
Les contenus liés aux tags Nvidia et GTC
Afficher sous forme de : Titre | FluxLa GTX Titan Z est là, prix et specs confirmée
La GeForce GTX Titan Z pour mercredi
La GTX Titan Z en retard
GTC: Quelques détails de plus sur le GPU Pascal
GTC: Volta & Parker retardés, le 16nm TSMC responsable?
GTC: Nvidia Tesla P100: 10 Tflops, HBM2...



Comme prévu, Jen-Hsun Huang, le CEO de Nvidia, a levé un coin du voile concernant le premier produit Pascal, l'accélérateur Tesla P100. Au menu : 15 milliards de transistors, 10 Tflops, HBM2, 4 Mo de L2

Le Tesla P100 est un nouvel accélérateur dédié au calcul massivement parallèle qui embarque un GPU GP100, auquel nous faisions référence précédemment en tant que Pascal, nom de code de son architecture. Il s'agit bel et bien d'un nouveau monstre de puissance. Pour cette première utilisation de procédé de fabrication 16nm FinFET Plus, Nvidia n'a pas eu peur de concevoir un énorme GPU et le GP100 intègre pas moins de 15.3 milliards de transistors répartis sur 610 mm². A comparer aux 8 milliards de transistors de l'actuel GM200 qui mesure également 600 mm².
De quoi pouvoir pousser la puissance de calcul vers le haut mais surtout intégrer de nouvelles fonctionnalités avant tout dédiées au monde du HPC telles que la connectique NVLink qui offre une bande passante combinée de 160 Go/s.



Le Tesla P100 se présente sous la forme d'un module au format mezzanine qui revient à superposer 2 PCB, avec un ou plusieurs connecteurs entre ceux-ci. Sur le Tesla P100 il s'agit de 2 connecteurs de 400 broches qui vont permettre de proposer la connectique NVLink. Ce format facilite également l'intégration dans les serveurs et la mise en place d'un refroidissement performant ce qui permet à Nvidia de pousser le TDP à 300W.

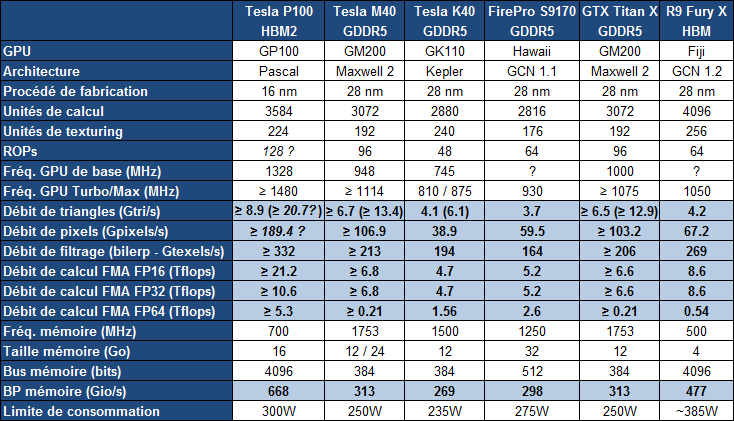
Concernant la puissance brute du Tesla P100, Nvidia annonce 10.6 Tflops avec GPU Boost en FP32, la précision classique, un gain de 60% par rapport aux 6.6 Tflops de la Titan X. L'architecture Pascal dans cette implémentation supporte également la double précision en demi-vitesse, soit 5.3 Tflops, un nouveau bond en avant par rapport au record actuel : 2.6 Tflops pour le GPU Hawaii d'AMD des FirePro W9100 et S9170. Dans l'autre sens, Pascal supporte également la demi-précision, le FP16, et peut alors monter à 21.2 Tflops.
A quelle configuration de GPU pourrait correspondre tout cela ? Au départ, nous supposions que le nombre d'unités de calcul passerait de 3072 sur le GM200 à 4608 sur le P100, réparties dans 36 blocs d'unités de calcul (SMP ?), ce qui aurait permis assez facilement d'augmenter à peu près toutes les capacités brutes du GPU de 50%. Il n'en est cependant rien et les changements sont plus profonds au niveau de l'architecture. Il s'agit ainsi pour le Tesla P100 de 3584 unités de calcul réparties dans 56 blocs de 64, mais le GP100 continent physiquement 60 de ces blocs.
Le gain de puissance de calcul brute provient ainsi principalement d'une hausse de la fréquence du GPU (+/- 1.5 GHz) alors que le GPU computing devrait profiter de cette organisation en plus petits blocs d'unités de calcul, mais également des autres évolutions de l'architecture Pascal, pour gagner en efficacité.
Sur ce point, Nvidia se contente de parler d'une augmentation de la taille du fichier registre. Au total le GM200 embarque +/- 6 Mo de registres, ce qui correspond à 256 Ko par SMM ou encore à 512 registres 32-bit par unités de calcul. Le GP100 passe à 15 Mo de registres, ce qui implique une augmentation de 100%, soit 256 Ko par SMP ou encore 1024 registres 32-bit par unité de calcul. De quoi permettre de maintenir un meilleur taux d'occupation des unités de calcul, particulièrement en double précision.
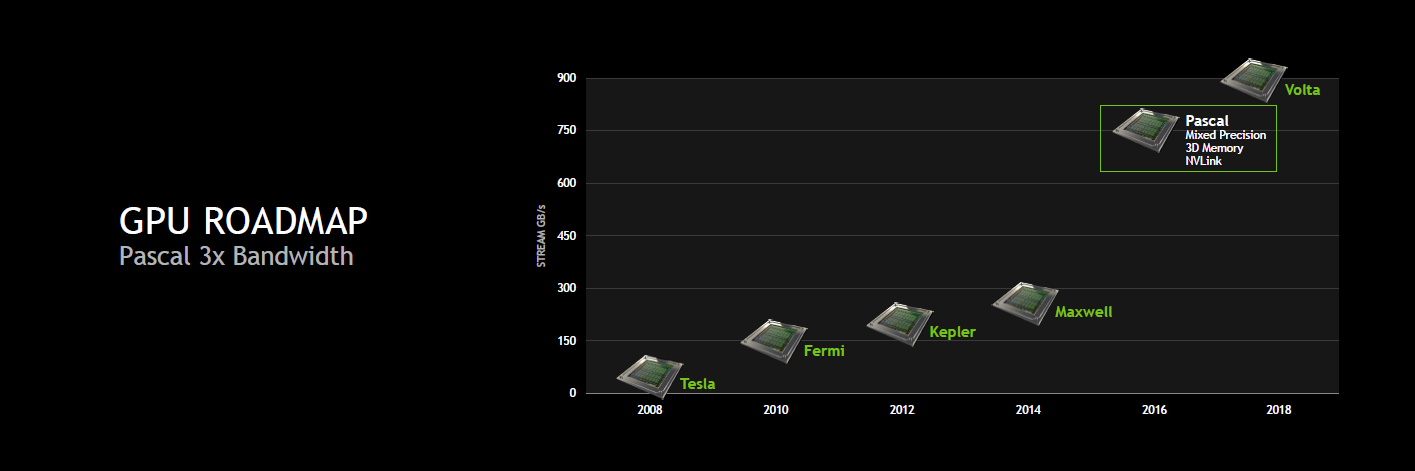
Le cache L2 passe de son côté de 3 à 4 Mo alors que l'interface mémoire est large de 4096-bit en HBM2. Nvidia annonce une bande passante de 720 Go/s pour les 16 Go de mémoire HBM2 CoWoS, le nom donné par TSMC à sa technologie 2.5D, similaire à celle employée par AMD pour son GPU Fiji.
Ce passage à la mémoire HBM2, associé à NVLink, à la puissance de calcul en hausse et au support de la précision FP16 permet au Tesla P100 d'afficher une progression conséquente sur différents plans par rapport à ses prédécesseurs.
Jen-Hsun Huang a terminé le chapitre consacré à Pascal en déclarant que la production en volume avait débuté et que son propre serveur basé sur le Tesla P100 serait commercialisé à partir du mois de juin. Il est probablement raisonnable de s'attendre à une nouvelle GeForce Titan d'ici là, mais sera-t-elle basée sur le GP100 ?
GTC: Deep-learning : +70% pour Pascal
Au détour d'une présentation consacrée à ses outils spécifiques au deep learning, soit à l'apprentissage progressif par un réseau de neurones artificiels, Nvidia a débuté le teasing concernant les performances de sa future architecture Pascal :
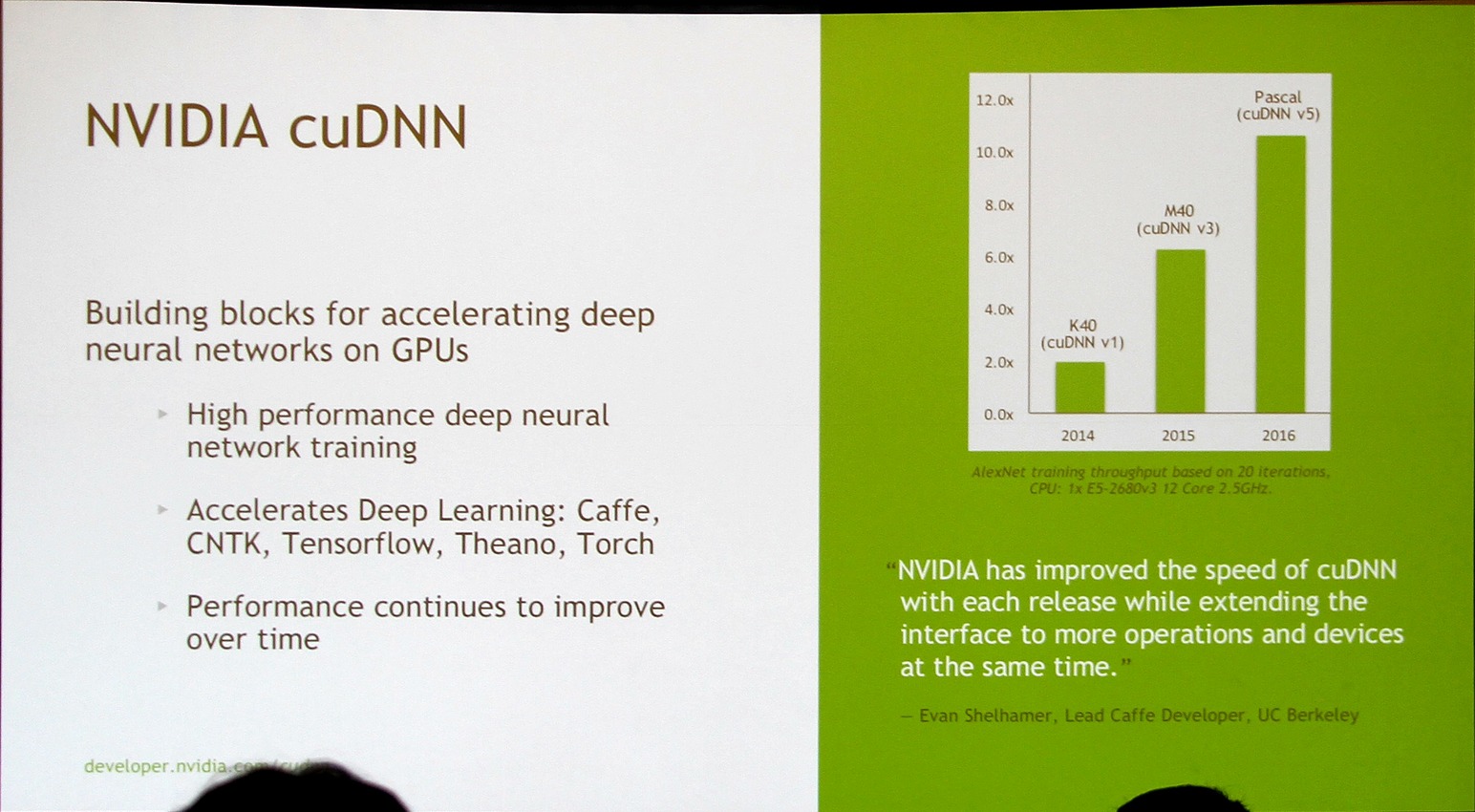
Nvidia fait évoluer régulièrement sa librairie cuDNN (CUDA Deep Neural Network) et en propose des évolutions majeures pour ses nouvelles architectures GPU. Ces évolutions vont d'ailleurs de pair pour booster les performances : cuDNN v1 avec une Tesla K40 (GK110) a doublé les performances par rapport aux précédentes solutions et cuDNN v3 avec une Tesla M40 (GM200) sous architecture Maxwell les a plus que triplées (6.25X).
Le deep learning étant l'une des priorités principales de Nvidia avec les performances en jeu, Pascal va bien entendu pousser la barre encore plus haut dans ce domaine. Il est ainsi question de 10.5X, soit +70% par rapport au GM200, pour un GPU Pascal indéterminé associé à cuDNN v5.
Difficile cependant de juger des performances globales de ce GPU Pascal sur base de ce seul chiffre puisqu'il reste bien entendu à savoir dans quelle proportion ces gains proviennent d'une augmentation de la puissance brute du GPU ou d'optimisations de l'architecture spécifiques au deep learning. Nous devrions en apprendre un peu plus dans le courant de la semaine.
GTC: Multi-Res Shading, pas que pour la VR ?
Lors d'une session consacrée à la suite VRWorks, soit l'ensemble des technologies que Nvidia propose pour améliorer l'exploitation de la VR, John Spitzer, Vice Président du GameWorks Labs, est revenu sur le Multi-Resolution Shading et les futures possibilités offertes par cette approche.

Pour rappel, la déformation des images pour s'adapter aux lentilles des casques de réalité virtuelle réduit la résolution en périphérie. Une perte qui n'est pas très importante puisque le regarde se porte vers le centre de l'image, mais des pixels ont été calculés alors qu'ils n'apportent qu'un bénéficie limité. Le Multi-Resolution Shading part de ce constat pour réduire directement la résolution lors du rendu de l'image. Une perte de qualité minimale en périphérie qui permet un gain substantiel sur le plan des performances.
Si cette approche a été développée pour la réalité virtuelle, Nvidia envisage cependant de la proposer pour l'affichage sur des écrans classiques. C'est d'ailleurs ce format que Nvidia a utilisé à la GTC pour faire la démonstration du Multi-Resolution Shading et le résultat était loin d'être mauvais, tout du moins sur le grand écran de la salle de présentation.
Nvidia explique que certains jeux pour lesquels le regard du joueur doit se porter sur le centre de l'image pourraient être de bons candidats. C'est le cas de certains fps, d'autant plus que le champ de vision classique fait que les textures sont étirées sur les côtés de l'images et perdent donc déjà en résolution, ce qui amoindrit quelque peu l'impact de cette optimisation qui pourrait être bienvenue pour certains GPU d'entrée de gamme ou encore pour faciliter le passage à la 4K.
Nvidia envisage également une solution de type eye tracking qui permettrait de toujours conserver la pleine résolution là où se porte le regard du joueur. Un eye tracking basique à 60 Hz (ce qui est très loin d'être idéal) produirait déjà de bons résultats si la marge de sécurité est suffisante autour de la zone où le regard est détecté.
Ce ne sont encore que des expérimentations, mais il est possible que Nvidia propose d'ici quelques temps ce type d'optimisation optionnelle soit directement via ses pilotes soit indirectement via les moteurs de jeux.
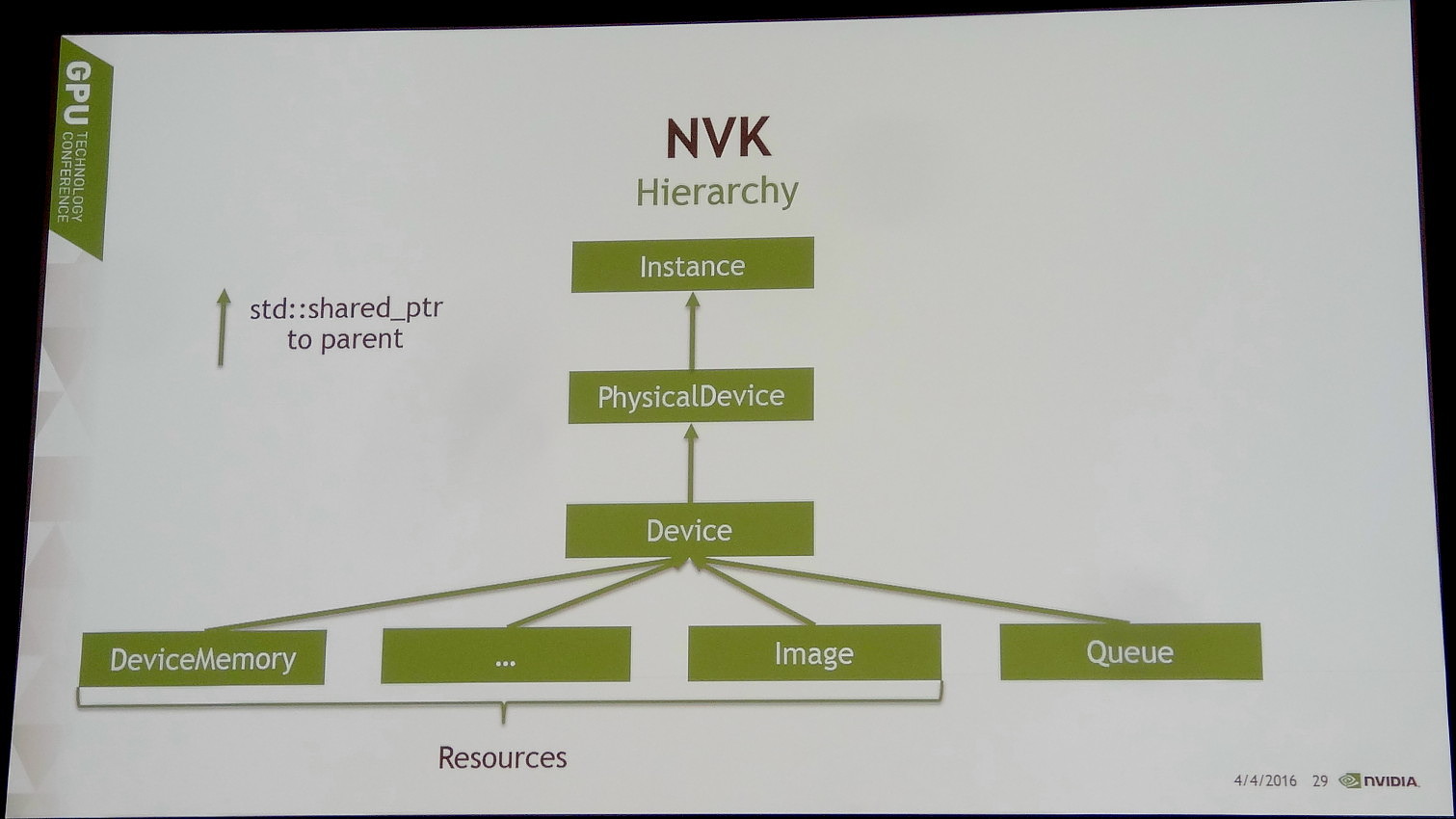
GTC: VKCPP et NVK pour simplifier Vulkan
Lors de la GDC, nous vous indiquions qu'Imagination proposait un framework destiné à faciliter l'utilisation de l'API Vulkan. Avec VKCPP et surtout NVK dévoilé à l'occasion de la GPU Technology Conference (GTC), Nvidia suit la même voie.

Comme vous l'aurez sans aucun doute compris, maîtriser les nouvelles API de bas niveau est loin d'être aisé. Si elles ouvrent de nouvelles possibilités et permettent aux meilleurs développeurs de produire un code plus efficace sur le plan des performances, elles sont moins abordables et les opportunités explosent pour les bugs en tout genre. Proposer des outils qui en simplifient la bonne exploitation est donc assez logique pour Nvidia et particulièrement en ce qui concerne Vulkan qui va intéresser les développeurs au-delà du jeu vidéo, domaine qui peut se satisfaire plus facilement d'API complexes mais bien exploitées par une poignée de gros moteurs de jeu. Le potentiel de cette API est en effet très varié du côté professionnel mais encore faut-il convaincre les développeurs de sauter le pas.
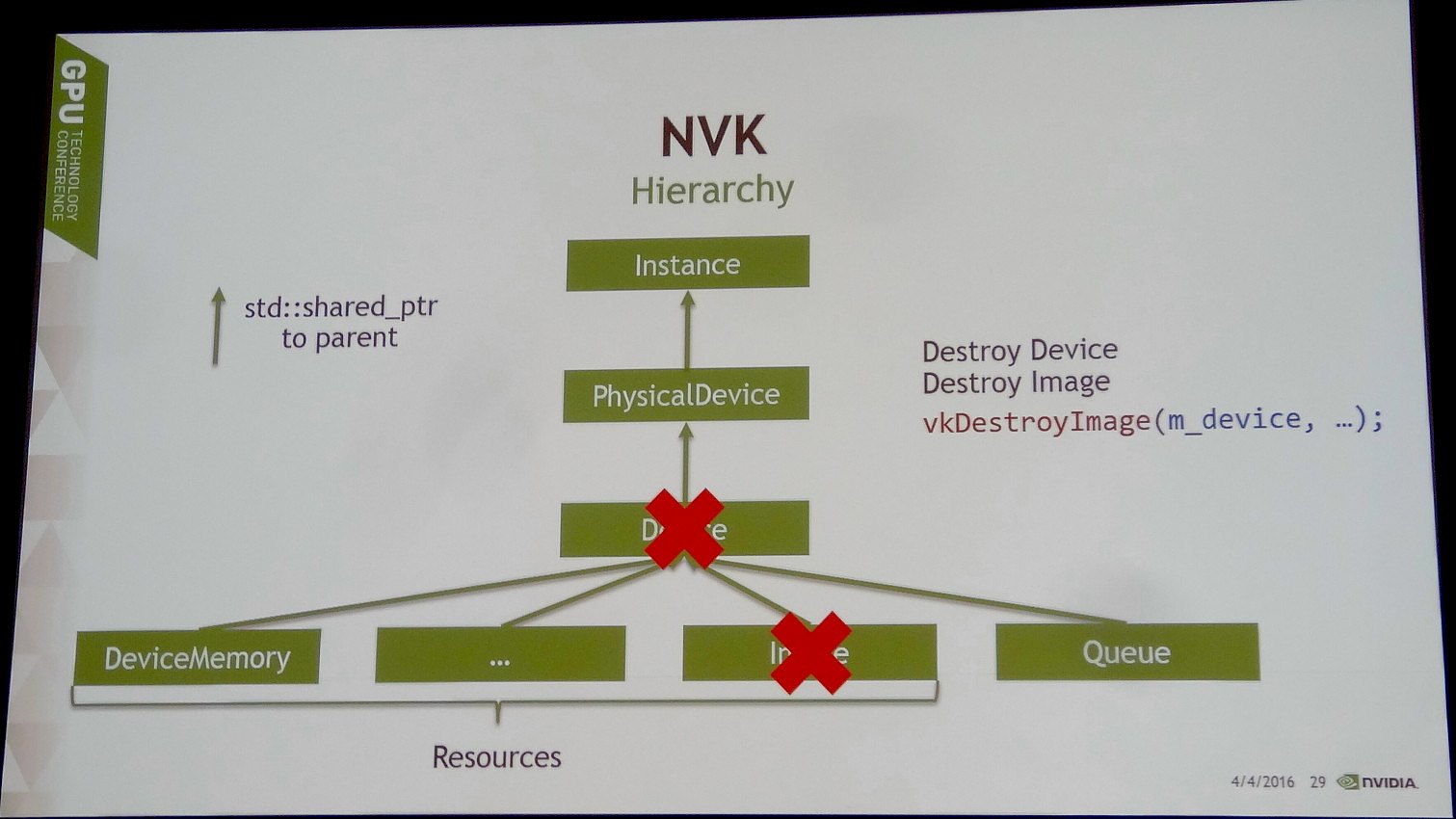
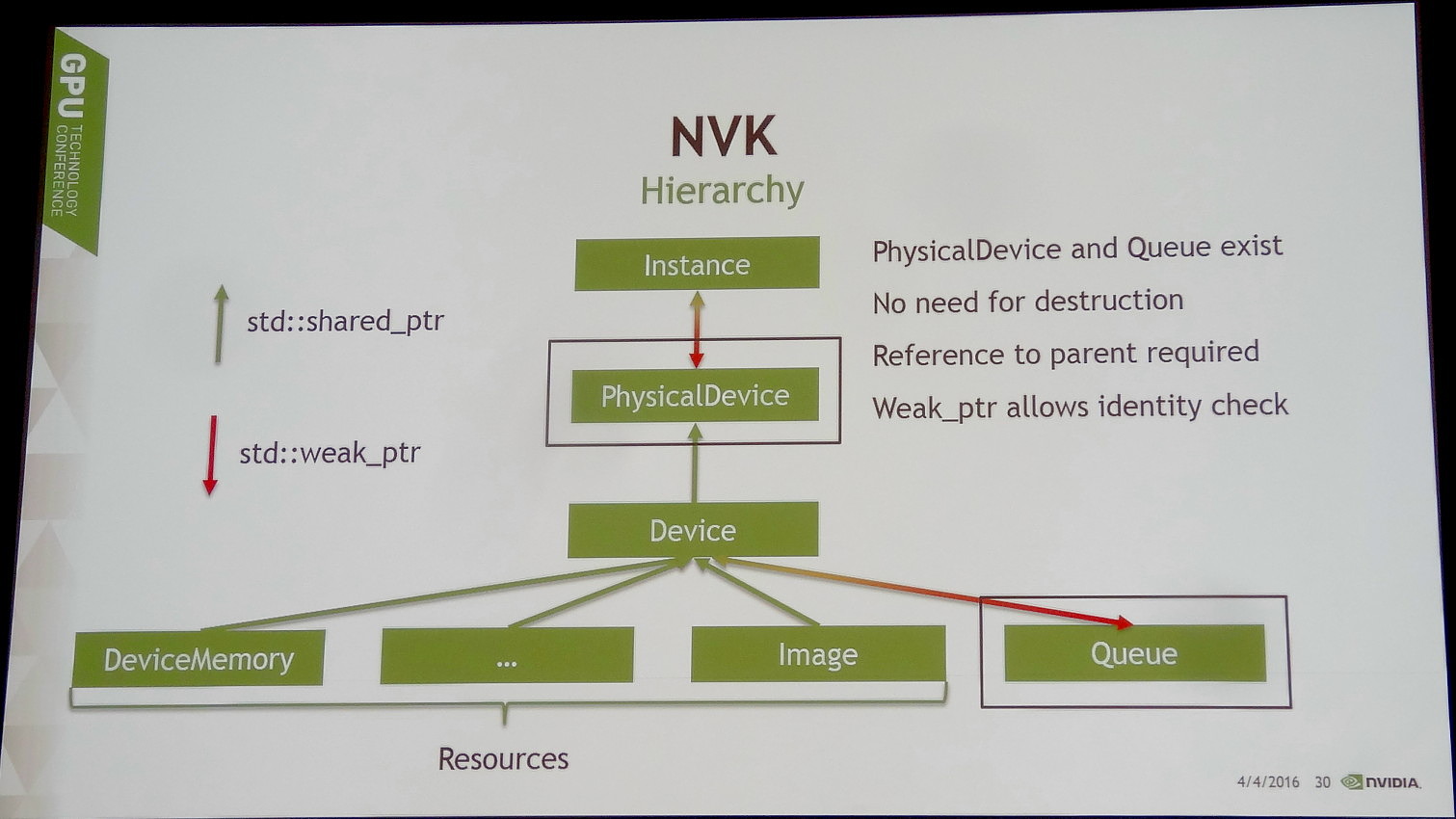
Lors de l'annonce du framework d'Imagination, Nvidia nous avait indiqué également proposer un outil similaire avec Vulkan C++, ou VKCPP. Ce n'était en fait pas tout à fait correct, mais Nvidia travaille également sur NVK qui s'en rapproche beaucoup.


VKCPP est un portage de Vulkan, une API de type C, vers C++. Certains aspects du code gagnent en clarté, d'autres peuvent être condensés et le compilateur s'assure de la validité de certaines commandes, là où Vulkan classique va autoriser des opérations qui les pilotes n'acceptent pas. Nvidia précise cependant que VKCPP reste une solution destinée aux experts, qui ne rend pas réellement plus abordable l'API Vulkan.
Une solution différente destinée à s'attaquer à ce problème est cependant en développement, NVK, son nom de code actuel (il pourrait changer).


Le but de NVK est de permettre aux développeurs d'obtenir un premier résultat très rapidement. Pour cela, ce framework va proposer des fonctions simples pour les tâches de routine telles que le suivi des ressources, l'allocation de la mémoire, la préparation du framebuffer etc. NVK empêche également les développeurs de faire par erreur des opérations qui n'ont aucun sens mais qui peuvent entraîner toute une série de bugs plus ou moins difficiles à corriger.
Au final, la démo HelloVulkan de Nvidia, qui consiste simplement à dessiner un triangle, demande 750 lignes de code avec l'API Vulkan classique. En passant par le prototype actuel du framework NVK, 200 lignes de code suffisent. Et même si une bonne partie de ces lignes de code supprimées représentent des aspects triviaux pour la plupart des développeurs, ils sont surtout des sources de bugs potentiels éliminées.
Par ailleurs, ce n'est pas seulement le développement initial qui se trouve simplifié, mais également l'évolution et la maintenance du code. Des aspects cruciaux pour bon nombre de développeurs. Reste cependant à voir si Nvidia compte proposer des back-ends pour des solutions autres que ses propres GPU. Ce ne sera peut-être pas directement le cas, mais VKCPP est un projet open source disponible sur GitHub et de toute évidence il devrait en être de même pour NVK.
Vous pourrez retrouver la présentation complète de Nvidia ci-dessous :






























Nvidia Pascal: le FP16 pour doubler les Tflops
Le CEO de Nvidia, Jen-Hsun Huang, a profité de l'ouverture de la GPU Technology Conference pour donner un détail de plus concernant sa future architecture GPU prévue pour 2016 : Pascal supportera la précision de calcul FP16.
L'an passé, les premiers détails avaient déjà été communiqués au sujet de Pascal, vous pourrez retrouver nos actualités dédiées ici et là.
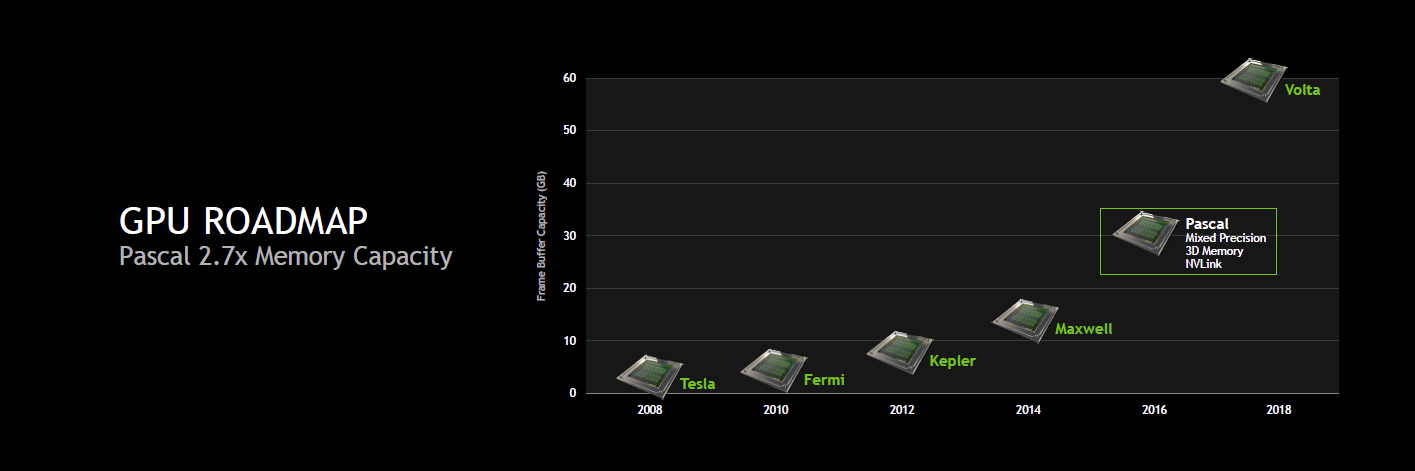
Ainsi, pour rappel, nous savions déjà au sujet de cette architecture intermédiaire entre Maxwell et Volta que Nvidia visait 32 Go de mémoire 3D et une bande passante totale de 1 To/s, soit à peu près le triple de ce dont est capable un GPU tel que le GM200 de la GeForce GTX Titan X. Nvidia avait également annoncé un format de type mezzanine pour les serveurs et une nouvelle interconnexion : NVLink.
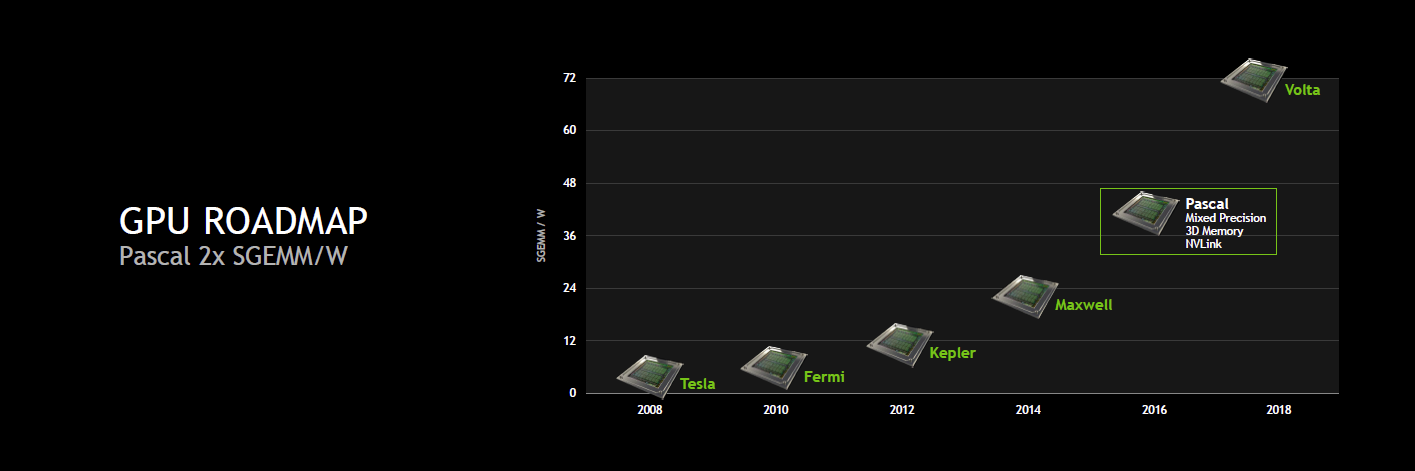
Il était par contre alors question d'une augmentation de 66% des performances par watts en SGEMM (FP32). Visiblement, Nvidia est plus ambitieux cette année et parle dorénavant d'un doublement des performances par watts.
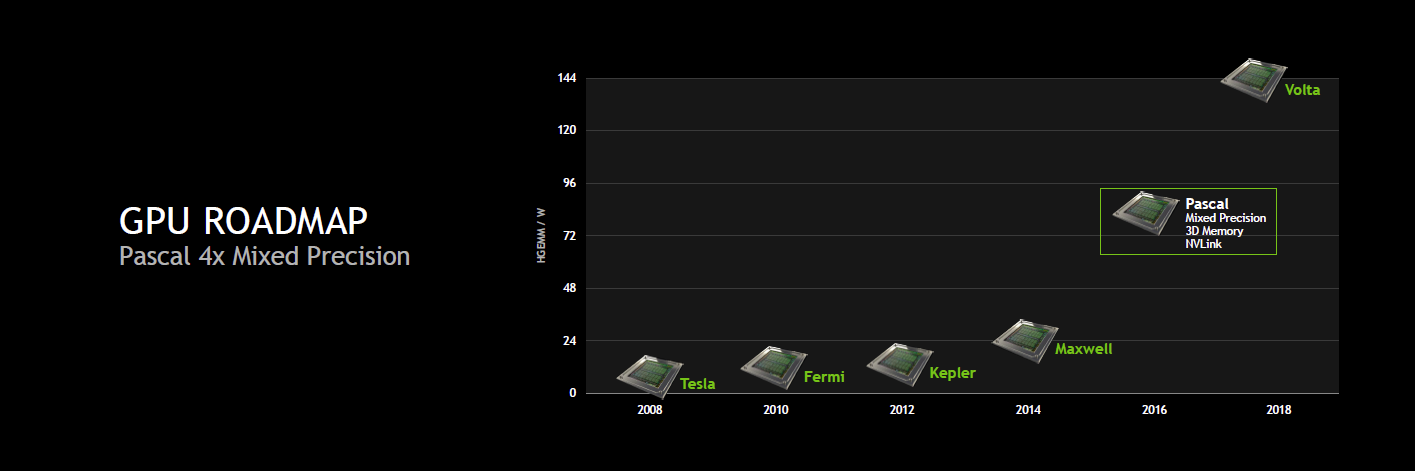

Mais surtout, Nvidia compte aller plus loin dans l'augmentation de la puissance de calcul et c'est là que se trouve le nouveau détail concernant Pascal : il supportera le calcul en FP16 et la précision mixte. Nvidia reprend probablement cette spécificité du Tegra X1 dont les unités de calcul FP32 sont également capables de traiter 2 opérations FP16, étendue pour plus de flexibilité. De quoi potentiellement doubler les performances pour les applications qui peuvent se satisfaire d'une précision de calcul réduite.
Le but de la précision mixte sera de pouvoir mélanger dans un algorithme des opérations des différents niveaux de précision supportés par le GPU, FP16, FP32, FP64, pour n'exploiter les instructions plus lentes et plus gourmandes que là où elles sont réellement nécessaires. Les optimisations potentielles sont légions mais les identifier et les exploiter efficacement en pratique est probablement une difficulté qui va se poser.
En combinant les évolutions au niveau du sous-système mémoire à cette précision mixte et en doublant le nombre de GPU d'un système à l'aide de NVLink, Nvidia table sur une multiplication par 10 des performances. Un chiffre qui est par contre probablement très optimiste.