Les contenus liés au tag HSA
Afficher sous forme de : Titre | FluxAMD hUMA: la mémoire unifiée trouve un nom



Il y a près de 2 ans, AMD avait dévoilé ses plans concernant l'évolution de la plateforme GPU computing pour une exploitation en symbiose plus simple et plus efficace des cores GPU et CPU. Cette plateforme dénommée HSA (Heterogeneous System Architecture) a pour rappel été ouverte par AMD et transférée à un consortium chargé d'en finaliser les spécifications et de poursuivre son développement tant logiciel que matériel. Une approche qui a permis de rallier de nombreux acteurs importants, issus du monde ARM, à la cause d'AMD.
Si en pratique AMD reste le pilote au niveau de la HSA, en finaliser les spécifications à plusieurs a entraîné plusieurs retards, notamment sur la publication des différentes documentations et des premiers outils complets à destination des développeurs. Tout cela semble cependant commencer à se préciser.
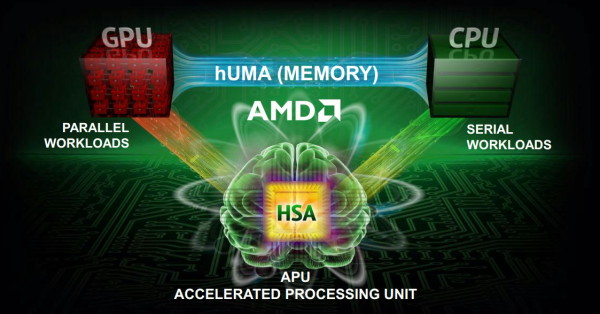
AMD a récemment donné un nom commercial à l'une des évolutions les plus importantes qui seront apportées par la HSA : l'unification de l'espace mémoire entre CPU et GPU pour simplifier le travail des développeurs et améliorer les performances notamment en supprimant des déplacement de données inutiles.
Pour représenter l'unification de la mémoire entre le CPU et le GPU, AMD s'est inspiré des acronymes tirés du SMP : UMA (Uniform Memory Architecture), une seule mémoire physique partagées par les cores CPU, et son évolution NUMA (Non Uniform Memory Architecture), plusieurs mémoires physiques partagées par les cores CPU. Dans un système multi-socket, NUMA permet à chaque CPU de disposer de son propre contrôleur mémoire et de sa propre mémoire, tout en gardant un espace mémoire unifié mais bien entendu sans garantir des performances homogènes sur l'ensemble de celui-ci.
Préparée et annoncée (voire réannoncée régulièrement) par AMD, Nvidia et même Intel, l'unification de l'espace mémoire entre les CPU et les GPU est une évolution logique et primordiale de (N)UMA vers le GPU computing. AMD a ainsi décidé de la nommer hUMA pour Heterogeneous Uniform Memory Architecture. Notez qu'en principe, dans le cas d'un GPU non-intégré, il serait plus correct de parler de hNUMA, puisque la mémoire est non-uniforme, mais nous ne savons pas si AMD prévoit de faire cette distinction.
En réalité, nous ne savons pas grand chose sur les détails, AMD n'ayant strictement rien dévoilé de neuf en dehors de l'acronyme hUMA. Si les aspects pratiques d'une mémoire virtuelle unifiée sont logiques dans le cas d'un APU ou de tout CPU avec GPU intégré, de nombreuses questions se posent par rapport aux GPU externes. Le support au niveau des OS est également un point important puisque leurs gestionnaires mémoire devront être revus pour la supporter.
Pour que la HSA et les produits qui l'implémenteront puissent réellement ouvrir de nouvelles portes et trouver un certain succès, il est important qu'AMD fournisse dès que possible tous les outils et toute la documentation nécessaires aux développeurs. Inutile de dire que cela demandera plus que de faire de la communication pour de la communication autour d'un nouvel acronyme pour représenter l'espace mémoire unifié.
Notez qu'AMD a récemment reporté son forum technologique dédié au GPU Computing de juin à septembre. Il change au passage de nom pour abandonner sa composante Fusion et devenir l'AMD Developer Summit (APU13 en abrégé). Il devrait laisser plus de visibilité aux autres membres de la HSA Foundation et enfin être le lieu de la concrétisation de cette plateforme.
Si vous désirez en savoir plus concernant la HSA et la mémoire unifiée, c'est un whitepaper de l'été 2012 qui reste le plus complet. Vous pourrez le consulter ici .
AMD Kaveri et Steamroller repoussés ?
Lancée en 2011 avec Bulldozer, l'architecture CMT d'AMD devait connaitre plusieurs évolutions :
- Piledriver en 2012
- Steamroller en 2013
- Excavator en 2014
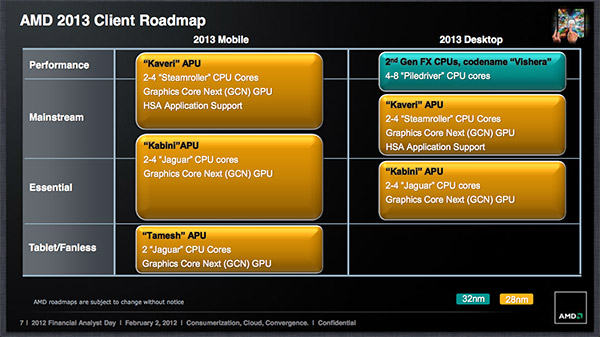
La dernière roadmap publique datant de février faisait en fait mention pour 2013 uniquement d'un APU doté de Steamroller en 2013, Kaveri, qui devait au passage profiter de curs graphiques de type "GCN" comme les Radeon 7000 et être gravé en 28nm.

DonanimHaber a mis les mains sur une roadmap plus récente sur laquelle Kaveri est absent en 2013. A la place, on trouve Richland, une évolution de Trinity utilisant toujours des curs x86 PileDriver et des curs graphiques dénommés "Radeon Cores 2.0" qui sont a priori encore des VLIW4 (en opposition au VLIW5 utilisés sur Llano).
Rien de bien neuf donc si ce n'est la mention d'amélioration au niveau de l'HSA, peut-être l'unification de l'espace mémoire entre CPU et GPU dont il était question ici pour 2013. Rien n'est indiqué concernant le process utilisé pour cet APU. Côté AM3+, comme en février on reste sur Vishera, alors que sur l'entrée de gamme l'APU Kabini et ses curs Jaguar remplaceront Brazos 2.0 et ses curs Bobcat.
Voilà une mauvaise nouvelle qui risque de mettre AMD dans une situation difficile face à l'offensive Haswell d'Intel, prévue pour le second trimestre 2013.
HSA, calcul hétérogène: Intel et Nvidia isolés?
Début juin, AMD inaugurait la HSA Foundation en partenariat avec ARM, Imagination Technologies, MediaTek et Texas Instruments. Cette fondation a pour rappel comme objectif de concevoir des standards dédiés au calcul hétérogène qu'ils concernent l'aspect programmation ou l'implémentation matérielle. Coup sur coup, elle vient d'accueillir de nouveaux membres importants.
ATI, avant d'être englobé par AMD, avait été le premier à nous faire part de l'ambition d'utiliser la puissance de calcul des GPU à d'autres fins que le rendu 3D en temps réel pour lequel ils ont à l'origine été conçus. Probablement par manque de moyens, ces développements ont avancé très lentement et il aura fallu attendre plus d'un an avec la concrétisation de l'initiative similaire de Nvidia pour que le GPU mette enfin un pied dans la porte du monde du calcul haute performance. Disponible dès début 2007, CUDA a ainsi relégué au second plan toute initiative similaire de la part d'ATI/AMD.
Quelques tergiversations au niveau des choix technologiques et des langages de programmation, ainsi que l'intégration d'ATI dans AMD, ont par la suite empêché toute avancée rapide. Il faut dire qu'avec le projet Fusion d'AMD, l'objectif n'était plus simplement d'exploiter le GPU, mais de profiter de la symbiose GPU + CPU. Par ailleurs AMD a fait le choix, probablement par défaut, de se reposer sur des standards ouverts. A l'inverse, Nvidia a opté pour une approche propriétaire qui lui a permis d'être plus agile et surtout beaucoup plus rapide dans ses développements.
Entre le monde x86 largement dominé par Intel, et le calcul sur GPU dominé par Nvidia, AMD s'est retrouvé dans une situation délicate dans laquelle il était devenu difficile de peser sur les choix technologiques des développeurs et donc de les inciter à programmer pour ses solutions hétérogènes.
Pour sortir de cette impasse, AMD avait besoin de rallier d'autres acteurs à sa cause. Proposer un standard d'architecture pour le calcul hétérogène était une solution naturelle à ce problème, d'autant plus qu'il allait devenir essentiel pour de nombreux autres acteurs : les concepteurs de SoC ultra basse consommation. Lorsque l'enveloppe thermique est limitée, comme c'est le cas pour tous les périphériques mobiles, pouvoir exploiter différents types de curs destinés au calcul (séquentiel ou massivement parallèle) permet de maximiser les performances dans plus de cas de figure. En d'autres termes, tout l'écosystème ARM était voué à exploiter le calcul hétérogène et allait faire face aux mêmes problèmes qu'AMD lorsqu'il s'agirait de trouver la meilleure approche pour le mettre en place.
Mi-2011, AMD a ainsi proposé la FSA, Fusion System Architecture, comme base de travail, avec en coulisse le support d'ARM. Un an plus tard, après un changement de nom pour HSA, Heterogeneous System Architecture, AMD a remis tous ses travaux initiaux à une fondation dont les membres fondateurs initiaux incluaient également ARM, Imagination Technologies, MediaTek et Texas Instruments. Les statuts de la fondation laissaient cependant la possibilité à d'autres acteurs de devenir des membres fondateurs s'ils se manifestaient dans les 3 mois, à partir du 1er juin 2012.
A quelques jours de l'échéance, Samsung a ainsi rejoint la fondation en tant que sixième membre fondateur, accompagné par Apical, Arteris, MulticoreWare, Sonics, Symbio et Vivante en tant que membres secondaires. Si l'arrivée d'un poids lourd tel que Samsung était une bonne nouvelle pour la HSA, l'absence de Qualcomm était étonnante. Avec des objectifs très importants au niveau des capacités de ses SoC, et l'arrivée à la tête de son département d'ingénierie d'Eric Demers, l'ancien responsable des architectures GPU d'AMD, il ne faisait aucun doute que Qualcomm voudrait rejoindre la HSA
et pas en tant que membre secondaire.
Les négociations ont probablement été plus compliquées et longues que prévues, mais ont fini par aboutir et la HSA Foundation a modifié ses statuts de manière à faire disparaître la date limite pour l'entrée de nouveaux membres fondateurs. Hier, Qualcomm est ainsi devenu le septième membre fondateur.

En s'adjoignant le poids de presque tout l'écosystème ARM, AMD ne pouvait probablement pas trouver de meilleure approche pour le développement d'un standard dédié au calcul hétérogène et la présentation graphique du site de la fondation ne laisse guère de doute concernant le fait que la porte reste ouverte pour un huitième membre principal. S'il faudra encore convaincre certains acteurs importants tels qu'Apple ou Microsoft, les grands absents restent Intel et Nvidia.
Ceux-ci, d'une part par égo vis-à-vis d'AMD et d'autre part pour ne pas faciliter l'arrivée de concurrence sur des marchés très juteux, restent hostiles à l'arrivée d'un tel standard. Intel veut conserver un contrôle total de sa plateforme, proposer ses propres solutions destinées au calcul massivement parallèle et favoriser l'utilisation des cores x86 qui sont en train de gagner beaucoup en efficacité énergétique. De son côté, Nvidia n'entend pas saboter les premiers succès commerciaux de sa division Tesla liée à l'architecture propriétaire CUDA, et prépare sa propre solution hétérogène.
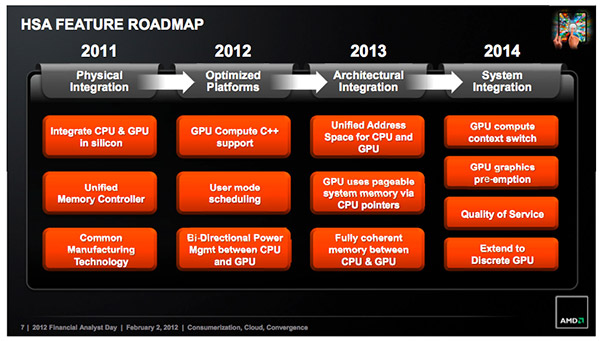
Pour éviter de se retrouver isolés du reste de l'industrie, nul doute cependant qu'Intel et Nvidia vont suivre de très près l'évolution de la HSA ainsi que ses premières spécifications. Annoncées pour fin 2011, elles ont pris du retard mais seraient maintenant entre les mains de l'ensemble des membres de la fondation pour une publication avant la fin de cette année.
AFDS: AMD, ARM, ImgTech, TI : HSA Foundation

L'AMD Fusion Developer Summit, un forum technologique dédié au calcul hétérogène, a actuellement lieu à Seattle. Ce forum peut être vu comme la réplique d'AMD à la GPU Technology Conference de Nvidia qui s'est tenue le mois passé, mais un point important distingue cependant les deux évènements : AMD conçoit autant des cores CPU que des cores GPU. Plus que le calcul massivement parallèle, qui exploite les GPU, c'est ainsi le calcul hétérogène qui est ici à l'honneur.
Exploiter en symbiose des cores CPU et des cores GPU est complexe, notamment parce qu'ils ne partagent pas encore un espace mémoire totalement unifié, même si l'APU Trinity apporte quelques avancées à ce niveau. L'an passé, AMD avait annoncé la Fusion System Architecture, une tentative d'apporter des réponses à cette problématique de manière à pouvoir fournir une plateforme plus simple à exploiter pour un maximum de développeurs. AMD avait alors précisé vouloir en faire un standard ouvert : publier une documentation complète avant la fin 2011 et mettre en place un consortium pour gérer la FSA.
AMD a pris du retard sur la documentation qui n'est toujours pas disponible, mais a entretemps renommé la FSA en Heterogeneous System Architecture de façon à la détacher de sa marque Fusion. Il y a quelques mois, AMD précisé ses plans au sujet du consortium qui se dénommerait HSA Foundation et se verrait transférer tous ses travaux initiaux.
Cette édition de l'AFDS est l'occasion pour AMD de concrétiser la mise en place de la HSA Foundation, qui est effective depuis quelques jours. Il s'agit d'une organisation à but non-lucratif qui sera dorénavant chargée du développement et de la promotion de ce standard ouvert destiné à simplifier le calcul hétérogène qu'il concerne les PC, les smartphones ou les serveurs. Sa tâche sera également de produire des outils de développements efficaces et d'aider à la formation des développeurs.


AMD transfère à cette fondation la totalité de ses travaux initiaux sur la FSA/HSA, à savoir : un compilateur open source, des librairies et les documentations préliminaires qui concernent la programmation, les spécifications hardware ainsi que les spécifications software. AMD fournis par ailleurs une partie des fonds pour la mise en place de la fondation.
La fondation est bien entendu destinée à accueillir un maximum de membres, qui pourront être de plusieurs types : fondateurs (ce qui est encore possible s'ils y sont invités dans les 90 jours), promoteurs, supporters, contributeurs, universitaires et autres associés. Comme c'est généralement de mise pour ce type d'organisation, chaque membre participe à son budget de fonctionnement suivant son rôle, ce qui représente jusqu'à 125.000$ par an pour les membres fondateurs.

Les représentants des cinq membres fondateurs de la HSA Foundation, qui forment son conseil d'administration actuel.
La mise en place de la HSA Foundation n'aurait pas pu se faire sans son élargissement à d'autres grands noms de l'industrie. La présence d'ARM à l'AFDS l'an passé ne laissait aucun doute sur l'intérêt de la société spécialisée dans les modules destinés au SoC, pour laquelle le calcul hétérogène est la seule solution viable sur le plan énergétique, et c'est donc sans surprise qu'ARM fait partie des membres fondateurs de la fondation. D'autres ont rejoint l'initiative et sont tous liés aux SoC d'une manière ou d'une autre : Imagination Technologies, MediaTek et Texas Instruments.
Chacune de ces sociétés disposera d'un membre au conseil d'administration de la fondation (Manju Hedge, Vice-Président des solutions développeurs destinées au calcul hétérogène chez AMD et ex-CEO d'Ageia; Jem Davies Vice-Président responsable de la division Media Processing chez ARM ) qui sera gérée au quotidien par Phil Rogers, Président de la HSA Foundation et AMD Corporate Fellow.
Reste bien entendu que d'autres grands noms sont malheureusement absents du tableau, tels que Nvidia et surtout Intel. Les membres fondateurs ne désespèrent pas à l'idée de les voir rejoindre l'initiative, sans cependant se faire d'illusion à ce sujet. Mais ce sont, avant tout autre chose, les développeurs qu'ils devront s'attacher à convaincre et pour cela, comme le rappelait Adobe présent également à l'AFDS, il faudra leur proposer des outils complets, performants, simples d'utilisation et fiables. Un gros chantier en perspective.
Vous pourrez retrouver toutes les informations disponibles actuellement sur le site de la HSA Foundation qui vient d'être mis en ligne mais la documentation complète se fait cependant toujours attendre.
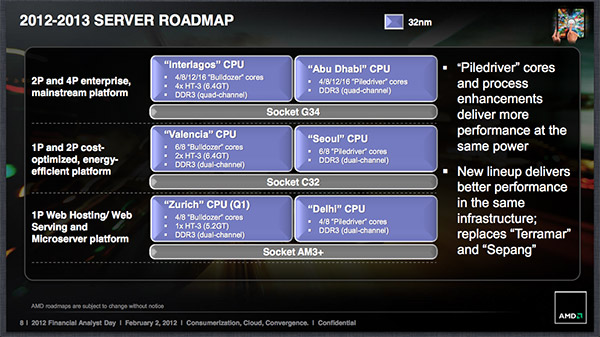
AMD détaille sa roadmap 2012-2013
AMD a donné hier sa conférence annuelle destinée aux analystes financiers, l'occasion de donner quelques détails sur ses produits à venir.

2012 sera marqué par plusieurs nouveautés, avec côté desktop la seconde génération de processeur AMD FX dont le nom de code est Vishera et qui disposera de 4 à 8 curs de type Piledriver, une évolution de l'actuelle architecture Bulldozer qui devrait être compatible avec les cartes AM3+ actuelles. AMD n'a toutefois pas donné de détail supplémentaire sur ces processeurs. Le focus se fait plutôt sur Trinity côté Desktop comme Mobile, cette APU qui devrait arriver au second trimestre intégrera pour rappel 2 à 4 curs Piledriver et un nouveau GPU plus véloce que celui de Llano.
Du côté des APU d'entrée de gamme Brazos sera remis au gout du jour avec une version 2.0 intégrant un mode Turbo et associé à une plate-forme proposant l'USB 3. On notera l'arrivée de Hondo, toujours basé sur l'architecture Bobcat et offrant un TDP de 4.5w pour les tablettes. Il sera associé au sein de la plate-forme Brazos-T à un chipset ayant un TDP de 1w.
2013 sera l'année de deux évolutions architecturales côté CPU. Piledriver sera tout d'abord remplacé par Steamroller sur un nouvel APU, Kaveri. Ce dernier intégrera en plus un GPU d'architecture GCN (comme les Radeon 7970) et sera gravé en 28nm avec a priori le process bulk de Global Foundries au lieu du 32nm SOI à l'heure actuelle, ce qui devrait simplifier le design des puces. L'autre évolution c'est l'architecture Jaguar qui viendra remplacer Bobcat sur les APU d'entrée de gamme. Kabini combinera 2 à 4 curs Jaguar avec un GPU de type GCN, une version basse consommation, Temash, étant également prévue. Il faudra a priori attendre 2014 pour voir éventuellement débarquer Steamroller sur un CPU seul.

Côté graphique AMD se contente d'annoncer une nouvelle architecture pour 2013 dénommée Sea Island qui sera dotée de fonctionnalité HSA (Heterogeneous Systems Architecturen, le nouveau nom pour Fusion). A ce propos, après avoir intégré physiquement CPU et GPU au sein d'un même die sur les APU, AMD compte pousser plus loin dans les années à venir l'intégration avec notamment en 2013 un espace mémoire unifié entre CPU et GPU.

Enfin côté serveur AMD fera évoluer en 2012/2013 les processeurs Interlagos et Valencia respectivement destinés aux Socket G34 et C32 vers les Abu Dhabi et Seoul qui disposeront de la nouvelle architecture Piledriver. Les Terramar et Sepang, qui devaient atteindre 20 et 10 curs, sont donc abandonné et on ne connaitra pas d'évolution en terme de nombre de curs, la suite logique de l'annulation de Komodo 10 curs sur desktop. Les plates-formes actuelles seront compatibles avec ces nouveaux processeurs, il en vas de même pour Delhi qui viendra prendre place sur AM3+.