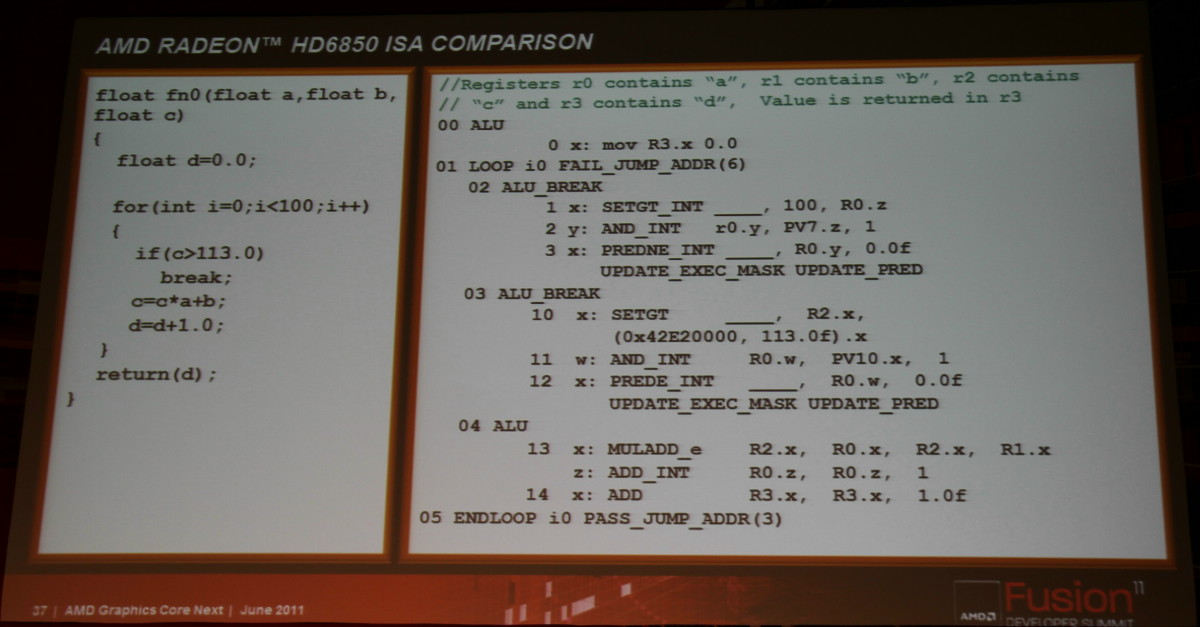
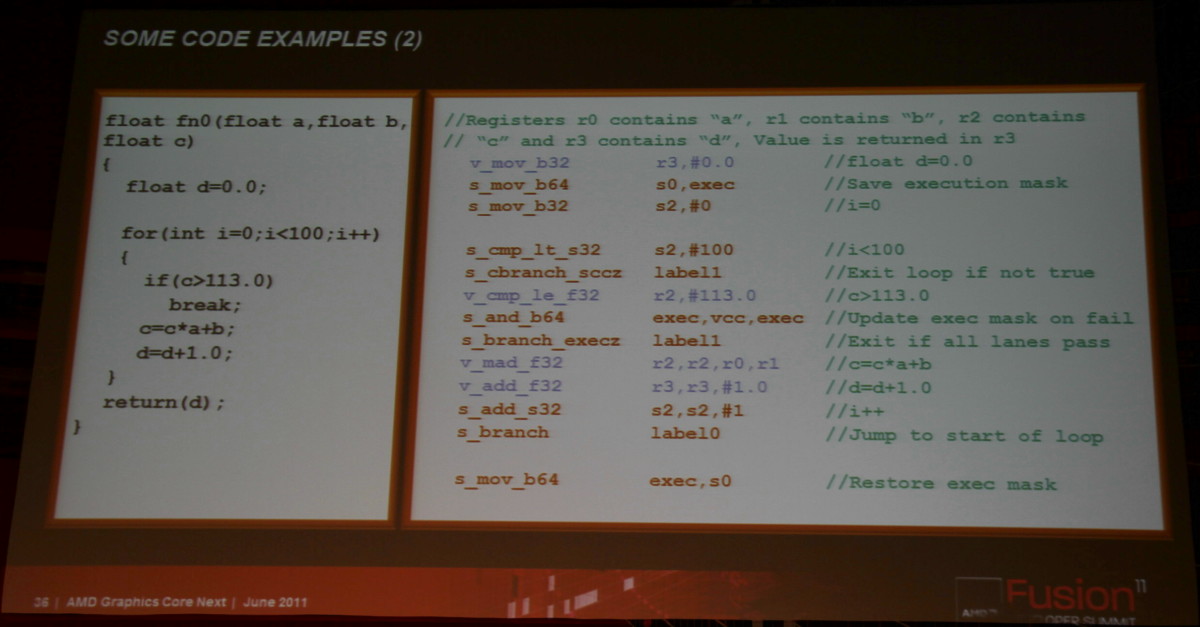
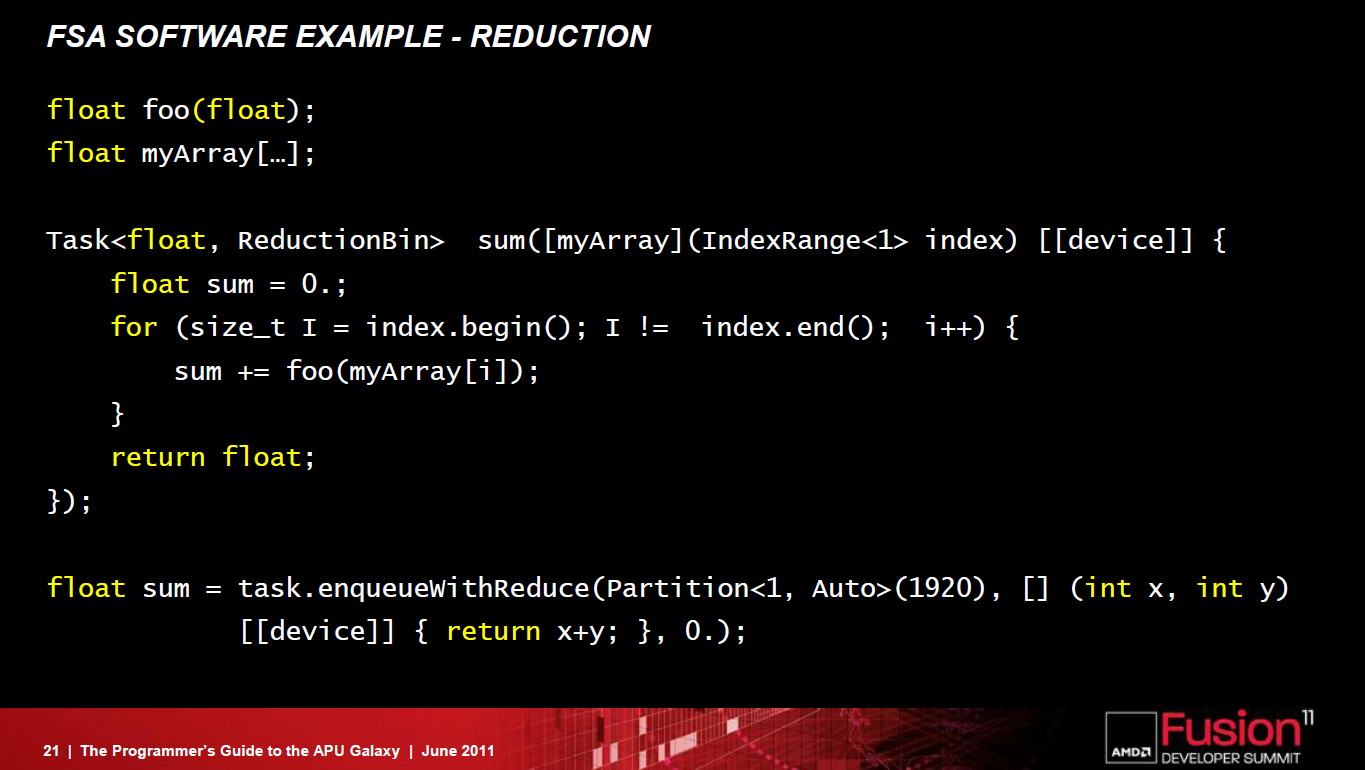
Ainsi que deux exemples de code généré pour l'architecture actuelle d'une part et pour cette nouvelle architecture d'autre part :