
Impact des compilateurs sur les architectures CPU x86/x64
Publié le 28/02/2012 par Guillaume Louel



Performances sous SPEC, bzip2, mcfLes benchmarks qui suivent sont tous issus de la suite SPEC cpu2006, version 1.2 (septembre 2011), nous utilisons les scripts de compilation inclus dans SPEC pour Visual Studio (cl) et Intel C++ Compiler (icc). Si SPEC supporte officiellement GCC (gcc) sous Linux, ce n'est pas le cas sous Windows. Un port sous Cygwin existait bel et bien mais ce dernier a été retiré. Nous avons donc modifié cpu2006 pour le faire fonctionner sous mingw.
Comme nous l'indiquions précédemment, mingw peut être sensiblement handicapé sur les opérations liées aux chaines de caractères et de mémoire, relativement lentes car issues d'une DLL Microsoft ancienne. Nous notons pour chaque benchmark qui suit le langage du bench, ainsi que le type de charge rencontré (entiers ou virgule flottante). Enfin, nous indiquons si le benchmark est multithreadé ou non.
Pour chaque test, nous mesurons les performances à partir de builds réalisées avec les options de compilations autorisées par SPEC base. Nous supprimons toutefois (pour Intel) l'option qui crée automatiquement un code optimisé en fonction de la plateforme. Base dans notre graphique correspond donc à la configuration par défaut. Nous forçons ensuite pour Visual Studio la génération de code SSE2 et AVX (les deux seules options offertes) et pour Intel, nous testons les options
Qax, recommandée par Intel et qui génère un code optimisé pour un niveau de processeur donné ainsi qu'un code de base qui sera exécuté sur tous les autres processeurs ne correspondant pas à ce niveau (SSE2, 3, 4.1, 4.2 et AVX sont testés). Ces builds sont indiquées par la lettre D (pour dispatcher) dans nos graphiques. Nous ajoutons également les builds avec l'option arch pour les différents modes supportés par Intel. Enfin pour GCC, nous utilisons les profils dédiés aux processeurs à savoir
barcelona (architecture Phenom II), bdver1 (Bulldozer v1, architecture du FX), corei7 (architecture Intel précédente) et corei7avx (architecture Sandy Bridge). N'incluant pas de dispatcher, les builds AVX ne sont pas testées sur le Phenom II, elles ne sont tout simplement pas fonctionnelles. Notez enfin que si certains noms de benchmarks font référence à des programmes connus, il s'agit généralement de versions modifiées - par SPEC - de ces programmes, notamment pour améliorer la compatibilité, retirer un éventuel biais pour une architecture ou une autre, ou améliorer la qualité des mesures.
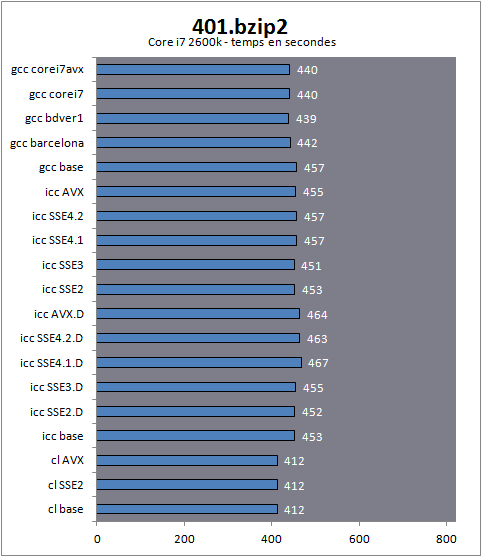
401.bzip2bzip2 est un utilitaire de compression très populaire sous Linux. Le benchmark a été modifié pour effectuer ses tâches de compression et décompression uniquement en mémoire, et ainsi limiter l'influence du disque. Des données de niveaux de compressibilité différentes (fichiers images JPEG, code source, programme binaire) sont compressés et décompressés avec trois tailles de blocks différentes. Le résultat obtenu est un temps en secondes.
Langage : C
Type de charge : Entiers
Multithreadé : Oui
[ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ]
Passez la souris sur un modèle de processeur pour afficher ses résultats
Premier benchmark et première surprise : le compilateur Microsoft est ici le plus performant sur Core i7 et sur FX ! Ironiquement, le compilateur d'Intel est celui qui produit le code le plus rapide pour le Phenom II. Les écarts ne sont pas ridicules puisque sur Core i7 le compilateur de Microsoft se place 12% devant une build AVX avec dispatcher, censée être la plus optimisée possible. En matière d'optimisations, comme nous allons le voir, les résultats ne sont pas forcements ceux auxquels on s'attend. De manière intrigante on notera que les versions SSE 4.1/4.2 et AVX sont les plus lentes sur le Core i7 et le FX, ce qui n'est pas le cas pour le Phenom II. Dans tous les cas, le mode SSE3 sans dispatcher est le plus rapide qui soit proposé par ICC.
Le comportement des versions dispatcher sur le Phenom II sont particulièrement intrigantes, en effet si l'on admet que le dispatcher traite de la même manière tous les processeurs AMD, le même code devrait tourner à la fois sur le Phenom II, et à la fois sur le FX. Dans la pratique les choses ne sont pas si simples.
Notons enfin que GCC est le seul compilateur à proposer un gain de performances via ses profils dédiés aux processeurs, tous les profils obtenant des performances équivalentes sur chaque architecture. On notera pour ce premier test que GCC est en milieu de peloton pour les processeurs Intel et en dernière place sur les machines d'AMD. L'écart de performances CL/GCC reste de 10% sur les deux architectures, ICC est simplement plus efficace sur le Phenom II
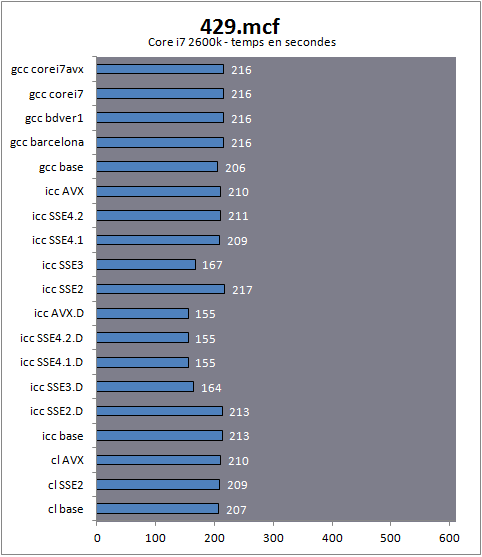
429.mcfCe benchmark est tiré de MCF, un programme de génération d'horaires pour transports en communs. Il répond au problème dit de flot minimum en implémentant un algorithme network simplex. Un PDF décrivant le problème et ce type de solution est disponible ici , l'algorithme utilisé dans le benchmark étant un peu plus complexe et optimisé.
Langage : C
Type de charge : Entiers
Multithreadé : Non
[ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ]
Passez la souris sur un modèle de processeur pour afficher ses résultats
Si les modes SSE2 et AVX n'apportent aucun gain sur ce benchmark sur le compilateur Microsoft, on peut noter des premiers gains liés aux optimisations Intel.
Si l'on regarde d'abord les builds "dispatcher", on note que la version SSE3 apporte 30% de performances en plus, les trois modes suivants apportant un nouveau léger gain. Problème ? Ces gains ne sont pas reproduits de manière exacte lorsque l'on utilise les builds "arch" censées optimiser de la même manière sur un processeur Intel. Ici, le mode SSE3 est bien plus rapide, mais ce n'est pas le cas des autres modes ! A la décharge d'Intel, on retrouve, pour ces builds sans dispatcher un même comportement sur les processeurs AMD, le Phenom II profitant une fois de plus assez fantastiquement du mode
arch:SSE3Les versions dispatcher sur AMD FX et Phenom II ont toutes des performances identiques en tout cas : c'est ce à quoi nous nous attendions.
Sommaire
Vos réactions
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 04/05: Un Coffee Lake 8 coeurs en préparat...
- [+] 27/04: Le 10nm d'Intel (encore) retardé, l...
- [+] 27/04: AMD Vega 7nm en labo, Zen 2 échanti...
- [+] 26/04: Jim Keller rejoint... Intel !
- [+] 23/04: MAJ de notre test des Ryzen 7 2700X...
- [+] 19/04: AMD Ryzen 2700X et 2600X : Les même...
- [+] 19/04: 2008-2018 : tests de 62 processeurs...
- [+] 18/04: ASUS AREZ, l'effet GeForce Partner ...
- [+] 13/04: Les AMD Ryzen Pinnacle Ridge en pré...