Les derniers contenus liés aux tags HBM et HBM2
Samsung augmente la production de HBM2 8 Go
La HBM2 Hynix dispo ce troisième trimestre
GTC: Nvidia Tesla P100: 10 Tflops, HBM2...
La HBM2 4 Go Samsung en production
Samsung augmente la production de HBM2 8 Go



Si Samsung est plutôt habitué à annoncer l'échantillonnage de puce ou le lancement de leur production en volume, la dernière annonce est étonnante puisque le constructeur annonce simplement avoir "augmenté la production" de ses puces 8 Go HBM2 afin de satisfaire la demande.
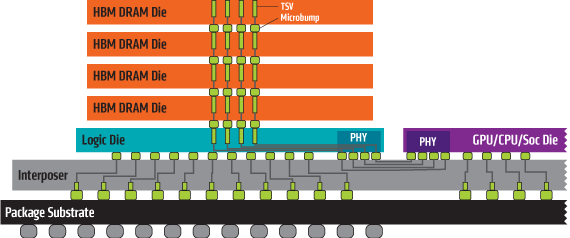
Officiellement, la mémoire HBM2 Samsung est la seule à être disponible en version 8 Go, il s'agit pour rappel d'une version empilant 8 die de 1 Go chacun, interconnectés par un total de 40 000 TSV. SK Hynix, qui fournit a priori AMD pour ses Vega, annonçait une disponibilité en volume pour ce troisième trimestre. A terme Samsung indique qu'au second semestre 2018 plus de la moitié de sa production HBM2 sera en puce 8 Go.

A ce jour NVIDIA, qui utilise de manière certaine des puces HBM2 Samsung, n'utilise que des versions 4 Go avec le GV100 (en quatuor). Les Vega Frontier Edition d'AMD utilisent pour leur part 2 puces 8 Go, a priori de SK Hynix donc, alors que les Radeon RX Vega devraient se limiter à 2 puces 4 Go. C'est à se demander si derrière cette annonce ne se cache pas le lancement de la véritable production en volume de la HBM2 8 Go Samsung !
La HBM2 Hynix dispo ce troisième trimestre
Dans la dernière version de son catalogue dédié à la mémoire graphique, SK Hynix précise que sa HBM2 devrait être disponible au cours du troisième trimestre. Deux références sont au catalogue, la distinction se faisant au niveau de la vitesse - 1.6 ou 2.0 Gbps soit 204 ou 256 Go/s. La HBM2 Samsung utilisée par Nvidia sur Tesla P100 fonctionne pour sa part à 1.4 Gbps soit 179 Go/s.
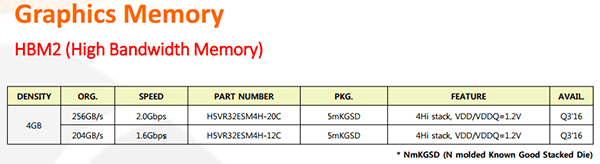
Dans les deux cas il s'agit de puces de 4 Go intégrant 4 die de 1 Go empilés et alimentés en 1.2V. De quoi obtenir avec un bus 4096-bit comme celui intégré sur la puce AMD Fiji ou Nvidia GP100 16 Go de HBM2 à 1 To/s. Il est probable qu'AMD fasse appel à l'une ou l'autre de ces références pour sa future puce Vega, reste à savoir si cela se fera au travers d'un bus 2048 ou 4096-bit.
GTC: Nvidia Tesla P100: 10 Tflops, HBM2...
Comme prévu, Jen-Hsun Huang, le CEO de Nvidia, a levé un coin du voile concernant le premier produit Pascal, l'accélérateur Tesla P100. Au menu : 15 milliards de transistors, 10 Tflops, HBM2, 4 Mo de L2

Le Tesla P100 est un nouvel accélérateur dédié au calcul massivement parallèle qui embarque un GPU GP100, auquel nous faisions référence précédemment en tant que Pascal, nom de code de son architecture. Il s'agit bel et bien d'un nouveau monstre de puissance. Pour cette première utilisation de procédé de fabrication 16nm FinFET Plus, Nvidia n'a pas eu peur de concevoir un énorme GPU et le GP100 intègre pas moins de 15.3 milliards de transistors répartis sur 610 mm². A comparer aux 8 milliards de transistors de l'actuel GM200 qui mesure également 600 mm².
De quoi pouvoir pousser la puissance de calcul vers le haut mais surtout intégrer de nouvelles fonctionnalités avant tout dédiées au monde du HPC telles que la connectique NVLink qui offre une bande passante combinée de 160 Go/s.



Le Tesla P100 se présente sous la forme d'un module au format mezzanine qui revient à superposer 2 PCB, avec un ou plusieurs connecteurs entre ceux-ci. Sur le Tesla P100 il s'agit de 2 connecteurs de 400 broches qui vont permettre de proposer la connectique NVLink. Ce format facilite également l'intégration dans les serveurs et la mise en place d'un refroidissement performant ce qui permet à Nvidia de pousser le TDP à 300W.

Concernant la puissance brute du Tesla P100, Nvidia annonce 10.6 Tflops avec GPU Boost en FP32, la précision classique, un gain de 60% par rapport aux 6.6 Tflops de la Titan X. L'architecture Pascal dans cette implémentation supporte également la double précision en demi-vitesse, soit 5.3 Tflops, un nouveau bond en avant par rapport au record actuel : 2.6 Tflops pour le GPU Hawaii d'AMD des FirePro W9100 et S9170. Dans l'autre sens, Pascal supporte également la demi-précision, le FP16, et peut alors monter à 21.2 Tflops.
A quelle configuration de GPU pourrait correspondre tout cela ? Au départ, nous supposions que le nombre d'unités de calcul passerait de 3072 sur le GM200 à 4608 sur le P100, réparties dans 36 blocs d'unités de calcul (SMP ?), ce qui aurait permis assez facilement d'augmenter à peu près toutes les capacités brutes du GPU de 50%. Il n'en est cependant rien et les changements sont plus profonds au niveau de l'architecture. Il s'agit ainsi pour le Tesla P100 de 3584 unités de calcul réparties dans 56 blocs de 64, mais le GP100 continent physiquement 60 de ces blocs.
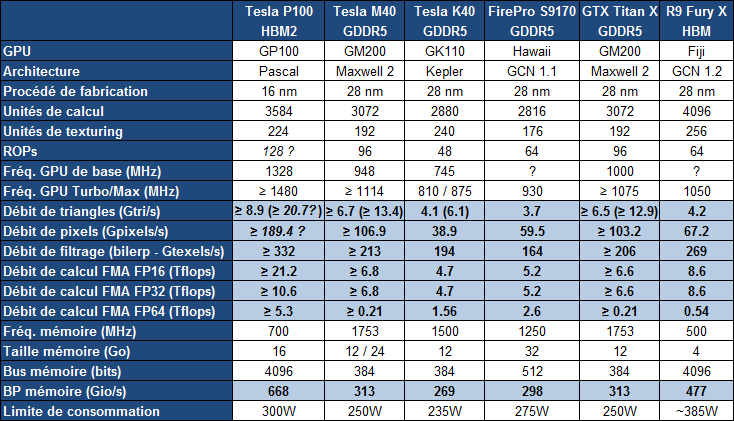
Le gain de puissance de calcul brute provient ainsi principalement d'une hausse de la fréquence du GPU (+/- 1.5 GHz) alors que le GPU computing devrait profiter de cette organisation en plus petits blocs d'unités de calcul, mais également des autres évolutions de l'architecture Pascal, pour gagner en efficacité.
Sur ce point, Nvidia se contente de parler d'une augmentation de la taille du fichier registre. Au total le GM200 embarque +/- 6 Mo de registres, ce qui correspond à 256 Ko par SMM ou encore à 512 registres 32-bit par unités de calcul. Le GP100 passe à 15 Mo de registres, ce qui implique une augmentation de 100%, soit 256 Ko par SMP ou encore 1024 registres 32-bit par unité de calcul. De quoi permettre de maintenir un meilleur taux d'occupation des unités de calcul, particulièrement en double précision.
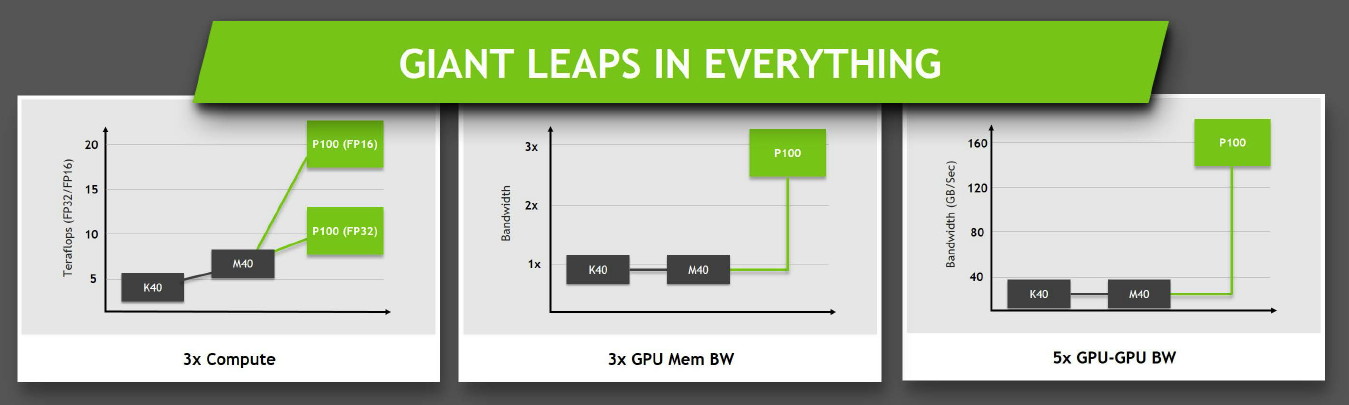
Le cache L2 passe de son côté de 3 à 4 Mo alors que l'interface mémoire est large de 4096-bit en HBM2. Nvidia annonce une bande passante de 720 Go/s pour les 16 Go de mémoire HBM2 CoWoS, le nom donné par TSMC à sa technologie 2.5D, similaire à celle employée par AMD pour son GPU Fiji.
Ce passage à la mémoire HBM2, associé à NVLink, à la puissance de calcul en hausse et au support de la précision FP16 permet au Tesla P100 d'afficher une progression conséquente sur différents plans par rapport à ses prédécesseurs.
Jen-Hsun Huang a terminé le chapitre consacré à Pascal en déclarant que la production en volume avait débuté et que son propre serveur basé sur le Tesla P100 serait commercialisé à partir du mois de juin. Il est probablement raisonnable de s'attendre à une nouvelle GeForce Titan d'ici là, mais sera-t-elle basée sur le GP100 ?
La HBM2 4 Go Samsung en production
Samsung vient d'annoncer qu'il avait débuté la production en volume d'une puce HBM2 d'une capacité de 4 Go. Offrant une bande passante de 256 Go /s, elle est composée de 4 die de 1 Go empilés, chacun comprenant environ 5000 trous pour l'interconnexion via TSV. Par rapport à la HBM utilisée sur l'AMD Fury, la capacité est multipliée par 4 et la bande passante par 2. Le tout est gravé en process 20nm, Samsung indique qu'il devrait également produire une version 8 Go via 8 die empilés cette année.