Les derniers contenus liés aux tags CrossFire et DirectX 12
Pilotes AMD Radeon Software 16.10.2
Pilotes AMD Radeon Software 16.9.1
GDC: D3D12, multi-GPU et frame pipelining
DirectX 12 supportera un mix de GPU
Pilotes AMD Radeon Software 16.10.2



 AMD vient de mettre en ligne une nouvelle version de ses pilotes Radeon Software dédiés à ses cartes graphiques. Cette version 16.10.2 apporte des optimisations pour les jeux Battlefield 1, Civilization VI, Titanfall 2, Serious Sam VR et Eagle Flight VR. Un profil Crossfire pour Civ VI en mode DX11 est également inclus et celui pour Battlefield 1 a été mis à jour.
AMD vient de mettre en ligne une nouvelle version de ses pilotes Radeon Software dédiés à ses cartes graphiques. Cette version 16.10.2 apporte des optimisations pour les jeux Battlefield 1, Civilization VI, Titanfall 2, Serious Sam VR et Eagle Flight VR. Un profil Crossfire pour Civ VI en mode DX11 est également inclus et celui pour Battlefield 1 a été mis à jour.
Des bugs ont également été corrigés, comme certains cas ou la vitesse des ventilateurs restait élevée sur les Radeon RX400 après avoir quitté une application graphique, ou des incompatibilités pour les jeux DirectX 12 avec des processeurs ne disposant pas des instructions x86 popcnt (introduites respectivement à partir de Nehalem et Barcelona). Des crash sous Gears of War 4 ont aussi été résolus pour ceux qui jouent dans des résolutions graphiques élevées.
Les pilotes sont disponibles directement sur le site d'AMD .
Pilotes AMD Radeon Software 16.9.1
AMD a mis en ligne une nouvelle version de ses pilotes pour cartes graphiques, les 16.9.1. Cette nouvelle version apporte des optimisations pour le mode DirectX 12 de Deus Ex : Mankind Divided. Le patch DX12 pour ce jeu est pour rappel attendu aujourd'hui.
Le constructeur rajoute également un profil Crossfire pour DOTA 2 en mode DX11. Des bugs ont été corrigé du côté des écrans 144 Hz qui pouvaient montrer par intermittence des clignotements en jeu ou sur le bureau Windows, à la fois pour les écrans FreeSync et ceux qui en sont dépourvus. Des crashs ont été résolus sous GTAV et DOOM, ainsi que des clignotements en mode high/ultra sous Dirt Rally. Un bug particulièrement gênant de charge GPU élevée en sortie de veille a également été corrigé.
Vous pourrez retrouver plus de détails et les liens pour télécharger la version adéquate des pilotes pour votre système d'exploitation sur le site d'AMD .
GDC: D3D12, multi-GPU et frame pipelining
Lors de la journée de la GDC consacrée aux tutoriaux liés à DirectX 12, organisée par AMD et Nvidia, c'est ce dernier qui s'est chargé de présenter la partie multi-GPU et de distiller des conseils d'utilisation réalistes pour le nouveau mode explicite. Les combinaisons exotiques laissées de côté, c'est le frame pipelining sur base d'une configuration de GPU identiques qui est mis en avant.
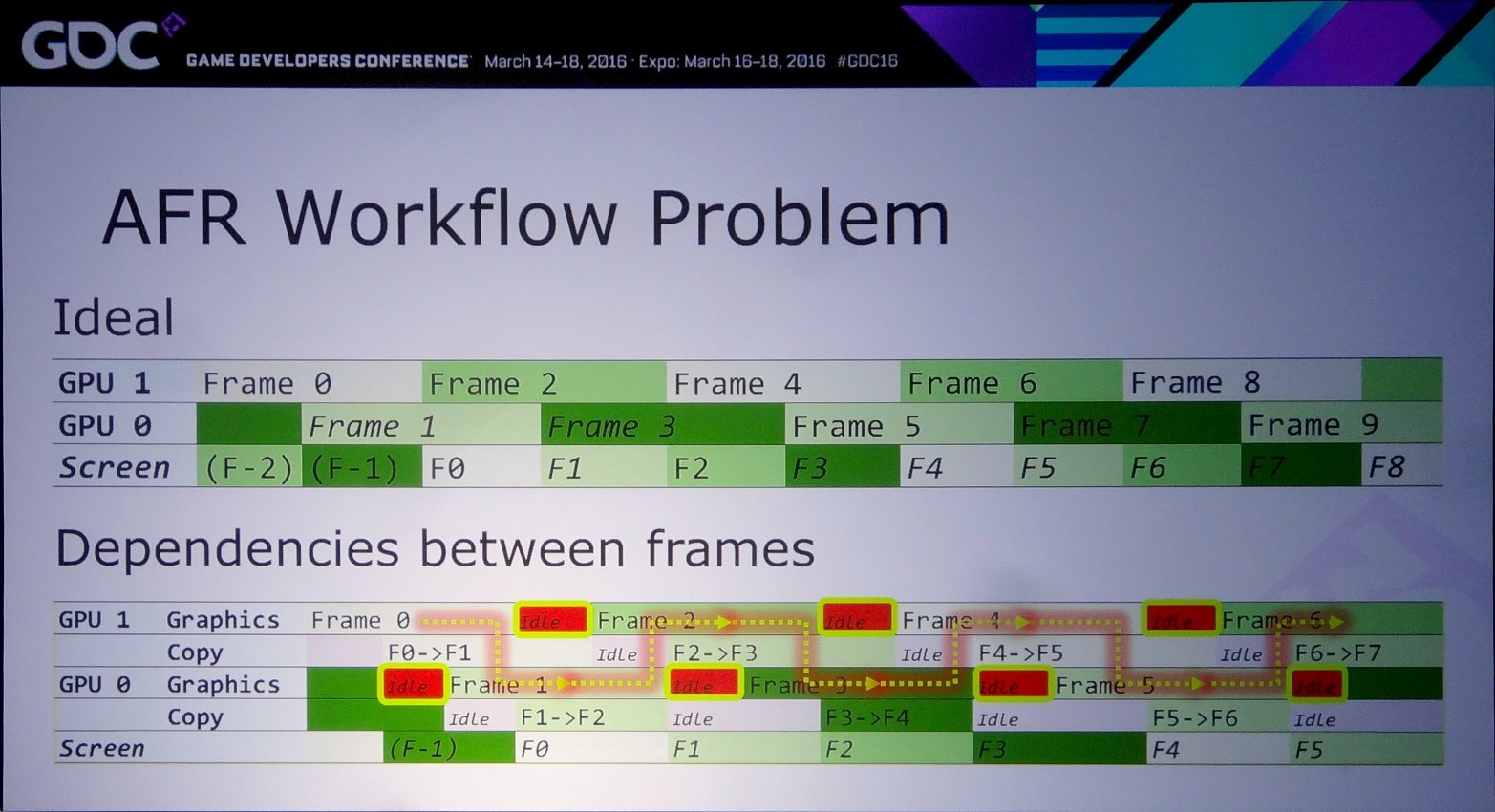
L'an passé, Microsoft a annoncé avoir intégré à DirectX 12 un support explicite très flexible pour le multi-GPU. Pour rappel, la nouvelle API conserve tout d'abord un mode implicite, similaire au SLI et CrossFire sous DirectX 11. Avec ce mode les pilotes sont censés se charger en toute transparence de donner vie au multi-GPU via le mode AFR.
Mais comme l'explique Nvidia, entre la théorie et la pratique il y a un gouffre et dans de plus en plus de cas le multi-GPU ne fonctionne pas, ou avec de très faibles performances, notamment quand des techniques de rendu dites "temporelles" sont exploitées. Celles-ci englobent toute approche qui a besoin de données issues d'images précédentes pour en calculer une nouvelle, par exemple certains filtres d'antialiasing. Vu que ces images précédentes ont été calculées par un autre GPU, ces données ne sont pas facilement accessibles.
Pour résoudre ce type de problème, et bien d'autres, DirectX 12 supporte une gestion explicite du multi-GPU. Cette fois il ne fonctionne plus automatiquement et il revient aux développeurs de prévoir leur moteur pour qu'il prenne conscience du nombre de GPU et les contrôle explicitement. Plusieurs possibilités existent alors.
Celle qui a fait le plus parler d'elle est le mode explicite non-lié (unlinked) qui permet d'associer tout type de GPU, de marques différentes, de génération différente et de niveau de performances différent. C'est le mode qu'a choisi d'implémenter Oxide dans Ashes of the Singularity, probablement pour pousser le plus loin possible ses expérimentations avec la nouvelle API, mais ce n'est pas celui qui va intéresser la majorité des développeurs, celui-ci impliquant la prise en compte de trop nombreuses combinaisons. Le multi-GPU est une niche du marché PC, ce qui implique que ce n'est pas sur ce point que les développeurs veulent investir le plus de temps en implémentation et en validation.

Reste alors le mode explicite à noeud lié (linked node), un noeud représentant un ensemble de GPU activé au niveau des pilotes. Autant AMD que Nvidia exposent un tel noeud dès que le CrossFire ou le SLI sont enclenchés dans leurs panneaux de contrôle. Attention, cela ne veut pas dire que le multi-GPU fonctionnera automatiquement ! Tout le contrôle reste dans les mains des développeurs mais ils ont alors l'assurance d'avoir affaire à des GPU identiques ou similaires, ce qui simplifie leur travail. Tout du moins pour le moment puisqu'il n'est pas impensable qu'AMD et Nvidia autorisent des noeuds hétérogènes dans le futur.
Ce mode explicite lié donne également accès à un lien dédié éventuel, soit au point SLI dans le cas des GPU Nvidia, AMD ayant abandonné le lien CrossFire au profit exclusif du PCI Express. Cet accès spécial n'est cependant exploité que si le multi-GPU implémenté est de type AFR. Le reste des transferts se fait via le bus PCI Express mais directement de GPU à GPU.
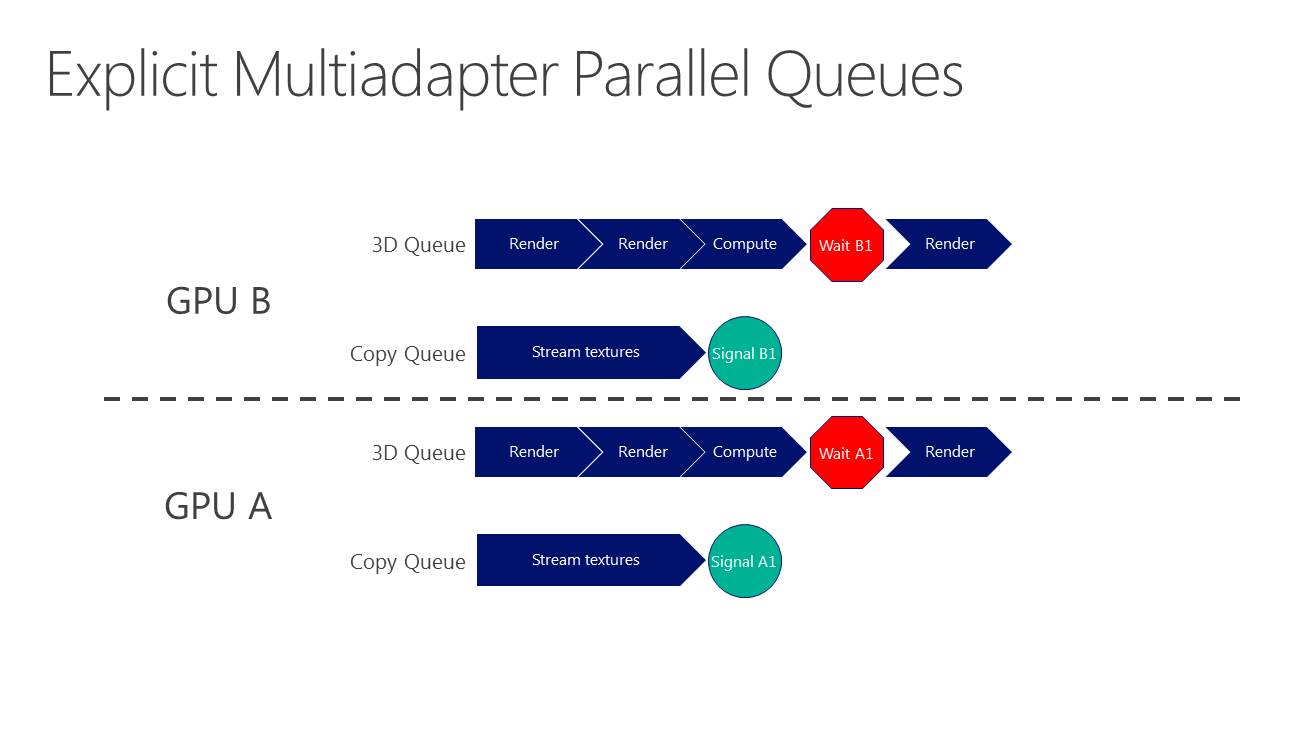
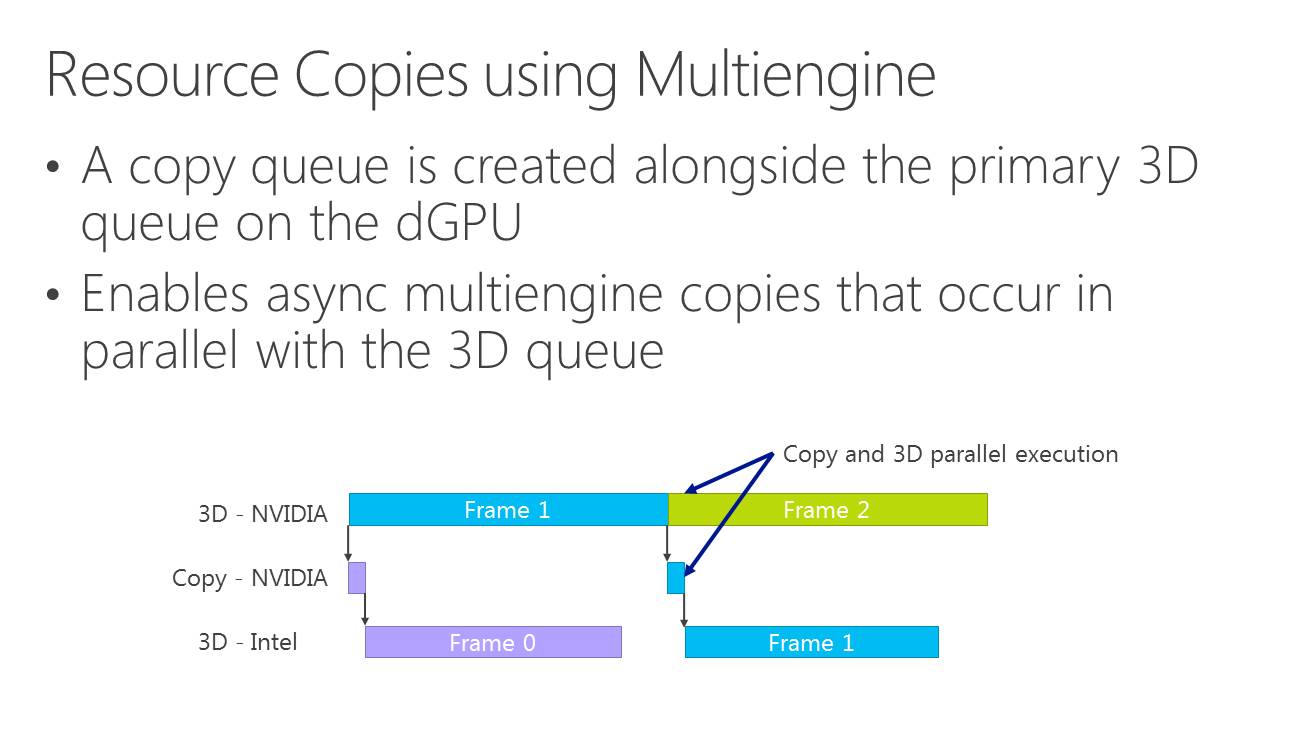
Les développeurs pilotent le multi-GPU à travers le multi engine, cette même fonctionnalité présente au coeur de DirectX 12 et qui permet de booster les performances à travers l'exécution concomitante de files de commandes (Async Compute). Il suffit de dédoubler la ou les files de commandes pour alimenter deux GPU.

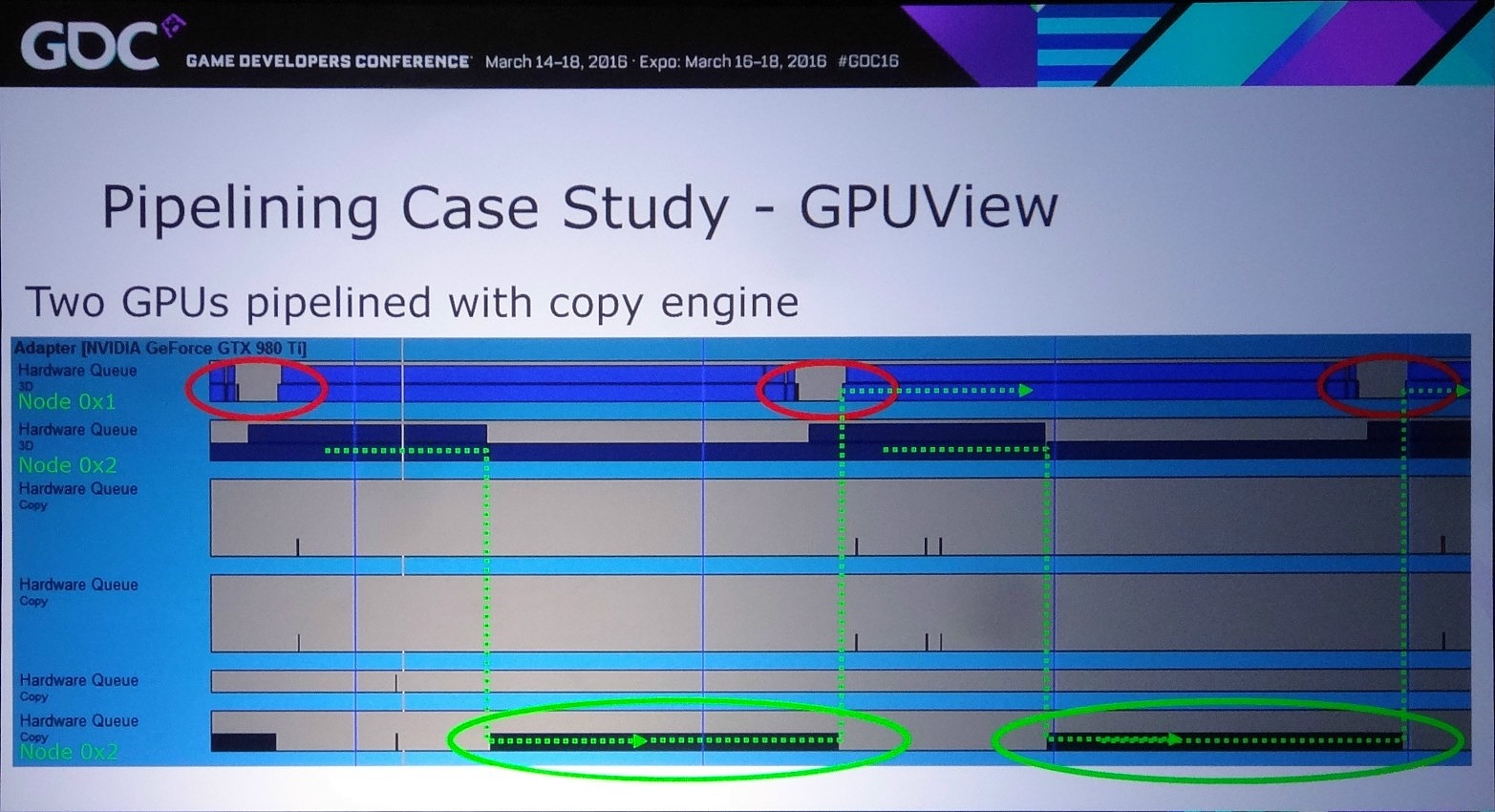
D'ailleurs, pour maximiser les performances, il est important d'avoir recours à une file dédiée de type copy pour organiser les transferts entre GPU. De quoi effectuer ces opérations en parallèle du rendu 3D et en masquer le coût. Si les GPU Nvidia ont du mal avec les files graphics et compute, ils n'ont par contre pas de problème pour traiter simultanément des files graphics et copy, tout du moins dans le cas des GPU Maxwell 2 qui disposent de deux moteurs de transferts DMA. A ce point, nous ne savons pas si les GPU précédents qui s'en contentent d'un seul pourraient être affectés.

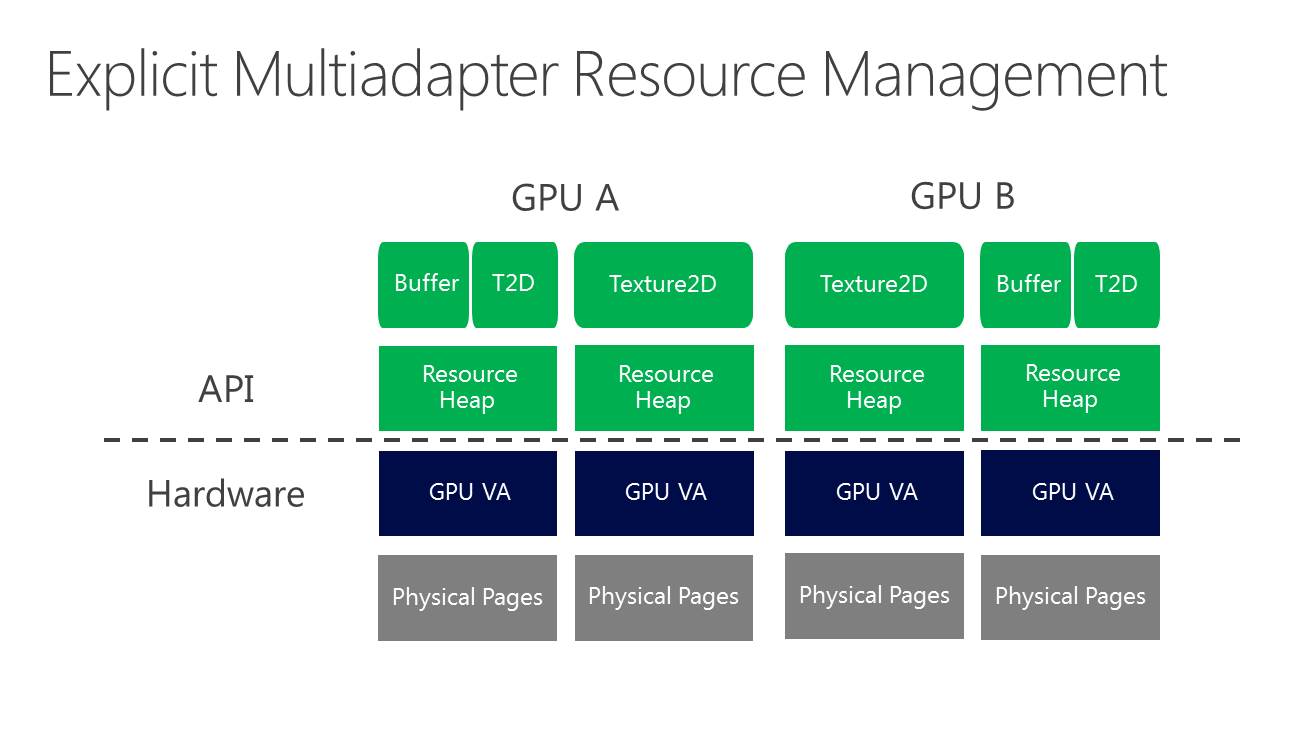
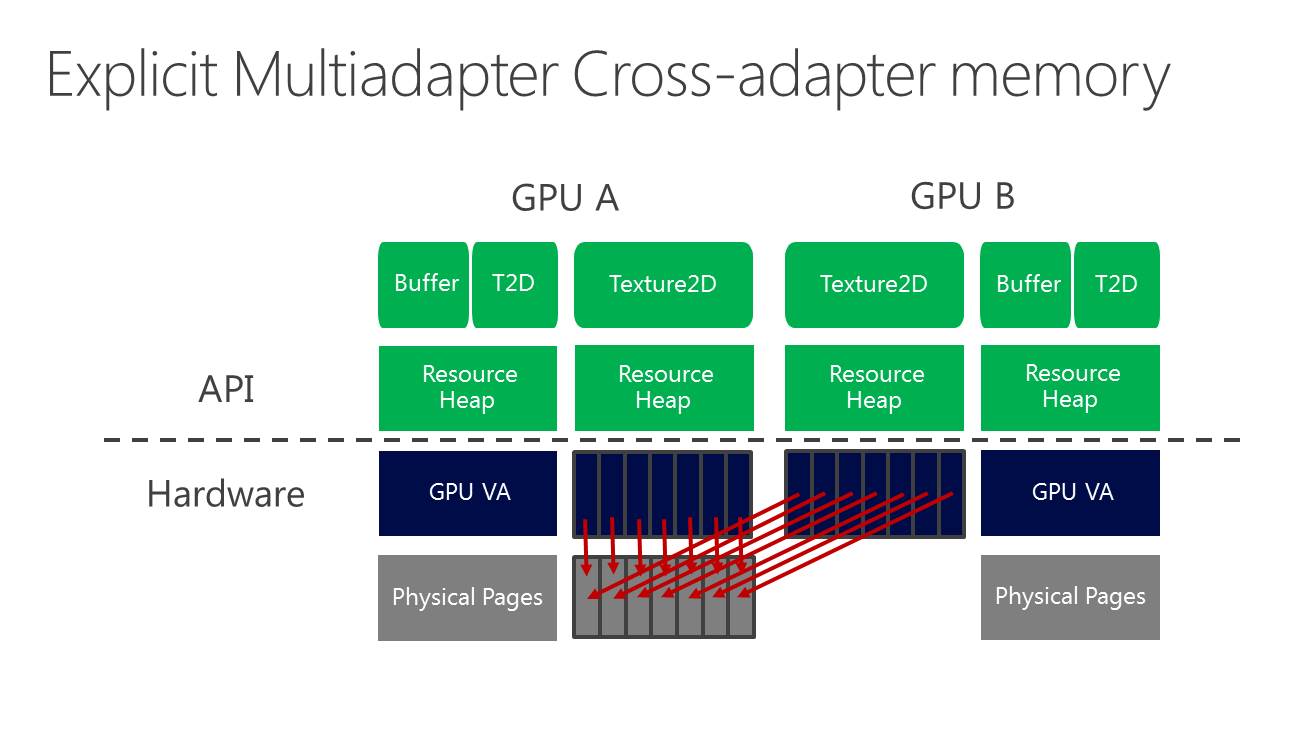
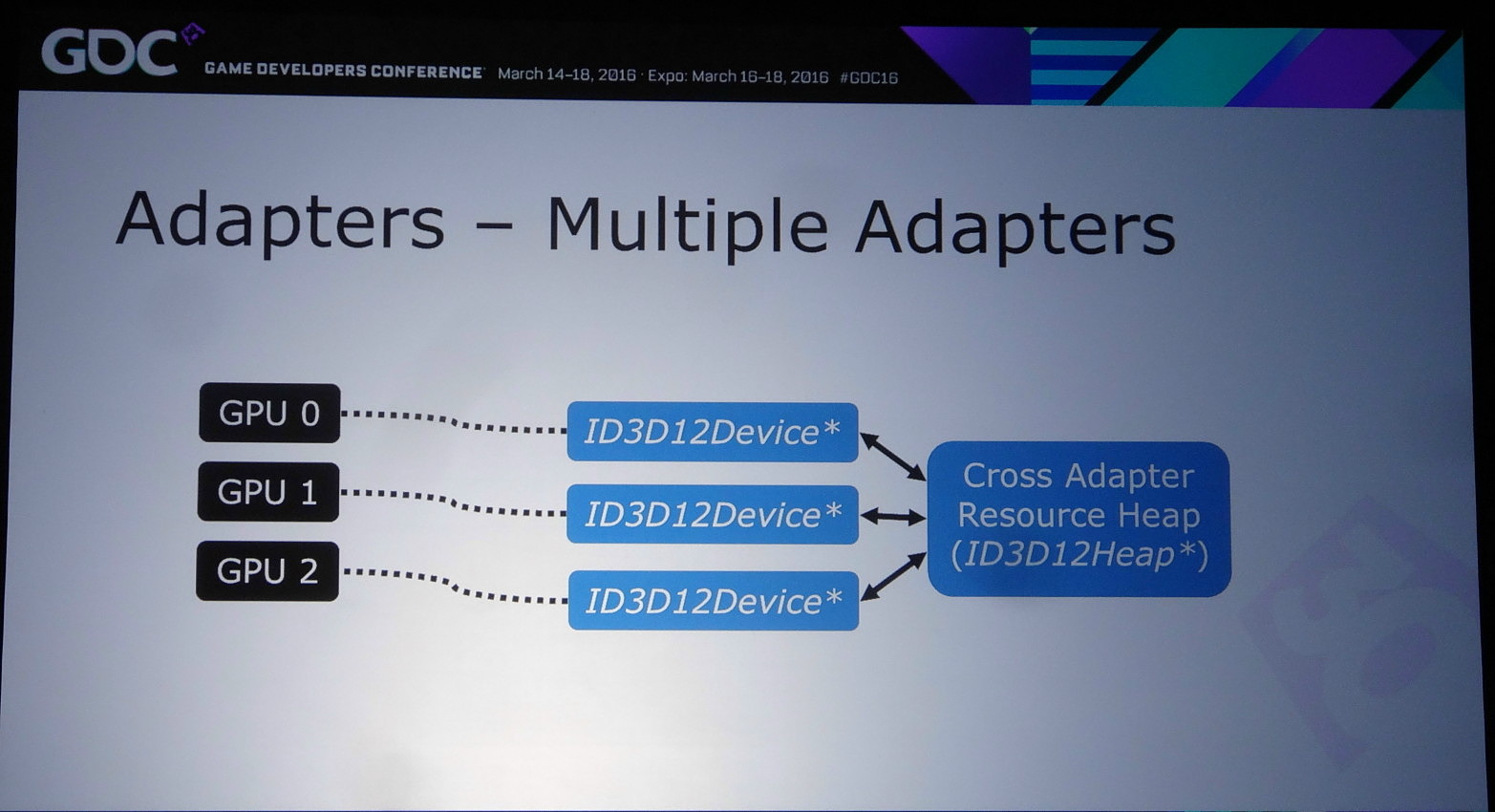
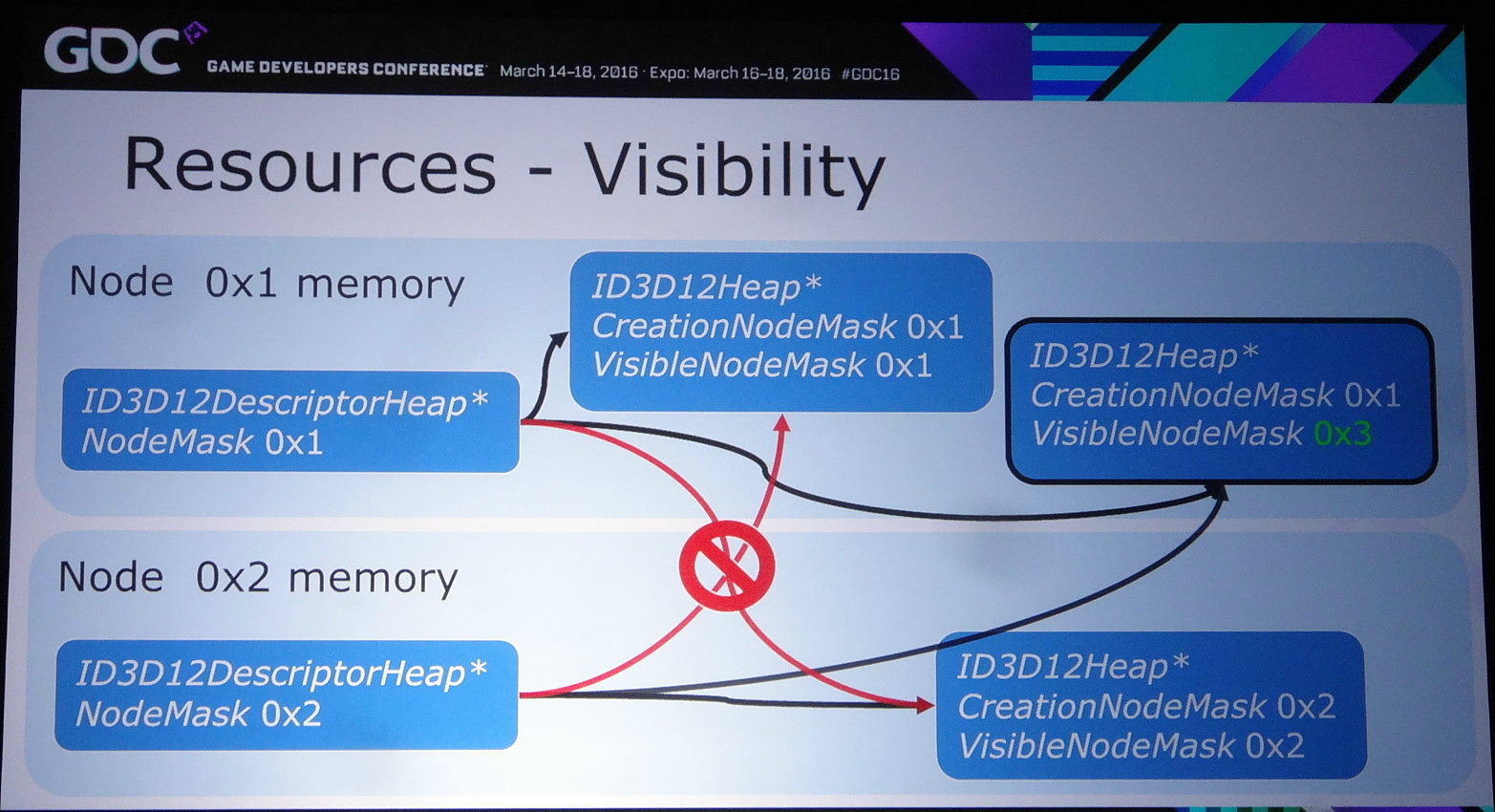
Nvidia rappelle ensuite qu'il existe différents tiers pour le partage de ressources à l'intérieur d'un noeud. Ce niveau de support est exposé à travers D3D12_CROSS_NODE_SHARING_TIER. Deux niveaux sont possibles : le tiers 1 ne supporte que les copies entre GPU alors que le tiers 2 autorise les accès à certaines ressources présentes dans la mémoire d'un autre GPU. Un dernier mode, le tiers 1 émulé est également proposé et consiste à implémenter dans les pilotes un mécanisme de transfert lorsque la copie directe de GPU à GPU n'est pas supportée.
Nous avons vérifié rapidement quel était le niveau de support proposé par AMD et Nvidia. Sur les GeForce Maxwell 2 il est de type tiers 2 alors qu'AMD se contente du tiers 1 sur GCN 1.1 et 1.2 (Hawaii et Fiji). Nvidia précise cependant que si les accès autorisés par le tiers 2 peuvent sembler pratiques, dans bien des cas il sera plus efficace d'effectuer une copie complète et de se contenter des fonctions du tiers 1.
Si exploiter le mode explicite lié peut permettre de faire de l'AFR (alternate frame rendering) avec un peu plus de flexibilité qu'en mode implicite, son intérêt réside surtout dans la possibilité d'implémenter d'autres modes de rendu, notamment pour résoudre les problèmes liés aux techniques qui font appel à une composante temporelle.

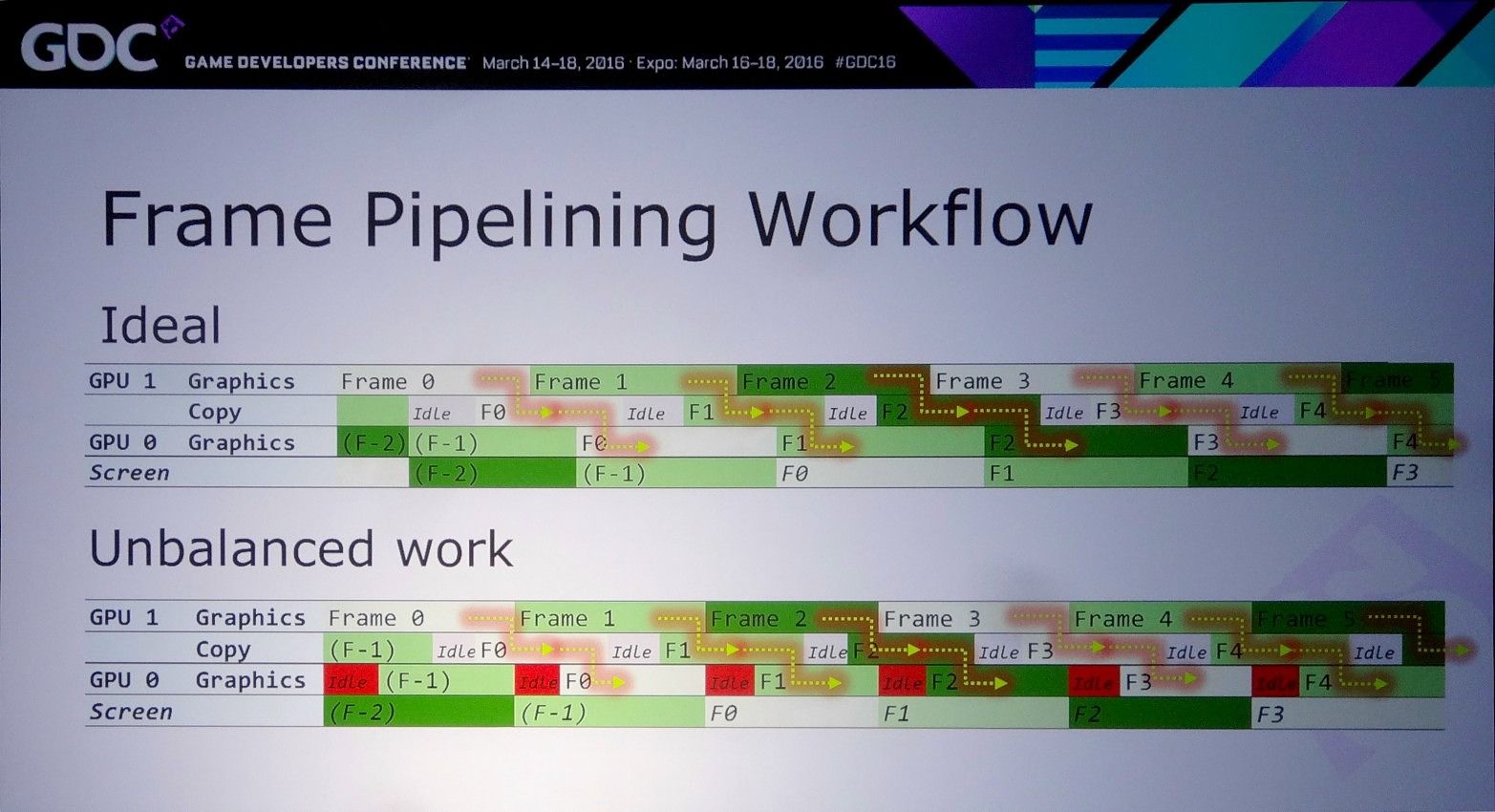
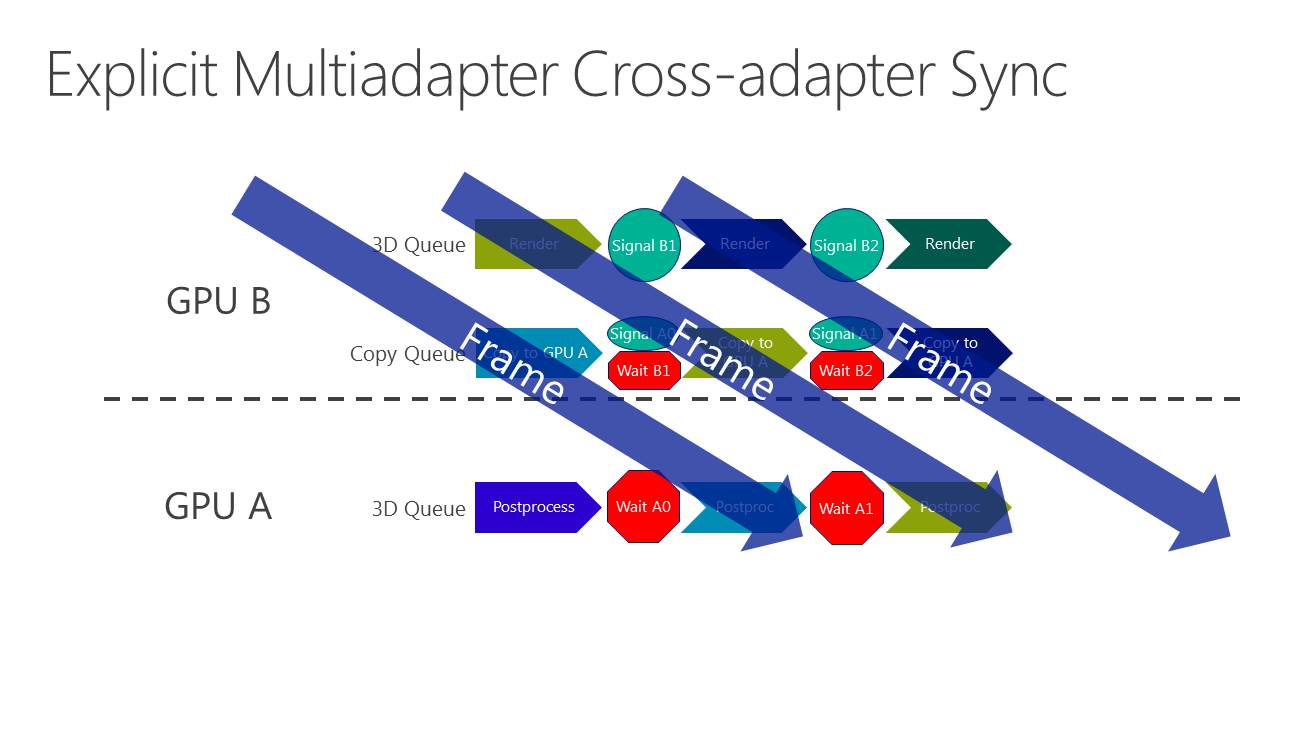
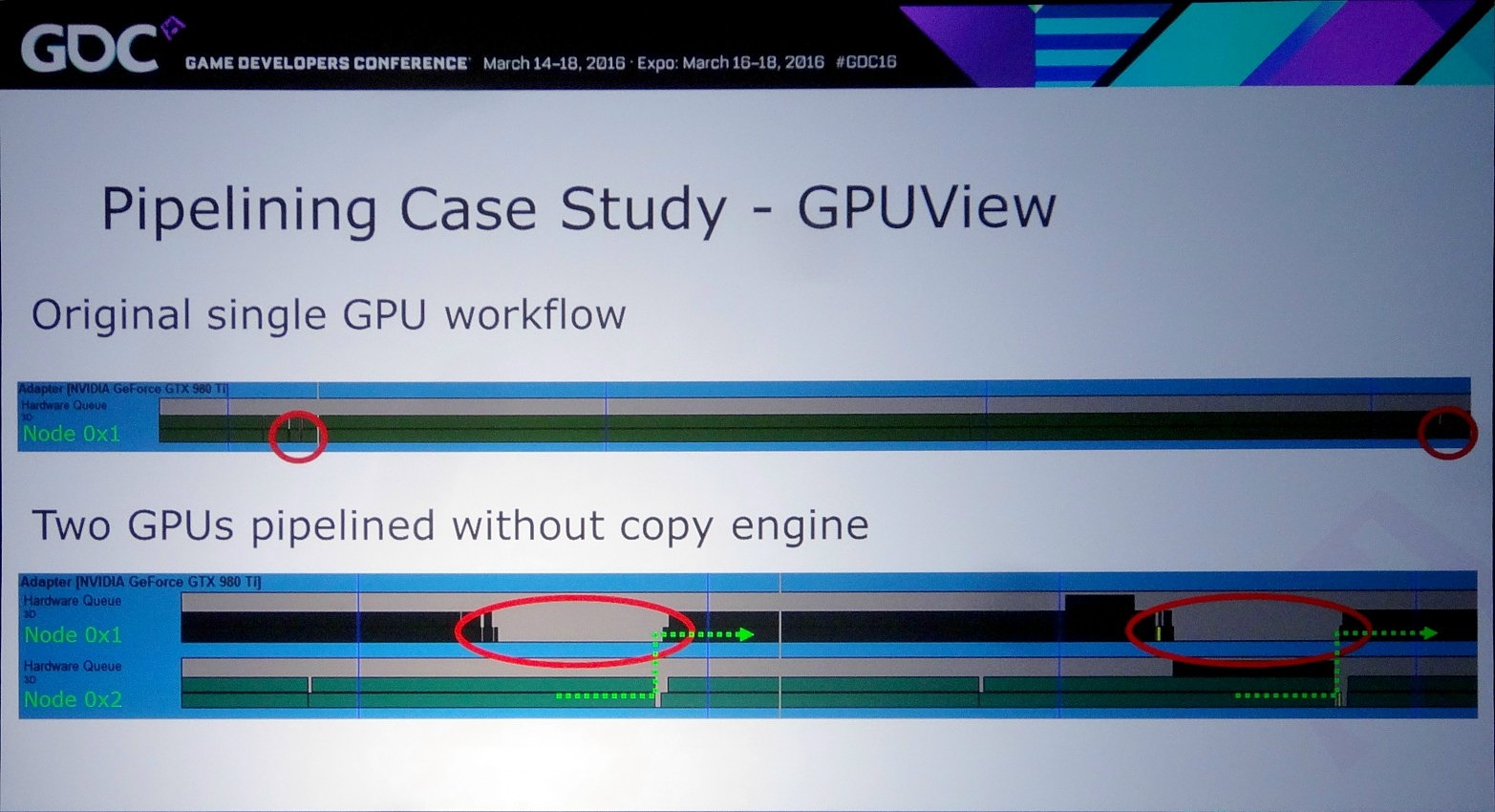
La solution à ces problème est appelée frame pipelining par Nvidia. Elle consiste à débuter le rendu d'une image sur un GPU et à transférer ces premiers éléments au second GPU en vue de la finalisation du rendu. Les GPU et leurs moteurs de copies travaillent alors à la chaine, d'où le nom de cette approche. Il est alors possible de prendre en charge sans problème un antialiasing temporel par exemple.
Pour mettre en place le frame pipelining, il faut parvenir à scinder son rendu en deux phases qui représentent une charge à peu près similaire et à un niveau qui permette de limiter les données à transférer. Il ne faut en effet pas oublier qu'un transfert de 64 Mo à travers un bus PCIe 3.0 8x prend au moins 8 ms, en général un peu plus en pratique. Pour éviter de transférer trop de données il peut alors être censé de dédoubler sur chaque GPU le calcul de certains éléments.
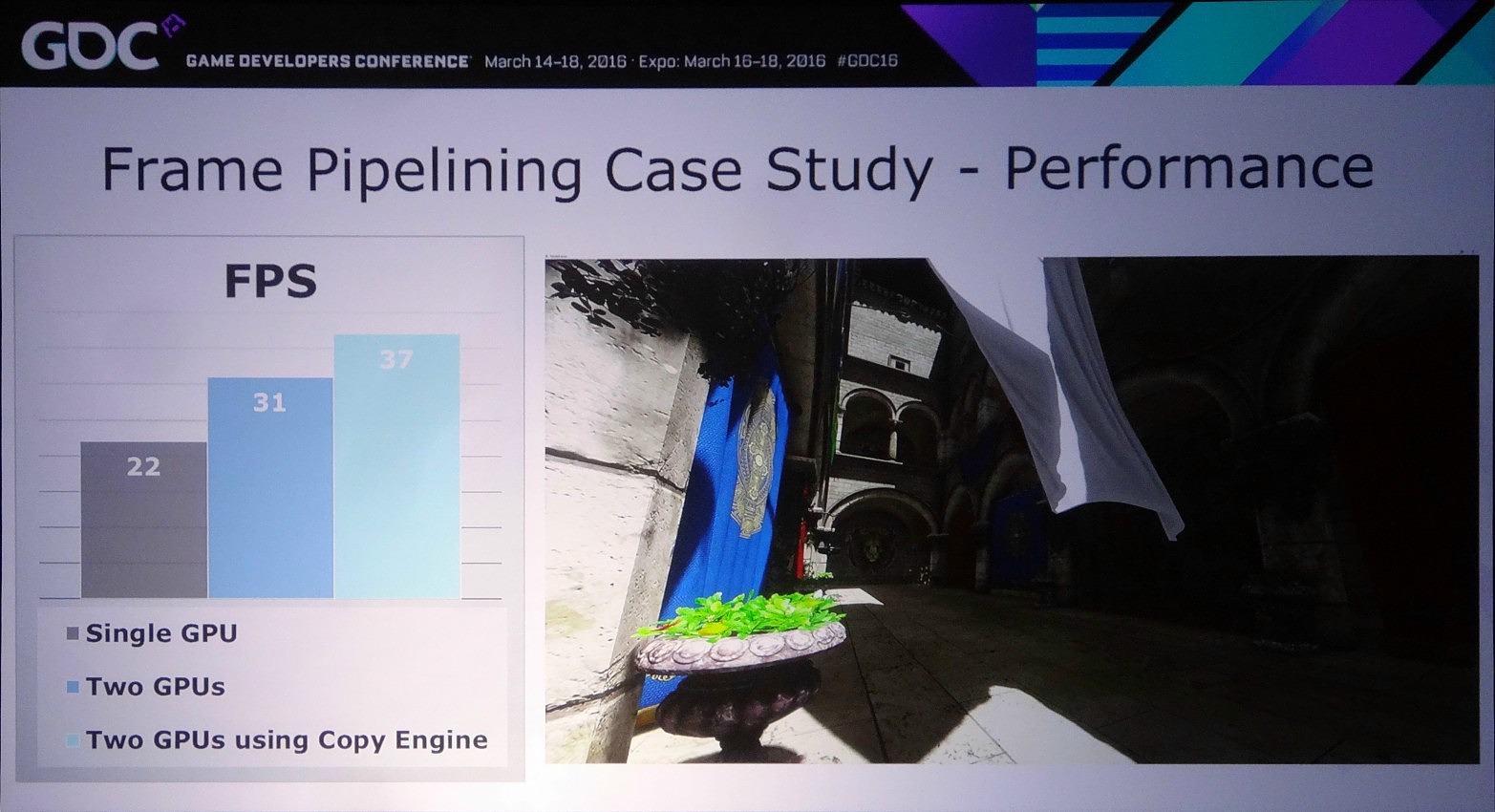

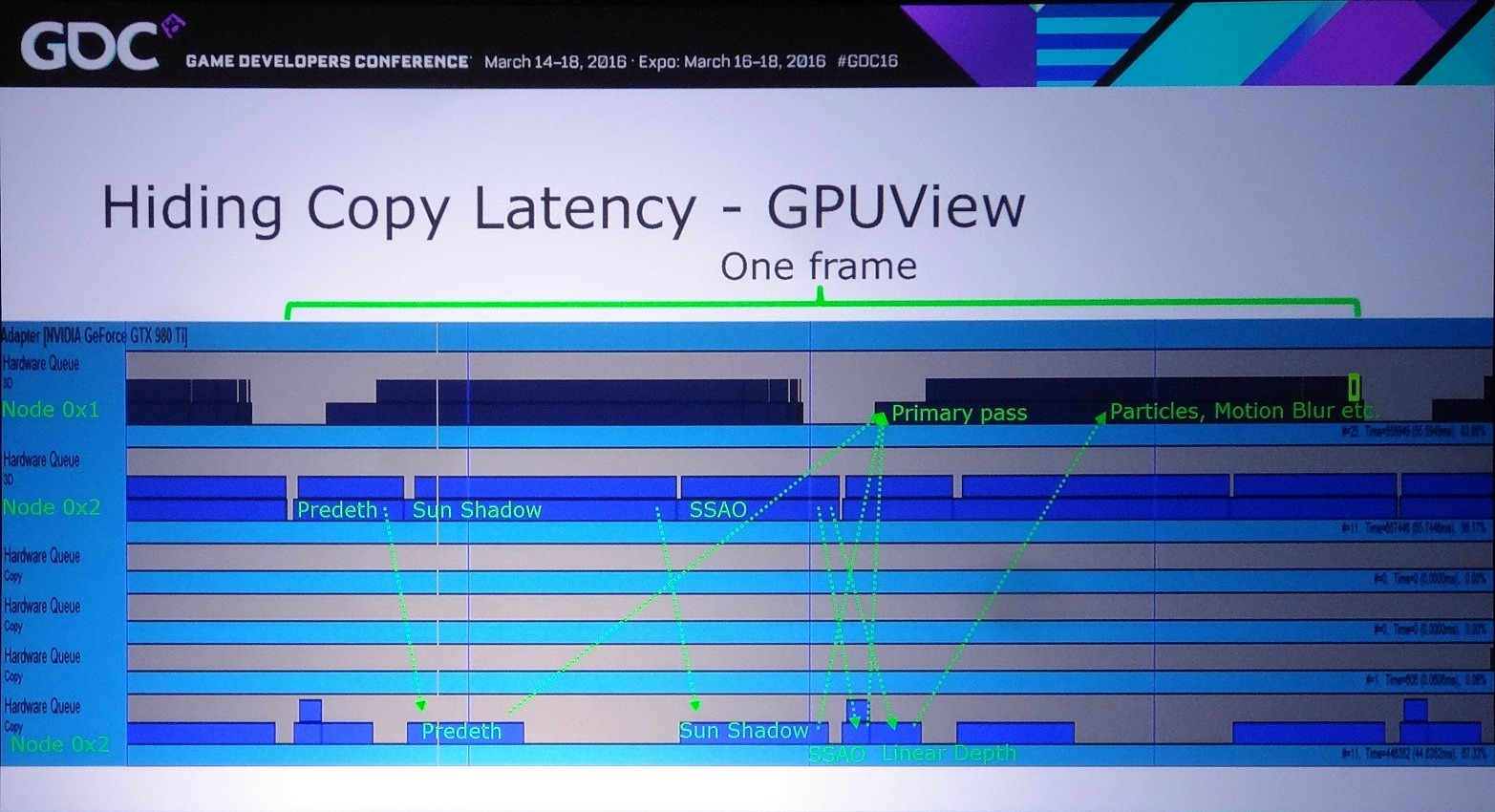
Dans l'exemple pris par Nvidia, le bi-GPU implémenté via le frame pipelining permet à la base de passer de 22 à 31 fps (+41%) et de monter à 37 fps (+68%) en exploitant le copy engine. Cet exemple est cependant un stress test en haute résolution (2160p) qui implique le transfert de la shadow map, du depth buffer et du SSAO, ce qui représente 87.3 Mo et prend à peu près 15 ms en PCIe 3.0 8x. Un temps de transfert qui limite le nombre de fps à +/- 60.
Le problème restant avec cette approche concerne la latence qui augmente à peu près comme en mode AFR. Le GPU1 effectue tout son travail, les données sont transférées puis le GPU effectue son travail. A 60 fps, et par rapport à un gros GPU de puissance équivalente, cela implique un triplement de la latence (de 16.7 ms à près de 50 ms). Heureusement, la partie liée au transfert de cette latence supplémentaire peut être masquée, exactement comme le fait Oxide pour le mode Async Compute d'AotS. Il suffit de décomposer le rendu en plus petits groupes de commandes et de transférer progressivement les éléments entre les GPU à travers le copy engine.
Reste bien entendu à voir ce que feront les développeurs de tout cela et à quel point AMD et Nvidia pourront les aider. Même si implémenter le frame pipelining en prenant en compte uniquement des ensembles de GPU similaires est plus simple que d'autres modes de rendus avec des combinaisons exotiques, cela représente un travail supplémentaire que tous n'accepteront probablement pas de prendre en charge. Et nous ne parlons mêmes pas des modes tri-GPU et quadri-GPU dont le support exigerait des développements complémentaires spécifiques
Vous pourrez retrouver l'intégralité de la présentation de Nvidia ci-dessous :





























DirectX 12 supportera un mix de GPU
Microsoft avait réservé pour sa conférence Build 2015 les détails concernant une énième nouvelle fonctionnalité de Direct3D 12 : le support explicite du multi-GPU. Il ouvre en théorie la voie aux combinaisons de tous types de GPU, y compris de marques différentes, mais la pratique ne sera pas aussi simple.
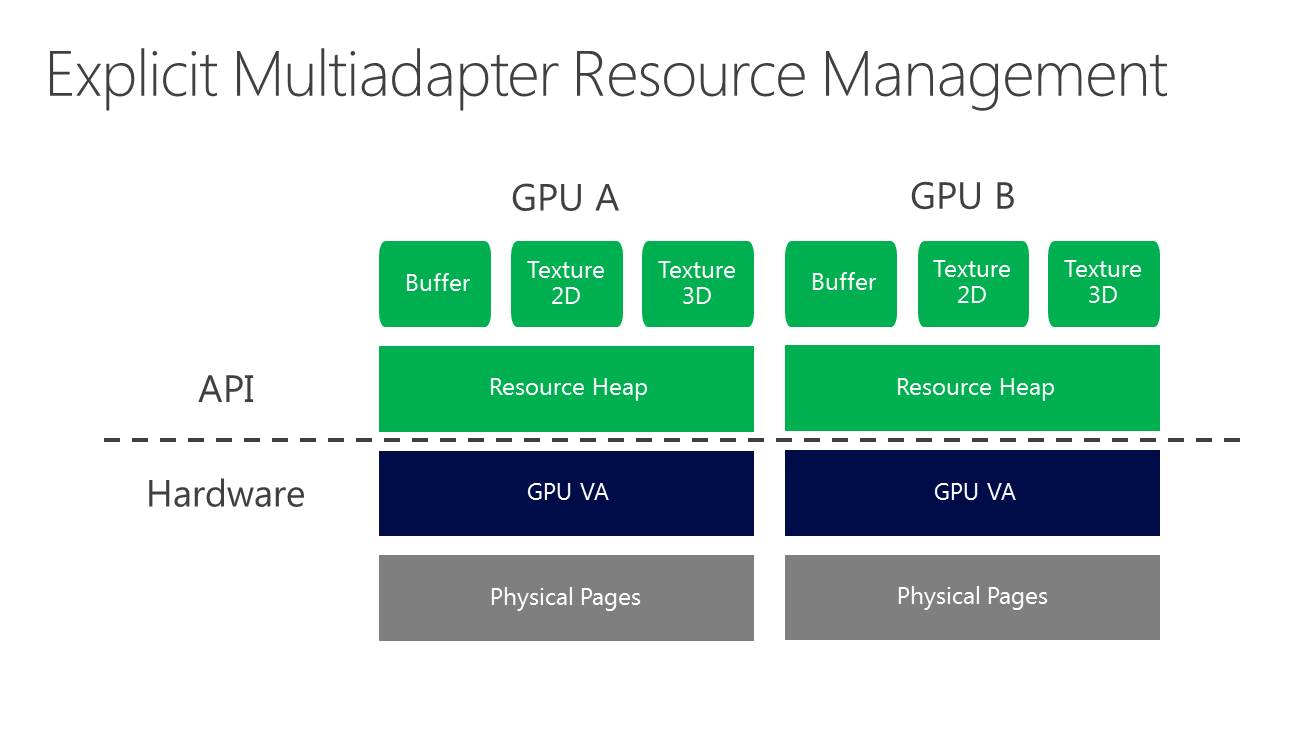
Direct3D 12, la composante graphique du prochain DirectX, supportera plusieurs modes de multi-GPU (multiadapter). Le premier est un mode de multi-GPU implicite, similaire à ce qui est utilisé actuellement par AMD et Nvidia sous Direct3D 11 ou OpenGL pour supporter le CrossFire et le SLI. Avec ce mode, les développeurs n'ont pas trop à se soucier du multi-GPU, les pilotes se chargeant de son support de façon à peu près transparente, même s'ils doivent faire en sorte qu'il n'y ait pas de dépendance entre les images, puisqu'il s'agit en général d'un rendu des images en alternance (AFR).

La nouveauté c'est le support du mode multi-GPU explicite, ou plutôt des modes explicites. Dans ces cas de figures, le contrôle du multi-GPU revient aux développeurs qui pourront en faire à peu près tout ce qu'ils veulent. Ce support est basé sur l'extension de la gestion par Direct3D de différents moteurs pour piloter un GPU (graphics, compute, copy), fonctionnalité qui permet pour rappel de profiter du parallélisme entre différents types de tâches, comme expliqué ici. En multi-GPU explicite, ces différents moteurs seront exposés pour chaque GPU.
A partir de là, deux sous modes peuvent être exploités. Le multi-GPU explicite lié (linked) est proche des CrossFire et SLI actuels (il en exploite le moteur de composition), si ce n'est que les développeurs prennent le contrôle. L'ensemble est vu comme un seul gros GPU qui dispose de plus de moteurs de types graphics, compute et copy. Ce mode pourrait par exemple permettre de supporter plus facilement un rendu de type AFR malgré certaines dépendances entre images. Microsoft n'est pas rentré dans les détails à ce niveau et s'est contenté d'indiquer qu'ils seraient communiqués plus tard. Nous ne savons pas non plus si AMD et Nvidia conserveront la mains sur les combinaisons supportées (par exemple 2 GTX 980 et pas GTX 980 + GTX 970).
Enfin, le multi-GPU explicite non-lié (unlinked) est le mode qui autorise tout type de combinaisons de GPU. Direct3D 12 est très flexible et permet aux développeurs de gérer les synchronisations entre GPU, leurs mémoires respectives, des buffers distincts ou partagés, les transferts entre GPU Bref de quoi faire à peu près tout ce qui peut leur passer par la tête pour exploiter tous les GPU du système.
De quoi imaginer la combinaison d'une GeForce avec une Radeon ? Oui et non. C'est théoriquement possible, mais en pratique différents problèmes vont se poser, que ce soit en termes de performances via les optimisations spécifiques des pilotes, ou en termes de qualité avec de petites différences dans le rendu des images (notamment au niveau du filtrage des textures ou de l'antialiasing) qui vont entraîner un clignotement. Des modes de types AFR ou SFR avec un mix de GPU ne sont donc pas réalistes, tout du moins pour l'instant.
Rappelons cependant que dans la documentation de Mantle, nous avons pu découvrir qu'AMD avait prévu un mécanisme pour demander à ses cartes graphiques de rentrer dans un mode "neutre" en terme de qualité de manière à uniformiser le rendu autant que possible entre des GPU Radeon différents. Dans le futur ce principe pourrait être étendu à Intel et Nvidia, mais mettre tout le monde d'accord ne sera pas simple, d'autant plus que l'intérêt commercial sera limité.
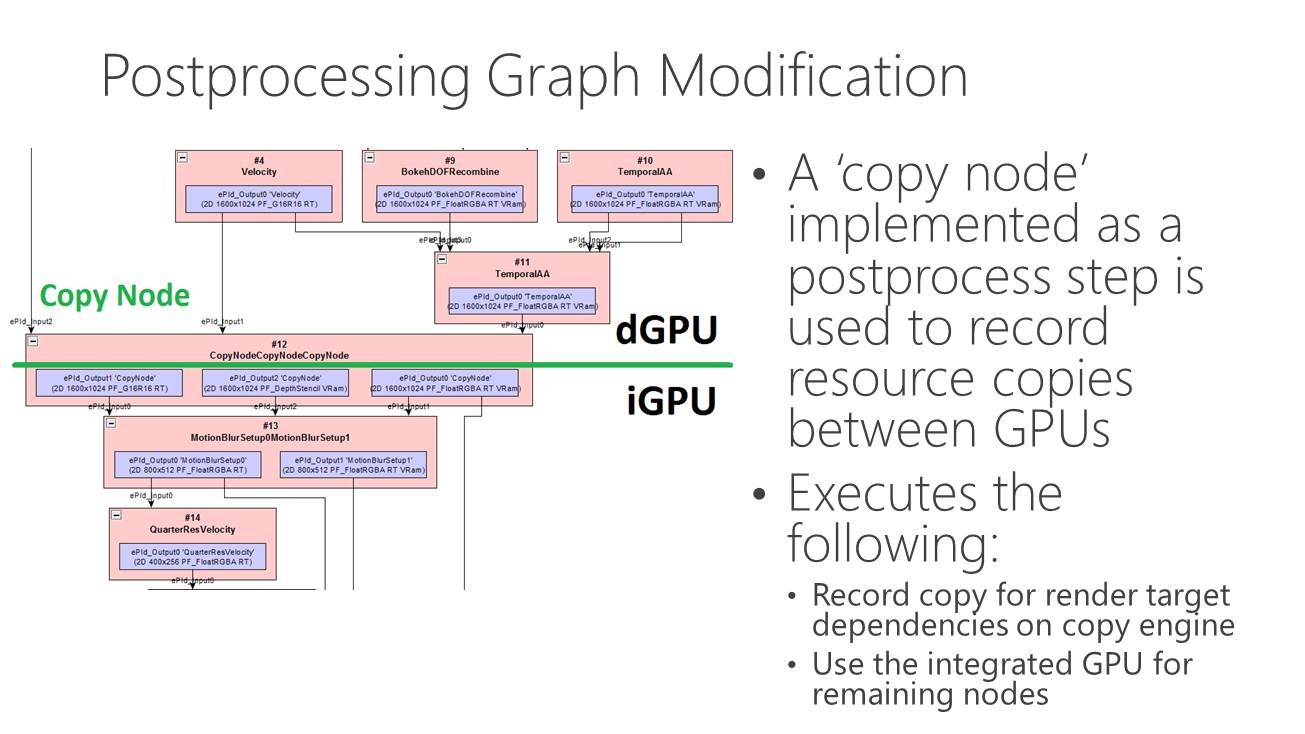
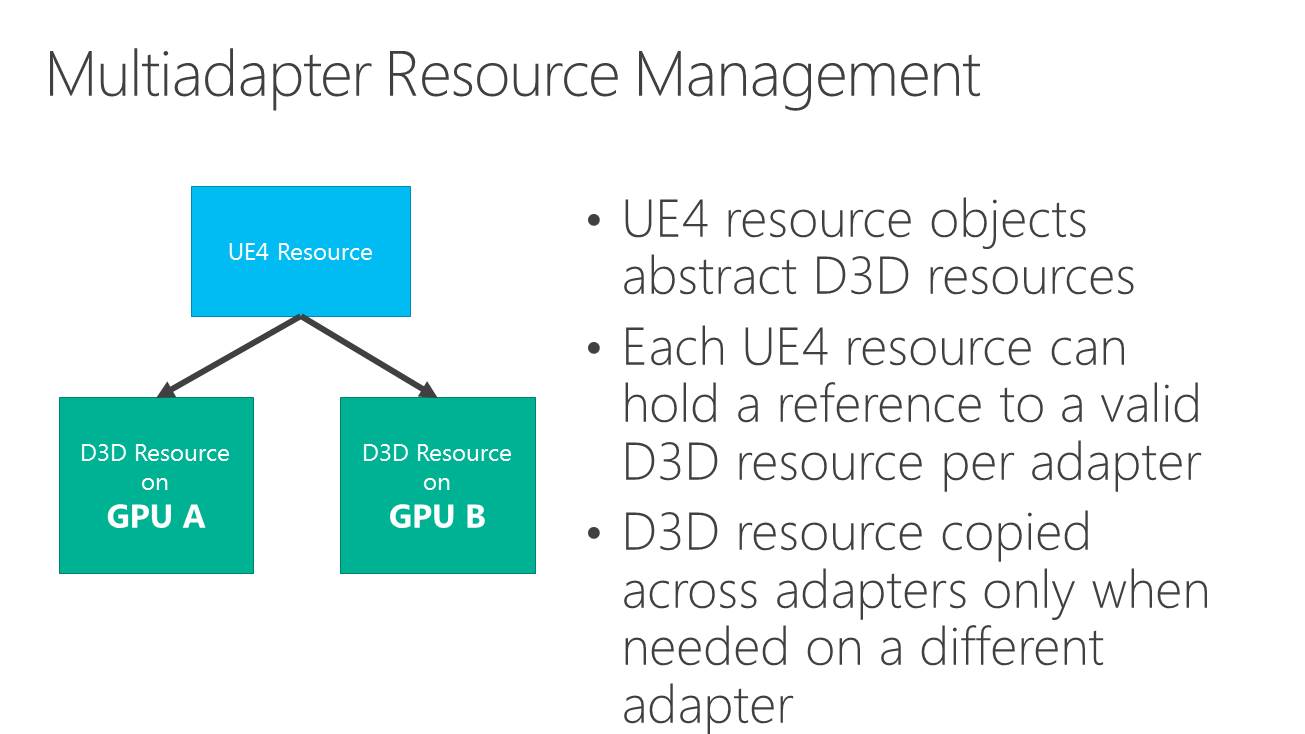
Dans l'immédiat, l'utilisation réaliste du multi-GPU explicite non-lié est différente. Il s'agit plutôt de faire traiter par chaque GPU différentes étapes du rendu, ce qui évite tout souci de qualité et de clignotement. C'est d'ailleurs ce qu'a choisi d'illustrer Microsoft qui a pour l'occasion modifié quelque peu l'Unreal Engine 4 de manière à déporter certaines tâches d'une carte graphique Nvidia vers un GPU intégré Intel.

Dans cette démonstration, le plus gros du rendu est traité par la carte graphique mais la fin du post processing est traitée par le GPU Intel qui se charge ensuite de l'affichage. Travailler de la sorte au niveau du post processing permet d'exploiter toute la puissance de calcul disponible en minimisant les échanges de données via le bus PCI Express puisqu'il suffit en gros de transférer le frame buffer et le Z-Buffer.
Choisir où scinder le rendu est essentiel pour s'assurer qu'il y ait bel et bien un gain de performances. Microsoft explique à ce sujet avoir fait en sorte que le GPU intégré prenne toujours moins de temps à faire son travail que la carte graphique. Celle-ci reçoit un coup de boost mais reste l'élément qui définit les performances.
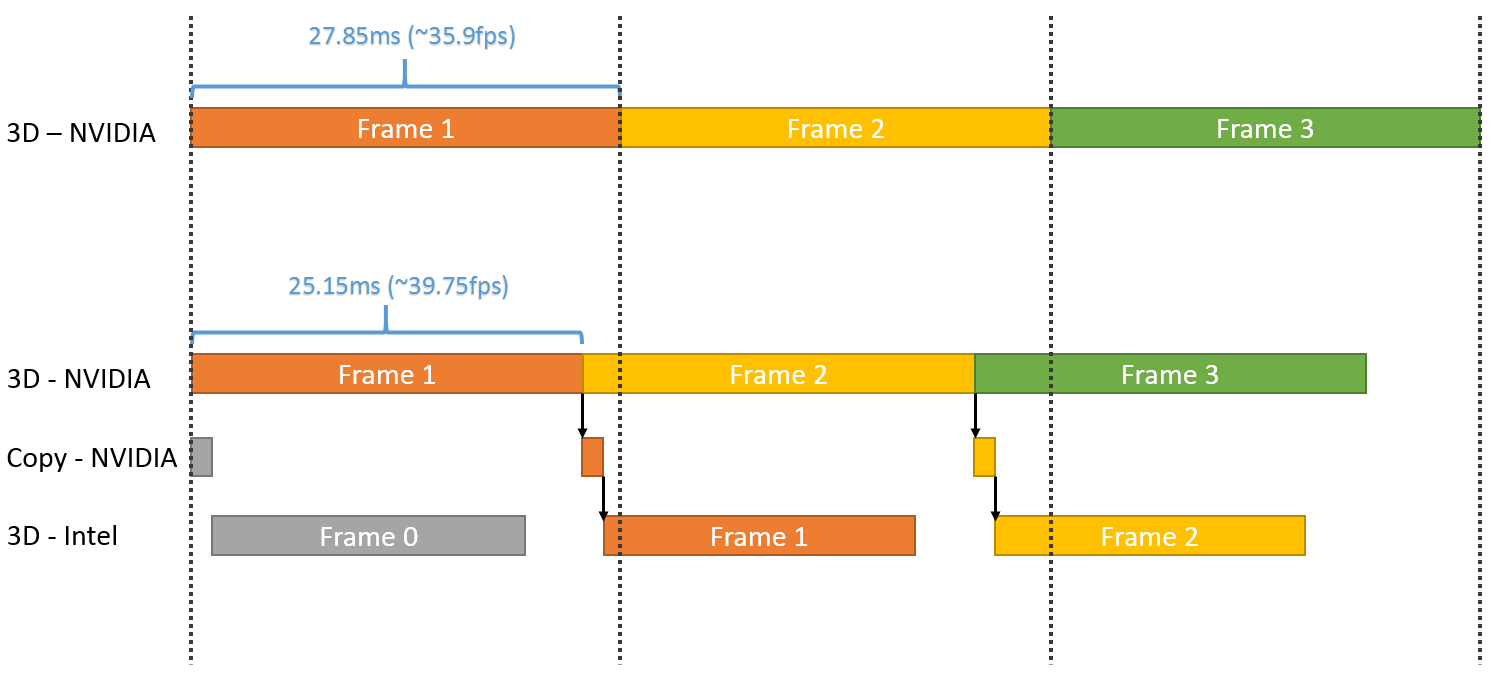
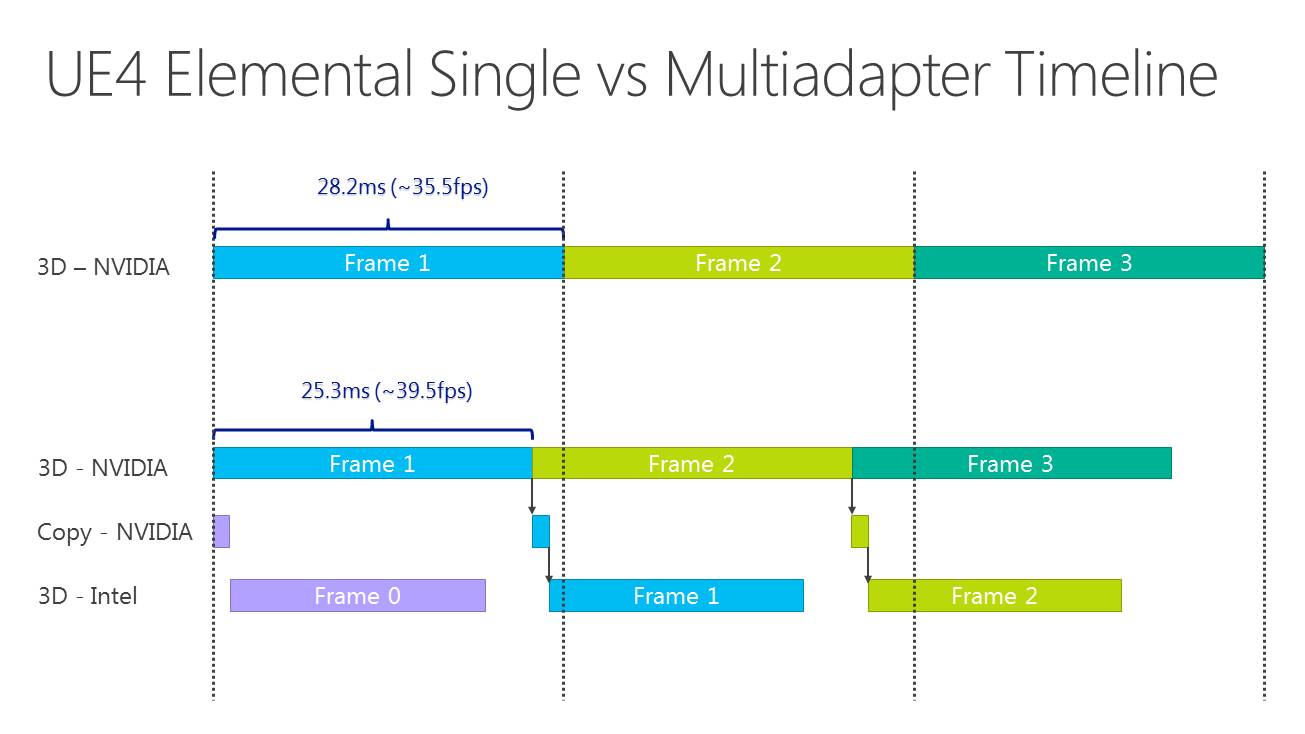
Plus spécifiquement, l'opération permet de passer de 35.9 à 39.7 fps, soit un gain de 10%. En observant de plus près cet exemple, il apparaît que le GPU intégré prend beaucoup plus de temps pour traiter la partie finale du post processing que la carte graphique, mais ce dernier n'ayant rien d'autre à faire, cela permet un gain de performances. C'est probablement surtout vrai pour les GPU d'entrée voire de milieu de gamme (Microsoft ne précise pas la configuration) alors qu'il serait peut-être contreproductif de vouloir aider une GeForce GTX Titan X avec un GPU intégré.
Par contre, il y a un désavantage évident à cette technique qui apparaît sur ce graphique : elle augmente la latence. Dans l'exemple de Microsoft, la partie de la latence liée au rendu passe de 28ms à plus ou moins 45ms quand le GPU intégré entre en action. Suivant le mode d'affichage, cela peut correspondre à l'ajout de l'équivalent d'une image de latence, ce qui ne plaira pas aux joueurs exigeants sur ce point.
Du coup est-ce bien utile pour les développeurs de jeux vidéo d'essayer de proposer ce type d'optimisations ? Une démonstration telle que celle de Microsoft est relativement facile à mettre en place grâce à Direct3D 12, mais dans la pratique, sur PC, il y a un nombre énorme de combinaisons possibles à prendre en compte pour que l'opération ne soit pas contre-productive. Et mettre en place un système de load balancing automatique dans les moteurs est loin d'être simple, même si ce n'est pas impossible.
Dans l'immédiat, il nous semble donc probable que cette possibilité de mélanger différents types de GPU reste avant tout dans la zone d'expérimentation pour les développeurs de jeux vidéo, même si les gros moteurs graphiques pourraient la supporter rapidement. Un peu plus tard, la première utilisation commerciale pourrait concerner certains PC d'entrée de gamme. Nous pensons par exemple aux plateformes Dual Graphics d'AMD (APU + GPU) ou encore aux portables Optimus de Nvidia (GeForce associée à un GPU Intel). Avec un petit effort de la part des développeurs de jeux vidéo, AMD et Nvidia pourraient prendre le relais avec des profils adaptés pour booster certaines de leurs plateformes.
Vous pourrez retrouver ci-dessous l'ensemble des slides de la présentation de Microsoft effectuée lors de la Build 2015 (section multiadapter à partir de la page 11) :