| |
| |
| Intel Technology and Manufacturing Day 2017 Processeurs Publié le Mercredi 29 Mars 2017 par Guillaume Louel URL: /focus/116/.html Intel tenait aujourd'hui son « Technology and Manufacturing Day », l'occasion d'apporter quelques détails sur ses process actuels et à venir. Cette présentation se fait dans un contexte assez compliqué pour le constructeur sur un sujet qu'il dominait pourtant assez largement il y a encore quelques années. On se souvient en effet qu'Intel a accumulé les retards sur son 14nm, une situation qui ne s'est pas arrangée puisque le 10nm a lui aussi été retardé l'année dernière, nous valant un stepping/speed bump de Skylake renommé en Kaby Lake pour cacher la situation. 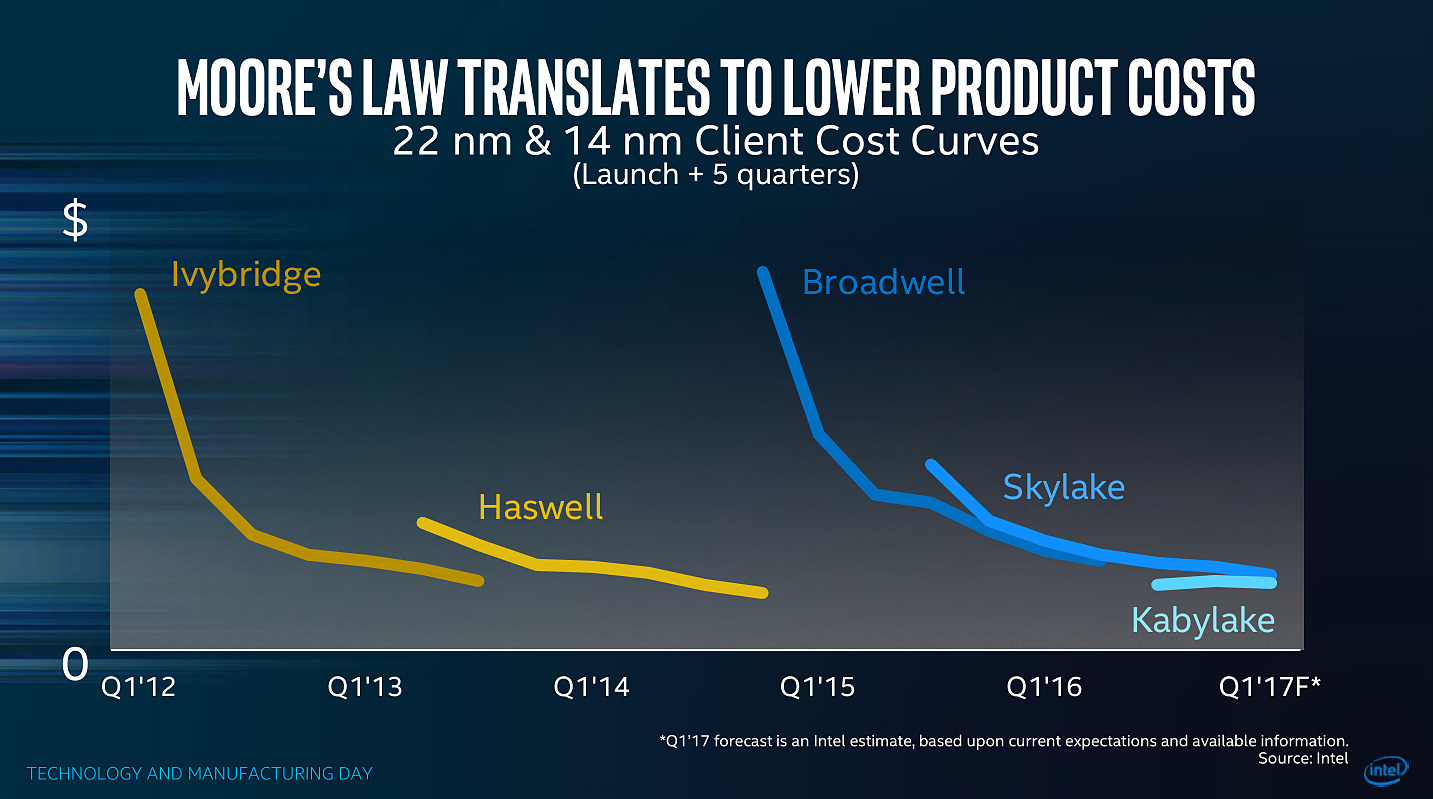 Les couts de fabrication de Kaby Lake sont particulièrement bas pour Intel, ce qui n'est pas surprenant même si cela ne se traduit pas sur les prix publics ! Et les roadmaps du constructeur qui avaient filtrées jusqu'ici ne donnaient pas forcément confiance dans ce 10nm qui ne serait lancé que fin 2017, uniquement sur des puces mobiles deux coeurs (les 5/15W), tandis qu'en 2018 on aurait droit à (enfin !) jusque 6 coeurs, mais toujours fabriqués en 14nm avec Coffee Lake. Cette situation s'accompagne d'un climat concurrentiel encore plus compliqué pour Intel. Le constructeur a construit son avance sur la particularité de son business : un nombre limité de puces différentes qui se transforment en de multiples produits, le tout en grand volume sur un marché en forte croissance, celui du PC. Aujourd'hui le marché du PC, bien qu'encore large, continue de reculer pour la cinquième année consécutive. Pour compenser le déclin du marché du PC, et d'aucuns diront pour l'aider à mieux utiliser la capacité de ses usines, le constructeur a lancé une activité « Custom Foundry » avec un petit nombre de clients (même si Intel a racheté son client principal, Altera, prenant même une licence ARM pour le 10nm. S'ajoute à ce problème la montée en puissance du marché des smartphones qu'Intel a jusqu'ici totalement raté, tenant d'y imposer l'architecture x86 là où ARM domine sans débat possible. Au-delà d'avoir raté un marché, le véritable problème pour Intel est que ce sont les acteurs de ce nouveau marché qui financent très fortement les fondeurs concurrents (Qualcomm et plus particulièrement Apple ont largement financés les avancées récentes de TSMC, Samsung étant présent des deux côtés de l'équation). 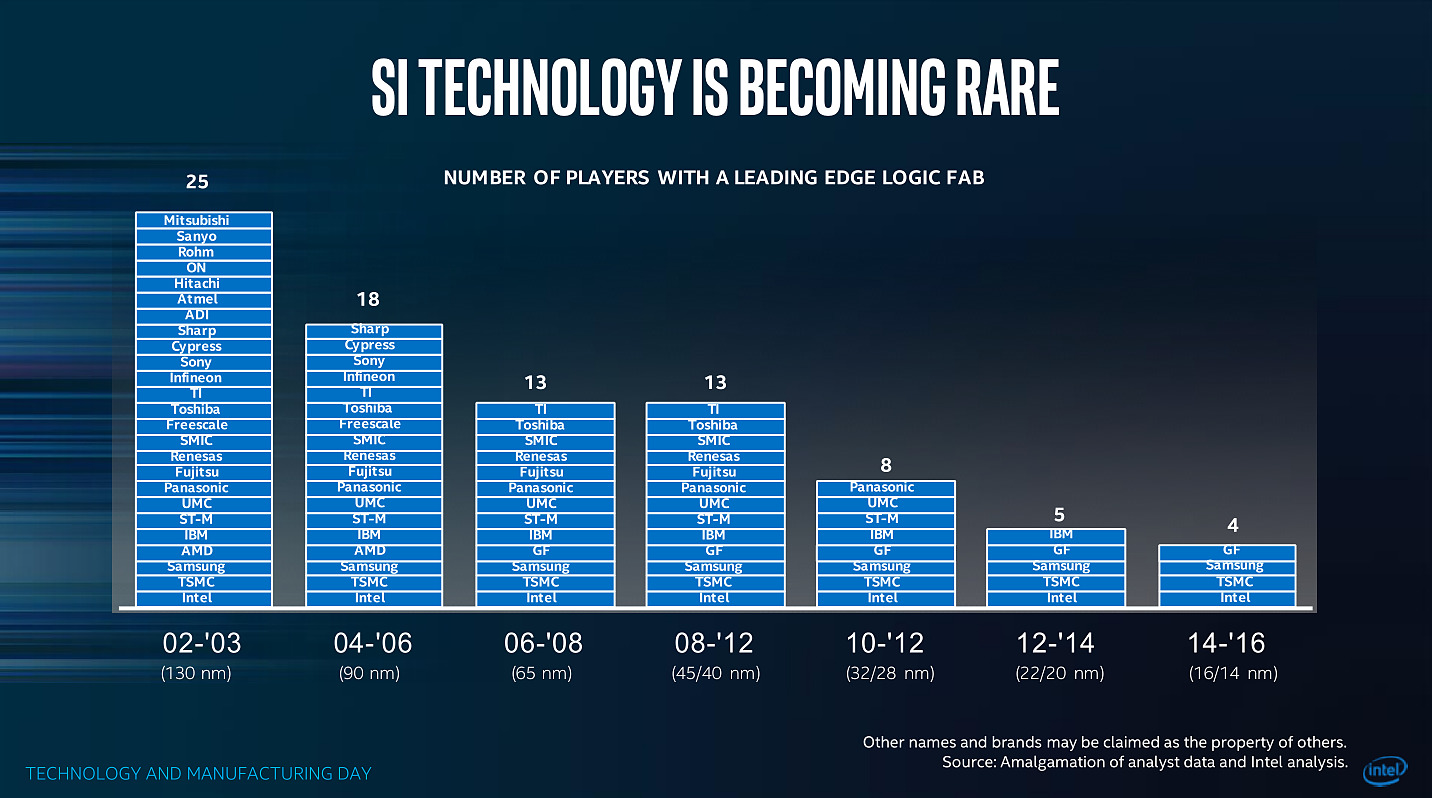 Le nombre d'acteurs dans le marché des semi conducteurs ne fait que diminuer au fil des années, certains d'entre eux n'apprécieront peut être pas de ne plus être considérés comme "leading edge" Au point que et TSMC, et Samsung ont lancé la production en volume d'un process plus dense que ce que propose aujourd'hui Intel (leurs 10nm), TSMC passant même la semaine dernière symboliquement devant Intel en terme de capitalisation boursière . Il est important de garder en tête tout ce contexte pour juger précisément ce qu'a annoncé Intel aujourd'hui. Une nouvelle formule pour calculer la densitéNous avons eu l'occasion d'évoquer le sujet maintes fois, les nomenclatures utilisées par les différents fondeurs ne sont pas comparables. Si autrefois tout le monde se basait sur les critères fournis par l'ITRS , l'absence de publication depuis 2013 fait que chacun interprète à sa manière la question. Il n'y a d'ailleurs pas de bonne ou de mauvaise méthode : depuis maintenant plusieurs années, toutes les parties composantes d'une puce ne scalent plus à la même vitesse, poussant à des équivalences de plus en plus complexes. En pratique il n'y a d'ailleurs pas de formule simple pour calculer et comparer la densité des process, tant le sujet est compliqué. Intel avait utilisé une formule simpliste, et assez problématique qui avait donné cet assez peu honnête graphique : 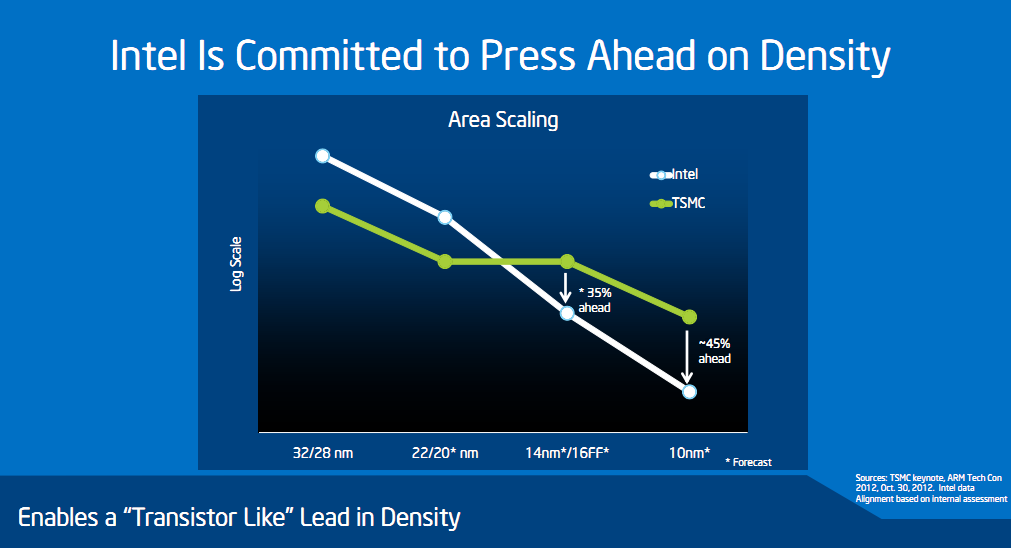 Intel estimait via la formule qu'ils utilisaient que le 20nm et le 16nm de TSMC avaient strictement la même densité, une attaque rare envers la concurrence de la part de la firme de Santa Clara. Une attaque qui avait valu une réponse aussi rare de TSMC. Si l'on rappelle cela, c'est parce qu'Intel réclame aujourd'hui que l'industrie se « standardise » autour d'une nouvelle formule pour exprimer la densité. On ne perdra pas de temps à analyser en détail la formule choisie par Intel : on peut prédire facilement qu'aucun autre constructeur ne l'utilisera. Il est surtout intéressant de décrypter le message qui accompagne cette formule : la métrique simpliste utilisée à l'époque ne permet pas de mesurer l'intégralité des gains de densité obtenus par les futurs process d'Intel. On ne doute pas que TSMC acquiescera ! Trois ans par node (ou un peu plus)Derrière la nouvelle formule, Intel tente d'expliquer que les gains de densité sont en réalité plus importants que ce qu'ils ne devraient être grâce à des innovations qui ne se limitent pas uniquement à de simples données techniques comme le pitch mesuré. En soit l'argument n'est pas faux, mais l'on ne peut pas s'empêcher d'y voir une manière de justifier le passage à un rythme de trois années entre deux nodes auprès des investisseurs, le tout accompagné d'un terme marketing, Hyper Scaling pour décrire la situation. 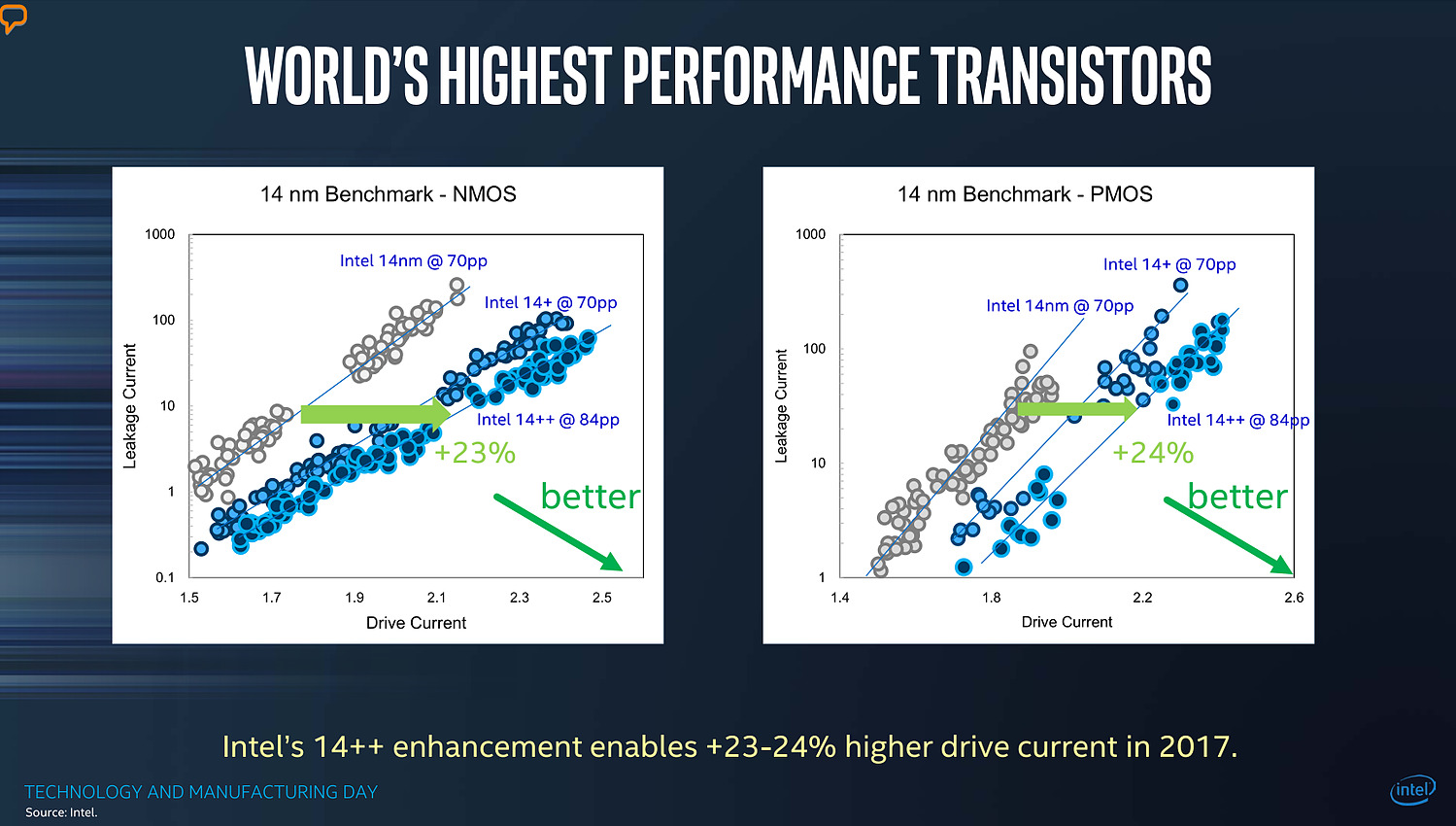 Le 14++ apporterait la possibilité d'augmenter la tension d'alimentation des transistors sans augmenter trop fortement les pertes dues au leakage En parallèle, Intel explique également qu'il fera désormais « vivre » ses nodes qui ne resteront plus figés. On en avait eu un bref aperçu avec Kaby Lake, annoncé comme utilisant un 14nm+. Il faudra compter sur trois versions successives du process qui apporteront des gains au niveau de la performance des transistors. Pour le 14nm, un 14nm++ devrait se retrouver dans des produits d'ici la fin de l'année, et pour le 10nm on aura également droit à des 10nm+ et 10nm++. Le parallèle avec ce que proposent ses concurrents qui multiplient les versions (TSMC a proposé quatre versions différentes de son 16nm, la dernière s'appelant... 12FFC !) est facile à réaliser, mais il faut rappeler qu'en tout temps, les fondeurs ont toujours optimisé en permanence leur process. Ce qui est nouveau - pour Intel et les autres - c'est que ces améliorations soient mises en avant si publiquement pour leurs clients et présentées comme de "nouveaux" process. 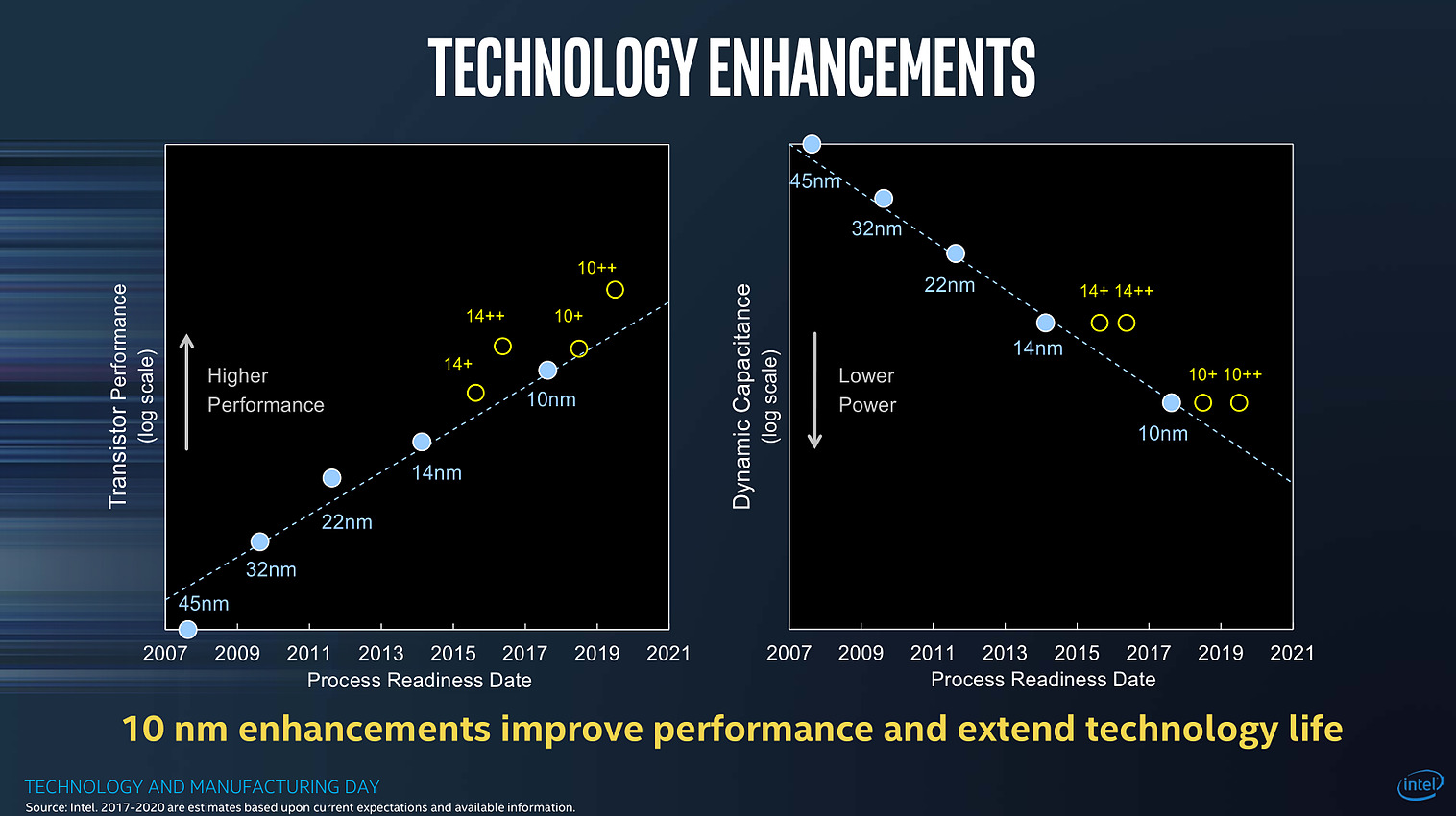 La notion de "performance" des transitors est relativement vague dans ce slide, mais l'on note que le "14++" est plus "performant" que le 10nm... Une grande partie du message d'Intel visait également à expliquer que les lancements de produits ne suivraient pas forcément les annonces de process, Intel se réservant la possibilité de choisir le node le plus approprié en fonction du produit, tout en souhaitant lancer une nouvelle génération par an. Ceci va a l'encontre du message habituel d'Intel, comme l'a fait remarquer un analyste financier durant une session de questions/réponses : faire avancer la loi de Moore et diminuer les coûts était historiquement la priorité. Cannon Lake et 8eme Gen CoreAu niveau des annonces de produit, Intel a confirmé que la monté en production de son 10nm se fera à la seconde moitié de l'année, et que le lancement de ses premiers produits (Cannon Lake) se fera au mieux à la toute fin 2017 ou au tout début 2018, soit un léger retard par rapport à ce qui était attendu jusqu'ici.  En parallèle, Intel lancera une 8ème génération de Core en 14nm dont on ne sait strictement rien pour l'instant, si ce n'est qu'elle apporterait des gains "supérieurs à 15%" sous Sysmark d'après Intel ce qui est peu optimiste s'il s'agit bien de Coffee Lake et ses 6 coeurs. On peut se demander si ces puces 14nm et Cannon Lake partageront l'appellation commerciale de 8eme génération, quelque chose que nous avons cru comprendre entre les lignes du discours des différents intervenants d'Intel. 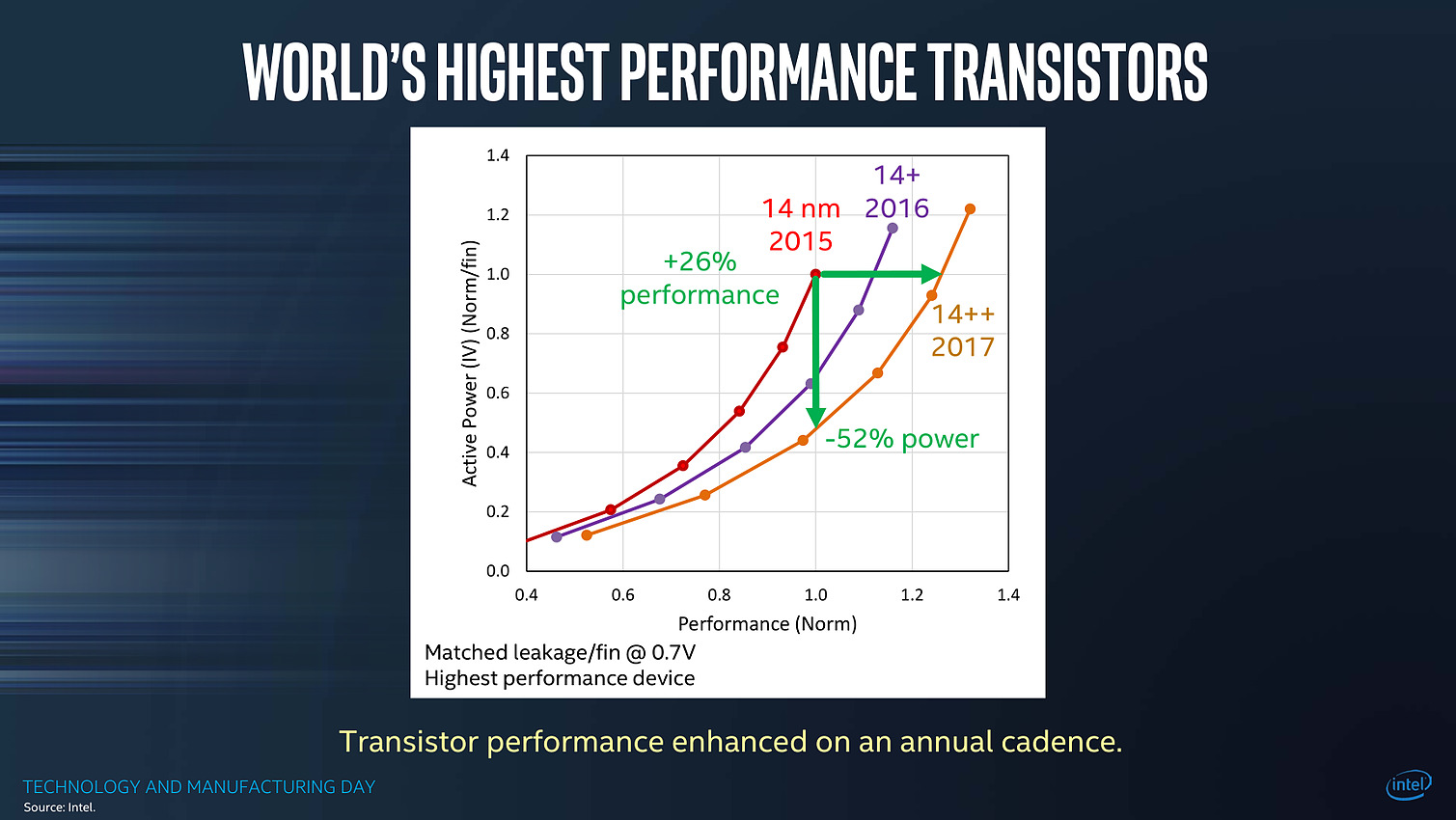 Le 14++ permettrait au choix de baisser la consommation de 52%, ou d'augmenter de 25% les performances par rapport à la première version du 14nm, il s'agit ici des performances individuelles des transistors FinFET et non des puces dans leur ensemble La notion de génération, basée sur le « tick tock » historiquement (puis sur le très éphémère « Process Architecture Optimization » qui n'a pas vécu une année) doit désormais être vue sous la forme de « vagues » annuelles de produits, qui utiliseront le process « le plus approprié ». Intel clarifiera certainement tout cela dans les prochains mois. Un 10nm un peu plus dense que prévu !Intel a présenté pour la première fois des détails concrets sur son process 10nm, et l'on a eu droit à une petite surprise. Il s'agira du troisième process FinFET du constructeur qui est annoncé avec un Gate Pitch de 54nm, et un Metal Pitch de 36nm ! 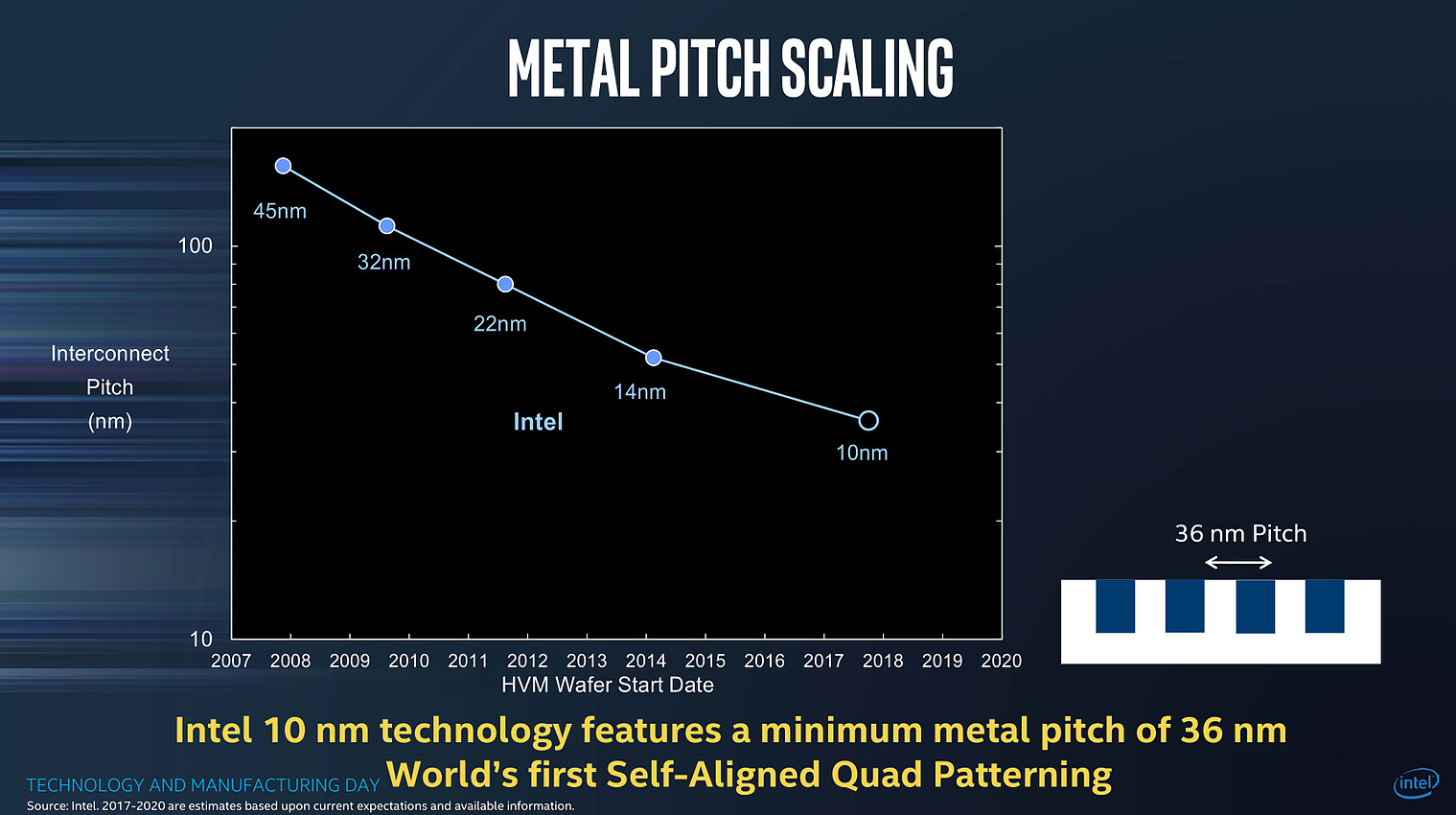 C'est une petite surprise, les estimations jusqu'ici considéraient bien un Gate Pitch de 54nm, mais plutôt un Metal Pitch de 40nm. Pour comprendre l'importance de cette valeur, on peut reprendre ce schéma proposé sur le blog SemiWiki : 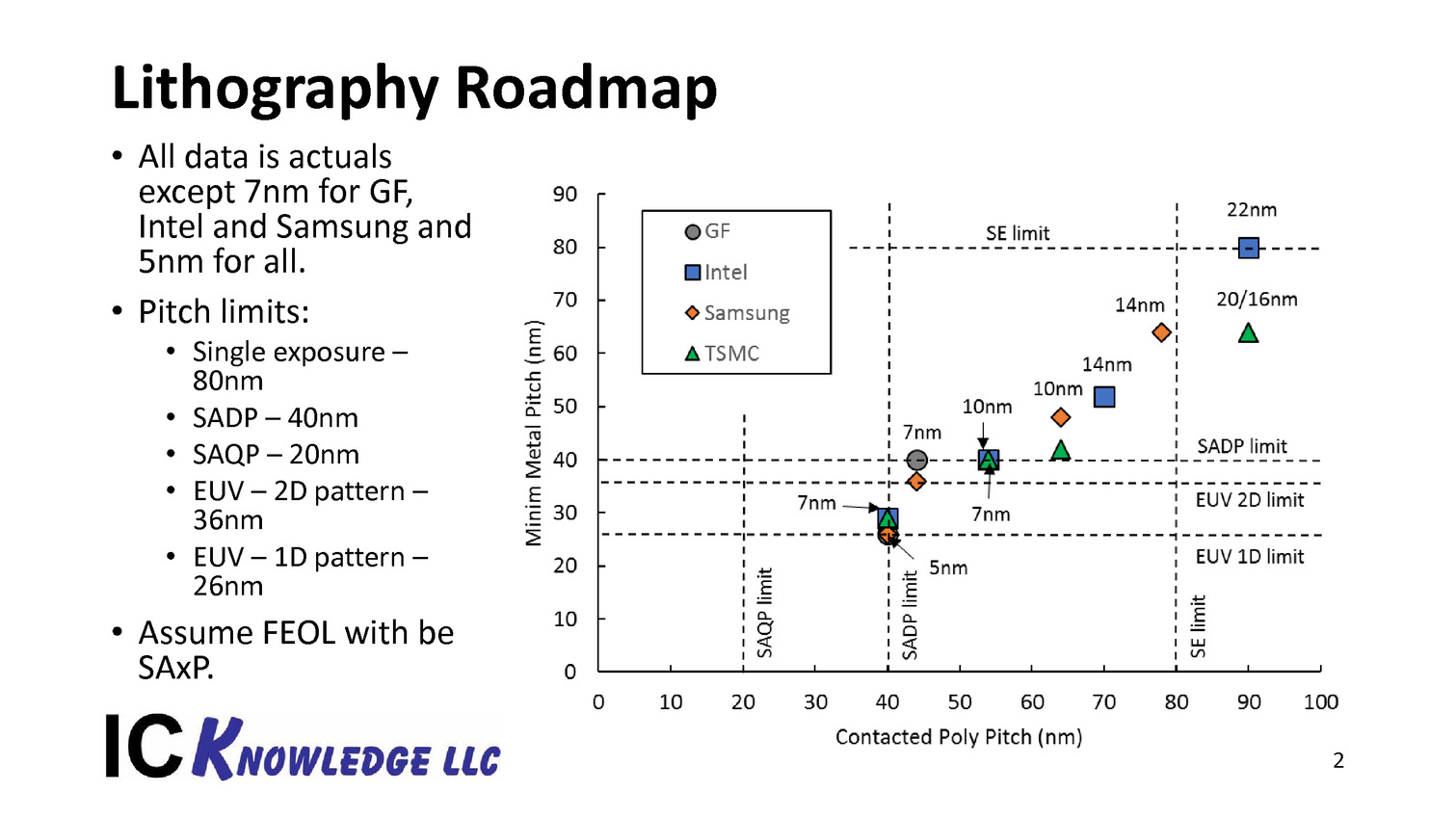 Ce schéma estimait encore à 40nm le Metal Pitch pour le 10nm d'Intel 40nm est la limite du SADP (Self-Aligned Double Patterning, réaliser deux expositions au lieu d'une, une image grossière serait de dire qu'il s'agit de l'équivalent de passer deux fois une même feuille dans une photocopieuse dont le toner est quasi vide pour rendre l'image plus « foncée » au risque qu'elle soit un peu plus floue), et TSMC par exemple restera en SADP pour son futur 7nm (prévu pour l'année prochaine) en se limitant à 40nm pour son Metal Pitch. Pour descendre en dessous, à défaut de l'EUV, il faut absolument en passer par le SAQP (Self-Aligned Quadruple Patterning, quatre expositions, comme si l'on passait quatre fois la même feuille dans une photocopieuse). En plus de complexifier significativement le process pour certaines couches, le choix du SAQP augmente assez nettement les coûts ce qui n'est pas forcément dans les habitudes d'Intel. On pourra se demander si 36nm n'a pas été choisi pour se laisser l'option de passer, en cours de node, à l'EUV (36nm représentant ce que l'on peut atteindre avec la première génération d'EUV prévue en déploiement fin 2018 chez les concurrents d'Intel). Le constructeur n'a pas voulu confirmer ses intentions éventuelles vis-à-vis de l'EUV, notant simplement que des progrès intéressants avaient été réalisés ces deux dernières années, mais ne donnant aucune information sur une introduction éventuelle. Mark Bohr a indiqué tout au plus qu'Intel était "le mieux placé dans l'industrie" pour savoir quand introduire l'EUV.  Le gain de densité annoncé est basé sur la nouvelle formule proposée par Intel, qui est taillée pour profiter du passage au single dummy gate, on relativisera donc le chiffre de 2.7x annoncé qui écarte par exemple la SRAM pour gonfler le chiffre Techniquement Intel disposera avec son 10nm d'un process très dense, on rappellera que le 7nm de TSMC qu'on estimait « équivalent » au 10nm d'Intel utilisera lui aussi un Gate Pitch de 54nm, mais un Metal Pitch de « seulement » 40nm. Samsung de son côté proposera pour son process 7nm lui aussi un Metal Pitch de 36nm, Samsung ayant misé sur l'EUV dès le début de sa production 7nm. Le choix du SAQP, présenté comme une « première » nous laisse perplexe : il s'agit avant tout d'une technologie de mitigation pour tenter de repousser encore un peu plus les limites de la lithographique « classique » à immersion, en attendant encore l'EUV. Le surcoût engendré, ainsi que les contraintes techniques que cette technologie impose sont non négligeables, et l'on peut se demander si les retards d'Intel autour du 10nm ne viennent pas en grande partie de ces choix un peu trop ambitieux. En brefIntel a également donné quelques autres informations durant sa conférence, on retiendra l'arrivée d'une version « low power » de son 22nm, destiné avant tout à ses clients « Foundry » (TSMC a également annoncé une version « Low Power » de son 28nm il y a peu, baptisée 22ULP, dans les deux cas le but est de concurrencer le 22 FD-SOI), et l'on notera qu'Intel devrait produire (enfin !) ses propres modems en 14nm d'ici à la toute fin de l'année 2017, ou pour début 2018 (les modems Intel, y compris ceux inclus dans les derniers iPhone sont toujours produits par TSMC). Une semi bonne nouvelle pour Intel qui profitera de marges plus importantes avec une production en interne, mais la date avancée est trop lointaine pour pouvoir entrer dans la prochaine itération de l'iPhone.  Les chipsets d'Intel passeront aussi au 14nm en 2018, probablement pour Coffee Lake ! Pour le reste, certaines des annonces réalisées par Intel aujourd'hui nous laissent particulièrement perplexes. Le constructeur a voulu faire passer avant tout deux messages : des cycles de trois ans entre les nodes qui seraient compensés par un scaling « meilleur » que prévu, et des produits qui choisiront « le node le plus adapté », et non le node le plus récent - et le plus rentable - comme habituellement. De quoi ouvrir la porte à une éventuelle 8ème génération Core utilisant un mélange de nodes, et justifier pour l'année prochaine le fait que Coffee Lake utilisera encore le 14nm et non le « nouveau » 10nm qui pourrait bien être cantonné un bon moment aux puces double coeur mobiles (les versions 5/15W) avant d'arriver sur les marchés gros volumes habituels d'Intel (les autres puces portables et les puces desktop). Le fait que le 10nm ne sera pas, si l'on en croit Intel, son node le plus « performant » pourrait expliquer ce choix, même si à nos yeux il s'agit surtout d'un jugement assez sévère sur la qualité attendue du process 10nm dans sa première itération. Si Intel a répété plusieurs fois que la loi de Moore continue sa course, certaines des actions d'Intel nous semblent surtout être là pour masquer son ralentissement et la difficulté - commune à tous les acteurs du milieu des semi-conducteurs - à continuer à la faire avancer au même rythme que précédemment. Et si Intel pourra se targuer d'avoir, en 2018, un process encore légèrement plus dense que celui de ses concurrents grâce au choix d'un Metal Pitch très agressif, on pourra se demander quel est son intérêt si ses produits principaux ne l'utilisent pas. Copyright © 1997-2026 HardWare.fr. Tous droits réservés. |