
Les derniers contenus liés aux tags Intel et Xeon Phi
Xeon Platinum pour accompagner les Xeon Gold
Micron en charge de la mémoire des Knights Landing
Intel dévoile l'AVX-512
Intel lance les Xeon Phi 5110P
Cray XC30 avec processeurs Intel
Xeon Platinum pour accompagner les Xeon Gold



Il y a quelques semaines de cela, nous vous indiquions que la nomenclature Xeon Gold devrait faire son apparition à l'occasion du lancement des Skylake-EP, nous faisant nous poser pas mal de question sur ce qui se cachait derrière.
On comprend un peu mieux la question du Gold aujourd'hui grâce à un PCN (PDF) . En pratique, ce PCN (Product Change Notification, un document qui indique un changement au niveau du produit) indique simplement l'ajout d'un marquage supplémentaire sur l'IHS pour pouvoir repérer plus facilement le sens dans lequel insérer ces (bien larges) puces dans les sockets.
Mais en donnant la liste des produits affectés, Intel nous dévoile en parallèle la liste de ses futurs Xeon :
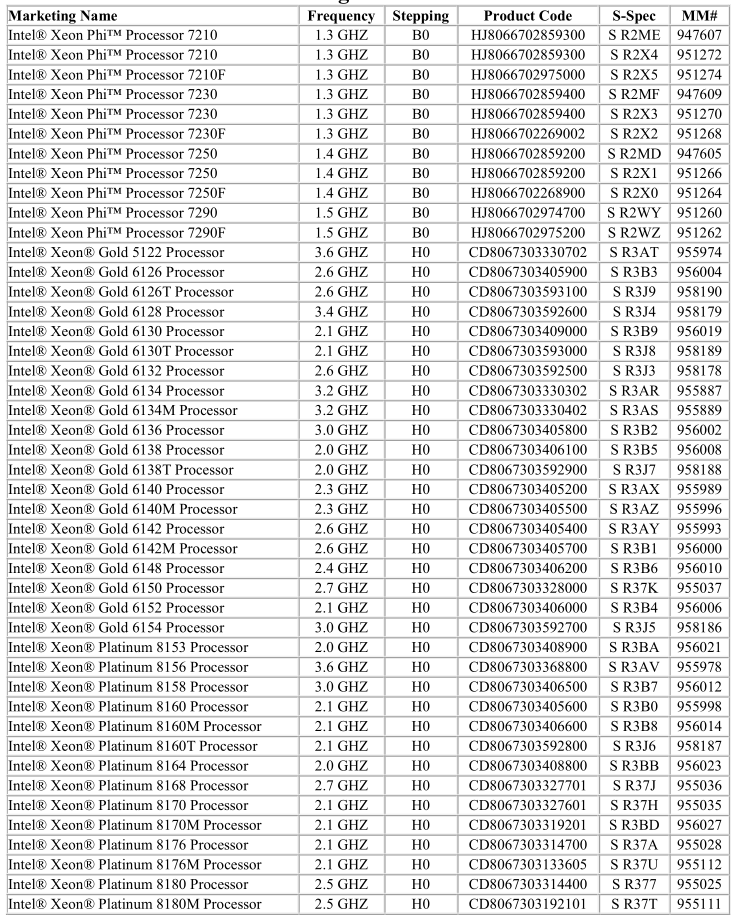
Toutes ces puces utiliseront le futur socket LGA 3647 qui représentera l'offre serveur très haut de gamme du constructeur. Le nombre colossal de broches s'explique par le fait que chaque socket pourra gérer jusque 6 canaux mémoires (avec 3 DIMM par canal). On devrait retrouver des configurations jusque 8 sockets qui pourront accueillir ces nouvelles puces.
La marque Xeon Gold représentera donc les Xeon 6000 tandis qu'une nouvelle marque, Xeon Platinum (!) sera réservée aux modèles 8000. On ne connaît pas encore les différences de cette segmentation (le PCN n'indique que les numéros de modèles, pas encore les caractéristiques) mais historiquement le premier numéro permettait de distinguer le nombre de sockets gérés.
On peut supposer que les modèles 8000 seront réservés pour les modèles 8 sockets, et les 6000 possiblement pour les 4 sockets, même si Intel pourrait changer ses habitudes. Le plus gros des Xeon 8000 intégrera 28 coeurs, soit quatre de plus que l'actuel Xeon E7-8894 v4.

On notera que des Xeon Phi en version socket seront là aussi disponibles, mais ils n'ont pas droit à un métal, on imagine pour éviter toute confusion. Si Intel suit sa logique, on devrait voir arriver des Xeon Silver et Bronze, possiblement pour le socket LGA 2066 qui remplacera l'actuel LGA 2011v3 avec le lancement des Xeon Skylake-W.
La version desktop du LGA 2066 (Skylake-X) a vu son lancement avancé à fin juin/début juillet, avec une introduction probable aux alentours du Computex comme nous vous l'indiquions il y a quelques jours.
Micron en charge de la mémoire des Knights Landing
Nous vous en parlions en novembre dernier, la prochaine génération de Xeon Phi (Knights Landing) prévue pour la mi-2015 intégrera jusqu'à 16 Go de mémoire embarquée ultra-rapide délivrant une bande passante de l'ordre de 500 Go /s.
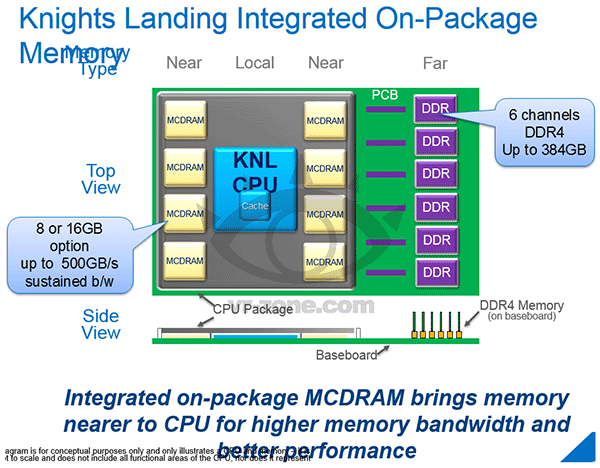
On apprend aujourd'hui que cette mémoire sera produite par Micron, qui l'a développée en collaboration avec Intel en prenant pour base l'Hybrid Memory Cube dont on parle depuis quelques années déjà. Les puces se trouveront sur le même packaging que les Xeon Phi, et seront reliées à ce dernier par une interface à très haute vitesse.
Dans son communiqué Micron indique que cette mémoire a une bande passante 5x supérieure à la DDR4 tout en prenant 50% de place en moins et avec un ratio bande passante/consommation multiplié par 3.
Pour rappel ces nouveaux Xeon Phi gravés en 14nm devraient gérer l'AVX-512, la DDR4, le PCIe Gen3 et seront disponibles en version Socket comme en carte fille PCIe. Un Xeon Phi pourra intégrer jusqu'à 72 curs de type Silvermont associés par paire, gérant chacun deux grosses unités vectorielles prenant en charge le traitement des instructions AVX-512 et partageant un cache L2 de 1 Mo. En sus de la mémoire embarquée, ils géreront six canaux de DDR4 permettant d'adresser 384 Go de mémoire supplémentaire.
Intel dévoile l'AVX-512
C'est par le biais d'un de ses blogs qu'Intel vient d'annoncer la prochaine version d'AVX, que l'on connaissait précédemment sous le nom de code 3.1 et 3.2. Il s'agira finalement d'AVX-512.
Comme son nom l'indique, AVX-512 est une extension du jeu d'instruction AVX qui rajoute des instructions SIMD (une instruction qui s'applique à de multiples données) 512 bits, soit le double de l'AVX actuel, pouvant cibler aussi bien des données entières que flottantes. Ce n'est pas la première fois que l'on voit un jeu d'instructions 512 bits chez Intel car c'est précisément ce que proposait le jeu d'instruction de Larrabee, et plus récemment de Knights Corner que l'on connait sous la dénomination commerciale Xeon Phi.
AVX-512 apporte une série de changements détaillés dans ce document PDF, on notera en premier lieu le nombre de registres qui passe de 16 à 32, tandis que les nouvelles instructions sont préfixées EVEX (au lieu de VEX pour AVX2). Ces dernières concernent aussi bien les entiers que les flottants et vous pourrez retrouver ci-dessous les grandes familles (classes) d'instructions disponibles.
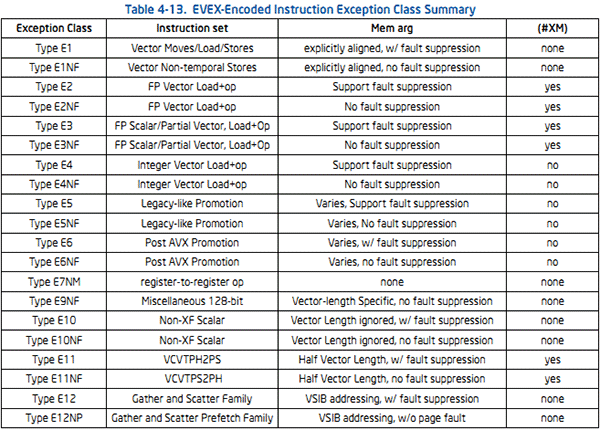
La liste des classes d'instructions d'AVX-512. Vous retrouverez dans le PDF la liste complète des instructions à la page 75.
Notez qu'Intel parle dans son document "d'AVX-512 Foundation", sous entendant qu'il s'agit là du socle commun et que certains produits pourraient proposer des instructions supplémentaires. Ce n'est pas forcément surprenant puisque ces slides indiquaient que Knights Landing (la prochaine version de Xeon Phi) utiliserait AVX3.1, tandis que Skylake (la prochaine nouvelle architecture CPU d'Intel qui apparaitra après Broadwell en 14nm) utilisera AVX 3.2.
Il sera intéressant de voir ce qu'Intel fera exactement de ces unités AVX 512 bits dans le processeur Skylake. Le directeur du Visual and Parrallel Architecture Group d'Intel, Ofri Wechsler est en effet à la fois en charge des projets Xeon Phi du constructeur (l'actuel Knights Corner, le suivant Knights Landing, et le futur Knights Hill) mais aussi de l'architecture graphique qui sera utilisée dans Skylake.
Sa biographie sur le site d'Intel indique également qu'il était responsable du projet qui tentait de construire un pipeline de rendering 3D logiciel fonctionnant sur Larabee, l'ancêtre des actuels Xeon Phi. Si des rumeurs laissaient penser qu'Intel pourrait un jour utiliser ce type de solution pour remplacer un GPU, l'échéance de Skylake est probablement encore trop proche pour que l'on voit arriver ce type de solution pour remplacer l'iGPU intégré aux processeurs. Skylake dans sa version desktop est en effet prévu pour 2015.
Intel lance les Xeon Phi 5110P
Après AMD et Nvidia, c'est ce soir au tour d'Intel d'annoncer officiellement ses cartes accélératrices pour calculs parallèles dédiées au marché HPC (Hautes Performances) : les Xeon Phi.
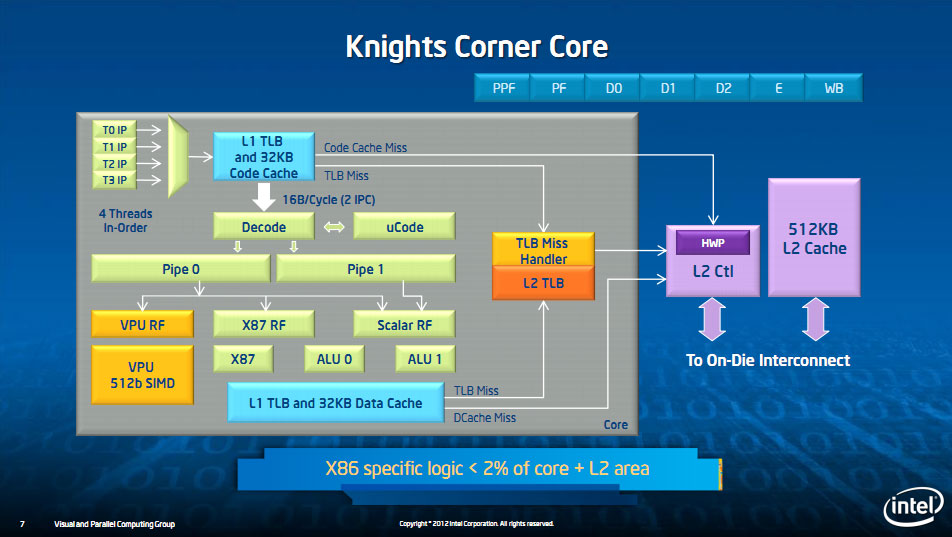
Nous avions présenté précédemment l'architecture de ces puces. Il s'agit pour rappel d'un processeur x86 très particulier où l'on retrouve sur le die 64 cores x86 de type P54C (Pentium) sur lesquels sont accolés un cache de niveau 2 ainsi qu'une large unité de calcul vectorielle (le P54C servant de chef d'orchestre en quelque sorte). Tous ces curs sont reliés autour d'un large ring bus (512 bits dans chaque sens) qui relie également ces curs à des contrôleurs mémoires GDDR5. Pour terminer ce rappel, terminons en indiquant qu'une des particularités du design de Xeon Phi est que les cartes font tourner leur propre système d'exploitation (un Linux) dans lequel s'exécutent les programmes.

Intel annonce donc aujourd'hui sa première carte, le coprocesseur Xeon Phi 5110P. Fabriqué en 22nm, on retrouve 60 curs actifs sur le die cadencés à une fréquence de 1.053 GHz. Xeon Phi est fabriqué en 22nm et chaque cur dispose de 512 Ko de cache de niveau 2.
Côté performances, le constructeur annonce 1010 Gigaflops en double précision, soit légèrement moins que les produits concurrents annoncés ce matin (1173, 1317 et 1478 respectivement pour les Tesla K20, K20X et Firepro S10000). Xeon Phi se distingue cependant côté mémoire avec 8 Go de mémoire GDDR5 (2.5 GHz) embarquée (5, 6 et 3 Go pour les Tesla K20, K20X et Firepro S10000 toujours) et une bande passante de 320 Go/secondes (contre 193.7, 232.4 et 447 Gio/s pour les modèles cités précédemment).

Côté tarifaire Intel est cependant plus agressif puisque sa carte est annoncée à 2649$ (3200, 5000 et 3600$ pour les cartes de Nvidia et d'AMD). Une position qui n'est pas surprenante, Intel étant un nouvel entrant sur ce type de marchés.
Petit tacle en passant à la concurrence
En ce qui concerne le développement d'application, Intel se repose avant tout sur ses propres compilateurs (avec des jeux d'extensions propriétaires) et ses bibliothèques comme MKL (Math Kernel Library) qui ont été portés pour l'architecture Xeon Phi.

Intel indique cependant qu'il s'agit d'une approche "pré-standard" et que l'avenir, aussi bien pour Nvidia que pour Intel est à la version 4.0 d'OpenMP qui - selon Intel - devrait représenter l'avenir de toutes les solutions de développement parallèles. Intel indique s'engager à fournir un compilateur OpenMP 4.0 pour le mois de janvier.

Notez que si les cartes Xeon Phi sont officiellement lancées aujourd'hui (Intel indique commencer les livraisons aujourd'hui à ses partenaires), la disponibilité générale des 5110P ne se fera que le 28 janvier 2013. D'autres déclinaisons sont également prévues avec la famille Xeon Phi 3100 annoncés pour la première moitié 2013 (et qui devraient reposer sur une nouvelle version de la puce). Disponibles en versions actives et passives pour un TDP de 300 watts, les cartes viseront au-delà d'un téraflop DP pour un prix inférieur à 2000$. Le nombre de curs actifs sur ces cartes n'est pas officiellement annoncé, mais avec 28.5 Mo de mémoire cache L2 sur les 3100 Series, il devrait être de 57. Les cartes embarqueront également moins de mémoire avec seulement 6 Go, la bande passante tombant à 240 Go/s.
Cray XC30 avec processeurs Intel
Le constructeur américain de supercalculateurs Cray vient d'annoncer l'arrivée de processeurs Intel dans son nouveau modèle, les XC30. Une première car le constructeur utilisait jusqu'ici exclusivement dans ses XE6 et XK7 des processeurs AMD Opteron (avec une mise à jour récente pour les Opteron 6300 annoncés en début de semaine).

Les XC30 sont basés sur un nouveau système d'interconnexion, Aries, développé par Cray et utiliseront dans un premier temps des Xeon E5-2600 (Sandy Bridge) avec la possibilité d'utiliser plus tard des Xeon Ivy Bridge. Le système est organisé en nodes, reposant chacun sur deux processeurs, regroupés en blades (4 nodes par blades). Le tout est regroupé dans des chassis (16 blades) eux-mêmes regroupés en armoire (3 chassis par armoire), chaque armoire contenant ainsi 384 processeurs.

Côté co-processeur, en sus des K20/K20X de Nvidia qui étaient déjà disponibles dans les systèmes XK7 (et qui ont commencé à être déployés, par exemple dans le supercalculateur Titan), Cray proposera également l'intégration de cartes Intel Xeon Phi (dont nous avions parlé précédemment et qui devraient être lancés sous peu).
Avec ses systèmes XC30, Cray vise des charges pouvant dépasser 100 Petaflops. Plusieurs institutions et universités ont annoncé leur intérêt pour ces nouveaux systèmes, la société annonçant 100 millions de dollars de contrats déjà signés.