| |
| |
| AMD Ryzen 7 1800X en test, le retour d'AMD ? Processeurs Publié le Dimanche 12 Mars 2017 par Guillaume Louel URL: /articles/956-1/amd-ryzen-7-1800x-test-retour-amd.html Page 1 - Ryzen, le renouveau pour AMD ?  Un marché qui avait été délaissé par AMD ces dernières années alors même que c'est sur celui-ci que la société avait signé ses plus belles heures à partir de la fin des années 90. Avec en point d'orgue le lancement en 2003 des Athlon 64 qui mirent à mal leur concurrent de toujours, Intel, dont l'architecture Netburst était à contretemps avec les nouvelles contraintes imposées par les process de fabrication. Dix ans de disetteLa suite est toute aussi connue, Intel réagira en 2006 avec le lancement des Core 2 Duo basés sur une nouvelle architecture plus adaptée, tandis qu'AMD s'engouffrera dans une ère difficile avec pour commencer le Phenom et son bug du TLB en 2007. Si les Phenom II redressèrent la barre, l'architecture CMT lancée en 2011 avec Bulldozer fut par la suite un échec. Cette architecture était pour rappel basée sur un concept de modules qui regroupaient deux coeurs dont avaient été fusionnés les parties qui servent le moins. Un moyen de proposer plus de coeurs sur une surface plus petite, c'est en tout cas comme cela qu'était vendue la chose sur le papier. En pratique, les concessions effectuées sur la fusion de deux coeurs en un module ont eu un impact lourd sur les performances, et si les itérations de l'architecture ont permis petit à petit de corriger les problèmes les plus graves, au final l'offre "haut de gamme" desktop d'AMD se résumait jusqu'à hier aux FX Vishera lancés en 2012. Des puces gravées en 32nm, pour le moins anachroniques en 2017 ! Quatre années de développementCe qui marquera réellement l'année 2012 pour AMD, c'est avant tout le retour de Jim Keller qui avait participé au design des K7 avant de tenir le rôle d'architecte principal du K8. Une "grosse prise" à l'époque pour un AMD au milieu d'une situation financière particulièrement difficile, la société le récupérant même à Apple (!) où il avait dessiné la très remarquée et très performante architecture armv8 des A7 de la marque. Il faudra attendre 2014 pour avoir les premiers échos : AMD travaille en parallèle sur deux nouvelles architectures, une x86 haute performance qu'on connaîtra sous le nom de Zen, et l'autre dédiée au jeu d'instructions armv8. On parle alors d'un lancement commercial en 2016 pour Zen, même si assez rapidement - courant 2015 - plusieurs sources internes chez AMD nous auront confirmé qu'il ne faudrait pas attendre la sortie avant 2017. En septembre 2015, Jim Keller quittera AMD (il fera un passage éclair chez Samsung avant d'atterrir aujourd'hui chez Tesla) mais tout laissait penser à l'époque que son travail était déjà terminé : les architectes travaillant en effet très en amont. Car sur le papier, Zen semble corriger tout ce qui n'allait pas avec Bulldozer. Exit les modules, Zen apporte un retour à un design de coeurs classiques avec le support du SMT (deux threads logiques sur un coeur, une technologie plus connue sous la dénomination marketing d'HyperThreading chez Intel). L'architecture serait "équilibrée", visant de hautes performances tout en profitant d'un process 14nm un peu plus dans l'ère du temps. De quoi faire naître de nombreux espoirs chez les fans de la marque, et plus généralement tous ceux qui constataient les conséquences ces dernières années du manque de concurrence sur le marché des CPU, à savoir des gains de performances de plus en plus réduits et des prix parfois tout simplement délirants. En pratique, les ingénieurs d'AMD se sont lancés dans une véritable course contre la montre pour être dans les temps, certains détails des processeurs n'ayant été finalisés que dans les tous derniers jours via des mises à jour de microcode.  Précipitation ou non, les puces finales et leur microcode sont enfin là, disponibles à partir d'aujourd'hui dans les rayons. Ces nouveaux processeurs basés sur l'architecture "Zen" portent, lois sur la protection des marques obligent, le nom plus stylisé de Ryzen. Un nom à mi-chemin entre risen (qu'on pourrait traduire rapidement par s'élever) et horizon. Des attentes extrêmes, alimentées aussi par AMD !Une fois n'est pas coutume, AMD n'a cependant pas fait coïncider la mise en vente de ses puces avec la sortie des tests dans la presse, le constructeur ayant ouvert dès la semaine dernière les pré-commandes. Une décision d'autant plus discutable qu'elle était accompagnée des résultats d'un bench qu'on pouvait imaginer savamment choisi, Cinebench R15. AMD ayant qui plus est laissé de côté le détail que le 6900K n'était, dans ses comparaisons internes, qu'équipé de mémoire sur deux canaux (la plateforme en gère pour rappel quatre !) même s'il faut bien dire que cela n'a quasi pas d'impact sur Cinebench R15. C'est moins le cas d'autres benchmarks "internes" d'AMD qui ont filtré et alimenté les rumeurs dans l'intervalle. Le but était de créer une histoire simple : un Ryzen 7 1800X serait équivalent à un Core i7 6900K, pour un prix de quasi moitié inférieur. Cette promesse est-elle tenue ? Que valent en pratique ces nouvelles puces ? C'est ce que nous allons essayer de voir concrètement dans notre dossier ! Le jeu d'instructions Avant d'entrer dans les détails, faisons le point sur les jeux d'instructions. AMD se met à jour en supportant à peu près toutes les extensions existantes, on retrouve ainsi AVX et AVX2, l'accélération des instructions SHA, mais aussi des choses plus originales comme les instructions de mémoire transactionnelle (TSX), introduites avec assez peu de succès par Intel pour Haswell. AMD rajoute en prime deux nouvelles instructions, dont une pour libérer une ligne de cache, et l'autre pour combiner des pages mémoires. AMD est donc aligné sur ce que proposait Intel jusque Broadwell, Skylake n'ajoutant que SGX et MPX dont l'utilisation est plus particulière, servant comme on pouvait le craindre à la mise au point de DRMs ! Les instructions FMA4, XOP et TBM, introduites par AMD sur Bulldozer/Piledriver et non utilisées par Intel, sont par contre abandonnées. Un coeur Zen en pratiqueLe responsable (post Jim Keller) de l'architecture Zen, Mike Clark, la décrit lui même comme une architecture "équilibrée" (il a utilisé précisément le mot balanced).  Sur ce schéma on retrouve les grandes lignes d'un coeur Zen. Pour rappel ce schéma commence en haut à droite, avec la partie Branch Prediction où les instructions arrivent avant d'être décodées. On notera que chaque coeur dispose d'un cache L1 d'instructions de 64 Ko, et d'un cache L1 de données de 32 Ko. Chaque coeur dispose enfin d'un cache L2 de 512 Ko. Le point important à retenir sur ce schéma est qu'AMD distingue clairement le chemin "Integer" (bloc rouge, opérations sur les nombres entiers, et toutes les opérations classiques comme les boucles, etc...) et le chemin "Floating Point" (bloc orange, opération sur les nombres à virgules plus gourmandes). Le choix de séparer les opérations entières et flottantes est une particularité de l'architecture Zen. A titre de comparaison, Intel mélange toutes ses unités de calcul sur des ports (des files indépendantes), ne séparant pas le traitement des instructions entières et flottantes. Par le passé, cette scission était nécessaire pour AMD, l'architecture Bulldozer regroupait dans un module deux blocs "Integer" et partageait un seul bloc "Floating Point". AMD a voulu conserver l'idée de la séparation tout en résolvant les problèmes restant, nous y reviendrons. Le front-end Tout en haut du graphique d'architecture précédent, on retrouve la partie du front end qui récupère (fetch) les instructions. Son rôle est d'extraire les instructions à exécuter, la prédiction de branchements (on parle de conditions, si elle est vraie, effectue ceci, sinon, effectue cela) tentant de déterminer à l'avance le résultat de la condition pour pouvoir commencer a travailler sur la bonne "branche". Cette prédiction est effectuée par un perceptron , un type de réseau neuronal simple. Deux branches par cycles peuvent être évaluées, par le perceptron, Le TLB (un cache pour traduire les adresses mémoires virtuelles) est intégré et tout le mécanisme a été amélioré pour être plus efficace en ajoutant une table pour les adresses de retour des branches (l'endroit ou l'exécution doit se poursuivre à la fin de la branche, le bloc d'instruction exécuté après la condition). Décodage des instructions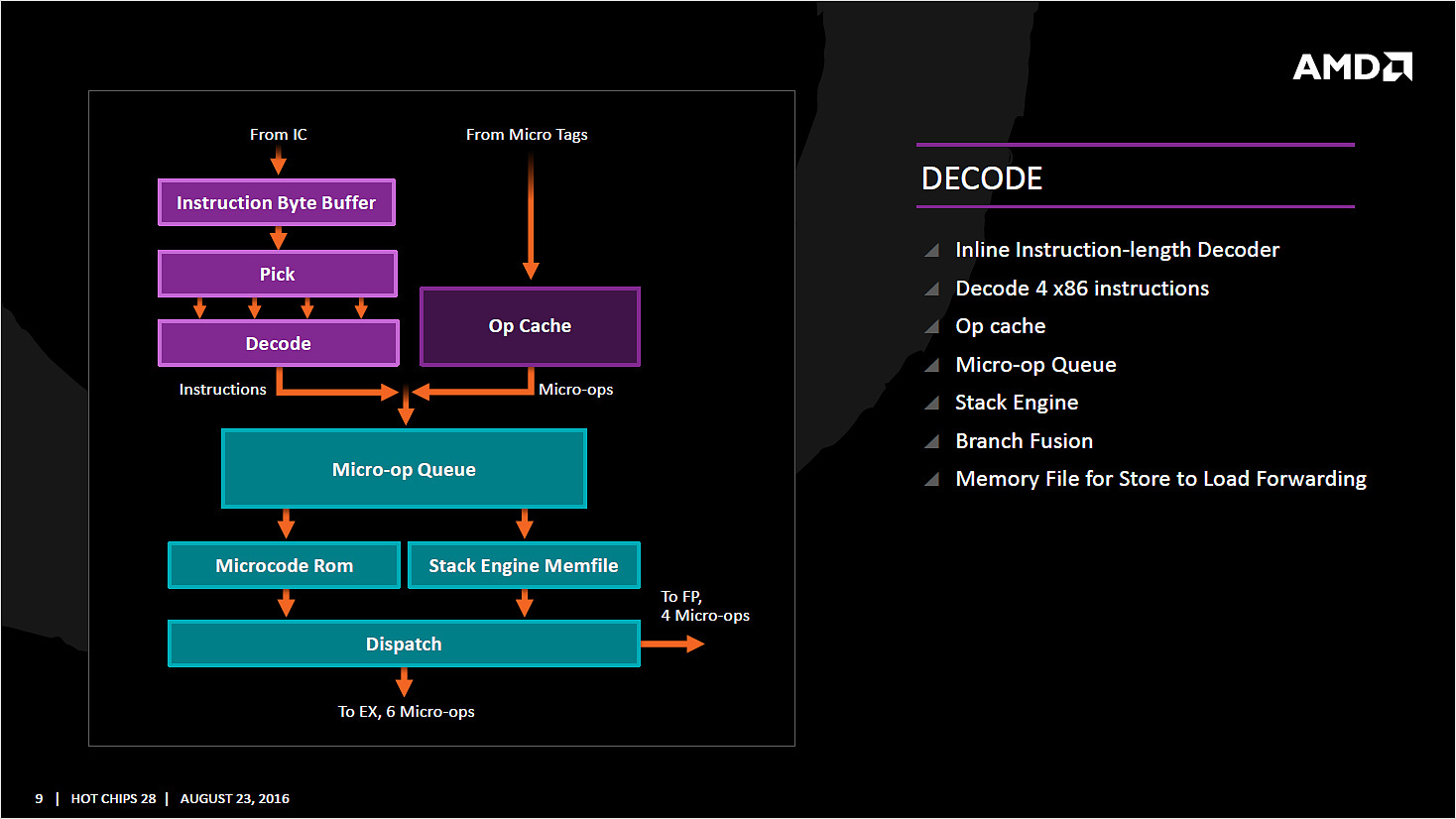 Les instructions récupérées vont ensuite être placées dans le cache d'instruction avant d'être décodées. C'est ici que les instructions x86 sont lues par le processeur, qui les transforme en des micro-opérations (micro-op) qui seront exécutées par la suite dans le pipeline. On rappellera que le jeu d'instructions x86 est particulièrement large (CISC), pour plus d'efficacité les processeurs travaillent en interne (sur les unités d'exécution plus bas) sur un jeu de micro-opérations réduit (RISC). Les décodeurs sont capables de traiter jusque quatre instructions par cycle (c'est équivalent à ce que propose Intel sur Haswell et Skylake) qui sont transformées en jusque 6 micro-op. Certaines instructions peuvent être fusionnées en une seule micro-op (notamment celles de branchements), là encore les similarités avec ce que propose Intel sont fortes. Comme chez Intel, AMD utilise un cache qui stocke la correspondance entre une instruction décodée et la micro opération qui en est issue. Le jeu d'instructions x86 comportant un bon millier d'instructions de tailles variables, l'idée est de garder en cache les instructions les plus récemment décodées en mémoire pour pouvoir les traduire automatiquement en micro-op sans repasser par la case décodage. Cela permet d'ajouter plusieurs micro-op supplémentaires par cycle à traiter. Par rapport à ses architectures précédentes, AMD dit avoir "significativement" augmenté la taille de son Op Cache et que ce seul changement est responsable d'une grande partie des gains d'IPC et de consommation. On y retrouve une logique semblable aux évolutions architecturales que l'on a vu à la concurrence : le front-end joue un rôle excessivement important dans les architectures x86 sur les performances du reste de la puce et il est important de le peaufiner. Le voir soigné de la sorte est plutôt prometteur sur l'IPC de Zen, ce que nous vérifierons en pratique dans quelques pages ! On notera que les micro-ops sont placées dans une file, ou plus exactement deux files. AMD implémente pour rappel le SMT (Simultaneous Multi Threading) qui permet de gérer deux threads par coeur (l'HyperThreading est le nom marketing de l'implémentation SMT d'Intel). La file de micro-op est ainsi scindée en deux (ce qui est identique à ce que fait Intel pour Sandy Bridge et Skylake, Haswell ayant utilisé une file commune). Les instructions vont enfin être dispatchées vers les ports. En pratique 10 micro ops peuvent être envoyées (6 vers la partie "Integer" de la puce, 4 vers la partie "Floating Point"), soit deux de plus que sur Haswell (Intel ne nous a pas donné l'information pour Skylake). Les unités d'exécution Les micro-op vont être dispatchées vers 6 files d'exécution (l'équivalent des ports d'Intel) dont la taille a été significativement augmentée (14 entrées par file, soit 84 pour cette partie de la puce, Skylake en compte 97 en tout mais il faut ajouter celles dédiées aux opérations FP, nous y reviendrons). AMD dispose de deux files dédiées aux opérations mémoires (AGU, address generation unit) qui asservissent un système de lecture/écriture mémoire (Load/Store) sur lequel on reviendra. Quatre files sont dédiées aux instructions de "calcul" et de branchements. AMD les appelle ALU sur son schéma, il s'agit en pratique d'une série d'unités d'exécution. Chaque ALU regroupe au minimum la possibilité de traiter les instructions logiques de base. AMD ne le détaille pas sur son schéma, mais d'autres unités sont présentes. Le constructeur nous a confirmé que deux des ALU contiennent une unité dédiée au branchement, une ALU contient une unité gérant les divisions, une ALU contient une unité gérant les multiplications entières, et enfin une ALU contient une unité dédié au CRC32. L'efficacité de ces unités dépendra en grande partie de la capacité du front-end à les alimenter, mais sur le papier là encore, le design semble largement adéquat pour maximiser le nombre d'instructions traitées par cycle. 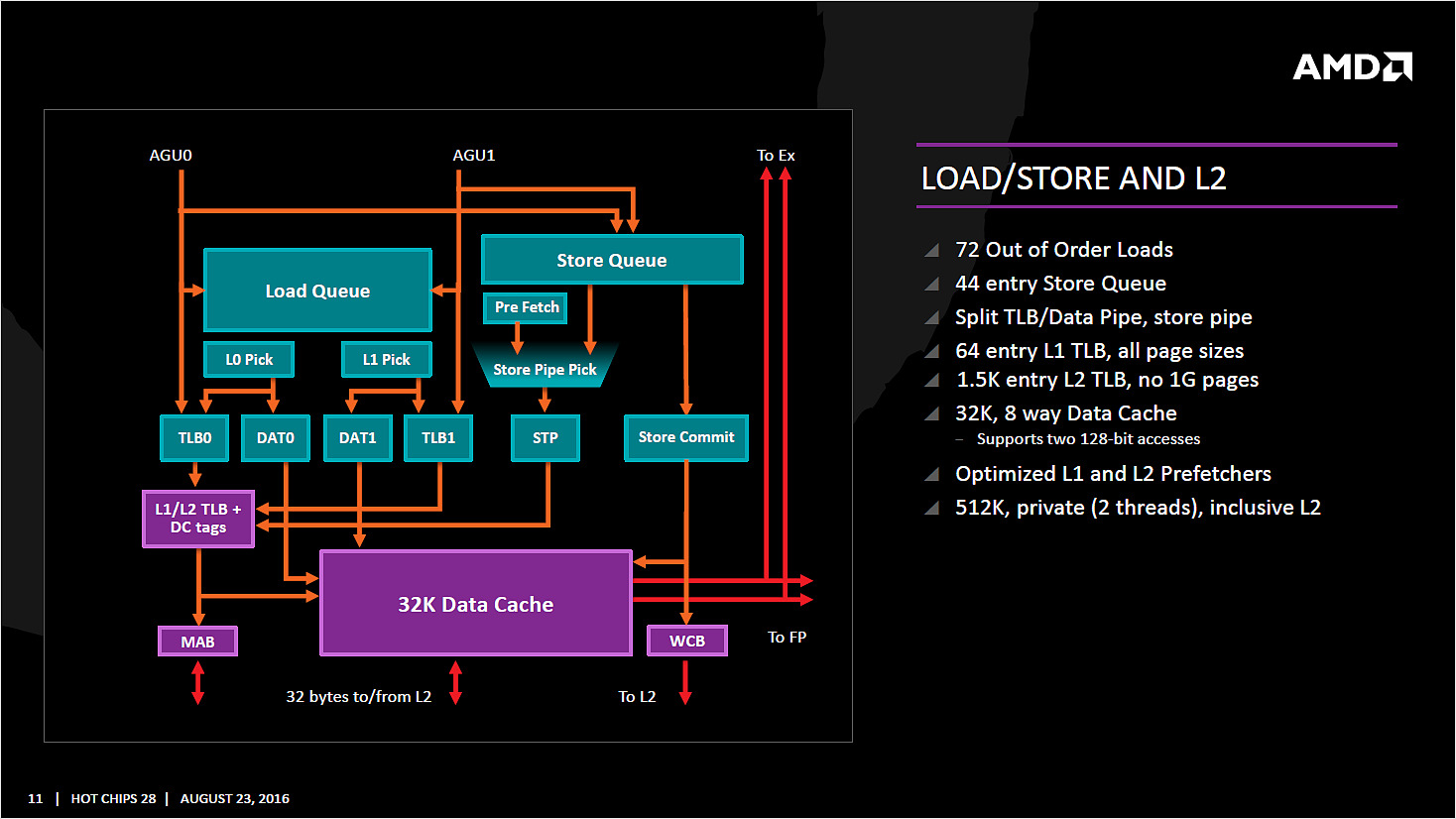 Comme nous le disions, les AGU asservissent les unités qui lisent et écrivent les données dans le sous-système de cache. On retrouve des longueurs de files comparables à ce que l'on a chez le concurrent (72/44 pour Zen, 72/42 pour Haswell et 72/56 pour Skylake). Pour les chargements, AMD rentre dans le détail en indiquant qu'un des autres points faibles de ses architectures précédentes était lié aux opérations de chargement mémoire. Deux accès séparés de 128 bits en lecture sont désormais possibles, et les unités peuvent accéder en simultanée au cache L1 et au cache TLB pour maximiser le débit, et ainsi streamer les données rapidement du cache L2 vers le L1. L'efficacité des prefetchers (qui tentent de récupérer les informations en avance du moment ou le processeur en aura besoin) est indiquée comme meilleure sans plus de détails.  Si l'on revient en arrière, le dispatcher de micro-op pouvait envoyer jusque 6 instructions vers la partie Integer, et quatre vers la partie Floating point. Le scheduler dédié aux unités flottantes dispose ici de 96 entrées ce qui nous donne un total de 180 entrées par coeur (contre 97 pour Skylake). Il s'agit même en pratique d'un double scheduler. C'était l'un des points faibles du design séparé que l'on évoquait plus haut : sur Bulldozer un scheduler trop petit sur la partie FP pouvait arriver à bloquer la partie Integer du CPU, un cas qui visiblement était assez fréquent. Avec un double scheduler, AMD dit avoir résolu le problème en pratique. On disposerait désormais bel et bien de deux blocs réellement indépendants pouvant travailler en parallèle (et ne se bloquant plus l'un l'autre). Quatre unités d'exécution FP 128 bits sont donc présentes, deux dédiées plus spécifiquement aux multiplications et deux aux additions. Elles peuvent être combinées pour réaliser jusque 2 FMA 128 bits en parallèle par cycle. Sur ce point AMD est en retrait puisque depuis Haswell, les architectures Intel peuvent effectuer deux FMA 256 bits par cycle et ont donc l'avantage dans ce type de charge en AVX2, certes assez rare en pratique. C'est un point sur lequel l'architecture de Zen peut être limitée. Les caches mémoires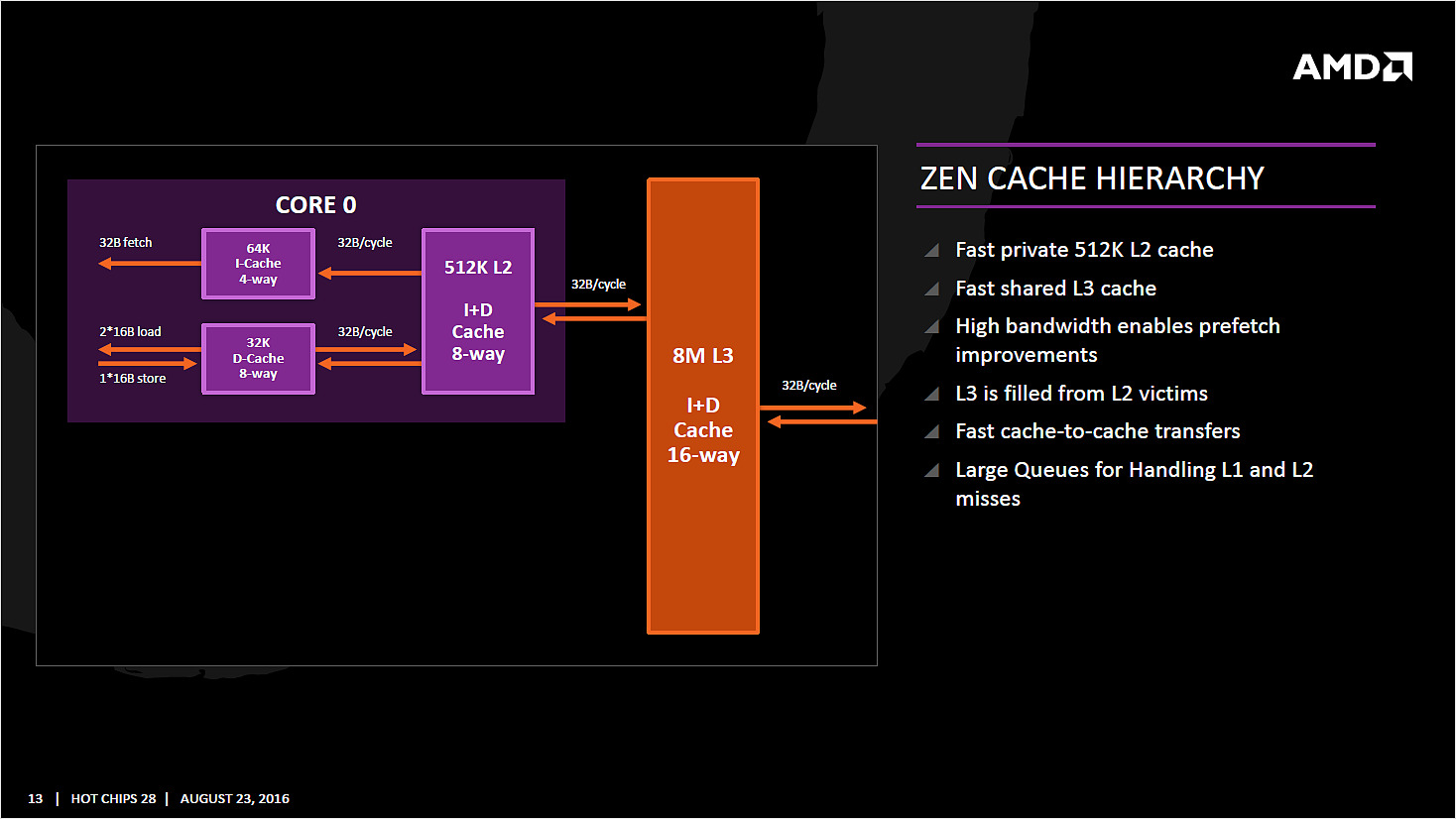 Chaque coeur dispose bien entendu de ses propres caches. On retrouve pour chaque coeur un cache L1 d'instructions de 64 Ko, et un cache L1 de données de 32 Ko. On y retrouve également un cache de niveau 2 de 512 Ko. Un des changements principaux est sur le type de cache utilisé : AMD a choisi d'utiliser un cache L1 write back au lieu du write through utilisé précédemment, s'alignant là aussi sur ce que fait Intel. Cela devrait assurer une bien meilleure bande passante mémoire pour le L1 par rapport aux architectures précédentes d'AMD. CCX : CPU ComplexChaque CCX est composé de quatre coeurs qui sont regroupés autour d'un cache L3 de 8 Mo. En pratique c'est même un peu plus compliqué, puisque le cache L3 est partitionné en quatre morceaux de 2 Mo, un étant accolé à chaque coeur. Le L3 est de type "victime", les données qui sont éjectées du L2 se retrouvent stockées dans le L3. 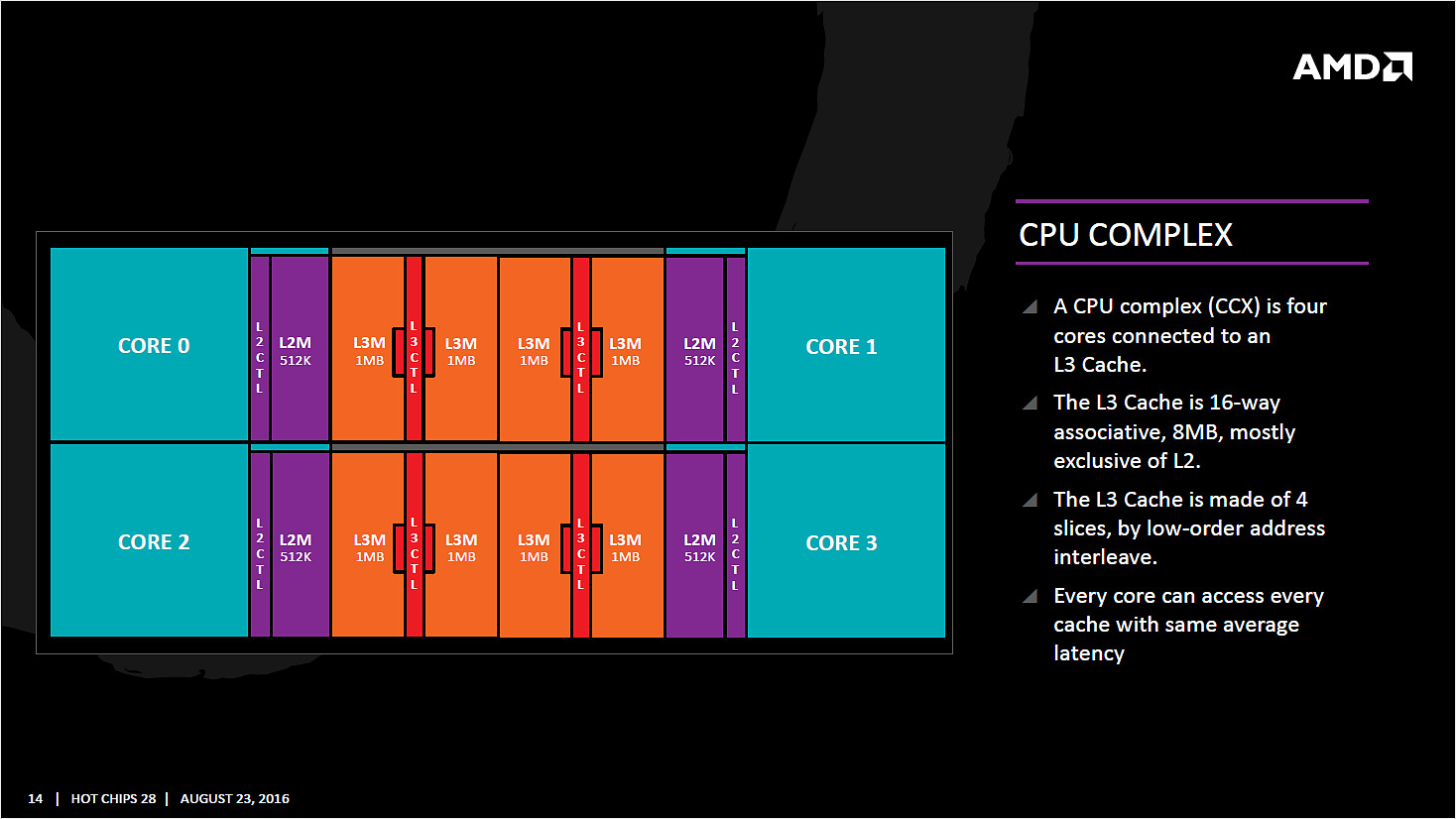 C'est là que les choses deviennent un peu plus complexes puisque la latence devient variable en fonction de l'emplacement des données. Ainsi sur le schéma ci-dessus, si le Core 0 a besoin de données dans le L3 du troisième Core 3, la latence sera plus élevée que si les données sont dans le L3 du Core 0. AMD tempère cela en expliquant que tous les cores ont la même latence "moyenne" vers tous les caches, ce qui ne fait que tenter de noyer la différence. Summit Ridge = Deux CCX reliés... mais comment ?Là où les choses se compliquent encore plus, c'est dans le fait qu'un Ryzen 7 (les Summit Ridge lancés aujourd'hui) est composé de 8 coeurs, et donc de deux CCX indépendants.  Le die de Ryzen, on peut voir à gauche et à droite les deux CCX indépendants AMD nous a donné beaucoup plus de détails la veille du lancement sur la question. Mike Clark avait expliqué durant la conférence Hot Chips que les deux CCX ne disposaient pas de lien direct entre eux. AMD a clarifié cela, en pratique, chaque CCX est relié via une data fabric (rebaptisée Infinity Fabric, le marketing est parfois ironique) au contrôleur mémoire. En pratique, quand un coeur a besoin d'une information qui n'est pas dans la hiérarchie de cache de son CCX local, deux requêtes sont envoyées dans la data fabric, la première vers le contrôleur mémoire qui tente de rapatrier la donnée, la seconde vers l'autre CCX (en passant par un switch placé juste devant le contrôleur mémoire, entre les CCX et le contrôleur). Si le second CCX dispose de la donnée, elle est rapatriée directement, et la demande faite au contrôleur mémoire est annulée. Si ce n'est pas le cas, on attendra que le contrôleur mémoire rapatrie la donnée. AMD ajoute que le protocole MOESI est utilisé pour synchroniser les deux caches. D'un point de vue conceptuel, Ryzen est donc assez différent des autres processeurs, qui disposent en général d'un lien direct entre les groupes de coeurs lorsque les caches sont séparés. On se retrouve à mi-chemin entre une architecture classique, et un système bi-CPU. Si l'on reprend notre exemple plus haut, et que le Core 0 doit accéder à une donnée présente dans l'autre CCX, on paiera donc une pénalité de latence par rapport à si la donnée est présente dans le CCX où se situe le core. Mais en général, on va s'attendre à voir des latences mémoires plus hautes du fait de la nécessité d'effectuer deux requêtes à chaque fois dès que l'on sort du CCX. Il nous semble probable qu'AMD révise assez rapidement cette approche avec d'autres itérations de l'architecture Zen, tant cela pourrait impacter les performances dans des cas spécifiques. Et aussi un SoC !En plus des deux CCX et du contrôleur mémoire double canal, on retrouve dans les Ryzen plusieurs blocs supplémentaires. Le premier gère 24 lignes PCI Express 3.0. Ces dernières sont découpées en trois, avec seize lignes qui peuvent être partagées entre deux ports PCI Express (8x/8x), quatre lignes pour un port M.2 et enfin quatre lignes pour l'interconnexion avec le chipset. 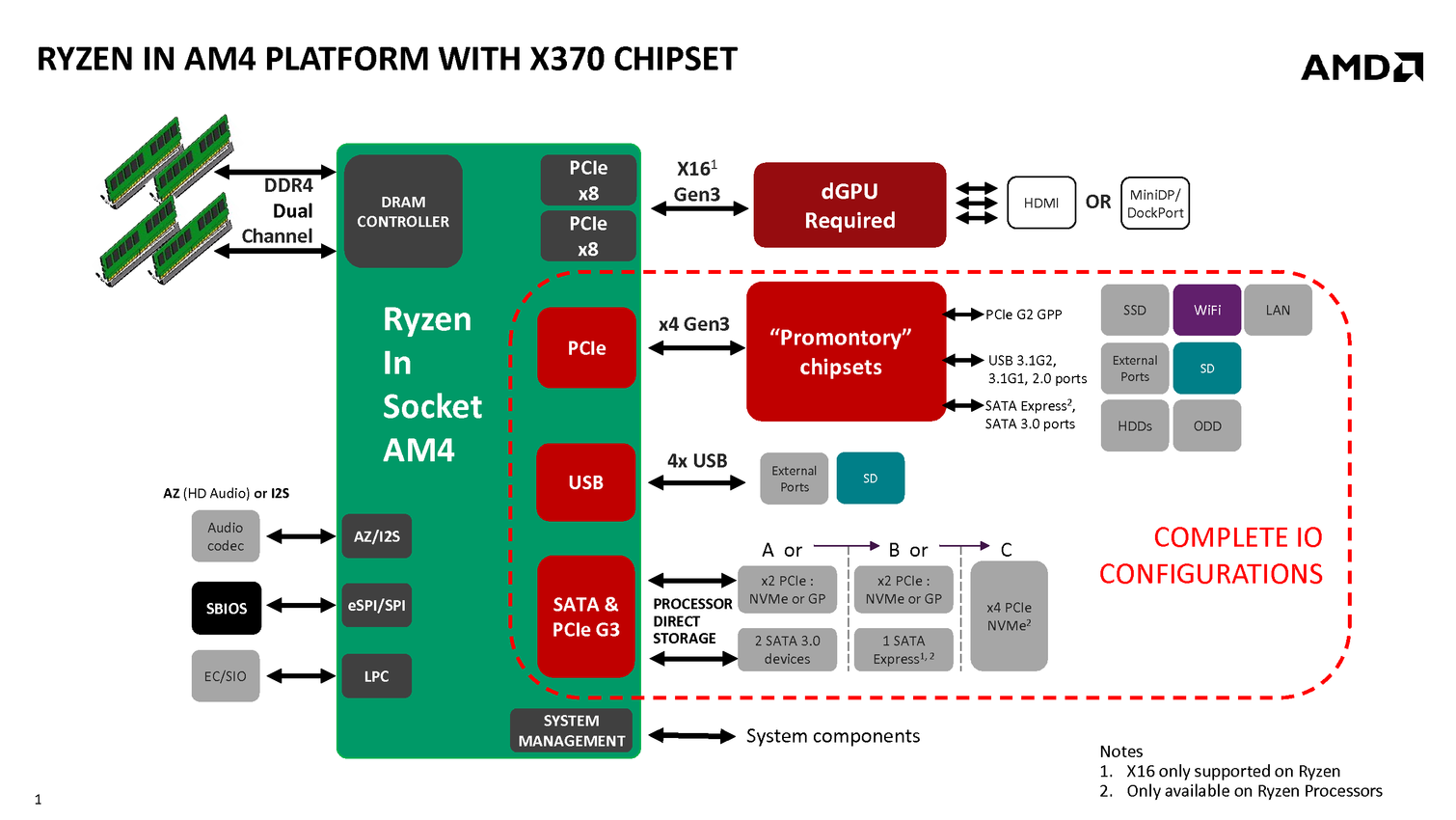 Mais ce n'est pas tout, en effet Ryzen inclut nativement la gestion de quatre ports USB 3.0, ainsi qu'une gestion du SATA. Les autres IO (gestion système, connexion HD Audio, etc) sont également incluses ce qui permettra aux cartes mini-ITX de se contenter d'une petite puce compagnon interconnectée via un simple lien SPI. Une tension par coeurCôté alimentation, Ryzen innove là aussi puisque la carte mère AM4 fournie deux tensions principales au processeur, VDDCR CPU et VDDCR SOC (ainsi qu'une troisième pour le GPU pour les APU). Les deux CCX sont alimentés par VDCCR CPU, le reste (data fabric, contrôleur mémoire, contrôleur pcie, soc) l'étant par VDDCR SOC qui est à 0,99v par défaut. 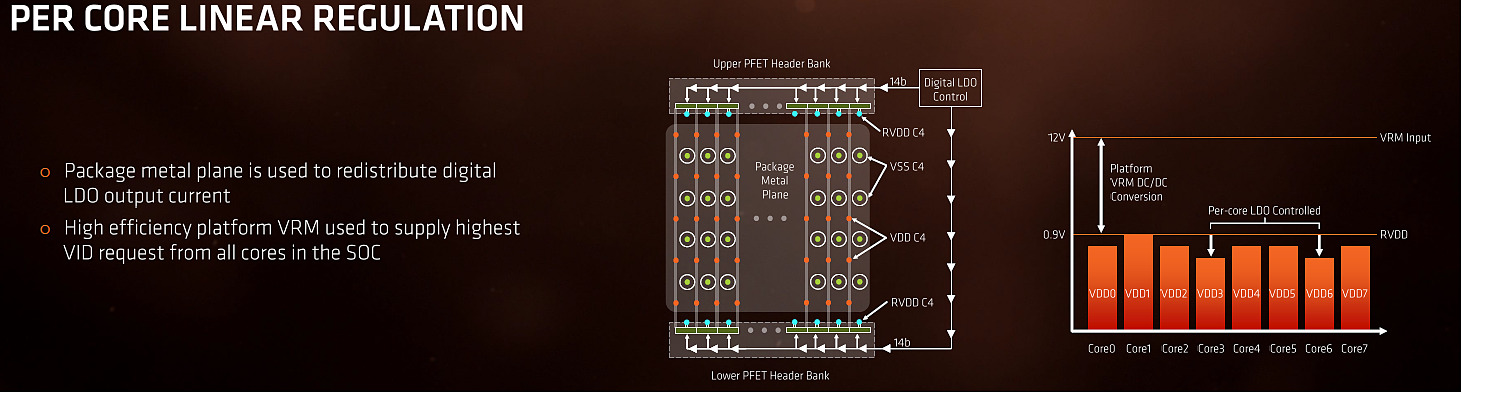 L'innovation se situe au niveau de VDDCR CPU, puisque la tension fournie par la carte mère sera légèrement modifiée afin de correspondre au mieux à celle nécessaire pour chacun des coeurs plutôt que d'appliquer une tension unique correspondant au moins bon. De quoi gagner en efficacité.  Il s'agit d'un SoC 8 coeurs avec SMT (16 threads logiques, l'équivalent de l'HyperThreading d'Intel) au TDP de 95 watts. Sa fréquence de base est annoncée à 3.6 GHz avec une fréquence Turbo maximale de 4 GHz. La fabrication de la puce est confiée à GlobalFoundries, en 14nm. 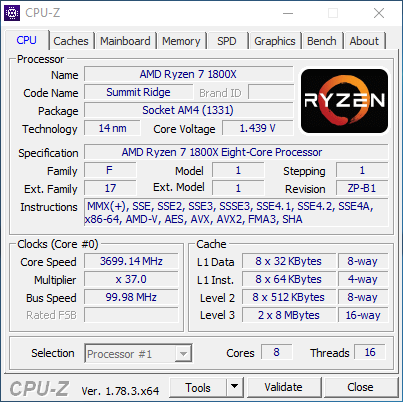 [ Charge sur un coeur ] [ Charge sur tous les coeurs ] On rappellera que le 14nm de GlobalFoundries est en partie hérité de celui de Samsung suite à un accord passé entre les deux sociétés. En pratique cependant, GlobalFoundries aurait selon nos informations fait diverger son process, en grande partie parce que les relations de travail entre les deux sociétés concurrentes n'ont pas été excellentes. AMD de son côté dit avoir profité de l'apprentissage du process sur ses puces graphiques Polaris pour en tirer le meilleur pour Ryzen. On notera que la tension en fonctionnement est particulièrement élevée sur les Ryzen 1800X, 1.350V sur notre processeur de test dans le BIOS. En pratique la tension de fonctionnement dépend du nombre de coeurs utilisés, comme vous pouvez le voir sur les captures CPU-Z au-dessus on est, à une charge sur un coeur, au-delà de 1.4V tandis que sur une charge sur tous les coeurs, on reste à seulement 1.2V. Monter en fréquence aura été l'un des plus gros problèmes des derniers mois de finalisation de Ryzen pour AMD, qui a dû contorsionner assez fortement le process de GlobalFoundries pour obtenir un rapport fréquence/consommation adéquat. On remarquera aussi que la fréquence au repos du processeur est assez haute en apparence, 2.2 GHz. Les auteurs des différents outils de monitoring nous ont cependant confirmé que cette lecture est erronée. La lecture des P-States n'est pas pour l'instant possible, ces derniers attendent de plus amples informations de la part d'AMD pour avoir une lecture correcte. Si l'on se fie au BIOS de notre carte mère qui permet de régler manuellement les P-States, il est possible que la fréquence descende à 400 MHz au repos. Deux turbosIl y a en pratique deux niveaux de Turbo sur les Ryzen. Le premier est classique : en fonction du nombre de coeurs stressés, une fréquence maximale est autorisée. Si six coeurs sont au repos (en mode CC6) - donc jusque deux coeurs utilisés, il pourra être cadencé à 4.0 GHz, contre 3.7 GHz lorsque tous les coeurs sont utilisés. Par dessus cela s'ajoute XFR - eXtended Frequency Range - un second niveau de Turbo dit "opportuniste" : ce dernier ne s'enclenche que si la température du processeur reste sous le seuil maximal autorisé. La technologie rappellera ce que l'on retrouve sur les cartes graphiques.  En pratique, sur le 1800X, XFR permet d'obtenir un gain supplémentaire de 100 MHz, pour atteindre des fréquences de 4.1 GHz sur jusque deux coeurs (et 3.7 GHz au-delà). Notez que XFR est géré 100% en hardware par Ryzen, il n'est pas lié à un support particulier d'une version de Windows. AMD est bien entendu conscient que 100 MHz ne représente qu'un gain modeste : les futures itérations de l'architecture Zen, et l'on pense plus particulièrement à la version Mobile de Ryzen devraient utiliser XFR beaucoup plus largement. En pratique, trois références sont lancées dans la famille Ryzen 7 :
On notera que pour le R7 1700, le XFR est encore plus contenu : seulement + 50 MHz ! Tous ces modèles (et tous les modèles de Ryzen à venir) disposent d'un coefficient multiplicateur débloqué comme nous vous l'avions annoncés. Notez enfin que la famille Ryzen s'étendra au second trimestre avec l'arrivée de la gamme Ryzen 5, qui aura pour tête de proue un R5 1600X avec 6C/12T pour des fréquences de 3.6/4.0 GHz pour un prix sous les 300 dollars. Les Ryzen R3, enfin, n'arriveront que dans la seconde moitié de 2017. Un support mémoire limité... ou pas ...L'autre point qui pose question est le support mémoire. Officiellement, voici ce qu'AMD indique comme compatible :
Autant dire que c'est excessivement limité, et le fait qu'AMD doive distinguer la mémoire dual ranked et single ranked est pour le moins stupéfiant. A titre de comparaison, Intel propose un support de la DDR4-2400 sur quatre canaux de manière officielle. Les spécifications officielles ne font pas tout, et les constructeurs de cartes mères proposent en général des marges d'overclocking importantes. Et là, il y a un flou assez épais, en partie dû au timing. Car les spécifications "officielles" plus haut sont liées à l'état du support concret de Ryzen... il y a quinze jours de cela. Dans ces derniers jours, les ingénieurs d'AMD ont corrigé un problème dans le microcode de Ryzen qui permet de monter plus haut. En pratique nous l'avons constaté, sur notre carte mère de test, avec le BIOS d'origine, incapable de démarrer avec quatre barrettes en DDR4-2400. Avec le nouveau BIOS (et le nouveau microcode), aucun problème. Lors de la présentation de Ryzen, cette avancée nous a été présentée, mais le fait qu'elle soit de dernière minute fait qu'en pratique, les constructeurs de cartes mères sont restés sur les anciennes informations. Et AMD même, s'il reconnaît bien l'avancée, reste prudent. En pratique "l'overclocking" mémoire est possible, les modes DDR4-1866/2133/2400/2666/2933/3200 sont accessibles et au-delà il faut en plus augmenter la fréquence du bus par défaut à 100 MHz. Une nouvelle version de la grille au-dessus, un peu plus lisible nous a été fournie par AMD :  On notera que le double canal est désormais possible selon AMD en DDR4-2667, ce qui n'était pas le cas précédemment. AMD nous a confirmé que "pour l'instant", les recommandations ci-dessus sont les recommandations officielles, et "qu'elles pourront évoluer dans les semaines à venir" quand des tests plus approfondis auront été réalisés par les constructeurs de cartes mères... et AMD. ...mais parfois chaotique !Une des surprises que nous avons eu durant notre test concerne les performances en fonction du nombre de barrette de mémoire. En effet, afin de maintenir l'équité dans nos tests de consommation, nous avions entrepris de tester toutes les plateformes avec quatre barrettes mémoires. Etant donné les changements de dernière minute dans le microcode, nous avons voulu vérifier si utiliser deux barrettes mémoires n'était pas légèrement plus performant. Nous avons alors constaté plusieurs choses en passant de 4 x 4 Go à 2 x 8 Go :
Nous avons interrogé AMD sur la question, le constructeur était le premier surpris (AMD a fourni à la presse des kits n'incluant que deux barrettes mémoires, on ne les accusera pas pour le coup d'avoir tenté de cacher la chose !). Le constructeur investigue la question actuellement, un ingénieur nous a suggéré que le Bank Interleaving était probablement un facteur même si l'écart semble très important pour cette explication. En pratique nous n'avons pas noté de différence de performances dans les autres applications où la mémoire ne joue qu'un rôle limité, comme x264 par exemple. Nous pensons qu'il s'agit ici d'un artefact d'un changement au niveau de la dernière mise à jour du microcode qui n'aurait pas été anticipé. Nous vous tiendrons au courant si le constructeur revient vers nous avec plus de détails. La marque s'engage à rester sur le socket AM4, commun avec les APU, pour les années à venir, visant un remplacement éventuel en 2020. Une arrivée prématurée de la DDR5 ou du PCI Express 4.0 entraînerait cependant la nécessité d'un nouveau socket. Notez que les systèmes de refroidissement ne sont pas compatibles, la position des trous de fixation sur la carte mère ayant été modifiée. Plusieurs constructeurs proposent des adaptateurs, parfois gratuitement. Pour effectuer notre test, AMD nous a fourni une carte mère Crosshair VI Hero, un modèle haut de gamme d'Asus. Elle utilise côté chipset l'AMD X370.  Le chipset dans le cas de la plateforme AM4 rajoute des ports à ceux gérés directement par le processeur (pour rappel, deux ports SATA et quatre ports USB 3.0 sont gérés par le SoC Ryzen). Nous avions eu l'occasion de vous en parler, ces chipsets ont été sous-traités à la société ASMedia. Le chipset est relié au SoC par quatre lignes PCIe 3.0. On obtient ces caractéristiques pour rappel : 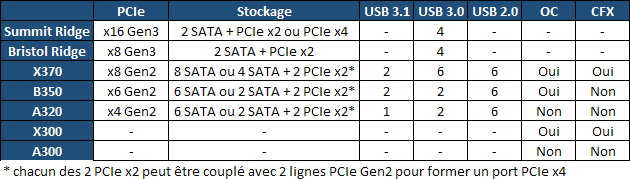 Dans le cas du chipset X370 présent sur notre carte mère, il permet de rajouter jusque 8 ports SATA, deux USB 3.1, 6 USB 3.0 et 6 USB 2.0. Le chipset agit également comme un hub en proposant 8 lignes PCIe 2.0 qui peuvent être utilisées pour des ports PCie ou pour connecter des contrôleurs additionnels. En pratique, notre Crosshair VI Hero propose huit ports SATA gérés par le chipset, tandis que le slot M.2 est relié directement au CPU en mode PCIe x4 (avec support du mode SATA optionnel). Côté USB, on retrouve à l'arrière 4 ports USB 3.0 gérés par le CPU, et 4 ports 3.0 gérés par le chipset. Côté USB 3.1, les ports du chipset sont accessibles par un connecteur sur la carte mère, les ports en façade arrière étant reliés aàun autre contrôleur ASMedia USB 3.1. A noter que les X300/A300 sont des puces basiques n'offrant pas d'I/O supplémentaires par rapport à celles présentes dans le SoC de Ryzen. Elles sont connectées via un simple lien SPI à Ryzen et permettent d'avoir accès à certaines options de sécurités (secure boot, trusted platform module par exemple) nécessaires à la plateforme. Cela libère au passage 4 lignes PCIe Gen3 au niveau du Ryzen, et permet d'avoir un puce additionnelle compacte pour du mini-ITX, de l'ordre de 1cm². Nous cadençons pour ce test nos FX-8350 (Piledriver), Ryzen 7 1800X (Zen) et Core i7 6900K (Broadwell-E) à 3 GHz. Le SMT/HyperThreading est actif sur ce test pour les processeurs qui disposent de cette technologie. Nous utilisons 4 barrettes de 4 Go de DDR4-2400 15-15-15-35 1T sur les plateformes DDR4, et 4 barrettes de 4 Go de DDR3-1600 9-9-9-24 1T pour le FX. Dans les applicationsNous calculons un indice 100 sur Piledriver, commençons par les applications (nous avons également ajouté les scores avec le Core Parking désactivé, pour plus de détails sur ce que cela veut dire, rendez-vous dans deux pages !) : On peut trouver de nombreux arguments pour excuser Piledriver, entre le fait qu'il ne soit pas pourvu de HT/SMT, qu'il soit handicapé par son architecture à base de modules... mais tout de même. L'écart à fréquence égale avec les architectures modernes d'Intel est embarrassant, et résume la situation difficile dans laquelle se trouvait le constructeur jusqu'ici. Car avec l'arrivée de Zen, les choses changent enfin. Si l'on se concentre d'abord sur l'indice applicatif, on peut voir qu'en moyenne, Zen fait 2.3x fois mieux que Piledriver ! Le gain en lui même est massif, mais il faut surtout regarder où Zen atterrit. Car Intel ne s'était pas arrêté. A fréquence égale, Zen se rapproche fortement de Broadwell-E, on trouve 11% d'écart entre les deux architectures sur notre moyenne applicative, en notant que trois benchmarks plombent la moyenne : 7-Zip, WinRAR et Lightroom. Nous y reviendrons. On notera que dans x264 par exemple, Zen se paye le luxe d'être devant Broadwell-E, ce qui tend à prouver qu'en termes d'IPC, les gains sont bel et bien là ! Dans les jeuxRegardons la situation dans les jeux 3D : La situation est assez différente avec des gains globalement plus mesurés si l'on compare les moyennes, Broadwell-E ne fait "que" deux fois mieux que Piledriver dans les jeux, là où l'écart applicatif était plus proche de 2.5x. L'écart entre Zen et Broadwell-E est cependant assez large à 3 GHz, +28%. Cependant en changeant le mode Core Parking de Windows 10 pour Ryzen, l'écart se réduit à 21%. Dans les deux cas, nous cadençons les processeurs à 3 GHz. Nous utilisons 4 barrettes de 4 Go de DDR4-2400 15-15-15-35. Commençons d'abord par les applications, nous normalisons à 100 les performances HT/SMT désactivé, et dans le cas du 1800X, nous ajoutons les performances en désactivant le Core Parking. Vous retrouverez l'explication de ce que cela signifie sur la page suivante : D'abord on notera que globalement, toutes les applications de notre protocole profitent du SMT/HT, et certaines massivement ! Adobe Lightroom et x265 étant les deux applications qui en profitent le moins. L'autre point à noter est que si l'on met de côté le cas particulier de 7-Zip et WinRAR (nous reviendrons sur leur cas !), en règle générale l'activation du SMT apporte de plus gros gains chez AMD que chez Intel. Sur la moyenne, on note que l'on gagne 22.47% chez Intel, et 25.6% chez AMD ce qui est appréciable (on monte à 28% avec le Core Parking désactivé). Si les applications en profitent, quid des jeux, généralement moins fans de cette technologie ? Les jeux ont rarement profité de cette technologie associée à un nombre de coeurs élevés, et en pratique nos tests du jour montrent que la situation n'a pas vraiment changée. Même chez Intel, on perd 2% de performances sur la moyenne avec l'HyperThreading actif. Mais dans le cas d'AMD l'écart est plus large avec les réglages Windows par défaut : sur la moyenne on dépasse 7% de pertes de performances à cause de l'activation du SMT. Comme vous le verrez sur la page suivante, la cause de cet écart est surtout liée à un réglage de Windows. Si on aligne le traitement de Zen sur celui appliqué aux processeurs Intel, on retrouve un impact beaucoup plus proche entre l'HyperThreading d'Intel, et le SMT d'AMD ! Nous verrons aussi que dans certains cas, la détection du SMT n'est pas correcte dans les jeux actuels ce qui désavantage le SMT d'AMD. Nous avons décrit en long et en large notre protocole dans cet article, et celui-ci où vous pouvez même le voir en action en vidéo. Nous utilisons Windows 10 Anniversary Update pour réaliser nos tests, et si nous modifions certaines choses (nous désactivons des services inutiles et des choses qui qui pourraient ralentir de manière aléatoire les benchmarks et fausser les écarts), nous conservons les options importantes par défaut. L'une d'entre elle est le mode de gestion de l'alimentation (Power Plan en anglais). Il vous est peut-être arrivé de passer par ce panneau, notamment pour changer le temps avant la mise en veille de l'écran et du PC. Par défaut, après une installation de Windows (y compris sur desktop), c'est le mode "Balanced" qui est actif : 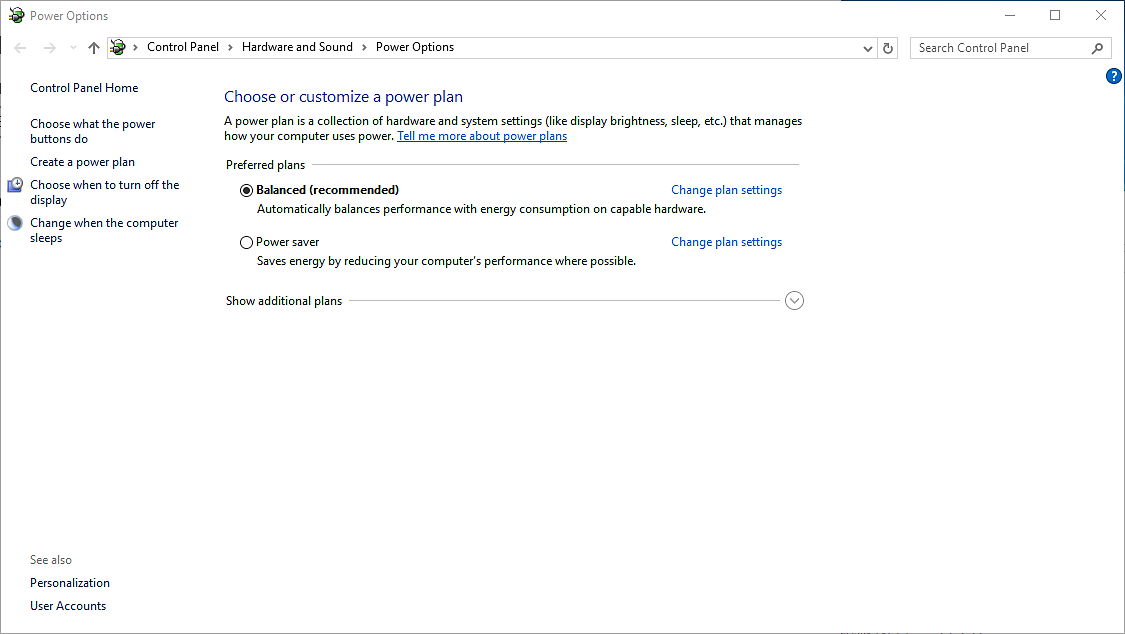 Microsoft n'y va pas dans la subtilité puisque le mode "Balanced" est affiché en gras, en plus d'une mention "recommended" entre parenthèses ! On voit un autre mode, "Power saver" (dédié plus spécifiquement aux portables) et c'est tout. Il y a cependant un autre mode, caché derrière "Show additional plans" : le mode "High Performance". Pourquoi ce profil est-il caché par Microsoft ? Pour de bonnes raisons, il désactive la plupart des mécanismes d'économie d'énergie gérés par logiciel sur les composants du PC, avec ces impacts côté processeur :
D'un point de vue technique les P-States sont désactivés côté logiciel. Dans le cas de notre 1800X, cela veut dire être bloqué à 3.7 GHz au minimum (le plus petit P1, soit la fréquence en charge sur tous les coeurs dans le cas du 1800X), quelle que soit la charge. Les C-States sont par contre eux toujours actifs. L'impact sur la consommation côté processeur en cas de scénario "simple" tel que le repos pur et dur est très léger, à peine 2w, mais dans des cas de charge mixte il peut être un peu plus important. En pratique, ce mode n'a aujourd'hui qu'un impact mesuré sur les processeurs modernes en termes de performances. C'est pour cela qu'il n'est pas recommandé, même s'il reste disponible. AMD lui-même recommande bien évidemment aux utilisateurs d'utiliser le mode "Balanced". Cependant, le constructeur a suggéré aux testeurs en début de semaine de ne pas utiliser le mode "Balanced", mais d'utiliser le mode "High Performance". Nous avons été particulièrement surpris par cette suggestion d'AMD. L'argument du constructeur (dans un premier temps) était de dire que le mode High Performance permettait le changement de P-State (le couple tension/multiplicateur qui détermine la fréquence de la puce) en une milliseconde, contre trente millisecondes en mode "Balanced", sa gestion n'étant en fait pas désactivée mais déportée du logiciel au matériel. Ce type d'assertion est particulièrement complexe à vérifier avec les outils dont nous disposons, la plupart des outils de monitoring n'ont pas la précision suffisante pour voir le changement avec une telle granularité. Plus gênant, cet argument ne colle pas avec les présentations techniques d'AMD à propos de Precision Boost : 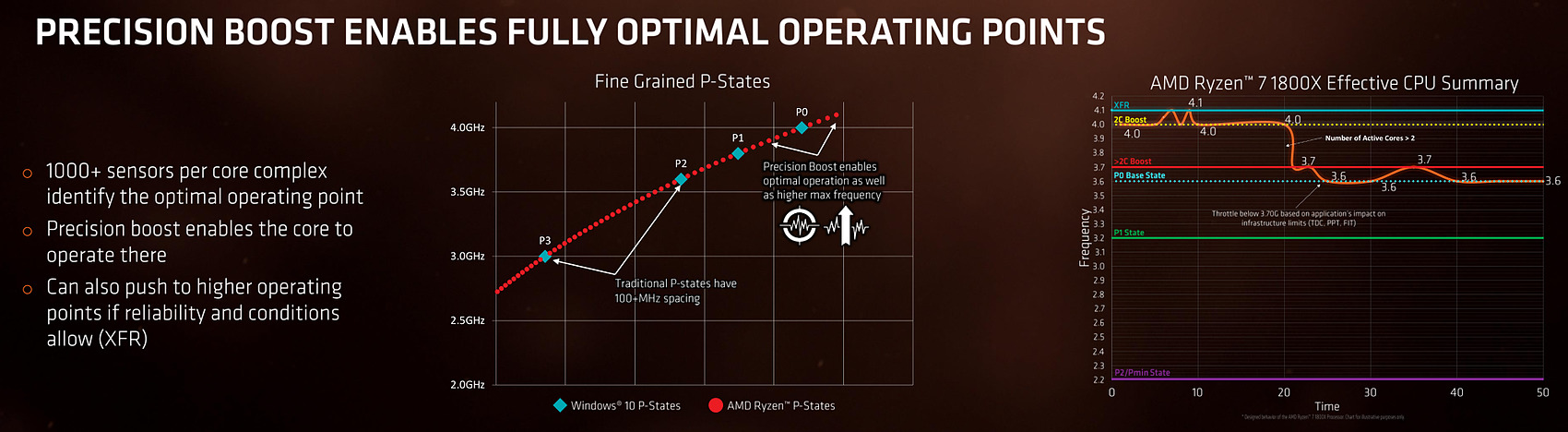 Precision Boost est une gestion matérielle des P-States qui se veut plus fine que celle de Windows. Lors de sa présentation, AMD nous avait indiqué que la fonctionnalité était toujours active et disponible indépendamment du système d'exploitation utilisé. Elle permet notamment une gestion par pas de 25 MHz (ce qui n'est pas impossible avec des P-States classiques), et XFR est bâti sur Precision Boost. Etant donné que XFR est bien actif en mode "Balanced", et que nous constatons des coefficients multiplicateurs identiques en pratique dans les deux modes de gestion d'énergie de Windows (y compris des coefficients intermédiaires qui donnent des fréquences comme 3825 MHz), nous avons longuement douté de l'explication donnée par AMD. Un lien avec le SMT ?Dans le doute ces derniers jours nous avons voulu comparer tout de même le mode "High Performance" au mode "Balanced" dans les jeux, pour voir si l'on pouvait constater quelque chose : Vous retrouvez en bleu les résultats en mode "Balanced" et en orange en mode "High Performance", dans les deux cas nous testons avec et sans SMT actif. Vous remarquerez d'abord qu'à la marge d'erreur près, les performances avec le SMT désactivé sont identiques à celles en mode "Balanced" et en mode "High Performance". Si, comme le disait AMD, le mode "High Performance" apportait un gain de rapidité au niveau du changement de P-State, on pourrait s'attendre à des gains aussi avec le SMT désactivé. Ce n'est pas le cas. Lorsque l'on active le SMT, on voit effectivement une différence :
On mettra de côté Civilization VI pour qui les choses ne changent pas quel que soit le mode. La similarité de performance dans les quatre premiers titres avec ce que l'on retrouve avec le SMT désactivé est assez troublante. Et l'on notera que Total War Warhammer en version 1.6.0 s'est aligné sur ces derniers. Pour rappel, un des points que nous avions relevé dans notre analyse du comportement du SMT à 3 GHz, était que si l'on gagnait massivement dans le cas des performances applicatives (+25.6%), on perdait par contre 8.9% dans les jeux. Si perdre dans les jeux avec l'HyperThreading n'est pas une nouveauté - cela à longtemps été le cas avec les architectures Intel - de nos jours cela ne semblait plus être le cas. Dans notre comparaison, on notait que l'on perdait à peine 2% chez Intel, loin de ce que l'on trouve chez AMD et même si les implémentations sont différentes chez les deux constructeurs, l'écart est sensible. Y a-t-il un lien entre le SMT et ce changement de mode ? Dans tous les cas, la piste des P-State nous a paru de plus en plus fausse. Le Core Parking avancé... puis retiré par AMDAprès le lancement, des employés d'AMD ont répondu à quelques questions sur reddit. A la question de savoir pourquoi on voyait de la variabilité dans les tests, trois arguments ont été avancés :
Pour information, le Core Parking est une fonctionnalité au niveau du scheduler de Windows qui va placer en mode C6 (un état de tension minimale) une partie des coeurs lorsque le système est peu chargé. L'idée étant par la suite de privilégier les coeurs déjà actifs pour répartir les charges, plutôt que de réveiller de nouveaux coeurs sauf si cela est nécessaire. La description sur le site de Microsoft est assez succincte. Microsoft utilise le terme de coeurs "logiques", laissant penser que le Core Parking pourrait justement être lié au SMT et à l'Hyper Threading et que la technologie désactiverait ces coeurs logiques en priorité. Nous avons donc demandé une clarification à AMD, ce qui a eu pour conséquence que le commentaire soit édité aussitôt sur reddit : 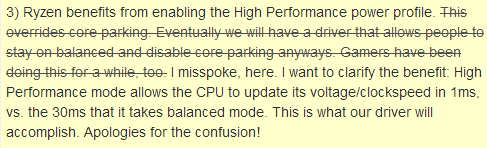 On revient donc à l'explication précédente... Après avoir tenté en vain de trouver une raison à la différence de performances entre les deux modes, nous sommes revenus au Core Parking, comment est-il réglé dans les deux modes pour un Ryzen ? Vous pouvez voir comment est réglé actuellement le Core Parking sur votre machine en utilisant la commande En mode "High Performance", cette valeur (Processor performance core parking min cores) est réglée sur 100 : aucun coeur n'est parqué. En mode "Balanced", elle est réglée... sur 10 ! 90% des coeurs sont donc parqués par défaut. Est-ce anormal ? Pour en avoir le coeur net nous avons regardé sur une config Intel en X99. En mode "Balanced", la valeur par défaut est de 100 : le Core Parking est bel et bien désactivé ! Dans le doute, nous avons réalisé une installation "fraîche" de Windows 10 Anniversary Update sur les deux plateformes, et nous confirmons : sur Ryzen, le Core Parking est réglé à 10%, et sur un 6900K à 100%. Il semble probable que Microsoft ait désactivé le Core Parking sur les dernières générations de processeurs Intel et qu'il n'ait pas encore fait cette modification pour le tout nouveau Ryzen. Reste la question, pourquoi le Core Parking n'est-il pas si pénalisant sur Ryzen lorsque l'on désactive le SMT ? Après vérification, dans ce cas aussi, le Core Parking est réglé à 10%. L'impact n'est cependant pas le même. Et cela tient à deux facteurs selon nous.
On voit donc assez facilement la différence : lorsque le SMT est actif, le scheduler Windows va tenter d'empiler les threads sur les coeurs disponibles, ce qui veut dire risquer de saturer les deux threads logiques d'un même coeur. A l'inverse, si le SMT est désactivé, Windows n'active et ne désactive que des coeurs indépendants, et l'impact disparaît. Cela explique aussi pourquoi AMD a suggéré juste avant le lancement d'utiliser le mode "High Performance", même si sa raison n'était pas la bonne. Reste la question principale : les performances suivent-elles ? Oui... Et c'est même légèrement mieux puisque dans Project Cars, on retombe sur des performances proches du mode SMT désactivé, contrairement au mode Performance. Trois jeux dénotent : Total War Warhammer en version 1.5.0 (la version 1.6.0 corrige le tir), F1 2016 dont nous savons désormais qu'il ne détectait pas correctement le SMT sur Ryzen, et Watch Dogs 2. L'écart de performances noté sous TotalWar Warhammer et Watch Dogs 2 reste par contre présent. En résuméNous comprenons désormais un peu mieux pourquoi AMD met en avant la question du mode "High Performance" sous Windows 10 : un réglage trop agressif du Core Parking de Windows par défaut sur Ryzen provoque une perte de performances dans les jeux. Cela ne compense pas l'intégralité du déficit de performances que nous avons constaté entre le mode SMT actif et inactif, mais une bonne partie. En attendant un patch de Windows, les possesseurs de Ryzen pourront tout simplement rester en mode Balanced pour profiter des modes d'économies d'énergie, en désactivant simplement le Core Parking. Le logiciel Park Control permet de le faire simplement. Reste que l'on ne peut pas s'empêcher de se dire qu'AMD a clairement eu un gros raté sur sa communication. En annonçant un argument inexact, puis le bon avant de revenir encore dessus, AMD ne s'est pas facilité la vie, et n'a pas facilité la notre en nous obligeant à déchiffrer leur communication. Afin de vous proposer les résultats les plus équitables possibles, nous avons ajouté dans les pages jeux les résultats du Ryzen 7 1800X avec le Core Parking désactivé. Nous avons également supprimé les scores en SMT Off pour plus de lisibilité. Pour overclocker Ryzen, on pourra passer au choix par le BIOS, ou par une nouvelle application proposée par AMD baptisée Ryzen Master. 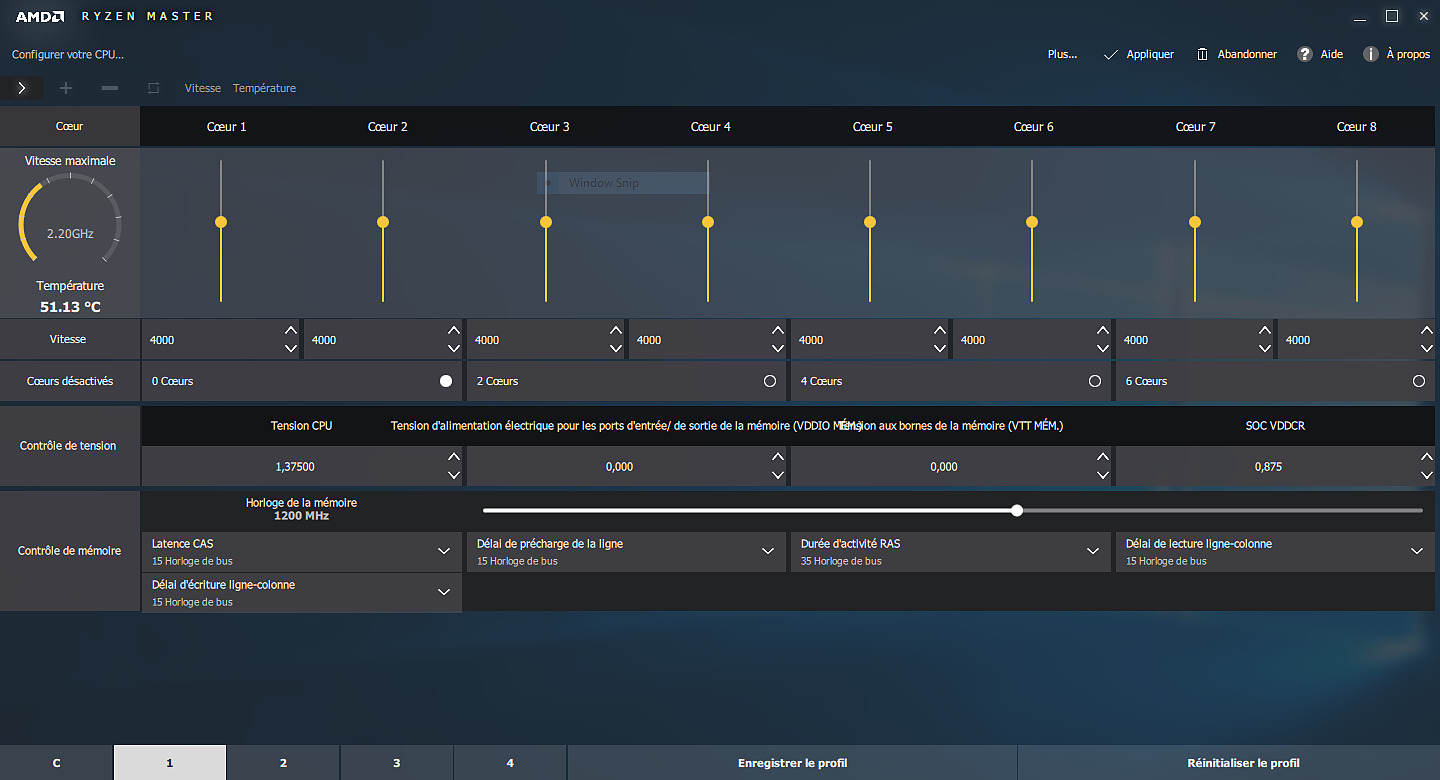 Elle permet - outre des fonctionnalités de monitoring - de régler la fréquence des coeurs, d'en désactiver (par paire) et de jouer sur un certain nombre de tensions. L'overclocking de la mémoire est également possible. Certains réglages (désactivation des coeurs, mémoire) réclament un redémarrage. Que l'on passe par le BIOS ou par l'application, il faudra régler le coefficient multiplicateur avec une granularité de 25 MHz. La fréquence de référence, 100 MHz par défaut, est modifiable mais attention celle du PCIe par exemple y est liée ce qui peut entrainer des instabilités : il est donc plus sûr de se contenter d'un overclocking par coefficient. En pratique le fonctionnement de Ryzen est assez particulier. Pour atteindre les 4/4.1 GHz sur un coeur, AMD est obligé de pousser très en avant la tension comparativement à la charge sur tous les coeurs. Ainsi, vous l'avez vu un peu précédemment, là où 1.2V suffisent pour atteindre 3.7 GHz sur 8C en fonctionnement normal, il faut dépasser les 1.4V pour tenir sur un coeur à 4.1 GHz. Techniquement, la tension demandée est de 1.35V mais la carte mère Asus que nous utilisons applique un offset. En pratique AMD ne recommande pas de pousser la tension, et indique que pour un overclocking sur le long terme une tension de 1.35V est acceptable dans ses guides, à l'oral il a même été question d'une limite à 1.40V. Il précise au passage que 4.2 GHz à 1.45V sont atteignables par la majorité des processeurs mais que cette tension peut atténuer la longévité des processeurs selon leurs simulations. Pour l'instant notre expérience d'overclocking reste assez limitée et étant donné le potentiel léger annoncé et les tests qu'il nous reste à réaliser, nous n'avons pas poussé très haut. Comme toujours nous vous rappellons que nous vérifions la stabilité des overclocking sous Prime95 en mode FFT 256k. Il est très facile d'atteindre des fréquences plus hautes qui seraient instables sur ce test. Nous utilisons un radiateur Noctua U12S-SE en version AM4 pour le refroidissement. 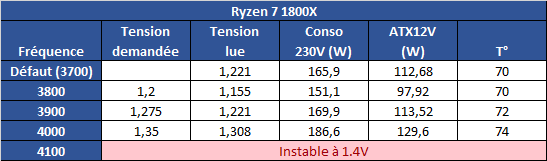 Atteindre 4 GHz sur tous les coeurs est relativement aisé sur notre modèle de test, avec une tension contenue. En réclamant 1.35V de manière continue (ce qui se traduit, offset et Vdroop oblige, par une tension lue de 1.308), on reste stable sous Prime95. La température, déjà haute à la tension par défaut, monte un peu plus mais AMD a confirmé qu'il applique lui même un "offset" de 20°C sur les modèles X de sa gamme. La raison de l'offset est inconnue, mais on notera que les constructeurs de cartes mères ne semblent avoir été prévenus (le ventilateur tourne en fonction de ces températures)... ni les développeurs de Ryzen Master qui indiquent eux aussi cette température comme si elle était réelle. 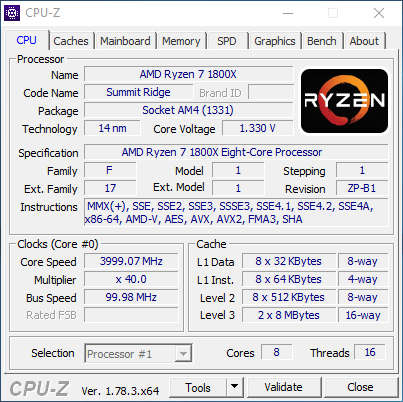 En demandant 1.4V dans Ryzen Master, les 4.1 GHz ne sont pas tenus de manière stable. Nous reviendrons ultérieurement sur la question ! Notez enfin que l'IHS est soudé : n'essayez pas de le retirer ! On ne peut que saluer ce choix de la part d'AMD qui garantit une meilleur conductivité thermique que la pâte thermique utilisée sur LGA 115x chez Intel ! Performances sous x264Nous commençons par les mesures de performances sous x264, la mesure est effectuée sur un thread, et sur le nombre maximal de thread présent sur le processeur : On notera rapidement les excellentes performances du 1800X sous ce benchmark. ConsommationRegardons maintenant la consommation, nous la mesurons à la fois à la prise ainsi que sur l'ATX12V : [ ATX12V (W) ] [ 230V (W) ] Plusieurs constatations s'imposent. D'abord quand on regarde la consommation au repos, la plateforme AM4 s'approche plus de la plate-forme Intel grand public que du X99 dont les processeurs ont tendance à beaucoup consommer au repos. En charge, la consommation du 1800X sur un coeur est assez légère, à mi-chemin entre un 7700K et un 6900K. En charge complète sous x264 la consommation est par contre nettement plus élevée, AMD se plaçant cette fois à mi-chemin entre le 5960X et le 6900K, ce qui est tout de même très bon mais plus élevé que ce que laissait penser son TDP de 95w qui est clairement dépassé. Notez enfin que désactiver le Core Parking n'a pas d'impact sur nos mesures de consommation. Efficacité énergétiqueNous calculons l'efficacité en croisant la consommation ATX12V et les performances x264 : A l'ATX12V, sur un thread, Ryzen fait nettement mieux que les plateformes X99, profitant d'une consommation au repos plus basse. De la même manière cet écart se retrouve lorsque tous les coeurs sont stressés, le Ryzen R7 ayant une efficacité qui s'approche de celle de Broadwell-E (entre le 6800K et le 6900K) et clairement au-dessus d'Haswell-E. On est plus proche de l'efficacité d'un 6700K en pratique, ce qui est plutôt bon (on note au passage que Kaby Lake, la version overclockée de Skylake, ne fait pas de miracle et paye cher ses MHz supplémentaires sur la consommation et l'efficacité !). L'avantage est plus net sur le 230V, Broadwell-E consommant peu en charge en comparaison d'Haswell-E, mais la hiérarchie est sensiblement équivalente. Globalement, AMD n'a pas à rougir de l'efficacité de Ryzen. Et encore une fois, quand l'on considère le process 14nm de GlobalFoundries utilisé, par rapport au 14nm, rôdé, d'Intel, la consommation du Ryzen 1800X est largement satisfaisante même si supérieure à ce que laisse penser son TDP. TDP et TDP...En effet avec une consommation mesurée sur l'ATX12 à 128,9 watts, il est évident que la consommation du Ryzen 7 1800X dépasse les 95 watts annoncés côté TDP (Thermal Design Power). En effet même si on se base sur un rendement de 85% au niveau de l'étage d'alimentation de la carte mère, on arrive presque à 110 watts. Une estimation confirmée par le monitoring interne du processeur qui indique même 112 watts sous x264. 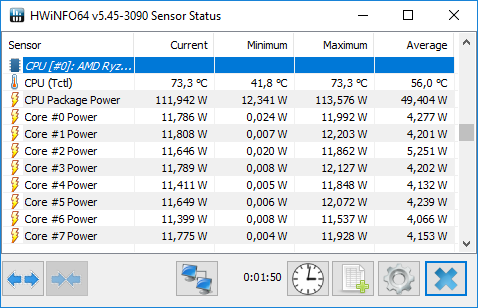 Chez Intel, les limites de consommation relatives au Turbo et le TDP sont identiques, ce qui semble le plus logique puisque chaque watts consommé par le processeur est évacué sous forme de chaleur. Dans de très rares cas ne correspondant pas à une charge réaliste, en charge 100% AVX particulièrement, la consommation peut par contre dépasser cette valeur commune même à la fréquence initiale. Pour Ryzen, AMD utilise une autre formule :
Les trois valeurs à droite sont définies de la sorte :
Pour les 1800X et 1700X, ces valeurs sont respectivement de 60°C, 42°C et 0.189. Pour le 1700, on est à 72,3°C, 42°C et 0.451. La formule donne donc respectivement 95.23W et 64.96W. Si la mise en relation de toutes ces valeurs est logique lors de la définition de spécifications thermique, AMD profite à notre sens de l'absence de norme pour définir ce que doit être le TDP d'un composant. Ce qui résulte de cette formule n'est pas un TDP au sens habituel du terme mais le nombre de watts du processeur qu'il faut dissiper (et donc qu'il peut consommer) afin de maintenir son niveau de performance maximal dans certaines conditions. Quels sont alors les TDP, au sens de la limite de consommation et donc du nombre de watts maximum à dissiper, des Ryzen ? AMD communique également cette valeur, de manière moins marquée : 128 watts pour les 1800X/1700X, et 90 watts pour le 1700. Ce sont ces valeurs qui sont les plus comparables avec le TDP communiqué par Intel.  Pour rappel, ce protocole introduit plusieurs changements, à commencer par l'utilisation de Windows 10 dans sa version "Anniversary Edition". Afin de limiter la variabilité durant les tests, nous désactivons un maximum de tâches, services, et fonctionnalités qui peuvent se déclencher de manière intempestive. Nous vous renvoyons à l'article ci-dessus pour plus de détails. Pour la partie processeur, les tests utilisés sont :
Tous les benchs applicatifs sont lancés deux fois, le système étant redémarré au milieu. Notre protocole est pour rappel automatisé. Nous prenons le meilleur score des deux runs, en pratique la marge d'erreur est très faible. Lightroom, ayant un peu plus de variabilité, est lancé quatre fois. Et les jeux !La seconde partie de notre protocole concerne les jeux et là aussi nous avons renouvelé notre sélection de titres. Les jeux modernes ont beaucoup changé dans leur comportement. Si historiquement les jeux étaient souvent limités par les performances sur un coeur (et donc par la fréquence), de plus en plus de titres tirent partie du multithreading au point que la fréquence n'est plus forcément le facteur limitant. Nous verrons au cas par cas ce qui se passe dans ces jeux. Un des critères pour l'inclusion dans notre protocole est que le processeur joue un rôle ! Il nous parait strictement inutile de vous montrer des benchmarks où tous les processeurs produisent, à la marge d'erreur près, le même nombre d'images par seconde tout simplement parce que la carte graphique est le facteur limitant. Il est très facile de vous montrer, par exemple en montant la résolution, que deux processeurs font "jeu égal". Cela ne nous parait pas une bonne méthode. Nous avons donc cherché des jeux modernes où le processeur joue un rôle. Dans tous les cas nous utilisons une scène gourmande pour le processeur, et si possible reproductible (l'intelligence artificielle, tout comme certaines générations aléatoires peuvent ajouter une dose de variabilité dans certains titres). Nous décrivons dans chaque cas l'endroit où nous effectuons nos mesures et si nous avons cherché des endroits dans les jeux où le processeur est le plus limitant, les scènes choisies restent représentatives de l'expérience. Côté sélection, nous avons donc retenu :
Chaque test est effectué en tout 15 fois (trois fois 5 tests, avec un redémarrage au milieu). Nous vous indiquons la moyenne des 15 résultats. Configurations de testPour être le moins limité possible par la carte graphique, nous avons opté pour une GeForce GTX 1080. Nous overclockons cette dernière légèrement (+100/+400 MHz) tout en utilisant un profil de ventilation très agressif pour limiter l'impact de la variabilité du Turbo Boost 3.0. Nous utilisons les pilotes GeForce 378.49 pour nos tests. Nous utilisons côté plateformes :
Côté mémoire, nous utilisons 16 Go de RAM sous la forme de 4 barrettes. Selon ce que supportent les plateformes, il s'agit de :
Enfin, pour être complet, nous utilisons un bloc d'alimentation Seasonic Platinum 660 (80 Plus Platinum). Passons enfin aux performances ! 7-Zip 16.04 Nous compressons un répertoire d'Arma II (un peu plus de 3.5 Go) avec le logiciel de compression 7-Zip. Nous utilisons l'algorithme de compression le plus performant, à savoir le LZMA2 en mode maximal (9). Nous commençons par un des tests qui semblait particulièrement difficile dans les pages précédentes pour Ryzen. Si en pratique le 1800X reste plus rapide de 15.6% que le 7700K, le gain reste limité quand l'on considère le nombre de coeurs doublé. La plateforme X99 d'Intel profite également de la mémoire sur quatre canaux ce qui l'aide quelque peu. L'écart pratique avec le 6900K est de 30%, un écart qui se réduit de 5% avec le Core Parking désactivé. WinRAR 5.40 Nous compressons toujours un répertoire d'Arma II, mais ce dernier est un peu plus gros (7.5 Go, il inclut des extensions). Nous jouons sur la quantité de fichiers pour obtenir des temps de benchmarks satisfaisants, il ne s'agit en aucun cas de comparer directement les deux logiciels (une comparaison de la taille des fichiers obtenus s'imposerait). Nous utilisons le mode de compression Ultra qui tire partie du multithreading. L'autre logiciel de compression phare propose là aussi un profil de performance similaire, le Ryzen 7 1800X faisant tout juste jeu égal avec les meilleurs quad core d'Intel. L'écart avec le 6900K est de 37% (un peu moins de 36% avec le Core Parking désactivé). Visual Studio 2015 Update 3 Nous compilons les bibliothèques C++ Boost avec le compilateur de Visual Studio 2015 Update 3 en édition Community. La compilation est moins sensible au sous-système mémoire que les logiciels de compression de fichiers, et cela se voit ! Ici le Ryzen 7 1800X vient se placer beaucoup plus proche du 6900K, l'écart n'étant que de 9% avec les réglages Windows par défaut, et il se réduit de moitié avec le Core Parking désactivé. On notera la division par deux du temps de compilation par rapport au FX-8350 ! Par rapport au 7700K, Ryzen apporte un temps de compilation inférieur de 24%. MinGW 64/GCC 6.2.0 Nous compilons là aussi les bibliothèques C++ Boost avec la version 6.2.0 de GCC sous l'environnement MinGW 64. L'écart se resserre encore plus sous GCC où l'avantage du 6900K n'est plus que de 6% par rapport au Ryzen 7 1800X qui se permet de battre le plus gros des Haswell-E, le Core-i7 5960X. x264 r2744 Nous encodons un extrait de Blu-Ray (1080p) d'une minute environ ayant un débit moyen de 23 Mbps. La version de x264 (64 bits) utilisée est compilée par komisar avec GCC 4.9.2. Nous utilisons le preset slower sur un encodage mode CRF (facteur 20) avec les optimisations ssim et psnr activées. Une version récente de FFmpeg officie comme serveur d'image. Les options exactes utilisées sont :
Si l'architecture Zen brille dans un bench, c'est définitivement dans x264. Cette version qui ne dispose pas encore d'optimisations spécifiques pour Ryzen permet au 1800X d'être 9% plus performant que le 6900K d'Intel, tutoyant même le trop cher Core i7-6950X. Le Core Parking n'a pas d'impact ici. x265 2.1 (18/12)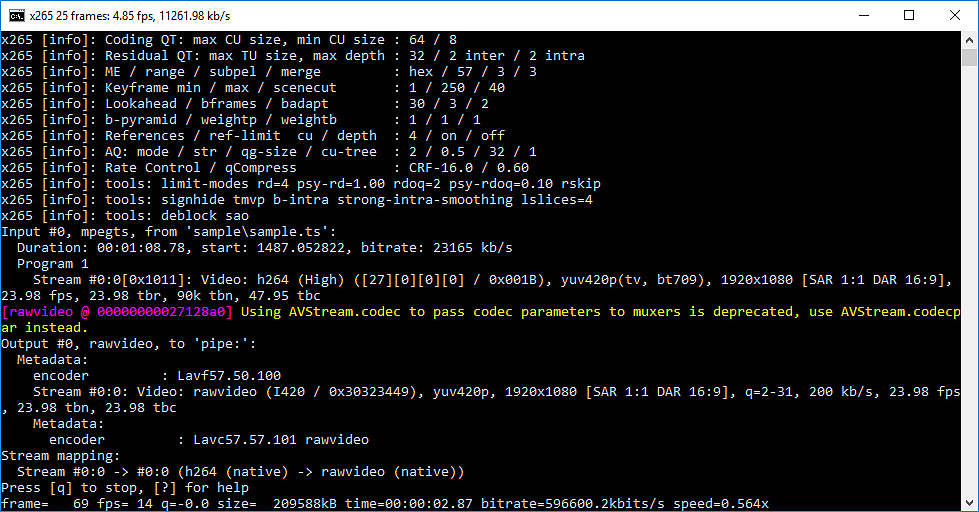 Nous encodons le même extrait de Blu-Ray avec une version de x265 (64 bits) cross-compilée avec MinGW . Nous utilisons le preset slower sur un encodage en mode CRF (facteur 16) en activant des optimisations psychovisuelles. Les options utilisées sont :
Sous x265, l'écart se renverse, le 6900K reprenant notamment grâce à l'AVX2 un avantage de 6% par rapport au 1800X (2.5% avec le Core Parking désactivé), qui reste tout de même devant le 5960X d'Intel. A noter qu'avec notre source 1080p, x265 n'exploite de base pas pleinement les processeurs 8 et 10 coeurs, ce qui sera le cas avec une source 4K. Stockfish 8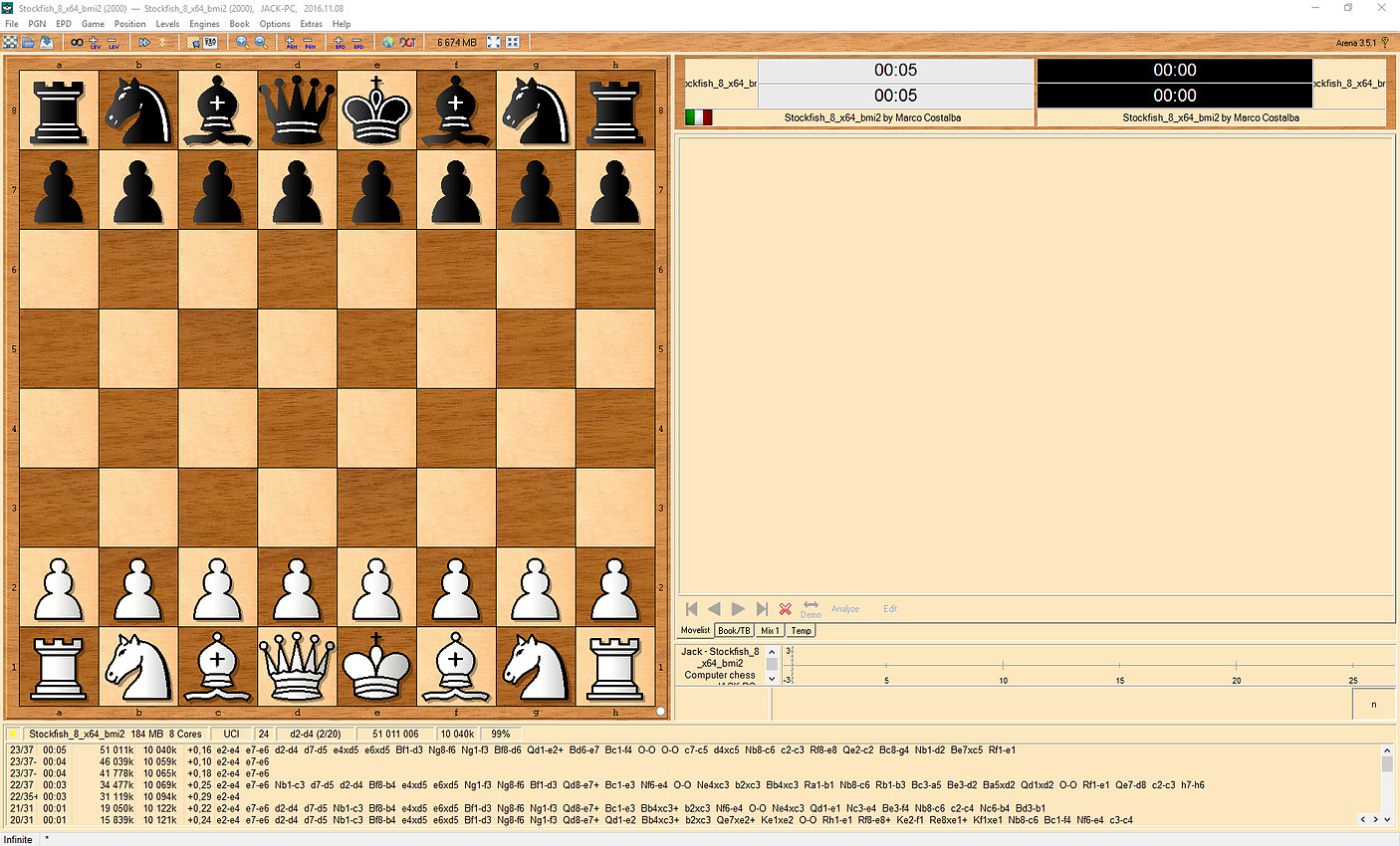 Nous utilisons la dernière version en date du moteur d'échecs open source Stockfish, l'un des deux meilleurs moteurs du moment. Trois exécutables sont disponibles, une version basique 64 bits, une version SSE4 (popcnt) et une version BMI (Haswell et supérieurs). Nous lançons les trois versions à la suite et récupérons le meilleur score des trois. Nous laissons tourner le moteur jusqu'au 31ème tour en début de partie, puis nous notons la vitesse, exprimée en Kilonoeuds par seconde Le test est réalisé dans l'interface Arena en version 3.5.1. Sous Stockfish, le Ryzen 7 1800X se place 3.6% devant le 6900K, là aussi un très bon score. Le SMT permet à AMD de gagner 39% de performances en plus dans ce test, un gain massif qui confirme le potentiel côté IPC de l'architecture Zen. Komodo 10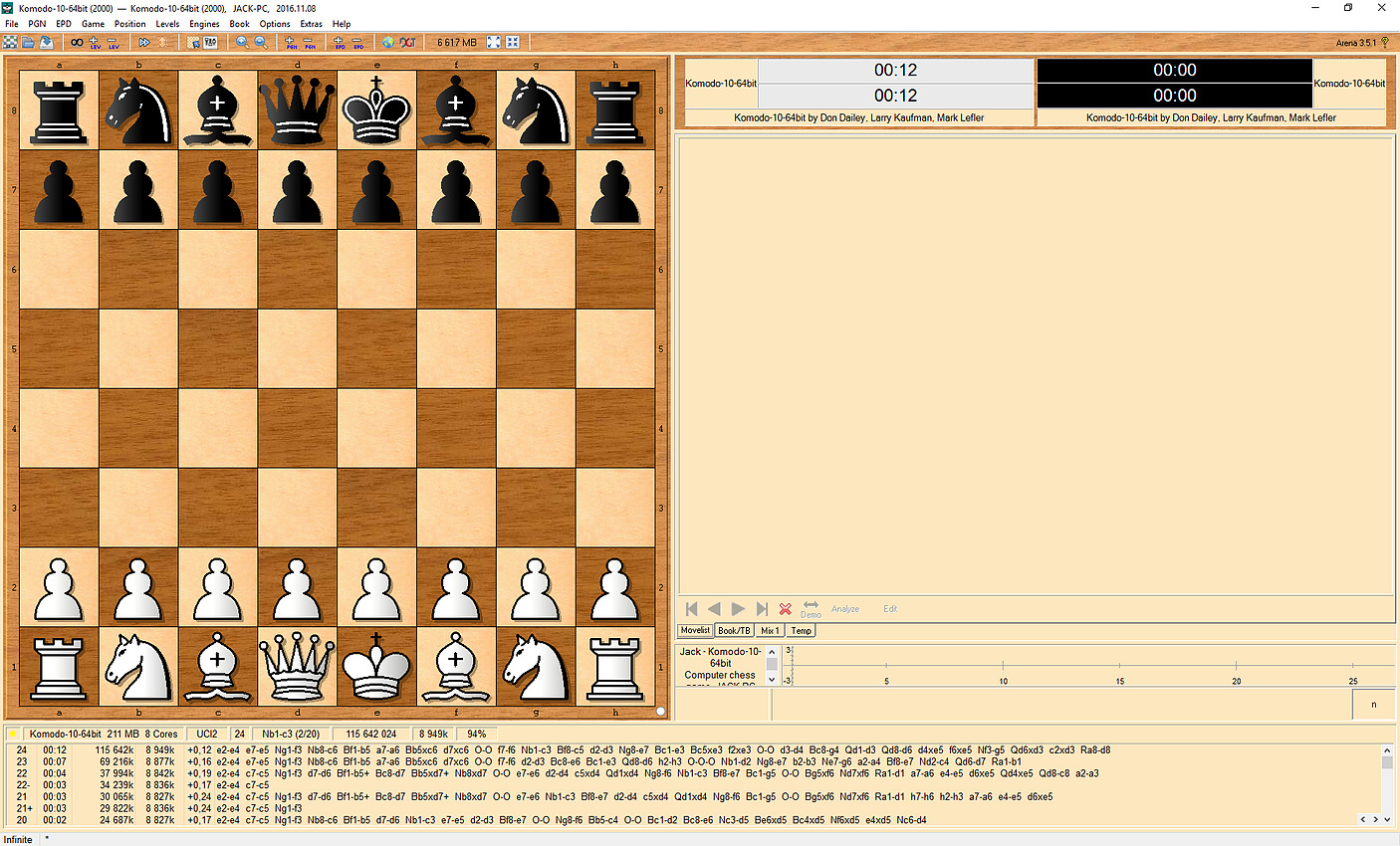 L'autre moteur que nous testons est Komodo. Ce moteur commercial est passé devant Stockfish et Houdini dans les derniers classements. Contrairement à Stockfish, un seul exécutable est fourni. Nous utilisons là aussi l'interface Arena pour réaliser le test. Nous laissons tourner le moteur jusqu'au 29ème tour en début de partie, puis nous notons la vitesse, exprimée en Kilonoeuds par seconde. L'écart est encore plus important sous Komodo avec 11.8% d'avance pour le Ryzen 7 1800X face au 6900K. C'est dans ce titre que le SMT apporte le gain le plus net : +42% ! Lightroom 6.7 Nous utilisons la version 6.7 d'Adobe Lightroom. Nous désactivons l'accélération GPU et effectuons des traitements d'export avec notamment une correction d'objectif. Le niveau de multithreading n'a pas beaucoup été amélioré par rapport à l'ancienne version que nous utilisions, nous continuons donc d'effectuer deux exports JPEG en parallèle de deux lots de 96 photos issues d'un Canon 5D Mark II. L'utilisation de deux lots en simultanée semble être plus stressant pour le système mémoire. Sous cette charge lourde sous Lightroom, le Ryzen 7 1800X est 30% plus lent environ que le 6900K. Il reste tout de même plus rapide qu'un 7700K, mais l'on retrouve un profil de performances similaires aux outils de compression de fichiers. DxO Optics Pro 11.2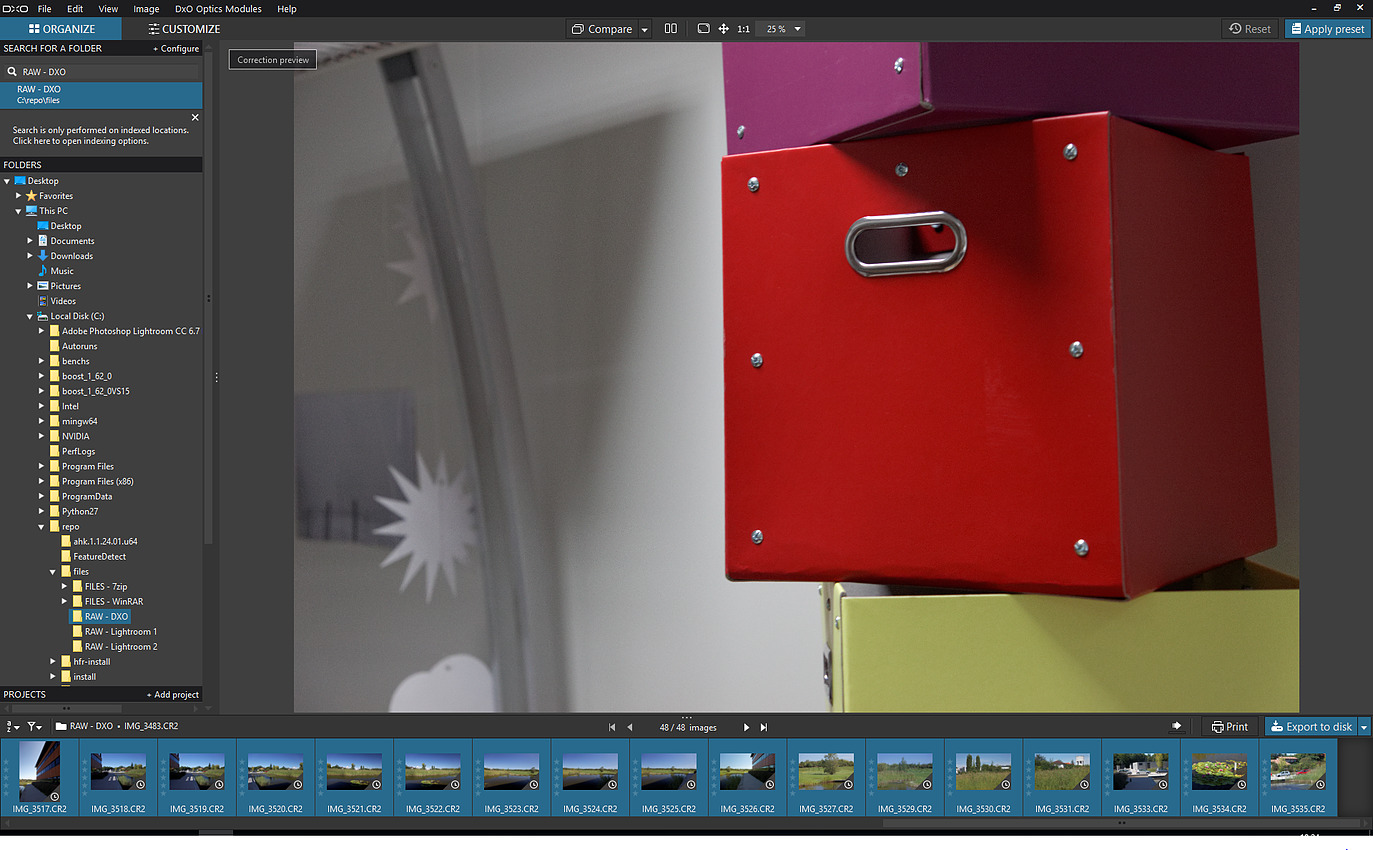 Nous utilisons la version 11.2 du logiciel Optics Pro de DxO. Nous traitons cette fois-ci 48 photos RAW issues d'un 5D Mark II auquelles nous appliquons diverses retouches (compensation d'exposition, réduction du bruit, corrections optiques, etc). Nous réglons le nombre de photos à traiter en parallèle sur le nombre de coeurs physiques présents sur le processeur (le maximum autorisé par le logiciel). Sous DxO, les choses se passent beaucoup mieux pour Ryzen avec un écart de 2% avec le 6900K, devant ou derrière en fonction des réglages Windows. Il est intéressant dans ces deux logiciels de le comparer au FX-8350, le temps de traitement n'est "que" 75% plus élevé sur le FX par rapport au Ryzen dans Lightroom, et 125% plus élevé dans DxO. Mental Ray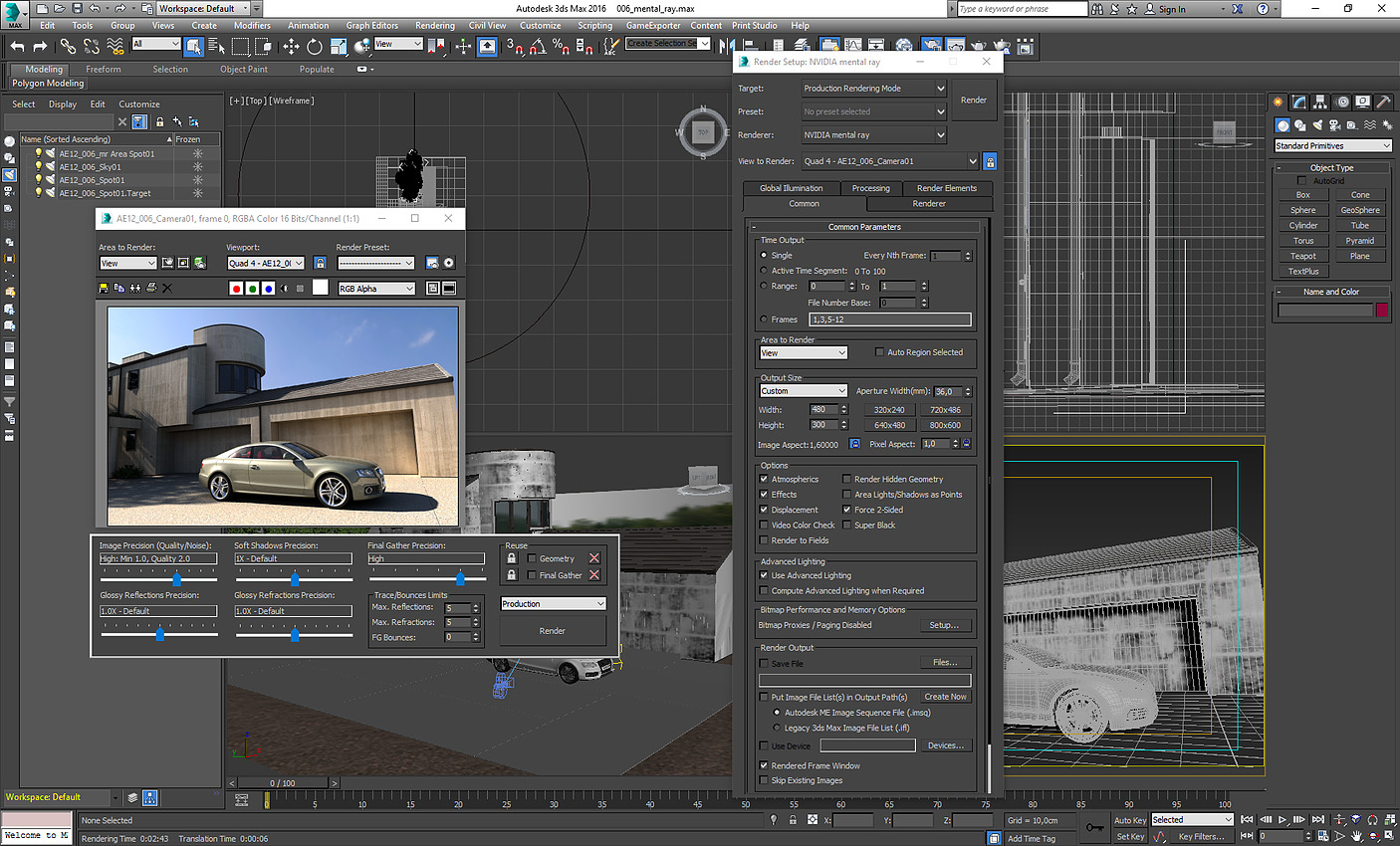 Nous lançons le rendu d'une scène préparée par Evermotion. Nous utilisons la version de Mental Ray incluse dans 3ds Max 2017, le rendu est effectué en 480 par 300 afin de conserver un temps de test convenable. Sous Mental Ray, on retrouve un niveau de performances assez elevé pour le Ryzen 7 1800X qui se place derrière le 6900K de 4% avec le réglage par défaut de Windows 10. C'est encore mieux avec le Core Parking désactivé, on est 2.9% devant. Il est 20% plus rapide que le 6800K et ses six coeurs. V-Ray 3.4Nous utilisons le moteur de rendu alternatif V-Ray, toujours sous 3ds Max 2017 pour rendre une version adaptée de notre scène. Le rendu est effectué cette fois-ci en 1200 par 750. 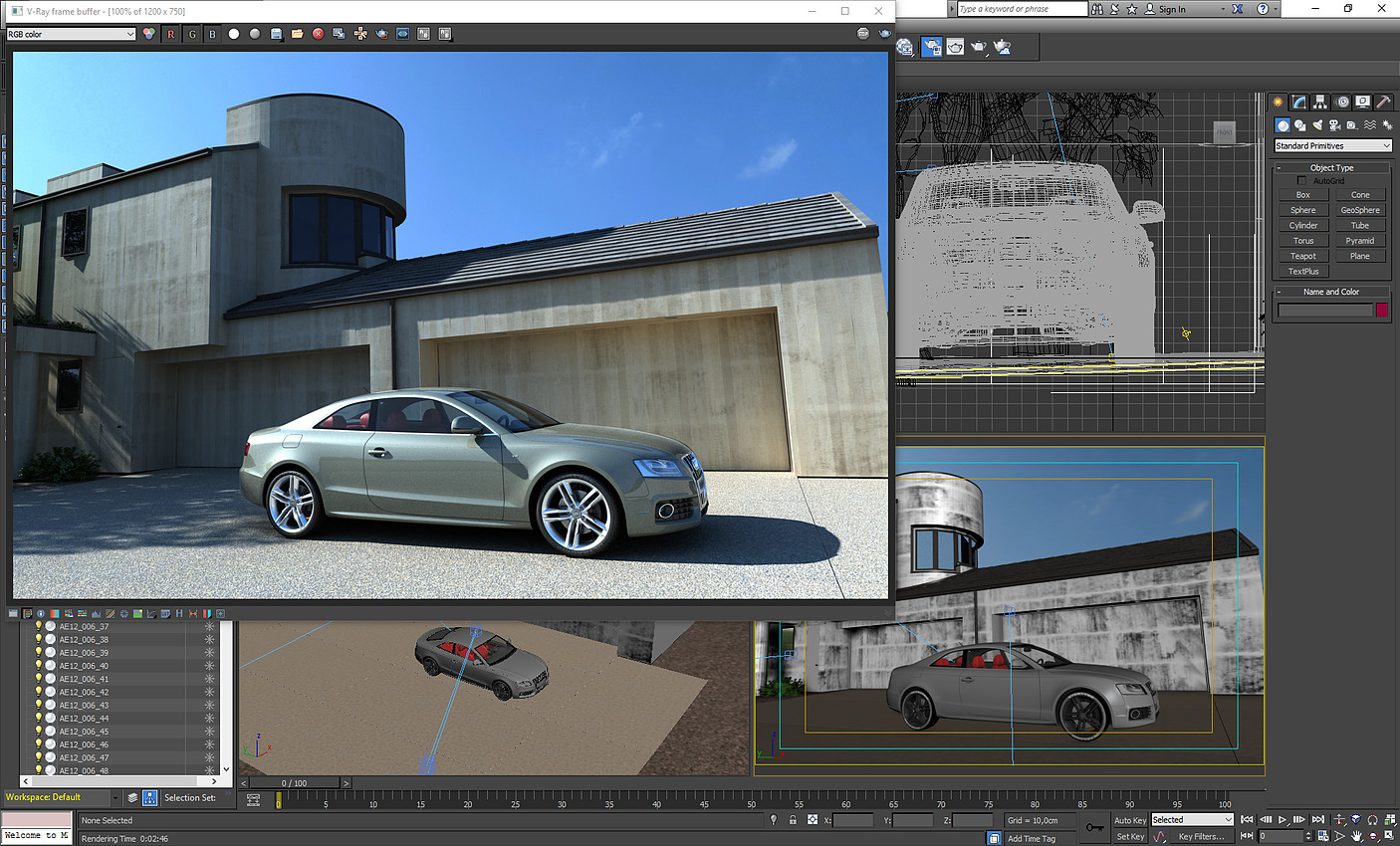 C'est encore mieux pour le Ryzen 7 1800X sous V-Ray, avec un temps de rendu 2% inférieur au 6900K. Ce temps de rendu est divisé par un facteur de plus de 3x par rapport au FX-8350, clairement à la peine dans ce test. Passons maintenant aux performances dans les jeux ! Project Cars Nous regardons les performances sous l'excellent Project Cars, dans sa version 64 bits. Nous mesurons les performances sur 20 secondes lors d'un départ sur le circuit "California Highway Etape 1" dans une course de GT3. Le jeu est réglé en mode Ultra avec l'anti-aliasing désactivé. Dans Project Cars, la fréquence continue de jouer un rôle important même si les meilleurs 8 coeurs ne sont pas très loin. Ainsi, le Core i7-6900K est devant le 6700K par exemple. Pour le Ryzen 7 1800X c'est ici plus difficile même si le niveau d'images par seconde reste élevé. On n'est "que" au niveau d'un Core i7-2600K avec les réglages Windows par défaut, et au niveau d'un Core i7-3770K avec le Core Parking désactivé. F1 2016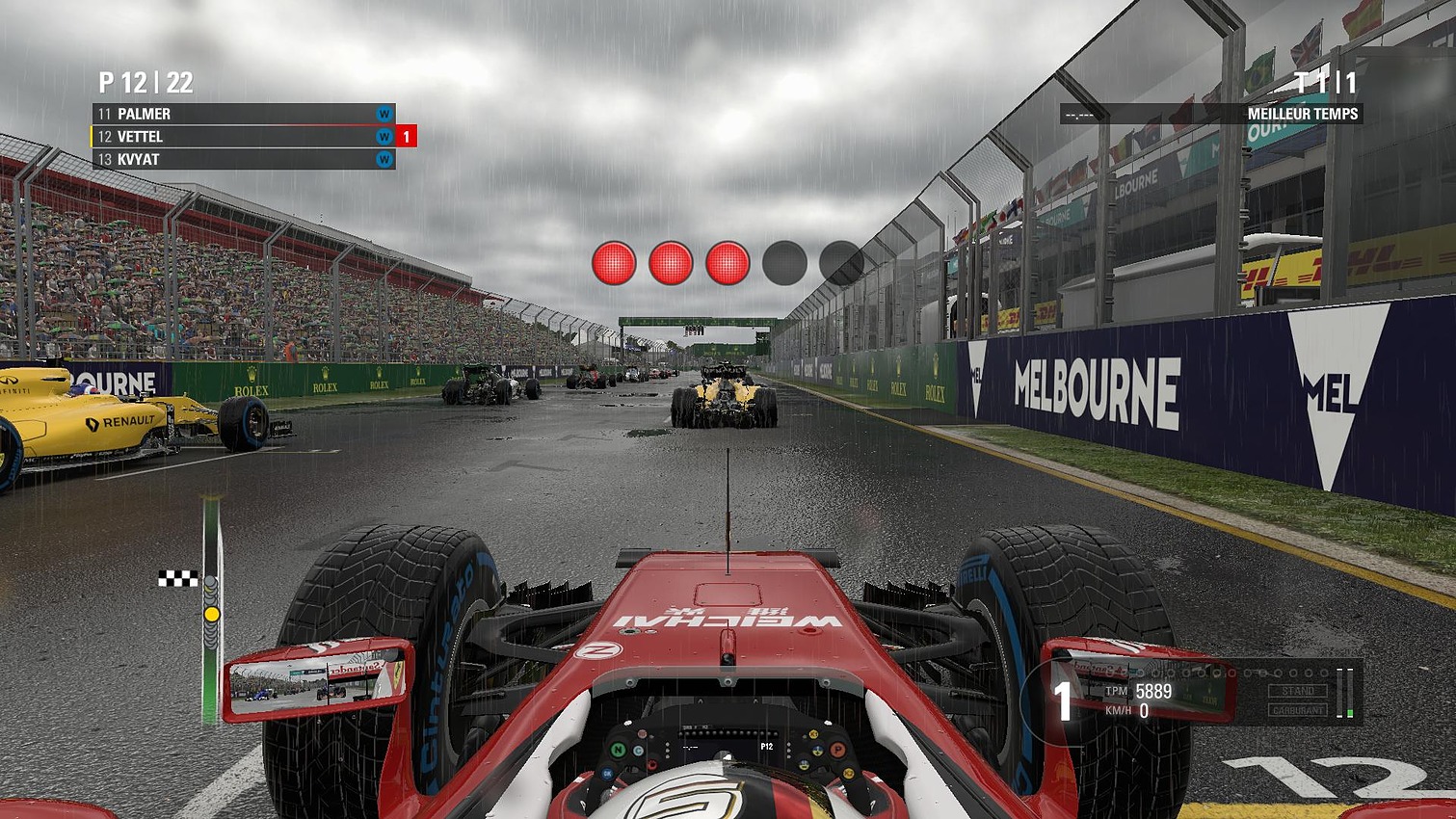 La dernière version en date du jeu de F1 de Codemasters utilise un nouveau moteur plus moderne et mieux threadé. Nous avons modifié le benchmark utilisé après la découverte d'un bug dans notre procédure de test. Une des particularités de F1 2016 est que son fichier de configuration contient le résultat d'une détection du nombre de coeurs. Notre procédure de test copiait ce fichier sans l'adapter, ce qui fait que nos résultats précédents étaient obtenus avec le moteur configuré pour quatre coeurs avec l'HyperThreading désactivé. Cela nous donnait des résultats où l'on était limité par la fréquence, logiquement. Nous mesurons désormais les performances via le benchmark intégré sur le circuit de Melbourne, sous la pluie. Le jeu est réglé en mode Ultra et nous baissons d'un cran les réflexions, baissons au maximum le post processing, le flou et désactivons l'occlusion. Ces options impactent toutes la charge GPU : en les désactivant on se retrouve moins limité par la carte graphique. Notez qu'il serait possible d'être encore moins limité en baissant d'autres options, cependant contrairement à celles que nous avons retenues, elles ont un impact parfois très important sur la charge CPU. Notre réglage tente d'être le plus proche d'une utilisation réelle, pour la question de l'utilisation processeur. Contrairement à ce que l'on pensait, lorsqu'il est correctement configuré, le moteur de F1 2016 n'est pas très limité par la fréquence et est capable d'utiliser un grand nombre de coeurs. Les plateformes 6/8/10C d'Intel sont ainsi toutes devant le 7700K. La correction du bug dans notre procédure de test n'avantage cependant pas Ryzen qui reste significativement derrière les 6900K. Plus intriguant, le Core Parking n'a aucun impact. Comme nous vous l'indiquions un peu plus haut à propos du bug dans notre procédure de test, F1 2016 utilise - généralement - les informations présentes dans le fichier de configuration. Cependant ce n'est pas systématique et dans de rares cas, une nouvelle détection peut être forcée par le jeu. C'est le cas lorsque l'on essaye de forcer "l'HyperThreading" sur le Ryzen : dans tous les cas F1 2016 effectue une nouvelle détection. Et celle-ci est bugguée pour Ryzen avec la dernière version du jeu au moment où nous écrivons ces lignes (1.8.0) :  En théorie, on devrait lire ici 8 coeurs, et l'HT actif (le "stride" correspond à l'espace entre les coeurs physiques et logiques, AMD a opté pour rappel pour une configuration similaire à celle d'Intel sur ce point). Or ce n'est pas le cas, F1 2016 considère tous les coeurs comme égaux ce qui a un impact. Codemasters devrait pouvoir corriger très facilement le problème via un patch. Civilization VI La version VI de Civilization apporte là aussi un nouveau moteur qui a la particularité d'être compatible DirectX 12. Nous utilisons ce mode, le jeu est réglé en Ultra avec l'anti-aliasing désactivé. Nous utilisons le benchmark graphique intégré. Il est à noter qu'un benchmark de l'intelligence artificielle est également présent. Malheureusement, celui-ci montre que cette dernière n'est que peu ou pas threadée, ne réagissant qu'à la fréquence ! Dommage pour les joueurs ! Civilization VI en mode DX12 est clairement plus rapide sur les processeurs 8 coeurs, le 6900K dominant dans ce test assez nettement. Le Ryzen 7 1800X fait une prestation correcte, entre le 6700K et le 7700K. Ces deux derniers ont des performances en retrait par rapport au reste du plateau. Nous avons vérifié de nouveau les performances sur ce titre sur nos plateformes et confirmons le déficit noté, assez surprenant par rapport à Haswell. Total War : Warhammer Ce nouvel opus dans la série des Total War a droit lui aussi à une nouvelle version du moteur graphique de The Creative Assembly. Un mode DirectX 12 est présent, mais il est malheureusement significativement moins performant sur notre GeForce GTX 1080 de test. Nous utilisons donc le mode DirectX 11. Nous mesurons les performances sur la première scène de campagne du jeu. Un benchmark est également intégré au jeu, et s'il semble gourmand à l'oeil, en pratique il ne l'est pas du tout pour le processeur. Extrêmement gourmand, TotalWar Warhammer voit un nombre d'images par seconde assez limité sur nos configurations. En pratique la fréquence reste plus importante que les cores même si ces derniers compensent un peu. Avec le patch 1.6.0, le 1800X passe d'un cheveu devant le 6900K. Grand Theft Auto V Pour la cinquième itération de son jeu phare, Rockstar a proposé un portage PC beaucoup plus intéressant que pour la quatrième version. Le moteur profite en prime bien du multithreading. Nous utilisons le benchmark intégré au jeu, en choisissant la GTA V est capable de profiter de nombreux coeurs, même si la fréquence garde un avantage important. Le 7700K domine dans ce titre mais l'on note que le Core i7-6950X est quasi au niveau d'un 6700K. Le déficit de performances est de 16% pour le 1800X par rapport au 6900K. Il se réduit sous les 10% avec Core Parking désactivé. Watch Dogs 2 Le titre d'Ubisoft dispose lui aussi d'un moteur particulièrement bien threadé. Nous mesurons les performances sur un déplacement dans une zone particulièrement dense et gourmande de la ville. Le jeu est réglé en mode Ultra, nous désactivons le SSAO. Le Core i7-6950X domine ici dans ce titre, une rareté. En pratique le 1800X est derrière le 6900K de 17% environ. Battlefield 1 Ce dernier opus dans la série des Battlefield utilise le moteur Frostbite 3 de Dice. Si ce moteur dispose d'un mode DX12, là encore il est moins performant sur notre GeForce GTX 1080, nous testons donc en DX11. Malgré tout, le Frostbite 3 est très multithreadé. Nous mesurons les performances sur un déplacement prédéfini dans une zone particulièrement gourmande. Le jeu est réglé en mode Ultra, nous réglons le FOV au maximum (105°). Pour éviter la limite GPU, nous désactivons le HBAO et réglons l'éclairage sur élevé, et nous passons le post-traitement en mode normal. Ce moteur gourmand permet là aussi au Core i7-6950X de régner, d'un cheveu, sur le 7700K. Le déficit de performances du 1800X est de 21% environ par rapport au 6900K avec le réglage par défaut de Windows 10, mais il se réduit à moins de 11% une fois le Core Parking désactivé. The Witcher 3 Nous terminons sur le très populaire The Witcher 3 de CD Projekt RED. Nous mesurons les performances sur un déplacement prédéfini en entrant dans une partie gourmande de la ville de Novigrad. On notera une fois de plus un recul de 20% pour le 1800X par rapport au 6900K avec le réglage Windows par défaut. Il se réduit par deux en désactivant le Core Parking. Le bond en avant proposé par AMD face au FX est énorme, et le Ryzen 7 1800X arrive à se placer devant le meilleur des Haswell-E dans les applications, et seulement 8% derrière le 6900K dans le mode de performances Windows par défaut, et 5.4% derrière seulement avec le Core Parking désactivé. Moyenne en jeux 3DLa situation dans les jeux avec une installation Windows par défaut accuse un déficit de 18% de performances en moyenne face au 6900K. Une fois que l'on désactive le Core Parking qui handicape Ryzen, l'écart se réduit et le déficit n'est plus "que" de 14%. Dans tous les cas, le niveau reste très acceptable, et largement au-dessus de ce que proposait AMD jusqu'ici. Si l'on prend en compte le bug que nous avons constaté dans F1 2016, on peut imaginer qu'effectivement l'écart pourrait encore légèrement se réduire. Dans l'absolu, et même si les moteurs améliorent petit à petit leur capacité à exploiter un nombre important de coeurs, la fréquence continue de primer encore un peu sur les coeurs supplémentaires, même si au final un 6900K s'approche très fortement d'un 7700K ! Nous avons souhaité comprendre pourquoi et nous pensons avoir un début de réponse. Les détails qui suivent peuvent paraître complexes et nous nous en excusons, ils sont cependant nécessaires pour expliquer les comportements que nous avons notés. Les benchmarks qui réussissent moins bien à Ryzen (on pense en particulier à 7-Zip et WinRAR, mais aussi aux jeux) ont un point commun : ils sont connus pour être assez sensibles au contrôleur mémoire et à la rapidité des caches. Nous avons donc voulu commencer par regarder la bande passante mémoire obtenue sur trois plateformes :
Pour obtenir un point de comparaison, le 6900K est testé dans deux configurations, avec deux et quatre canaux mémoires actifs. Afin d'obtenir une meilleure lecture, nous cadençons ces puces 8 coeurs à 3 GHz en désactivant SMT et HT sur les plateformes qui en sont pourvues. La mémoire est réglée comme pour tous nos tests précédents, à savoir :
Voici les résultats obtenus. Nous utilisons une version beta de l'excellent Aida64 : 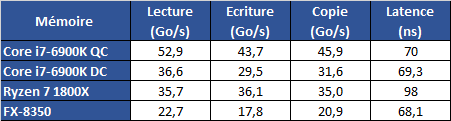 Si l'on compare les bandes passantes sur deux canaux, AMD n'a pas a rougir avec des scores au dessus d'Intel en écriture et en copie, et très proche en lecture. Les problèmes ne viennent donc pas d'ici. La latence par contre dénote, on est ici à 98 nanosecondes, soit une latence 40% plus élevée que celle du 6900K ! Il ne faut pas minimiser cet écart, +28ns est particulièrement élevé et est équivalent à fonctionner avec des timings mémoires très hauts. Pour vous donner un ordre d'idée, passer, en DDR4-2133, de timings 11-11-11 à 15-15-15 rajoute une latence de 4ns. L'impact est donc non négligeable, même s'il n'explique à notre avis qu'une partie du problème. Une latence plus élevée seulement ?Pour en comprendre la raison, il faut revenir à la manière dont Ryzen fonctionne. Vous vous souvenez probablement du fait que Ryzen est composé de deux CCX, les CPU Complex de quatre coeurs, qui incluent chacun leur propre segment de cache L3. Comme nous l'avions pointé un peu plus tôt, ces coeurs ne sont pas interconnectés directement, AMD les relies à un data fabric, un système de bus interne qui va jusqu'au contrôleur mémoire double canal. En pratique, un accès mémoire pour le processeur ne se réalise pas de manière isolée. Lorsque le processeur a besoin d'une donnée, il va commencer par interroger sa hiérarchie de caches, pour voir si la donnée, à jour, est présente. Si c'est le cas, elle va être lue directement et aucune requête mémoire ne sera effectuée. La double partition du L3 de Ryzen complique cependant les choses. Lorsqu'une donnée est nécessaire, et après avoir vérifié à l'intérieur du CCX, le core va émettre deux requêtes en simultanée, une à destination de l'autre CCX, et l'autre à destination du contrôleur mémoire. Les deux opérations ont lieu en simultanée (attendre la réponse de l'autre CCX serait beaucoup trop pénalisant), mais elles imposent un surcoût. Les ingénieurs d'AMD nous ont confirmé qu'il faut probablement regarder de ce côté pour expliquer la latence, même si le constructeur est resté assez vague. En pratique, désactiver un CCX (et supprimer cette seconde requête) ne change en rien la latence. Logique étant donné que les requêtes sont de toute façon effectuées en parallèle. Un cache L3... complexeSi cela explique la latence plus élevée, et que son impact est probablement indéniable, il n'explique pas à lui tout seul les baisses de performances nettes notées dans les benchs où la mémoire joue un rôle important. Nous avons donc regardé du côté de la mémoire cache : 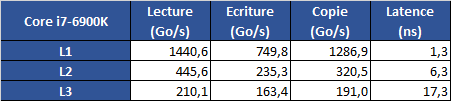 [ Core i7-6900K ] [ Ryzen 7 1800X ] [ FX-8350 ] Faisons abstraction du FX, si ce n'est pour noter que les caches de Ryzen sont massivement plus rapide en termes de bande passante. Si l'on compare au Core i7, on note que le L1 dispose d'une bande passante supérieure, c'est effectivement un avantage d'Intel mais qui n'explique pas les résultats que l'on obtient. La bande passante L2 est plutôt à l'avantage d'AMD, et la latence à Intel. C'est jusque là cohérent avec les données d'AMD qui annonce une latence comparable à Intel sur le L1 et un peu supérieure sur le L2. Mais sur le L3, annoncé par AMD comme plus rapide que celui d'Intel, la latence pose question, et dans une moindre mesure la bande passante. Le L3 de Ryzen serait il plus lent que celui du FX ? Oui et non. AMD est bien conscient du problème et a ajouté dans son "Reviewer's Guide" une mention indiquant que les logiciels comme Sandra ou Aida64 ne sont pas capables de déterminer correctement la rapidité du cache L3. Ce n'est pas la première fois que l'on rencontre une mention de ce type, même si en général les écarts sont de quelques pourcents. Pour mesurer la bande passante, les outils doivent déterminer la taille des caches, puis effectuer des mesures sur un bloc de données. Dans certains cas, la taille des blocs à tester peut être erronée, un cache L2 mal mesuré ou mal rapporté par le processeur. Plus souvent, les méthodes d'accès agressives à la mémoire utilisées peuvent avoir un effet sur une autre partie de la puce, comme un cache TLB et réduire les performances notées. Dans ce cas, l'algorithme, ou la taille des blocs, est adaptée à la main. AMD nous a confirmé que les auteurs de Sandra et Aida64 n'ont malheureusement pas eu accès à une plateforme Ryzen avant son lancement, les empêchant d'optimiser leurs benchmarks. Cela ne justifiant pas l'écart, nous avons voulu réaliser un autre bench qui cette fois ci ne tente pas de déterminer magiquement la taille des blocs mémoires à tester, mais va tester de manière séquentielle différentes tailles de données. De quoi se donner une meilleure idée des performances. Voici ce que nous avons obtenus avec ce bench qui a été développé par les auteurs d'Aida64 et qui sera intégré dans une future version du logiciel. Avant de vous donner les résultats, on se doit d'insister sur le fait que leurs auteurs n'ont pas pu le tester sur Ryzen, et que les résultats ne sont pas forcément optimaux dans certains cas (on pense aux problèmes d'algorithmes qui pourraient créer quelques petits pourcents de différence). Ces résultats sont cependant très instructifs sur le profil de performance de Ryzen : [ Core i7-6900K ] [ Ryzen 7 1800X ] [ FX-8350 ] Si l'on commence par regarder le cas du Core i7, les choses sont assez simples. Il dispose d'un cache L1 de 32 Ko où la latence est parfaitement alignée, d'un cache L2 de 256 Ko, on note que la latence est relativement stable jusqu'au bout, et d'un large cache L3 de 20 Mo. Jusque 16 Mo, les accès se réalisent dans le cache L3 et la latence est excellente, dès que la taille des accès augmente par contre, une partie des données est lue en mémoire centrale en plus du cache et la latence "moyenne" monte, logiquement, jusqu'à atteindre la latence de la mémoire. Sur le FX-8350, vous pouvez retrouver la même logique avec un cache L1 de 16 Ko, un L2 de 2 Mo partagé par le module (on note la montée passé 256Ko, la latence n'est pas uniforme), et un L3 de 8 Mo à latence uniforme. Sur Ryzen, le comportement est différent. Dans sa présentation Hot Chips, AMD notait que l'accès à différentes parties du L3 pouvait avoir une latence différente (en fonction du coeur où il est attaché) à l'intérieur d'un CCX. On peut voir un comportement de ce type sur les 4 premiers Mo, et une augmentation au delà particulièrement forte. Nous ne nous attacherons pas sur ce point sans retour des auteurs du benchmark. Cependant la situation au-delà de 8 Mo est sans appel : sur un accès de 12 Mo (dans un L3 combiné de 16 Mo), on a une latence proche de celle que l'on obtiendrait si l'on effectuait les accès au-dessus de 8 Mo en mémoire. Nous avons posé la question à AMD qui a confirmé cela : en pratique, dans ce cas d'école le L3 du second CCX n'est pas utilisé, Ryzen se comportant comme s'il ne disposait que de 8 Mo de L3. Il s'agit en effet d'une particularité du benchmark utilisé : pour pouvoir mesurer correctement la latence, il est indispensable que les threads soient attachées à un coeur et n'en bougent pas. Or, vous vous en souvenez probablement, le cache L3 est un cache de type "victime", il contient les données qui sont écartées du cache L2. Et pour remplir le cache L2, il faut qu'un accès se fasse... à l'intérieur du CCX. Résultat, en bloquant notre benchmark (la latence ne se mesure que sur un thread) sur le premier coeur, l'autre CCX n'est pas sollicité, son cache ne se remplissant pas. C'est effectivement un désavantage de l'architecture même s'il est excessivement théorique : en pratique, Windows 10 adore, on ne cesse de le dire, balader les threads des logiciels d'un coeur à l'autre. Si AMD n'a pas pu nous donner une idée de la latence d'un accès sur le second CCX, il nous a fourni une autre donnée largement plus importante : la bande passante entre ces deux CCX : ils l'auraient mesuré en pratique à seulement 22 Go/s ! Seulement, car vous l'aurez noté, cette bande passante est non seulement plus faible que celle du L3 à l'intérieur du CCX ("au moins" 175 Go/s, un chiffre à vérifier lorsque les logiciels de mesures auront été mis à jour), mais surtout inférieure... à la bande passante mémoire ! Lors de la GDC, AMD a partagé ce schéma qui donne quelques clarifications et explique le chiffre de 22 Go/s annoncé : 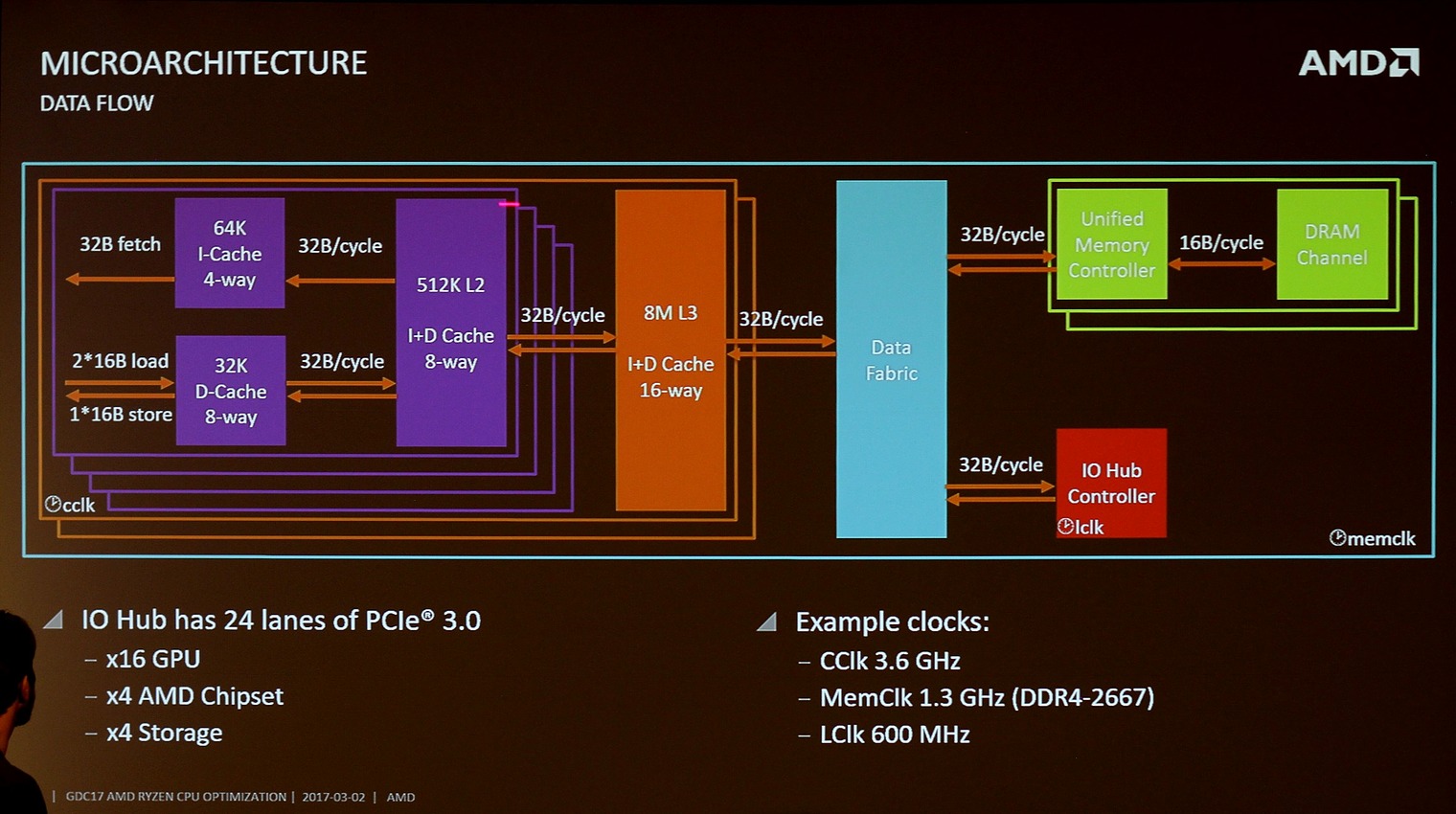 Chaque CCX est relié au Data Fabric par un bus capable de transférer 32 octets/cycles, et cadencé à la fréquence de la mémoire (1200 MHz pour de la DDR4-2400). C'est par ce bus que passent à la fois les requètes vers le contrôleur RAM, et vers l'autre CCX. A 1200 MHz, on obtient un chiffre théorique de bande passante pour ce bus de 38 Go/s. Sachant qu'il est partagé pour les accès mémoire et RAM, on peut voir se dessiner assez rapidement des problèmes de contention entre les accès RAM, et les inter communications avec l'autre CCX. Une partie de la bande passante est elle réservée à la RAM, et l'autre aux échanges L3 ? Certaines requêtes ont elles la priorité sur d'autres ? Le constructeur n'a pas donné plus de détails pour l'instant. On notera en prime que toutes les IO PCI Express se retrouvent aussi sur ce bus commun, ce qui peut ne pas être sans impact sur les jeux.
Cela nous permet de voir en pratique l'impact de la communication entre les CCX. Comme pour au dessus, nous réalisons les tests à 3 GHz, le SMT est désactivé pour limiter la variabilité. De manière assez intéressante (on y reviendra), les 8 Mo de cache sont disponibles dans chaque CCX en configuration 2+2. En théorie, donc, cette configuration est avantagée, elle a accès à 2 x 8 Mo de L3, contre seulement 1 x 8 Mo pour la configuration 4+0. Nous calculons un indice 100 de performances pour la configuration 4+0 : Beaucoup de choses à dire sur ces résultats. D'abord sur les applications, on notera que cela va dans tous les sens ! x264 et x265, peu sensibles au sous système mémoire font des performances virtuellement identiques dans les deux modes. Surprise cependant, les cas de WinRAR et 7-Zip, deux benchs très sensibles au sous système mémoire qui montrent des résultats bien différents. Dans le cas de 7-Zip, c'est la configuration 2+2 qui est la plus intéressante. Il semblerait que le logiciel profite mieux de la présence des 16 Mo de L3. A l'inverse, WinRAR est plus pénalisé par la synchronisation et le cache L3 supplémentaire ne compense pas. C'est cependant les jeux qui montrent le résultat le plus intéressant. Dans tous les cas, la configuration ou un CCX est désactivé est la plus performante. Le cache L3 supplémentaire disponible n'y change rien, les pertes sont très variables en fonction des titres mais pour certains la différence est massive : Battlefield 1 annonce un différentiel de presque 20% qui se traduit en pratique par 22 FPS d'écart ! La synchronisation des données semble extrêmement pénalisante dans ce titre. Project Cars et Civilization VI accusent aussi des pertes non négligeables. Vraiment 2 x 8 Mo de L3 en 2+2 ?Si l'on faisait abstraction dans le graphique précédent du cas de 7-Zip, on pourrait presque se demander si l'on a réellement deux fois 8 Mo de cache L3 en configuration 2+2 ? Sachant que le L3 dans le CCX est découpée en "slice", accolé à chaque coeur, on pourrait penser que désactiver un coeur désactive le slice de L3 ? Nous avons réalisé une fois de plus notre test de latence en fonction de la taille des accès pour nous en rendre compte. Et une fois de plus, nous n'avons pas vraiment eu les résultats auxquels nous nous attendions. On vous rappellera une dernière fois qu'il s'agit d'un bench beta et que ses auteurs n'ont pas pu le tester sur Ryzen. Malgré tout, nous estimons que les résultats sont suffisamment intéressants pour vous les montrer : Pour plus de lisibilité, nous avons limité le graphique autour de la taille du cache L3 (il n'y a pas de différence avant, sur les L1/L2, et après, sur les accès mémoires qui ont toujours la même latence). Pour éviter la variabilité, nous utilisons des accès linéaires dans ce test. Comme vous pouvez le voir, nous avons regardé la latence sur toutes les configurations de CCX disponibles sur notre Ryzen. En bleu, on retrouve les configurations ou un CCX est désactivé, et en orange les configurations à deux CCX. Nous étions passés rapidement sur la question de la latence sur les accès à 6 et 8 Mo page précédente. Nous allons maintenant nous y intéresser. En pratique, les accès au L3 devraient être a peu près identiques, autour de 13ns sur la totalité du cache. Si la valeur est supérieure, c'est que l'une partie des accès se fait non plus dans le L3, mais en mémoire centrale. Dans le cas des modes ou un CCX est désactivé (en bleu), dès 6 Mo on s'aperçoit que l'on est déjà parti en RAM. On ne se focalisera pas trop sur la variabilité une fois que le seuil des 13ns est dépassé : il y a environ 5ns de variabilité sur la latence mémoire d'un accès sur l'autre. Nous pensons que cela vient du design qui veut que les deux contrôleurs indépendants soient reliés eux aussi à la data fabric. Il est possible que l'accès à l'un soit légèrement plus rapide qu'au second à partir d'un CCX, ou que la data fabric ajoute une variabilité. Ce qui compte, c'est l'ordre de grandeur et clairement tout le L3 ne semble pas accessible de la même manière en fonction des configurations. Ca n'est pas forcément anormal, mais cela va avoir un impact sur notre comparaison au dessus, ce qui fait que l'on se doit de vous le signaler. En pratique, le mode 4+0, pourtant plus rapide en jeu, est handicapé au moins dans ce test. Pour ce qui est de la raison précise, nous éviterons de trop spéculer. AMD dans les informations communiquées à Hot Chips indique que son L3 est mostly exclusive, ce qui laisse penser qu'une partie du L3 est réservée pour certains usages. Cela n'a rien d'anormal. Pour expliquer la différence entre les modes où l'on a un et deux CCX actifs, il est probable que soit cet espace réservé soit placée sur le second CCX, ce qui du coup libère totalement le L3 ou nous effectuons la mesure (l'espace réservé pourrait aussi être coupé en deux). Il semble probable également qu'une partie de chaque slice soit réservé pour le coeur auquel il est accolé, s'il est actif. En pratique ces détails n'ont pas d'importance : on notera juste que le mode ou un seul CCX est actif, le 4+0 dans notre test au dessus, était en prime légèrement désavantagé sur ce point. Pour résumerOn commence maintenant à y voir un peu plus clair. Oui, la communication entre les CCX à un coût, et selon les applications il n'est pas forcément anodin. Pour les applications peu sensibles, l'effet est quasi nul, c'est le cas des logiciels d'encodage vidéo par exemple. Pour d'autres c'est largement plus marquant, comme par exemple Battlefield 1 où l'on perd 20% de performances. Si l'on résume ce que l'on a pu voir jusqu'ici :
Il peut y avoir par dessus des facteurs aggravants. Sachant que la communication entre les CCX est gourmande, balader les threads d'un CCX à l'autre (Windows 10 adore déplacer en permanence les threads !) peut aggraver la situation, même s'il est difficile de quantifier en quelle proportion. Les limites techniques, au final, priment. Cela ne veut pas dire que les choses ne changeront pas pour Ryzen à l'avenir. La solution la plus évidente serait un patch pour le scheduler de Windows, afin de limiter les déplacements des threads d'un CCX à l'autre. AMD et Microsoft avaient collaboré pour un patch pour Bulldozer à l'époque, on peut imaginer à nouveau un patch pour Ryzen. Reste qu'AMD s'est montré très prudent et n'a pas voulu nous confirmer travailler ou non sur la question. Un autre changement qui pourrait se révéler salutaire pour les jeux est l'arrivée du "Game Mode" de Windows 10, dont l'une des particularités serait justement là aussi, de moins bouger les threads. Reste que même accrochés à un coeur, les communications entre les threads resteront tout aussi coûteuses lors de l'utilisation de données partagées. D'un titre à l'autre, l'impact du Game Mode, s'il en à un, sera forcément variable. AMD met également en avant la bonne volonté des développeurs qui pourraient adapter leurs titres pour contourner les éventuelles limitations de Ryzen et en tirer de meilleures performances. Cela n'est pas forcément un argument creux, dans le sens ou les coeurs Zen pourraient être utilisés dans des consoles assez rapidement. Reste que l'argument semble surtout tourné sur les particularités du SMT d'AMD. Rien ne dit que ces futurs SoC pour consoles utiliseront le même data fabric, aux mêmes fréquences, et avec les mêmes limitations. Quelle partie de l'écart sera rattrapée par ces éventuels correctifs, patchs, et modifications ? C'est en l'état impossible à dire et il faut rester très prudent sur ce que feront, ou non, les divers développeurs concernés. Les contraintes techniques évoquées comme la latence plus élevée de la mémoire, et le bus unique où passent les données RAM, cache L3, et PCI Express elles n'évolueront pas, en tout cas pas avant une future révision de Zen.  En pratique le plus gros défaut de Ryzen reste son sous-système mémoire, qui bride les performances dans certaines applications spécifiques et dans les jeux. Pour ces derniers, il faut au passage rappeler que la désactivation du "Core Parking" sous Windows 10 permet un gain non négligeable et il faut relativiser puisque le niveau de performances est globalement largement suffisant. On est très, très, loin de la situation des FX ! AMD regrettera peut-être sa communication autour de l'idée que le 1800X ferait aussi bien que le 6900K, pour deux fois moins cher. En pratique nous n'y sommes pas tout à fait, particulièrement dans les cas impactés par ce souci et c'est dommage. Reste que par rapport à la grille tarifaire d'Intel, le 1800X se place au niveau d'un 6800K qu'il domine très facilement d'un point de vue applicatif avec ses deux coeurs supplémentaires. Dans le domaine du jeu, l'i7-7700K, moins cher, reste un peu supérieur avec les jeux actuels mais ne fait bien entendu pas le poids dès qu'on s'attaque à de l'applicatif plus apte à exploiter les 16 coeurs logiques que Ryzen propose. Ce que nous retiendrons enfin de ce test sur une toute nouvelle plate-forme qui reste encore à peaufiner, c'est le potentiel à venir de l'architecture Zen. Les efforts réalisés par les ingénieurs d'AMD sont déjà indiscutablement traduits en pratique mais on peut déjà très facilement imaginer le potentiel de futures implémentations de Zen qui n'auraient pas les limites de Ryzen, particulièrement autour du sous-système mémoire. De quoi donner de très grands espoirs pour Zen 2 ? Copyright © 1997-2026 HardWare.fr. Tous droits réservés. |