
Les contenus liés aux tags Kepler et GK110
Afficher sous forme de : Titre | FluxDossier : Nvidia GeForce GTX Titan en test : big Kepler débarque enfin !



Le GK110, ou big Kepler et ses 7.1 milliards de transistors, débarque dans la GeForce GTX Titan avec laquelle Nvidia vise la première place, sans faire exploser la consommation et, mieux, en réduisant les nuisances sonores.
[+] Lire la suite

Nvidia dévoile la GeForce GTX Titan
C'est ce mardi que Nvidia a finalement décidé de lever le voile sur la GeForce GTX Titan, l'incarnation grand public du GPU GK110 présenté en mai dernier et commercialisé en tant que Tesla K20 / K20X depuis quelques mois.
Notez qu'il n'y aura pas de mesures de performances et autres tests aujourd'hui mais seulement une présentation de la carte, Nvidia ayant opté pour un lancement en deux temps. Le test complet est prévu pour jeudi. Nous sommes loin d'être fans de cette approche qui nous met dans une position ridicule puisque nous avons déjà testé la carte
et que ces tests, dont nous ne pouvons pas encore vous parler, apportent des éléments d'information essentiels par rapport à la description officielle.
Officiellement ce décalage est destiné à laisser plus de temps pour les tests, les cartes et pilotes ayant été reçus plus tard que prévu, et le constructeur met en avant la difficulté de décaler le lancement de ce jour du fait des implications chez ses partenaires. D'un autre côté nous pouvons supposer qu'un tel lancement en deux temps permet à Nvidia de faire plus de bruit et de mieux contrôler la première impression que vous aurez de la carte...
Quelles que soient les raison de cette approche, elle nous dérange puisqu'elle ne nous permet pas de présenter les choses aux mieux de nos connaissances. Nous éviterons donc de donner le moindre avis aujourd'hui et nous vous conseillerons vivement d'attendre les tests complets pour former votre avis, et si la carte vous intéresse, de ne pas sauter aveuglément sur d'éventuelles précommandes.

La GeForce GTX Titan reprend un design similaire à celui de la GeForce GTX 690 : des matériaux de qualité pour une finition exemplaire. Le tarif est équivalent lui aussi, à près de 1000 TTC. Cela ne veut pas dire que les deux cartes sont équivalentes en termes de performances, la GTX 690 va garder la tête, mais que Nvidia estime que le mono-GPU a une valeur relative plus élevée. Vous noterez que la carte ne prend pas place à l'intérieur de la gamme actuelle, d'où son nom différent, ce qui indique probablement que la GTX Titan restera supérieure à la probable future GeForce GTX 780.

Le GK110 embarqué, 7.1 milliards de transistors et 569 mm² en 28nm, est partiellement castré puisqu'il se contente de 14 SMX actifs sur les 15 qu'il intègre, soit 2688 unités de calcul sur 2880, un choix dicté par les impératifs de production pour une puce aussi large. Il conserve son bus mémoire de 384-bit qui s'interface à pas moins de 6 Go de GDDR5 cadencée à 1503 MHz, de quoi offrir un gain de 50% au niveau de la bande passante par rapport à la GeForce GTX 680.
La fréquence de base du GPU est de 837 MHz mais il dispose d'un turbo, dénommé GPU Boost. Officiellement il est annoncé à 876 MHz, mais comme pour les autres cartes de la génération Kepler, il est en réalité variable d'un exemplaire à l'autre. Nvidia indique que la fréquence du plus mauvais exemplaire dépasse 876 MHz mais refuse de communiquer le chiffre exact. Nous supposerons donc qu'il s'agit de 889 MHz, le premier pallier au-dessus de la fréquence annoncée.
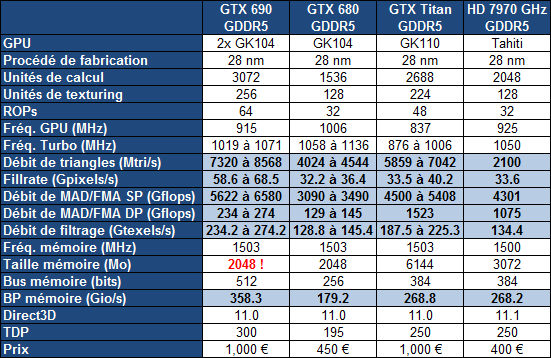
Avec certains échantillons qui peuvent dépasser le GHz, la marge de variation peut ainsi être énorme ! Entre un bon échantillon de GTX 680 et un mauvais de Titan, la puissance de calcul théorique va progresser de 30% alors qu'entre un mauvais échantillon de GTX 680 et un très bon de Titan, elle pourra atteindre 75%. C'est le fillrate qui progresse le moins, puisqu'il ne passe "que" de 32 pixels par cycles à 40 pixels par cycle (bien qu'équipé de 48 ROP, le GK110 ne dispose que de 5 rasterizers capables chacun de générer 8 pixels).
Nvidia a voulu démontrer qu'il était possible d'exploiter un GPU aussi monstrueux que le GK110 sans faire exploser les nuisances en termes de bruit et de température. Ce dernier point est un élément essentiel pour la GeForce GTX Titan. Nvidia rappelle que températures et tensions élevées ne font pas bon ménage quand il s'agit de garantir la durée de vie d'un composant, ce qui concerne visiblement particulièrement le GK110. Ainsi, la limite de température visée par GPU Boost, soit la limite au-delà de laquelle le turbo ne peut pas s'enclencher passe de 95 °C sur une GTX 680 à 80°C seulement. La limite de consommation pour le turbo passe par contre de 170 à 235W, alors que le TDP passe de 195 à 250W, une valeur identique à celle de la Radeon HD 7970.
En pratique la limite de 95°C de la GTX 680 n'était que rarement un facteur limitant, et elle est d'ailleurs masquée par Nvidia. Avec 80°C pour la GTX Titan, la donne change et la température pourra avoir un aspect déterminant sur les performances. Cette limite de 80°C devient d'ailleurs un paramètre d'overclocking destiné à prendre place dans les utilitaires tels que Precision X.
Petite surprise, Nvidia a décidé de ne pas bloquer l'accès aux unités de calcul double précision du GK110. Un mode spécial doit cependant être activé dans les pilotes et précisons qu'il fixe la fréquence GPU à 850 MHz. La GTX Titan est ainsi capable de les traiter avec un débit équivalent à un tiers du débit en simple précision, contre 1/24ème sur les GTX 600. Rappelons qu'en dehors de la double précision, l'architecture du GK110 est identique à celle des autres GPU Kepler. Il a été pensé en priorité pour offrir plus de performances à tous les niveaux et ensuite à être polyvalent dans les domaines professionnels, exactement comme pour les GPU GT200, GF100, Cayman et Tahiti.
Rendez-vous jeudi pour un test complet de la GeForce GTX Titan !
Tesla K20 et GK110 : les specs finales ?
Comme vous devez le savoir, Nvidia prévoit de commercialiser à partir du mois de décembre la première carte basée sur le gros GPU Kepler, le GK110 et ses 7.1 milliards de transistors. Dénommée K20, elle prend place dans la gamme Tesla destinée au calcul intensif.
Certains gros clients ont reçu les premiers échantillons de la part de Nvidia et les détails commencent à fuiter. Citons par exemple le cas d'Oak Ridge National Laboratory qui est en train de faire évoluer son supercalculateur Cray XT5, dénommé Jaguar, en remplaçant progressivement ses 18688 nuds par des plateformes XK6 équipées d'Opteron 6274 Bulldozer. 14592 de ces nuds sont voués à recevoir un accélérateur Tesla K20.

heise online a pu relever, avant leur retrait, les spécifications finales de la Tesla K20 qui ont été publiées par CADnetwork, un revendeur de serveurs. Comme nous le supposions à son annonce, une partie des unités de calcul sont désactivées de manière à obtenir un volume de production suffisant. Alors que le GK110 embarque 15 blocs d'unités de calcul, les SMX, 13 seront actifs sur la Tesla K20.
Inattendu par contre, Nvidia aurait également désactivé l'un des 6 contrôleurs mémoire 64-bit du GPU ce qui impliquerait qu'il devrait se contenter de 5 Go de GDDR5 et non de 6 Go comme annoncé au départ. Nous utilisons cependant le conditionnel sur ce point puisqu'il est possible, mais peu probable, que ces spécifications reposent sur des chiffres qui correspondent à l'ECC activé : sur 6 Go, seuls 5.25 Go restent ainsi accessibles dans ce mode.
Les spécifications font état d'une fréquence GPU relativement faible de 705 MHz, ce qui était sans aucun doute nécessaire pour ne pas dépasser le TDP de 225W. En présumant que les spécifications ne prennent pas en compte l'activation de l'ECC, ce n'est en général pas le cas, la mémoire GDDR5 serait ainsi cadencée à 1250 MHz.
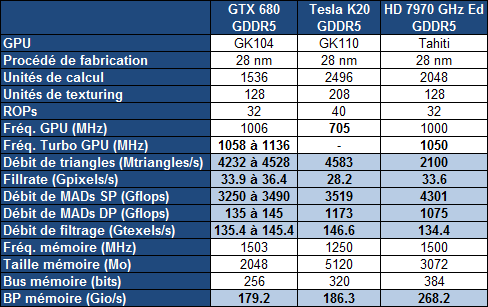
Comme vous pouvez le constater à travers ces quelques chiffres bruts, avec quelques unités désactivées et une fréquence relativement faible, la carte Tesla K20 se situe au niveau d'un exemplaire de GeForce GTX 680 équipé d'un GPU dont le turbo dispose d'une fréquence élevée. La Tesla K20 profite par contre d'une puissance en double précision nettement plus élevée ainsi que de différentes petites évolutions qui permettront de rendre le GPU plus efficace en tant que coprocesseur massivement parallèle.
Ces spécifications laissent cependant penser qu'il sera difficile pour Nvidia de proposer une variante GeForce intéressante du GK110 sans faire exploser le TDP, même si le turbo maison, GPU Boost, permet de laisser la fréquence GPU monter quelque peu dans le TDP défini. Notons que certaines rumeurs laissent d'ailleurs entendre que Nvidia pourrait ne pas utiliser ce GK110 pour sa prochaine GeForce haut de gamme. Au profit d'un GPU moins complexe mais plus hautement cadencé ?
GTC: Plus de détails sur le GK110
Lors d'une session technique sur l'architecture du GK110, nous avons pu apprendre quelques détails de plus à son sujet par rapport aux premières informations d'hier. Des détails bien entendu concentrés sur la partie compute de ce GPU. Tout d'abord, Nvidia propose cette fois un schéma de l'architecture qui montre sans ambiguïté que le GK110 est composé de 15 SMX de 192 unités de calcul, soit un total de 2880, et d'un bus mémoire de 384 bits.

On apprend par ailleurs que le cache L2 passe à 256 Ko par contrôleur mémoire 64 bits, soit un total de 1.5 Mo contre 768 Ko pour le GF1x0 et 512 Ko pour le GK104. Tout comme pour le GK104, chaque portion de cache L2 affiche une bande passante doublée par rapport à la génération Fermi.
Les blocs fondamentaux d'unités de calcul, appelés SMX dans la génération Kepler, sont similiaires pour le GK110 ceux du GK104 :

Le nombre d'unités de calcul simple précision est identique, tout comme le nombre d'unités dédiées aux fonctions spéciales, aux lectures/écritures, au texturing Les caches sont également identiques que ce soit les registres, le L1/mémoire partagée, les caches dédiés aux texturing.
La seule différence fondamentale réside dans la multiplication des unités de calcul en double précision qui passent de 8 pour le GK104 à 64 pour le GK110. Alors que le premier est 24x plus lent dans ce mode qu'en simple précision, le GK110 n'y sera que 3x plus lent. Couplé à l'augmentation du nombre de SMX, cela nous donne un GK110 capable de traiter 15x plus de ces instructions par cycle ! Par rapport au GF1x0 il s'agit d'un gain direct de 87.5% à fréquence égale.
Dans le GK110, tout comme dans le GK104, chaque SMX est alimenté par 4 schedulers, chacun capable d'émettre 2 instructions. Toutes les unités d'exécution ne sont cependant pas accessibles à tous les schedulers et un SMX est en pratique séparé en 2 parties symétriques à l'intérieur desquelles une paire de schedulers se partage les différentes unités. Chaque scheduler dispose de son propre lot de registres : 16384 registres de 32 bits (512 registres généraux de 32x32 bits en réalité). Par ailleurs chaque scheduler dispose d'un bloc dédié de 4 unités de texturing accompagnées d'un cache de 12 Ko.
Contrairement à ce à quoi nous nous attendions, l'ensemble cache L1 / mémoire partagée n'évolue pas dans le GK110 par rapport au GK104 et reste proportionnellement inférieur à ce qui était proposé sur la génération Fermi. Nvidia introduit par contre trois petites évolutions qui peuvent entraîner des gains importants :
Tout d'abord, chaque thread peut se voir attribuer jusqu'à 256 registres contre 64 auparavant. Quel intérêt quand le nombre de registres physiques n'augmente pas ? Il s'agit de donner plus de flexibilité au développeur et surtout au compilateur pour jongler entre le nombre de thread en vol et la quantité de registres allouée à chacun pour maximiser les performances. C'est particulièrement important dans le cas des calculs en double précision qui consomment le double de registres et qui étaient auparavant limités à 32 registres par thread. Passer à 128 permet des gains impressionnants dans certains cas selon Nvidia.

Ensuite, la seconde petite évolution consiste à autoriser l'accès direct aux caches dédiés au texturing. Auparavant il était possible d'en profiter manuellement en bricolant un accès à travers les unités de texturing, mais ce n'était pas pratique. Avec le GK110, ces caches de 12 Ko peuvent être exploités directement depuis les SMX mais uniquement dans le cas d'accès à des données en lecture seule. Ils ont l'avantage de disposer d'un accès royal au sous-système mémoire du GPU, de souffrir moins en cas de cache miss et de mieux supporter les accès non alignés. C'est le compilateur (via une directive) qui se charge d'y avoir recours lorsque c'est utile.
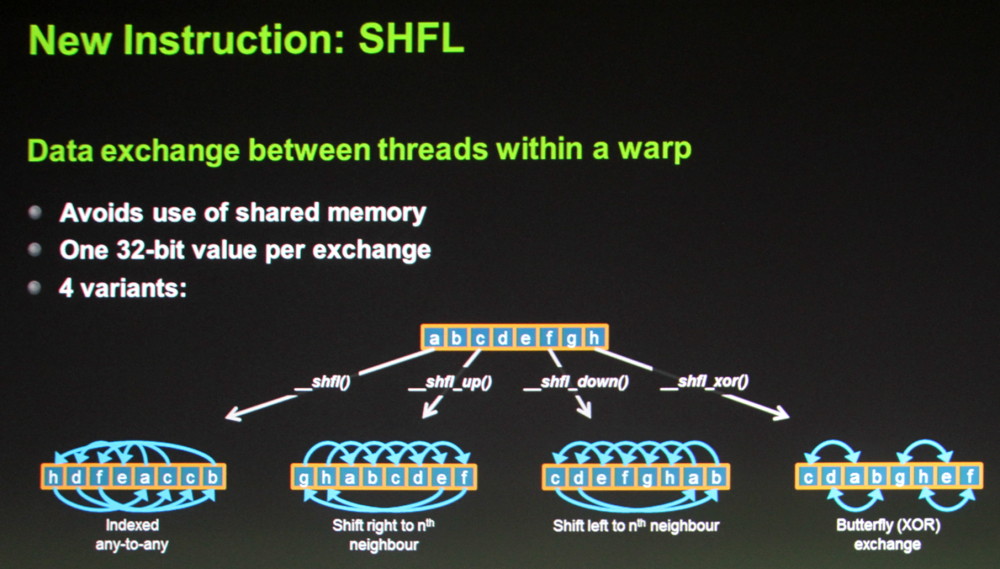
Enfin, une nouvelle instruction fait son apparition : SHFL. Elle permet un échange de donnée de 32 bits par thread à l'intérieur d'un warp (bloc de 32 threads). Son utilité est similaire à celle de la mémoire partagée et cette instruction vient donc en quelque sorte compenser sa quantité relativement faible, proportionnellement au nombre d'unités de calcul. Dans le cas d'un échange de données simple il sera donc possible d'une part de gagner du temps (un transfert direct à la place d'une écriture puis d'une lecture) et d'autre part d'économiser la mémoire partagée.
D'autres petits détails évoluent également tels que l'ajout des quelques instructions atomiques manquantes en 64 bits (min/max et opérations logiques) et une réduction de 66% du surcoût lié à la mémoire ECC.
Au final, avec la génération Kepler, Nvidia a bien pris une direction différente de celle de la génération Fermi. Le gros GPU Fermi, le GF100/110, disposait d'une organisation interne différente de celle des autres GPU de la famille, de manière à augmenter la logique de contrôle au détriment de la densité des unités de calcul et du rendement énergétique.
Avec le GK110, Nvidia n'a pas voulu faire de compromis sur ce dernier point ou plutôt devrions nous dire "n'a pas pu". Il s'agit dorénavant de faire un maximum dans une enveloppe thermique qui n'est plus extensible. C'est la raison pour laquelle le GK110 reprend la même organisation interne que celle du GK104, en dehors de la capacité de calcul en double précision qui a été revue nettement à la hausse.
Ainsi, Nvidia n'a pas cherché à complexifier son architecture pour soutenir les performances en GPU computing et s'est attaché à essayer de faire un maximum avec les ressources disponibles en se contentant d'évolutions mineures mais qui peuvent avoir un impact énorme. C'est également la raison pour laquelle le processeur de commandes a été revu pour permettre de maximiser l'utilisation du GPU avec les technologies Hyper-Q et Dynamic Parallelism que nous avons décrites brièvement hier et sur lesquelles nous reviendront dès que possible avec quelques détails de plus.
GTC: Tesla passe à Kepler avec les K10 et K20

Nvidia vient de dévoiler deux nouvelles cartes Tesla basées sur l'architecture Kepler. La première, dénommée K10 est en quelque sorte une version Tesla serveur de la GeForce GTX 690. Il s'agit donc d'une carte équipée de 2 GPU GK104 et d'un switch PCI Express 3.0 PLX. Par rapport à la GeForce GTX 690, les fréquences ont bien entendu été revues à la baisse et passent d'une fourchette de 915 à plus de 1100 Mhz (suivant le niveau de turbo) à 745 MHz pour le GPU et de 1500 à 1250 MHz pour la mémoire.
Nvidia semble ainsi avoir laissé de côté GPU Boost, probablement parce que la variabilité qui y est liée n'est pas compatible avec le monde professionnel. La base de la technologie, qui permet de contrôler dynamiquement la fréquence pour maintenir un certain TDP est par contre de toute évidence de la partie, ce qui permet à Nvidia de proposer un TDP relativement faible qui tourne autour de 225-235W, contre 300W pour la GeForce GTX 690.
La K10 est équipée de 4 Go de mémoire GDDR5 par GPU, soit 8 Go au total, et supporte l'ECC, d'une manière similaire à ce qui se fait sur les précédentes cartes Tesla : une partie de la mémoire est utilisée pour stocker les données de parité, ce qui réduit l'espace mémoire disponible ainsi que la bande passante pratique. La puissance de calcul en double précision reste par contre extrêmement faible, tout comme certaines opérations logique ou sur les entiers, le GPU GK104 étant très limité à ce niveau. En d'autres termes, la carte K10 affiche une puissance de calcul en simple précision flottante énorme, de 4577 Gflops et sera donc destinée à ce type de calculs uniquement. En double précision le débit tombe à 190 Gflops.
La seconde carte Kepler annoncée aujourd'hui, la K20 est la plus intéressante des deux puisqu'elle embarquera un GPU GK110 au sujet duquel Nvidia vient de donner les premières informations. Peu de détails sur la K20 sont communiqués à ce jour, ses spécifications ne seront fixées que plus tard dans l'année puisqu'elle est prévue pour le dernier trimestre 2012. Il est cependant probable qu'elle soit équipée d'un GK110 partiellement castré avec 13 blocs d'unités de calcul actifs sur les 15 disponibles pour un total de 2496 de ces unités de calcul. Nvidia indique par ailleurs que ses performances en double précision seront triplées par rapport à la génération actuelle et supérieures à 1 Tflops, ce qui en fera une carte bien plus polyvalente pour le calcul, d'autant plus que son GPU apporte plusieurs innovations importantes pour faciliter son exploitation avec un maximum d'efficacité.
La carte K20 devrait être accompagnée de 6 Go de mémoire GDDR5 et sera disponible avec un TDP de 225W, ce qui est plutôt impressionnant compte tenu de la complexité de ce GPU. Il est probable que Nvidia profite du fait qu'en général les blocs du GPU dédiés au graphique ne seront pas utilisés pour pouvoir compresser le TDP. Nvidia nous précise cependant que si un intégrateur dispose d'une plateforme certifiée pour un TDP plus élevé, la carte K20 pourra s'y adapter pour profiter de la marge supplémentaire. Elle sera par ailleurs disponible en version workstation en plus de la version serveur.