
Les contenus liés au tag Tesla
Afficher sous forme de : Titre | FluxComputex: serveurs avec GPUs chez Supermicro
Tesla 20 et Fermi : plus de détails
Nvidia dévoile des Tesla 20 avec Fermi
Computex : serveur Tesla chez Supermicro
Computex : Nvidia mise sur GPU Computing
Tesla K20 et GK110 : les specs finales ?



Comme vous devez le savoir, Nvidia prévoit de commercialiser à partir du mois de décembre la première carte basée sur le gros GPU Kepler, le GK110 et ses 7.1 milliards de transistors. Dénommée K20, elle prend place dans la gamme Tesla destinée au calcul intensif.
Certains gros clients ont reçu les premiers échantillons de la part de Nvidia et les détails commencent à fuiter. Citons par exemple le cas d'Oak Ridge National Laboratory qui est en train de faire évoluer son supercalculateur Cray XT5, dénommé Jaguar, en remplaçant progressivement ses 18688 nuds par des plateformes XK6 équipées d'Opteron 6274 Bulldozer. 14592 de ces nuds sont voués à recevoir un accélérateur Tesla K20.

heise online a pu relever, avant leur retrait, les spécifications finales de la Tesla K20 qui ont été publiées par CADnetwork, un revendeur de serveurs. Comme nous le supposions à son annonce, une partie des unités de calcul sont désactivées de manière à obtenir un volume de production suffisant. Alors que le GK110 embarque 15 blocs d'unités de calcul, les SMX, 13 seront actifs sur la Tesla K20.
Inattendu par contre, Nvidia aurait également désactivé l'un des 6 contrôleurs mémoire 64-bit du GPU ce qui impliquerait qu'il devrait se contenter de 5 Go de GDDR5 et non de 6 Go comme annoncé au départ. Nous utilisons cependant le conditionnel sur ce point puisqu'il est possible, mais peu probable, que ces spécifications reposent sur des chiffres qui correspondent à l'ECC activé : sur 6 Go, seuls 5.25 Go restent ainsi accessibles dans ce mode.
Les spécifications font état d'une fréquence GPU relativement faible de 705 MHz, ce qui était sans aucun doute nécessaire pour ne pas dépasser le TDP de 225W. En présumant que les spécifications ne prennent pas en compte l'activation de l'ECC, ce n'est en général pas le cas, la mémoire GDDR5 serait ainsi cadencée à 1250 MHz.
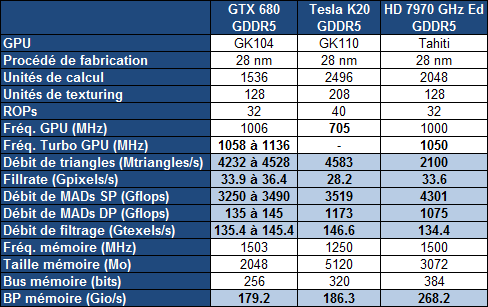
Comme vous pouvez le constater à travers ces quelques chiffres bruts, avec quelques unités désactivées et une fréquence relativement faible, la carte Tesla K20 se situe au niveau d'un exemplaire de GeForce GTX 680 équipé d'un GPU dont le turbo dispose d'une fréquence élevée. La Tesla K20 profite par contre d'une puissance en double précision nettement plus élevée ainsi que de différentes petites évolutions qui permettront de rendre le GPU plus efficace en tant que coprocesseur massivement parallèle.
Ces spécifications laissent cependant penser qu'il sera difficile pour Nvidia de proposer une variante GeForce intéressante du GK110 sans faire exploser le TDP, même si le turbo maison, GPU Boost, permet de laisser la fréquence GPU monter quelque peu dans le TDP défini. Notons que certaines rumeurs laissent d'ailleurs entendre que Nvidia pourrait ne pas utiliser ce GK110 pour sa prochaine GeForce haut de gamme. Au profit d'un GPU moins complexe mais plus hautement cadencé ?
Nvidia lance les Quadro K5000 et Kepler mobiles
La réponse de Nvidia face à l'arrivée de la nouvelle gamme FirePro n'aura pas tardé avec tout d'abord l'annonce de la première Quadro de la génération Kepler. Nvidia ne pouvant pas laisser le champ libre à AMD en attendant l'arrivée du GPU haut de gamme de cette génération, mieux pensé pour le monde professionnel, c'est une déclinaison de l'actuelle GeForce GTX 680 qui verra le jour dans un premier temps.
La Quadro K5000 (Kepler), qui remplace la Quadro 5000 (Fermi), est ainsi basée sur le GPU GK104, avant tout optimisé pour offrir un rendement optimal dans les jeux. En version professionnelle et par rapport à l'ancienne gamme, ce GPU offre des performances graphiques élevées, un très bon rendement énergétique, le support du PCI Express 3.0 et la gestion de 4 écrans. En contrepartie, il n'est pas du tout adapté au calcul en double précision et perd la protection ECC des caches internes, deux points qui seront corrigés par le GK110 début 2013.

La Quadro K5000 dispose de 1536 unités de calcul cadencées à +/- 690 MHz (Nvidia ne communique pas la fréquence exacte) pour une puissance brute de 2.1 Tflops en simple précision qui tombe à 0.1 Tflops en double précision (contre 0.52 Tflops pour la Quadro 6000 et 0.36 Tflops pour la Quadro 5000). Elle est accompagnée de 4 Go de GDDR5 cadencée à 1350 MHz et interfacée en 256 bits pour une bande passante mémoire totale de 160.9 Gio/s. La carte propose deux sorties DVI Dual Link ainsi que deux sorties DisplayPort. Particularité intéressante : elle se contente de 122W, ce qui ravira de nombreux intégrateurs qui préfèrent éviter de passer au-dessus de 150W.
Pour compenser les capacités limitées au niveau du GPU computing de cette Quadro K5000, Nvidia met en avant sa solution Maximus. Pour rappel, il s'agit du nom commercial donné à la possibilité d'associer dans un même système une carte Quadro (graphique pro et compute) et une carte Tesla (compute) tout en continuant à profiter de tous les avantages des pilotes Quadro. L'utilisation de ces pilotes débridés et certifiés pour de nombreuses applications graphiques professionnelles est strictement encadrée par Nvidia puisque ce sont eux qui justifient la tarification des Quadro. Les cartes Tesla, relativement moins chères, sont limitées au support du GPU computing et pouvoir les associer à des Quadro sans que celles-ci ne voient leurs pilotes limités permet de réduire quelque peu le coût de la mise en place de systèmes très performants tant sur le plan graphique que du calcul massivement parallèle, ce qui devient nécessaire pour certaines applications.

N'importe quelle combinaison de Quadro et de Tesla est possible, mais à condition de rester sur une même génération. Nvidia insiste donc sur l'association d'une carte Tesla K20 avec une Quadro K5000 pour former un couple Kepler très polyvalent. Reste que si la Quadro K5000 est prévue pour octobre, il faudra attendre au mieux le mois de décembre pour mettre en place un tel système, la Tesla K20 étant basée sur le GPU GK110 qui n'est pas encore disponible. Question tarification, la Quadro K5000 sera proposée à 2249$ et la Tesla K20 à 3199$ pour un coût total de 5448$. De quoi préfigurer du prix d'une future Quadro K6000 ?
Parallèlement à cette annonce, Nvidia étend sa famille de Quadro mobiles dérivées de l'architecture Kepler. Il y a 2 semaines, la Quadro K5000M avait fait une apparition discrète et est aujourd'hui rejointe par les Quadro K4000M, K3000M, K2000M, K1000M et K500M.
Leurs fréquences n'étant pas communiquées, nous ne disposons que d'une partie de leurs spécifications. La Quadro K5000M est basée sur le GK104 et équipée de 1344 unités de calcul. Il s'agit grossièrement d'une version pro de la GeForce GTX 680M mais dont la fréquence mémoire a été revue à la baisse, probablement pour rester dans le TDP de 100W malgré le passage à 4 Go de mémoire vidéo.
Les Quadro K4000M et K3000M sont probablement basées sur le GK106 : la première se contente de 960 unités de calcul et la seconde de 576. La Quadro K3000M voit également sa mémoire vidéo réduite à 2 Go, ce qui lui permet de tenir dans une enveloppe thermique de 75W.
Les trois autres Quadro mobiles sont pour leur part basées sur le GPU GK107. La Quadro K2000M en exploite une version complète, avec 384 unités de calcul, mais limitée à de la mémoire DDR3 sur 128 bits. Elle correspond à la version pro d'une GeForce GT 650M ou 640M DDR3. La Quadro K1000M est similaire mais voit son GPU bridé à 192 unités de calcul. Un bridage accentué sur la Quadro K500M qui doit également se contenter d'un bus mémoire de 64 bits pour la DDR3.
Toutes ces Quadro mobiles supportent Optimus, qui permet de les éteindre lorsqu'elles ne sont pas utiles sur les systèmes également équipés d'un core graphique intégré de manière à réduire la consommation énergétique des portables. Elles ont d'ores et déjà été intégrées par Dell, Fujitsu, HP et Lenovo dans différentes stations de travail mobiles.
GTC: Tesla passe à Kepler avec les K10 et K20

Nvidia vient de dévoiler deux nouvelles cartes Tesla basées sur l'architecture Kepler. La première, dénommée K10 est en quelque sorte une version Tesla serveur de la GeForce GTX 690. Il s'agit donc d'une carte équipée de 2 GPU GK104 et d'un switch PCI Express 3.0 PLX. Par rapport à la GeForce GTX 690, les fréquences ont bien entendu été revues à la baisse et passent d'une fourchette de 915 à plus de 1100 Mhz (suivant le niveau de turbo) à 745 MHz pour le GPU et de 1500 à 1250 MHz pour la mémoire.
Nvidia semble ainsi avoir laissé de côté GPU Boost, probablement parce que la variabilité qui y est liée n'est pas compatible avec le monde professionnel. La base de la technologie, qui permet de contrôler dynamiquement la fréquence pour maintenir un certain TDP est par contre de toute évidence de la partie, ce qui permet à Nvidia de proposer un TDP relativement faible qui tourne autour de 225-235W, contre 300W pour la GeForce GTX 690.
La K10 est équipée de 4 Go de mémoire GDDR5 par GPU, soit 8 Go au total, et supporte l'ECC, d'une manière similaire à ce qui se fait sur les précédentes cartes Tesla : une partie de la mémoire est utilisée pour stocker les données de parité, ce qui réduit l'espace mémoire disponible ainsi que la bande passante pratique. La puissance de calcul en double précision reste par contre extrêmement faible, tout comme certaines opérations logique ou sur les entiers, le GPU GK104 étant très limité à ce niveau. En d'autres termes, la carte K10 affiche une puissance de calcul en simple précision flottante énorme, de 4577 Gflops et sera donc destinée à ce type de calculs uniquement. En double précision le débit tombe à 190 Gflops.
La seconde carte Kepler annoncée aujourd'hui, la K20 est la plus intéressante des deux puisqu'elle embarquera un GPU GK110 au sujet duquel Nvidia vient de donner les premières informations. Peu de détails sur la K20 sont communiqués à ce jour, ses spécifications ne seront fixées que plus tard dans l'année puisqu'elle est prévue pour le dernier trimestre 2012. Il est cependant probable qu'elle soit équipée d'un GK110 partiellement castré avec 13 blocs d'unités de calcul actifs sur les 15 disponibles pour un total de 2496 de ces unités de calcul. Nvidia indique par ailleurs que ses performances en double précision seront triplées par rapport à la génération actuelle et supérieures à 1 Tflops, ce qui en fera une carte bien plus polyvalente pour le calcul, d'autant plus que son GPU apporte plusieurs innovations importantes pour faciliter son exploitation avec un maximum d'efficacité.
La carte K20 devrait être accompagnée de 6 Go de mémoire GDDR5 et sera disponible avec un TDP de 225W, ce qui est plutôt impressionnant compte tenu de la complexité de ce GPU. Il est probable que Nvidia profite du fait qu'en général les blocs du GPU dédiés au graphique ne seront pas utilisés pour pouvoir compresser le TDP. Nvidia nous précise cependant que si un intégrateur dispose d'une plateforme certifiée pour un TDP plus élevé, la carte K20 pourra s'y adapter pour profiter de la marge supplémentaire. Elle sera par ailleurs disponible en version workstation en plus de la version serveur.
GTC: Nvidia lève le voile sur le GK110

Sans le nommer directement, Jen-Hsun Huang, le CEO de Nvidia, vient de dévoiler les premières informations au sujet du "gros" GPU Kepler, le GK110. Nous avons tout d'abord la confirmation qu'il s'agit bien d'un énorme GPU de pas moins de 7.1 milliards de transistors fabriqués en 28nm, un nouveau record. Certains doutes subsistaient par rapport à ce chiffre puisqu'il correspond presqu'exactement à deux GPU GK104, la configuration de la nouvelle carte Tesla K10, mais ce n'est qu'une coïncidence.
GTC oblige, c'est avant tout son intérêt pour le monde professionnel et particulièrement pour le calcul haute performance qui est mis en avant par Nvidia. Deux nouvelles technologies importantes font leur apparition dans ce GPU. Tout d'abord Hyper-Q qui permet d'utiliser jusqu'à 32 queues d'exécution pour alimenter le GPU, contrairement à une seule auparavant. Une limitation qui empêchait dans bien des cas la pleine exploitation de toute la capacité de calcul des GPU.

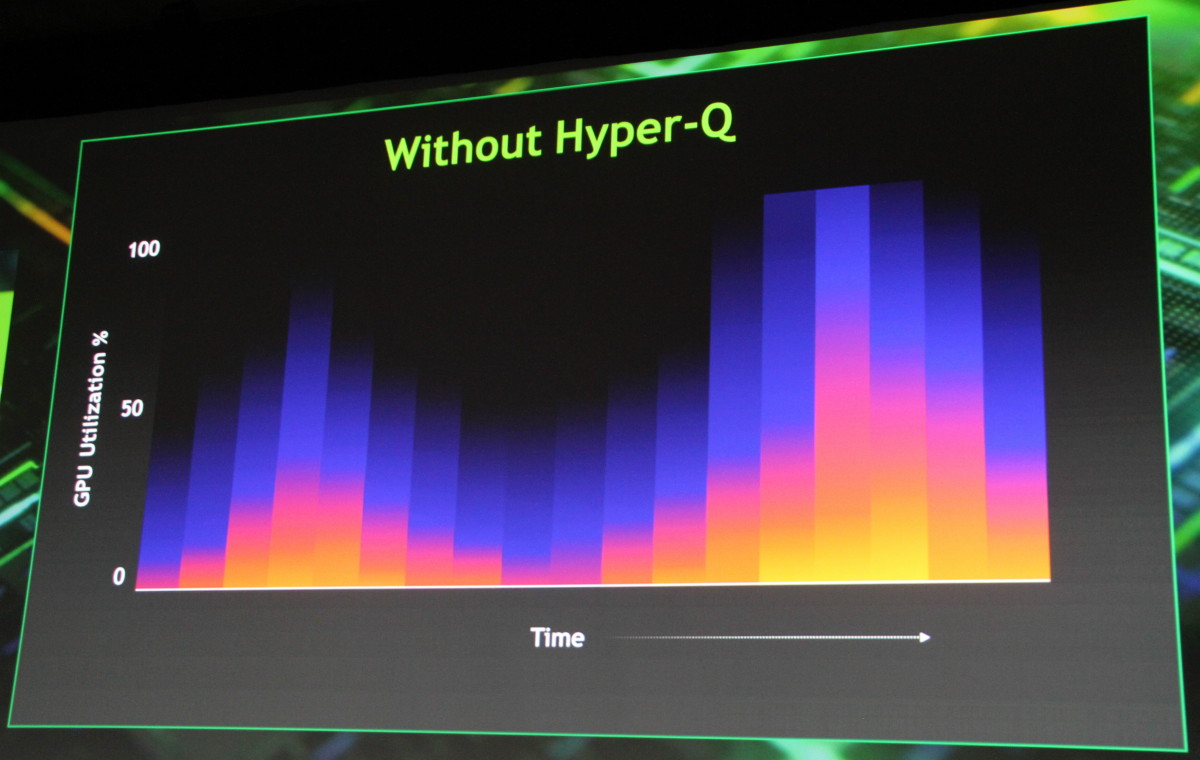
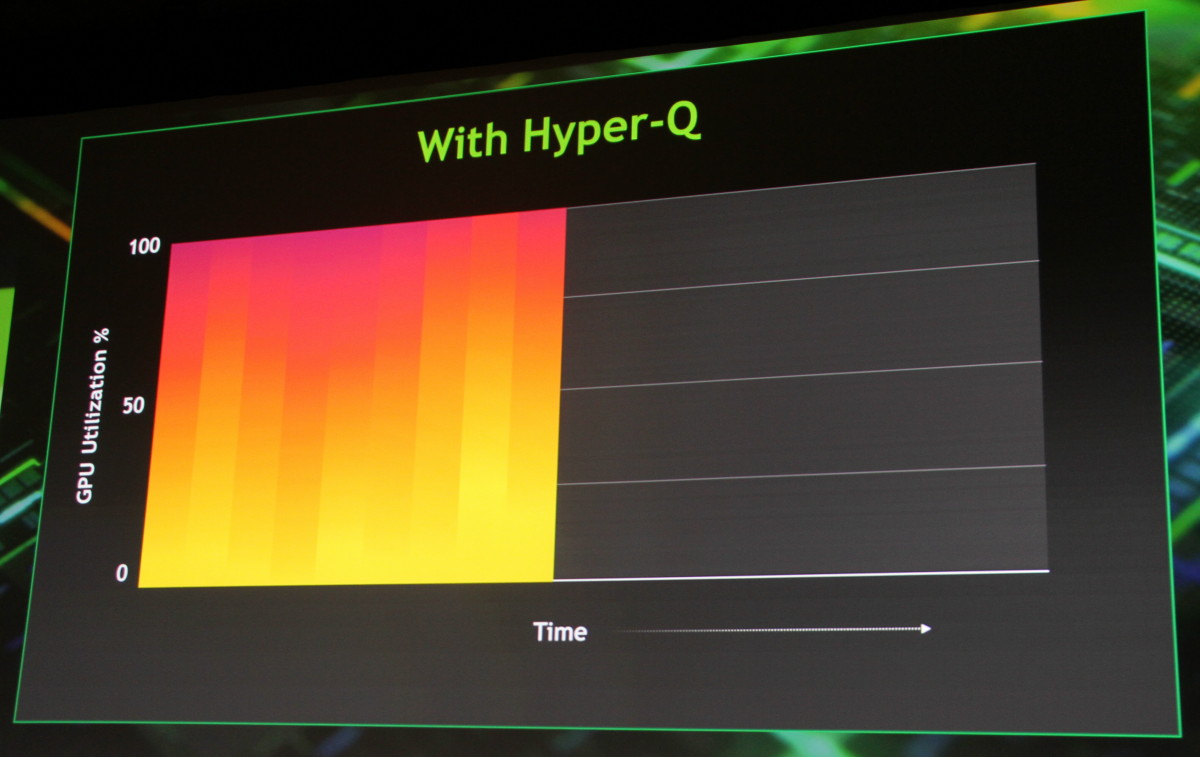
Hyper-Q permet de maximiser le rendement du GPU et de réduire le temps d'exécution.
La seconde innovation se nomme Dynamic Parallelism et vient également apporter une réponse à un problème d'efficacité actuelle. Le travail à exécuter sur le GPU est en général segmenté, et chacun des segments est initié par le CPU. Entre chacun de ceux-ci, le GPU rend ainsi la main au CPU qui reçoit les résultats d'une fonction, et dans certains cas renvoie ces mêmes résultats au GPU pour lancer une seconde fonction qui en est dépendante. L'inefficacité est évidente. Dynamic Parallelism représente la capacité du GK110 à auto-générer de nouvelles tâches, de quoi éviter ces allers-retours entre le CPU et le GPU.

Cette nouvelle flexibilité dans l'exécution des tâches va faciliter le travail des développeurs d'une part en proposant plus simplement un rendement élevé et d'autre part en leur permettant d'écrire leurs programmes d'une façon plus naturelle.

Enfin, Nvidia a dévoilé une photo du die du GK110, certes retravaillée artistiquement mais qui permet de se faire quelques idées sur les spécifications de ce GPU. On peut tout d'abord observer la présence de 15 SMX et d'un contrôleur mémoire de 6x 64 bits, soit 384 bits. Nvidia nous a confirmé ces spécifications et précisé que les SMX du GK110 seront également équipés de 192 unités de calcul, comme pour le GK104. Leur nombre total sera donc de 2880 et là aussi il s'agit d'un nouveau record, même si Nvidia précise qu'il n'y aura en principe pas de dérivé Tesla équipé d'une version complète de ce GPU, profiter d'un certain niveau de redondance étant nécessaire avec un GPU d'une telle taille, plus de 500mm². La première carte Tesla K20 basée sur le GK110 sera probablement limitée à 13 SMX et 2496 unités de calcul.
Nvidia nous a indiqué que l'organisation des registres et de la mémoire partagée avait été revue, et que la puissance de calcul en double précision était très élevée, mais il faudra patienter encore un jour ou deux avant d'avoir plus de détails sur le sous-système mémoire du GK110.
Sur le plan graphique, nous pouvons supposer que chaque SMX conserve 16 unités de texturing et que leur nombre total dans ce GPU est de 240. L'organisation des SMX en 5 groupes de 3 nous laisse penser que le GK110 serait capable de traiter jusqu'à 7.5 triangles par cycle mais de n'en rendre que 5 ou 6 par cycle (suivant l'implémentation pour laquelle a opté Nvidia), contre 4 et 4 pour le GK104. Enfin, de toute évidence il disposera de 48 ROP.
Ce futur GPU sera tout d'abord introduit à la fin de l'année en tant que Tesla K20 mais ne débarquera pas en tant que GeForce avant début 2013. Il sera bien entendu intéressant d'observer la consommation d'un tel monstre, même si Nvidia se veut rassurant en précisant que la carte Tesla K20 est prévue avec un TDP classique de "seulement" 225W !
Nvidia Maximus: Quadro et Tesla s'associent
A l'occasion du SC11 (Supercomputing 2011), Nvidia présente la plateforme Maximus qui permet de combiner une carte Quadro, orientée graphisme professionnel, et une carte Tesla, orientée calcul massivement parallèle, dans un même système. Jusqu'ici ce n'était pas possible, principalement pour des raisons commerciales et pour disposer de la puissance d'un tel système, il fallait acquérir 2 Quadro à prix plein.

Dans la gamme Nvidia, les Quadro représentent le sommet absolu, c'est-à-dire qu'elles ont accès à toutes les fonctionnalités des GPUs et des pilotes contrairement aux GeForce et aux Tesla, moins chères et pour lesquelles plusieurs limitations sont en place, notamment au niveau des optimisations qui concernent les logiciels graphiques professionnels. Impossible dès lors de combiner une Quadro avec une carte de rang inférieur, ce qui reviendrait à l'upgrader au rang de la Quadro ou à brider cette dernière. Deux solutions inacceptables commercialement.
La plateforme Maximus vient résoudre ce problème pour faciliter la commercialisation des cartes Tesla tout en conservant la poule aux ufs d'or que représente la gamme Quadro. Pour cela, les pilotes Tesla et Quadro ont été fusionnés pour permettre la prise en charge dans un même système des deux variantes tout en conservant leurs spécificités, c'est-à-dire que l'accélérateur Tesla n'aura pas accès aux fonctionnalités supplémentaires des Quadro.


Quadro 6000, à gauche, et Tesla C2075, à droite, sont presqu'identiques, si ce n'est au niveau du prix deux fois plus élevé pour la première.
Par défaut, les nouveaux pilotes redirigeront toutes les tâches de type compute (CUDA, OpenCL ) vers la carte Tesla, si elle est présente bien entendu, la Quadro se chargeant uniquement du rendu 3D et de l'affichage. Si une Quadro seule peut s'occuper de l'affichage, de la 3D et du calcul CUDA, cela peut lui faire perdre beaucoup de temps en changements d'état, une limitation importante de l'architecture actuelle des GPUs Nvidia. Qui plus est, l'affichage perd alors en réactivité, ce qui est désagréable à l'usage. Faire traiter la partie compute par une carte dédiée permet de gagner en efficacité et de conserver un affichage fluide en permanence.
Cette plateforme peut également permettre de faire quelques économies quand peu de puissance graphique est nécessaire, en adaptant chaque élément du couple Quadro / Tesla. Ainsi, opter pour une Quadro d'entrée de gamme permettra de ne pas souffrir des limitations imposées aux autres cartes dans les pilotes pour les logiciels professionnels (dans certains cas les performances ne dépendent que de ces pilotes et pas du GPU!), et l'accompagner d'un accélérateur Tesla permettra de disposer d'une puissance de calcul importante sans nuire au confort du système.
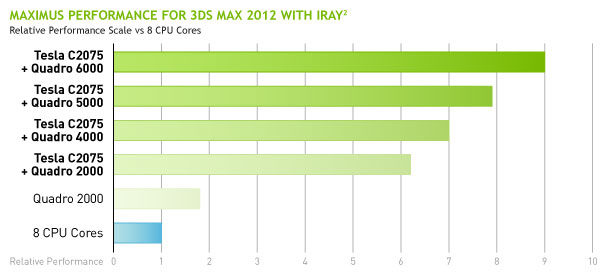
Par exemple une Quadro 6000 6 Go haut de gamme coûte près de 4500 alors qu'un accélérateur Tesla C2075 6 Go similaire ne coûte "que" 2300 et qu'une petite Quadro 600 se négocie pour moins de 200. Maximus permet ainsi de réduire de moitié l'investissement nécessaire pour profiter d'un environnement Quadro et de la puissance de calcul Tesla. Si ce type d'utilisation ne représente qu'une petite niche actuellement, Nvidia espère avec cette approche séduire un plus grand nombre de professionnels, comptant sur l'arrivée de plus en plus de logiciels capables d'exploiter les accélérateurs massivement parallèle tels que Tesla.
Bien qu'il soit toujours possible de définir manuellement le GPU qui sera chargé d'exécuter chaque tâche compute, Maximus dispose actuellement de profils optimisés pour une poignée d'applications, une liste qui devrait s'étendre progressivement :
- Adobe Premiere Pro CS5.5.2
- Autodesk 3ds Max 2012 avec iRay
- Dassault Systèmes CATIA V5/V6 avec SIMULIA Abaqus 6.11-1 ou plus récent
- Dassault Systèmes CATIA V6 Live Rendering avec iRay
- MathWorks MATLAB R2011b avec MATLAB Parallel Computing Toolbox
- SolidWorks 2010 ou plus recent avec ANSYS Mechanical 13.0 SP2 / 14.0
- PTC Creo Parametric 1.0 m010 ou PTC Pro/Engineer 5.0 avec ANSYS Mechanical 13.0 SP2 / 14.0