
Intel Core 2 Extreme QX9650
Publié le 29/10/2007 par Marc Prieur



 Depuis le lancement des Core 2 durant lété 2006, la gamme de processeur Intel na pas évolué dun point de vue architectural. Intel sest en effet contenter de sortir des versions quatre curs composés de deux die Conroe, puis de faire légèrement évoluer la gamme avec lintroduction de modèles utilisant un FSB1333. Alors que le Phenom dAMD nest toujours pas là, le géant de Santa Clara propose avec le Core 2 Extreme QX9650 son premier processeur basé sur larchitecture Penryn.
Depuis le lancement des Core 2 durant lété 2006, la gamme de processeur Intel na pas évolué dun point de vue architectural. Intel sest en effet contenter de sortir des versions quatre curs composés de deux die Conroe, puis de faire légèrement évoluer la gamme avec lintroduction de modèles utilisant un FSB1333. Alors que le Phenom dAMD nest toujours pas là, le géant de Santa Clara propose avec le Core 2 Extreme QX9650 son premier processeur basé sur larchitecture Penryn.Penryn : Core v1.1

Le core Penryn et ses 6 Mo de cache L2
Le core Penryn est une évolution du Conroe. Toujours basé sur larchitecture Core, il laméliore sur quelques points à commencer par la gravure qui ne se fait plus en 65nm mais en 45nm. Intel en a du coup profité pour rajouter du cache L2, puisque lon passe de 4 à 6 Mo ce qui fait que le total de transistor explose, passant de 290 à 410 millions. La taille du die reste cependant à la baisse puisquelle est désormais de 107mm², contre 143mm², ce qui permet à Intel daugmenter son nombre de processeur par galette de silicium et donc dabaisser ses coûts de production.
Du côté des améliorations architecturales, Penryn se distingue surtout sur deux points. Le premier cest lamélioration de lunité responsable de la division. Les processeurs Intel utilisent, tout comme nous, la méthode euclidienne : à un diviseur et un dividende sont associés un quotient et un reste. Les processeurs opèrent la division par morceau, c'est-à-dire qu'à chaque cycle ne sont traités qu'un nombre fini de bits. L'opération est relativement lente (le nombre de cycles nécessaire dépend de la taille du dividende), mais est exacte.
Là où un Conroe traite deux bits par cycle (on parle de Radix-4), Penryn en traite quatre (Radix-16). La technique bénéficie également à d'autres opérations plus complexes faisant intervenir des divisions, telles que le calcul de la racine carrée qui a fait l'objet d'optimisations toutes particulières.
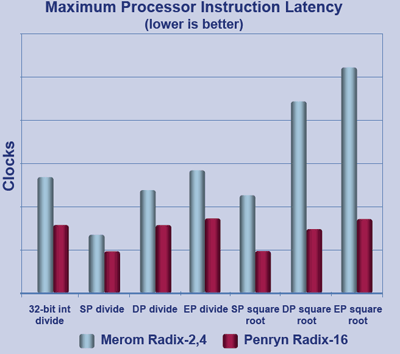
Le SSE se voit pour sa part améliorer en deux points, le premier étant laccélération des instructions de shuffle, cest-à-dire les instructions qui mélangent les données de plusieurs registres SSE et qui sont grandement utilisées dans le codage et le décodage vidéos. De plus, une nouvelle série dinstructions fait son apparition, le SSE4 dont vous pouvez lire les détails dans ce document . Une cinquantaine dinstructions sont au menu du jour, dont une bonne partie pourrait apporter des gains très généraux, et dautres dans des domaines plus spécifiques tels que le calcul dune valeur CRC. Bien entendu il faudra que les programmes soient écrits ou compilés pour prendre en compte ces instructions, elles napporteront rien aux programmes actuels.
En pratique

Sommaire
Vos réactions
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 04/05: Un Coffee Lake 8 coeurs en préparat...
- [+] 27/04: Le 10nm d'Intel (encore) retardé, l...
- [+] 26/04: Jim Keller rejoint... Intel !
- [+] 23/04: MAJ de notre test des Ryzen 7 2700X...
- [+] 20/04: MAJ de notre comparatif CPU géant
- [+] 19/04: AMD Ryzen 2700X et 2600X : Les même...
- [+] 19/04: 2008-2018 : tests de 62 processeurs...
- [+] 13/04: Les AMD Ryzen Pinnacle Ridge en pré...
- [+] 10/04: LGA4189 pour les Xeon Ice Lake !