
Les contenus liés aux tags AMD et AFDS
Afficher sous forme de : Titre | FluxAFDS: AMD dévoile la FSA pour OpenCL
AFDS: L'architecture des futurs GPUs AMD!
AFDS: +50% pour Trinity et 10 Tflops en 2020
AFDS: OpenCL gagne du terrain ?
AFDS: AMD Fusion 11 Developer Summit
AFDS: ARM Cortex A5 dans les futures APU AMD



Il y a quelques mois, AMD avait expliqué être en train de réorganiser ses méthodes de développement pour atteindre un niveau de modularité similaire à celui des SoC. En plus de réduire les coûts à terme, une telle approche permet de gagner en flexibilité et de pouvoir intégrer plus facilement des technologies tierces à ses produits. AMD ayant précisé vaguement ne pas être forcément limité à l'ISA x86, la conclusion logique était que des cores ARM ou dérivés de son jeu d'instruction feraient leur apparition dans de futurs produits AMD.

C'est ce qui aura lieu dès l'an prochain, mais pas spécialement sous la forme que certains attendaient, telle qu'un SoC combinant cores ARM et GPU Radeon. Si un tel produit pourrait voir le jour dans le futur, ce n'est pas la première utilisation visée par l'utilisation de cores ARM. AMD souffre actuellement de l'absence de technologie de sécurisation dans ses plateformes, telle que la Trusted Execution Technology d'Intel (TXT), qui permet de sécuriser certains systèmes de paiement, DRM et autres infrastructures professionnelles et est vouée à se généraliser à l'avenir. Développer en interne une telle technologie est complexe et coûteux, d'autant plus qu'il faut ensuite convaincre tout l'écosystème de la supporter.
Malheureusement pour AMD, TXT ne fait pas partie de la licence x86 et l'accès à cette technologie n'est pas automatique. Intel ayant probablement rechigné à transférer sa technologie sous licence, ou le coût de cette celle-ci étant prohibitif, AMD a décidé de se tourner vers TrustZone d'ARM. Il s'agit de la plateforme concurrente principale de TXT et elle est présente au sein de tous les cores Cortex A. Elle repose sur une extension du jeu d'instruction d'ARM et ne peut donc pas être transposée facilement dans un core x86.

AMD a donc décidé d'inclure un core ARM dans ses futures APU, à commencer par Kabini et Temash qui succèderont à Brazos 2.0 et Hondo l'an prochain, avant de le généraliser à l'ensemble de ses produits. AMD a opté pour un Cortex A5, qui est le plus petit core de la famille : 0.53mm² en 40nm soit en principe moins de 0.30mm² en 28nm. Son intégration prendra probablement un petit peu plus de place mais à l'échelle de la puce elle aura un impact insignifiant.
AMD n'a pour l'instant pas donné plus de détails sur l'implémentation, ni sur la manière dont ce core ARM interagira avec les cores x86 dont il devra contrôler l'exécution, et encore moins sur l'exposition directe éventuelle de ce core qui pourrait par exemple être exploité par un antivirus. Une utilisation qui permettrait par exemple à AMD de répondre à l'intégration dans les CPU Intel d'optimisations destinées aux logiciels McAfee.
AFDS: 1 Teraflops pour l'APU Kaveri
Dans la vision d'AMD concernant le calcul hétérogène, les APU jouent comment vous vous en doutez un rôle important, d'une parte parce qu'elles permettent de démocratiser la technologie et d'autre part parce qu'elles autorisent une communication plus efficace entre les cores CPU et GPU.
En 2013, l'APU Kaveri apportera de nouvelles évolutions importantes pour le calcul hétérogène et profitera en partie pour cela de l'architecture graphique GCN introduite dans les Radeon HD 7000. Si AMD ne rentre pas encore dans ces détails, les objectifs en termes de puissance de calcul ont été dévoilés lors de l'AFDS : 1 Teraflops pour l'ensemble CPU/GPU.
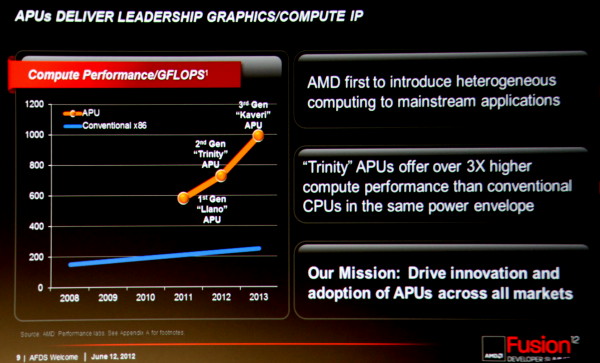
Par rapport à Trinity et l'A10-5800K qui culmine à 738 Gflops, il s'agit d'un gain de 35% qui proviendra en toute logique avant tout du GPU dont nous pouvons supposer qu'il passera de 384 à 512 unités de calcul. Notez que l'architecture GCN étant plus efficace que l'architecture VLIW4 de Trinity, les gains devraient être en pratique supérieurs à ce que ne laissent penser ces premiers chiffres.
AFDS: AMD, ARM, ImgTech, TI : HSA Foundation

L'AMD Fusion Developer Summit, un forum technologique dédié au calcul hétérogène, a actuellement lieu à Seattle. Ce forum peut être vu comme la réplique d'AMD à la GPU Technology Conference de Nvidia qui s'est tenue le mois passé, mais un point important distingue cependant les deux évènements : AMD conçoit autant des cores CPU que des cores GPU. Plus que le calcul massivement parallèle, qui exploite les GPU, c'est ainsi le calcul hétérogène qui est ici à l'honneur.
Exploiter en symbiose des cores CPU et des cores GPU est complexe, notamment parce qu'ils ne partagent pas encore un espace mémoire totalement unifié, même si l'APU Trinity apporte quelques avancées à ce niveau. L'an passé, AMD avait annoncé la Fusion System Architecture, une tentative d'apporter des réponses à cette problématique de manière à pouvoir fournir une plateforme plus simple à exploiter pour un maximum de développeurs. AMD avait alors précisé vouloir en faire un standard ouvert : publier une documentation complète avant la fin 2011 et mettre en place un consortium pour gérer la FSA.
AMD a pris du retard sur la documentation qui n'est toujours pas disponible, mais a entretemps renommé la FSA en Heterogeneous System Architecture de façon à la détacher de sa marque Fusion. Il y a quelques mois, AMD précisé ses plans au sujet du consortium qui se dénommerait HSA Foundation et se verrait transférer tous ses travaux initiaux.
Cette édition de l'AFDS est l'occasion pour AMD de concrétiser la mise en place de la HSA Foundation, qui est effective depuis quelques jours. Il s'agit d'une organisation à but non-lucratif qui sera dorénavant chargée du développement et de la promotion de ce standard ouvert destiné à simplifier le calcul hétérogène qu'il concerne les PC, les smartphones ou les serveurs. Sa tâche sera également de produire des outils de développements efficaces et d'aider à la formation des développeurs.


AMD transfère à cette fondation la totalité de ses travaux initiaux sur la FSA/HSA, à savoir : un compilateur open source, des librairies et les documentations préliminaires qui concernent la programmation, les spécifications hardware ainsi que les spécifications software. AMD fournis par ailleurs une partie des fonds pour la mise en place de la fondation.
La fondation est bien entendu destinée à accueillir un maximum de membres, qui pourront être de plusieurs types : fondateurs (ce qui est encore possible s'ils y sont invités dans les 90 jours), promoteurs, supporters, contributeurs, universitaires et autres associés. Comme c'est généralement de mise pour ce type d'organisation, chaque membre participe à son budget de fonctionnement suivant son rôle, ce qui représente jusqu'à 125.000$ par an pour les membres fondateurs.

Les représentants des cinq membres fondateurs de la HSA Foundation, qui forment son conseil d'administration actuel.
La mise en place de la HSA Foundation n'aurait pas pu se faire sans son élargissement à d'autres grands noms de l'industrie. La présence d'ARM à l'AFDS l'an passé ne laissait aucun doute sur l'intérêt de la société spécialisée dans les modules destinés au SoC, pour laquelle le calcul hétérogène est la seule solution viable sur le plan énergétique, et c'est donc sans surprise qu'ARM fait partie des membres fondateurs de la fondation. D'autres ont rejoint l'initiative et sont tous liés aux SoC d'une manière ou d'une autre : Imagination Technologies, MediaTek et Texas Instruments.
Chacune de ces sociétés disposera d'un membre au conseil d'administration de la fondation (Manju Hedge, Vice-Président des solutions développeurs destinées au calcul hétérogène chez AMD et ex-CEO d'Ageia; Jem Davies Vice-Président responsable de la division Media Processing chez ARM ) qui sera gérée au quotidien par Phil Rogers, Président de la HSA Foundation et AMD Corporate Fellow.
Reste bien entendu que d'autres grands noms sont malheureusement absents du tableau, tels que Nvidia et surtout Intel. Les membres fondateurs ne désespèrent pas à l'idée de les voir rejoindre l'initiative, sans cependant se faire d'illusion à ce sujet. Mais ce sont, avant tout autre chose, les développeurs qu'ils devront s'attacher à convaincre et pour cela, comme le rappelait Adobe présent également à l'AFDS, il faudra leur proposer des outils complets, performants, simples d'utilisation et fiables. Un gros chantier en perspective.
Vous pourrez retrouver toutes les informations disponibles actuellement sur le site de la HSA Foundation qui vient d'être mis en ligne mais la documentation complète se fait cependant toujours attendre.
AFDS: Retour sur le futur GPU d'AMD

Lors du dernier keynote de l'AFDS, Eric Demers, Chief Technology Officer pour la partie GPU chez AMD, est revenu sur la future architecture GPU qui a été présentée avec de très nombreux détails cette semaine, de manière à en mettre en avant les grandes lignes d'une manière simplifiée. Il a également été confirmé qu'AMD espérait lancer cette architecture à la fin de l'année, si le procédé de fabrication 28nm n'entrave pas ces plans.
Eric a rappelé que l'évolution des GPUs ATI/AMD nous a fait passer d'une architecture au comportement vec4 + 1 vers une architecture vec5 à partir des Radeon HD 2900 puis enfin vers une architecture vec4 avec les Radeon HD 6900 qui sera déclinée dans de futurs GPUs milieu et bas de gamme ainsi que dans Trinity. Ces choix architecturaux s'expliquent par la présence de nombreuses opérations vec4 mais aussi scalaires dans le rendu graphique qui reste la tâche principale des GPUs. La flexibilité des unités de calcul de type MIMD/VLIW des derniers GPUs a permis de se passer du canal scalaire et de laisser le compilateur se charger de mixer toutes les opérations dans les 5 ou 4 canaux disponibles.
Avec sa future architecture, AMD a voulu conserver une organisation similaire. Si le modèle VLIW est abandonné, les blocs fondamentaux de ces GPUs vont garder ces 4 canaux, non pas pour exécuter des opérations vec4 mais pour conserver un ratio similaire et vu comme le plus adapté pour le graphique. Les tâches de type "compute" devenant de plus en plus importantes et affichant souvent une utilisation moindre des unités vec5 ou vec4, il fallait revenir à un modèle scalaire du point de vue du programmeur.
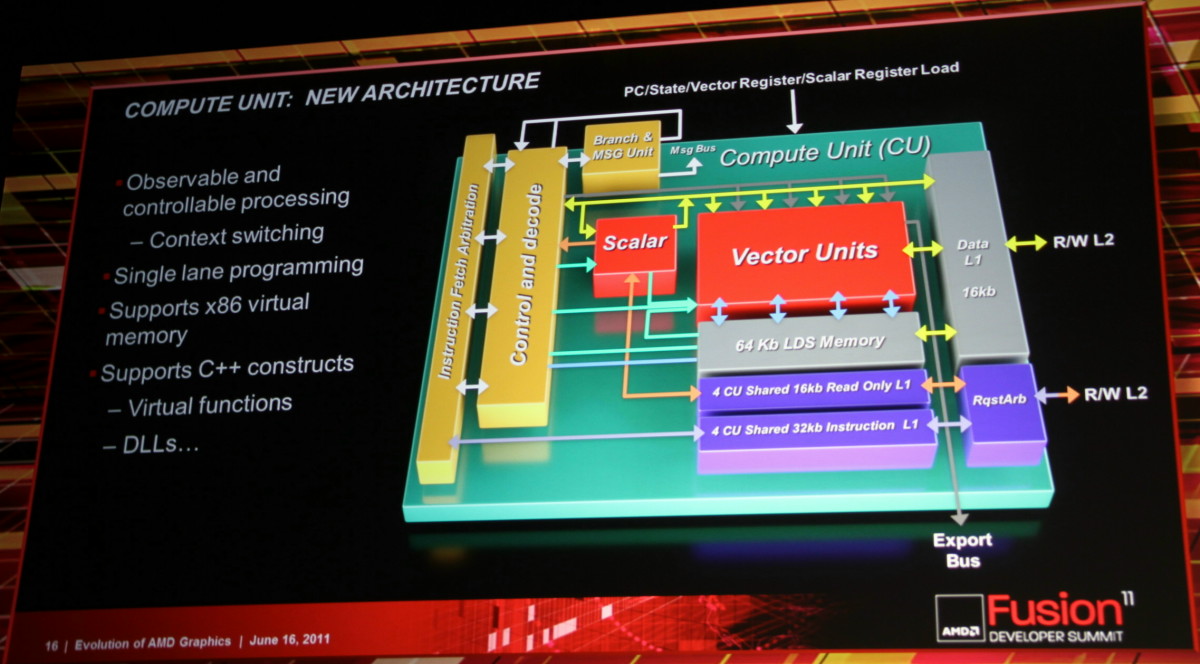
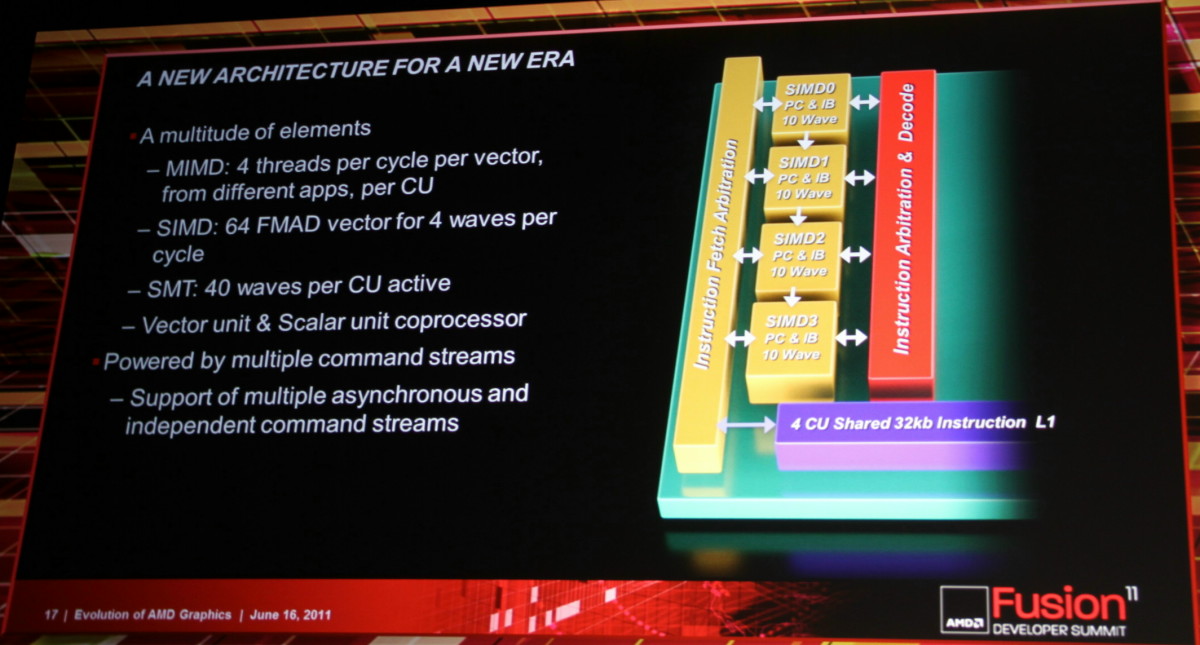

L'architecture proposée par AMD permet de combiner ces deux aspects en plaçant dans chaque Compute Unit non pas une grosse unité MIMD mais 4 plus petites unités SIMD indépendantes. Par ailleurs, AMD leur adjoint une unité scalaire qui sera destinée à éviter de monopoliser la puissance de calcul vectorielle par des opérations simples. Comme pour les blocs fondamentaux des GPUs actuels, chaque CU recevra 4 unités de texturing. Une CU est donc, sur le plan des unités d'exécution, très proche de ce qu'AMD appelle actuellement les SIMDs. C'est au niveau de l'exploitation de ces unités d'exécution que le changement est radical. Le GPU Cayman des Radeon HD 6900 peut d'ailleurs être vu comme une étape intermédiaire vers cette nouvelle architecture. Un côté hybride/prototype qui explique probablement son efficacité discutable.
Un autre aspect important de la nouvelle architecture est le multitâche puisque ces nouveaux GPUs seront capables de gérer différentes commandes simultanément ainsi que la priorité à donner à chacune d'elles. Tout ceci se passera au niveau du GPU et non au niveau du système d'exploitation.
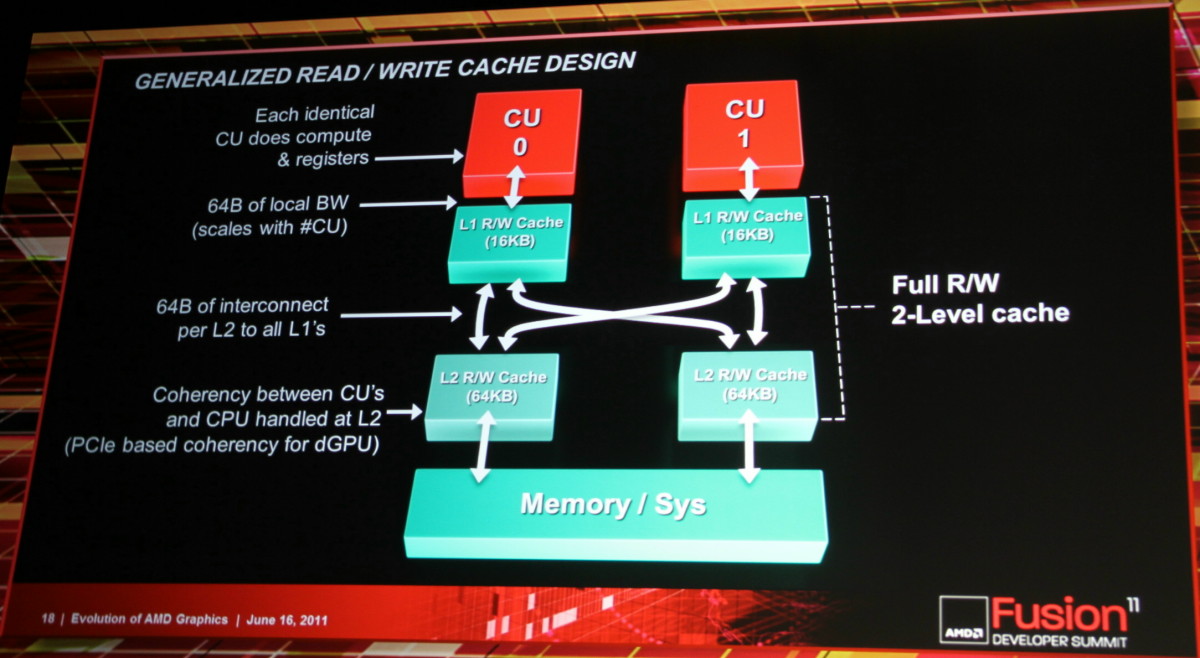
Le cache L2 utilisable en lecture et en écriture est la troisième grosse évolution. Il permet également l'existence d'un espace cohérent entre toutes les CUs ainsi qu'avec le CPU, que ce soit à l'intérieur d'un APU ou avec une carte graphique dédiée.
Ce cache L2 généralisé, le fonctionnement scalaire des unités de calcul, le support de l'espace mémoire virtuel x86 et du C++ vont faire exploser l'intérêt du GPU computing. Notez cependant que sur certains de ces points, AMD ne fait que rattraper le retard pris sur Nvidia.



Une interrogation importante que nous avons par rapport à cette nouvelle architecture est son efficacité énergétique. Comme nous avons pu le voir avec les Radeon HD 6970, elle était quelque peu en baisse. Augmenter le rendement d'une Compute Unit va donc faire progresser sa consommation relative. Si le procédé de fabrication 28nm permettra d'en faire baisser la consommation absolue, la question reste importante.
Nous avons pu nous entretenir avec Eric Demers à ce sujet et selon lui il s'agit d'un faux problème. Dans l'architecture actuelle, quand certaines lignes des unités vec4 ou vec5 ne sont pas utilisées, elles restent alimentées. Leur consommation est moindre que quand elles sont exploitées, mais elles gaspillent malgré tout beaucoup d'énergie. Ce gaspillage va disparaître avec la future architecture. En d'autres termes, nous nous approcherons probablement plus souvent de la consommation maximale des Compute Units, mais leur rendement énergétique serait dans tous les cas supérieur.
Enfin, nous avons demandé au CTO d'AMD s'il envisageait d'inclure à l'avenir dans les GPUs plus de CUs que ne le permet le TDP, tout en sachant qu'ils ne pourraient pas tous être exploités en rendu 3D (limités par PowerTune par exemple), mais en supposant qu'ils pourraient l'être dans le mode compute qui n'exploite pas certaines parties du GPU très gourmandes telles que les unités de texturing. Eric Demers nous a répondu qu'AMD envisageait effectivement cela et qu'une telle possibilité pourrait éventuellement être retenue à l'avenir, si les simulations le justifiaient, notamment pour un GPU qui viserait le HPC.
AFDS: Le GPU de Trinity dérivé des HD 6900
Lors de la présentation de sa future architecture, AMD a accidentellement divulgué un détail important sur le GPU de sa future APU Trinity : il sera dérivé de l'architecture des Radeon HD 6900. Pour rappel, cette architecture repose sur des unités de calcul vec4 au lieu de vec5 au rendement par unité de surface quelque peu plus élevé, ce qui facilite l'augmentation de leur nombre.

Un prototype de portable équipé de Trinity.
Si nous supposions il y a quelques jours que le GPU de Trinity pourrait intégrer 640 "cores" nous estimions alors qu'il s'agirait de 128 unités de calcul vec5. Etant donné l'utilisation confirmée d'unités vec4, s'il est possible que Trinity en intègre 160, nous estimons dorénavant plus probable qu'il s'agisse de 128 unités vec4 soit de 512 "cores", ce qui devrait suffire à proposer un gain de 50% au niveau de la partie GPU.