
Les derniers contenus liés aux tags AMD et HSA
AMD Kaveri et Steamroller repoussés ?
HSA, calcul hétérogène: Intel et Nvidia isolés?
AFDS: AMD, ARM, ImgTech, TI : HSA Foundation
AMD détaille sa roadmap 2012-2013
AFDS: AMD dévoile la FSA pour OpenCL
AMD et HPC: nouveaux outils, support de CUDA
La spécification HSA 1.0 disponible
CES: AMD en dit plus sur les APU A10 Kaveri
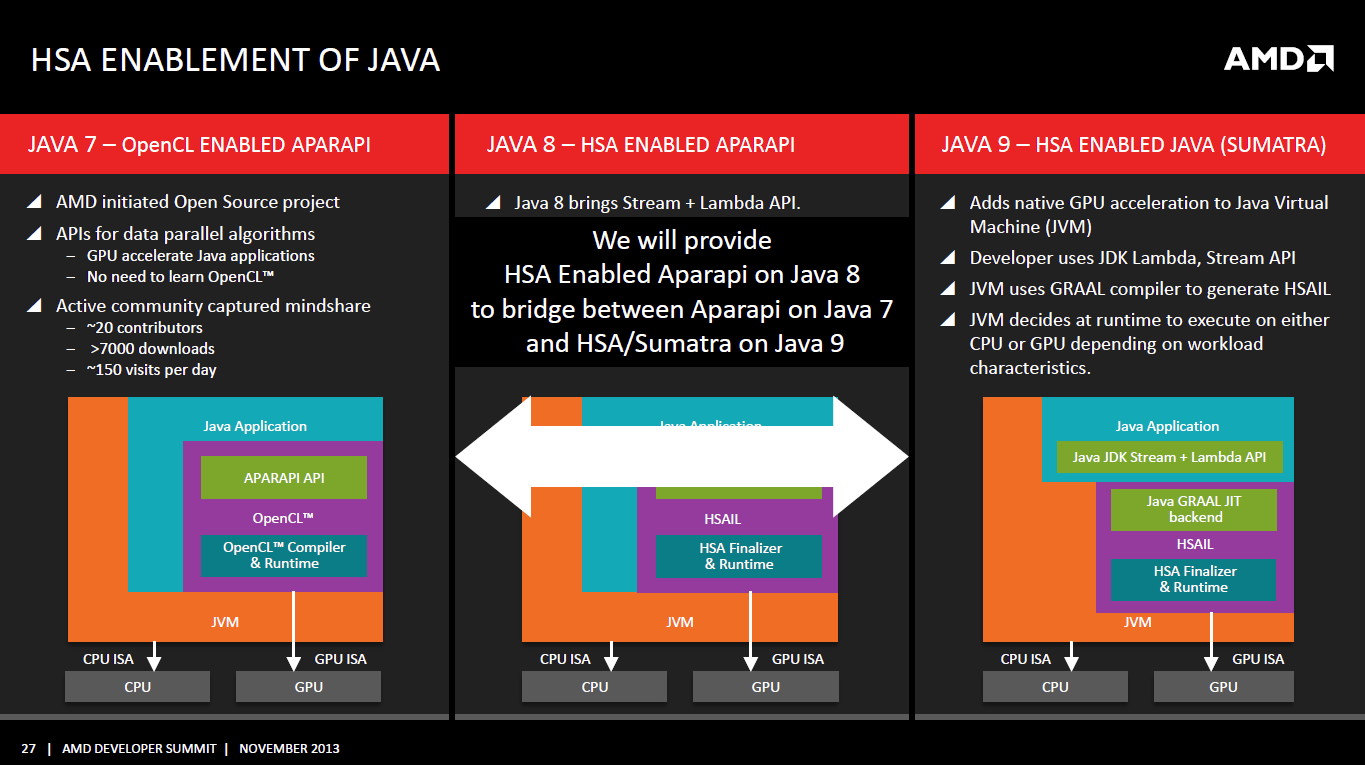
APU13: HSA: nouveaux membres, Oracle, Java...
AMD hUMA: la mémoire unifiée trouve un nom
AMD et HPC: nouveaux outils, support de CUDA



AMD profite du forum SC15 pour annoncer l'initiative Boltzmann, un ensemble de nouveaux outils dédiés à renforcer sa présence dans le HPC, notamment via un portage du code CUDA.
Il y a quelques semaines, le départ de Phil Rogers d'AMD pour rejoindre Nvidia a pu soulever quelques inquiétudes. Cet ingénieur émérite était la figure de proue de la HSA, la plateforme ouverte dédiée au calcul hétérogène ("CPU + GPU"), poussée par AMD avec le support du monde ARM. Une perte incontestable pour AMD qui mise beaucoup sur la HSA, que ce soit au niveau du HPC (calcul haute performances) ou du grand public.

A l'occasion du SC15 (SuperComputing), AMD tient cependant à rassurer quant à l'avenir de la HSA et de son écosystème dédié au calcul hétérogène. De nombreux développements, dédiés initialement au monde professionnel, sont en cours de finalisation et, avec une bonne dose de pragmatisme, ont pour objectif commun d'apporter aux développeurs et aux clients potentiels les outils dont ils ont besoin. AMD regroupe cet ensemble de développements sous le nom de code "Initiative Boltzmann", en référence au physicien Ludwig Eduard Boltzmann dont les équations profitent aujourd'hui de la puissance de calcul des GPU.

Sans donner de précisions liées au hardware, les annonces sont concentrées sur le software, AMD annonce tout d'abord l'extension du support de la HSA des APU (Kaveri) vers les GPU dédiés. Pour cela, AMD proposera un nouveau pilote Linux headless, c'est-à-dire totalement dédié au calcul, allégé du support des parties graphiques et vidéo. De quoi proposer plus facilement un adressage mémoire unifié entre les CPU et les GPU (et rattraper Nvidia sur ce point crucial), réduire la latence des transferts PCIe et de l'envoi des commandes, mieux exploiter tout le sous-système mémoire des GPU etc. Des systèmes de gestion spécifique des GPU (fréquences turbo etc.) seront également proposés ainsi qu'un support étendu de la communication P2P, y compris pour des GPU présents dans des nuds différents dans le cadre des supercalculateurs.

Ensuite, AMD annonce un nouveau compilateur : HCC pour Heterogeneous Compute Compiler. Il s'agit d'un compilateur de type source unique, c'est-à-dire qu'il traite autant le code CPU que le code GPU mis en avant à l'aide de directives (à la manière de C++ AMP de Microsoft). HCC est compatible C++ 11/14, C11 et OpenMP 4.0. Il propose par ailleurs un support alpha de la Parallel Standard Template Library de C++17 (C++1z), la prochaine révision de C++ attendue pour 2017. AMD annonce différentes optimisations qui devraient profiter aux performances tels qu'une meilleure gestion de la mémoire et le support de l'exécution asynchrone des kernels (et concomitante).

Enfin, AMD fait face à la réalité : CUDA de Nvidia est bien implanté dans le monde du HPC. Suffisamment pour que sa seule stratégie à ce niveau ne puisse plus se résumer à essayer de nier cet état de fait avec des statistiques d'utilisation d'OpenCL chez les développeurs. Avec pragmatisme, AMD annonce ainsi l'interface HIP (Heterogeneous-compute Interface for Portability) dont le but est de permettre au code CUDA de tourner sur ses propres GPU.
Cela se fera de manière indirecte bien entendu, avec des outils qui porteront le code source CUDA vers un language C++ commun (cudaMemcpy -> hipMemCpy). Après conversion, le code pourra ensuite tourner aussi bien sur les GPU Nvidia via le compilateur NVCC que sur les GPU AMD via le compilateur HCC. AMD indique que d'après ses tests, 90% du code CUDA peut être automatiquement porté alors que les 10% restants doivent être traités manuellement mais en C++ standard. AMD estime que cela devrait répondre aux demandes du marché qui appréciera l'ouverture de l'offre matérielle pour une bonne partie des systèmes amenés à faire tourner du code CUDA. A voir par contre si Nvidia appréciera cette initiative de la même manière...
A noter que ce support du code CUDA reste partiel et ne concerne que l'ensemble de plus haut niveau, soit le code C/C++ CUDA pour l'API runtime. Le code qui vise l'API driver ainsi que le code PTX ne seront pas supportés, tout du moins initialement.
AMD fera la démonstration de ces outils durant le SC15 et une première version beta sera mise dans les mains des développeurs au premier trimestre 2016.









La spécification HSA 1.0 disponible
 La fondation HSA (Heterogenous System Architecture) a annoncé cette semaine la publication de la version 1.0 de sa spécification. Pour rappel, le but de cette technologie est de proposer des solutions pour les problèmes d'hétérogénéité des plateformes de calcul - CPU et GPU qui diffèrent fondamentalement dans leur fonctionnement et dans leur programmation. HSA tente de résoudre certains de ces problèmes, notamment autour de la manière de collaborer autour d'un espace mémoire unique.
La fondation HSA (Heterogenous System Architecture) a annoncé cette semaine la publication de la version 1.0 de sa spécification. Pour rappel, le but de cette technologie est de proposer des solutions pour les problèmes d'hétérogénéité des plateformes de calcul - CPU et GPU qui diffèrent fondamentalement dans leur fonctionnement et dans leur programmation. HSA tente de résoudre certains de ces problèmes, notamment autour de la manière de collaborer autour d'un espace mémoire unique.
Trois documents ont été publiés, ciblant respectivement le matériel, les développeurs bas niveau (ceux qui réalisent les outils, compilateurs, etc) et les développeurs d'applications (avec notamment un support de C++, Java et Python). Toutes ces spécifications sont téléchargeables librement sur le site de la fondation .
Lancé (et toujours présidé) par AMD, l'effort HSA regroupe désormais d'autres sociétés, particulièrement dans le monde de la mobilité. La fondation compte désormais parmi ses membres ARM, Imagination Technologies (PowerVR), LG, Mediatek, Qualcomm et Samsung.
CES: AMD en dit plus sur les APU A10 Kaveri

Alors que le lancement de l'APU Kaveri, qui inaugure le 28nm de GlobalFoundries, est confirmé pour mardi prochain, AMD profite du CES pour lever un coin du voile sur les deux premiers modèles desktop, les APU A10-7850K et A10-7700K. Leurs spécifications de base avaient pour rappel fuité le mois passé. Concernant ces spécifications, nous apprenons en plus aujourd'hui que la fréquence de base de l'A10-7850K est de 3.7 GHz contre 4.0 GHz pour sa fréquence turbo maximale.
AMD confirme également que le GPU intégré portera la marque Radeon R7 alors que nous aurions pu penser qu'AMD opterait par exemple pour Radeon R5 de manière à réserver Radeon R7 et R9 aux GPU dédiés.


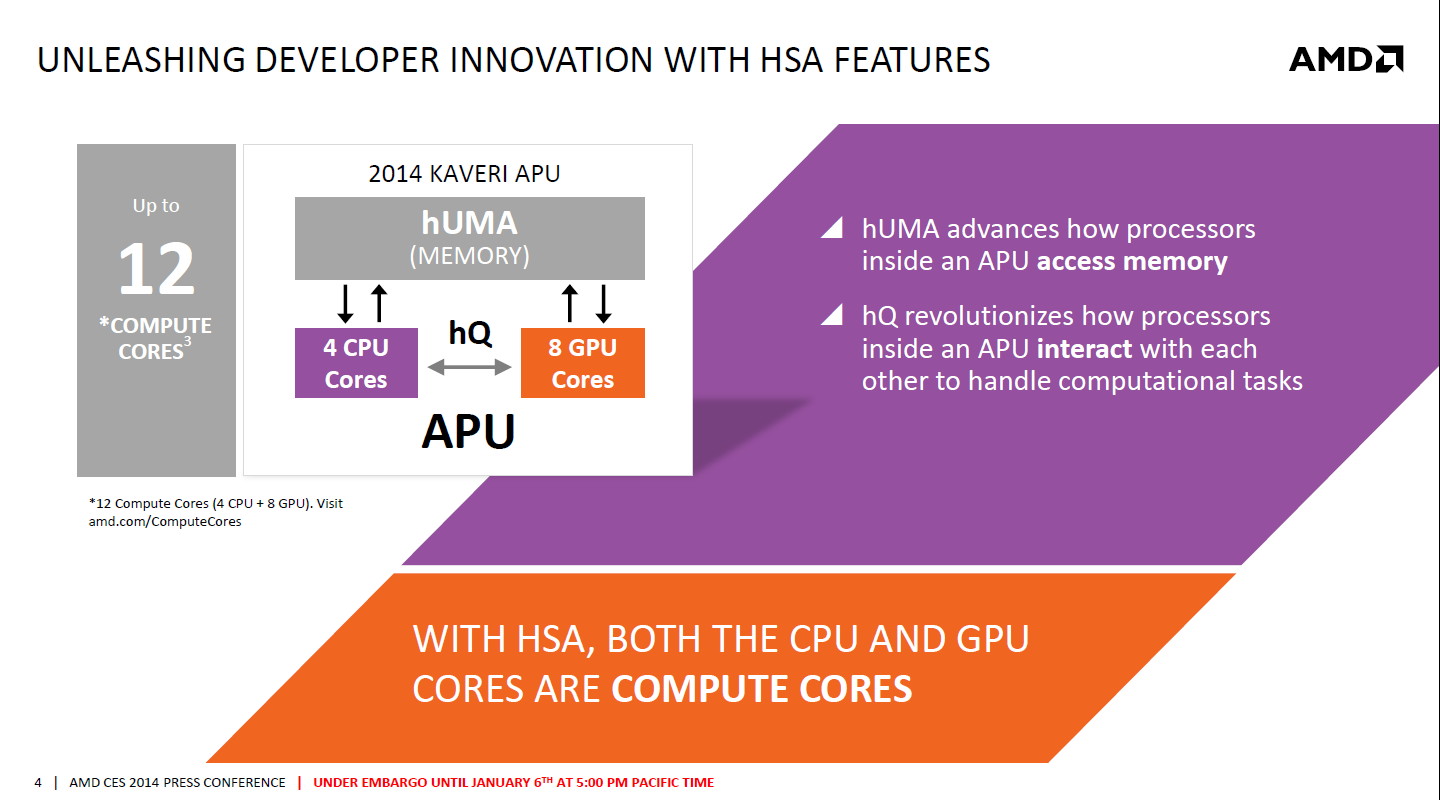
Avec Kaveri, AMD introduit le concept de Compute Cores, qui ne manquera pas de générer de nombreuses discussions. Un Compute Core est défini par AMD comme un bloc capable d'exécuter des tâches à travers la HSA : soit un "core" CPU (la moitié d'un module) soit un "core" GPU (une compute unit incluant 4 unités vectorielles 16-way).
Si représenter de la sorte le GPU est bien plus pertinent et honnête que de faire passer chaque ligne d'une unité vectorielle pour un core (et ainsi en porter le nombre à 512), nous ne sommes pas convaincus qu'il soit très évident pour le consommateur de comprendre la qualification d'un A10-7850K en APU 12 cores (4 cores CPU + 8 cores GPU) Nous espérons donc qu'AMD n'abuse pas de cette simplification.
Sur le plan technique, AMD avance toujours un gain maximal de 20% au niveau de l'IPC pour les cores Steamroller, insiste sur le support de la HSA qui ouvre de nouvelles possibilités, l'intégration du moteur TrueAudio et rappelle que le GPU de type GCN supporte Mantle pour une efficacité supérieure en se débarrassant du surcoût de l'API DirectX, si les développeurs acceptent de faire cet effort.
Pour les APU Kaveri desktop, le TDP variera entre 45 et 95W suivant les modèles. AMD précise que ces APU supporteront un TDP configurable, c'est-à-dire qu'il sera possible via le bios d'adapter le TDP, que ce soit pour l'overclocking ou pour réduire température et nuisances sonores.
AMD présente également quelques chiffres de performances, probablement histoire de compenser quelque peu les premiers résultats moins encourageants qui ont circulé sur le net :
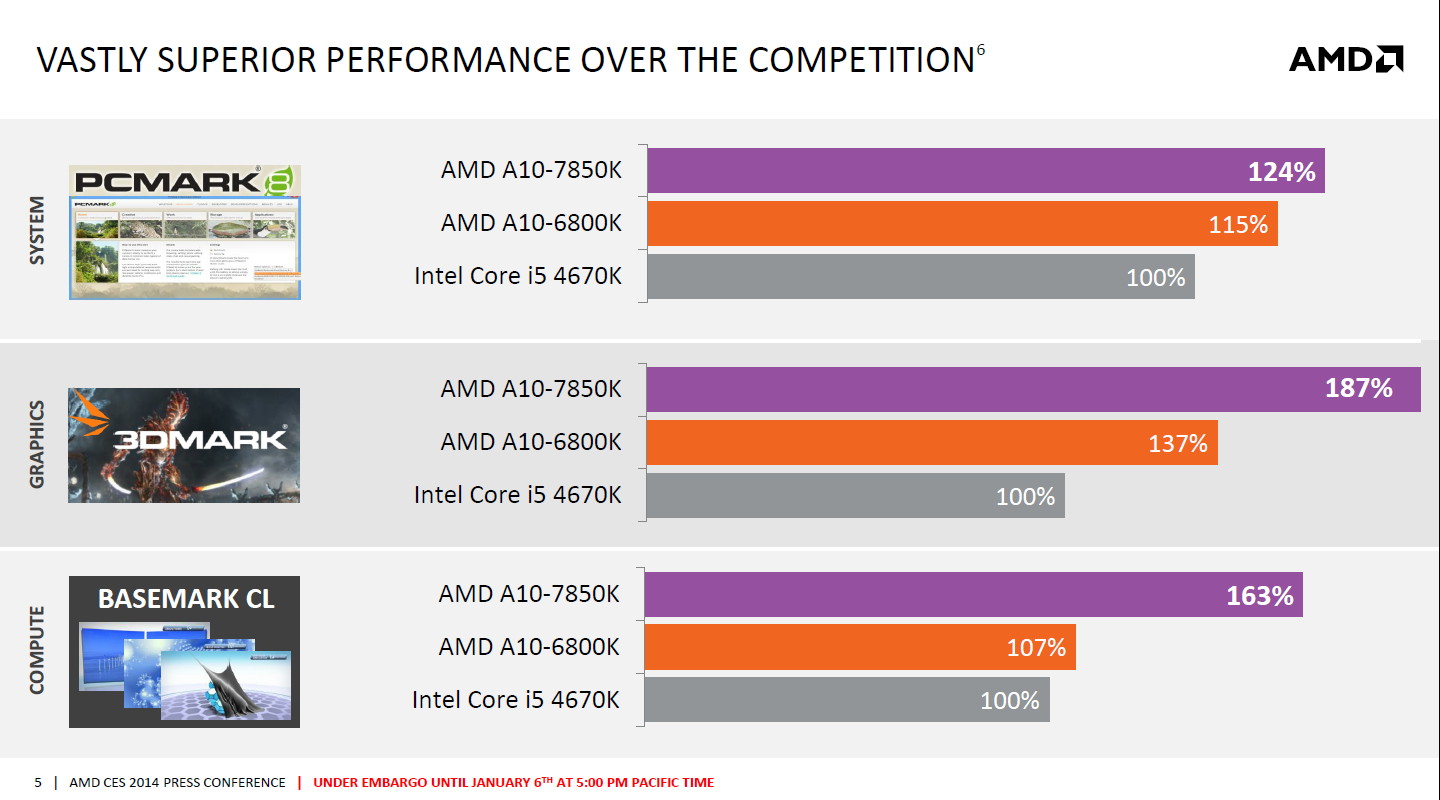


Ces chiffres fournis par AMD indiquent clairement la tendance, les gains seront à chercher du côté du GPU intégré et pas vraiment du côté des cores CPU.
APU13: HSA: nouveaux membres, Oracle, Java...
Il y a un peu plus d'un an, AMD inaugurait la HSA Foundation en partenariat avec ARM, Imagination Technologies, MediaTek et Texas Instruments. Rapidement, Samsung et Qualcomm ont rejoint le groupe de fondateurs de ce consortium qui a pour rappel comme objectif de concevoir des standards dédiés au calcul hétérogène, qu'ils concernent l'aspect programmation ou l'implémentation matérielle.

Petit à petit, la liste de membres qui ont rejoint la HSA Foundation à un niveau ou à un autre s'est allongée et à l'occasion du Developer Summit 2013, AMD annonce avoir à nouveau renforcé les rangs du consortium :
Broadcom
Canonical Limited
Electronics and Telecommunications Research Institute (ETRI)
Huawei
Industrial Technology Res. Institute
Kishonti
Lawrence Livermore National Laboratory
Linaro
Oak Ridge National Laboratory
Oracle
Synopsys
TEI of Crete
UChicago Argonne, LLC. Operator of Argonne National Laboratory
VIA Technologies
Parmi les nouvelles arrivées notons le géant chinois des télécoms Huawei, Kishonti (GLBenchmark), Oak Ridge (qui a mis en place le supercalculateur Titan équipé en Tesla Kepler de Nvidia), Oracle (qui a pour rappel racheté Sun et donc Java) et VIA/S3 Graphics. De quoi donner progressivement de plus en plus d'influence à la HSA.
Son support s'étend également au niveau des langages de programmation. L'implémentation du support de la HSA est actuellement en cours pour Python, OpenMP, C++ AMP et Java :


Annoncé lors de l'AFDS de 2011 par Microsoft, C++ AMP sera, comme nous pouvions alors le supposer, étendu pour supporter la HSA en plus d'un mode OpenCL générique. La différenciation se fera au moment de la compilation où il sera possible de viser le langage intermédiaire HSAIL pour la HSA ou SPIR 1.2 pour les périphériques compatibles OpenCL. Par ailleurs, bien qu'initiative de Microsoft, AMD annonce que C++ AMP sera disponible également sous Linux et que ce support sera mis en place autant pour ses APU que pour ses GPU.
Depuis quelques temps, AMD travaille avec Oracle pour intégrer le support de la HSA dans Java 9 Sumatra et rendre l'utilisation des cores massivement parallèles aussi simple que possible. Un projet ambitieux et en attendant que cela soit finalisé et disponible, APARAPI initialement limitée à OpenCL dans Java 7 va supporter la HSA dans Java 8 (Project Lambda). Oracle a d'ailleurs réalisé une première démonstration sur base d'une simulation de type N-Body, qui, vous vous en doutez, était nettement plus rapide une fois accélérée par un GPU.
AMD hUMA: la mémoire unifiée trouve un nom
Il y a près de 2 ans, AMD avait dévoilé ses plans concernant l'évolution de la plateforme GPU computing pour une exploitation en symbiose plus simple et plus efficace des cores GPU et CPU. Cette plateforme dénommée HSA (Heterogeneous System Architecture) a pour rappel été ouverte par AMD et transférée à un consortium chargé d'en finaliser les spécifications et de poursuivre son développement tant logiciel que matériel. Une approche qui a permis de rallier de nombreux acteurs importants, issus du monde ARM, à la cause d'AMD.
Si en pratique AMD reste le pilote au niveau de la HSA, en finaliser les spécifications à plusieurs a entraîné plusieurs retards, notamment sur la publication des différentes documentations et des premiers outils complets à destination des développeurs. Tout cela semble cependant commencer à se préciser.
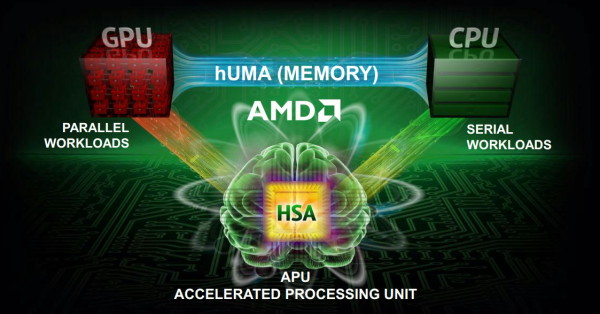
AMD a récemment donné un nom commercial à l'une des évolutions les plus importantes qui seront apportées par la HSA : l'unification de l'espace mémoire entre CPU et GPU pour simplifier le travail des développeurs et améliorer les performances notamment en supprimant des déplacement de données inutiles.
Pour représenter l'unification de la mémoire entre le CPU et le GPU, AMD s'est inspiré des acronymes tirés du SMP : UMA (Uniform Memory Architecture), une seule mémoire physique partagées par les cores CPU, et son évolution NUMA (Non Uniform Memory Architecture), plusieurs mémoires physiques partagées par les cores CPU. Dans un système multi-socket, NUMA permet à chaque CPU de disposer de son propre contrôleur mémoire et de sa propre mémoire, tout en gardant un espace mémoire unifié mais bien entendu sans garantir des performances homogènes sur l'ensemble de celui-ci.
Préparée et annoncée (voire réannoncée régulièrement) par AMD, Nvidia et même Intel, l'unification de l'espace mémoire entre les CPU et les GPU est une évolution logique et primordiale de (N)UMA vers le GPU computing. AMD a ainsi décidé de la nommer hUMA pour Heterogeneous Uniform Memory Architecture. Notez qu'en principe, dans le cas d'un GPU non-intégré, il serait plus correct de parler de hNUMA, puisque la mémoire est non-uniforme, mais nous ne savons pas si AMD prévoit de faire cette distinction.
En réalité, nous ne savons pas grand chose sur les détails, AMD n'ayant strictement rien dévoilé de neuf en dehors de l'acronyme hUMA. Si les aspects pratiques d'une mémoire virtuelle unifiée sont logiques dans le cas d'un APU ou de tout CPU avec GPU intégré, de nombreuses questions se posent par rapport aux GPU externes. Le support au niveau des OS est également un point important puisque leurs gestionnaires mémoire devront être revus pour la supporter.
Pour que la HSA et les produits qui l'implémenteront puissent réellement ouvrir de nouvelles portes et trouver un certain succès, il est important qu'AMD fournisse dès que possible tous les outils et toute la documentation nécessaires aux développeurs. Inutile de dire que cela demandera plus que de faire de la communication pour de la communication autour d'un nouvel acronyme pour représenter l'espace mémoire unifié.
Notez qu'AMD a récemment reporté son forum technologique dédié au GPU Computing de juin à septembre. Il change au passage de nom pour abandonner sa composante Fusion et devenir l'AMD Developer Summit (APU13 en abrégé). Il devrait laisser plus de visibilité aux autres membres de la HSA Foundation et enfin être le lieu de la concrétisation de cette plateforme.
Si vous désirez en savoir plus concernant la HSA et la mémoire unifiée, c'est un whitepaper de l'été 2012 qui reste le plus complet. Vous pourrez le consulter ici .