
Les derniers contenus liés aux tags Volta et NVLink
Les 2 contenus de cette page
IBM Power9 et Nvidia Volta : 100+ petaFlops en 2017
GTC: Nvidia annonce Pascal: NVLink, stacked DRAM, 2016
IBM Power9 et Nvidia Volta : 100+ petaFlops en 2017
Publié le 02/12/2014 à 17:15 par Damien Triolet



Le département de l'énergie américain a tranché il y a quelques jours : les prochains supercalculateurs qu'il finance seront mis en place par IBM sur base d'une plateforme OpenPower équipée de ses futurs CPU Power9 et des GPU Volta de Nvidia associés via l'interconnexion NVLink.

Cinq années, cela semble être la durée de vie des supercalculateurs pour lesquels le département de l'énergie américain (DoE) met la main à la poche. Délivré mi-2012 sur base d'une plateforme IBM Blue Gene/Q et de CPU Power8 à l'administration nationale pour la sécurité nucléaire, Sequoia et ses 20 petaFlops (17 petaFlops mesurés) prendra sa retraite en 2017. Il en ira de même pour le supercalculateur Titan exploité par le laboratoire national d'Oak Ridge qui affiche 27 petaFlops au compteur (17.5 petaFlops mesurés). Pour rappel, ce dernier est basé sur une plateforme Cray XK7 équipée d'Opteron 6274 et d'accélérateurs Tesla K20X.
La course à la puissance ne s'arrête jamais, d'autant plus que la Chine a volé la première place du podium aux Etats-Unis avec Tianhe-2, une plateforme 100% Intel qui affiche 55 petaFlops au compteur (34 petaFlops mesurés) à travers ses Xeon E5-2692 et ses Xeon Phi 31S1P. Si ce dernier est plus performant, à noter cependant que sa consommation explose pour atteindre près de 18 mégawatts là où les actuels supercalculateurs américains se contentent de 8 à 9 mégawatts.
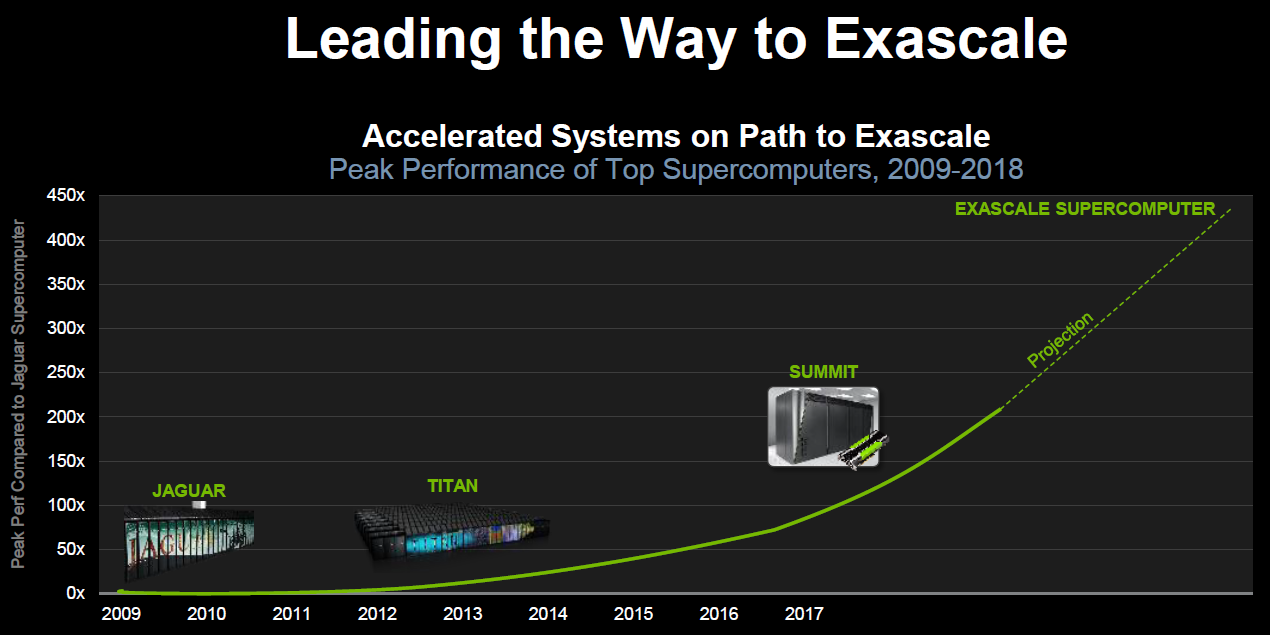
Ce détail est en fait très important. Nul doute en effet que le cahier des charges du DoE pour ses futurs supercalculateurs, baptisés Sierra et Summit, exigeait de ne pas trop augmenter le budget énergétique de ses futures installations, en plus bien entendu de pousser la puissance de calcul vers le haut en attendant l'arrivée des systèmes exaFlops, prévus pour la génération suivante.
Pour les deux systèmes, une même plateforme de plus de 100 petaFlops a cette fois été retenue et c'est IBM qui a reçu ce contrat de 325 millions de $. La plateforme proposée par IBM a pour particularité de s'efforcer de rapprocher les données de la puissance de calcul pour réduire les déplacements coûteux tant en performances qu'en énergie. Un argument important à l'heure où la quantité de données à traiter explose.
Alors que l'actuel Sequoia était de type 100% CPU IBM, le DoE a favorisé une solution hétérogène, étant visiblement satisfait des résultats du Titan, et a renouvelé sa confiance dans les GPU Nvidia et l'écosystème CUDA. Une étape cruciale pour Nvidia qui voit donc sa place de fournisseur de puissance de calcul confirmée sur un marché dans lequel il est difficile de percer.

Les raisons du choix du couple IBM/Nvidia sont bien entendu nombreuses et ne sont pas dues au hasard. Les deux acteurs travaillent ensemble depuis quelques temps déjà, Nvidia ayant annoncé en mars dernier une interconnexion NVLink développée en partenariat avec IBM. Pour rappel, celle-ci permet de s'affranchir du PCI Express et de ses limitations pour proposer une voie de communication plus performante entre les GPU mais également entre les GPU et les CPU. Cela implique des changements importants, notamment au niveau du format physique qui passera à un socket de type mezzanine.
Ce support de NVLink est une évolution logique du côté d'IBM qui propose déjà sur ses CPU Power8 une interface CAPI (Coherent Accelerator Processor Interface) dédiée au support d'accélérateurs spécifiques basés sur des modules FPGA interconnectés en PCI Express. De toute évidence IBM a étendu l'interface CAPI de manière à y intégrer le support de NVLink mais les spécificités à ce niveau restent inconnues.
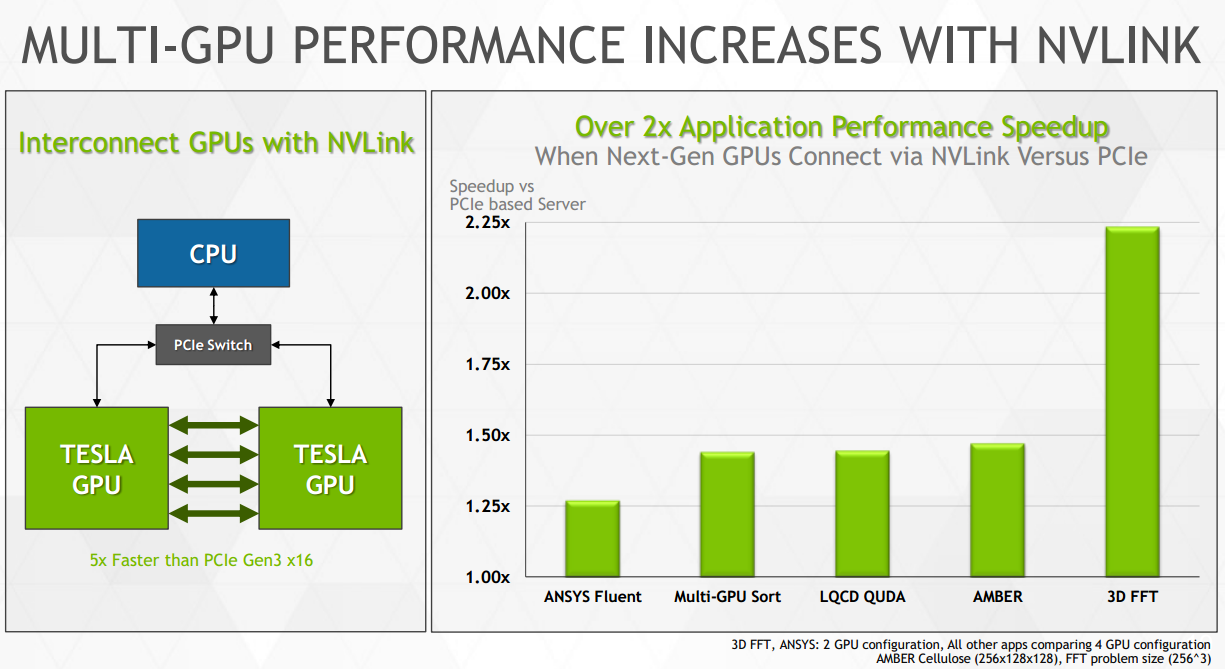
Chaque lien NVLink est constitué d'un certain nombre de couples de lignes point-à-point et dans le cas de la première version de NVLink il est question d'une bande passante de 20 Go/s par lien (16 Go/s effectifs). Nvidia prend pour exemple un GPU équipé de 4 de ces liens qui pourrait ainsi profiter au total de 64 Go/s pour ses voies de communications vers les autres GPU et vers le CPU auquel il est rattaché, contre seulement 12 Go/s en PCI Express 3.0. De quoi booster les performances sur certains algorithmes : dans sa documentation Nvidia met en avant des projections avec +20% à +400% de mieux suivant les algorithmes observés.
Toujours au niveau de la mémoire, avec Volta, chaque GPU pourra alors être équipé d'une quantité importante de mémoire haute performances grâce à la technologie HBM. Pas question cependant de tester tout cela lors de la mise en place de ces supercalculateurs, ces technologies devront être éprouvées avant. C'est ce qu'a prévu Nvidia. En 2016, le GPU Pascal sera le premier à supporter NVLink, la mémoire HBM et le nouveau format. De quoi être prêt pour 2017 et le GPU Volta qui profitera de la version 2.0 de NVLink dont l'évolution principale sera la possibilité de supporter un espace mémoire totalement cohérent entre le ou les CPU et le ou les GPU. Pour en profiter une bande passante élevée sera nécessaire, elle pourra monter jusqu'à 200 Go/s à travers l'ensemble des liens NVLink (5 liens à 40 Go/s ?). De quoi permettre de revoir en profondeur l'architecture des supercalculateurs.
Alors que Titan par exemple est un ensemble de 18688 nuds équipés chacun d'un Opteron 16 curs avec 32 Go de DDR3 et d'une Tesla K20X avec 6 Go de GDDR5, Sierra et Summit se contenteront de beaucoup moins de nuds mais bien plus costauds et chacun équipé d'une zone de stockage locale.
Les informations concernant Sierra restent actuellement limitées, puisqu'il remplacera Sequoia dans le domaine sensible de la sécurité nucléaire. Par contre plus de détails ont été communiqués au sujet de Summit, qui remplacera Titan avec une puissance de calcul théorique qui se situera entre 150 et 300 petaFlops pour une consommation qui ne devrait augmenter que de 10% alors que l'encombrement sera nettement réduit.
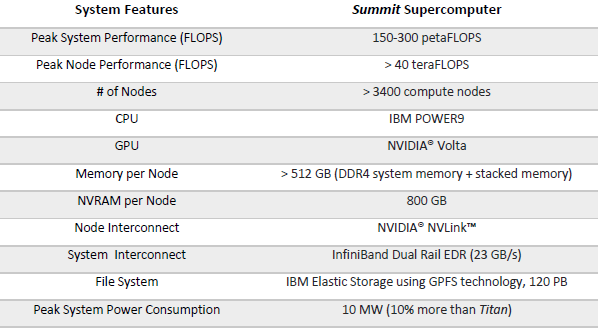
Summit sera constitué de plus de 3400 nuds, chacun présenté avec une puissance de calcul théorique de plus de 40 teraFlops (probablement bien plus puisque cela ne représente que 136 petaFlops). Chacun de ces nuds sera équipé de plusieurs CPU Power9 et de plusieurs accélérateurs Tesla dérivés du GPU Volta. Nous pouvons raisonnablement supposer qu'il s'agira de 4 à 8 composants de chaque type par nud. Ils seront accompagnés par un ensemble de plus de 512 Go de mémoire DDR4 (côté CPU) et HBM (côté GPU) qui formeront un seul et unique espace cohérent, même si les accès mémoire resteront optimisés pour des usages différents de part et d'autre. Par ailleurs 800 Go supplémentaires de mémoire flash seront installés, de quoi par exemple faire office de buffer pour le système de stockage de 120 petaOctets qui devra se "contenter" d'une bande passante de 1 To/s.
Ce type de contrat est très important en terme d'image de marque pour un acteur tel que Nvidia, mais il lui restera à démontrer de l'intérêt, en pratique, d'une plateforme basée autour de NVLink dans les plus petits systèmes qui représentent le gros du marché. Si seul le Power9 d'IBM et le Volta de Nvidia supportent NVLink, ils resteront dépendants l'un de l'autre pour être exploités au maximum de leurs capacités. Un pari risqué ? Sans commenter le fond de cette question, Nvidia précise qu'un petit ensemble de 4 nuds similaires à ceux développés par IBM pour Summit suffirait à placer la machine dans la liste Top500 des supercalculateurs actuels.
Pour en savoir plus, vous pourrez retrouver deux whitepapers chez Nvidia , l'un tourné autour de ces supercalculateurs, l'autre autour de NVLink et de ses promesses (sans prendre en compte le support CPU).
GTC: Nvidia annonce Pascal: NVLink, stacked DRAM, 2016
Publié le 25/03/2014 à 18:20 par Damien Triolet
Le forum technologique GTC de Nvidia commence fort avec l'annonce du successeur de Maxwell. Prénommé Pascal et prévu pour 2016, ce GPU intégrera une nouvelle technologie d'interconnexion, NVLink, ainsi que le support de la mémoire 3D.

Jen Hsun Huang, le CEO de Nvidia présente le premier prototype du GPU Pascal.
L'an passé, Nvidia nous avait présenté une roadmap qui mettait en avant l'arrivée des GPU Maxwell en 2014, nous y sommes, ainsi que des GPU Volta en 2016. Pour Maxwell, Nvidia mentionnait alors le support de la mémoire unifiée et pour Volta de la mémoire 3D ou stacked DRAM, qui consiste à empiler plusieurs puces mémoire pour former un module dont la bande passante va exploser.
A noter que dans ces présentations, le nom de l'architecture ou de la génération représente toujours le plus gros GPU de la famille. La nouvelle roadmap de Nvidia est quelque peu différente :

DirectX 12 est rentré dans l'air du temps et dorénavant mis en avant comme le point de communication principal pour la génération Maxwell. Etrangement la mémoire unifiée passe vers la génération suivante qui change de nom. Exit Alessandro Volta, bonjour Blaise Pascal. La génération Volta a en réalité été repoussée et une génération intermédiaire introduite. Avec Pascal, Nvidia entend s'attaquer aux goulets d'étranglements des GPU actuels, au moins sur 2 fronts.

Tout comme cela était mis en avant pour Volta, Pascal bénéficie du DRAM stacking pour faire exploser la bande passante de sa mémoire locale. Nvidia précise avoir recours à la technique "3D chip-on-wafer integration" et estimer pouvoir atteindre une bande passante de 1 To par seconde en 2016. La quantité de mémoire pourra également progresser significativement, il est question de 2.5x plus de mémoire qu'aujourd'hui, soit probablement 10 Go dans le cas des GeForce et près de 30 Go dans le cas des cartes professionnelles. Tout ceci se ferait avec une progression de 4x de l'efficacité énergétique liée à la mémoire et à son interface.

L'autre point sur lequel Nvidia travaille pour Pascal est l'interconnexion. Le bus PCI Express représente une limitation importante au niveau de la communication avec le CPU et entre GPU. Dans le cas d'une utilisation grand public, ce n'est pas un problème, mais cela peut le devenir dans d'autres situations liées au GPU computing.
Pour contourner ce problème et avoir le contrôle de sa propre interconnexion, Nvidia a mis au point NVLink. Il s'agit d'un bus de communication dont les protocoles sont annoncés similaires à ceux du PCI Express, prévus pour la mémoire unifiée et la cohérence des caches dès la génération 2.0, probablement pour le successeur de Pascal. NVLink pourra offrir 5 à 12X la bande passante du PCI Express, probablement avec une latence réduite. Dans un sens, NVLink peut être vu commme une version musclée et plus flexible du lien SLI.
NVLink pourra être implémenté pour la communication entre GPU, le schéma de Nvidia indique qu'au moins 4 GPU pourront ainsi disposer d'une connexion directe. Il sera également possible d'utiliser NVLink pour offrir au GPU un accès plus performant au CPU. Nvidia précise d'ailleurs avoir collaboré avec IBM lors du développement du NVLink et que ce dernier sera implémenté dans de futurs CPU POWER. Nous pouvons également raisonnablement estimer que Nvidia proposera ce support sur ses futurs SoC/CPU dérivés de ses propres cores ARMv8 Denver. Il est par contre improbable qu'Intel propose un jour une connexion NVLink sur ses Xeon.

Pour terminer, Nvidia indique déjà disposer dans ses labos des premiers prototypes de Pascal. Une plateforme relativement compacte dont nous ne savons cependant pas si elle est réellement fonctionnelle. Nous pouvons y apercevoir 4 modules de stacked DRAM et Nvidia précise que cette carte Pascal lui permet de travailler sur NVLink. Sur la face avant du PCB, aucune interconnexion n'est cependant visible, celle-ci étant probablement au dos. Rien ne dit cependant que c'est ce format qui sera retenu pour la version commerciale de Pascal.
La guerre s'annonce rude entre Pascal et les futurs Xeon Phi !
Les 2 contenus de cette page