
DirectX 10 et GPUs
Publié le 07/07/2006 par Damien Triolet



Les GPUsPour ATI et Nvidia, DirectX 10 est une évolution majeure et tous deux sont très enthousiastes par rapport aux nouvelles possibilités qui vont faire leur apparition. Nous avons pu avoir le point de vue des 2 fabricants et à une nuance près, ils sont identiques. Ils sont contents des optimisations internes à lAPI qui réduisent la consommation CPU et vont permettre pour une utilisation CPU identique daugmenter la complexité de la scène ainsi que de lévolution du pipeline graphique qui était resté figé depuis très longtemps. Les geometry shaders et le stream output ouvrent de nouvelles portes. Point de divergence : lunification de larchitecture du GPU au niveau des unités de calcul. Selon ATI cest la meilleure solution, selon Nvidia ça ne lest pas encore. Voici une représentation basique des architectures que nous nous attendons à retrouver chez Nvidia et chez ATI :
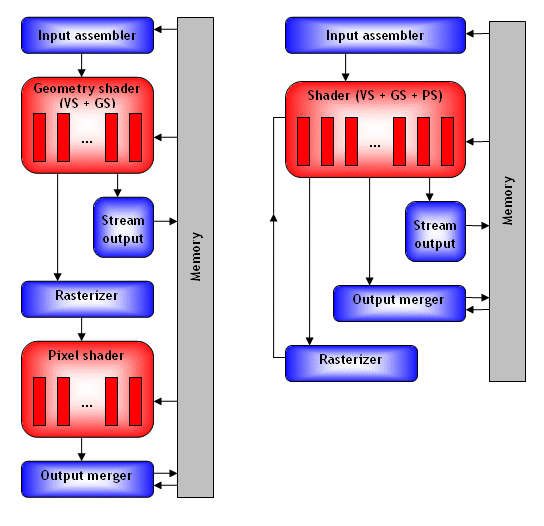
A gauche limplémentation de Direct 3D 10 supposée des G8x, à droite limplémentation de Direct 3D 10 supposée des R6xx.
Bien que les fabricants de GPU aiment bien parler darchitecture complètement nouvelle, développée à partir de zéro etc., il sagit toujours dévolutions. Développer un GPU est complexe et pour obtenir un bon rendement demande tout un tas de petites optimisations, destinées à arrondir les coins, à sassurer que le flux de données et dopérations ne soit pas interrompu. Cela demande une expertise très importante quATI et Nvidia ont acquise au fil du temps et qui a manqué à de nombreux concurrents potentiels comme XGI, S3 et Matrox qui se sont cassé les dents sur le rendement de leurs GPUs. Pour ATI et Nvidia il est bien entendu hors de question dabandonner cette expertise et donc davancer dans une direction qui représenterait une rupture complète avec les architectures précédentes.
Du côté dATI, passer à une architecture unifiée au niveau des unités dexécution (= de traitement des shaders) est une évolution logique, dans la continuité des architectures précédentes et actuelles. Une architecture unifiée demande une gestion avancée des différents threads (tâches) or les Radeon X1000 en disposent déjà bien que cela soit limité aux pixel shaders. Une architecture unifiée permet de pouvoir attribuer les unités dexécution aux tâches qui en ont besoin et de ne pas avoir dunité qui se tourne les pouces. Autrement dit cela améliore le rendement par unité dexécution. Notez quATI dispose déjà dune expérience avec une architecture unifiée puisque le GPU qui est au cur de la Xbox 360 en est une.
Du côté de Nvidia, la situation est différente puisque lefficacité du calcul des pixels provient dun très long pipeline dans lequel laccès aux textures est masqué. Passer directement dune telle architecture à une architecture unifiée représenterait un gros risque qui pourrait amener à une baisse importante du rendement. Qui plus est, larchitecture actuelle de Nvidia est relativement économe au niveau de la taille de la puce alors que larchitecture actuelle dATI est très gourmande. Ne pas unifier son architecture avec les G8x permet donc à Nvidia dassurer un bon rendement et de ne pas faire exploser dans de trop grandes proportions le nombre de transistors. Nous nous attendons donc à ce que les G8x et donc le G80 (anciennement NV50), son premier représentant, ne soit pas unifiée tout du moins complètement.
Bien que Direct 3D 10 définisse un jeu dopérations similaire pour tous les types de shaders, de légères différences subsistent (seuls les geometry shader peuvent créer des éléments par exemple) et chaque type de shader est amené à traiter des tâches qui ont un profil différents. Optimiser une même unité dexécution pour un vertex shader ou pour un pixel shader mène dans des directions différentes. Ces directions ne sont cependant pas si différentes lune de lautre lorsquil sagit de geometry shaders et de vertex shaders, ce qui nous amène à penser que Nvidia aurait mis en place une unification partielle de son architecture au niveau de leurs unités de traitement quils partageraient donc. Les pixels shaders conserveraient pour leur part des unités dédiées, améliorées pour supporter les spécificités de DirectX 10. Avec ce compromis, Nvidia intègre le support de DirectX 10 en conservant un bon rendement par mm².
Quelle sera la meilleure solution ?Il est encore trop tôt pour se prononcer bien entendu. Nvidia devrait sortir son G80 en premier lieu, alors que DirectX 10 ne devrait pas encore être utilisable dautant plus que son support ne sera probablement pas activé directement dans les drivers. Du côté dATI, le R6xx arrivera vraisemblablement avec un support DirectX 10 puisque nous estimons quil sera très facile de montrer un avantage dune architecture unifiée dans différents cas théoriques. ATI ne devrait donc pas sen priver, avec raison dailleurs. Reste que ces cas théoriques ne représenteront peut-être pas la pratique, ou tout du moins pas avant un certain temps.
 Dans les jeux DirectX 9 et les premiers jeux DirectX 10 (que Microsoft annonce pour larrivée de celui-ci) que feront tourner ces cartes, le G80 devrait se comporter comme un GeForce 7900 avec plus dunités de calcul et le R6xx comme une Radeon X1900 plus efficace (ATI parle de 25% de gain dans certains jeux à nombre dunités de calcul égal entre une architecture classique et unifiée), ce qui ne vous apprend rien en dehors du fait quil est trop tôt pour savoir qui des 2 lemportera. Les fréquences auront comme à chaque fois leur mot à dire et Nvidia ne devrait pas laisser de côté une éventuelle double carte comme la GeForce 7950 GX2.
Dans les jeux DirectX 9 et les premiers jeux DirectX 10 (que Microsoft annonce pour larrivée de celui-ci) que feront tourner ces cartes, le G80 devrait se comporter comme un GeForce 7900 avec plus dunités de calcul et le R6xx comme une Radeon X1900 plus efficace (ATI parle de 25% de gain dans certains jeux à nombre dunités de calcul égal entre une architecture classique et unifiée), ce qui ne vous apprend rien en dehors du fait quil est trop tôt pour savoir qui des 2 lemportera. Les fréquences auront comme à chaque fois leur mot à dire et Nvidia ne devrait pas laisser de côté une éventuelle double carte comme la GeForce 7950 GX2.Les architectures dATI et Nvidia seront valables pour toute une gamme de GPUs et ce nest pas parce quune architecture sera la plus efficace sur le haut de gamme que ce sera vrai sur lentrée et le milieu de gamme.
Notez que lorsquon parle du rendement par mm² chez Nvidia il sagit dune grosse simplification, admise parce que la différence est énorme entre les puces ATI et Nvidia actuelles. En pratique la taille de la puce nest quun des éléments qui définit le rendement par mm² (de wafer). La fréquence utilisée en est un autre. Si un fabricant est obligé dutiliser une très haute fréquence pour concurrencer le concurrent, il réduit le nombre de puces qui sont utilisables et donc le rendement par mm² de wafer. Une architecture peut offrir plus dopportunités quune autre pour y intégrer de la redondance, ce qui réduit le nombre de puces inutilisables et donc augmente le rendement par wafer. Une puce plus grosse peut ainsi au final offrir un meilleur rendement quune plus petite.
Vous laurez probablement compris, nous nous attendons à ce que Nvidia mette en avant la petite taille de sa puce (ainsi que la consommation) et quATI fasse lapologie dune architecture unifiée. Comme dhabitude il sagira de simplifications marketing et il faudra prendre un peu de recul pour se faire une opinion plus pertinente. Pour terminer, les développeurs auront eux aussi leur mot à dire puisque leurs choix technologiques pourront mettre en avant ou pas une certaine architecture.
A lire également




Vos réactions
Contenus relatifs
- [+] 04/05: Nvidia abandonne son GeForce Partne...
- [+] 27/04: AMD Vega 7nm en labo, Zen 2 échanti...
- [+] 18/04: ASUS AREZ, l'effet GeForce Partner ...
- [+] 10/04: Nvidia : fin du support Fermi et 32...
- [+] 27/03: Pilotes Radeon et GeForce pour Far ...
- [+] 20/03: Pilotes GeForce 391.24 pour Sea of ...
- [+] 20/03: Microsoft annonce DirectX Raytracin...
- [+] 20/03: Radeon Software 18.3.3 beta avec Vu...
- [+] 08/03: 3 millions de GPU vendus pour le mi...
- [+] 08/03: Radeon Software 18.3.1 optimisé pou...