
Les contenus liés aux tags Tesla et GTC
GTC: CUDA on ARM: Tegra 3 + Tesla K20
GTC: Tesla passe à Kepler avec les K10 et K20
GTC: Nvidia lève le voile sur le GK110
GTC: CUDA on ARM: Tegra 3 + Tesla K20



En plus des plateformes CUDA on ARM destinées à simuler de futurs SoC que ce soit pour une utilisation de type périphérique mobile grand public ou de type micro-serveur, des développements se font également autour d'accélérateurs très puissants tels que les Tesla K20.
C'est le cas chez l'européen PRACE qui développe des systèmes dédiés au supercomputing et s'intéresse à CUDA on ARM depuis quelques temps. En collaboration avec le Barcelona Supercomputing Center, PRACE est en train de mettre au point une plateforme ARM équipée en GK110 : Pedraforca v2. Celle-ci est composée d'une carte mini-ITX sur laquelle prend place un module Q7 Tegra 3 dont 4 des lignes PCI Express 2.0 sont connectées à un switch PLX PCI Express 3.0 sur lequel vont venir se greffer un accélérateur Tesla K20 et une carte contrôleur InfiniBand 40 Gbps.

Cette plateforme a la particularité de ne pas rechercher la complémentarité entre les cores CPU et GPU. Grossièrement, le but est d'utiliser le SoC ARM uniquement pour activer un système CUDA plus ou moins indépendant. C'est la raison pour laquelle le Tesla K20 est associé à un contrôleur InfiniBand sur un même switch PCI Express 3.0 : ils peuvent ainsi communiquer très rapidement avec les accélérateurs d'autres nuds en ignorant autant que possible la communication avec les SoC et leurs mémoires.
Les développeurs de Pedraforca v2 sont bien conscients qu'une telle approche n'est pas une solution de remplacement générale à un système CUDA classique et se contentera de répondre avantageusement à un sous-ensemble de problématiques : si un problème massivement parallèle peut être résolu sans CPU, autant réduire l'encombrement et la consommation de celui-ci.
Une telle solution permet par ailleurs de simuler le comportement de futurs GPU haut de gamme qui pourraient intégrer un ou plusieurs cores ARMv8 Denver pour gagner en indépendance. De quoi commencer à préparer des algorithmes qui leur seront adaptés ?
GTC: Tesla passe à Kepler avec les K10 et K20

Nvidia vient de dévoiler deux nouvelles cartes Tesla basées sur l'architecture Kepler. La première, dénommée K10 est en quelque sorte une version Tesla serveur de la GeForce GTX 690. Il s'agit donc d'une carte équipée de 2 GPU GK104 et d'un switch PCI Express 3.0 PLX. Par rapport à la GeForce GTX 690, les fréquences ont bien entendu été revues à la baisse et passent d'une fourchette de 915 à plus de 1100 Mhz (suivant le niveau de turbo) à 745 MHz pour le GPU et de 1500 à 1250 MHz pour la mémoire.
Nvidia semble ainsi avoir laissé de côté GPU Boost, probablement parce que la variabilité qui y est liée n'est pas compatible avec le monde professionnel. La base de la technologie, qui permet de contrôler dynamiquement la fréquence pour maintenir un certain TDP est par contre de toute évidence de la partie, ce qui permet à Nvidia de proposer un TDP relativement faible qui tourne autour de 225-235W, contre 300W pour la GeForce GTX 690.
La K10 est équipée de 4 Go de mémoire GDDR5 par GPU, soit 8 Go au total, et supporte l'ECC, d'une manière similaire à ce qui se fait sur les précédentes cartes Tesla : une partie de la mémoire est utilisée pour stocker les données de parité, ce qui réduit l'espace mémoire disponible ainsi que la bande passante pratique. La puissance de calcul en double précision reste par contre extrêmement faible, tout comme certaines opérations logique ou sur les entiers, le GPU GK104 étant très limité à ce niveau. En d'autres termes, la carte K10 affiche une puissance de calcul en simple précision flottante énorme, de 4577 Gflops et sera donc destinée à ce type de calculs uniquement. En double précision le débit tombe à 190 Gflops.
La seconde carte Kepler annoncée aujourd'hui, la K20 est la plus intéressante des deux puisqu'elle embarquera un GPU GK110 au sujet duquel Nvidia vient de donner les premières informations. Peu de détails sur la K20 sont communiqués à ce jour, ses spécifications ne seront fixées que plus tard dans l'année puisqu'elle est prévue pour le dernier trimestre 2012. Il est cependant probable qu'elle soit équipée d'un GK110 partiellement castré avec 13 blocs d'unités de calcul actifs sur les 15 disponibles pour un total de 2496 de ces unités de calcul. Nvidia indique par ailleurs que ses performances en double précision seront triplées par rapport à la génération actuelle et supérieures à 1 Tflops, ce qui en fera une carte bien plus polyvalente pour le calcul, d'autant plus que son GPU apporte plusieurs innovations importantes pour faciliter son exploitation avec un maximum d'efficacité.

La carte K20 devrait être accompagnée de 6 Go de mémoire GDDR5 et sera disponible avec un TDP de 225W, ce qui est plutôt impressionnant compte tenu de la complexité de ce GPU. Il est probable que Nvidia profite du fait qu'en général les blocs du GPU dédiés au graphique ne seront pas utilisés pour pouvoir compresser le TDP. Nvidia nous précise cependant que si un intégrateur dispose d'une plateforme certifiée pour un TDP plus élevé, la carte K20 pourra s'y adapter pour profiter de la marge supplémentaire. Elle sera par ailleurs disponible en version workstation en plus de la version serveur.
GTC: Nvidia lève le voile sur le GK110

Sans le nommer directement, Jen-Hsun Huang, le CEO de Nvidia, vient de dévoiler les premières informations au sujet du "gros" GPU Kepler, le GK110. Nous avons tout d'abord la confirmation qu'il s'agit bien d'un énorme GPU de pas moins de 7.1 milliards de transistors fabriqués en 28nm, un nouveau record. Certains doutes subsistaient par rapport à ce chiffre puisqu'il correspond presqu'exactement à deux GPU GK104, la configuration de la nouvelle carte Tesla K10, mais ce n'est qu'une coïncidence.
GTC oblige, c'est avant tout son intérêt pour le monde professionnel et particulièrement pour le calcul haute performance qui est mis en avant par Nvidia. Deux nouvelles technologies importantes font leur apparition dans ce GPU. Tout d'abord Hyper-Q qui permet d'utiliser jusqu'à 32 queues d'exécution pour alimenter le GPU, contrairement à une seule auparavant. Une limitation qui empêchait dans bien des cas la pleine exploitation de toute la capacité de calcul des GPU.

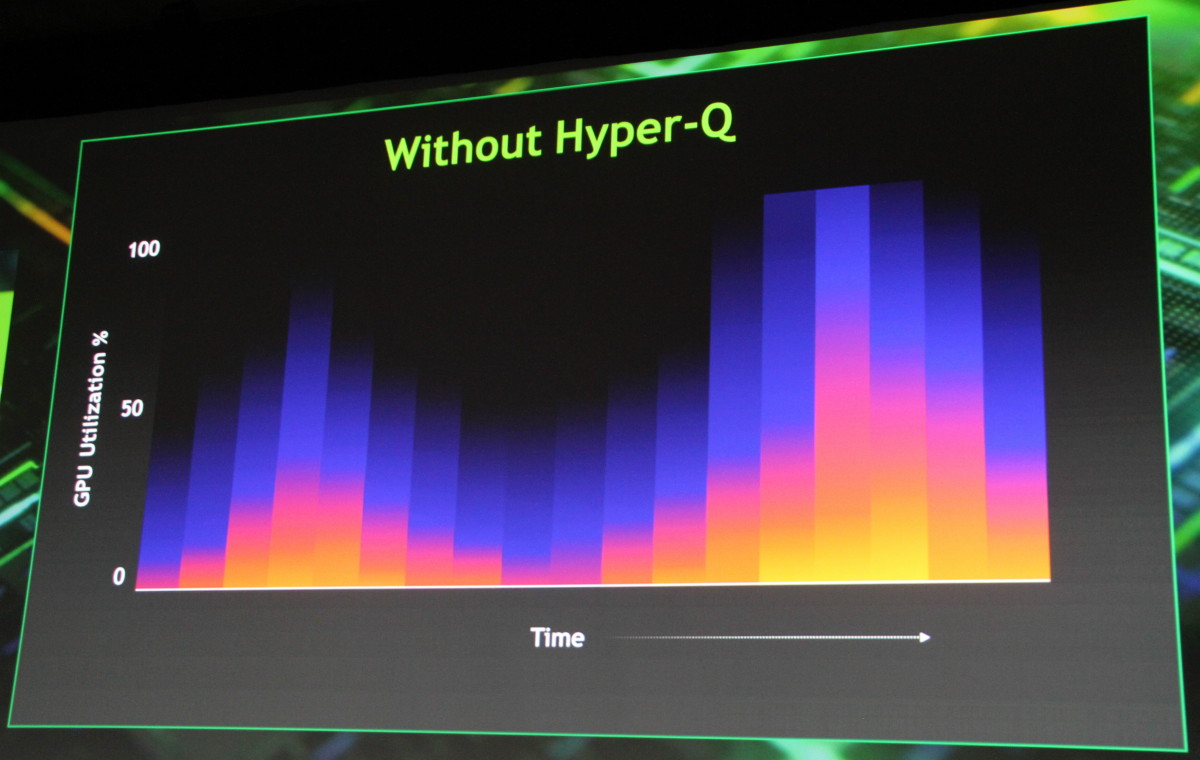
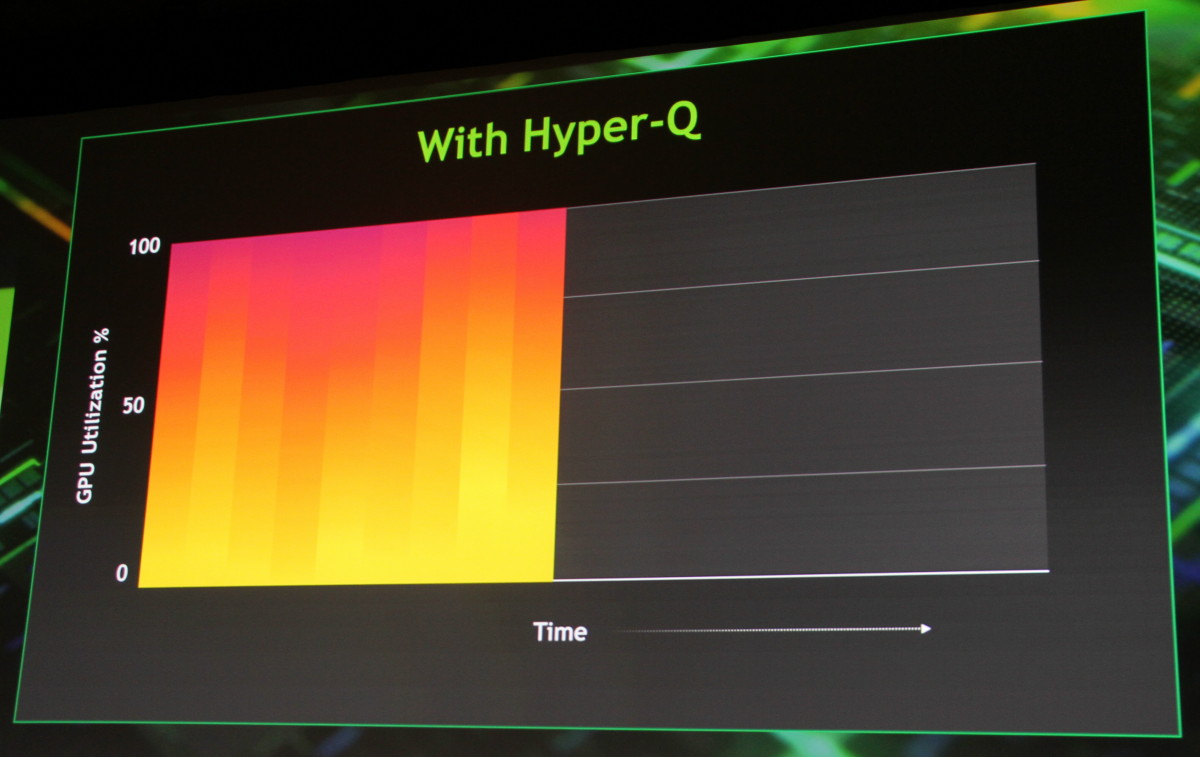
Hyper-Q permet de maximiser le rendement du GPU et de réduire le temps d'exécution.
La seconde innovation se nomme Dynamic Parallelism et vient également apporter une réponse à un problème d'efficacité actuelle. Le travail à exécuter sur le GPU est en général segmenté, et chacun des segments est initié par le CPU. Entre chacun de ceux-ci, le GPU rend ainsi la main au CPU qui reçoit les résultats d'une fonction, et dans certains cas renvoie ces mêmes résultats au GPU pour lancer une seconde fonction qui en est dépendante. L'inefficacité est évidente. Dynamic Parallelism représente la capacité du GK110 à auto-générer de nouvelles tâches, de quoi éviter ces allers-retours entre le CPU et le GPU.

Cette nouvelle flexibilité dans l'exécution des tâches va faciliter le travail des développeurs d'une part en proposant plus simplement un rendement élevé et d'autre part en leur permettant d'écrire leurs programmes d'une façon plus naturelle.

Enfin, Nvidia a dévoilé une photo du die du GK110, certes retravaillée artistiquement mais qui permet de se faire quelques idées sur les spécifications de ce GPU. On peut tout d'abord observer la présence de 15 SMX et d'un contrôleur mémoire de 6x 64 bits, soit 384 bits. Nvidia nous a confirmé ces spécifications et précisé que les SMX du GK110 seront également équipés de 192 unités de calcul, comme pour le GK104. Leur nombre total sera donc de 2880 et là aussi il s'agit d'un nouveau record, même si Nvidia précise qu'il n'y aura en principe pas de dérivé Tesla équipé d'une version complète de ce GPU, profiter d'un certain niveau de redondance étant nécessaire avec un GPU d'une telle taille, plus de 500mm². La première carte Tesla K20 basée sur le GK110 sera probablement limitée à 13 SMX et 2496 unités de calcul.
Nvidia nous a indiqué que l'organisation des registres et de la mémoire partagée avait été revue, et que la puissance de calcul en double précision était très élevée, mais il faudra patienter encore un jour ou deux avant d'avoir plus de détails sur le sous-système mémoire du GK110.
Sur le plan graphique, nous pouvons supposer que chaque SMX conserve 16 unités de texturing et que leur nombre total dans ce GPU est de 240. L'organisation des SMX en 5 groupes de 3 nous laisse penser que le GK110 serait capable de traiter jusqu'à 7.5 triangles par cycle mais de n'en rendre que 5 ou 6 par cycle (suivant l'implémentation pour laquelle a opté Nvidia), contre 4 et 4 pour le GK104. Enfin, de toute évidence il disposera de 48 ROP.
Ce futur GPU sera tout d'abord introduit à la fin de l'année en tant que Tesla K20 mais ne débarquera pas en tant que GeForce avant début 2013. Il sera bien entendu intéressant d'observer la consommation d'un tel monstre, même si Nvidia se veut rassurant en précisant que la carte Tesla K20 est prévue avec un TDP classique de "seulement" 225W !