
Nvidia CUDA : aperçu
Publié le 02/03/2007 par Damien Triolet



En pratiqueNous avons pu jouer pendant quelques temps avec CUDA, de quoi se faire une petite idée de ce qu'il permet.
Commençons par ce qu'il ne permet pas : profiter simplement d'un système SLI pour doubler la puissance de calcul. Chaque GPU est vu indépendamment des autres et un kernel est exécuté sur un seul GPU. Il faut donc lancer un kernel différent sur chaque GPU pour profiter des systèmes multi-GPU ce qui complique la bonne exploitation de toute la puissance de calcul. Qui plus est, l'exécution d'un kernel est synchrone ce qui veut dire qu'une fois que le CPU a demandé l'exécution du kernel au GPU, le thread et donc le core qui l'exécute va être bloqué jusqu'à ce que le GPU ait terminé son travail. La puissance CPU peut donc être facilement gaspillée en attente au lieu d'être utilisée en complément du GPU. Un point que Nvidia devra améliorer dans le futur sans quoi il faudra autant de cores CPU dans le système (utilisé à ne rien faire !) qu'il y a de GPUs.
Nous avions au départ envisagé de comparer plusieurs algorithmes sur GPU et sur CPU de manière à juger des écarts de performances. Nous sommes cependant rapidement revenus sur cet objectif pour différentes raisons, la principale est que nous n'avons pas la prétention de pouvoir affirmer avoir développer une fonction qui a autant d'efficacité d'un côté comme de l'autre. Autrement dit, si le GPU est plus rapide est-ce parce qu'il est plus performant ou parce que la même fonction a été moins bien optimisée sur le CPU et vice versa. Ensuite, il est facile de prendre un exemple qui sera beaucoup plus rapide sur le CPU et vice versa également. Autrement dit, à moins de passer des semaines voire plus à mettre au point des tests relativement objectifs, ce que nous ne pouvons malheureusement pas nous permettre de faire, il est difficile de comparer directement les performances entre CPU et GPU. Néanmoins nous avons décidé de publier 2 graphes de performances. S'ils représentent le GPU et le CPU, ils ne sont pas destinés à être comparés directement, mais plutôt à montrer comment se comportent les performances d'un côté comme de l'autre avec un paramètre qui varie.
Il convient bien entendu de garder à l'esprit qu'il s'agit ici d'une version beta de CUDA qui verra ses performances progresser avec de nouvelles révisions.
Le premier paramètre que nous avons fait varier est le nombre de blocks. Le nombre total de threads soit d'éléments traités reste identique mais ils sont soit regroupés un 1 seul gros block soit en plusieurs plus petits blocks. Dans le cas du CPU chaque block peut être vu comme un thread et donc être exécuté sur un core différent. Le kernel consiste à effectuer une série d'opérations sur des données et à en écrire le résultat dans une table.
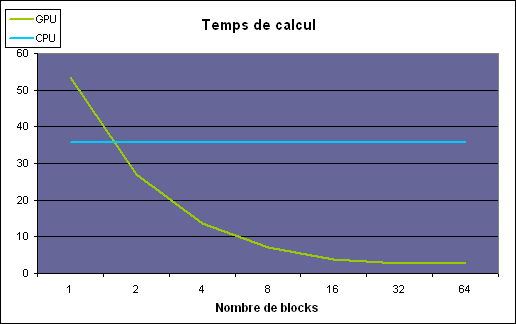
Sur le CPU simple core, peu importe l'organisation, les performances sont identiques. Un CPU quadcore permettrait par contre par exemple de traiter ce type de kernel 4x plus vite à partir de 4 blocks. Dans le cas du GeForce 8800 GTX, il faut au moins 16 blocks pour que les 16 multiprocesseurs soient exploités, et 32 pour qu'ils le soient efficacement. Plus de travail lors du développement mais le gain en performances est conséquent.
Le second test consiste à augmenter la complexité du kernel (soit le nombre d'opérations), le nombre de blocks étant fixé à 32.
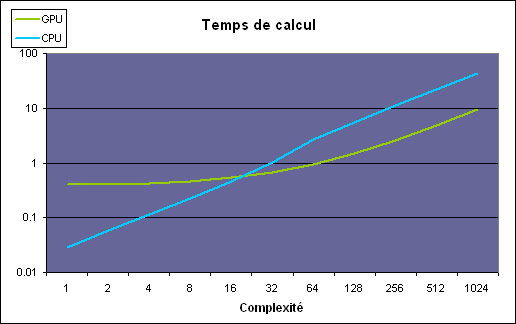
Alors que le temps de calcul augmente linéairement avec le CPU, ce n'est pas le cas sur le GPU en dessous d'une certaine complexité, ce qui indique que le coût de gestion reste élevé et doit donc être amorti sur des opérations complexes. Il ne suffit donc pas de traiter un nombre élevé de données, il faut que ce traitement soit suffisamment complexe pour que le jeu en vaille la chandelle.
Sommaire
Vos réactions
Contenus relatifs
- [+] 09/02: Nvidia lance les Quadro Pascal dont...
- [+] 05/04: GTC: Nvidia Tesla P100: 10 Tflops, ...
- [+] 15/12: GPUOpen, la réponse d'AMD à GameWor...
- [+] 16/11: AMD et HPC: nouveaux outils, suppor...
- [+] 09/07: AMD lance la FirePro S9170: Hawaii ...
- [+] 08/12: Nvidia lance la Tesla K80: double G...
- [+] 02/12: IBM Power9 et Nvidia Volta : 100+ p...
- [+] 25/11: Nvidia annonce la Tesla K40 et CUDA...
- [+] 13/11: APU13: HSA: nouveaux membres, Oracl...
- [+] 06/05: AMD hUMA: la mémoire unifiée trouve...