
Les derniers contenus liés aux tags DirectX et GDC 2015
[MAJ] GDC: D3D12: AMD parle des gains GPU
GDC: D3D12: des feature levels 12_0 et 12_1
[MAJ] GDC: D3D12: AMD parle des gains GPU



En bas de page, nous avons mis à jour cette actualité initialement publiée le 16 mars. AMD nous a transmis une nouvelle présentation sur le sujet et Nvidia nous a précisé ce dont étaient également capables ses GPU en terme de traitement simultané des tâches.
De nombreuses sessions dédiées à Direct3D 12 étaient organisées à la GDC. Après celle de Microsoft consacrée à Direct3D, lors de laquelle les niveaux de fonctionnalités ont été mentionnés et des démonstrations ont été faites sur du matériel Nvidia, nous avons assisté à la session d'AMD. Lors de celle-ci, il a été question d'une nouvelle opportunité d'optimisation : améliorer les performances GPU en profitant du traitement simultané de certaines tâches liées au rendu 3D.
Si l'intérêt des API de plus bas niveau est avant tout d'optimiser les performances au niveau du CPU, en réduisant le surcoût des commandes des rendus et en profitant mieux de tous les curs, des gains peuvent également être obtenus au niveau du GPU. Dans la plupart des démonstrations auxquelles nous avons pu assister jusqu'ici, les gains mis en avant concernaient avant tout les GPU intégrés dont l'enveloppe thermique limite les performances. Si la charge CPU est réduite, le GPU a plus de marge au niveau de sa fréquence turbo et c'est ce qui permet de faire grimper ses performances.
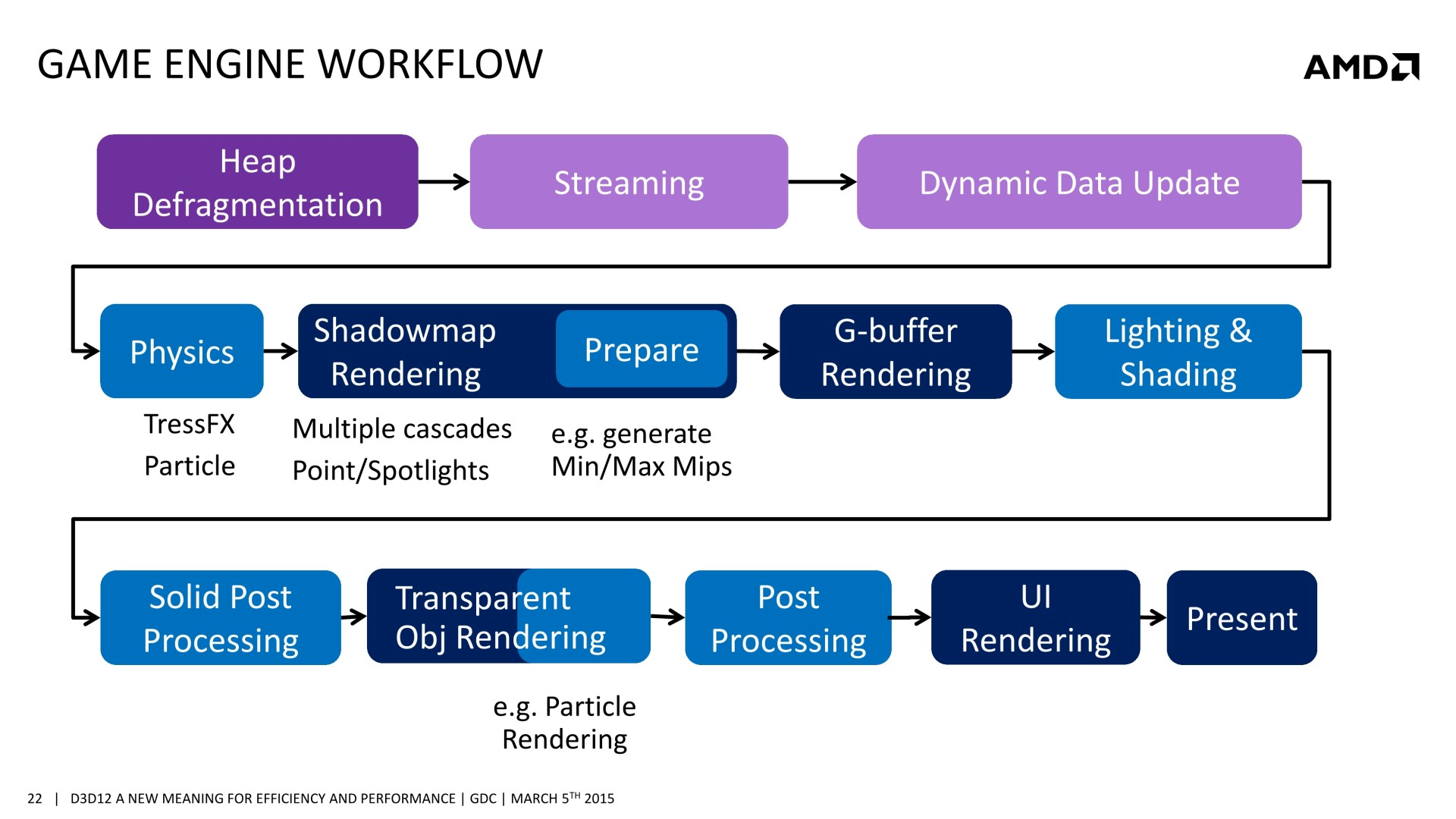
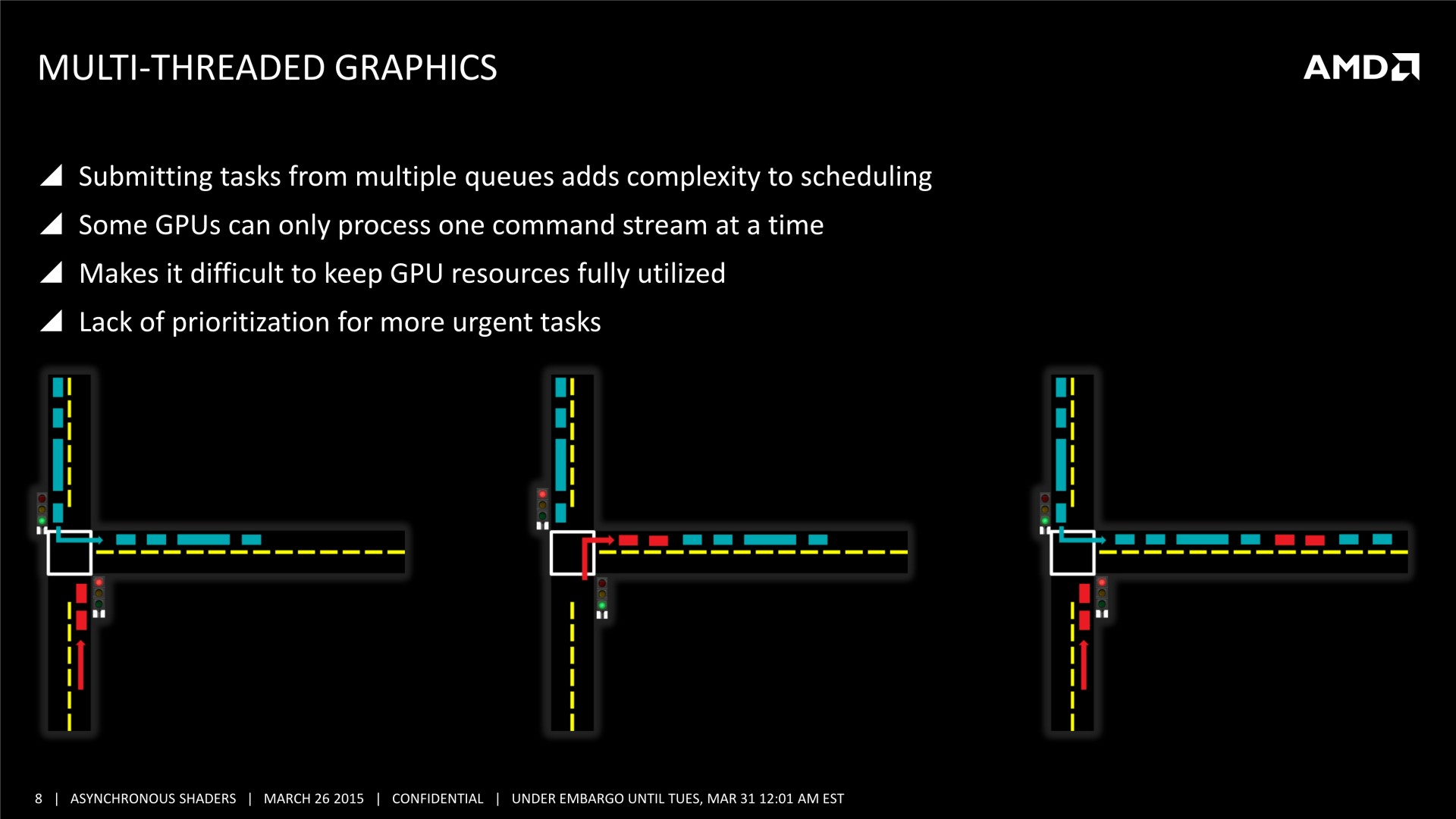
Mais il y a d'autres possibilités au potentiel important. AMD a ainsi mis en avant l'opportunité d'améliorer les performances GPU en profitant du traitement concomitant de certaines tâches. Avec les API classiques, toutes les étapes du rendu sont traitées en série par le GPU. Par exemple, le calcul de la physique, la préparation des ombres dynamiques, le remplissage du G-Buffer, l'éclairage et le post processing sont traités l'un après l'autre, aussi vite que possible par les GPU, mais en série.
Chacune de ces tâches n'exploite cependant pas la totalité des capacités d'un GPU. Par exemple, la préparation des ombres et le remplissage du G-Buffer vont plutôt saturer le sous-système mémoire alors que la physique, l'éclairage et le post processing ont plutôt tendance à saturer les unités de calcul. Il semble ainsi logique que traiter en même temps certaines de ces tâches représente une optimisation intéressante pour mieux exploiter les GPU.

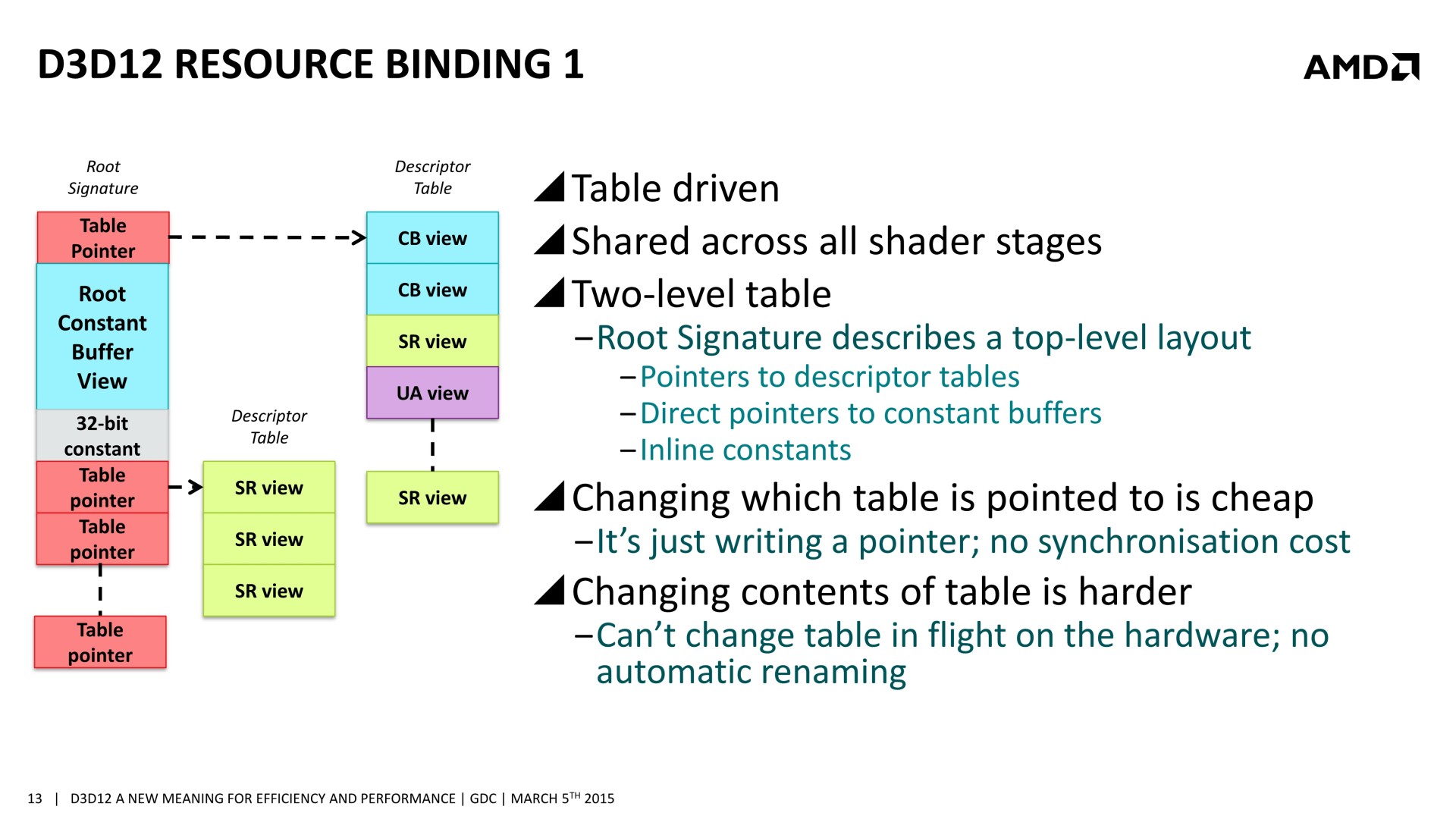
Et ça tombe bien, Direct3D 12, l'autorise. L'API de Microsoft semble reprendre exactement la base de Mantle sur ce point et prévoit 3 types de files d'attentes, également appelées "moteurs", dont les tâches peuvent être traitées en concomitance : Graphics, Compute et Copy. Au niveau des fonctionnalités prises en charge, Graphics est un superset de Compute qui est un superset de Copy. Cela veut dire que par défaut seul le moteur Graphics peut être exploité, puisqu'il est polyvalent. Il revient aux développeurs de spécifier l'utilisation des autres moteurs pour potentiellement optimiser les performances.
Il faut noter que ce type d'optimisation permet d'exploiter les ACE (Asynchronous Compute Engines) des GPU Radeon de la génération GCN. Pour rappel, AMD a implémenté ces processeurs de commandes secondaires justement pour pouvoir exécuter efficacement des tâches de type Compute en même temps que des tâches de type Graphics. D'autres GPU ne disposent pas de files d'attentes spécifiques au niveau matériel pour tous ces types de tâches et doivent alors les traiter de manière classique, en série. Ainsi, il n'est pas certain que les GPU Nvidia puissent profiter autant que ceux d'AMD de ce type d'optimisation.

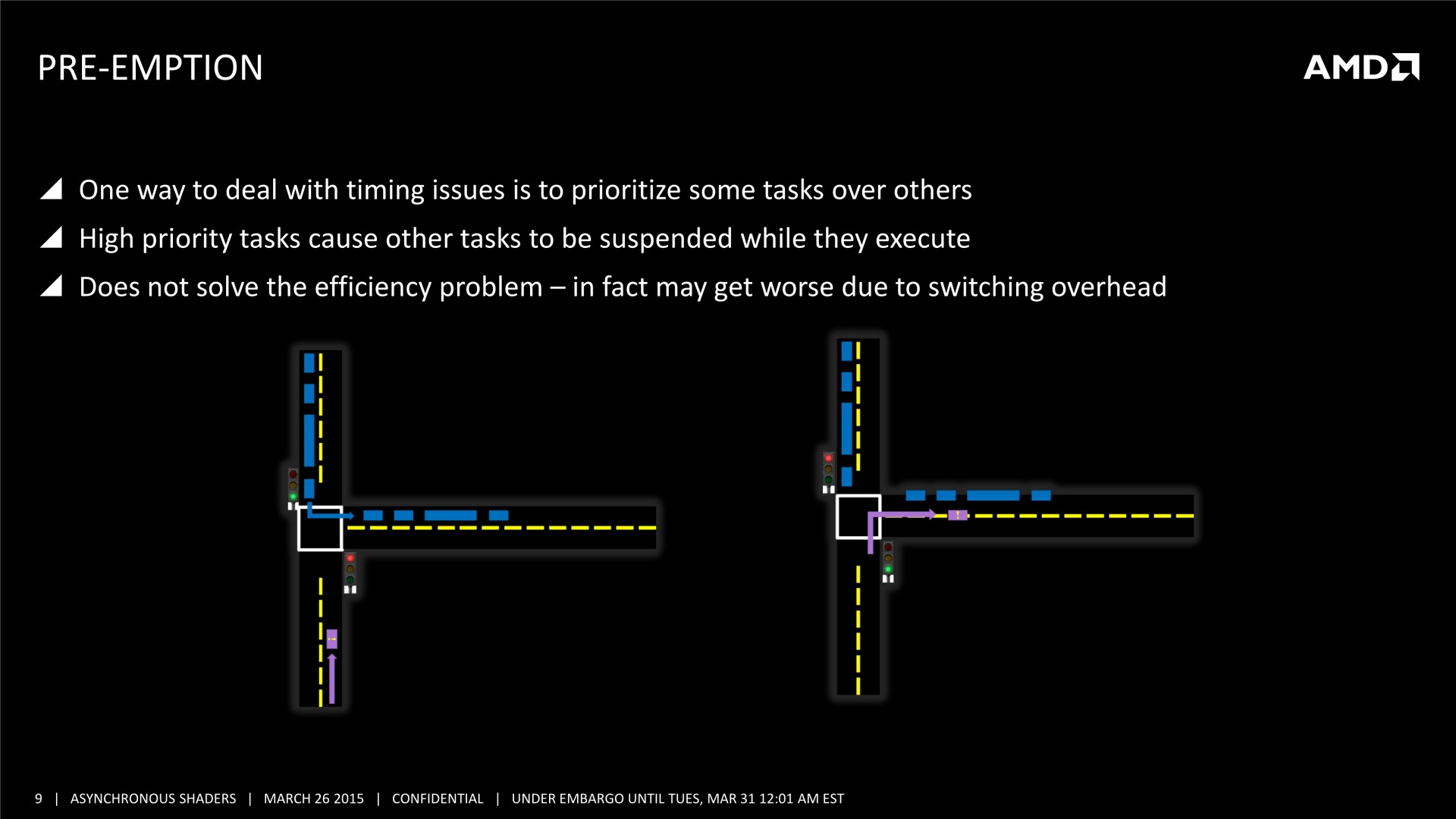
Une bonne compréhension des architectures GPU et un profilage avancé des demandes de chaque tâche sont nécessaires. Il est également crucial de mettre en place correctement les barrières de synchronisation nécessaires, sans quoi des tâches dépendantes l'une de l'autre pourraient être exécutées en parallèle et causer des problèmes. AMD a insisté lourdement sur ce point, précisant que l'absence de barrières de synchronisation adéquates pourra passer inaperçue dans l'immédiat, sans bug visible, mais être source de gros problèmes avec de futurs GPU dont l'augmentation des performances profitera plus à certaines tâches qu'à d'autres. Comme le sait très bien AMD, les développeurs seront peu enclins à proposer un patch 2 ou 3 ans après la sortie d'un jeu, et appliquer un correctif au niveau des pilotes sera alors un véritable casse-tête, voire impossible dans certains cas.
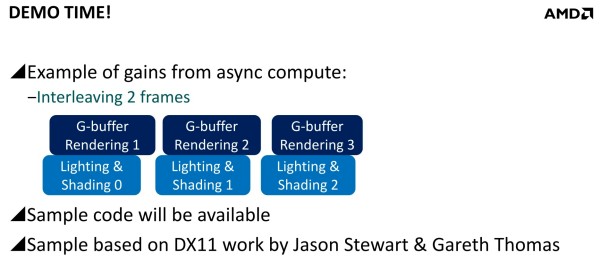
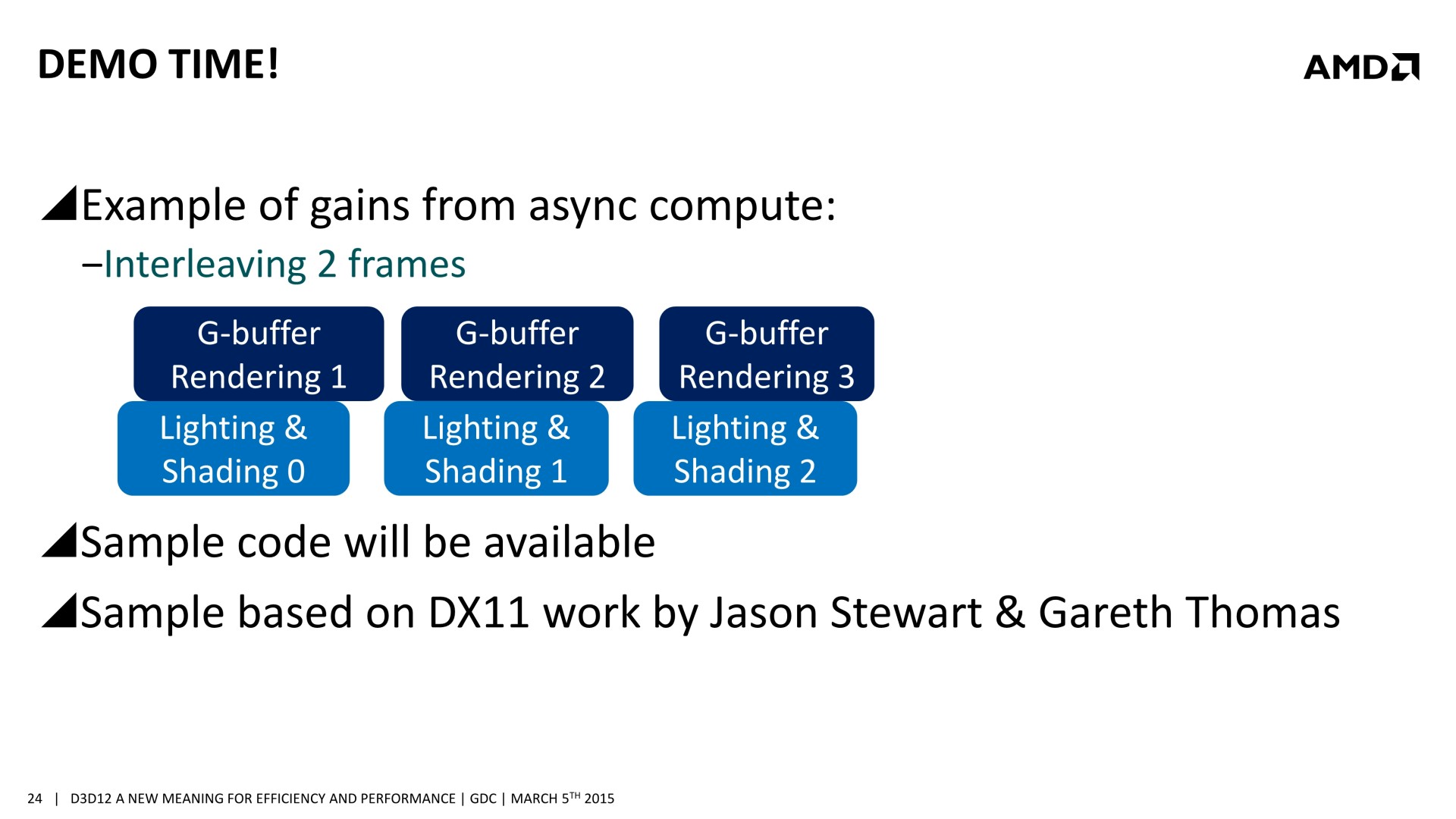
Mais avec un code robuste et un bon profilage, les gains peuvent être conséquents. Il est question de 20 à 25% dans des situations réalistes et avec des GPU capables d'en profiter. Deux exemples ont été mentionnés. Le premier, accompagné d'une démonstration, découple le remplissage du G-Buffer du calcul de l'éclairage qui est réalisé à travers un compute shader. Au lieu de traiter ces 2 opérations l'une après l'autre, elles sont effectuées en parallèle et de manière asynchrone : pendant que l'éclairage est calculé pour l'image 1, les opérations sur le G-Buffer sont traitées pour l'image 2 et ainsi de suite.
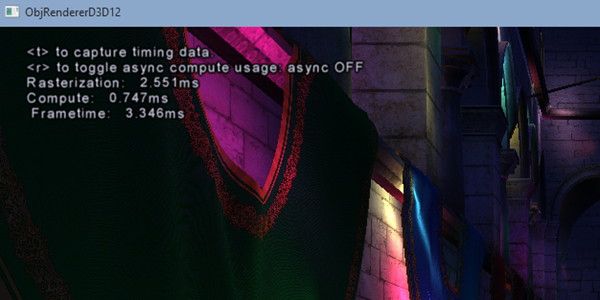
[ Concomitance OFF ] [ Concomitance ON ]
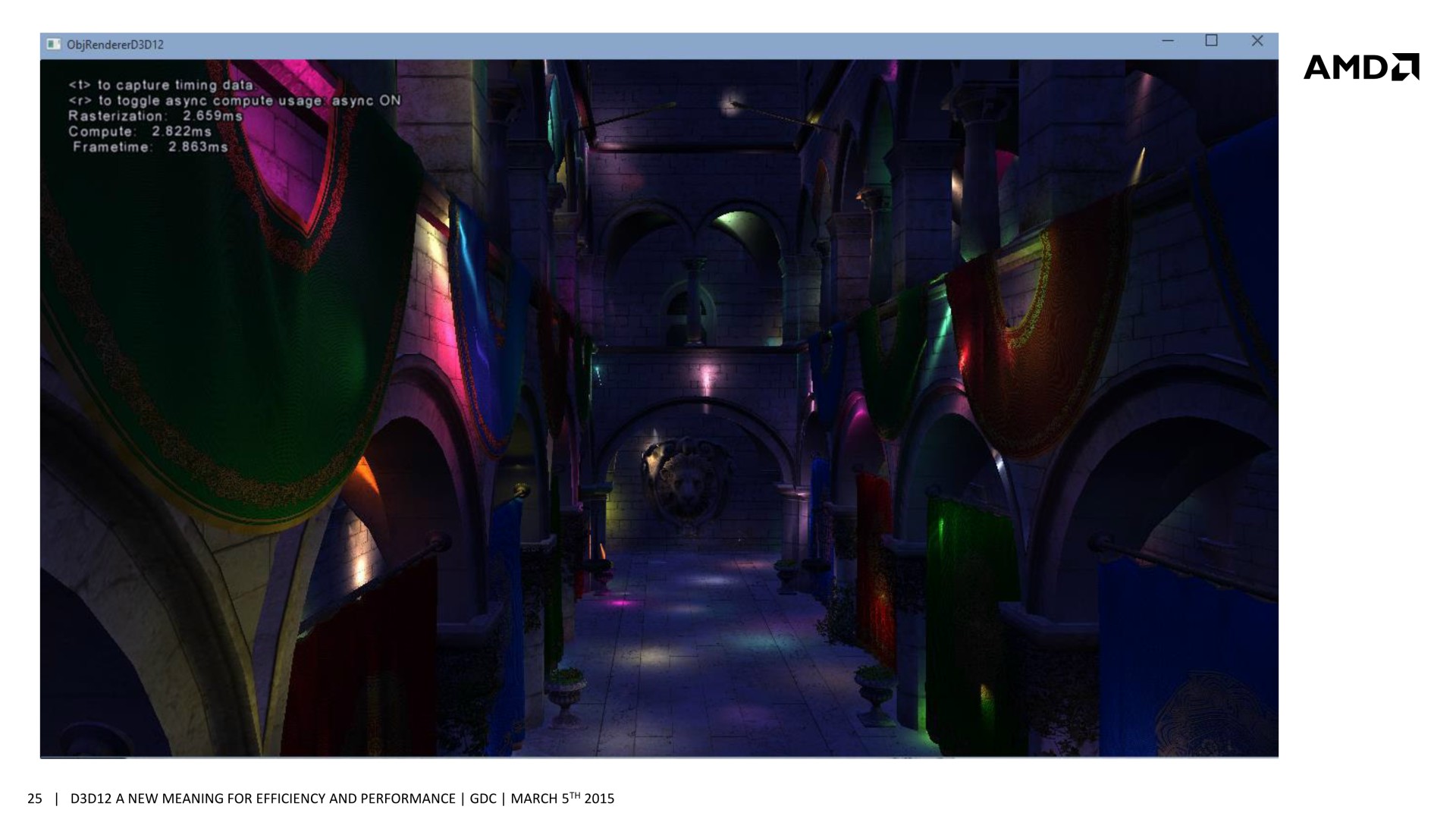
Sans traitement concomitant des tâches Graphics et Compute, le temps de rendu total prend 3.346ms (299 fps), ce qui est la somme des 2.551ms de la partie Graphics (remplissage du G-Buffer) et des 0.747ms de la partie Compute (calcul de l'éclairage). En activant le traitement concomitant dans cette démonstration, le remplissage du G-Buffer prend 2.659ms, et le calcul de l'éclairage 2.822ms. Ces deux tâches prennent plus de temps à être traitées, mais elles le sont en même temps et le rendu total ne prend plus que 2.863ms (349 fps), ce qui représente un gain de 17%. La latence peut par contre être légèrement plus élevée.
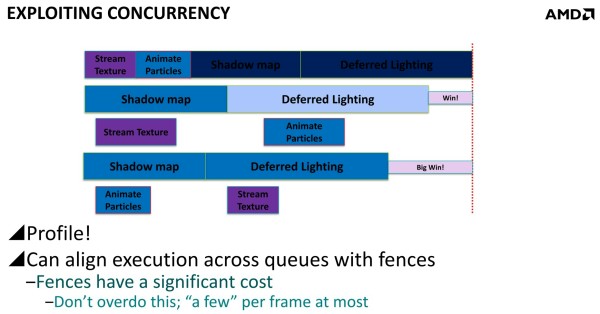
Dans un autre exemple, AMD explique que streamer les textures et animer les particules via les moteurs Copy et Compute permet un petit gain puisque ces opérations sont alors traitées en concomitance avec les ombres et l'éclairage. Mais il est possible d'aller plus loin en constatant qu'il est plus efficace d'animer les particules en même temps que la préparation des ombres et de streamer les textures en même temps que le calcul de l'éclairage que de faire l'inverse. En évitant d'exécuter en même temps des tâches qui ont des demandes similaires en termes de ressources GPU, les gains sont plus importants. D3D12 offre des mécanismes aux développeurs pour pouvoir gérer cela.
Les GPU modernes doivent en général faire face à des limites de consommation directes ou indirectes (via la température) et mieux exploiter la totalité de leurs capacités revient bien entendu à les pousser plus souvent ou plus loin dans ces limites. La fréquence GPU des cartes graphiques est alors réduite quelque peu, ce qui impacte les performances, mais dans des proportions bien moins élevées que les gains liés à ce type d'optimisations. Elles restent donc totalement légitimes. A voir par contre si de tels moteurs graphiques seront qualifiés de "power virus" par AMD et Nvidia, comme c'est le cas de Furmark et d'OCCT qui font également en sorte de saturer toutes les unités des GPU
Le set de slides de la session d'AMD à la GDC : (nous avons profité de la mise à jour pour remplacer nos clichés par des screenshots plus propres)























Mise à jour du 31/03 :
Quelques semaines après la GDC, AMD a décidé de mettre en avant ces possibilités d'optimisations auprès de la presse technique. Une présentation simplifiée nous a ainsi été distribuée il y a quelques jours. A noter que, bizarrement, elle était par contre accompagnée d'un embargo qui prenait fin ce matin alors même que la présentation plus complète, dont nous vous avions parlé ci-dessus, est publique depuis la GDC. Peu de médias s'y étaient cependant intéressés et le département de marketing technique d'AMD a probablement voulu mettre en place une communication synchronisée sur le sujet.







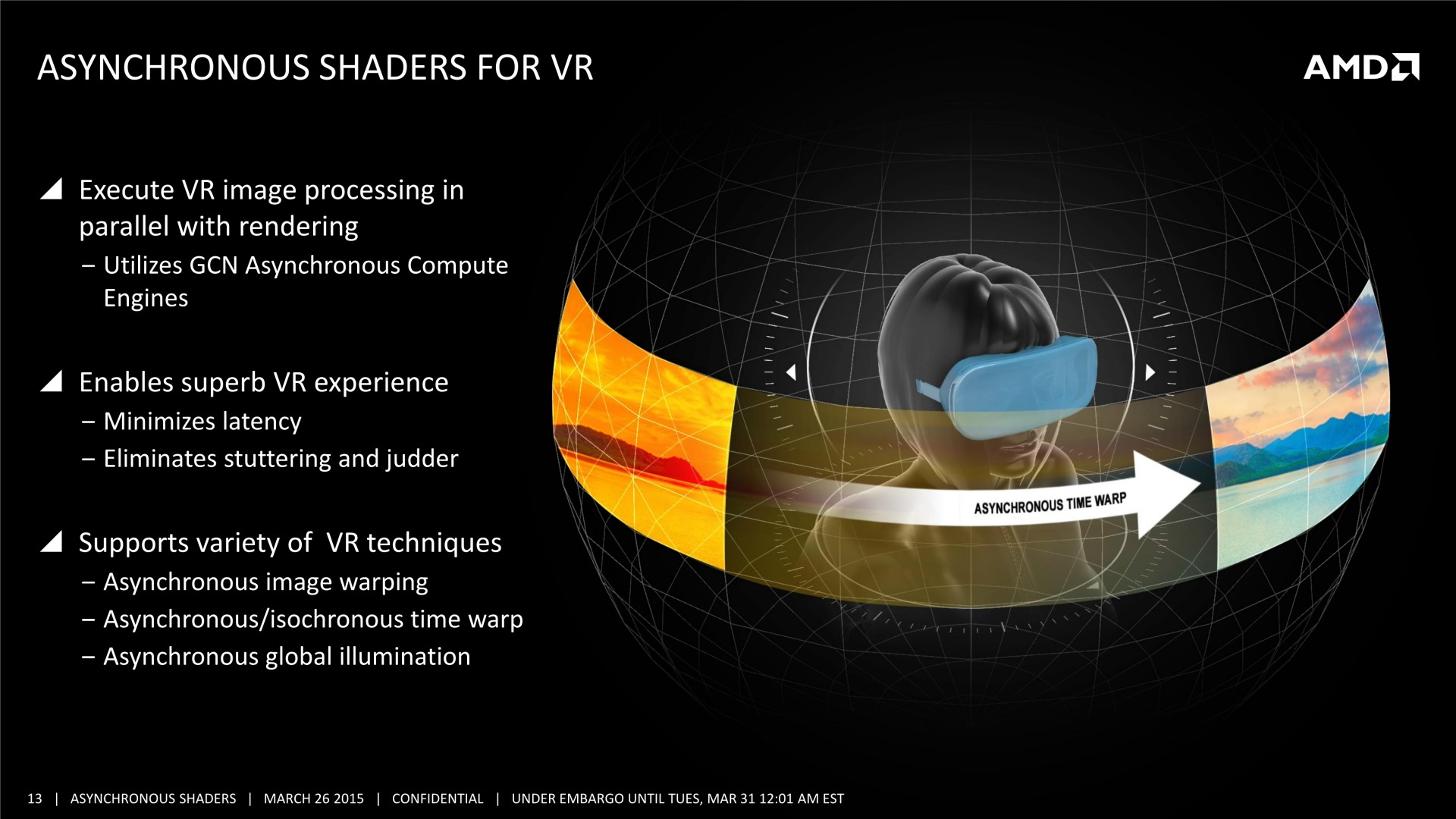





Il n'y pas pas d'information supplémentaire dans cette présentation, mais elle est plus simple à comprendre et mieux finie que celle adressée aux développeurs, nous l'avons donc ajoutée à cette longue actualité. A noter que le marketing technique d'AMD parle d'Asynchronous Shaders pour faire référence à l'exécution concomitante de différentes tâches (même si les opérations de type Copy ne sont pas des shaders). Vous pourrez également observer le résultat obtenu sous une autre démo, que nous avions pu observer également pendant la GDC durant la présentation de LiquidVR. L'utilisation du traitement concomitant du rendu (Graphics) et du post processing (Compute) y permet un gain de performances de 46%.
Si cette stratégie de communication d'AMD ne nous en a pas appris plus, elle a par contre eu le mérite de pousser Nvidia à enfin communiquer sur le même sujet. L'occasion de faire le point sur ce dont sont capables tous les GPU récents, notre première supposition n'étant pas tout à fait correcte concernant les derniers GPU Maxwell.
Du côté d'AMD :
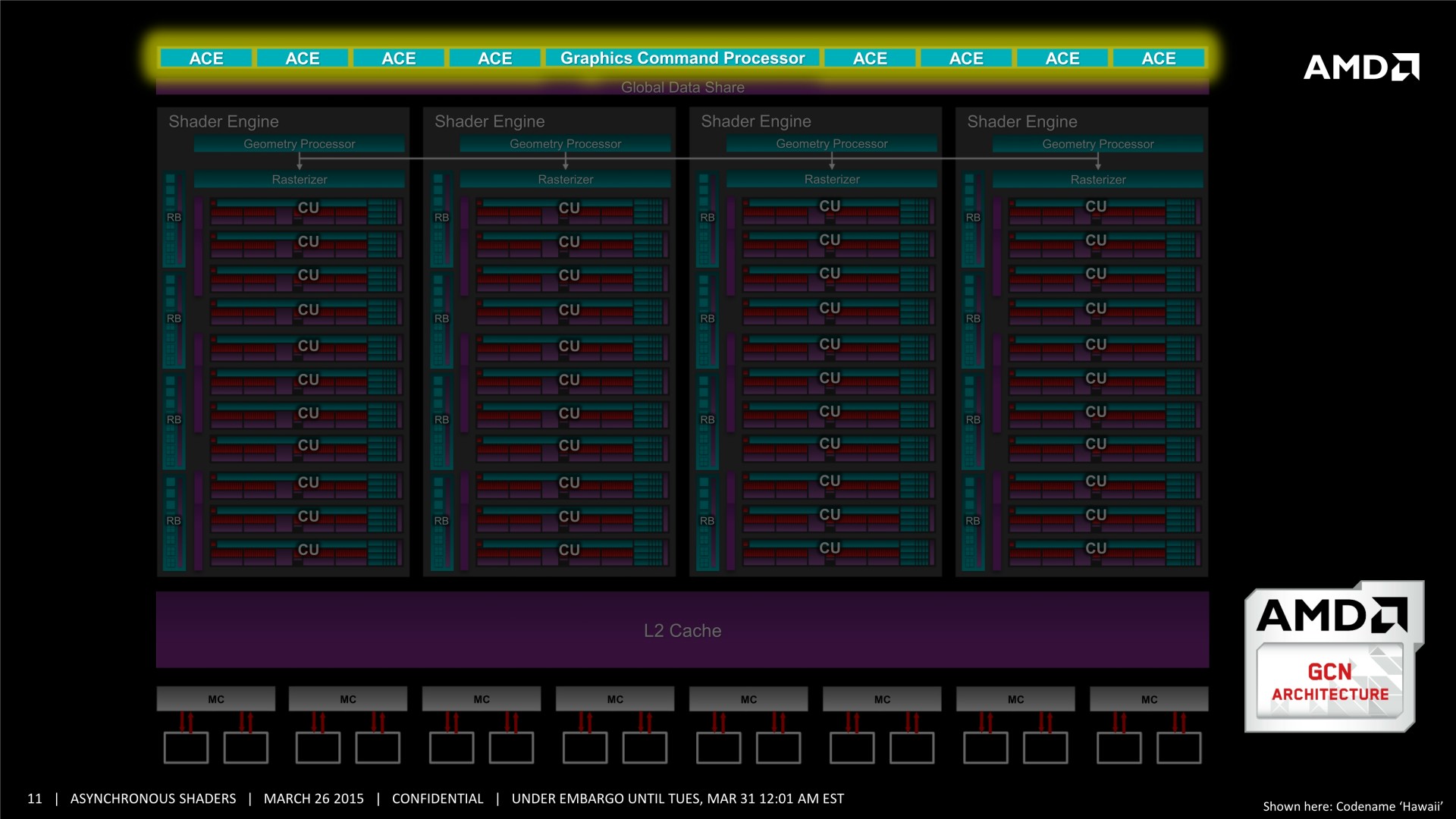
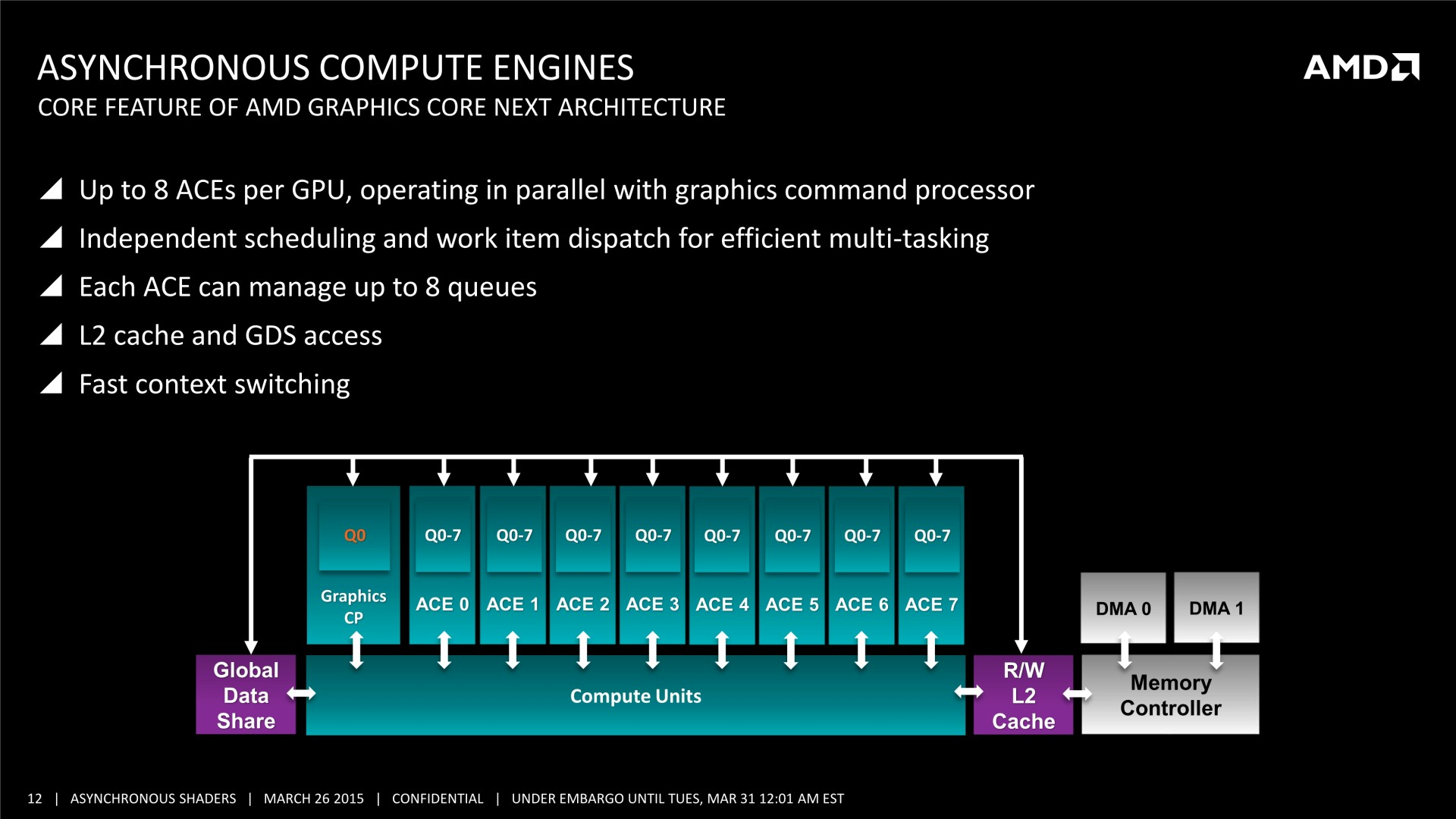
Tous les GPU de type GCN supportent le traitement concomitant des tâches Graphics/Compute/Copy. En plus d'un processeur de commande principal polyvalent, ils disposent au moins de 2 ACE (Asynchronous Compute Engine), dédiés aux tâches de type Compute, et de 2 DMA Engines dédiés aux tâches de type Copy.
Il y a par contre des limitations pour les GPU GCN 1.0 (Tahiti, Pitcairn, Cape Verde, Oland). Leurs DMA engines ne supportent pas toutes les fonctions de synchronisation avec le CPU, ce qui impose probablement des limites au niveau du traitement concomitant des tâches de type Copy. Ensuite, les GPU plus récents, GCN 1.1, supportent plus de files d'attente par ACE (8 au lieu de 1), qui peuvent par ailleurs être présents en plus grand nombre. Ils sont ainsi adaptés au traitement concomitant de nombreuses petites tâches de type Compute (par exemple pour la physique ?), contrairement à leurs prédécesseurs.
AMD a implémenté dans ses pilotes Direct3D 12 un support complet de traitement concomitant de tous les types de tâches, exactement comme c'est le cas sous Mantle. Par contre, nous ne savons pas si les pilotes AMD sont capables de profiter de certaines de ces possibilités pour apporter des optimisations sous certains jeux Direct3D 11.
Du côté de Nvidia :
Les GPU Fermi et Kepler se contentent d'un seul processeur de commandes qui ne peut pas prendre en charge simultanément des commandes de type Graphics et de type Compute. Soit il est dans un mode, soit dans l'autre, un changement d'état relativement lourd à opérer.
Par ailleurs, à l'exception des GK110/GK210, ces anciens GPU ne disposent que d'une seule file d'attente au niveau de leur processeur de commande qui doit traiter les tâches dans l'ordre dans lequel elles sont soumises. Cela limite fortement la possibilité d'en traiter plusieurs simultanément à l'intérieur du mode Compute lorsqu'il y a des dépendances entre elles.
Avec le GK110, Nvidia a introduit un processeur de commandes plus évolué, qui supporte une technologie baptisée Hyper-Q. Elle représente la capacité de prendre en charge jusqu'à 32 files d'attente, mais uniquement en mode Compute. Ce GPU, et les GM107/GM108 qui reprennent cette spécificité, sont ainsi adaptés au traitement concomitant de nombreuses petites tâches de type Compute (par exemple pour la physique ?). Le GK110 a également introduit un second DMA Engine, mais il est réservé aux déclinaisons Tesla et Quadro.
Enfin, avec les GPU Maxwell 2 (GM200/GM204/GM206), Nvidia a fait sauter toutes ces limitations, contrairement à ce que nous pensions. Tout d'abord, le second DMA Engine est bien actif sur les déclinaisons GeForce. Mais surtout, quand Hyper-Q est actif, une des 32 files d'attente peut être de type Graphics.
Au niveau de l'implémentation logicielle, un traitement concomitant complet de tous les types de tâches est supporté sous Direct3D 12 pour les GPU Maxwell 2. Il n'est par contre pas possible d'effectuer une exécution concomitante entre Direct3D 12 et CUDA, qui repose sur un pilote différent.
Nvidia a également implémenté dans ses pilotés un support limité de l'exécution concomitante sous Direct3D 11, pour les tâches compute uniquement. L'API ne permet pas d'y accéder explicitement, mais quelques astuces permettent aux pilotes d'activer un tel mode pour optimiser les performances (dans le cas de GPU PhysX ?). Nvidia nous a précisé que la question d'y ajouter le support d'un traitement concomitant complet de tous les types de tâches, comme sous Direct3D 12, restait en suspens. Ce n'est pas impossible si cela avait une utilité, mais aucun jeu Direct3D 11 actuel n'est prévu pour en profiter. Sans support explicité dans l'API il est très difficile pour les développeurs de faire en sorte que cela puisse fonctionner.
En résumé :
HD 7000 & Rx 240/250/270/280 : processeur de commandes x1 queue + 2 ACE x1 queue + 2 DMA engines
->Graphics/Compute/Copy avec limitations
HD 7790 & R7 260 : processeur de commandes x1 queue + 2 ACE x8 queues + 2 DMA engines
->Graphics/Compute/Copy
R9 285/290 : processeur de commandes x1 queue + 8 ACE x8 queues + 2 DMA engines
->Graphics/Compute/Copy
GTX 400/500/600/700 : processeur de commandes x1 queue + 1 DMA engine
->Pas de support
GTX 750/780/Titan : processeur de commandes x32 queues (limité) + 1 DMA engine
->Compute/Compute
GTX 900/Titan X : processeur de commandes x32 queues + 2 DMA engines
->Graphics/Compute/Copy
Au final, c'est surtout au niveau des anciens GPU que se différencient AMD et Nvidia, le premier ayant un support en place au niveau matériel depuis plus longtemps. Au niveau des cartes graphiques plus récentes, les GeForce GTX 900 pourront profiter pleinement des optimisations liées au traitement concomitant des tâches, tout comme le feront les Radeon R9 290 par exemple.
Par contre, il reste à voir ce qu'en feront les développeurs. Les gains ne seront pas automatiques et il faudra que les différentes étapes du rendu 3D s'y prêtent. Ce n'était de toute évidence pas le cas pour Battlefield 4 et le Frostbite Engine par exemple, dont la version Mantle ne profite pas réellement de ce type d'optimisation.
GDC: D3D12: des feature levels 12_0 et 12_1
Microsoft a dévoilé cet après-midi l'organisation des feature levels, soit des nouveaux niveaux de fonctionnalités de Direct3D 12. Finalement ce seront 2 nouveaux niveaux qui vont être introduits : 12_0 et 12_1.

Le niveau 12_1 apporte spécifiquement le support des Raster Ordered Views et de la Conservative Rasterization. La première fonctionnalité permet de contrôler le respect de l'ordre de rendu des différents éléments de la scène, ce qui est par exemple nécessaire lorsqu'il y a plusieurs niveaux de transparence à respecter, et la seconde permet de vérifier si une primitive est présente dans n'importe quelle petite partie de la zone couverte par un pixel et pas simplement présente en son centre. De quoi pouvoir mieux évaluer sa couverture, ce qui est nécessaire pour certains algorithmes.
Nous vous avions déjà parlé de ces fonctionnalités lors du lancement de la GeForce GTX 980 et de Maxwell de seconde génération, ce qui implique que ces GPU Nvidia récents supporteront bien le niveau 12_1 en plus du 12_0.
Nous ne savons pas encore quels GPU supporteront le niveau 12_0, AMD ne nous ayant pas encore répondu par exemple. Il n'est pas impossible que certains GPU de génération DirectX 11 en soient capables. Rappelons qu'il sera bien entendu également possible d'exploiter à travers Direct3D 12 le matériel limité aux niveaux de fonctionnalités inférieurs, du moment que le GPU supporte une MMU (Memory Management Unit). Les niveaux 11_x seront ainsi exploitables pour la plupart des GPU de la génération DirectX 11 (pas avant GCN chez AMD).

Une autre segmentation existera pour les GPU supportés avec 3 niveaux (Tiers) de capacités de gestion des différentes ressources (Resource Binding). Un GPU devra supporter au moins le Tier 2 pour pouvoir prétendre au niveau de fonctionnalité 12_0. Sans donner plus de détails, Microsoft indique que sur base des dernières statistiques de Steam, et en ne prenant en compte que le matériel compatible avec Direct3D 12, 39% du parc installé est limité au Tier 1, 44% au Tier 2 et 17% supporte le Tier 3. Des chiffres qui seront tirés vers le haut d'ici la sortie de Windows 10.
Nous avons pu poser quelques questions à Microsoft après la présentation et ainsi confirmer que ces niveaux de fonctionnalités 12_0 et 12_1 seront également exposés à travers Direct3D 11.3. Cette mise à jour pour Direct3D 11 ne sera par contre pas proposée en dehors de Windows 10. Microsoft tient d'ailleurs à insister à ce sujet sur le fait qu'un nouvel OS gratuit à la place d'une mise à jour de l'API n'est pas un mauvais deal pour les joueurs, ce qui n'est pas faux il est vrai.
Enfin, au niveau des améliorations matérielles éventuelles à apporter pour parfaire le support de Direct3D 12, Microsoft nous a indiqué qu'un point inhabituel jusqu'ici était ressorti : les processeurs de commandes des GPU peuvent être saturés. C'est assez logique puisque Direct3D 12 permet d'augmenter fortement le nombre de commandes de rendu qu'ils doivent prendre en charge. Muscler ces processeurs de commandes pourra ainsi être bénéfique à l'avenir.












