
Preview : GeForce4 Ti
Publié le 06/02/2002 par Marc Prieur



Lightspeed Memory Architecture IISous ce nom ce cache en fait 6 fonctions dont le but est d´optimiser la gestion de la bande passante mémoire :
- Crossbar Memory Controller
- Quad Cache
- Lossless Z Compression
- Z-Occlusion Culling
- Auto Pre-Charge
- Fast Z-Clear
> Crossbar Memory Controller
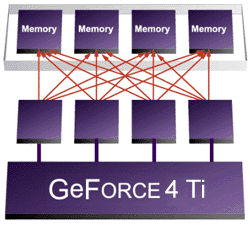
Déjà intégré dans le GeForce3, c´est le contrôleur mémoire du GeForce4, ou plutôt les contrôleurs mémoires puisqu´ils sont 4. Cela permet au GeForce4 de pouvoir lire et écrire dans le frame buffer par blocs de 64 bits, et non pas par blocs de 256 bits comme sur les anciens contrôleurs mémoires. Cela permet donc d´économiser en bande passante lorsque les données font moins de 256 bits. Bien entendu, ces 4 contrôleurs sont capables de communiquer entre eux afin d´accéder a la mémoire par bloc de 256 bits si besoin est. D´après NVIDIA, le Crossbar Memory Controller peut être jusqu´a 4x plus efficace que les contrôleurs mémoire d´ancienne génération : c´est effectivement le cas si toutes les données que l´on veut lire / écrire ne font que 64 bits, mais heureusement ce cas ne représente pas une majorité des accès mémoire.
> Quad Cache
NVIDIA a regroupé sous ce nom 4 mémoires cache distinctes destinées respectivement aux informations concernant les primitives, les vertex, les textures et les pixels. Les données déjà stockées dans ces caches, dont la taille n´est pas communiquée par NVIDIA, sont disponibles instantanément, ce qui évite de les relire dans la mémoire vidéo et de les recalculer.
> Lossless Z Compression
Comme son nom l´indique, il s´agit d´un algorithme de compression non destructeur des données de profondeur Z. Déjà intégré dans le GeForce3, il permet de compresser ces données selon un ratio de 4 pour 1.
> Z-Occlusion Culling
Egalement intégré dans le GeForce3, le Z-Occlusion Culling a pour but de déterminer si un pixel sera visible ou pas au final, afin de savoir s´il est utile d´en effectuer le rendu. S´il s´avère que ce pixel ne sera pas visible, puisque caché par un pixel de mêmes coordonnées x, y qui se trouve plus près, il ne sera pas rendu. Avec les jeux actuels, qui ont une depth complexity 2 (en moyenne deux pixels de mêmes coordonnées X,Y mais de coordonnées Z différentes pour chaque point à l´écran), on peut donc économiser jusqu´a 50% de la bande passante mémoire nécessaire pour le rendu. Il est à noter que l´algorithme de Z-Occlusion Culling a été amélioré depuis le GeForce3.
> Auto Pre-Charge
Le contrôleur mémoire du GeForce4 est également capable d´indiquer à la mémoire vidéo quelle partie des bancs de la mémoire vidéo qui ne sont pas encore utilisés mais qui vont l´être prochainement. Cela permet d´économiser les cycles d´horloges liés au pre-charge, et le GPU pourrait du coup accéder directement aux zones voulues.
> Fast Z-Clear
Après chaque rendu d´une image d´une scène 3D, un chip graphique conventionnel efface le Z-Buffer en écrivant une valeur de 0 pour chaque pixel. Le but du Fast Z-Clear est d´effacer le Z-Buffer sans passer par cette étape. Il est amusant de constater qu´ATI a intégré cette fonction dès le Radeon. Par ailleurs, il est possible que NVIDIA l´ait intégré dans le GeForce3, mais à l´époque ils n´avaient pas communiqué dessus.
> En pratique
Quelles sont les performances de la Lightspeed Memory Architecture II en pratique ? Pour le savoir, nous avons clocké une GeForce4 Ti et une GeForce3 Ti aux mêmes fréquences, à savoir 250 MHz pour le core et 270 MHz DDR pour la mémoire. Sous Quake III Arena en 1600*1200 32 bits, nous avons obtenu 116.6 fps sur la GF4, 109.6 fps sur la GF3. Sous le célèbre VillageMark, bench de PowerVR dont le but est de mettre en avant les performances dans des scènes ou les techniques du type Z-Occlusion Culling, on passe de 39 fps sur GF3 à 45 fps sur GF4. La deuxième version de la Lightspeed Memory Architecture est donc au dessus de la première.
Sommaire
Vos réactions
Contenus relatifs
- [+] 04/05: Nvidia abandonne son GeForce Partne...
- [+] 27/04: AMD Vega 7nm en labo, Zen 2 échanti...
- [+] 18/04: ASUS AREZ, l'effet GeForce Partner ...
- [+] 10/04: Nvidia : fin du support Fermi et 32...
- [+] 27/03: Pilotes Radeon et GeForce pour Far ...
- [+] 20/03: Pilotes GeForce 391.24 pour Sea of ...
- [+] 20/03: Microsoft annonce DirectX Raytracin...
- [+] 20/03: Radeon Software 18.3.3 beta avec Vu...
- [+] 08/03: 3 millions de GPU vendus pour le mi...
- [+] 08/03: Radeon Software 18.3.1 optimisé pou...