
Les derniers contenus liés aux tags GlobalFoundries et 16/14nm
12nm et EUV à 7nm pour TSMC
AMD annonce Polaris, sa future architecture GPU
AMD valide le 14nm LPP de GloFo
Le 16nm en retard chez TSMC
12nm et EUV à 7nm pour TSMC



TSMC a publié hier ses résultats financiers pour le dernier trimestre 2016. Le fondeur taiwannais a annoncé pour ce trimestre un revenu brut de près de 7.8 milliards d'euros, en hausse de 28.8% par rapport à la même période sur l'année précédente. Sur la totalité de l'année 2016, TSMC aura augmenté son revenu de 12.4% par rapport à 2015.
Pour 2017, TSMC s'attend à voir ses revenus progresser de "seulement" 5 à 10% (ce qui n'a pas manqué de décevoir les analystes financiers). Lors de la présentation des résultats, quelques informations supplémentaires ont été données.

Morris Chang, Chairman de TSMC s'est lancé dans quelques prédictions pour le marché 2017, s'attendant à voir le marché des smartphones grimper de 6% en unités, et celui du PC se contracter de 5% en unités également (il envisage également un déclin de 7% sur les tablettes tout en voyant le marché Internet of Things progresser de 34%).
Sur le 16/14nm, Morris Chang estime que la part de marché de TSMC est entre 65 et 70%, en dessous de ses attentes (TSMC dispose encore de 80% du marché sur le 28nm par exemple). Toujours poétique, le Chairman voit dans le 10 et le 7nm un "ciel bleu" par rapport à la compétition.
Quelques détails plus techniques ont été donnés, notamment par rapport à un "12nm" qui avait été évoqué ici ou là dans la presse. En pratique, TSMC travaille sur une nouvelle version de son process 16nm (une quatrième après les 16FF, 16FF+ et 16FFC) qui incorpore des améliorations importantes de densité. L'appellation commerciale exacte n'a pas été donnée, et on ne sait pas exactement quand elle sera disponible. On s'attendra dans quelques semaines à une annonce officielle, même si TSMC à confirmé aujourd'hui l'existence de ce "12nm".
Pour le 10nm, si le début de production est bien en cours, le gros du volume se situera sur la seconde partie de l'année (coïncidant avec le lancement des prochains iPhones dont le SoC utilisera le 10nm TSMC).
Sur le 7nm, plus de 20 sociétés travailleraient déjà sur des designs pour l'année prochaine, un chiffre qui devrait doubler dans l'année. Sur la question du 7nm en lui même, nous nous étions interrogés sur la manière dont le constructeur augmenterait la densité. Pour rappel, TSMC s'engage à lancer la production du 7nm dès la fin de l'année, il s'agira du node qu'utiliseront la majorité de ses clients, le 10nm devrait avoir une durée de vie courte et être réservé à quelques gros clients.
Le 10nm rappelle d'une certaine manière le 20nm de TSMC, lui aussi utilisé par des gros clients uniquement avant un passage rapide au 16nm. Cependant, avec une augmentation de la densité de 1.63x entre le 10 et le 7nm, la recette utilisée est plus complexe que pour le passage 20/16nm (qui ne proposait qu'une augmentation de densité de 1.15x). Nos confrères de SemiWiki, très au fait des détails, ont confirmé il y a quelques jours que des changements sur les tailles minimales des cellules sont en grande partie à l'origine des gains de densité et que pour réduire les coûts, TSMC évitera au maximum de généraliser le quadruple patterning (SAQP). Le 10 et le 7nm auront donc bel et bien des similarités techniques.
Pour essayer d'y voir un peu plus clair, et étant donné que plus aucun constructeur ne suit de règles équivalentes pour parler de densité, SemiWiki a publié ce graphique intéressant qui montre une "estimation" de la densité comparée de tous les fondeurs :
D'après SemiWiki, le 10nm d'Intel et le 7nm de TSMC auraient, après ajustement, une densité comparable. Il s'agit bien entendu d'estimations qui valent ce qu'elles valent, vous pouvez retrouver l'explication de la formule utilisée ici , mais elles donnent un bon ordre d'idée de ce à quoi il faut s'attendre (un seul bémol à cette analyse : les prévisions concernant GlobalFoundries nous semblent excessivement optimistes, en grande partie à cause des annonces de GlobalFoundries qui nous paraissent déconnectées de leur capacité d'exécution ces dernières années).
En pratique le 10nm de TSMC disposera tout de même d'une meilleure densité que l'actuel 14nm d'Intel, TSMC pourra donc se targuer d'avoir dépassé Intel côté process lorsque les premiers produits 10nm seront disponibles plus tard dans l'année. Et si Intel reprendra l'avantage avec "son" 10nm, TSMC sera effectivement - et pour la première fois - à parité dès la fin de l'année en lançant la production de son 7nm. Une situation qui durera un moment, et pour la première fois les constructeurs "fabless" pourront disposer d'un process équivalent en densité à celui d'Intel.

On notera enfin, concernant le 7nm, que TSMC a confirmé qu'ils inséreront l'EUV au bout d'un an de production à 7nm (soit fin 2018) pour créer une nouvelle version du 7nm (à l'image des multiples 16nm). Des propos plutôt optimistes concernant la lithographie EUV qui sera, Mark Liu le rappelle, indispensable à 5nm. Et un timing qui coïncide exactement avec le lancement de la production du 7nm de Samsung qui utilisera elle, dès le début, l'EUV !
AMD annonce Polaris, sa future architecture GPU
Enfin, après 4 années de GCN en 28nm, les Radeon vont accueillir une nouvelle architecture gravée en 14nm : Polaris. Et pour AMD le focus se portera sur l'efficacité énergétique avec un bond en avant annoncé sans précédent !

Le Radeon Technology Group d'AMD profite de ce début d'année pour lever un (très petit) coin du voile qui entoure sa prochaine génération de GPU, notamment en donnant un nom de code à son architecture : Polaris (l'étoile polaire). Et pour positionner sans équivoque ses objectifs avec cette architecture, AMD explique avoir opté pour ce nom de code en faisant le parallèle entre l'efficacité des étoiles à générer des photons et l'efficacité demandée aux GPU pour générer des pixels.
Comme vous le savez, l'architecture actuelle des Radeon est globalement en retrait par rapport à l'architecture Maxwell de Nvidia au niveau de l'efficacité énergétique. Fort de larges parts de marché et ayant bien anticipé le très long passage par le procédé de fabrication 28nm (exploité pour les GPU depuis 4 ans déjà !), Nvidia a développé deux architectures pour celui-ci : Kepler et Maxwell. En face, AMD est resté sur une architecture GCN moins efficace en se contentant d'évolutions mineures de son cur. Pourquoi ? Probablement parce que, contrairement à Nvidia, AMD avait parié sur l'exploitation d'un procédé en 20nm qui ne s'est jamais concrétisée pour les GPU.
Tout cela va enfin changer en 2016 avec l'arrivée de GPU fabriqués en 16nm FinFET+ chez TSMC et en 14nm LPP chez GlobalFoundries et Samsung. Ces nouveaux procédés de fabrication ont pour point commun de donner enfin aux GPU l'accès à la technologie FinFET, de quoi donner un coup de pied dans une fourmilière bien trop tranquille à notre goût !
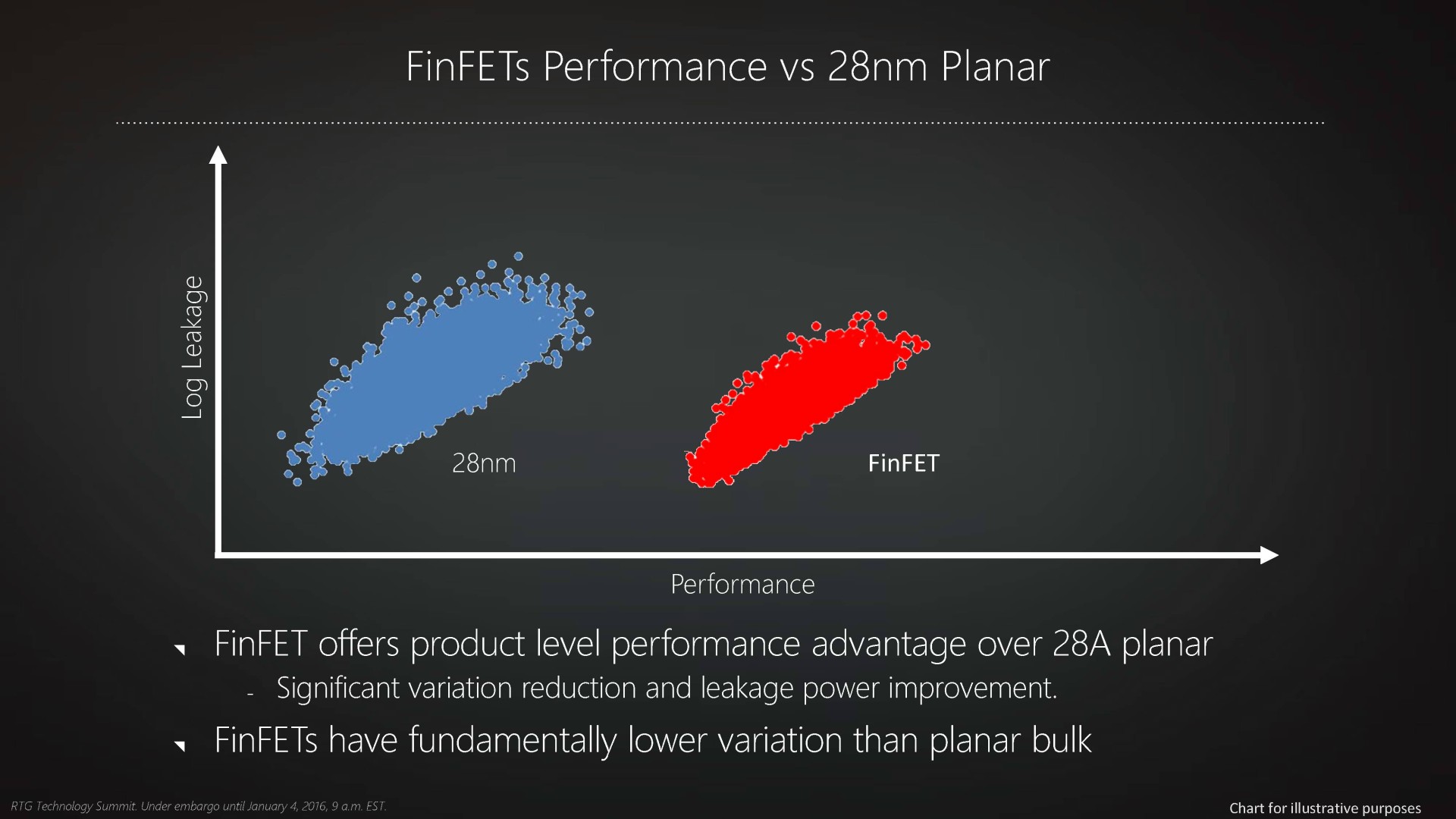
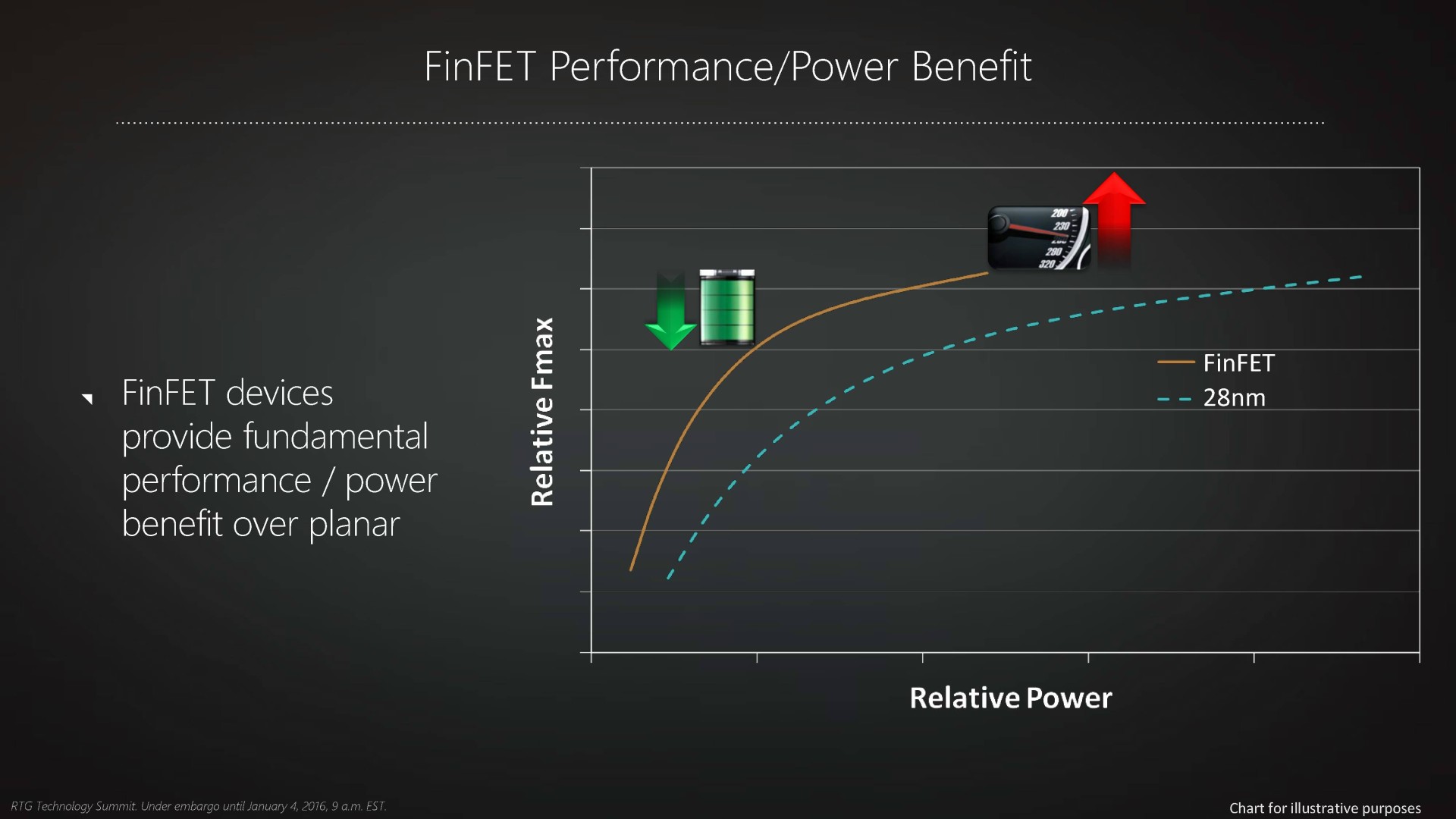
Introduit par Intel en 2012 sous les noms de "transistors tri-gates" ou de "transistors 3D", le FinFET se détache de la construction planaire classique des transistors en donnant une troisième dimension à la porte ce qui permet d'en augmenter la surface de contact et de mieux l'isoler. Les courants de fuite, qui peuvent représenter une grosse partie de la consommation d'un transistors classique, sont alors nettement réduits.
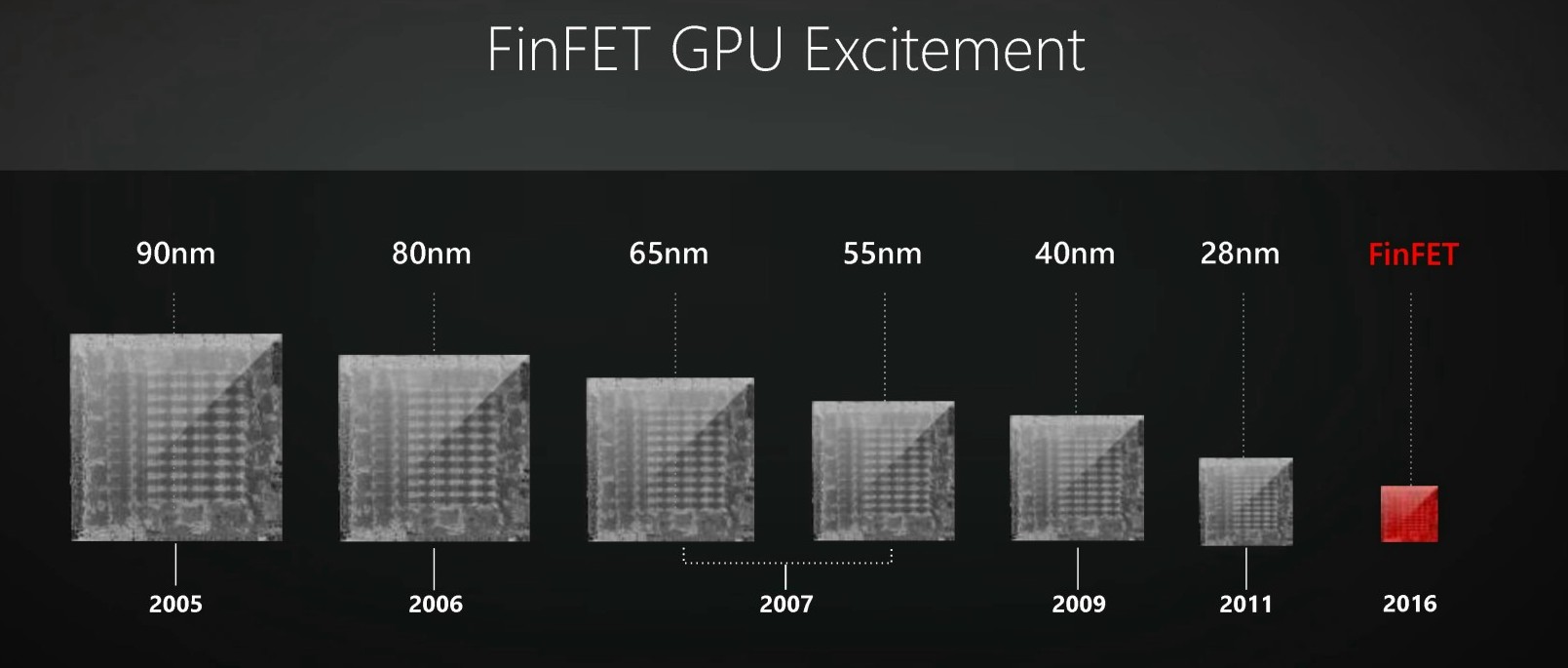
Autant, voire plus, que la finesse de gravure, c'est ainsi le passage au FinFET qui autorise une avancée significative dans les performances des transistors, ce qui peut se traduire par un gain de fréquence, une nette réduction de la consommation ou un mélange de ces deux points selon le positionnement de la puce. Autre avantage selon AMD, le FinFET permet d'obtenir un comportement plus homogène de l'ensemble des transistors, ce qui réduirait la variabilité dans les échantillons produits.
Comme c'est traditionnellement le cas pour les Radeon, c'est lors de ce changement de process qu'AMD va introduire une évolution significative de son architecture GPU, sur laquelle le Radeon Technology Group va bien entendu vouloir communiquer. Et pour cela il faut pouvoir lui mettre un nom.
La nomenclature des architectures GPU d'AMD, ou plutôt son absence, a été source de confusion ces dernières années. En l'absence de communication d'AMD, nous avons ainsi fait référence à GCN 1.1 et GCN 1.2 pour parler des petites évolutions apportées depuis la Radeon HD 7970 de décembre 2011. AMD préfère cependant concentrer le terme GCN sur les unités de calcul du GPU (ses "curs"), d'autres éléments du GPU pouvant évoluer indépendamment. Polaris représente ainsi le nom global de la nouvelle architecture et GCN 4 la nouvelle version de ses unités d'exécution (après GCN 1 / 1.0, GCN 2 / 1.1 et GCN 3 / 1.2).
Raja Koduri, qui dirige Le Radeon Technology Group, nous a indiqué vouloir faire en sorte que les cartes graphiques qui embarqueront un GPU de type Polaris soient clairement identifiables. Pragmatique et réaliste, il est bien conscient qu'avec une éventuelle future gamme de cartes graphiques, il pourra être difficile pour ses équipes de résister à la tentation d'y intégrer d'anciens GPU. Il sera ainsi important de permettre aux GPU Polaris d'être mis en avant de manière explicite.
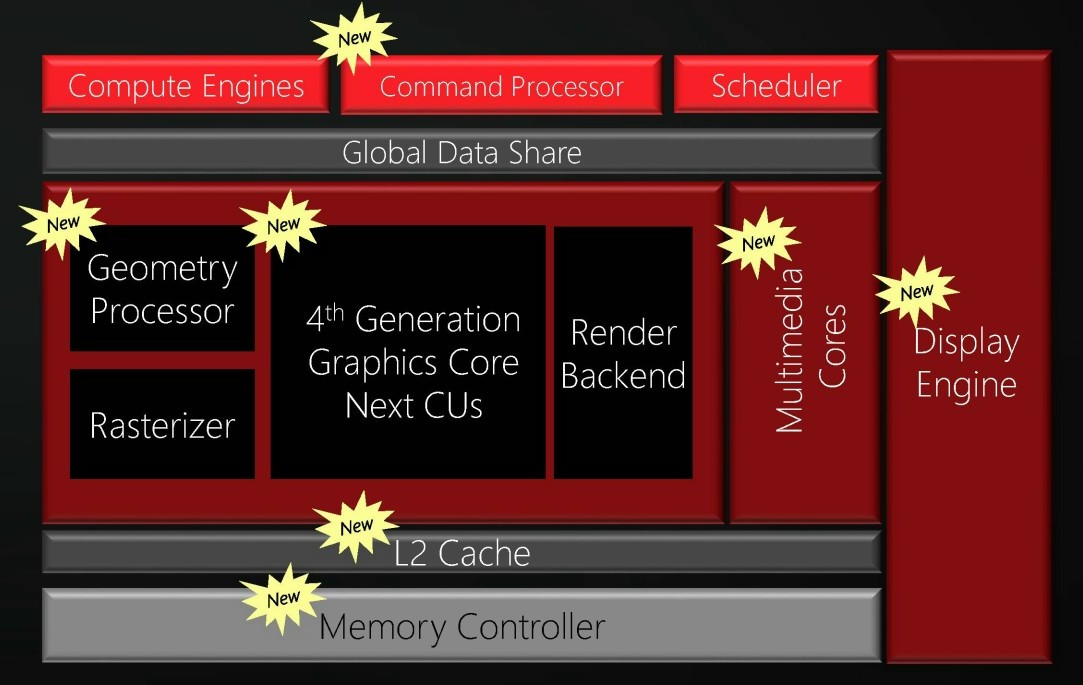
Avec Polaris, à peu près tous les blocs du GPU vont être mis à jour. Nous vous avons déjà parlé de l'aspect affichage et vidéo le mois passé. Pour rappel, les GPU Polaris supporteront le HDMI 2.0a, le DisplayPort 1.3 et le décodage des vidéo 4K en H.265.
Les processeurs de commandes (grahiques et compute), les processeurs géométriques, le cache L2 et le contrôleur mémoire seront également revus pour accompagner le passage aux Compute Units (CU) de type GCN de 4ème génération. Sur ce dernier point AMD précise que Polaris pourra supporter soit un bus GDDR5 soit un bus HBM, suivant les GPU.
Malheureusement, AMD en dit très peu sur les évolutions et ne donne que ces quelques maigres détails :

AMD indique tout d'abord que le cur de l'architecture a été amélioré pour une meilleure efficacité énergétique. Comme Nvidia a commencé à le faire à partir de la génération Kepler, nous pouvons supposer qu'AMD va essayer de ne plus avoir besoin d'une logique d'ordonnancement complexe et gourmande à l'intérieur des CU, là où le comportement d'une suite de certaines instruction est totalement déterministe et peut donc se contenter d'un ordonnancement statique préparé lors de la compilation.
AMD parle également d'amélioration des ordonnanceurs matériels, mais cette fois nous supposons qu'ils ne font pas référence aux CU mais au front-end et aux tâches globales initiées par les processeurs de commandes. Il s'agit ainsi probablement d'améliorations destinées au support du multi-engine de Direct3D 12. Il est également question de nouveaux modes de compression. Il pourrait s'agir de la compression ASTC, coûteuse à implémenter (mais le 14nm règle ce problème) et qu'AMD et Nvidia avaient évité jusqu'ici, contrairement aux concepteurs de GPU pour SoC pour lesquels quelques transistors de plus ne sont jamais trop chers payés pour économiser de la bande passante mémoire et de l'énergie.
Enfin, AMD mentionne un Primitive Discard Accelerator, soit un système d'éjection des triangles masqués du pipeline de rendu. Pour rappel, statistiquement, à peu près la moitié des triangles d'un objet tournent le dos à la caméra et peuvent être éjectés du rendu dès que cet état est confirmé. Pouvoir le faire rapidement permet de booster les performances géométriques en situation réelle.
Actuellement, les moteurs géométriques des Radeon ne sont pas capables d'effectuer cette tâche plus rapidement que le rendu d'un triangle, contrairement aux GeForce qui en profitent pour se démarquer dans certaines scènes, notamment quand la tesselation génère de nombreux triangles masqués. Avec Polaris, AMD devrait enfin combler ce déficit, probablement en doublant le nombre de moteurs d'éjection des primitives par moteur de rastérisation (Nvidia a opté pour une autre approche en décentralisant une partie du traitement géométrique mais nous ne nous attendons pas à ce qu'AMD suive cette voie).

Pour introduire Polaris, contrairement à ce qui se passe habituellement (à l'exception de Maxwell 1 et des GTX 750), AMD met en avant non pas son futur haut de gamme mais un petit GPU prévu pour les PC compacts et pour les portables. Il est équipé de mémoire GDDR5. Nous n'avons pas encore de nom pour ce GPU et n'avons pu l'apercevoir que brièvement sans pouvoir en prendre une photo. Tout juste de quoi apercevoir qu'il s'agit effectivement d'une petite puce et d'un packaging compact.
Sans confirmer que ce serait le premier GPU Polaris disponible, AMD a indiqué que ce petit GPU était important pour sa division graphique, qu'il serait lancé mi-2016 et qu'il serait fabriqué en 14nm chez GlobalFoundries. En précisant ne pas exclure que d'autres GPU soient fabriqués ailleurs, chez Samsung (probablement) ou chez TSMC (de moins en moins probable).
Au niveau de ses spécifications, nous ne saurons rien. Il faudra encore patienter quelque peu, le but d'AMD aujourd'hui étant de nous mettre l'eau à la bouche pour nous faire patienter quelques mois de plus.

Nous avons par contre pu voir ce GPU en action dans une version alpha lors d'un événement presse organisé il y a quelques semaines. AMD a voulu illustrer les gains d'efficacité énergétique apportés par Polaris par rapport à un GPU Maxwell, déjà très efficace. Des chiffres à prendre avec des pincettes, puisqu'ils restent dans le fond assez vagues et avec des conditions de mesure discutables, mais qui font état d'une progression fulgurante du rendement de l'architecture GCN.
Un système équipé d'un petit GPU Polaris est ainsi capable de maintenir 60 fps dans Star Wars Battlefront avec une consommation totale mesurée à la prise de 86W là où un même système équipé d'une GTX 950 demande 140W. Difficile d'en déduire exactement la consommation GPU et ce gain peut en partie être lié à la combinaison d'une puissance GPU supérieure avec un V-Sync à 60 Hz qui permet de rester à une plus faible fréquence, d'ailleurs le GPU utilisé est configuré à 850 MHz pour 0,8375v seulement. Mais de toute évidence Polaris en 14nm va enfin permettre à AMD de faire mieux que Maxwell en 28nm.
AMD tient d'ailleurs à préciser que cette démonstration a été effectuée avec un support partiel de Polaris par les pilotes. Les gains d'efficacité proviennent ainsi uniquement du 14nm et des CU GCN 4, le support des nouveaux mécanismes dédiés à économiser de l'énergie n'ayant pas encore été implémenté.
Bien entendu, les GPU Polaris n'auront pas simplement affaire aux GPU Maxwell actuels mais bien aux GPU Pascal et peut-être à de petits GPU Maxwell 2 fabriqués en 16/14nm. Et il est beaucoup trop tôt pour savoir comment s'opposeront ces futurs concurrents. Pour la première fois depuis très longtemps, il est d'ailleurs intéressant de noter qu'un élément tiers pourra venir semer le trouble dans le combat AMD vs Nvidia : les fondeurs. En effet, il semble de plus en plus probable qu'AMD exploite principalement les process 14nm de GlobalFoundries et Samsung alors que Nvidia exploiterait plutôt le 16nm de TSMC. Si l'un de ces process s'avère meilleur que l'autre, le fabricant de GPU qui aura misé sur le bon cheval s'en trouvera mécaniquement avantagé même si le process ne fait pas tout.
Vous retrouverez la présentation complète ci-dessous :















AMD valide le 14nm LPP de GloFo
GlobalFoundries vient d'annoncer dans un communiqué qu'il avait livré à AMD des puces fonctionnelles gravées avec le process 14nm LPP (Low Power Plus), la version la plus avancée du procédé de fabrication Samsung 14nm FinFet (l'Apple A9 utilisant le 14nm LPE Low Power Early) qui est pour rappel également déployé chez GF.

Le fondeur précise qu'AMD a "taped out" plusieurs produit chez GF en 14nm LPP et qu'il est actuellement en train de valider les échantillons produit. Il semble donc qu'un premier produit ai été validé, GF parlant de "silicon success". AMD indique au passage qu'il compte utiliser le process 14nm LPP sur des produits CPU, APU mais aussi GPU. Jusqu'alors les GPU AMD étaient comme ceux de Nvidia fabriqués par TSMC, mais sachant qu'AMD a toujours des engagements contractuels sur des volumes avec GF qu'il peine à remplir il est logique qu'il favorise ce dernier si le process est à la hauteur. On devrait donc avoir droit en 2016 à une bataille d'architecture entre AMD et Nvidia combinée à une bataille de fondeurs avec d'un côté le 16nm FinFET+ de TSMC et de l'autre le 14nm LPP de Samsung/GlobalFoundries !
GlobalFoundries indique que le 14nm LPP a été qualifié au cours du troisième trimestre pour la production, cette dernière va débuter au cours de ce quatrième trimestre et arrivera à plein débit en 2016, sans plus de précision. Difficile pour le moment de savoir quand les premières puces AMD produites en 14nm LPP seront lancées en 2016, mais il serait étonnant que ce soit avant le second trimestre côté GPU et le dernier trimestre côté CPU. Vivement !
Le 16nm en retard chez TSMC
TSMC a également publié ses résultats pour le second trimestre, avec un chiffre d'affaire de 6 milliards de dollars, en hausse de 17.4% par rapport à la même période sur l'année 2013. Le bénéfice net atteint 1.9 milliard, là aussi en hausse de 15.2%.
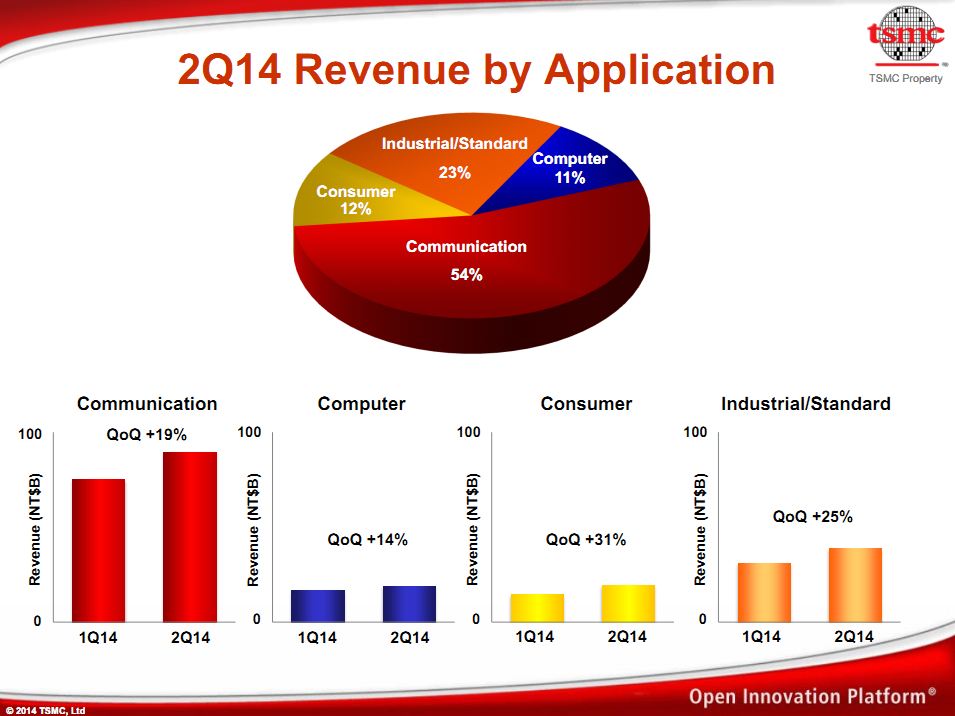
La conférence concernant ses résultats financiers a été l'occasion d'obtenir quelques détails supplémentaires. D'abord un rappel sur l'importance des SoC et Modems pour TSMC. Si tous les segments sont en hausse, la fabrication de SoC représente 54% du chiffre d'affaire sur le second trimestre. Une dépendance forte à des sociétés comme Qualcomm et Mediatek (et selon les rumeurs sur le 20nm, Apple) qui pourrait poser problème à l'avenir au fondeur taiwanais : Qualcomm ayant selon les rumeurs récentes choisi Samsung/GlobalFoundries pour le 16nm (tout comme Apple). A titre indicatif, la part « informatique » qui inclut les SoC x86 et les GPU est en baisse, passant de 13% à 11% du mix de produits fabriqués par TSMC.
Concernant le 20nm, Morris Chang a confirmé que les livraisons en volume ont commencé en juin, réitérant que le ramp-up (la montée des yields, massivement importante pour déterminer le cout final des puces) aura atteint un nouveau record. Selon les rumeurs, Qualcomm et Apple se sont accaparé la majorité de la production 20nm de TSMC pour les trimestres à venir pour la production de leurs SoC.
Le 16 nm devrait cependant être légèrement en retard si l'on en croit les commentaires légèrement cryptiques donnés durant la conférence. La production en volume ne débuterait que fin 2015, alors que TSMC laissait entendre plus tôt que le délai entre la production 20 et 16nm serait de 12 mois. Cela a valu au fondeur d'indiquer qu'il estime qu'un de ses concurrents (non nommé explicitement, mais il s'agit de Samsung) disposera d'une part de marché supérieure sur le 16nm en 2015, quelque chose de justifié en grande partie par le fait que Samsung ait choisi de passer directement au 16nm laissant de côté le 20nm. La perte de part de marché venant du fait que « certains clients » ait souhaité profiter du 16nm avant qu'il ne soit disponible chez TSMC, quelque chose qui semble aller dans le sens des rumeurs concernant Qualcomm et Apple.
TSMC estime que la situation s'équilibrera en 2016. L'allocation 16nm devrait être beaucoup moins problématique que celle en 20nm pour les acteurs du marché GPU dans tous les cas.
On notera que le 10nm a été évoqué et que l'EUV a - chose rare - été évoqué comme une possibilité pour une voir deux couches durant le process de fabrication. Les premiers tape-out seraient attendus sur la seconde moitié de 2015. La production en volume n'étant pas encore évoquée.