
Nvidia GeForce GF100 : la révolution géométrique ?
Publié le 18/01/2010 par Damien Triolet



Le GF100Nous ne reviendrons pas en détails sur le côté « compute » de larchitecture, celui-ci ayant déjà été traité en long et en large dans larticle consacré à Fermi, le nom de larchitecture, GF100 étant son implémentation.
Pour rappel, les G8x, G9x et GT2xx étaient basés sur des structures appelées TPCs pour Texture Processing Clusters qui englobaient 2 ou 3 SMs (Streaming Multiprocessors) et un groupe de 8 unités de texturing (avec limitations pour le G80). Le GT200 dispose par exemple de 10 TPCs de 3 SMs qui se partagent 8 unités de texturing. Ces TPCs sont pilotés par un ensemble unique dunités spécialisées dans la préparation des tâches, le setup des triangles, la rastérisation etc.

Le GF100 est de son côté composé de 4 gros blocs, les GPCs pour Graphics Processing Clusters. Toutes les unités spécialisées se retrouvent cette fois au niveau des GPCs et des SMs. Le GF100 est ainsi le premier GPU à pouvoir traiter plus dun triangle par cycle ! Nous reviendrons sur ce point. Chaque GPC englobe 4 SMs pour un total de 16 dans le GPU. Un autre changement important prend place avec des unités de texturing qui ne se situent plus au niveau de la structure principale mais bien au niveau du SM. Cest pour ces raisons que Nvidia a dû abandonner le nom TPC au profit de GPC. Chaque SM dispose dans le GF100 de 4 unités de texturing qui lui sont dédiées. Les groupes de SMs ne doivent donc plus se partager des unités de texturing ce qui simplifie le design et permet de gagner en efficacité.
Opter pour des unités de texturing découplées (AMD du R520 au RV670) ou semi-découplées (Nvidia du G80 ou GT200) était sur le papier une idée élégante qui permettait de faire évoluer larchitecture facilement vers un ratio puissance de calcul / puissance de texturing plus élevé, disoler une fonction fixe du core programmable et de maximiser le rendement en permettant à toutes les unités dêtre utilisées là où le GPU en a besoin. En pratique il sest cependant avéré que ce gain de rendement nétait pas aussi utile que cela et ne compensait pas la perte defficacité due à une complexification du design. AMD est donc revenu en arrière avec les Radeon HD 4000 et Nvidia en fait de même aujourdhui, ce qui démontre au passage quune évolution architecturale peut être contre productive.
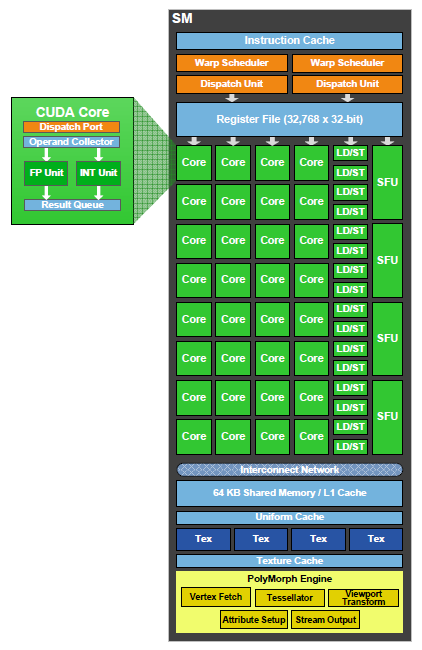
Chaque SM est donc composé dun double scheduler qui peut, à chaque cycle, envoyer une instruction à 2 de ces 5 blocs dexécution :
- unité SIMD0 16-way (les « cores ») : 16 FMA FP32, 16 ADD INT32, 16 MUL INT32
- unité SIMD1 16-way (les « cores ») : 16 FMA FP32, 16 ADD INT32
- unité SFU quadruple : 4 fonctions spéciales FP32 ou 16 interpolations
- unité Load/Store 16-way 32 bits
- unités de texturing
La latence et le débit de chaque instruction est différent, mais le tout est découplé, ce qui veut dire par exemple quune fonction spéciale qui prend plusieurs cycles ne va pas empêcher le scheduler denvoyer une instruction à un autre bloc dexécution. A un moment donné ils peuvent donc tous être au travail. Notez que nous laissons ici de côté le FMA FP64 qui utilise les unités SIMD0 et SIMD1 et nest pas utilisé en rendu graphique.
Notez que la notion de « core » est rendue encore plus complexe avec le GPC. Quelle structure devrait recevoir ce qualificatif ? Le GPC ? Le SM ? Chaque voie dune unité SIMD ? Nvidia préfère bien entendu cette dernière option et parler de 512 « CUDA Cores ». De notre côté nous penchons plus pour le SM. Un GF100 serait ainsi composé de 16 cores.
Sommaire
Vos réactions
Contenus relatifs
- [+] 10/04: Nvidia : fin du support Fermi et 32...
- [+] 12/03: Nvidia lance les GeForce 800M avec ...
- [+] 08/10: Comparatif : les super GeForce GTX ...
- [+] 24/03: Nvidia répond à AMD avec la GeForce...
- [+] 17/03: Nvidia GeForce GTX 550 Ti et Asus D...
- [+] 28/02: Nvidia annonce CUDA 4.0
- [+] 01/02: Nvidia lance une autre GeForce GT 4...
- [+] 25/01: GeForce GTX 560 Ti contre Radeon HD...
- [+] 24/01: Comparatif : 14 GeForce GTX 460 1 G...
- [+] 07/12: Nvidia GeForce GTX 570