
Nvidia CUDA : aperçu
Publié le 02/03/2007 par Damien Triolet



L'architecture GeForce 8800 plus en détailBien que contrairement à AMD, Nvidia ait décidé de ne pas proposer de langage de bas niveau accompagné d'une documentation détaillée du hardware, CUDA requiert malgré tout une bonne connaissance du GPU qui est donc décrit par Nvidia dans des termes moins marketing. L'occasion au passage d'apprendre quelques détails de plus sur ce GPU.
Grossièrement le GeForce 8800 a été décrit comme un GPU équipé de 128 processeurs scalaires répartir en 8 partitions de 16 et fonctionnant à très haute fréquence : 1350 MHz. Ces partitions traitent des groupes de 32 pixels ou de 16 vertices.
En réalité les 8 partitions contiennent chacune 2 groupes de 8 processeurs scalaires, ce qui fait du GeForce 8800 GTX une puce équipée de 16 groupes de processeurs. Nvidia appelle ces groupes les multiprocesseurs. Le fait que les multiprocesseurs soient composés de 8 processeurs et non de 16 ne fait pas de différence en termes de performances, il s'agit simplement d'une implémentation destinée à faciliter le fonctionnement à très haute fréquence des unités de calcul. En contrepartie elle requiert plus de transistors.
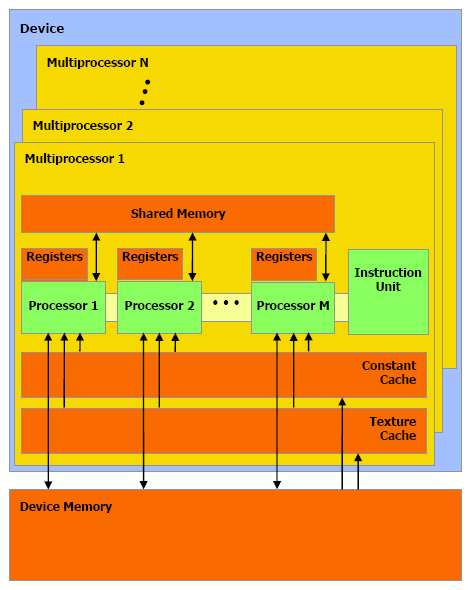
L'architecture GeForce 8 est constituée d'un assemblage de multiprocesseurs qui représentent une unité SIMD composée d'un certain nombre de processeurs.
Dans les documentations de CUDA, les multiprocesseurs ne sont pas décrits comme fonctionnant à 1350 MHz mais bien à 675 MHz avec des unités d'exécution de type "double pumped", c'est-à-dire qui fonctionnent à une fréquence double comme c'était le cas des ALU du Pentium 4. Ces multiprocesseurs traitent des blocs de 64 à 512 éléments appelés threads et répartis en sous-groupes de 32 threads, les warps. Il faut 2 cycles (4x 0.5 cycles étant donné le fonctionnement en mode "double pumped") à un multiprocesseurs pour exécuter une instruction flottante courante sur un warps. Débiter une instruction tous les 2 cycles est plus aisé que de le faire à chaque cycle, ce qui explique le choix de l'utilisation de 2 multiprocesseurs composés de 8 processeurs par partition au lieu d'un seul mais composé de 16 comme supposé à la lecture des documentations initiales sur le GeForce 8800.
Comme nous vous l'avions indiqué dans l'article consacré aux GeForce 8800, il dispose également d'unités de calcul dédiées aux instructions plus complexes (exp, log, sin, cos, rcp, rsq). 2 de ces unités se retrouvent dans chaque multiprocesseurs, en plus de 8 processeurs qui traitent les instructions courantes, les instructions spéciales sont donc 4x plus lentes et il faut 8 cycles pour les exécuter sur un warps entier. Notez que contrairement à ce que l'on retrouve dans les pixels et vertex shaders, les instructions sin, cos et exp sont 2x plus lentes que les 3 autres et prennent donc 16 cycles pour s'exécuter sur les 32 threads des warps. La raison est probablement que dans le cas du rendu 3D ces instructions sont exécutées avec moins de précision mais plus rapidement. Nvidia précise d'ailleurs que la plupart des instructions peuvent être exécutées dans un mode de précision plus réduit mais plus rapide.
Les multiplications entières sont elles aussi traitées par ces 2 unités et prennent donc 8 cycles. Une version de moindre précision (24 bits au lieu de 32 bits) peut par contre s'exécuter sur les 8 processeurs classiques soit en 2 cycles du point de vue du multiprocesseur.
En résumé, le GeForce 8800 GTX peut être vu comme une grosse unité de calcul divisée en 16 multiprocesseurs qui traitent des groupes de warps de 32 threads à travers 8 processeurs généraux et 2 processeurs spécialisés. Ces 16 multiprocesseurs cadencés à 675 MHz permettent ensemble de traiter tous les 2 cycles 1 instruction courante sur 512 threads, soit un débit de 256 opérations par cycle (512 opérations flottantes dans le cas des FMAD/FMAC qui représentent une multiplication + une addition), ce à quoi il faut ajouter jusqu'à 64 opérations spéciales. Un Core 2 Duo, vu à travers les unités SSE de ses 2 cores est capable de traiter 16 opérations par cycle (8 additions et 8 multiplications). Par contre il fonctionne à une fréquence bien plus élevée que 675 MHz mais ne traite pas les opérations FMAD/FMAC à pleine vitesse puisqu'il doit avoir recours à 2 unités pour traiter une opération de ce type.
Le tableau suivant représente la puissance de calcul des GeForce 8800 et des 2 Core 2 Extreme d'Intel dans 4 cas : multiplication flottante, addition flottante, la moitié de chaque (le meilleur cas pour les Core 2) et multiplication-addition flottante (le meilleur cas pour les GPUs puisque toutes ses unités gèrent cette instruction).

Les GeForce 8800 disposent donc clairement d'une puissance de calcul supérieure à celles des Core 2, y compris le quadcore. Néanmoins, la différence n'est pas toujours énorme. Entendez par là que ces chiffres laissent penser qu'il faut réellement exploiter efficacement un GeForce 8800 pour qu'il surpasse un processeur quadcore. Ceci étant dit il faut garder en tête que les GeForce 8800 peuvent traiter en plus et relativement rapidement des opérations plus complexes et également utiliser leurs unités de filtrage des textures pour accélérer certaines opérations. Si un algorithme permet d'exploiter les capacités tierces des GPUs les performances peuvent s'envoler par rapport au CPU.
Sommaire
Vos réactions
Contenus relatifs
- [+] 09/02: Nvidia lance les Quadro Pascal dont...
- [+] 05/04: GTC: Nvidia Tesla P100: 10 Tflops, ...
- [+] 15/12: GPUOpen, la réponse d'AMD à GameWor...
- [+] 16/11: AMD et HPC: nouveaux outils, suppor...
- [+] 09/07: AMD lance la FirePro S9170: Hawaii ...
- [+] 08/12: Nvidia lance la Tesla K80: double G...
- [+] 02/12: IBM Power9 et Nvidia Volta : 100+ p...
- [+] 25/11: Nvidia annonce la Tesla K40 et CUDA...
- [+] 13/11: APU13: HSA: nouveaux membres, Oracl...
- [+] 06/05: AMD hUMA: la mémoire unifiée trouve...