
IDF 2010 : Atom et Sandy Bridge à l'honneur
Publié le 05/10/2010 par Damien Triolet



Sandy Bridge : les cores

Après le retard de 2 ans pris par AMD sur lintégration du CPU et du GPU, cest finalement Intel qui devrait être le premier à commercialiser un tel produit avec Sandy Bridge. Pour rappel, les Core i3/i5 actuels nont fait que placer le CPU et le northbridge dans le même packaging pour réduire le coût de la plateforme. Avec Sandy Bridge, lintégration est réelle et ces deux composants ne font plus quun, ce qui permet de nombreuses optimisations tant sur le plan des performances que de la consommation.
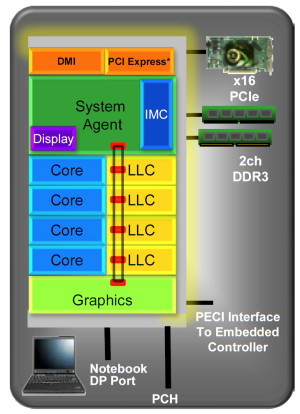
Sandy Bridge marque également larrivée dune nouvelle génération de cores CPUs qui profitent de petites améliorations à de nombreux niveaux, ce quIntel a détaillé lors de cet IDF, en plus dapporter un nouveau jeu dinstruction : AVX. Plus précisément, la plupart des modifications architecturales sont liées à AVX et ont été mises en place pour rendre celui-ci efficace. Laspect consommation est également au centre de tout cela, Intel ayant pour objectif que chaque amélioration augmente le rapport performances/watts.

Pour rappel, lAVX est un nouveau jeu dinstruction vectoriel 256 bits qui permet donc, avec une implémentation idéale, de doubler la puissance de calcul par rapport au SSE 128 bits. Pour cette première implémentation, Intel a fait en sorte de pouvoir exécuter les opérations vectorielles flottantes 256 bits à pleine vitesse, les opérations AVX sur les entiers étant pour leur part découpées en 2 opérations de 128 bits. Pour alimenter ces unités de calcul flottantes de 256 bits, sans faire exploser le coût et la consommation, Intel a réorganisé quelque peu ses unités dexécution de manière à pouvoir réutiliser une partie (principalement les datapaths) de celles dédiées aux opérations sur les entiers.
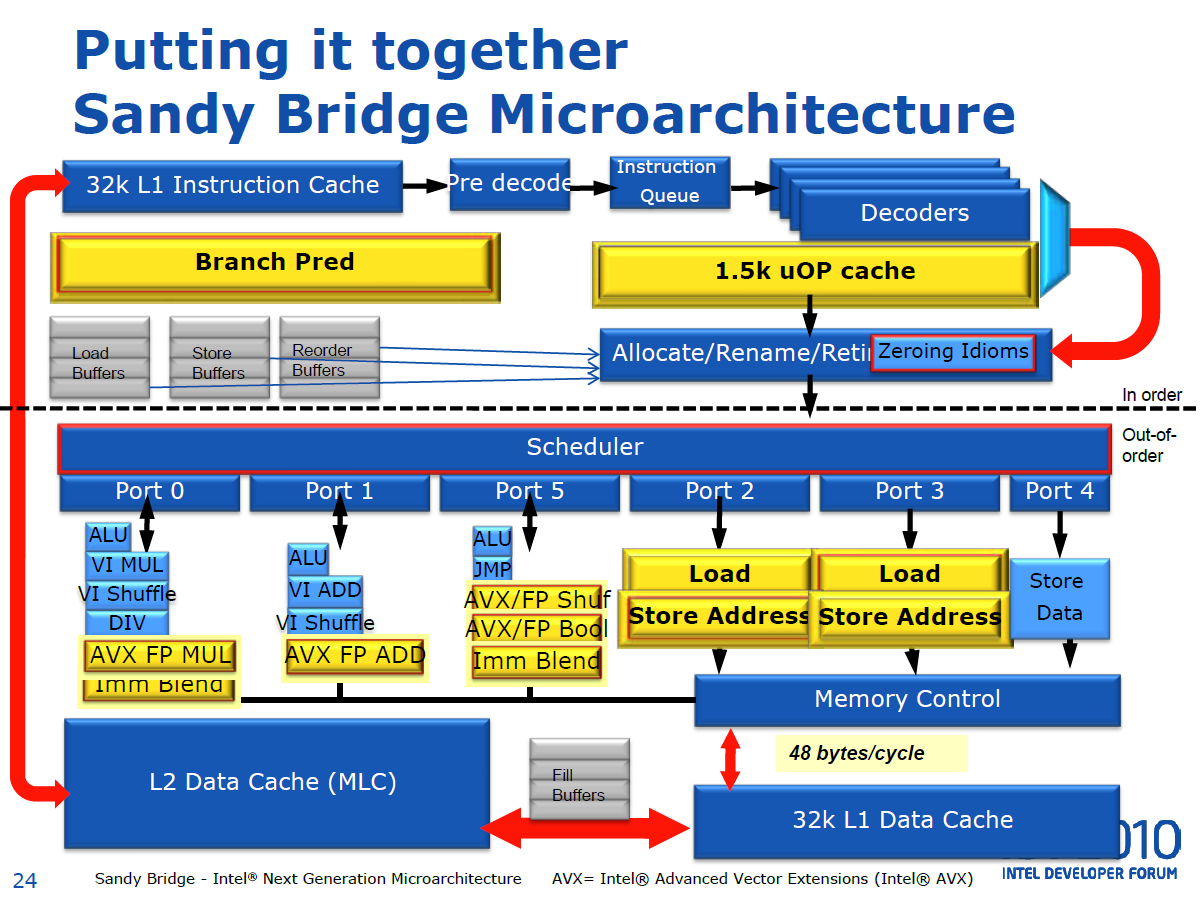
Ce nest pas tout puisque larchitecture actuelle ne peut charger et écrire que 128 bits de données par cycle. Intel a élargi cela et Sandy Bridge est capable de charger 256 bits en plus décrire 128 bits. Cette architecture est au final capable dexécuter, en flottant, une multiplication de 256 bits + une addition de 256 bits + un chargement de 256 bits, soit le double de larchitecture actuelle.
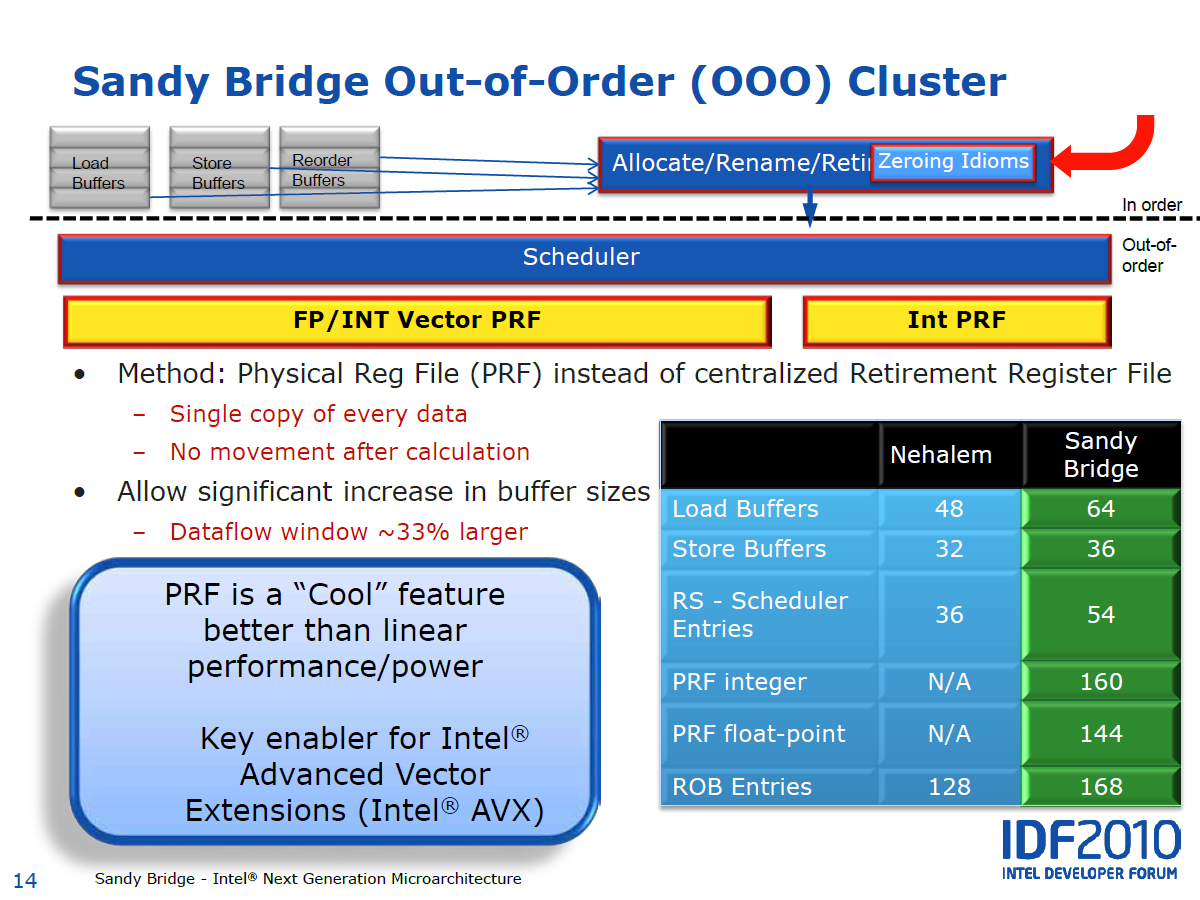
Pour optimiser le fonctionnement Out-of-Order de Sandy Bridge, Intel a opté pour un Physical Register File, tout comme il lavait fait avec le Pentium 4 et tout comme AMD va le faire avec Bulldozer. Par rapport au Retirement Register File utilisé dans les CPUs Core actuels, le PRF, via un jeu de renommage des registres, permet de garder toutes les données localement et donc déviter des déplacements de registres, ce qui est bénéfique pour la consommation et a donné plus de marge de manuvre à Intel pour élargir la fenêtre dopérations dans laquelle lordre dexécution peut être optimisé. Celle-ci passe de 128 à 168 uops.
Toujours dans le souci dalimenter au mieux ce cur dexécution, Intel a revu le front end en ajoutant tout dabord un cache des instructions décodées qui a également lavantage de réduire la consommation puisque la logique de décodage pourra se reposer plus souvent. Il est question dun hit rate de 80%, ce qui veut donc dire que la plupart du temps Sandy Bridge pourra débiter plus de uops que Nehalem/Westmere, tout en faisant des économies dénergie. Enfin, lunité de prédiction de branchement est annoncée comme ayant été entièrement revue avec un historique plus long et une identification plus fine des branches à conserver.
Sandy Bridge : le cacheUne nouvelle structure de mémoire cache a été mise en place pour pouvoir en faire profiter la partie graphique, mais également pour la rendre plus modulaire. Intel ne parle dailleurs plus de cache L3 mais bien de Last Level Cache, puisque du point de vue graphique le cache nest pas au même niveau que du point de vue des cores CPUs. Cette appellation permet déviter toute ambigüité à ce niveau.
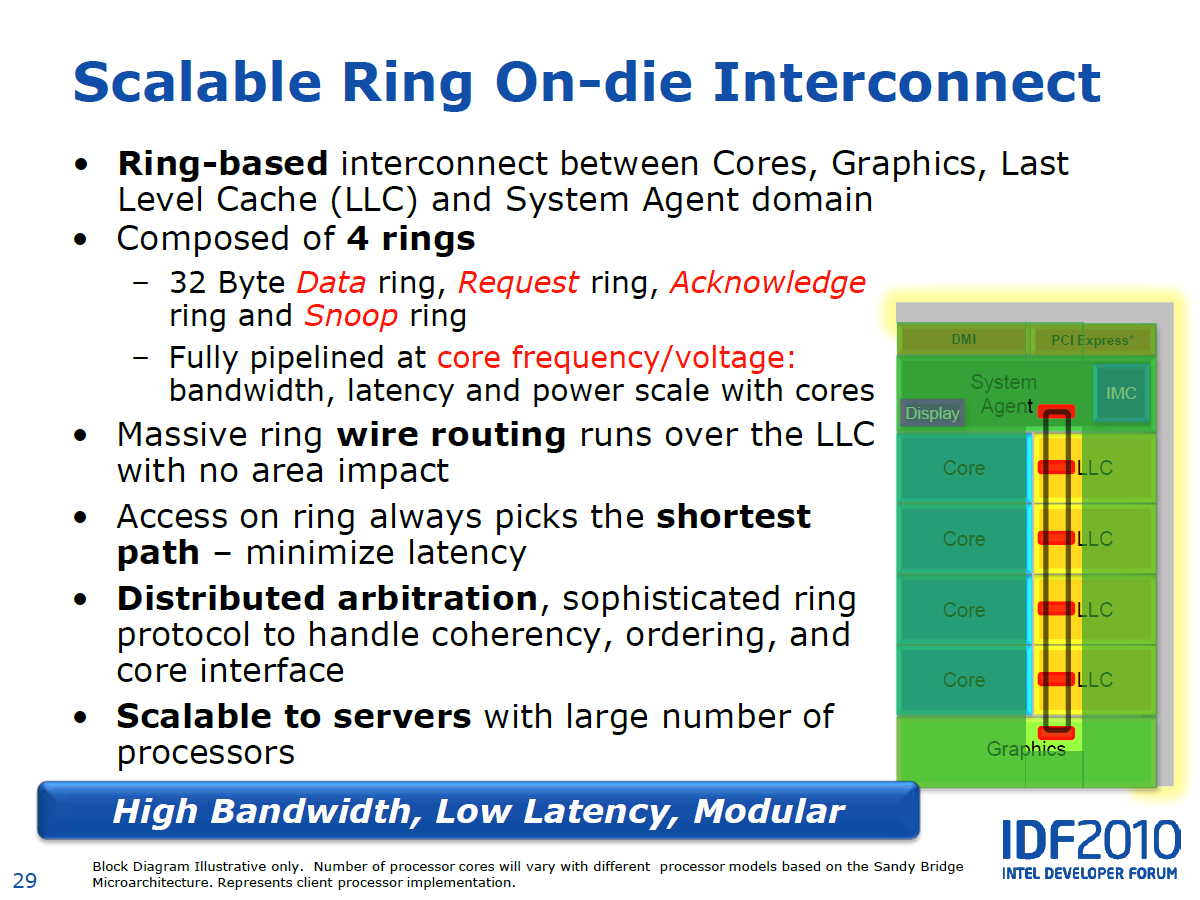
Ce LLC est segmenté en morceaux de 2 Mo par core CPU. Un ring bus se charge de connecter tous les segments entre eux ainsi que le contrôleur graphique et le System Agent par lequel laccès au contrôleur mémoire se fait. Intel précise que ce ring bus a lavantage de ne pas augmenter la taille du die puisquil est câblé par-dessus le LLC. Notez quil sagit en réalité dun quadruple ring bus : bus de 256 bits pour les données + request bus + acknowledge bus + snoop bus.
Au niveau de son implémentation, vous pouvez remarquer sur le schéma quau lieu de mettre en place un ring bus bidirectionnel, Intel le fait passer deux fois par segment de cache et donc par core. La partie graphique dispose également de deux accès au ring bus, mais le Systen Agent se contente dun seul. Cette architecture permet de limiter la latence de transmission, le chemin le plus court est toujours emprunté, sans avoir recours à la lourdeur dun bus bidirectionnel. Cest le core graphique qui est situé à lopposé du contrôleur mémoire puisque en cas de cache miss, il est le moins sensible à la latence des accès en mémoire centrale.

La latence lors de laccès au LLC pourra varier suivant où linformation se trouve puisque chaque étape dans le ring bus nécessite 1 cycle. Le LLC fonctionne à la même fréquence que les cores de Sandy Bridge, contrairement à larchitecture actuelle.
Sommaire
1 - Intel, solution provider
2 - Atom : de nouveaux SoCs
3 - Atom : AppUp, TVs
4 - Sandy Bridge : les cores, le cache
2 - Atom : de nouveaux SoCs
3 - Atom : AppUp, TVs
4 - Sandy Bridge : les cores, le cache
Vos réactions
Contenus relatifs
- [+] 05/04: Pas de MAJ Microcode pour les Gulft...
- [+] 09/11: Raja Koduri chez Intel avec l'ambit...
- [+] 24/07: Pas de Windows 10 CU pour Clover Tr...
- [+] 13/12: Influence du PCIe sur une GTX 1080
- [+] 25/10: Nouveaux Goldmont IoT/PC portable c...
- [+] 29/09: Carte mère Apollo Lake chez Asus
- [+] 08/04: GTC: Tesla P100: débits PCIe et NVL...
- [+] 08/04: Airmont 64% plus petit que Silvermo...
- [+] 02/03: Atom x3, 1ers SoC Intel avec modem ...
- [+] 26/02: Intel Atom x3, x5 et x7