
Impact des compilateurs sur les architectures CPU x86/x64
Publié le 28/02/2012 par Guillaume Louel



445.gombkgombk est un algorithme d'intelligence artificielle dédié au jeu de Go. Il s'agit d'une IA extraite du jeu open source GNU Go .
Langage : C
Type de charge : Entiers
Multithreadé : Oui

[ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ]
Passez la souris sur un modèle de processeur pour afficher ses résultats
Dans ce test, les gains apportés par les diverses optimisations sont relativement mineurs, on notera cependant que les compilateurs MS et GCC sont plus rapides que celui d'Intel sur un Core i7 alors que le compilateur Intel est le plus rapide sur le Phenom II ! Décidément, le compilateur d'Intel aime beaucoup ce processeur ! On notera, pour la version sans dispatcher que les builds SSE 4.1, 4.2 et AVX sont légèrement plus rapides que les autres sur Core i7, l'inverse est vrai sur FX, mais les marges sont extrêmement faibles. Notons une légère autre tendance à vérifier, tant elle est ici minime, les modes SSE2/AVX de Visual Studio semblent légèrement plus lents sur processeurs Intel que la version x87 classique, tandis que l'on note un léger gain sur FX et Phenom II
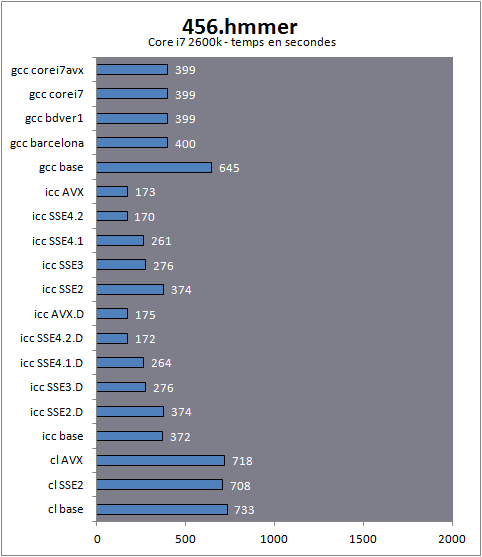
456.hmmerhmmer est un algorithme qui effectue des recherches dans une base de données de gènes, un algorithme notamment utilisé pour analyser les séquences de protéines.
Langage : C
Type de charge : Entiers
Multithreadé : Non
[ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ]
Passez la souris sur un modèle de processeur pour afficher ses résultats
Surprise de taille ! Si l'on note bel et bien des gains entre les différentes versions dispatcher du compilateur d'Intel sur le Core i7 on note également des gains significatifs sur les processeurs AMD !
Alors, que se passe-t-il ? Il faut regarder la version dispatcher "AVX" lancée sur le Phenom II, cette dernière est bel et bien trois fois plus rapide que la version de base, et pourtant, le Phenom II n'est non seulement pas capable de faire tourner un éventuel code AVX, mais en prime, la détection des processeurs Intel par le dispatcher l'empêche de faire tourner le code optimisé. Si l'on y regarde de plus près, on notera que les gains ne sont pas en effet exactement identiques. Alors que l'on peut grouper deux à deux les modes sur Core i7 par rapport à leurs performances (AVX et SSE 4.2, SSE 4.1 et SSE3, SSE2 et base), on notera un décalage sur les processeurs d'AMD ou une build SSE3 est aussi lente qu'une version SSE2. Décalage qui disparait lorsque l'on enlève le dispatcher, qui plus est !
Si cela est en soit une bonne nouvelle pour les processeurs AMD, cela souligne aussi l'opacité complète de l'option
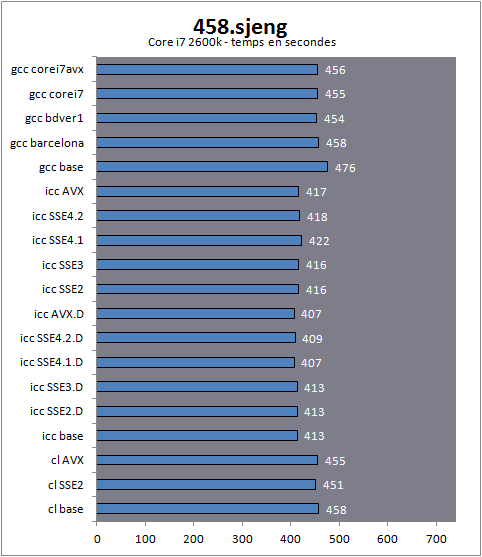
Qax du compilateur d'Intel. Les optimisations sont multiples et contrairement à ce que laisse sous entendre leur nom, il ne s'agit pas uniquement de la génération de code AVX ou SSE dont il s'agit, mais bel et bien de multiples couches d'optimisations qui peuvent aussi bien toucher les fonctions de chaines de caractères ou les fonctions mémoires. Le compilateur d'Intel semble laisser bénéficier les autres processeurs - certes à un rythme légèrement différent - d'une partie de ses optimisations. On apprécie le geste. Notons enfin que gcc est significativement plus rapide que le compilateur de Microsoft dans ce test. 458.sjengsjeng est une intelligence artificielle pour le jeu d'Echec, extraite de la version 11.2 du logiciel du même nom .
Langage : C
Type de charge : Entiers
Multithreadé : Non
[ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ]
Passez la souris sur un modèle de processeur pour afficher ses résultats
Si l'on notera ici un très léger gain obtenu par les versions SSE 4.1, 4.2 et AVX sur Core i7, on notera à l'inverse une légère dégradation dans ces modes sur les processeurs AMD avec le dispatcher. Les algorithmes partagés par la version classique et dispatchée des builds ne profitent pas de la même manière aux architectures. Une fois le dispatcher enlevé, l'AVX apporte bel et bien un petit gain sur le FX.
Sommaire
Vos réactions
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 04/05: Un Coffee Lake 8 coeurs en préparat...
- [+] 27/04: Le 10nm d'Intel (encore) retardé, l...
- [+] 27/04: AMD Vega 7nm en labo, Zen 2 échanti...
- [+] 26/04: Jim Keller rejoint... Intel !
- [+] 23/04: MAJ de notre test des Ryzen 7 2700X...
- [+] 19/04: AMD Ryzen 2700X et 2600X : Les même...
- [+] 19/04: 2008-2018 : tests de 62 processeurs...
- [+] 18/04: ASUS AREZ, l'effet GeForce Partner ...
- [+] 13/04: Les AMD Ryzen Pinnacle Ridge en pré...