
Actualités informatiques du 03-03-2015
- Micron affûte ses armes pour la NAND 3D
- Phanteks lance l'Enthoo EVOLVE ITX
- Le X79 Express en fin de vie
- GDC: Khronos annonce OpenCL 2.1
- GDC: Vulkan, l'API bas niveau de Khronos
- GDC: Direct3D12: premiers conseils aux devs
| Mars 2015 | ||||||
|---|---|---|---|---|---|---|
| L | M | M | J | V | S | D |
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 | |||||
Micron affûte ses armes pour la NAND 3D



Micron vient d'annoncer que les travaux visant à doubler la capacité de production de sa Fab10 de Singapour avaient débutés. Avec 23 700m² supplémentaires, cette extension nommée F10X permettra à elle-seule de graver de la NAND 3D Micron de 2nde génération sur 140 000 wafers par mois, soit le niveau actuel de production de la Fab 10 qui produit pour l'instant de la NAND 16nm.

Micron a également donné quelques détails supplémentaires sur ses avancées côté NAND lors d'une conférence destinée aux analystes en février . On a notamment appris à cette occasion de la 16nm TLC était actuellement produite à Singapour et que le fabricant avait pour intention de lancer des SSD l'utilisant au second semestre. Pour la suite Micron mise à 100% sur la NAND 3D et la première génération devrait pour sa part être produite à compter de la mi-2015, pour une introduction sur des SSD en toute fin d'année.

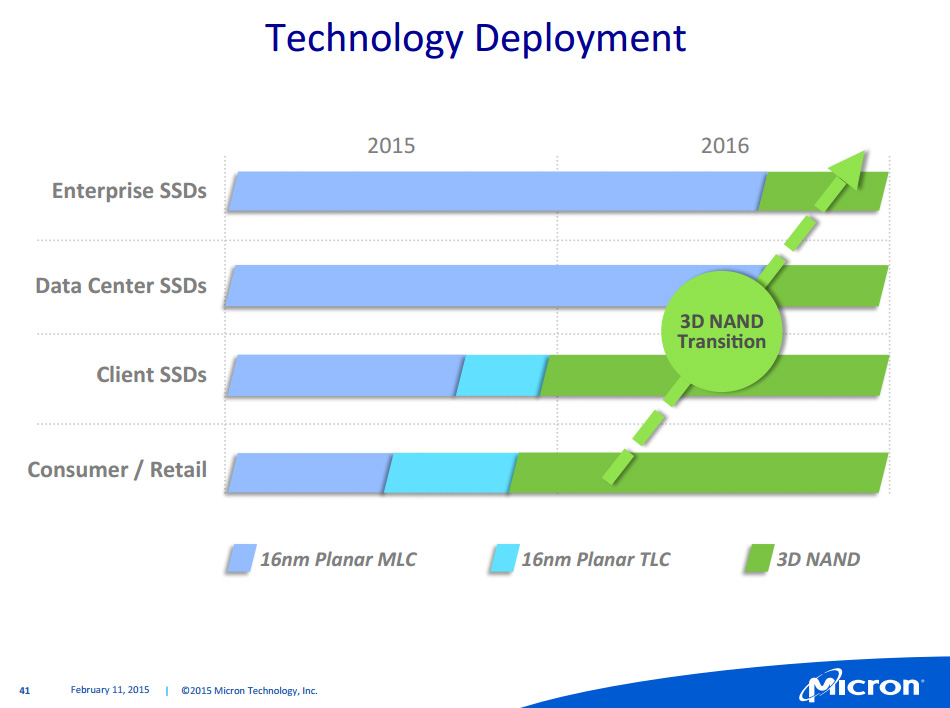
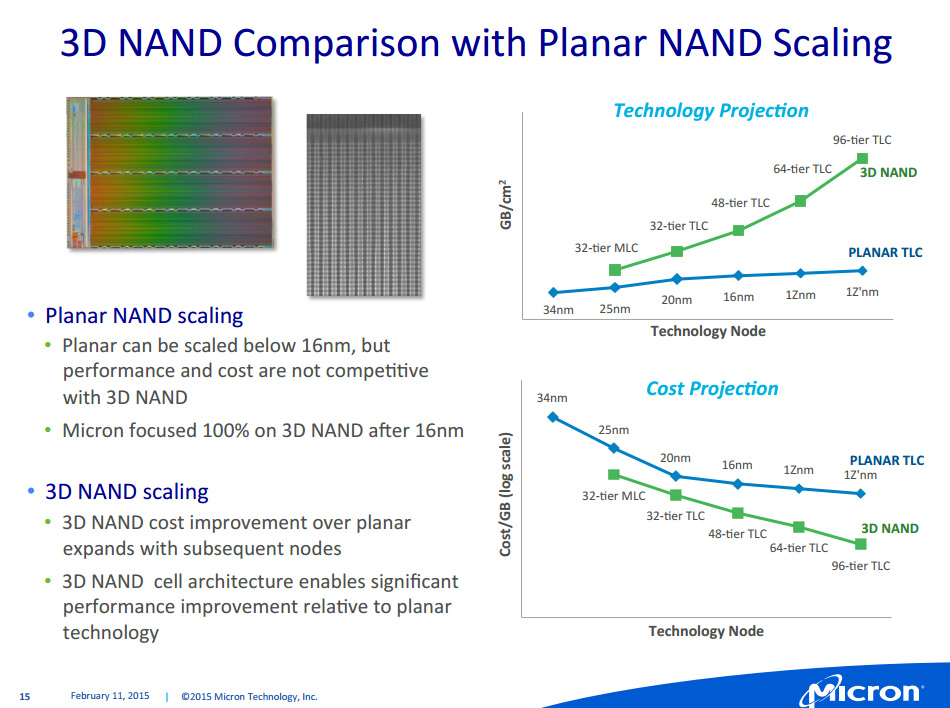
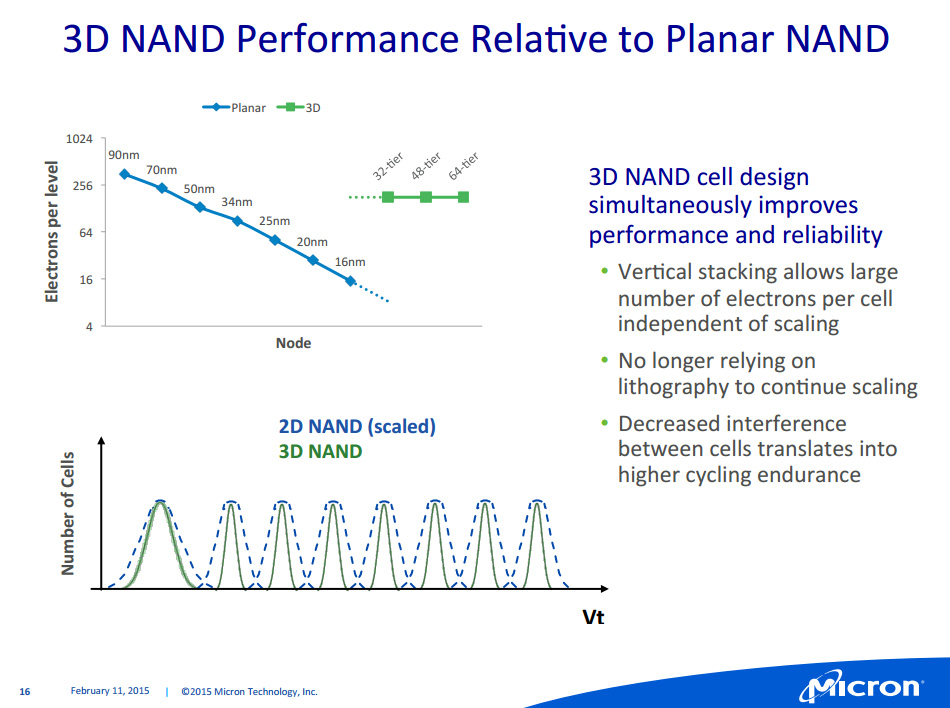
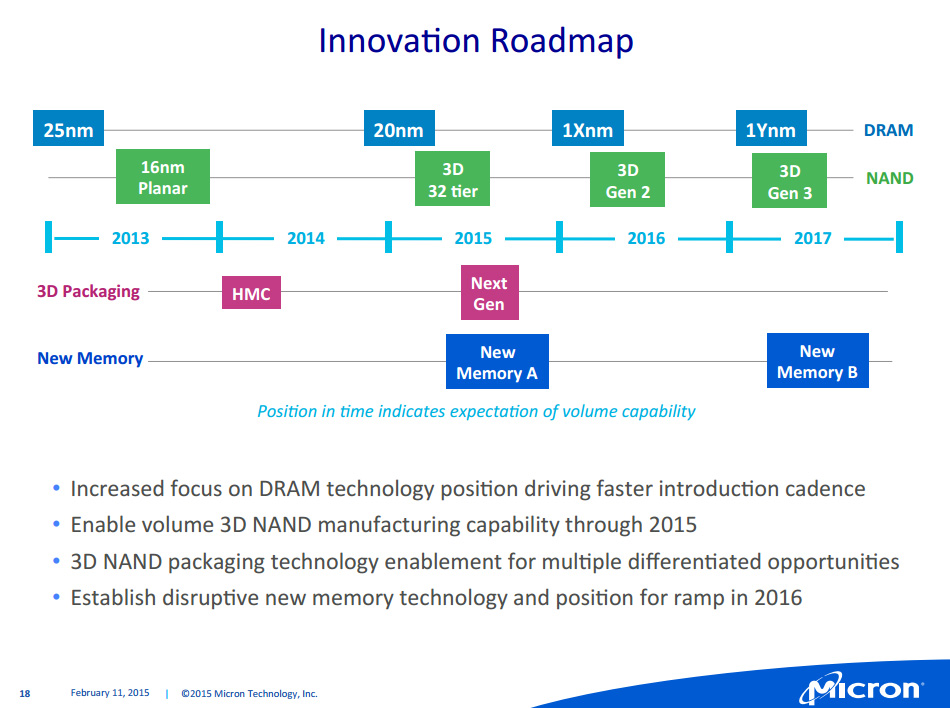
Micron travaille pour rappel conjointement avec Intel sur cette NAND 3D, un domaine dans lequel ils accusent du retard sur Samsung. Ils ont toutefois l'intention de le rattraper ce retard avec une puce 256 Gb 32 couches qui offrira une meilleure densité par mm² que Samsung et un coût inférieur. On notera que si les projections de coût font état de versions MLC et TLC pour la NAND 3D 32 couches, pour les futures versions générations 48, 64 et 96 couches seule la TLC est mentionnée. Actuellement en développement, la NAND 3D de 2nde génération qui sera produite dans l'extension de F10X débarquera un an après la 1ère, suivie un an plus tard de la 3è génération.
Phanteks lance l'Enthoo EVOLVE ITX
Phanteks continue d'étendre sa gamme de boitier avec l'Enthoo EVOLVE ITX. Ce petit bébé de 230*375*395mm pèse 5,4 Kg et accueille donc une carte mère au format mini-ITX. Côté stockage on dispose de deux emplacements 3.5" et d'un emplacement 2.5", il sera possible d'acquérir en option de quoi positionner un 3.5" ou un 2.5" supplémentaire au-dessus d'une partie faisant office de cache pour les connecteurs d'alimentation de la carte graphique. Cette dernière peut atteindre les 33 cm de longueur alors que le ventirad peut faire 20cm de hauteur.











Le refroidissement est assuré par défaut par un ventilateur de 200mm en façade, il est possible de mettre 2 ventilateurs 140/120mm à cet endroit ainsi qu'au-dessus, contre un ventilateur 140/120mm à l'arrière. Côté watercooling on peut intégrer un radiateur 140/120mm à l'arrière, un 240mm en haut ou en façade, ou un 280mm en haut. Des brackets permettant d'intégrer une pompe et un réservoir sont fournis, la pompe prend la place des deux emplacements 3.5" et le réservoir se positionne au-dessus du cache carte graphique.
Le Phanteks Enthoo EVOLVE ITX devrait être disponible à la fin du mois pour 65 en version classique et 70 avec fenêtre.
Le X79 Express en fin de vie
 Lancé le 14 novembre 2011, le X79 Express qui est à la base de la plate-forme LGA 2011 entre désormais dans le programme de fin de vie commerciale d'Intel. Comme d'habitude l'arrêt n'est pas brutal puisque les clients d'Intel peuvent passer commander jusqu'au 25 septembre prochain pour des livraisons pouvant s'étaler jusqu'au 5 février 2016.
Lancé le 14 novembre 2011, le X79 Express qui est à la base de la plate-forme LGA 2011 entre désormais dans le programme de fin de vie commerciale d'Intel. Comme d'habitude l'arrêt n'est pas brutal puisque les clients d'Intel peuvent passer commander jusqu'au 25 septembre prochain pour des livraisons pouvant s'étaler jusqu'au 5 février 2016.
Voilà qui ne devrait pas faciliter la disponibilité déjà compliquée des cartes mères X79 Express neuves, heureusement le marché de l'occasion est là pour dépanner ceux qui auraient besoin d'un tel produit !
GDC: Khronos annonce OpenCL 2.1
Parallèlement à l'annonce de Vulkan, le groupe Khronos fait évoluer légèrement OpenCL avec l'annonce des spécifications provisoires de la version 2.1 de cette API dédiée au GPU computing. La principale nouveauté est l'ajout d'un nouveau langage pour les kernels : à côté d'OpenCL C prendra désormais place OpenCL C++.
Ce langage correspond à un subset de C++14, amputé de quelques fonctionnalités, et permettra de faciliter le travail des développeurs, en leur permettant d'ignorer certains détails de bas niveau, tout en gardant une efficacité suffisamment élevée.

Alors que compiler vers un langage intermédiaire, SPIR, était possible optionnellement depuis quelques temps avec OpenCL 2.0, le langage intermédiaire SPIR-V, partagé avec Vulkan, rentre dans les spécifications "core" d'OpenCL 2.1. OpenCL C++ est d'ailleurs prévu pour passer exclusivement par SPIR-V.
De petites fonctionnalités font également leur apparition ou rentrent dans les spécifications "core", c'est par exemple le cas des requêtes concernant les "subgroups", qui exposent l'organisation matérielle du threading (warps chez Nvidia, wavefronts chez AMD etc.) et permettent des optimisations plus fines.
A noter que si Intel et AMD louent les avantages d'OpenCL 2.1 dans la communication officielle, Nvidia reste aux abonnés absents et tient donc le cap sur sa stratégie qui consiste à se concentrer sur son écosystème propriétaire CUDA.







GDC: Vulkan, l'API bas niveau de Khronos
Il y a 6 mois, à travers l'initiative Next Generation OpenGL, le groupe Khronos annonçait l'intention de faire évoluer son API phare pour répondre aux récentes API graphiques de plus bas niveau proposées par AMD, Microsoft ou encore Apple. Des travaux qui ont bien avancés et la GDC est l'occasion d'annoncer formellement Vulkan.

OpenGL est une API qui a été régulièrement critiquée pour son évolution trop lente et pour sa complexité trop élevée. Définie par un consortium qui regroupe tous les fabricants de GPU, des fabricants de SoC, des fabricants de périphériques mobiles, des spécialistes du moteur graphique, etc., cette API souffre de la difficulté de mettre tout le monde d'accord sur les directions principales des évolutions, et encore plus sur les points de détails. Toutes ces sociétés n'ont pas les mêmes intérêts, ce qui entraîne une bonne dose de politique et de lobbying, suivis d'un long processus de négociations. Par ailleurs, l'aspect rétrocompatibilité et le long historique de 22 ans ont fini par devenir des boulets que doit trainer OpenGL.
Dans le monde mobile, Khronos a tenté de gagner en agilité à travers une API dédiée et quelque peu simplifiée, OpenGL ES. Cela a plutôt bien fonctionné jusqu'ici, même si les 2 API partagent certaines limitations. Avec l'arrivée des API de plus bas niveau, initiée par AMD et Mantle, suivie par Microsoft et Direct3D 12 ainsi que par Apple et Metal, il y avait une vraie pression sur Khronos pour revoir en profondeur son API graphique. Une opportunité en fait puisqu'une pression suffisante était nécessaire pour parvenir à mettre d'accord, relativement rapidement, tous ses membres.
Pour se donner un maximum de liberté et probablement pour pouvoir contenter les membres qui tirent un avantage compétitif de la complexité actuelle d'OpenGL, ou de son long historique, un compromis s'est rapidement avéré nécessaire. OpenGL Next ne serait pas un OpenGL mais une nouvelle API, bien distincte. De quoi permettre à Khronos d'avancer les mains libres. OpenGL et OpenGL ES vont continuer à évoluer de leur côté, en restant des API de plus hauts niveaux, bien que certains accès de plus bas niveaux y soient déjà disponibles depuis quelques temps, tout du moins pour les développeurs expérimentés qui parviennent à les dénicher sous les différentes couches de complexité.
Parallèlement à ces API "historiques", la nouveauté que Khronos va proposer se nomme Vulkan, son interprétation de l'API graphique de plus bas niveau. A noter que lorsqu'on parle d'une API graphique de bas niveau, il ne s'agit pas d'attaquer les GPU en langage machine barbare. Un certain niveau d'abstraction est conservé, et représente un compromis entre le contrôle donné aux développeurs et la compatibilité avec une large gamme de processeurs graphiques et de plateformes. Du supercalculateur, au smartphone, en passant par le PC, Vulkan pourra trouver sa place.
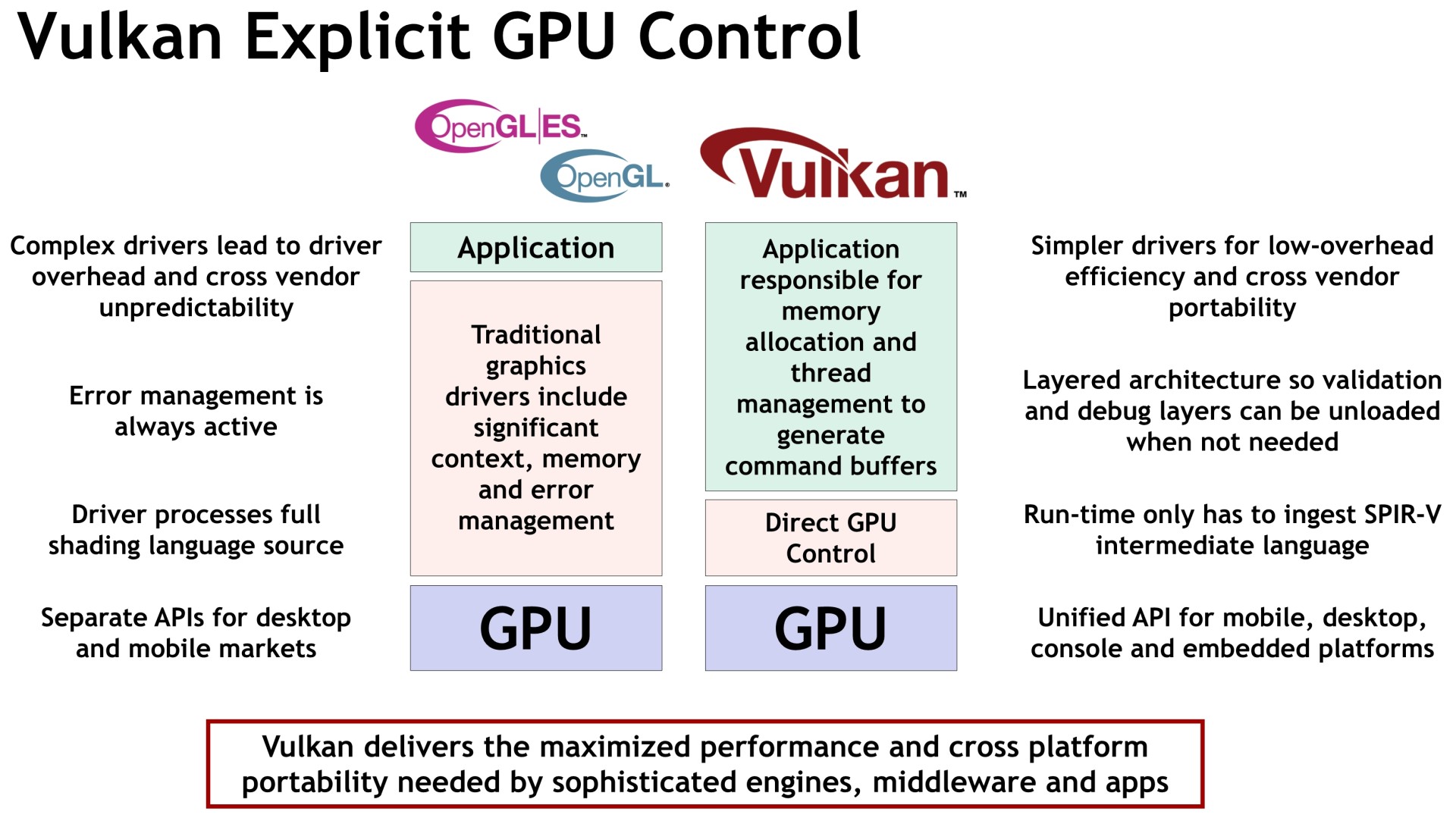
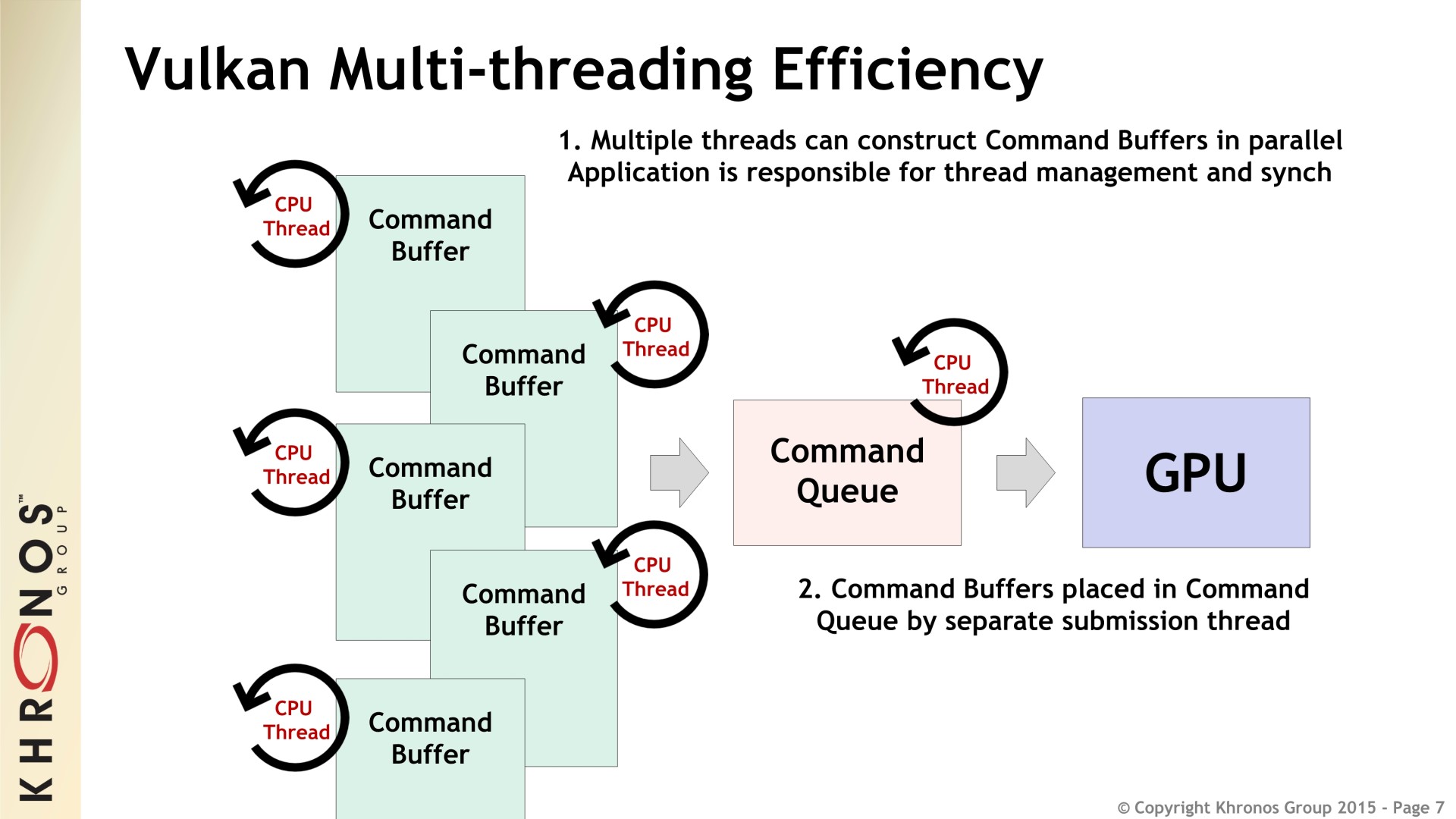
Comme les autres API de bas niveau, Vulkan offre un accès plus adapté aux GPU modernes, réduit le surcoût CPU des pilotes et permet l'implémentation d'un multi-threading efficace. Une API de plus bas niveau, qui rend le comportement du pilote GPU plus prédictible, facilite également la portabilité d'une plateforme à l'autre tout en conservant de bonnes performances, un point crucial pour tous les développeurs de moteurs de jeux et de middlewares.
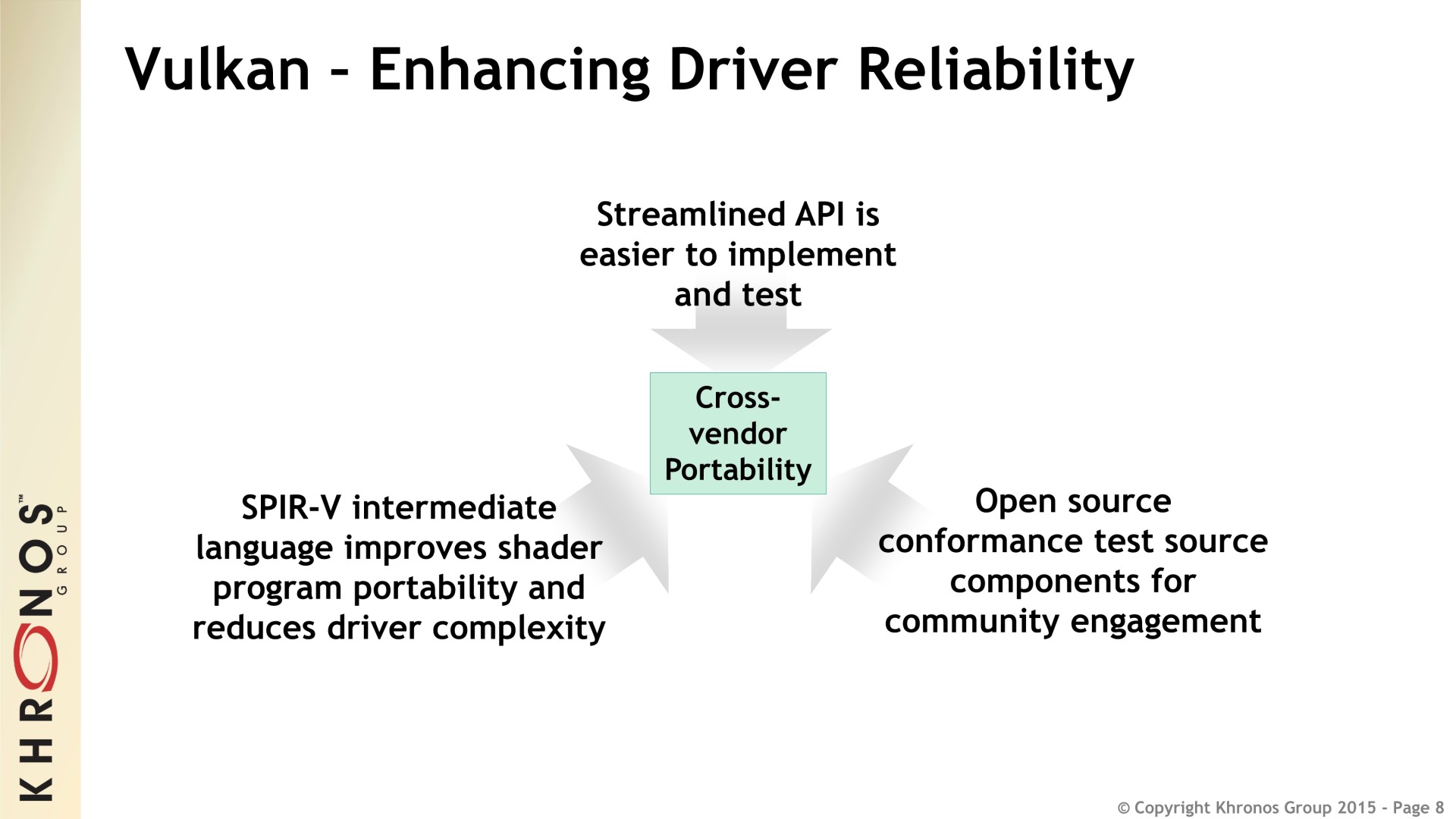
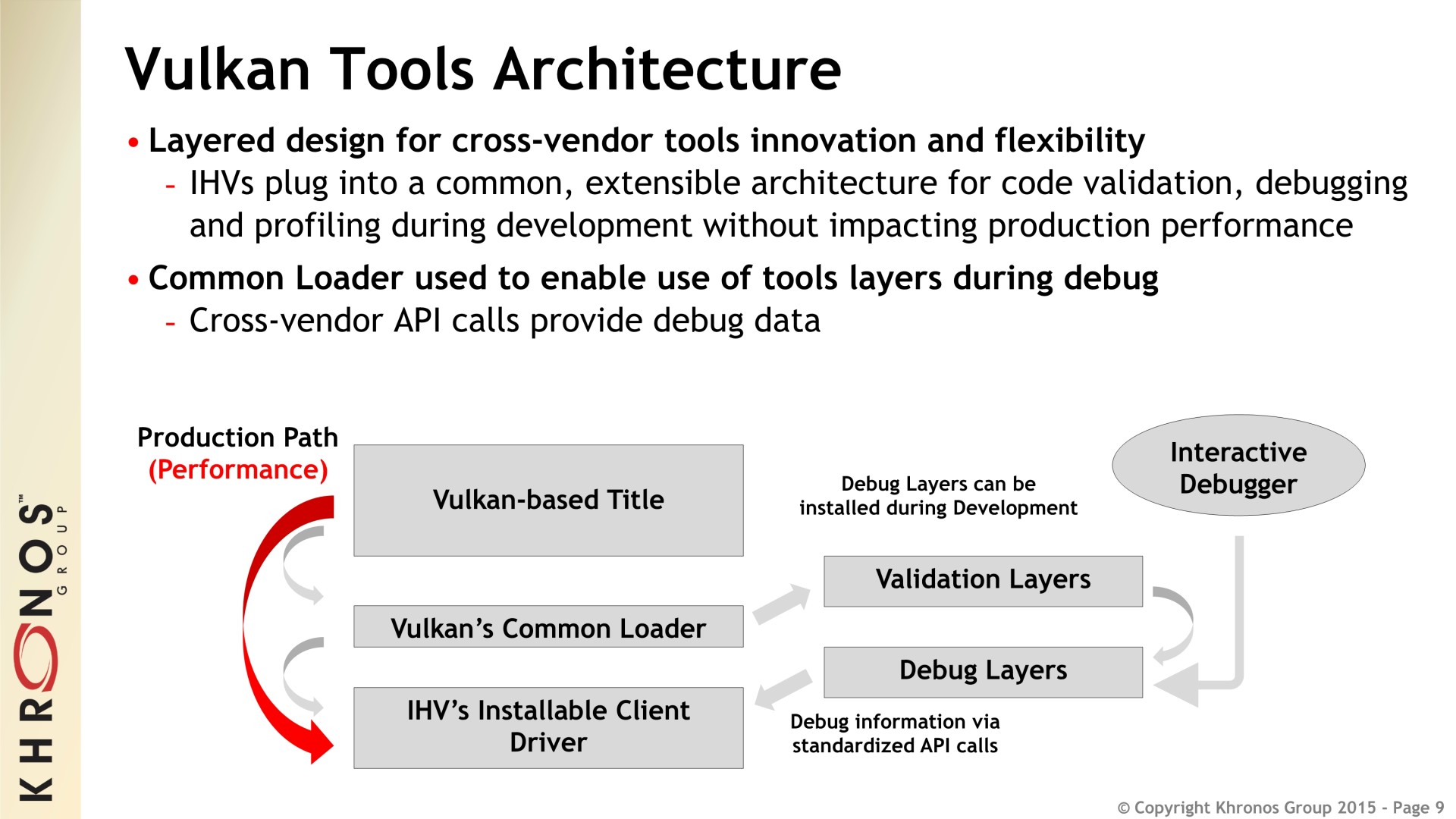
Khronos indique d'ailleurs avoir construit à l'intérieur de Vulkan des mécanismes dédiés spécifiquement à faciliter la portabilité, notamment au niveau du débogage. Des outils multiplateformes performants devraient ainsi pouvoir être proposés. Des développements dans ce sens son déjà bien avancés chez Valve, LunarG ou encore Codeplay.
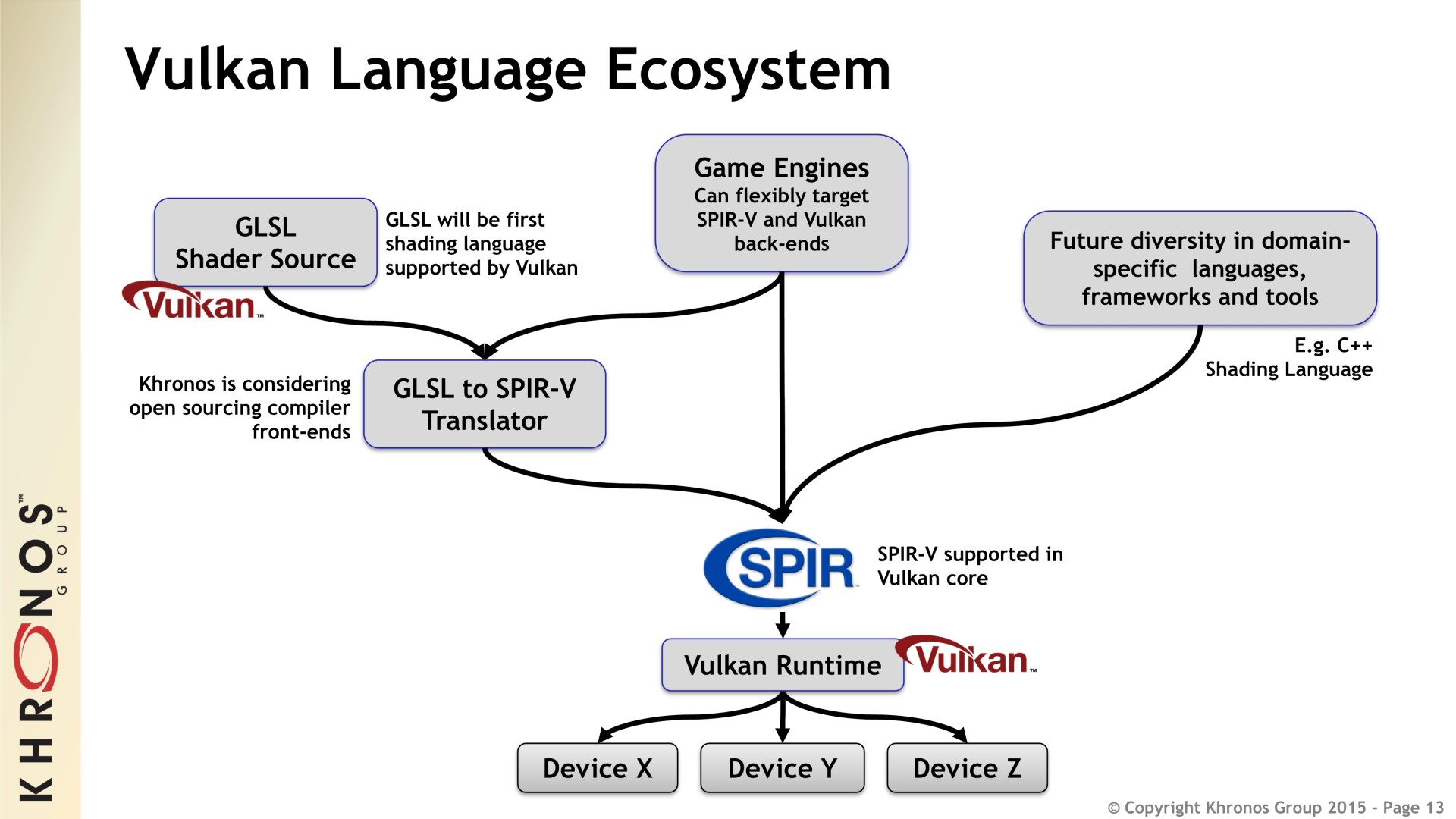
Pour permettre à Vulkan de voir le jour, une autre évolution majeure était indispensable. Avec OpenGL, les programmes (shaders) qui sont exécutés par le GPU sont écrits dans un langage de haut niveau spécifique, GLSL, et compilés à l'exécution par les pilotes en langage machine exécutable par le GPU. Cela a plusieurs inconvénients, il faut intégrer aux pilotes un compilateur complexe, les temps de compilation peuvent être importants, le débogage est plus complexe, le code source des shaders n'est pas protégé
Pour éviter tout cela, Khronos introduit SPIR-V, un langage intermédiaire entre le code source et le code machine. Il s'agit d'une évolution du SPIR déjà disponible en OpenCL et qui sera d'ailleurs partagée par Vulkan ainsi que par le futur OpenCL 2.1. Les développeurs pourront précompiler leur code GLSL vers SPIR-V, et les meilleurs d'entre eux ainsi que les fournisseurs de moteurs graphiques pourront optimiser directement ce code SPIR-V.
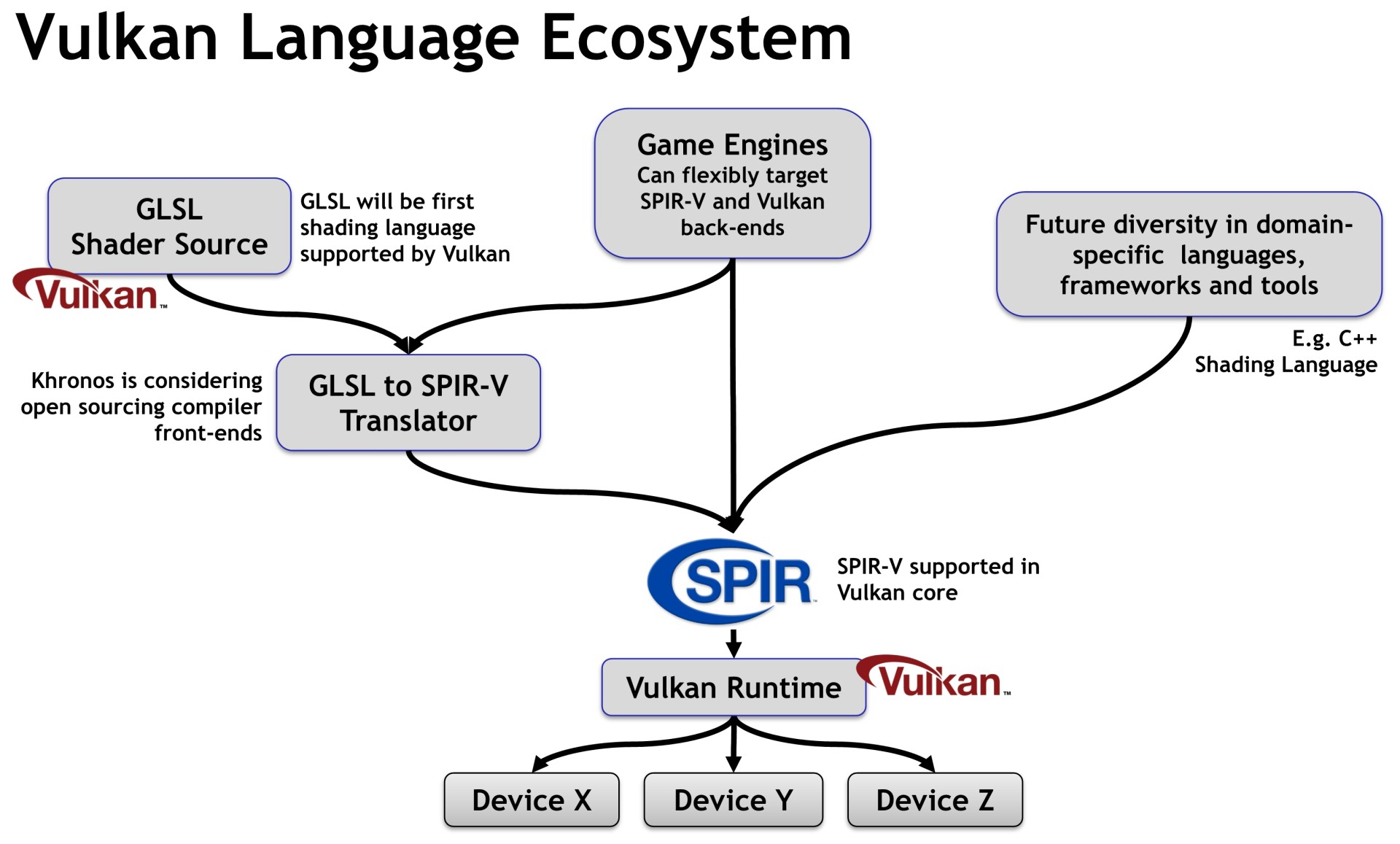
Khronos envisage de faire passer en open source le compilateur GLSL vers SPIR-V pour faciliter l'arrivée d'un riche écosystème, avec par exemple une variante HLSL vers SPIR-V. D'autres langages pourront également être traduits à l'avenir vers SPIR-V et Khronos a prévu que la conversion de et vers LLVM soit possible. Ces outils en sont toujours dans les premières phases de leur développement.
La semaine passée, nous avons pu nous entretenir brièvement avec Neil Trevett, Président de Khronos et Vice Président de l'écosystème mobile chez Nvidia, au sujet de Vulkan. Ce dernier nous a tout d'abord indiqué que de nombreux détails sont toujours en train d'être définis telles que l'implémentation exacte au niveau des pilotes et des OS.
Pour Neil Trevett, qui aborde la question sans détour, l'arrivée de Vulkan ne représente pas une menace dans le monde professionnel pour une société telle que Nvidia qui bénéficie actuellement d'un avantage compétitif énorme à travers son implémentation logicielle robuste d'OpenGL. D'une part Vulkan sera utile pour certaines applications trop limitées par le CPU pour pouvoir profiter des GPU haut de gamme récents de Nvidia et d'autre part l'importance d'OpenGL est loin de s'effacer dans un monde qui a tendance à bouger lentement.
Du côté grand public, tout GPU capable de supporter OpenGL ES 3.1, et donc les Compute Shaders, devrait être capable de faire tourner Vulkan, si bien entendu des pilotes sont développés en ce sens. Du côté PC, tous les GPU qui supportent D3D12 devraient ainsi également supporter Vulkan. Pour les SoC, c'est un petit peu plus compliqué en général, mais du côté de Nvidia, les Tegra K1 et X1 devraient bien entendu en profiter.
Neil Trevett nous a ensuite indiqué, qu'au niveau des OS, Vulkan devrait être rendu disponible partout là où OpenGL et OpenGL ES sont actuellement proposés. En d'autres termes le support devrait être très large et inclura sans problème d'anciennes versions de Windows telles que Windows 7. L'implémentation exacte n'est par contre pas précisée et il restera à voir si les fabricants de GPU développeront bel et bien de tels pilotes.
La possibilité est cependant prévue, et ce n'est pas anodin. Le point fort de Vulkan du côté grand public face aux API concurrentes sera son très large support, des plateformes Windows aux plateformes mobiles, en passant par Steam OS. De quoi redévelopper une présence de Khronos dans le monde du jeu vidéo PC ? Peut-être mais pas tout de suite, les spécifications initiales sont attendues pour cette année et les premières applications ne le sont pas avant 2016.
Vous pourrez retrouver la présentation complète ci-dessous :













GDC: Direct3D12: premiers conseils aux devs
Durant la journée des tutoriaux, la session dédiée à Direct3D 12 à laquelle nous avons assisté était destinée à donner quelques conseils aux développeurs intéressés par cette API. Une poignée de spécialistes des moteurs graphiques ont fait partie de la phase d'essai de D3D12 et ont travaillé sur des portages betas, souvent en collaboration avec AMD et Nvidia. Des premières expériences qui ont permis de façonner les détails de l'API et de partager certains conseils.

Durant cette présentation, Evan Hart, Principal Engineer chez Nvidia, et Dave Oldcorn, D3D12 Technical Lead chez AMD, ont rappelé que "de grands pouvoirs impliquent de grandes responsabilités". Entendez par là que le niveau de contrôle plus élevé donné aux développeurs leur permet de faire plus de choses et plus efficacement, mais uniquement s'ils exploitent correctement l'API. Une implémentation hasardeuse peut causer plus de problèmes qu'elle ne tente d'en résoudre.
Une expérience des développeurs sur console, même si elle n'est bien entendu pas obligatoire, est clairement en avantage puisqu'il y a des similitudes entre leurs API propriétaires et les nouvelles API de plus bas niveau. Il est d'ailleurs utile de rappeler qu'un certain niveau d'abstraction reste présent et que les développeurs doivent s'attendre à ce que les pilotes gardent en partie la main sur certains points.
Un portage d'API bête et direct vers D3D12 n'a pas réellement de sens. Pour réellement profiter de l'API, une réflexion en amont sur ses possibilités et ce qu'il est possible d'en faire en pratique est nécessaire. Il faut ainsi par exemple prévoir un bon multithreading, D3D12 ne s'en charge pas tout seul par magie. Il revient aux développeurs de bien segmenter et organiser toutes les tâches liées au rendu, et de préciser dans certains cas explicitement quand elles ne peuvent pas être traitées en parallèle. Par sécurité D3D11 présume qu'il y a d'office une dépendance entre certaines tâches, ce qui empêche leur exécution en parallèle et freine les performances. Tout cela disparaît avec D3D12, mais le développeur doit alors indiquer quand il y a une réelle dépendance, sans quoi il y aura bien entendu des problèmes.
Parmi les autres premiers retours abordés, citons ceux-ci :
- Le mieux est l'ennemi du bien et il peut être nécessaire de rechercher un compromis entre réduction maximale du surcoût CPU, via exécution groupées de nombreuses listes de commandes, et latence globale.
- Attention au budget mémoire. Si le développeur alloue trop de mémoire résidente (soit spécifiée en mémoire vidéo), un plantage peut arriver très vite. C'est particulièrement le cas en mode fenêtré dans lequel l'OS reprend la main sur une partie de la mémoire vidéo. En cas de possibilité de passer du plein écran au fenêtré il faut prévoir d'agir très vite sur la quantité de mémoire utilisée, par exemple en supprimant directement les plus hauts niveaux des mipmaps.
- Faire attention aux bus ! Vu qu'une API telle que D3D12 permet d'envoyer beaucoup plus d'objets, des nouveaux goulets d'étranglement peuvent apparaître, c'est par exemple le cas du bus PCI Express qui peut être saturé.
Vous pourrez l'intégralité de cette partie de la présentation ci-dessous :



























