
Nvidia CUDA : l'heure de la concrétisation ?
Publié le 26/07/2008 par Damien Triolet



Et AMD ?AMD, au départ précurseur dans le domaine de l'exploitation des puces graphiques comme unité de calcul, a pris du retard, beaucoup de retard, trop de retard selon nous. Nous évoquions déjà cet état de fait lors de notre dernier article consacré à CUDA et nous réitérons donc nos critiques.
AMD a été le premier à montrer de l'intérêt pour le GPU Computing, AMD a été le premier à présenter des fonctions dédiées dans ses GPUs, AMD a été le premier à supporter le FP64, mais AMD a été incapable de produire rapidement un kit de développement. Aujourd'hui, la situation s'est améliorée, mais nous sommes encore loin du but.
Au départ, AMD, ou plutôt ATI à l'époque, s'est focalisé sur un accès bas niveau à ses GPUs avec la CTM, Close To Metal. Cet accès avait l'avantage d'avoir un accès complet au GPU, mais le désavantage d'être très difficilement utilisable. Plus tard, AMD a proposé CAL, par-dessus la CTM. CAL, Compute Abstraction Layer, est un langage pseudo assembleur indépendant de l'architecture particulière du GPU. Il correspond a peu près au PTX, langage pseudo assembleur intermédiaire de CUDA.
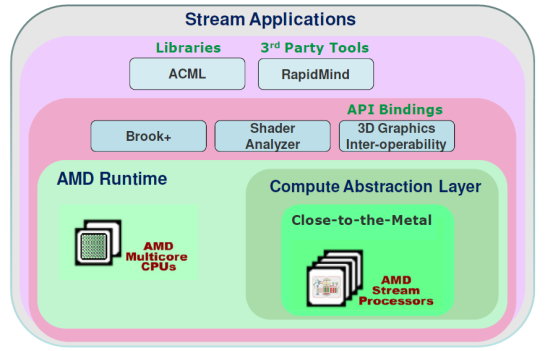
Enfin, AMD propose maintenant un langage de haut niveau, mais ne l'a pas développé comme Nvidia avec CUDA. AMD a choisi de reprendre Brook GPU déjà disponible. Brook GPU est le premier langage qui a été développé pour exploiter les GPUs. Son compilateur se charge de transposer le code proche du C/C++ en code OpenGL, ce qui n'est pas très efficace. AMD a amélioré cela et parle non pas de Brook mais de Brook+, la différence se situant justement à ce niveau puisque avec Brook+ le compilateur produit un code pour CAL et non pour OpenGL.
Brook+ est donc très proche de CUDA, mais n'a pas été développé spécifiquement pour l'architecture des GPUs modernes. Il est donc, selon nos premières impressions, moins efficace.
Notre plus gros reproche à AMD est de n'être toujours pas parvenu à rendre transparente l'utilisation des GPUs comme unité de calcul. L'aspect processeur graphique est très souvent rappelé au développeur. Par exemple, même avec CAL, il faut commencer le kernel en indiquant une version des Pixel Shader ! Il est aberrant que tout ceci n'ait pas été masqué. Et nous passerons certaines instructions qui existent en version _DX9 et en version _DX10
AMD pourrait compenser ce manque flagrant de finition par des documentations de qualité. Mais il faut être réaliste, si AMD n'a pas pu fignoler son interface d'accès, il ne faut pas s'attendre à des miracles au niveau des documentations qui ont un côté très brouillon. Elles sont dans l'état dans lequel nous nous attendions à les trouver il y a plus de 2 ans ! Ca part dans tous les sens. Il y a des documents de tout type, certains se recoupent etc. Certains documents font référence aux GPUs par leur nom commercial (Radeon HD 2900), d'autres par leur nom de code public (R600) et enfin d'autres par leur nom de code interne (Pele). Certains mélangent même plusieurs d'entre eux sans jamais dire à quoi ils correspondent. AMD indique ainsi que les architectures Pele et Boom ont un comportement différent sur certaines instructions, mais ne dit à aucun moment à quoi ils correspondent. Nous savons que Pele est le R600, mais quid de Boom ? RV670 ?
Pour les GPUs plus récents, il n'y a rien de disponible alors que Nvidia a rapidement intégré le support des cartes à base de GT200. Bref, ce n'est pas très sérieux du côté d'AMD et cela témoigne selon nous d'un manque flagrant de ressources. Du coup on se demande si AMD y croit réellement ou continue simplement à faire des annonces dans le GPU Computing histoire de pouvoir dire "moi aussi" A l'exception de quelques développeurs téméraires et du personnel d'AMD, le kit de développement proposé devrait malheureusement rebuter beaucoup de monde.
Sommaire
Vos réactions
Contenus relatifs
- [+] 09/02: Nvidia lance les Quadro Pascal dont...
- [+] 05/04: GTC: Nvidia Tesla P100: 10 Tflops, ...
- [+] 15/12: GPUOpen, la réponse d'AMD à GameWor...
- [+] 16/11: AMD et HPC: nouveaux outils, suppor...
- [+] 09/07: AMD lance la FirePro S9170: Hawaii ...
- [+] 08/12: Nvidia lance la Tesla K80: double G...
- [+] 02/12: IBM Power9 et Nvidia Volta : 100+ p...
- [+] 25/11: Nvidia annonce la Tesla K40 et CUDA...
- [+] 13/11: APU13: HSA: nouveaux membres, Oracl...
- [+] 06/05: AMD hUMA: la mémoire unifiée trouve...