
Nvidia CUDA : aperçu
Publié le 02/03/2007 par Damien Triolet



PrécisionLorsqu'il s'agit de calcul général, la précision et le comportement détaillé des unités de calcul doivent être connus et pour bien faire conformes aux standards IEEE. Le GeForce 8800, tout comme tous les autres GPUs actuels, n'est pas complètement conforme puisqu'il ne gère pas les nombres dénormalisés et propose une précision moindre sur certaines opérations. Nvidia documente en détail le comportement de ses unités de calcul, ce qui permet de savoir quand celui-ci s'écarte de ce que l'on retrouve sur un CPU :

Par ailleurs, les unités sont limitées à la simple précision (FP32), mais il est probable que la prochaine génération supporte les doubles (FP64) comme c'est le cas sur les CPUs.
Mémoire localeLes processeurs du GeForce 8800 supportent le gathering et le scattering soit la capacité de lire et d'écrire n'importe où en mémoire locale (sur la carte graphique) ou globale (étendue à une partie de la mémoire du système).
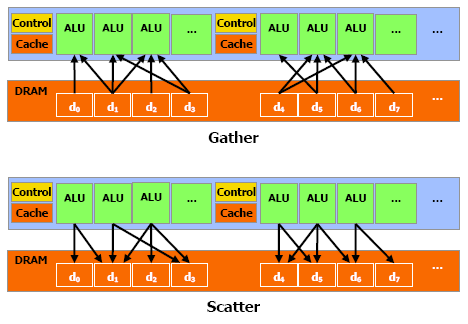
Cependant, ces mémoires ne sont pas cachées et le GeForce 8800 paye donc le prix fort de la latence de ces lectures/écritures qui varie entre 200 et 300 cycles ! Dans le cas où de nombreuses instructions mathématiques à traiter ne dépendent pas d'une lecture, elles serviront à masquer cette latence.
Mémoire partagéeNéanmoins, il faudra éviter au maximum ces lectures et écritures en mémoire locale ou globale. Pour ce faire, chaque multiprocesseur dispose d'une petite mémoire dédiée de 16 Ko appelée mémoire partagée. Celle-ci permet de rompre en partie les limitations imposées par un traitement parallèle des threads en leur permettant de communiquer et donc d'interagir entre eux rapidement, sans passer par la mémoire de la carte graphique.
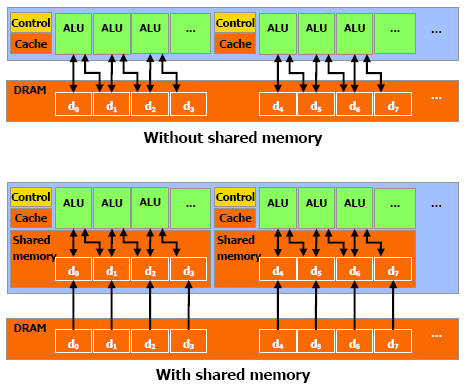
La mémoire partagée, en plus d'éviter l'énorme latence de la mémoire locale ou globale permet d'économiser de la bande passante mémoire, en réduisant les accès à celle-ci de 33% dans cet exemple.
Cette mémoire partagée ne l'est cependant que pour les éléments d'un même block ! Autrement dit, plus de threads par block signifie moins de mémoire par thread et moins de threads par block signifie que moins de thread vont pouvoir communiquer. Qui plus est, il est en général conseillé de permettre à chaque multiprocesseur de travailler sur plusieurs blocks de manière à pouvoir traiter un second block quand le premier est en pause et ainsi éviter de gaspiller des ressources. Ce qui réduit encore la taille relative de cette mémoire partagée. Elle sera ainsi de 8 Ko par block dans le cas classique et conseillé où 2 blocks se trouvent dans chaque multiprocesseur.
L'utilisation de cette mémoire partagée est très réglementée. Pour illustrer cet état de fait voici quelques détails pour les plus courageux. Elle est divisée en 16 banques mémoire. A chaque cycle il est possible d'accéder à chacune de ces banques via 16 bus internes de 32 bits (soit 512 bits en tout!). Etant donné qu'une instruction d'accès à cette mémoire est traitée par warps soit par groupe de 32 threads, ce sont 32 accès à la mémoire en 2 cycles qui doivent être traités. Pour les 16 premiers threads ce sera fait pendant le premier cycle et pour les 16 suivant pendant le second cycle. 2 accès simultanés à la même banque mémoire ne peuvent pas être traités lors d'un même cycle. Les 16 premiers (ou derniers) threads doivent donc tous accéder à une banque différente sans quoi plusieurs cycles sont nécessaires. Notez qu'il est cependant autorisé que tous les threads accèdent à la même banque. Cela exprime bien la complexité de l'utilisation de cette mémoire partagée si l'on veut maximiser les performances. Il ne s'agit pas d'une mémoire cache comme c'est le cas sur un CPU, elle est plus proche de la mémoire locale des SPEs du Cell par exemple.
Mémoire cache, registres et constantesLe GPU dispose d'une mémoire cache au niveau des unités de texturing. Celles-ci peuvent donc être utilisées, lorsque les accès sont bien alignés, pour lire (mais pas écrire) efficacement des données. Cette mémoire cache est de 8 Ko par multiprocesseur.
Chaque multiprocesseur dispose d'un certain nombre (non dévoilé) de registres généraux. Les threads en cours de traitement doivent se les partager. Plus il y a de threads, mieux la latence de certains opérations est masquée mais moins ils disposent de registres. C'est un paramètre important qui peut avoir une forte influence sur les performances. CUDA permet de le contrôler.
Le GeForce 8800 dispose d'une mémoire supplémentaire de 64 Ko qui stocke les constantes. Cette mémoire est cachée à hauteur de 8 Ko par multiprocesseur.
Mémoire locale, mémoire globale, mémoire partagée, mémoire cache des unités de texturing, mémoire cache des constantes et registres : de quoi entraîner quelques calvities chez les développeurs qui essayeront d'en tirer le meilleur parti !
Sommaire
Vos réactions
Contenus relatifs
- [+] 09/02: Nvidia lance les Quadro Pascal dont...
- [+] 05/04: GTC: Nvidia Tesla P100: 10 Tflops, ...
- [+] 15/12: GPUOpen, la réponse d'AMD à GameWor...
- [+] 16/11: AMD et HPC: nouveaux outils, suppor...
- [+] 09/07: AMD lance la FirePro S9170: Hawaii ...
- [+] 08/12: Nvidia lance la Tesla K80: double G...
- [+] 02/12: IBM Power9 et Nvidia Volta : 100+ p...
- [+] 25/11: Nvidia annonce la Tesla K40 et CUDA...
- [+] 13/11: APU13: HSA: nouveaux membres, Oracl...
- [+] 06/05: AMD hUMA: la mémoire unifiée trouve...