
Nvidia CUDA : plus en pratique
Publié le 09/08/2007 par Damien Triolet



John Stone , Senior Research Programmer dans le département Theorical and Computanional Biophysics du Beckman Institute for Advanced Science and Technology de l'université d'Illinois (UIUC), développeur principal de VMD, et que nous remercions au passage pour son aide, a pu nous fournir de quoi tester les GPUs et les CPUs dans une application pratique et massivement parallèle.
VMD, pour Visual Molecular Dynamics, est un outil qui permet de visualiser, animer et analyser des molécules biologiques énormes. Il est bien entendu capable d'utiliser un GPU pour le rendu de ces molécules, mais également pour la partie analyse et simulation.
Pour étudier une molécule biologique, il faut en général la placer dans un environnement réaliste, c'est-à-dire entourée d'eau et d'ions. Le placement de ces ions est une tâche relativement lourde avec les grosses molécules. La partie la plus exigeante de cette opération est le calcul d'une carte de potentiel coulombique autour de la molécule. C'est cette opération que nous avons testée sur les GPUs et sur les CPUs.
Protocole de testAprès avoir réalisé quelques tests initiaux avec les versions beta de VMD fournies par John, nous avons utilisés les dernières builds compilées pour CUDA 1.0 d'un côté et compilée avec les outils Intel et donc optimisée SSE de l'autre côté. Les algorithmes ont été optimisés pour chaque plateforme et varient donc légèrement. La version CPU fait ainsi appel à plus de précalcul que la version GPU.
VMD en version CUDA a tout d'abord été développé sur base de CUDA 0.8 qui avait besoin d'un core de CPU par GPU piloté. Cette limitation est restée d'application puisqu'elle est à la base même de la structure du code. Qui plus est, l'application divise la tâche à accomplir d'une manière fixe entre les différents CPUs/GPUs. Si l'application détecte 2 GPUs (et assez de cores CPUs pour les gérer), elle va diviser la tâche par 2, peu importe la puissance des GPUs. Autrement dit, un GPU plus rapide qui aurait terminé son travail plus vite devra attendre son collègue plus lent. Utiliser une GeForce 8800 Ultra et une GeForce 8400 GS revient à utiliser 2 GeForce 8400 GS.
Les tests ont été réalisés sous Linux, avec Fedora Core 7. Nous avons testé toute la gamme GeForce 8 (+ le modèle Superclocked d'eVGA) avec un Core 2 Extreme QX6850 équipé de 2 Go de mémoire DDR2 800 MHz, le tout prenant place sur la carte-mère eVGA à base de nForce 680i. Pour les tests du QX6850 et du E6850 nous avons utilisé la même plateforme avec une GeForce 8400 GS.


3 GeForce 8800 contre le V8 d'Intel.
D'autre part, nous avons effectués les mêmes tests sur la plateforme V8 d'Intel qui repose sur 2 Xeon X5365 (quadcore, 3 GHz, identique au QX6850) et le chipset 5000X qui supporte 4 canaux FBDIMM et des FSB distincts pour chacun des CPUs. Les 4 Go de mémoire utilisés reposant sur de la DDR2 à 667 MHz, nous obtenons 5.33 Go/s par canal, soit une bande passante de 21.33 Go/s au total. Notez que cette valeur n'est valable que pour la lecture puisque la bande passant en écriture est réduite de moitié. La GeForce 8400 GS est utilisée ici aussi pour l'affichage.
Nous reportons les résultats obtenus sur la première partie traitée, le traitement de la molécule entière prenant trop de temps.
Les résultatsNous reportons tout d'abord le temps de calcul et le nombre de milliards d'évaluations d'atomes par seconde. Il s'agit des mêmes valeurs mais mises en forme différemment de manière à ce que les performances des extrêmes soient représentées plus clairement.
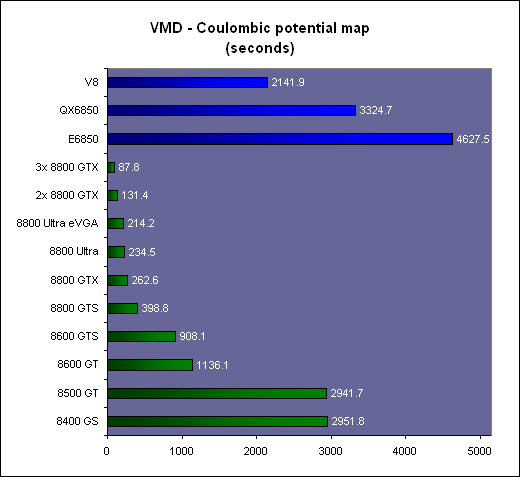
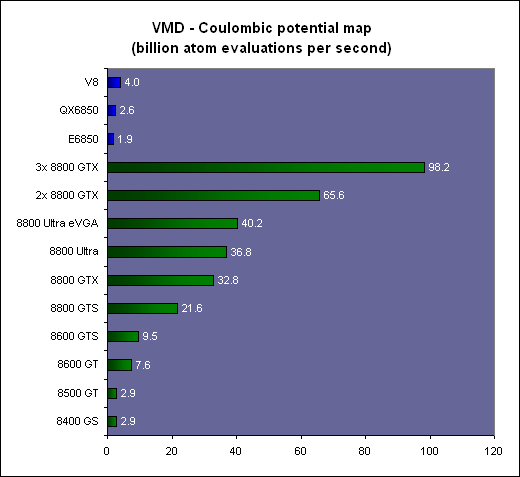
Là où il faut près de 4 minutes à une GeForce 8800 Ultra pour terminer le travail, il faut près d'une heure au Core 2 Extreme QX6850 qui est ici plus lent qu'une GeForce 8400 GS ! Le V8 fait un petit peu mieux mais reste loin de ce que permettent les GPUs haut de gamme dans une application massivement parallèle telle que celle-ci.
Comme vous pouvez le remarquer, les performances scalent presque parfaitement lorsque l'on utilise plusieurs GeForce 8. Par contre ce n'est pas le cas CPUs. Pourquoi ? Nous allons y répondre.
Sommaire
Vos réactions
Contenus relatifs
- [+] 09/02: Nvidia lance les Quadro Pascal dont...
- [+] 05/04: GTC: Nvidia Tesla P100: 10 Tflops, ...
- [+] 15/12: GPUOpen, la réponse d'AMD à GameWor...
- [+] 16/11: AMD et HPC: nouveaux outils, suppor...
- [+] 09/07: AMD lance la FirePro S9170: Hawaii ...
- [+] 08/12: Nvidia lance la Tesla K80: double G...
- [+] 02/12: IBM Power9 et Nvidia Volta : 100+ p...
- [+] 25/11: Nvidia annonce la Tesla K40 et CUDA...
- [+] 13/11: APU13: HSA: nouveaux membres, Oracl...
- [+] 06/05: AMD hUMA: la mémoire unifiée trouve...