
PCI Express 3.0 : impact sur les performances
Publié le 20/01/2012 par Guillaume Louel



Bande passante, mesures théoriques
Avant de mesurer l'impact pratique, nous avons tenté de vérifier via des tests théoriques si le PCI Express 3.0 tient ses promesses en termes de débits. Nous utilisons ici un test de performance inclus dans le kit de développement APP d'AMD, disponible en version 2.6 .
Paginable, non paginable
Pour rappel ce premier test est assez particulier dans le sens ou il tente d'obtenir les taux de transferts les plus élevés possible en utilisant de la mémoire dite non paginable. En effet, côté système l'outil réserve ses pages mémoires de façon à ce qu'elles ne puissent pas être déplacées. En pratique, cela veut dire que l'on est certain à 100%, pour toute la durée d'exécution du programme, que les pages mémoires seront situées physiquement en RAM et jamais dans un fichier swap.
Si cela peut sembler anecdotique en théorie sur une machine de test équipée de 16 Go de RAM, en pratique cela ne l'est pas. Certes, les données transférées resteront toujours en mémoire physique, mais la simple possibilité que ce ne soit pas le cas réclame des vérifications supplémentaires en ce qui concerne les opérations de copie mémoire. Pour les modes non paginables, AMD ici (tout comme Nvidia dans CUDA) utilise des algorithmes optimisés pour tirer le meilleur parti du PCI Express.
Nous avons mesurés, pour ce test et les suivants, six cas distincts :
- PCI Express 3.0 x16, x8 et x4
- PCI Express 2.0 x16 et x8
- PCI Express 1.0 x16
D'un point de vue théorique, certains modes disposent d'une bande passante équivalente :
- PCI Express 3.0 x16
- PCI Express 3.0 x8 et PCI Express 2.0 x16
- PCI Express 3.0 x4, PCI Express 2.0 x8 et PCI Express 1.0 x16
Pour les jeux et les applications le permettant, nous indiquerons également les résultats dans chacun de ces cas en mode Crossfire.
Bande passante théorique (mémoire non-paginable)
Nous mesurons indépendamment le taux de transfert dans le sens CPU vers GPU (cas typique pour les jeux), ainsi que dans le sens inverse (également mis à contribution en OpenCL).
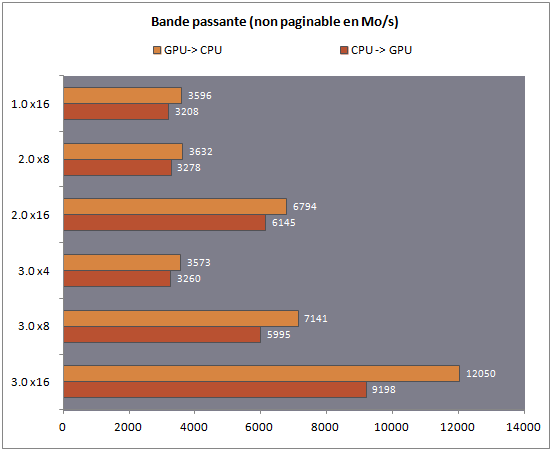
Passez la souris sur le graphique pour voir l'efficacité par rapport à la bande passante théorique
Plusieurs enseignements importants sont à noter. D'abord, si dans le sens GPU vers CPU on note bel et bien une augmentation de la bande passante de 77% entre le mode PCI Express 3.0 x16 et le 2.0 x16 (à comparer aux 89% entre 2.0 x16 et 1.0 x16), dans l'autre sens les gains sont beaucoup plus mesurés : seulement 50% de gain ! On reste ainsi sous la barre des 10 Go/s.
Autre enseignement intéressant, la comparaison entre PCI Express 3.0 x8 et PCI Express 2.0 x16, deux modes qui, théoriquement, disposent de bande passantes identiques. Si l'on note une baisse de 2.5% dans le sens CPU->GPU, on notera 5% de gains dans le sens inverse.
Les performances entre les modes PCI-E 3.0 x4, 2.0 x8 et 1.0 x16 sont globalement équivalentes.
Bande passante théorique (mémoire paginable)
Sachant qu'il n'est pas toujours possible pour les développeurs d'utiliser de l'espace mémoire non paginable, nous avons réalisé un second test via la bibliothèque Cloo (en version 0.9.1 ). Le pilote Open CL d'AMD est compatible avec la version 1.1 de la spécification.
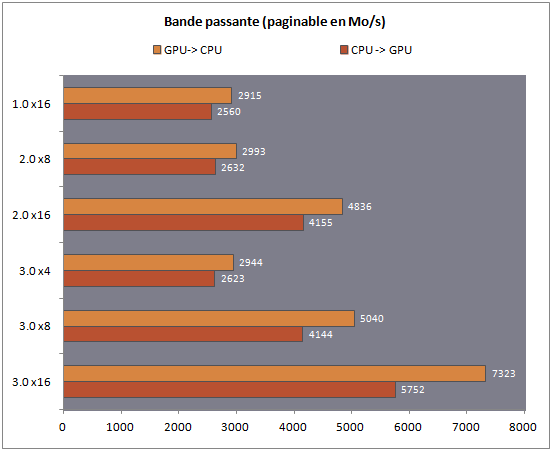
A l'image de ce que l'on avait vu côté non-paginable, de nouveau les gains sont asymétriques lorsque l'on compare les gains apportés par le PCI-E 3.0 x16 par rapport au 2.0 x16 : 38 et 51% respectivement dans les sens CPU->GPU et GPU->CPU. Des scores qui restent malgré tout relativement élevés puisque l'on atteint presque (ou dépasse dans le second sens) les performances du PCI Express 2.0 x16 non-paginable.
En ce qui concerne la comparaison 3.0 x8 et 2.0 x16, on retrouve un score identique dans le sens de transfert conventionnel, et un gain de 4.2% dans le sens inverse. Les performances des modes PCIE-E 3.0 x4, 2.0 x8 et 1.0 x16 restent de leur côté quasi identiques.
Voyons comment tout cela se traduit côté applicatif !
Sommaire
Vos réactions
Contenus relatifs
- [+] 13/12: Influence du PCIe sur une GTX 1080
- [+] 17/08: Un watercooling sur socket pour Coo...
- [+] 13/06: Computex: Asrock X99 Taichi et Fata...
- [+] 08/04: GTC: Tesla P100: débits PCIe et NVL...
- [+] 03/03: Le X79 Express en fin de vie
- [+] 29/08: Intel Haswell-E, LGA 2011-v3 et DDR...
- [+] 04/03: Dites au-revoir aux SNB-E LGA 2011
- [+] 13/09: IDF: M.2, NVM Express et SATA Expre...
- [+] 09/09: Intel Core i7-4960X : Ivy Bridge-E ...
- [+] 14/08: AMD annonce son bundle Never Settle...