
Les derniers contenus liés aux tags Kepler et GK110
Afficher sous forme de : Titre | FluxLa GTX Titan Z en retard
GTC: GeForce GTX Titan Z, 3000$, bi-GK110 en avril
Dossier: Nvidia GeForce GTX 780 Ti en test : le GK110 enfin au complet !
Nvidia Quadro K6000: GK110 complet et 12 Go
Dossier: Nvidia GeForce GTX 780 en test : GK110 pour tous (ou presque)
Nvidia lance la Tesla K80: double GK210 avec Boost



Lors de l'annonce d'une nouvelle gamme de Quadro cet été, nous nous étions étonnés de ne pas voir arriver un modèle haut de gamme basé sur un nouveau "gros" GPU Kepler : le GK210. Ce dernier n'est cependant pas passé à la trappe et vient d'être introduit au travers de la nouvelle carte accélératrice Tesla K80.

Après les Tesla K10, K20, K20X et K40, Nvidia introduit le Tesla K80 qui est le second modèle bi-GPU de la famille. Elle embarque en effet deux GK210, une petite évolution des GK110/GK110B exploités sur différents segments depuis deux ans. De quoi pousser les performances un cran plus haut tout en restant sur un même format, mais bien entendu en revoyant les demandes énergétiques à la hausse.
La Tesla K80La Tesla K80 se contente de GPU partiellement fonctionnels, seules 2496 unités de calcul sur 2880 sont actives, ce qui permet de limiter quelque peu la consommation. De quoi atteindre de 5.6 à 8.7 Tflops en simple précision et de 1.9 à 2.9 Tflops en double précision. Pour le reste, le bus mémoire est complet avec 384-bit par GPU pour une bande passante totale qui atteint 480 Go/s.
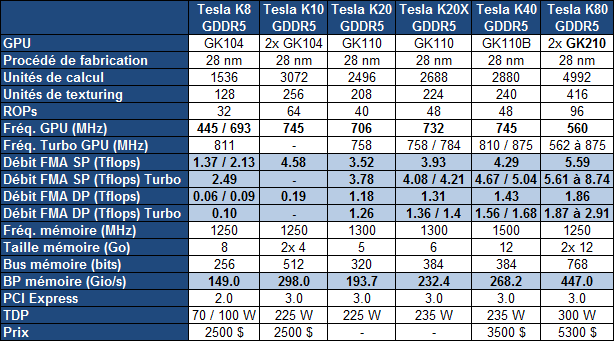
Comme pour les Tesla K40, chaque GPU de la Tesla K80 profite de 12 Go de GDDR5 avec une protection ECC optionnelle qui réduit la bande passante et la quantité de mémoire réellement disponible. Elle est alors réduite de 1/16ème et passe à 11.25 Go par GPU.
Le TDP de cet accélérateur bi-GPU est de 300W, contre 235W pour les Tesla mono-GPU. Une augmentation plutôt contenue liée au fait que le GK210 est un petit peu plus efficace sur le plan énergétique mais surtout à la mise en place d'un turbo dynamique et d'une fréquence de base relativement faible.
Les Tesla précédentes profitaient déjà d'un mode turbo, dénommé GPU Boost comme sur GeForce, mais il était statique et le TDP était défini par Nvidia comme la consommation moyenne du GPU à sa fréquence de base lors de l'exécution d'un algorithme gourmand finement optimisé pour exploiter au mieux le GPU : DGEMM. Si le GPU était exploité pour faire tourner des tâches moins lourdes, ou s'il était particulièrement bien refroidi, il était possible à travers une API spécifique de faire passer manuellement le GPU à un niveau de fréquence supérieur. Par exemple le GPU de la Tesla K40 est cadencé par défaut à 745 MHz, mais il peut être configuré en mode 810 ou 875 MHz et voir sa puissance de calcul bondir de 17%.
Nvidia justifiait l'utilisation d'un turbo statique par la nécessité de proposer un niveau de performances stable et un comportement déterministe, notamment parce que certains clusters font travailler les GPU en parallèle de manière synchrone. Un autre élément était probablement que valider un turbo dynamique était plus complexe dans le monde professionnel que grand public.
Avec la Tesla K80 cela change et par défaut c'est un turbo dynamique qui est activé et qui fonctionne de la même manière que sur les GeForce récentes à ceci près que pour des raisons de sécurité, le GPU débute à sa fréquence de base et accélère progressivement si les limites de consommation (150W par GPU) et de température n'ont pas été atteintes (il part de la fréquence maximale et la réduit sur GeForce). La plage pour ce turbo dynamique est particulièrement élevée, de 562 à 875 MHz, ce qui représente jusqu'à 55% de performances supplémentaires lorsque les tâches ne sont pas très lourdes. C'est bien entendu dans ce type de cas que cette Tesla K80 se démarquera le plus d'une K40. A noter que Nvidia propose toujours, optionnellement, la sélection de manière statique d'un certain niveau de fréquence.

Il s'agit d'un format dédié au serveur et donc passif, pour cette carte de 267mm de long, qui semble reprendre le même PCB que celui de la GeForce GTX Titan Z. Petite nouveauté, la Tesla K80 n'est pas alimentée via des connecteurs PCI Express mais bien via un seul connecteur d'alimentation CPU 8 broches, plus adapté aux serveurs et qui simplifie le câblage (les traces pour ce connecteur sont présentes sur la GTX Titan Z mais il n'a pas été utilisé).
La Tesla K80 est disponible dès à présent à un tarif de 5300$ et a été validée par Cray (CS-Storm, 8 K80 par nud 2U), Dell (C4130, 4 K80 par nud 1U), HP (SL270, 8 K80 par nud 4U half-width) et Quanta (S2BV, 4 K80 par nud 1U). De quoi pousser à la hausse la densité des capacités de calcul et atteindre de 7.5 à 11.6 Tflops en double précision par U suivant la tâche.
A noter que la concurrence n'est pas pour autant larguée. AMD a implémenté une proportion plus élevée d'unités de calcul double précision dans son dernier GPU haut de gamme (Hawaii), ce qui permet à la FirePro S9150 d'afficher un débit similaire à celui de la Tesla K80 et une densité de 10.1 Tflops par U dans le même type de serveurs.
La Tesla K8En octobre Nvidia a discrètement lancé un autre membre dans la famille Tesla : la K8. Celle-ci est en fait équipée d'un GPU Kepler GK104, non-adapté au calcul en double précision. Grossièrement il s'agit de l'équivalent Tesla d'une GeForce GTX 770/680. Le design proposé par Nvidia a la particularité d'être single slot et actif mais est prévu exclusivement pour l'intégration dans un serveur et non dans une station de travail.

Le GPU, qui affiche de 1.4 à 2.5 Tflops en simple précision, est associé à 8 Go de mémoire. Par défaut, il est cadencé à 693 MHz (2.1 Tflops) et affiche un TDP de 100W. Pour les tâches légères il peut être poussé à 811 MHz et il est également possible d'activer un mode 70W dans lequel la fréquence tombe alors à 445 MHz. Par ailleurs, l'interface PCI Express de ce GPU est limitée au PCI Express 2.0 dans le monde professionnel.
GK210, quoi de neuf ?
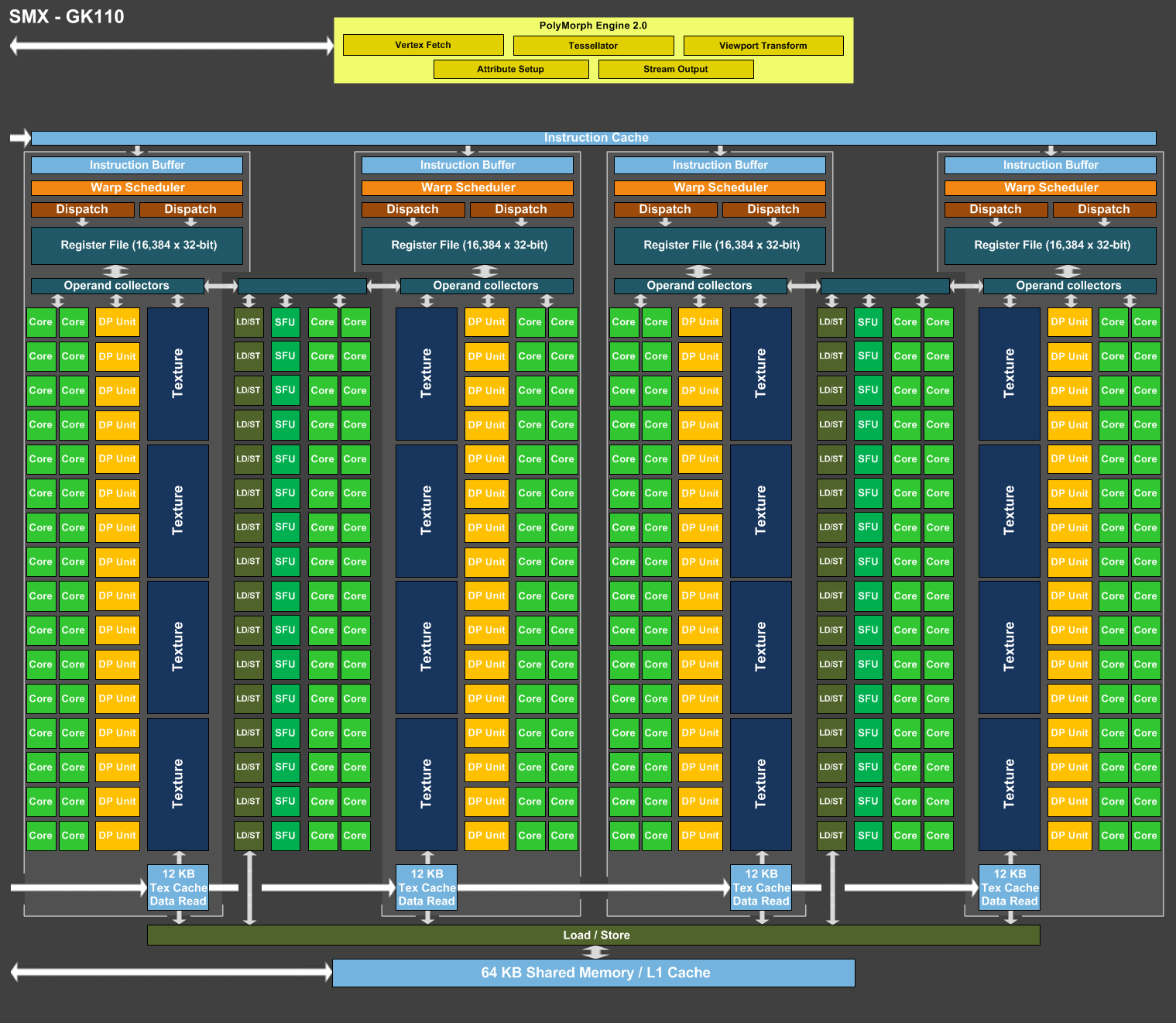
Alors que la génération de GPU Maxwell a pris place dans le haut de gamme grand public, c'est un nouveau GPU de la famille Kepler que Nvidia vient d'introduire dans sa gamme Tesla. Nvidia ne communique que peu de détails sur les évolutions apportées par le GK210 qui reste fabriqué en 28 nanomètres et présente une configuration globale similaire à celle du GK110. Nvidia se contente de préciser que le fichier registre et la mémoire partagée ont été doublés, ce qui dans les deux cas permet de mieux alimenter les unités de calcul du GPU et donc son rendement.
[ GK110 ] [ GK210 ]
Plus en détail, sur le GK110 comme sur tous les autres GPU Kepler, les unités de calcul sont intégrées dans les SMX, les blocs fondamentaux de l'architecture Kepler. Chaque SMX est subdivisé en 4 partitions qui se partagent l'accès aux unités de calcul, dont 192 FMA simple précision et 64 FMA double précision dans le cas des GPU GK110 et GK210. Chacune de ces partitions dispose d'un ordonnanceur et d'un fichier registres indépendant de 64 Ko, ce qui équivaut à 16384 registres 32-bit ou 8192 registres 64-bit. Le GPU étant une machine optimisée pour le débit, ces imposants fichiers registres sont exploités pour s'assurer que suffisamment d'éléments ("threads") puissent résider en interne de manière à ce que leur traitement successif puisque masquer la latence qui peut être très élevée pour certaines opérations.
Bien qu'imposants, ces fichiers registres ne sont pas sans limite et lorsqu'elle est atteinte, le taux d'utilisation des unités de calcul peut chuter fortement. Cela peut arriver quand le code à exécuter a besoin d'un nombre important de registres, quand de nombreuses opérations à latence élevée sont exécutées ou encore en 64-bit, mode deux fois plus gourmand sur ce point. Il peut ainsi s'agir d'un facteur limitant dans le cadre du calcul massivement parallèle et avec le GK210, Nvidia fait évoluer ces fichiers registres qui passent pour chaque partition de 64 Ko à 128 Ko (soit de 256 à 512 Ko par SMX et 7.5 Mo au total à l'échelle du GPU). De quoi s'assurer un taux de remplissage moyen plus élevé et donc de meilleures performances.
Le principe est le même pour le bloc qui regroupe la mémoire partagée et le cache L1. Chaque groupe d'éléments à traiter peut se voir attribuer une certaine quantité de mémoire partagée. Plus la quantité de mémoire partagée nécessaire est élevée, moins de groupes peuvent résider en même temps dans le GPU : la latence peut alors ne plus être totalement masquée ou un algorithme moins efficace, mais exigeant moins de mémoire partagée doit être utilisé, ce qui fait chuter les performances dans les deux cas.
Avec le GK210, Nvidia fait donc évoluer cette mémoire de 64 Ko à 128 Ko par SMX, mais, détail important, la totalité de la mémoire supplémentaire est attribuée à la mémoire partagée. Ainsi, alors que la répartition L1/mémoire partagée pouvait être sur GK110 de 16/48 Ko, 32/32 Ko ou 48/16 Ko, elle pourra être soit de 16/112 Ko, soit 32/96 Ko, soit de 48/80 Ko sur GK210 (suivant la quantité de L1 jugée nécessaire par le compilateur). En d'autres termes, la mémoire partagée sera en pratique de 2.33x à 5x supérieure sur ce nouveau GPU, ce qui pourra apporter un net gain de performances pour certaines tâches. Pour rappel sur les GPU Maxwell de seconde génération, la mémoire partagée n'est plus liée au L1 et est de 96 Ko.
Contrairement à ce que nous supposions au départ face à l'absence de réponse de Nvidia à cette question, le GK210 ne reprend pas la modification apportée aux autres GPU de la lignée GK2xx par rapport à la lignée GK1xx : la réduction de moitié du nombre d'unités de texturing. Un compromis qui permet de réduire la taille des SMX avec un impact sur les performances lors du rendu 3D, mais qui n'a pas été retenu dans le cas du GK210 qui conserve ses 240 unités de texturing, soit 16 par SMX. De quoi lui permettre de conserver l'ensemble de 4 petits caches de 12 Ko spécifiques aux unités de texturing (48 Ko par SMX). Ces derniers peuvent être déviés de leur rôle principal pour faire office de cache en lecture très performant.
Du côté grand public, ce GPU GK210 n'aura peut-être aucune existence et dans tous les cas un intérêt limité étant donné que les GPU de la nouvelle génération Maxwell y sont déjà commercialisés et sont plus performants et plus évolués sur le plan des fonctionnalités. Il permet par contre à Nvidia de proposer un GPU plus efficace dans le domaine du calcul massivement parallèle et pourrait bien être le premier GPU conçu spécialement pour cet usage. Dans tous les cas, Nvidia a de toute évidence stoppé la production de puces GK110B et, si nécessaire, pourra simplement remplacer le GK110/110B par un GK210 sur n'importe lequel de ses produits.
Reste que le timing de son arrivée peut évidemment sembler étrange. Pourquoi concevoir et introduire fin 2014 un nouveau GPU de l'ancienne architecture Kepler, alors que l'architecture Maxwell est déjà disponible ? Et qu'un plus gros GPU Maxwell, le GM200, est attendu ? Il peut y avoir plusieurs raisons à cela et deux d'entre elles nous paraissent les plus probables : soit le GM200 est très loin d'être prêt à être commercialisé, soit le GM200 n'est pas un GPU adapté au monde du HPC, par exemple parce qu'il ne serait pas équipé pour le calcul double précision.
Rien ne dit qu'il faille y voir une quelconque confirmation, mais cette seconde possibilité ne serait pas incompatible avec les roadmaps présentées par Nvidia. En mars 2013, la roadmap faisait état de l'évolution du rendement énergétique en double précision en passant de Kepler à Maxwell et enfin à Volta. En mars 2014, l'unité utilisée par Nvidia était cette fois du calcul en simple précision et une architecture Pascal, clairement pensée pour le monde du HPC, a été intercalée entre Maxwell et Volta. Ceci dit, il nous semble difficile d'imaginer Nvidia se contenter du GK210 en 2015, et de patienter jusqu'à l'arrivée de Pascal en 2016 pour proposer une évolution plus importante sur ce marché
Nvidia lance les Quadro K5200, K4200, K2200, K620, K420
Comme c'est souvent le cas lors du Siggraph, Nvidia a annoncé de nouvelles cartes graphiques professionnelles, dans la gamme Quadro. Pas de nouveauté majeure au menu, mais une augmentation de la puissance de traitement et de la mémoire vidéo à tous les niveaux tarifaires.
Commençons par ce qui ne change pas : le top de la gamme reste pour l'instant la Quadro K6000, dévoilée l'été passé. Nous nous attendions pourtant à du neuf puisque Nvidia a dans ses cartons un nouveau gros GPU Kepler, le GK210. Il n'y a aucune communication officielle à son sujet mais le kit de développement CUDA et divers documents y ont fait référence en parlant d'une hausse des performances par watts et de la quantité de mémoire partagée. Cette mémoire interne au GPU est exploitée lors du calcul intensif pour que les nombreux threads puissent communiquer entre eux.
Nous ne savons pas pourquoi une nouvelle Quadro basée sur ce GPU n'a pas été annoncée. Il est par exemple possible que Nvidia ait finalement décidé d'attendre un GPU de la génération Maxwell ou de réserver le GK210 à la gamme Tesla, pourquoi pas avec une annonce lors du salon SuperComputing 2014 (SC14) qui aura lieu au mois de novembre.
Ceci étant dit, tout le reste évolue et les Quadro K5000, K4000, K2000, K600 et 410 sont remplacées avantageusement par les Quadro K5200, K4200, K2200, K620 et K420 qui sont proposées à des tarifs similaires à ceux des anciens modèles.

De gauche à droite, les Quadro K420, K620, K2200, K4200, K5200 et K6000.
La Quadro K5000, à base de GPU GK104, laisse sa place à une Quadro K5200 basée sur un GPU GK110 plus musclé même si une partie de ses unités de calcul et de son interface mémoire a été désactivée. Une manière de laisser un net avantage à la Quadro K6000, basée sur le même GPU, mais également d'en réduire significativement la consommation. La Quadro K5200 se contente ainsi de 150W, soit seulement 25W de plus pour une puissance de calcul en hausse de 40%. Nvidia en a profité pour faire passer la mémoire embarquée de 4 à 8 Go de GDDR5.
Par rapport à la concurrence, elle se positionne en face de la FirePro W8100, également commercialisée à +/- 2200 et qui affiche une puissance de calcul ainsi qu'une bande passante mémoire nettement plus élevée. Contrairement à AMD, Nvidia a fait le choix de ne pas activer le calcul rapide en double précision sur cette Quadro K5200. Cela s'explique en grande partie parce que Nvidia dispose d'une gamme d'accélérateurs Tesla dédiés à ce type de calcul.
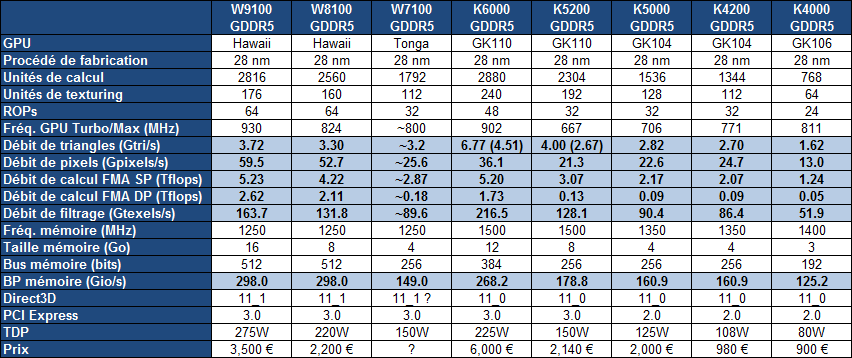
Ensuite, la Quadro K4200 peut être vue comme un glissement vers le bas de la Quadro K5000. Les spécifications sont presque identiques entre les deux, cartes, l'une disposant de quelques unités de calcul de plus, l'autre d'une fréquence plus élevée. La consommation maximale baisse de 125 à 108W, le tarif chute de 2000 à 980 et le format passe du double au simple slot. Par conséquent, elle doit se contenter d'une seule sortie DVI accompagnée de 2 sorties DisplayPort alors que la Quadro K5000 profitait d'une sortie DVI de plus. Un adaptateur est cependant fourni pour compenser cette différence.
Par rapport à la Quadro K4000, la puissance de calcul est en nette hausse : +67%. C'est la FirePro W7100, dont la disponibilité est attendue dans le courant de l'automne, qui devrait se positionner directement en face de cette Quadro K4200.
A noter que les Quadro K5200 et K4200 sont compatibles avec les modules SDI et Sync, elles sont d'ailleurs également proposées en kits avec ceux-ci. Un des connecteurs SLI de la carte est exploité pour connecter ces extensions. Le module Sync permet de synchroniser des entrées et sorties vidéos, par exemple pour mettre en place un mur d'écrans.

La Quadro K4200 associée au kit Sync.
Plus bas dans la gamme, les Quadro K2200 et K620 sont les premières Quadro basées sur l'architecture Maxwell (GPU GM107), plus efficace sur le plan énergétique que Kepler (68 et 45W) et capable de s'approcher plus facilement de ses débits bruts maximaux.
Par rapport à la Quadro K2000, grâce au gain d'efficacité, la K2200 double les performances pratiques en calcul et profite d'une mémoire en hausse de 2 à 4 Go. De son côté, la Quadro K620 double la puissance de calcul brute par rapport à la K600 et profite de 2 Go de mémoire au lieu de 1 Go. Les Quadro K2200 et K620 sont proposées respectivement à 520 et 190.
Enfin, la petite Quadro K420 revient sur l'architecture Kepler. Il s'agit à peu de choses près d'une Quadro K600 renommée, ses spécifications sont similaires si ce n'est que Nvidia autorise dorénavant le pilotage de 4 écrans (via hub DisplayPort), comme sur toutes ses autres Quadro, alors que précédemment les Quadro K600 et 410 étaient limitées à 2 écrans. La puissance de traitement de ce dernier modèle est très faible. Pour faire simple il faut le voir comme un ticket d'entrée pour pouvoir profiter des pilotes professionnels de Nvidia.
Nvidia met d'ailleurs en avant la qualité de ses pilotes en insistant sur leur fiabilité éprouvée et une certification pour un large panel d'applications. Alors que la concurrence est plutôt agressive sur le plan des spécifications et des performances brutes, Nvidia compte sur ses pilotes et leur réputation pour maintenir sa très large avance au niveau des parts de marché dans le monde graphique professionnel.
Dossier : Nvidia GeForce GTX Titan Z : la carte graphique à 3000 en test
Nous avons enfin pu mettre la main sur la GeForce GTX Titan Z, la dernière carte bi-GPU de Nvidia, proposée à 3000. Comment se comporte-t-elle face à la Radeon R9 295 X2 ? Sur le plan des performances ? Des nuisances sonores ?
[+] Lire la suite

La GTX Titan Z est là, prix et specs confirmée
Comme prévu, Nvidia vient d'annoncer sa GeForce GTX Titan Z. Rien n'a changé par rapport aux spécifications dévoilées par ASUS fin avril, on retrouve donc deux GK110 complets, c'est-à-dire avec chacun 15 SMX, 2880 unités de calcul simple précision et 960 unités de calcul double précision qui ne sont pas bridées côté fréquence (comme sur la TITAN Black).

Le TDP est donc de 375W pour une fréquence GPU variant entre une fréquence de base de 705 MHz et un Boost à 876 MHz, ce qui est logiquement inférieur à celle d'une TITAN Black (890-980 MHz). Les 2x6 Go de GDDR5 fonctionnent par contre à la même vitesse soit 1750 MHz.
Les boutiques commencent à référencer les cartes, toutes basées sur le design de référence, chez ASUS, Gigabyte et MSI notamment, avec un tarif qui varie entre 2900 et 3000 soit plus du triple d'une TITAN Black. On leur souhaite bonne chance pour les vendre !
La GeForce GTX Titan Z pour mercredi
Annoncée lors de la GTC fin mars, la GeForce GTX Titan Z devait être lancée en avril mais son lancement initialement prévue le 29 avril avait été reporté. C'est désormais ce mercredi 28 mai que la GeForce GTX Titan Z devrait débarquer au prix astronomique de 3000$.
Pour rappel cette carte intègre deux GPU GK110 complets associés chacun à 6 Go de GDDR5. Le TDP serait de 375 watts, d'où des fréquences GPU logiquement revues à la baisse par rapport à une GeForce GTX TITAN Black au TDP de 250 watts avec un seul GK110.