
Les contenus liés au tag IBM
Afficher sous forme de : Titre | FluxIBM ouvre un peu plus l'architecture Power
Focus: Common Platform Technology Forum 2013
Intel détaille son 22nm dédié aux SoC
Common Platform Technology Forum 2012
IBM et AMD
Premières puces en 7nm pour IBM !



Alors qu'IBM a revendu son activité fabrication de semi-conducteurs à Global Foundries en octobre dernier (un rachat qui s'est finalisé le premier juillet de cette année), IBM vient annoncer avoir produit une puce de test fonctionnelle en 7nm, une première que rapportent nos confrères d'EETimes .
Si IBM réalise l'annonce, en pratique la puce a été fabriquée dans un centre de recherche du SUNY Polytechnic Institute financé en partie par l'état de New York et divers partenariats privés. Virtuellement toutes les sociétés du milieu participent puisque l'on retrouve dans la liste des sociétés, outre IBM, Intel, TSMC, Samsung, GlobalFoundries ou encore ASML. C'est à cet endroit que l'on retrouve par exemple l'effort de recherche du Global 450mm Consortium qui travaille sur la future transition aux wafers de 450mm (contre 300 actuellement, un mouvement qui a pris un coup d'arrêt ces dernières années).
Avant son rachat, IBM avait annoncé participer à hauteur de 3 milliards (sur 5 années) au développement de futures puces, tandis qu'en début d'année, suite au rachat par GloFo, IBM avait regroupé ses 220 ingénieurs restants sur le site de SUNY sous l'égide « IBM Research ».
Historiquement, IBM a toujours aimé jouer au jeu des annonces et continue ici dans sa tradition. En pratique il s'agit d'une première puce de test qui inclut transistors, cellules SRAM et interconnexions, les blocs essentiels même si, évidemment, on reste cependant très loin de la production en volume.

Les transistors FinFet 7nm vus au microscope
Au-delà de l'effort, on s'intéressera surtout aux choix réalisés par IBM pour son process, qui repose cette fois sur l'EUV. Nous avions eu l'occasion d'en parler, l'EUV va mieux et si une introduction est possible en cours de node pour le 10nm, TSMC et les autres visent une introduction ferme pour le 7nm et de ce côté IBM ne déroge pas.
Plus surprenant, les choix réalisés autour des structures et des matériaux. Alors que l'on s'attend probablement à voir d'autres structures que le FinFet introduites à 10 ou 7nm par Intel, IBM utilise ici des structures FinFet également, la différence s'effectuant sur les matériaux avec le retour du silicium-germanium (SiGe) étiré pour le canal, sur substrat en silicium. Ce n'est pas la première fois que le germanium apparait dans les process, même si aujourd'hui on le trouve principalement dans les process analogiques/radio . L'utilisation du SiGe étiré dans les semi-conducteurs est une innovation d'IBM et il est assez surprenant de le retrouver sur un process si avancé, qui plus est en EUV. D'autant que côté densité, les transistors peuvent être espacés de 30nm ce qui permettrait, par rapport au 10nm qui était en développement par IBM, d'augmenter la densité de 50%.

Développer un process « clef en main » - c'est comme cela qu'il est décrit par IBM qui dit avoir optimisé non seulement l'EUV, le dépôt du SiGe mais aussi les autres étapes du process comme l'interconnexion (BEOL) ne manque évidemment pas d'ironie mais nos confrères d'EEtimes notent qu'IBM fera profiter logiquement de ses travaux de recherche à GlobalFoundries qui pour rappel dispose d'une exclusivité de 10 années pour la production des processeurs serveurs d'IBM. Nos confrères sous entendent que Samsung pourrait également profiter de ces travaux, en se rappelant aux bons souvenirs de l'abandonnée Common Platform qui liait les trois sociétés.
Rien n'en est cependant moins sur puisque pour rappel, Samsung avait développé son propre process 14 nm sans IBM qui aura au final sauté ce node. Le fondeur coréen avait ensuite partagé son 14nm en intégralité avec GlobalFoundries. Pour le 10nm, IBM avait travaillé également sur son propre process que l'on retrouvera vraisemblablement tel quel chez GlobalFoundries. Les trois sociétés semblent cependant être restées en bons termes et l'on imagine que si la solution 7nm d'IBM est plus intéressante que les efforts développés en internes, ces sociétés continueront de mutualiser leurs efforts pour une éventuelle mise en production, que l'on n'attend pas de toute manière avant 2018 ou 2019. Ce que fera Samsung en 10 nm nous donnera peut-être un indice. Pour l'instant, si le constructeur a montré un wafer 10 nm, et indiqué qu'il s'attend à lancer la production en volume fin 2016, il n'a rien dévoilé sur la technique
IBM Power9 et Nvidia Volta : 100+ petaFlops en 2017
Le département de l'énergie américain a tranché il y a quelques jours : les prochains supercalculateurs qu'il finance seront mis en place par IBM sur base d'une plateforme OpenPower équipée de ses futurs CPU Power9 et des GPU Volta de Nvidia associés via l'interconnexion NVLink.

Cinq années, cela semble être la durée de vie des supercalculateurs pour lesquels le département de l'énergie américain (DoE) met la main à la poche. Délivré mi-2012 sur base d'une plateforme IBM Blue Gene/Q et de CPU Power8 à l'administration nationale pour la sécurité nucléaire, Sequoia et ses 20 petaFlops (17 petaFlops mesurés) prendra sa retraite en 2017. Il en ira de même pour le supercalculateur Titan exploité par le laboratoire national d'Oak Ridge qui affiche 27 petaFlops au compteur (17.5 petaFlops mesurés). Pour rappel, ce dernier est basé sur une plateforme Cray XK7 équipée d'Opteron 6274 et d'accélérateurs Tesla K20X.
La course à la puissance ne s'arrête jamais, d'autant plus que la Chine a volé la première place du podium aux Etats-Unis avec Tianhe-2, une plateforme 100% Intel qui affiche 55 petaFlops au compteur (34 petaFlops mesurés) à travers ses Xeon E5-2692 et ses Xeon Phi 31S1P. Si ce dernier est plus performant, à noter cependant que sa consommation explose pour atteindre près de 18 mégawatts là où les actuels supercalculateurs américains se contentent de 8 à 9 mégawatts.
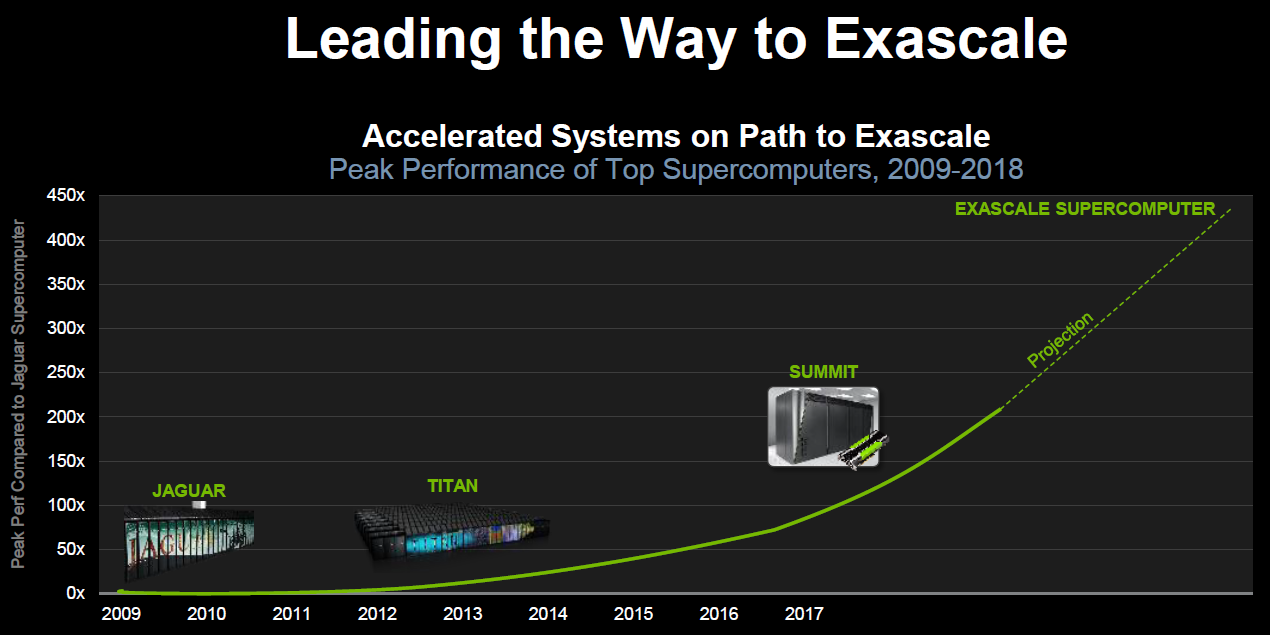
Ce détail est en fait très important. Nul doute en effet que le cahier des charges du DoE pour ses futurs supercalculateurs, baptisés Sierra et Summit, exigeait de ne pas trop augmenter le budget énergétique de ses futures installations, en plus bien entendu de pousser la puissance de calcul vers le haut en attendant l'arrivée des systèmes exaFlops, prévus pour la génération suivante.
Pour les deux systèmes, une même plateforme de plus de 100 petaFlops a cette fois été retenue et c'est IBM qui a reçu ce contrat de 325 millions de $. La plateforme proposée par IBM a pour particularité de s'efforcer de rapprocher les données de la puissance de calcul pour réduire les déplacements coûteux tant en performances qu'en énergie. Un argument important à l'heure où la quantité de données à traiter explose.
Alors que l'actuel Sequoia était de type 100% CPU IBM, le DoE a favorisé une solution hétérogène, étant visiblement satisfait des résultats du Titan, et a renouvelé sa confiance dans les GPU Nvidia et l'écosystème CUDA. Une étape cruciale pour Nvidia qui voit donc sa place de fournisseur de puissance de calcul confirmée sur un marché dans lequel il est difficile de percer.

Les raisons du choix du couple IBM/Nvidia sont bien entendu nombreuses et ne sont pas dues au hasard. Les deux acteurs travaillent ensemble depuis quelques temps déjà, Nvidia ayant annoncé en mars dernier une interconnexion NVLink développée en partenariat avec IBM. Pour rappel, celle-ci permet de s'affranchir du PCI Express et de ses limitations pour proposer une voie de communication plus performante entre les GPU mais également entre les GPU et les CPU. Cela implique des changements importants, notamment au niveau du format physique qui passera à un socket de type mezzanine.
Ce support de NVLink est une évolution logique du côté d'IBM qui propose déjà sur ses CPU Power8 une interface CAPI (Coherent Accelerator Processor Interface) dédiée au support d'accélérateurs spécifiques basés sur des modules FPGA interconnectés en PCI Express. De toute évidence IBM a étendu l'interface CAPI de manière à y intégrer le support de NVLink mais les spécificités à ce niveau restent inconnues.
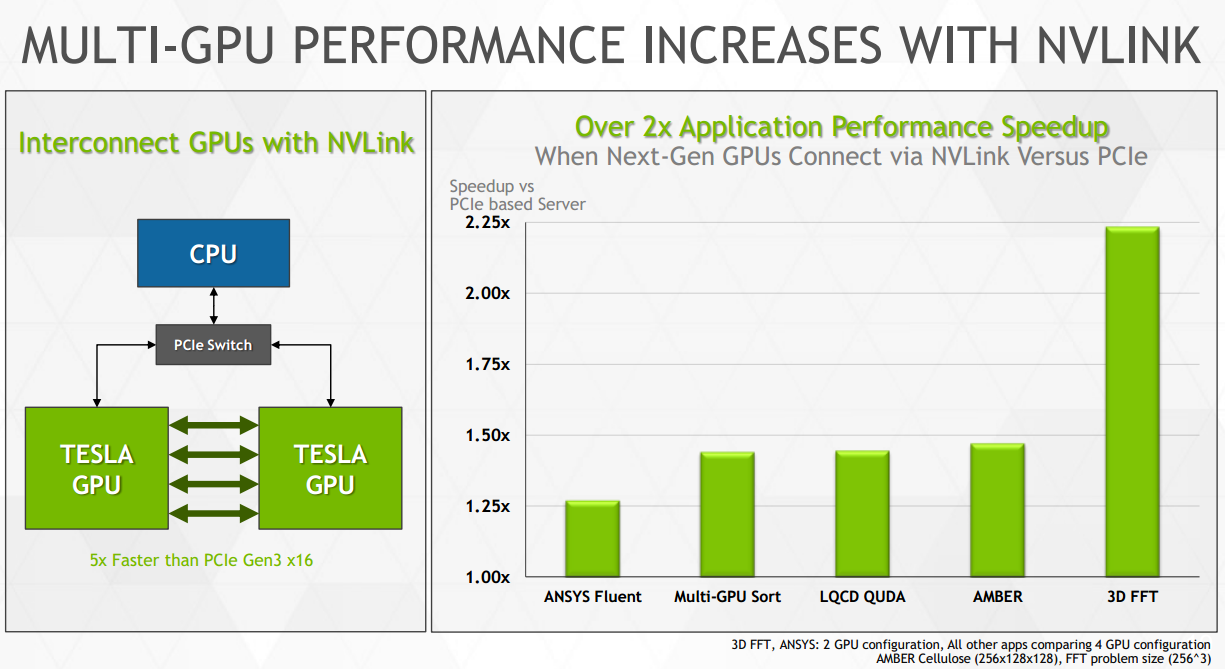
Chaque lien NVLink est constitué d'un certain nombre de couples de lignes point-à-point et dans le cas de la première version de NVLink il est question d'une bande passante de 20 Go/s par lien (16 Go/s effectifs). Nvidia prend pour exemple un GPU équipé de 4 de ces liens qui pourrait ainsi profiter au total de 64 Go/s pour ses voies de communications vers les autres GPU et vers le CPU auquel il est rattaché, contre seulement 12 Go/s en PCI Express 3.0. De quoi booster les performances sur certains algorithmes : dans sa documentation Nvidia met en avant des projections avec +20% à +400% de mieux suivant les algorithmes observés.
Toujours au niveau de la mémoire, avec Volta, chaque GPU pourra alors être équipé d'une quantité importante de mémoire haute performances grâce à la technologie HBM. Pas question cependant de tester tout cela lors de la mise en place de ces supercalculateurs, ces technologies devront être éprouvées avant. C'est ce qu'a prévu Nvidia. En 2016, le GPU Pascal sera le premier à supporter NVLink, la mémoire HBM et le nouveau format. De quoi être prêt pour 2017 et le GPU Volta qui profitera de la version 2.0 de NVLink dont l'évolution principale sera la possibilité de supporter un espace mémoire totalement cohérent entre le ou les CPU et le ou les GPU. Pour en profiter une bande passante élevée sera nécessaire, elle pourra monter jusqu'à 200 Go/s à travers l'ensemble des liens NVLink (5 liens à 40 Go/s ?). De quoi permettre de revoir en profondeur l'architecture des supercalculateurs.
Alors que Titan par exemple est un ensemble de 18688 nuds équipés chacun d'un Opteron 16 curs avec 32 Go de DDR3 et d'une Tesla K20X avec 6 Go de GDDR5, Sierra et Summit se contenteront de beaucoup moins de nuds mais bien plus costauds et chacun équipé d'une zone de stockage locale.
Les informations concernant Sierra restent actuellement limitées, puisqu'il remplacera Sequoia dans le domaine sensible de la sécurité nucléaire. Par contre plus de détails ont été communiqués au sujet de Summit, qui remplacera Titan avec une puissance de calcul théorique qui se situera entre 150 et 300 petaFlops pour une consommation qui ne devrait augmenter que de 10% alors que l'encombrement sera nettement réduit.
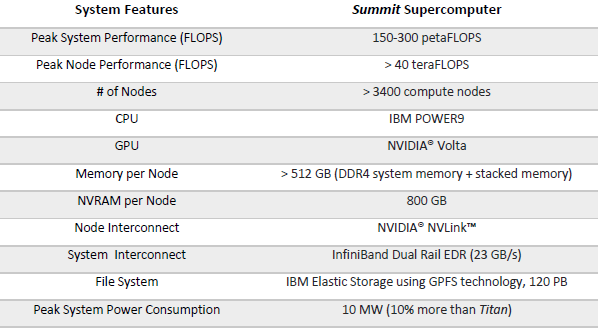
Summit sera constitué de plus de 3400 nuds, chacun présenté avec une puissance de calcul théorique de plus de 40 teraFlops (probablement bien plus puisque cela ne représente que 136 petaFlops). Chacun de ces nuds sera équipé de plusieurs CPU Power9 et de plusieurs accélérateurs Tesla dérivés du GPU Volta. Nous pouvons raisonnablement supposer qu'il s'agira de 4 à 8 composants de chaque type par nud. Ils seront accompagnés par un ensemble de plus de 512 Go de mémoire DDR4 (côté CPU) et HBM (côté GPU) qui formeront un seul et unique espace cohérent, même si les accès mémoire resteront optimisés pour des usages différents de part et d'autre. Par ailleurs 800 Go supplémentaires de mémoire flash seront installés, de quoi par exemple faire office de buffer pour le système de stockage de 120 petaOctets qui devra se "contenter" d'une bande passante de 1 To/s.
Ce type de contrat est très important en terme d'image de marque pour un acteur tel que Nvidia, mais il lui restera à démontrer de l'intérêt, en pratique, d'une plateforme basée autour de NVLink dans les plus petits systèmes qui représentent le gros du marché. Si seul le Power9 d'IBM et le Volta de Nvidia supportent NVLink, ils resteront dépendants l'un de l'autre pour être exploités au maximum de leurs capacités. Un pari risqué ? Sans commenter le fond de cette question, Nvidia précise qu'un petit ensemble de 4 nuds similaires à ceux développés par IBM pour Summit suffirait à placer la machine dans la liste Top500 des supercalculateurs actuels.
Pour en savoir plus, vous pourrez retrouver deux whitepapers chez Nvidia , l'un tourné autour de ces supercalculateurs, l'autre autour de NVLink et de ses promesses (sans prendre en compte le support CPU).
GlobalFoundries récupère les usines et brevets d'IBM
C'est désormais officiel, IBM a annoncé sa sortie de l'activité fabrication de semi-conducteurs. IBM avait commencé à se séparer petit à petit de son activité hardware, en commençant par le PC, vendu à Lenovo il y a 10 ans de cela, puis le serveur x86 toujours à Lenovo en début d'année. Après les rumeurs qui bruissaient depuis l'année dernière, le sort de l'activité fabrication semblait scellé en avril lors de l'annonce du partenariat entre Samsung et GlobalFoundries autour du 14 nm qui signait l'arrêt de la Common Platform, l'effort de développement commun poussé par IBM.
Depuis, pas grand-chose. Nous vous indiquions lors de l'été que les discussions entre GlobalFoundries, pressenti comme repreneur, et IBM étaient au point mort. L'accord est aujourd'hui finalisé.

GlobalFoundries récupère l'intégralité de l'activité fabrication d'IBM, qui inclut la fab de East Fishkill (22nm sur des Wafers de 300mm) ainsi qu'une autre fab plus ancienne dans le Vermont. L'accord assure la reprise de l'emploi de tous les salariés sur les deux sites. En plus des usines, GlobalFoundries récupère les activités connexes comme l'aspect commercial, ou l'activité ASIC. L'usine de Bromont au Quebec, spécialisée dans le packaging ne fait par contre pas partie du rachat.
Mieux, GlobalFoundries récupère plusieurs milliers de brevets et 1.5 milliards de dollars. L'activité d'IBM était pour rappel déficitaire, IBM effectuera donc un paiement de 1.5 milliards à GlobalFoundries, étalé sur les trois prochaines années. GlobalFoundries gagne en prime l'exclusivité pour la fabrication des processeurs serveurs d'IBM pour les 10 prochaines années sur les technologies 22, 14 et 10 nm.
Le rachat des usines d'IBM au point mort
Nos confrères locaux du Poughkeepsie Journal rapportent que les discussions de rachat de l'activité fabrication de semi-conducteurs d'IBM semblent aujourd'hui au point mort.
Pour rappel, IBM avait annoncé une « transition » en se détachant du hardware pour se concentrer sur le Big Data. Une stratégie qui s'est concrétisée en début d'année - et une dizaine d'année après la vente de son activité PC à Lenovo par la vente de son activité serveur x86, toujours à l'entreprise chinoise. Après l'annonce il y a quelques jours d'un partenariat avec Apple - là encore autour du Big Data et des services pour les entreprises il restait deux activités « hardware » à IBM dont l'avenir semblait incertain depuis un bon moment : l'architecture Power, et la fabrication.
Nous avions noté l'année dernière l'ouverture de l'architecture Power par IBM, autorisant entre autre l'arrivée de Tyan pour la fabrication de cartes mères dédiées à ses processeurs serveurs haut de gamme. Depuis, plus de vingt-cinq sociétés ont rejoint la fondation OpenPower, avec notamment Samsung, Micron, SK Hynix, Altera, Xilink ou encore Nvidia. On notera également que Tyan semble avoir (doucement) avancé en proposant une « reference board » POWER8 mono-socket aux membres de la fondation.

Une carte mère Power issue de l'initiative OpenPower
Le cas de l'activité fabrication semblait plus limpide puisque les rumeurs bruissaient depuis un long moment sur le fait qu'IBM souhaitait purement et simplement s'en séparer. Une rumeur qui s'est concrétisée en avril avec le partenariat sans précédent entre Samsung et GlobalFoundries qui se sont accordés pour disposer d'un process commun autour du 14nm (en pratique, GlobalFoundries prenant une licence pour le process de Samsung). Un accord qui semblait sceller le début d'une ère post-IBM, GlobalFoundries et Samsung étant les deux autres membres de ce que l'on appelait la Common Platform, une alliance entre les trois entreprises pour mettre en commun une partie de leur recherche et développement. Le fait que deux des trois membres s'allient semblait aller dans le sens de la disparition de la Common Platform et du désengagement d'IBM. On notera que depuis, le site de la Common Platform a été remplacé par une page unique contenant bien peu d'informations (l'ancien site étant toujours disponible via un moteur de recherche ) ainsi qu'une page de contact qui renvoi directement aux trois sociétés en question.
IBM serait depuis plusieurs mois en négociations avec diverses parties pour la vente de son activité de fabrication, et selon nos confrères du Poughkeepsie Journal, c'est avec GlobalFoundries que des négociations très avancées étaient actuellement en cours. Selon leurs informations, le projet de rachat portait le nom de « Project Next » et concernait à la fois l'usine principale d'IBM (en 22nm sur des wafers de 300mm) située à East Fishkill dans l'état de New York ainsi qu'une autre fab plus ancienne située à Burlington dans l'état du Vermont et une activité packaging à Montreal.
Une certaine tension semblait palpable autour des négociations, GlobalFoundries avait pour rappel lancé en 2012 la construction d'une Fab 8, elle aussi dans l'état de New York et avait même passé en début de semaine une « annonce » dans les journaux locaux d'East Fishkill et de Burlington indiquant qu'ils recrutaient pour leur Fab 8. Un manque de tact certain vis-à-vis des employés d'IBM qui sont depuis de longs mois dans l'attente d'une annonce.
Les négociations sembleraient cependant purement et simplement arrêtées selon des informations obtenues par le journal auprès de multiples sources sur place. Il sera intéressant de voir si IBM cherchera un autre repreneur, dans un monde des semi-conducteurs très restreint le nombre de repreneurs potentiels est pour le moins limité. La stratégie de désengagement d'IBM ne semble cependant pas changer, la société a annoncé la semaine dernière investir près de trois milliards de dollars au cours des cinq prochaines années dans de la recherche pure autour de « l'après silicium » en se focalisant notamment sur la recherche pour les nodes 7nm et au-delà, les nouveaux matériaux, ainsi que l'informatique quantique. De la recherche pure effectuée à la fois en interne et via le financement de travaux universitaires.
Nvidia annonce la Tesla K40 et CUDA 6
La semaine passée, à l'occasion du SC13 (Supercomputing 2013), Nvidia a annoncé deux nouveautés liées au calcul haute performance : l'accélérateur Tesla K40 et la version 6 de CUDA.
Pour rappel, c'est la gamme Tesla qui a été la première à profiter du plus gros GPU de la famille Kepler, le GK110. Contrairement aux Quadro K6000 et GeForce GTX 780 Ti plus récentes, cette gamme Tesla n'accueillait cependant toujours pas de version complète du GK110, c'est-à-dire avec l'ensemble de ses unités d'exécution actives. Une configuration facilitée par l'arrivée de la révision B1 du GPU.
La Tesla K40 profite ainsi de 15 SMX, de 2880 unités de calcul FMA 32-bit et de 960 unités FMA 64-bit pour afficher une puissance de calcul en hausse de près de 10% par rapport à la Tesla K20X. Par ailleurs, comme pour le Quadro K6000, Nvidia profite de la disponibilité effective de la GDDR5 4 Gbits pour faire passer la mémoire dédiée de son accélérateur de 6 à 12 Go. Sa fréquence est par ailleurs revue à la hausse ce qui profite à la bande passante mémoire en hausse de 15%.

Si la fréquence GPU ne progresse que très peu pour la Tesla K40, c'est uniquement pour garantir que l'enveloppe thermique ne soit pas atteinte dans les tâches de type calcul, sachant que, contrairement aux GeForce, Nvidia ne propose pas de turbo pour ces cartes afin d'éviter que leurs performances soient variables. Par contre, pour la Tesla K40, Nvidia propose 2 modes avec des fréquences GPU différentes : optionnellement, il sera ainsi possible de passer le GPU de 745 à 810 ou 875 MHz. Il ne s'agit pas d'un overclocking dans le sens où ces fréquences sont validées par Nvidia, ni d'un turbo automatique, même si Nvidia place cette possibilité sous l'appellation GPU Boost, marque du turbo des GeForce... Si la personne qui exploite ces Tesla K40 constate qu'elles restent loin de leur TDP dans une certaine situation, elle aura la possibilité de passer à un de ces modes de fréquence supérieure. De quoi profiter 9% voire 17% de puissance supplémentaire.
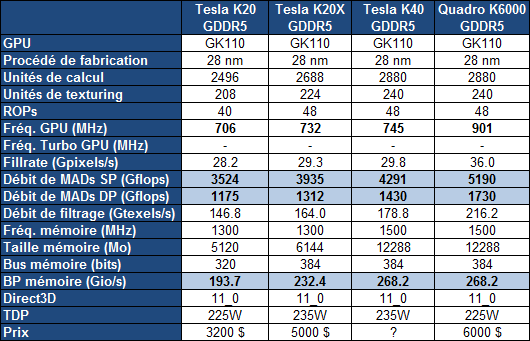
A noter que la Tesla K40 sera proposée autant avec un refroidissement actif, comme la K20, qu'avec un refroidissement passif en vue d'intégration dans un serveur, comme la K20X. Enfin, le PCI Express 3.0 est activé sur la K40 contrairement aux K20/X.
Nvidia ne communique pas au niveau de la tarification, mais elle devrait rester inférieure à celle de la Quadro K6000, probablement passer à 5000$ alors que les K20/X devraient voir leur tarif baisser. Il faut cependant garder en tête que sur ce marché de niche, les prix sont fortement variables, les grossistes n'hésitant pas à se réserver des marges conséquentes. Ainsi pour des tarifs annoncés par Nvidia de 3200$ et de 5000$ pour les K20 et K20X, en pratique, il fallait en général compter plutôt 4000$ et 7500$, la même chose en euros.
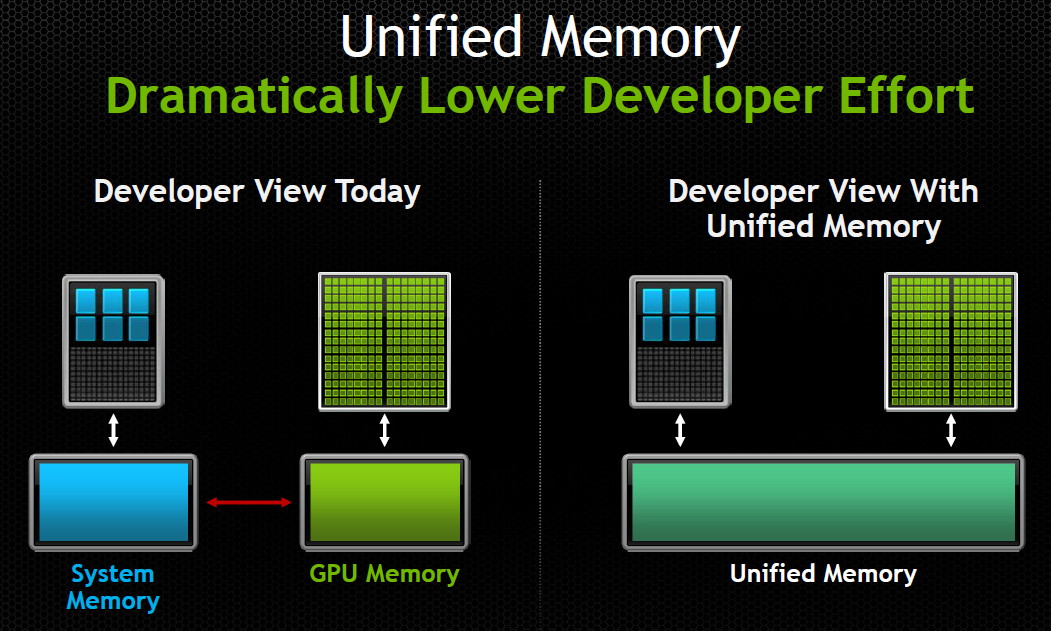
Parallèlement à l'arrivée de cette nouvelle Tesla, Nvidia a annoncé CUDA 6 qui apporte une nouveauté majeure et très attendue : la prise en charge d'une mémoire unifiée. Une fonctionnalité qui donne l'impression d'être annoncée et réannoncée régulièrement, AMD et Nvidia ayant régulièrement joué sur les mots à ce niveau. Pour rappel, depuis quelques temps, CUDA supporte un adressage de mémoire virtuelle unifié, qui facilite quelque peu le développement mais n'était qu'un premier pas. La mémoire unifiée, représente cette fois une abstraction totale de la gestion de la mémoire : il n'est plus nécessaire que le développeur gère les transferts de données de la mémoire centrale vers la mémoire de l'accélérateur.
Une gestion manuelle de la mémoire restera possible, étant donné qu'aussi bénéfique soit cette simplification, elle peut avoir un coût sur le plan des performances et de l'efficacité puisqu'il reviendra aux pilotes et/ou aux compilateurs d'essayer de placer automatiquement les données au bon endroit.

Confiant dans l'avenir, Nvidia termine par annoncer que l'ouverture par IBM, cet été, de sa plateforme serveur POWERn, va permettre d'y intégrer des accélérateurs Tesla dès 2014. Des accélérateurs qui seront ainsi exploités non plus uniquement sur x86 mais également sur architectures POWER et ARMv8.