
Les contenus liés aux tags CUDA et Tesla
GK110 : Nvidia lance les Tesla K20 et K20X
Computex : Nvidia mise sur GPU Computing
Nvidia lance Tesla
GK110 : Nvidia lance les Tesla K20 et K20X
A l'occasion de la conférence SC12, dédiée aux supercalculateurs et technologies liées, Nvidia annonce la disponibilité commerciale de l'accélérateur Tesla K20 dont nous vous avions déjà parlé. Cette carte embarque un GPU GK110 qui reprend l'architecture Kepler déjà en place sur les GeForce GTX 600 mais légèrement retouchée pour faciliter l'exploitation du GPU en tant qu'accélérateur.

Le GPU GK110 et ses 7.1 milliards de transistors.
Parmi les avancées citons une capacité de traitement en double précision très élevée, un texture cache plus flexible et surtout un processeur de commande plus évolué. Il est capable de gérer jusqu'à 32 files d'attente d'exécution pour mieux exploiter la capacité du GPU à exécuter plusieurs tâches concurrentes, ce que les GPU Nvidia précédents avaient du mal à faire en pratique. Il est également capable d'auto-générer des tâches, ce qui évite des allers-retours incessants avec le CPU qui réduisent l'efficacité réelle de l'accélérateur.
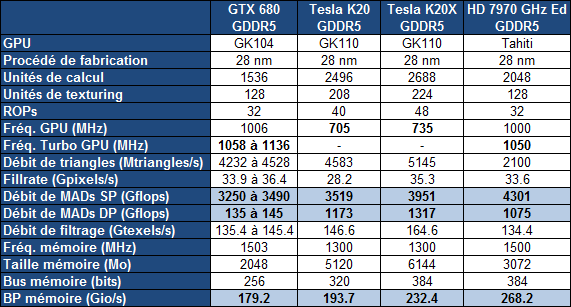
Par rapport à nos précédentes informations, les spécifications de la Tesla K20 sont confirmées, si ce n'est au niveau de la mémoire où elles évoluent très légèrement. Elle est donc bien basée sur un GK110 castré qui se contente de 13 blocs d'unités de calcul, SMX, sur les 15 physiquement présents sur la puce. Il en va de même pour les contrôleurs mémoire dont seulement 5 des 6 sont exploités, ce qui limite la mémoire de la Tesla K20 à 5 Go (4.38 Go avec ECC actif).
Petite surprise, Nvidia lance également une Tesla K20X. Le GK110 qu'elle embarque profite cette fois bien de 14 SMX, pour se rapprocher des 4 Tflops, ainsi que de ses 6 contrôleurs mémoire qui disposent donc de 6 Go de GDDR5 (5.25 Go avec ECC actif). C'est en réalité cette Tesla K20X qui prend place dans le supercalculateur Titan et nous pouvons imaginer que Nvidia a dû sortir 2 variantes de la K20 d'une part pour respecter le cahier de charge au niveau de ce supercalculateur et d'autre part pour disposer d'une production suffisante. Fabriquer un GPU de 7.1 milliards de transistors en 28 nanomètres reste un défi !
Avec plus d'unités de calcul et une fréquence légèrement supérieure, la Tesla K20X ne peut se contenter du TDP de 225W de la Tesla K20. Nvidia a cependant pu le limiter à une valeur proche : 235W. Il nous a par ailleurs été confirmé qu'une technologie de contrôle de la consommation similaire au GPU Boost des GeForce GTX 600 était bien présente sur cette carte et qu'elle pourrait éventuellement être personnalisée par certains fabricants de stations de travail et de serveurs, soit pour adapter la limite de consommation, soit pour activer sa composante turbo.

La Tesla K20 sera disponible en version workstation (refroidissement actif) ainsi qu'en version serveur (refroidissement passif) alors que la Tesla K20X n'existera que dans cette dernière version. Au moins deux formats serveurs sont proposés par Nvidia : carte PCI Express "classique" telle qu'illustrée ici ou SXM, similaire au MXM des cartes graphiques mobiles.

La disponibilité des Tesla K20 et K20X est annoncée pour la fin de ce mois avec un tarif de 3200$ pour la première alors qu'il faudra compter 5000$ pour la seconde. Des tarifs nettement plus élevés que sur la génération précédente qui laissent penser que, pour Nvidia, l'adhésion de l'industrie du calcul haute performance à ces accélérateurs massivement parallèles est désormais inéluctable. Nvidia compte sur un écosystème CUDA relativement répandu et réputé pour faire face à la concurrence des FirePro S d'AMD et des Xeon Phi d'Intel.
Computex : Nvidia mise sur GPU Computing



Le fabricant de GPUs a tenu une première conférence, avant l'ouverture officielle du Computex, qui était principalement tournée sur le GPU Computing.
Nvidia a pu annoncer l'arrivée chez SuperMicro d'un serveur équipé d'une plateforme Intel et d'accélérateurs Tesla offrant 2 teraflops en occupant seulement 1U. Les solutions proposées par Nvidia tiennent également dans 1U mais n'embarquent que les GPUs et doivent donc être liée à un serveur maître. La solution de SuperMicro présente donc un intérêt important même si nous n'en connaissons pas encore les spécifications exactes. Tout au juste pouvons nous déduire des 2 teraflops qu'elle sera équipée du côté GPU de 2 GT200b.

Jen-Hsun Huang, President & CEO, Nvidia.
Du côté grand public, Nvidia s'est félicité du nombre croissant d'applications capables de tirer partie du GPU en tant que coprocesseur parallèle tout en précisant que ce n'était qu'un début puisque l'arrivée de DirectX 11 et de Windows 7 devrait accélérer la tendance. Le premier permettra d'exploiter les GPUs (y compris les versions actuelles !) d'une manière standardisée à travers les Compute Shaders. Le second, en plus d'inclure DirectX 11 à sa base, intégrera un transcodeur capable d'exploiter les GPUs, à travers les Compute Shaders, pour accélérer la conversion des vidéos.

Microsoft et Nvidia mettent en avant la prise en charge native du GPU dans Windows 7 pour accélérer le transcodage vidéo.
Grâce à CUDA, Nvidia a pris une nette avance sur la concurrence du côté du GPU Computing puisque le fabricant est prêt depuis longtemps du côté logiciel. Si à l'avenir tous les composants devraient être supportés, dans l'immédiat, l'avance prise du côté logiciel permet aux GeForce de profiter de la primeur de ces accélérations dans quelques applications principalement dédiées au traitement des vidéos. Il en va de même avec PhysX qui offre aux GeForce le premier support matériel pour la physique d'effets.
Pour appuyer sa vision Nvidia a cependant recours à des artifices grossiers dont la société use et abuse et qui finissent par transformer un sujet intéressant en caricature de communication. Par exemple pour convaincre la presse que le GPU en tant que coprocesseur est l'avenir du PC, l'argument de Jen-Hsun Huang, CEO de Nvidia, est de dire que tout le monde affirme que c'est le cas. Sous-entendu « vous la presse devez écrire la même chose pour ne pas avoir l'air ridicule ». Autre exemple, quand Nvidia nous fait la démonstration d'un jeu avec effets physiques accélérés par le GPU, le volume sonore est réduit de moitié lorsque ces effets sont désactivés, pour accentuer la sensation de perte d'immersion.
Mais ce qui nous ennuie le plus, c'est la simplification qui consiste à présenter un élément d'une unité de calcul vectorielle des GeForce comme étant un core. Une simplification qui devient de plus en plus tordue à mesure que les GPUs et les CPUs s'affrontent. Si la rhétorique de Nvidia est acceptée, alors un CPU quadcore devrait être vu comme composé d'au moins 16 cores compte tenu de ses unités vectorielles. Tout le monde crierait alors au ridicule et à raison. Nvidia est cependant coincé puisqu'après avoir utilisé à la base de son marketing les cores de cette manière il est difficile de revenir en arrière. Comment dire maintenant que le GT200 est en fait composé de 10 voire 30 cores et non pas de 240 ?
Nvidia lance Tesla
 C'est aujourd'hui que Nvidia a décidé de dévoiler une toute nouvelle gamme de produit : Tesla. Après la gamme GeForce destinée au grand public et aux joueurs, la gamme Quadro destinée au professionnel de l'image, la gamme Tesla s'attaque au marché de la puissance de calcul.
C'est aujourd'hui que Nvidia a décidé de dévoiler une toute nouvelle gamme de produit : Tesla. Après la gamme GeForce destinée au grand public et aux joueurs, la gamme Quadro destinée au professionnel de l'image, la gamme Tesla s'attaque au marché de la puissance de calcul.
Nvidia concrétise ainsi son initiative lancée avec la GeForce 8800 et CUDA, la composante qui permet d'exploiter le GPU en tant que coprocesseur mathématique via des extensions au langage C. AMD, via ATI, a été le premier à annoncer une telle interface avec la CTM, en assembleur cette fois, et a également été le premier à annoncer un produit spécifique à ce marché avec le Stream Processor. Reste qu'en dehors de ces annonces et des démos réalisées par AMD, nous n'avons encore rien vu de concret, le tout étant toujours réservé à une poignée de développeurs, la CTM n'étant pas publique et les nouveautés annoncées avec les Radeon HD 2000 toujours en développement
De son côté, Nvidia a publié une version beta de CUDA (0.8) en février et nous a fourni une version plus avancée (0.9) avant la sortie de la version 1.0 prévue pour la semaine prochaine. Nous avons ainsi pu constater que la composante logicielle a fortement évolué. Par ailleurs, nous avons pu voir de nombreuses exploitations réelles du GPU démontrées par différentes sociétés lors de la présentation de Tesla il y a quelques semaines, preuve que CUDA est maintenant réellement utilisable.
Dans un premier temps, Nvidia annonce 3 produits. Le premier, le Tesla C870 est en quelque sorte une GeForce 8800 GTX dépourvue de sorties vidéo et donc destinée uniquement à servir d'accélérateur. La carte est par ailleurs équipée de 1.5 Go de mémoire vidéo au lieu de 768 Mo. Son prix est fixé à 1299$ ce qui reste raisonnable puisqu'une Quadro FX 5600 équipée elle aussi de 1.5 Go de mémoire coûte 2999$. La TDP est de 170W.

Le second élément de la gamme est le Tesla D870 qui reprend le concept des Quadro Plex. 2 cartes Tesla C870 prennent ainsi place dans un boîtier externe qui se raccorde au PC via une carte PCI express spéciale ainsi qu'un câble adapté. La TDP passe à 350W et le prix fait un bond à 7500$ ce qui reste malgré tout "bon marché" face au Quadro Plex de Quadro équivalentes proposé à 17500$. 2 de ces boîtiers peuvent prendre place dans une baie et occupent alors ensemble 3U.

Enfin le 3ème produit de la gamme est un rack 1U, le Tesla S870, équipé de pas moins de 4 Tesla C870, soit 4 G80 et 6 Go de mémoire vidéo en tout. Le rack se connecte à un système principal également en PCI Express et est déjà prêt pour le PCI Express 2.0 et ainsi booster les transferts entre le ou les CPU et les GPUs. La TDP est de 800W bien que Nvidia annonce une consommation qui en pratique se situe en général autour de 550W. Ce rack 1U est commercialisé au prix de 12000$.

Nvidia est donc paré pour essayer de s'introduire sur le marché de la puissance de calcul et concrétise ainsi la longueur d'avance prise sur AMD au niveau de la partie logicielle.
Concernant la stratégie à plus long terme de CUDA, Nvidia nous rassure sur le fait qu'il restera proposé sur toute la gamme de produits, Quadro et GeForce et ne sera pas réservé aux Tesla. CUDA devrait d'ailleurs bientôt faire partie intégrante des drivers grand public. Cependant, à l'avenir, certaines fonctions de CUDA ou des futurs GPUs pourraient être réservées à Tesla. Ce sera notamment le cas de la précision de calcul de 64 bits sur les flottants qui sera introduite avec le G92 et réservée aux Tesla (et à quelques Quadro haut de gamme).
Plus de détails dans un petit article qui sera publié prochainement