
Nvidia GeForce GF100 : la révolution géométrique ?
Publié le 18/01/2010 par Damien Triolet



FréquencesUne autre différence importante introduite avec le GF100 concerne les domaines de fréquence. Depuis le G80, 3 domaines principaux existent : la fréquence GPU, la fréquence des SMs/schedulers et la fréquence des unités de calcul. Ces deux dernières fréquences sont liées puisque les unités de calcul fonctionnent grossièrement à la manière des unités dual pumped du Pentium 4 et donc à une fréquence double par rapport au scheduler, aux registres etc. Du G80 au GT200, les fréquences importantes étaient uniquement celles du GPU et des unités de calcul. Les unités de texturing, les ROPs, le setup / rasterizer étaient tous dans le domaine du GPU.
Avec le GF100, cela change. Tout ce qui est dans le GPC fonctionne à la fréquence des SMs/schedulers. Autrement dit, en termes dunités dexécution, il ne reste que les ROPs dans le domaine de la fréquence GPU. Nvidia na pas voulu parler des fréquences pour le GF100 mais si nous nous basons sur larchitecture actuelle, cela apporterait un gain à de nombreuses unités. Cela facilite également la synchronisation entre tout ce petit monde, ce qui devrait améliorer le rendement et/ou simplifier le design.
Architecture mémoireLe GF100 dispose tout dabord de nombreux registres généraux, 32768 de 32 bits par SM, dune structure de caches généralistes avec un cache L1 de 16 Ko par SM (possibilité de 48 Ko en mode compute uniquement), un texture cache de 12 Ko per SM (lecture uniquement) et un cache L2 global de 768 Ko. Ce dernier se connecte, ou plutôt fait partie des 6 contrôleurs mémoire de 64 bits qui forment le bus de 384 bits.
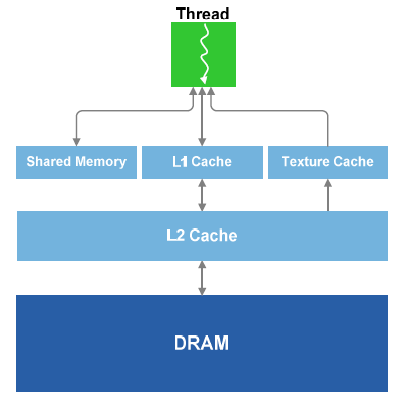
Les caches L1 et de texture partagent les mêmes ports vers le cache L2 en lecture. La bande passante entre le L1 et le L2 est au total de 384 octets per cycle, soit de +/- 270 Go/s suivant la fréquence qui sera retenue, et ce, dans chaque direction.
Si le nombre de registres de 32768 peut paraître élevé, il est en réalité en baisse par rapport au nombre dunités de calcul, ce qui veut dire que les longues latences seront moins bien masquées par le nombre de threads. Par contre la structure de cache permettra de réduire les longues latences et de pouvoir étendre lespace registre à travers le L1 pour conserver plus de threads dans les SMs quand la pression sur les registres généraux est forte.
Il est difficile de savoir à quel point larchitecture de cache généraliste choisie par Nvidia sera efficace. Certes elle est plus flexible et va permettre de faire de nouvelles choses, mais elle remplace une série de caches dédiés très efficaces dont elle devra se charger de tout le travail.
Si vous avez suivi la présentation compute de larchitecture Fermi, vous vous souvenez probablement que le cache L1 et la mémoire partagée (qui permet aux threads dun même groupe de communiquer entre eux) sont liés. Ils se partagent 64 Ko de cette manière : 16 Ko pour lun et 48 Ko pour lautre. Dans un sens ou dans lautre, ce qui laisse 2 possibilités. En mode graphique ce sera toujours 16 Ko de L1 et 48 Ko de mémoire partagée, le L1 nétant réellement utile que lors de calculs peu prédictibles, ce qui est le contraire du rendu 3D.
Direct3D 11 exige le support dune mémoire partagée de 32 Ko partagée entre maximum 1024 threads (1536 threads maximum dans un SM du GF100). Si le GF100 peut donc aller au-delà, en pratique il est en général recommandé de conserver au moins 2 groupes de threads par SM. Autrement dit pour de meilleures performances il faudra en général se contenter de 768 threads et de 24 Ko de mémoire partagée ou de 512 threads et de 16 Ko de mémoire partagée. Cette dernière option étant préférable puisquil sagit dun dénominateur commun avec larchitecture des Radeon HD 5000.
Sommaire
Vos réactions
Contenus relatifs
- [+] 10/04: Nvidia : fin du support Fermi et 32...
- [+] 12/03: Nvidia lance les GeForce 800M avec ...
- [+] 08/10: Comparatif : les super GeForce GTX ...
- [+] 24/03: Nvidia répond à AMD avec la GeForce...
- [+] 17/03: Nvidia GeForce GTX 550 Ti et Asus D...
- [+] 28/02: Nvidia annonce CUDA 4.0
- [+] 01/02: Nvidia lance une autre GeForce GT 4...
- [+] 25/01: GeForce GTX 560 Ti contre Radeon HD...
- [+] 24/01: Comparatif : 14 GeForce GTX 460 1 G...
- [+] 07/12: Nvidia GeForce GTX 570