| |
| |
| Intel Core i7-6700K, i5-6600K et Z170 : Skylake en test Processeurs Publié le Lundi 28 Septembre 2015 par Guillaume Louel et Marc Prieur URL: /articles/940-1/intel-core-i7-6700k-i5-6600k-z170-skylake-test.html Page 1 - Introduction Enfin ! Après des Broadwell lancés en catimini avec des mois de retard sur LGA 1150, les processeurs Skylake débarquent avec leur lot de nouveautés. Fers de lance de la gamme, ce sont les Core i7-6700K et Core i5-6600K qui sont lancés dans un premier temps. Au menu du jour de ce nouveau "tock", on retrouve par rapport à Haswell le passage en 14nm, une architecture améliorée côté CPU comme iGPU, ainsi qu'une nouvelle plate-forme LGA 1151 associée au chipset Z170 Express.  Reverse paper launch !Avant de passer aux choses sérieuses, nous tenons à faire pour une fois un petit aparté sur l'envers du décor. Le lancement d'un nouveau produit en informatique est assez rodé, notamment côté CPU ou GPU. Généralement les constructeurs fournissent en amont des documentations techniques et marketing à la presse, ainsi que des échantillons de test, ce qui permet à celle-ci de donner son avis sur les produits dès leur disponibilité. Une habitude qui n'est vraiment à l'avantage du constructeur que si le produit est bon, même si certains pensent que l'essentiel est qu'on parle d'eux, que ce soit en bien ou en mal. Cela ne se passe évidemment pas toujours ainsi, et il peut être nécessaire d'obtenir les informations ou le matériel via d'autres biais, que ce soit avant ou après le lancement, ce qui ne permet pas dans ce dernier cas de donner un avis avant la disponibilité. Il y a quelques années, alors que la concurrence était plus féroce les constructeurs allaient jusqu'à faire des "paper launch" : le produit et ses spécifications étaient annoncées, avec parfois des échantillons de test, mais il fallait attendre quelques semaines pour la disponibilité en boutique. Pour ce lancement Intel a procédé de manière pour le moins inhabituelle. En effet, si nous avons reçu un Core i7-6700K à la dernière minute (vendredi dernier), aucune documentation technique n'est disponible à ce jour. L'architecture Skylake ne sera dévoilée à la presse que lors de l'IDF qui se déroule dans deux semaines, avec un embargo jusqu'en septembre. Le lancement des Core i7-6700K, Core i5-6600K et Z170 Express a en effet été avancé par rapport au reste de la gamme, de manière à être synchronisé avec le salon Gamescom dédié aux jeux vidéo, le gaming et l'overclocking étant la cible annoncée par Intel pour ces produits. Une cible pour laquelle les détails techniques semblent accessoires d'après Intel. Nous ne sommes pas vraiment d'accord avec cette approche et malgré le temps très réduit à notre disposition nous avons essayé de faire au mieux malgré les circonstances pour vous offrir le maximum d'informations possibles aujourd'hui. Nous tâcherons dans les semaines à venir à combler les points d'obscurité laissés par Intel. Trêve de bavardages, passons au concret ! Un passage au 14nm plus compliqué que prévuDepuis les toutes premières rumeurs concernant Broadwell, le 14nm d'Intel s'est retrouvé entouré de nombreuses questions. Pour la première fois, le constructeur comptait lancer une nouvelle génération de processeurs en ne visant uniquement que les plateformes mobiles, laissant de côté les plateformes de bureau. De quoi poser à l'époque de nombreuses interrogations sur un éventuel désintérêt du constructeur pour ces plateformes, au profit d'une stratégie misant sur la mobilité. Avec le recul aujourd'hui, on peut voir qu'en pratique les premières rumeurs de retard du 14nm avaient rapidement suivi courant 2013 où Broadwell avait commencé à glisser petit à petit sur les roadmaps. En octobre 2013, Intel parlait officiellement d'un retard d'un trimestre blâmant les difficultés de production du 14nm, mais assurait que cela n'aurait aucun impact sur la génération suivante, Skylake. Une communication surprenante étant donné que Skylake utilise ce même process 14nm considéré comme en retard. 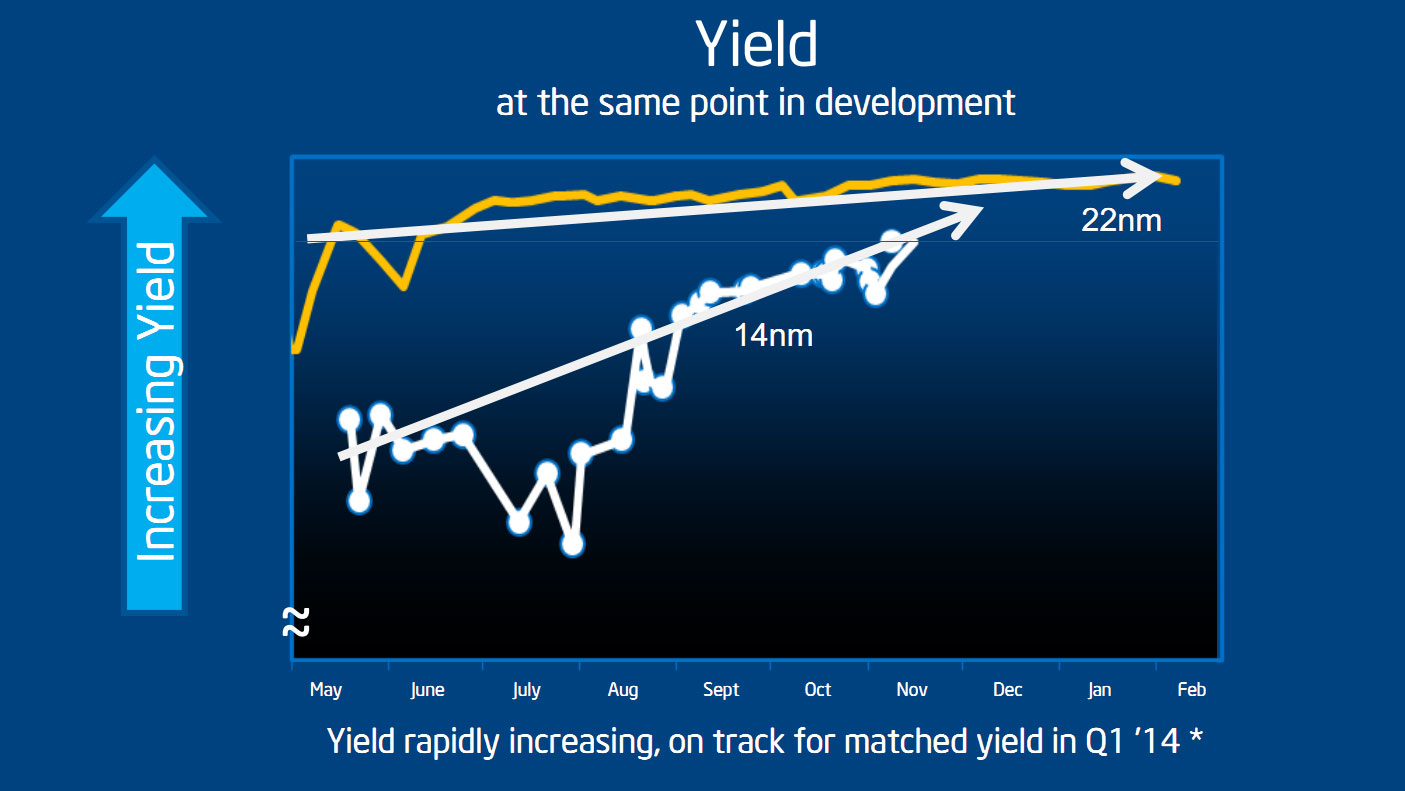 Trois mois de retard selon Intel fin 2013, la ligne rouge que nous avions rajouté sur le graphique montrait plutôt un retard de six mois à l'époque Une communication fin 2013 laissait entendre entre les lignes que le retard serait plutôt de six mois, puis finalement mi-2014 de neuf, tout en nous laissant penser que le constructeur allait sacrifier sur ses marges pour absolument lancer un produit 14nm en 2014 et satisfaire les promesses aux investisseurs. La confirmation sera vite arrivée : Intel a lancé fin 2014 un Core M éphémère, dont le stepping s'est vu annoncé en fin de vie avant même sa sortie. Ce n'est que début 2015 que nous auront vu arriver les premiers « vrais » Broadwell double cur, tandis que ce n'est qu'à la fin du second trimestre que les modèles quad core ont débarqué. Les prochaines années nous diront si Intel avait délibérément choisi de limiter l'étendue de Broadwell, non pas par un désintérêt des plateformes desktop, mais plutôt par la réalisation que son process 14nm ne serait pas à même de fournir en 2014 - et en volume - tous les marchés. Les lancements classiques commencent en effet en général par le desktop avec des modèles quad core, et donc des dies plus complexes à produire lorsque les yields sont bas. En attendant le constructeur a décidé de prendre de la marge puisqu'il a annoncé mi-juillet mettre de côté la cadence du Tick-Tock et l'arrivée d'un troisième produit 14nm en 2016 avec Kaby Lake sur lequel on ne sait pour l'instant pas grand-chose, si ce n'est que son arrivée sur les roadmaps est due à la difficulté de montée en production du 10nm. Cannonlake, déclinaison 10nm de Skylake n'arrivera que durant la seconde moitié 2017 (au lieu de 2016). Reste qu'au milieu de ces retards précédents et à venir, l'architecture Skylake lancée aujourd'hui est à l'heure puisque lancée 26 mois environ après Haswell ! Page 2 - LGA 1151 et Z170 Express LGA 1151 et Z170 Express  Après un peu plus de deux ans de bons et loyaux services, le LGA 1150 passe la main au LGA 1151. Visuellement rien ne change vraiment, les détrompeurs sont légèrement décalés afin d'empêcher l'insertion d'un processeur incompatible, et le système de fixation reste inchangé par rapport au LGA 1156/1155/1150. Si le passage du LGA 1155 au LGA 1150 était entre autre motivé par l'intégration du régulateur de tension au sein du processeur Intel repasse sur LGA 1151 à un régulateur externe ! Pour rappel, sur Haswell la carte mère ne fournit au processeur que 2 tensions via le Socket contre 6 auparavant : VDDQ qui est directement réutilisée pour l'alimentation de la DDR3, et VCCIN qui passe par un régulateur de tension intégré pour être transformé en 5 tensions distinctes. Intel mettait en avant à l'époque une simplification du design des plates-formes et un meilleur contrôle par le processeur de son alimentation. 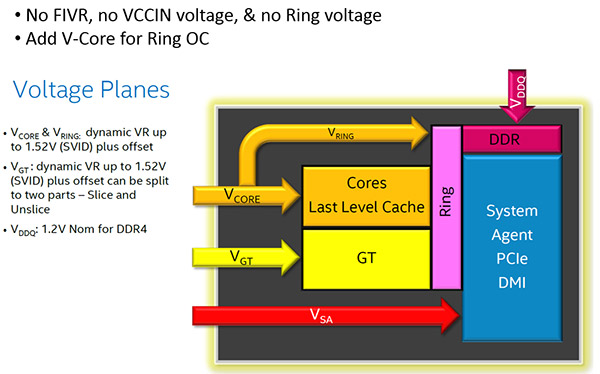 On assiste donc sur LGA 1151 à un retour en arrière puisqu'en sus de VDDQ la carte mère doit fournir 3 tensions supplémentaires via un régulateur de tension qui est de nouveau externe : VCORE pour les curs x86 et le cache LLC, duquel est dérivé VRING pour le ring bus d'interconnexion, VGT pour l'iGPU et VSA pour le System Agent (contrôleur mémoire, DMI, PCI-E). Nous avons essayé de savoir auprès d'Intel les raisons de ce retour en arrière, qui nous a expliqué que ce choix a été fait pour offrir plus de possibilités en termes de dissipation thermique sur les appareils mobiles ce qui est assez vague. Est-ce qu'il s'agit tout simplement de ressortir du CPU et de son packaging les pertes liées à la régulation de tension, même si ce n'est que quelques dixièmes de watts ? Un fabricant de carte mère nous a par ailleurs indiqué que l'IVR n'était pas bon pour l'OC et qu'un régulateur externe était nécessaire dans le cas de l'iGPU GT4e. Là encore c'est assez vague et nous espérons en apprendre plus lors de l'IDF, toujours est-il que ce changement empêche de facto toute compatibilité avec la plate-forme précédente, même si Intel nous a prouvé par le passé ne pas avoir besoin de ce genre d'excuse. 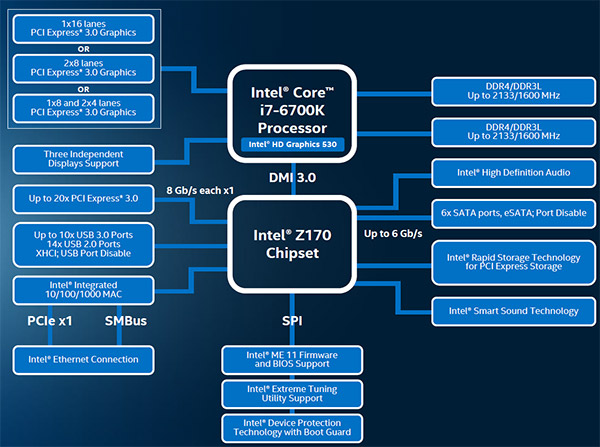 Mais le LGA 1151 apporte également son lot de nouveautés côté chipset avec le Z170 Express qui inaugure une toute nouvelle génération de chipsets. Premier point, le lien avec le CPU passe au DMI 3.0 au lieu du DMI 2.0 introduit en 2011. Les débits sont doublés pour atteindre 4 Go/s dans chaque sens, une nécessité vu les débits cumulés des interfaces disponibles au sein du chipset bien qu'on ne les utilise que rarement de manière simultanée. Si le nombre de SATA 6 Gbps reste limité à 6, Intel augmente par contre le nombre de ports USB 3.0 qui passe de 6 à 10 ! Attention dans les deux cas, Intel a allégé ces contrôleurs des anciennes normes. Le contrôleur SATA n'est donc plus compatible IDE et fonctionne uniquement en AHCI, alors que le contrôleur USB 3.0 ne fonctionne plus en EHCI mais en xHCI. Sachant que l'installeur de Windows 7 ne supporte pas le xHCI, il n'est donc pas possible d'installer Windows 7 depuis une clef USB sauf en intégrant les pilotes xHCI au sein de l'ISO au préalable (comme expliqué ici par exemple ). Enfin ce sont pas moins de 20 lignes PCIe Gen3 qui peuvent être gérées par le Z170, contre 8 lignes PCIe Gen 2. Ces lignes peuvent être utilisées pour des puces intégrées à la carte mère, pour des ports PCIe ainsi que des interfaces SATA Express x2 ou M.2 x2 ou x4 pour SSD. Bien entendu même si le bus DMI a été élargi, il reste insuffisant pour tout utiliser de manière simultanée puisque ce lien est équivalent au débit de 4 lignes PCIe Gen3 ! 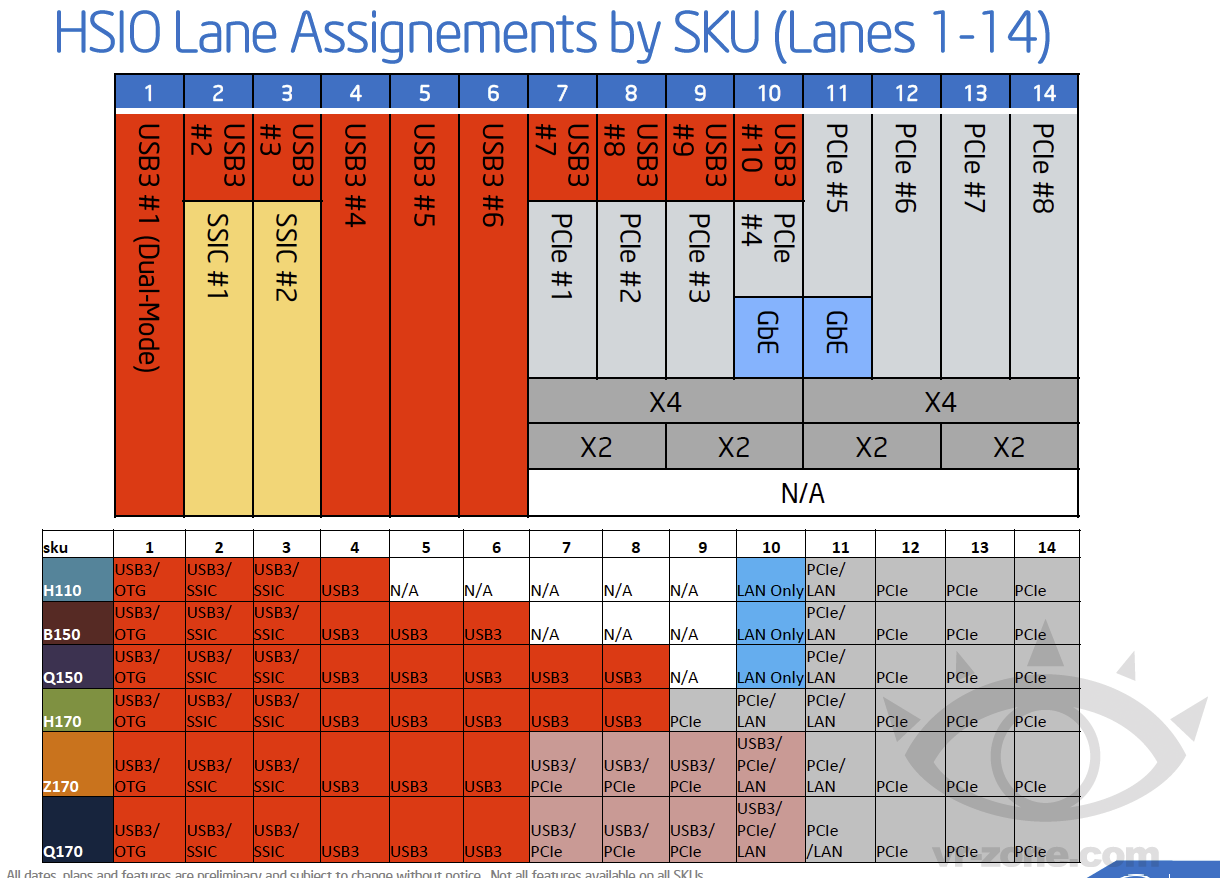 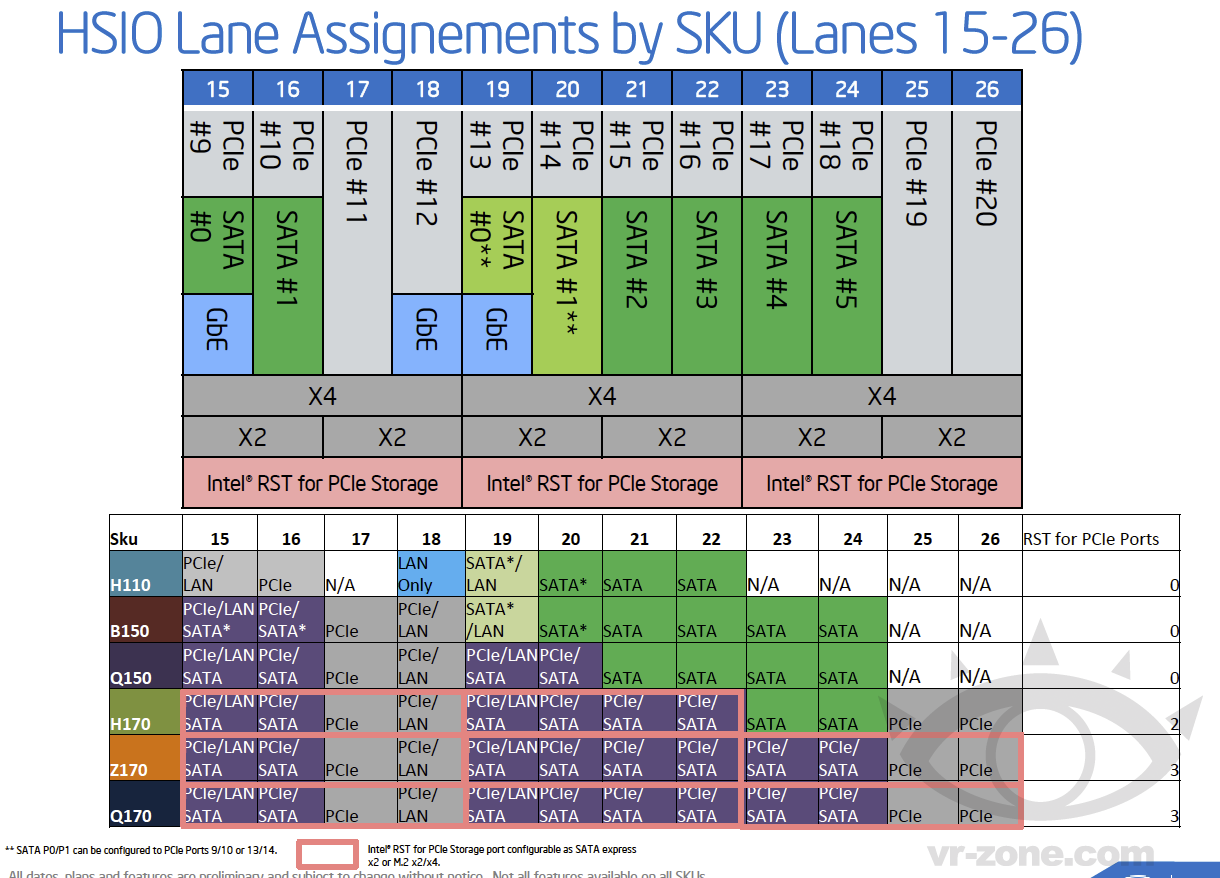 Dans tous les cas les constructeurs de cartes mères ne pourront pas intégrer toutes ces possibilités en même temps puisque Intel continue de garder le concept d'I/O Port Flexibility introduit avec le Z87. Le nombre combiné de lignes PCIe, ports USB 3.0 et ports SATA ne peut ainsi excéder les 26 (contre 18 sur Z87), et selon les besoins une ligne pourra être utilisée pour l'une ou l'autre de ces interfaces. Ces évolutions du Z170 Express sont une bonne chose, même si idéalement on aurait aimé qu'en parallèle le nombre de lignes PCIe Gen3 gérées par un CPU LGA 1151 augmentent un peu, par exemple en passant de 16 à 20 ce qui permettrait la gestion d'un port M.2 x4 sans monopoliser le lien DMI avec le chipset. Page 3 - Nouveautés côté CPU & OC Les nouveautés côté processeur et overclockingFaute de documentation, il est malheureusement difficile de connaitre quelles sont les améliorations apportées par Intel au niveau du front-end (récupération et décodage des instructions x86, prédiction de branchement), du scheduler (réorganisation de l'ordre d'exécution des instructions) voire des unités de calculs. Aidé d'AIDA64 nous avons effectué des mesures de latence et de débit pour les instructions supportées par Skylake (ici, à comparer à ce fichier pour Haswell)et les unités d'exécution sont généralement plus rapides, avec notamment un gain de 25% pour les instructions de type FMA.  Puisqu'on parle d'instruction, Skylake ne supporte finalement pas l'AVX-512 sur Core i7 et i5, il sera réservé aux Xeon comme nous l'avions déjà indiqué. Les instructions TSX, désactivées sur Haswell suite à un bug, sont comme sur Broadwell de retour et les instructions ADX et RDSEED introduites sur Broadwell sont de la partie. La seule nouveauté de Skylake tel qu'introduit aujourd'hui se situe donc au niveau des instructions Intel MPX qui permettent d'augmenter la sécurité des logiciels en permettant de vérifier au moment de l'exécution que les références mémoires prévues dans un programme ne sont pas utilisées de manière malicieuse (via un buffer overflow par exemple). Côté cache le gros changement opéré par Intel est le retour à un cache L2 associatif à 4 voies, contre 8 depuis les premiers Core i7. Cela simplifie la gestion du cache et devrait le rendre moins énergivore, mais avec un impact négatif sur les performances. En effet une ligne mémoire ne disposera plus de 8 options mais de 4 pour être stockée en cache, ce qui augmente potentiellement le risque de conflit avec une autre ligne mémoire utile et donc les défauts de cache conflictuel. 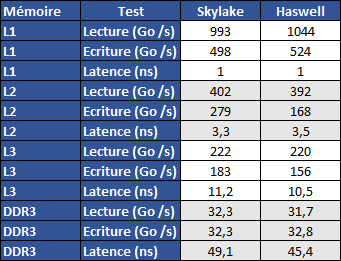 La vitesse mesurée sous AIDA64 montre à fréquence équivalente (4 GHz) un cache L1 légèrement moins rapide en débit mais équivalent en latence avec à 1ns soit 4 cycles, côté L2 on note une forte hausse (+66%) du débit en écriture et une baisse de l'ordre de 1 cycle de la latence. Le débit en écriture du cache L3 monte également (+18%) mais sa latence est en hausse, passant de 42 à 45 cycles environ. La latence d'accès à la DDR3-2133 augmente également par rapport à Haswell. Au-delà du cache la gestion de la mémoire évolue également avec le support au niveau du contrôleur mémoire de la DDR4, que nous avons largement décrite à l'occasion du lancement des Haswell-E, en sus de la DDR3. Officiellement la DDR3 n'est plus supportée qu'en version 1.35V ("DDR3L") en DDR3-1600, mais en pratique nous n'avons pas rencontré de problème avec de la mémoire classique à 1.50V et même en 1.65V (nous vous conseillons toutefois de vous limiter à 1.50V), la DDR4 peut être de type DDR4-2133 ou plus via overclocking. Puisqu'on parle de l'overclocking, Intel introduit quelques nouveautés sur Skylake, la principale étant un découplage complet des fréquences PCIe et DMI et de la BCLK. Complètement lié sur LGA 1155 ce qui limitait l'overclocking par le bus à quelques %, sur LGA 1150 Intel avait introduit des ratios permettant un peu plus de liberté. Cette fois le découplage est complet et quelle que soit la vitesse du bus BCLK choisie le PCIe et le DMI resteront à 100 MHz ce qui permet de laisser libre cours aux envies des overclockeurs, à condition bien entendu d'utiliser des ratios adéquat pour les éléments qui restent concernés (CPU, iGPU, DDR).  Un retour salutaire sur le papier, mais en pratique il ne sera vraiment utile que si il permet l'overclocking sur les processeurs "non K", et rien ne permet à ce jour de l'affirmer. A défaut, il s'agira juste d'une fioriture utile pour les chercheurs de records en tout genre prêts à passer du temps pour quelques points de benchmarks. Côté coefficients multiplicateurs Skylake est par ailleurs capable d'atteindre les x83, contre x80 sur Haswell, alors que les ratios mémoire permettent d'avoir une granularité par saut de fréquence de 100/133 MHz contre 200/266 MHz auparavant, avec un maximum en DDR4-4133 (et plus en augmentant la BCLK bien sûr). Mise à jour du 19/08/2015 : Lors de l'IDF nous avons pu en apprendre plus, vous trouverez ci-dessous notre actualité publiée à cette occasion pour la partie CPU : 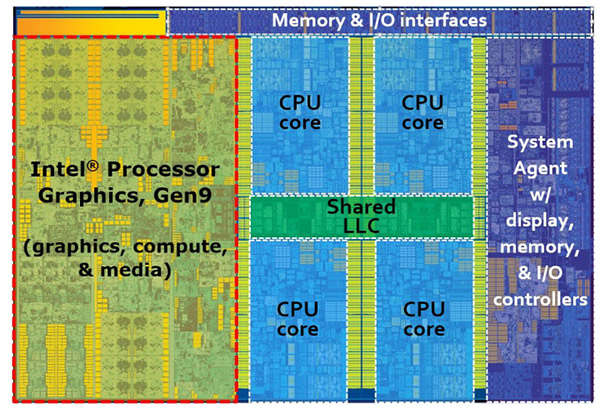 Enfin ! Comme promis, Intel profite de l'IDF pour commencer a parler des détails de l'architecture de Skylake au travers de plusieurs sessions qui ont eu lieu en cette première journée. Nous avons tenté de regrouper le maximum d'informations dans cette longue actualité, en sachant que le constructeur tend a lâcher au compte goutte les détails d'une session à l'autre, il n'est pas impossible que certains détails ne soient dévoilés que dans les jours à venir ! Nous allons tenter de noter les différences par rapport à Haswell, vous pouvez vous rafraichir la mémoire en relisant notre article.  Avant de commencer, on notera que le constructeur travaille sur Skylake depuis plusieurs années (plus de 5) et que le projet, réalisé en Israel (Intel alterne deux équipes, une en Israel, l'autre dans l'Oregon) aura été modifié plusieurs fois pour rajouter successivement des TDP de 15 watts (avec les Ultrabook lancés à partir de 2008) puis de 4.5W (Core M) ainsi que des variations de packaging. On notera aussi, et c'est une première, que les détails que nous indiquons en dessous ne concernent que la version grand public de Skylake. La version serveur profitera de choix différents au niveau de l'architecture, on sait par exemple que seule la version serveur de Skylake supportera l'AVX512, mais les différences devraient être plus larges. Frontend, scheduler et unités d'execution Dans les grandes lignes on ne notera pas de changement majeur sur le frontend qui reste de type 4-way (jusque 4 instructions x86 décodées en simultanées) comme pour Sandy Bridge et Haswell. En pratique de ces quatre instructions CISC, jusque 6 micro-ops (les instructions RISC) peuvent toujours être générées. En amont du décodage, on retrouve la prédiction de branchement qui évolue par contre significativement. Intel ne rentre pas dans les détails de l'algorithme mais indique qu'il est plus intelligent et capable de considérer des branchements beaucoup plus longs qu'auparavant. De la même manière, Intel a augmenté la taille des différents buffers durant les différentes étapes du front-end, un changement que l'on retrouve a presque toutes les nouvelles architectures. Les micro-ops décodées sont en effet stockées dans deux files capables d'en stocker 64 par thread (contre un buffer unique de 56 pour Haswell), un changement majeur qui permet au scheduler de tenter d'extraire un maximum de parallélisme. Le scheduler a pour but de dispatcher les micro-ops vers les unités d'exécution. Il profite des files rallongées et de certains changements au niveau de ses algorithmes dans la gestion de l'hyperthreading. 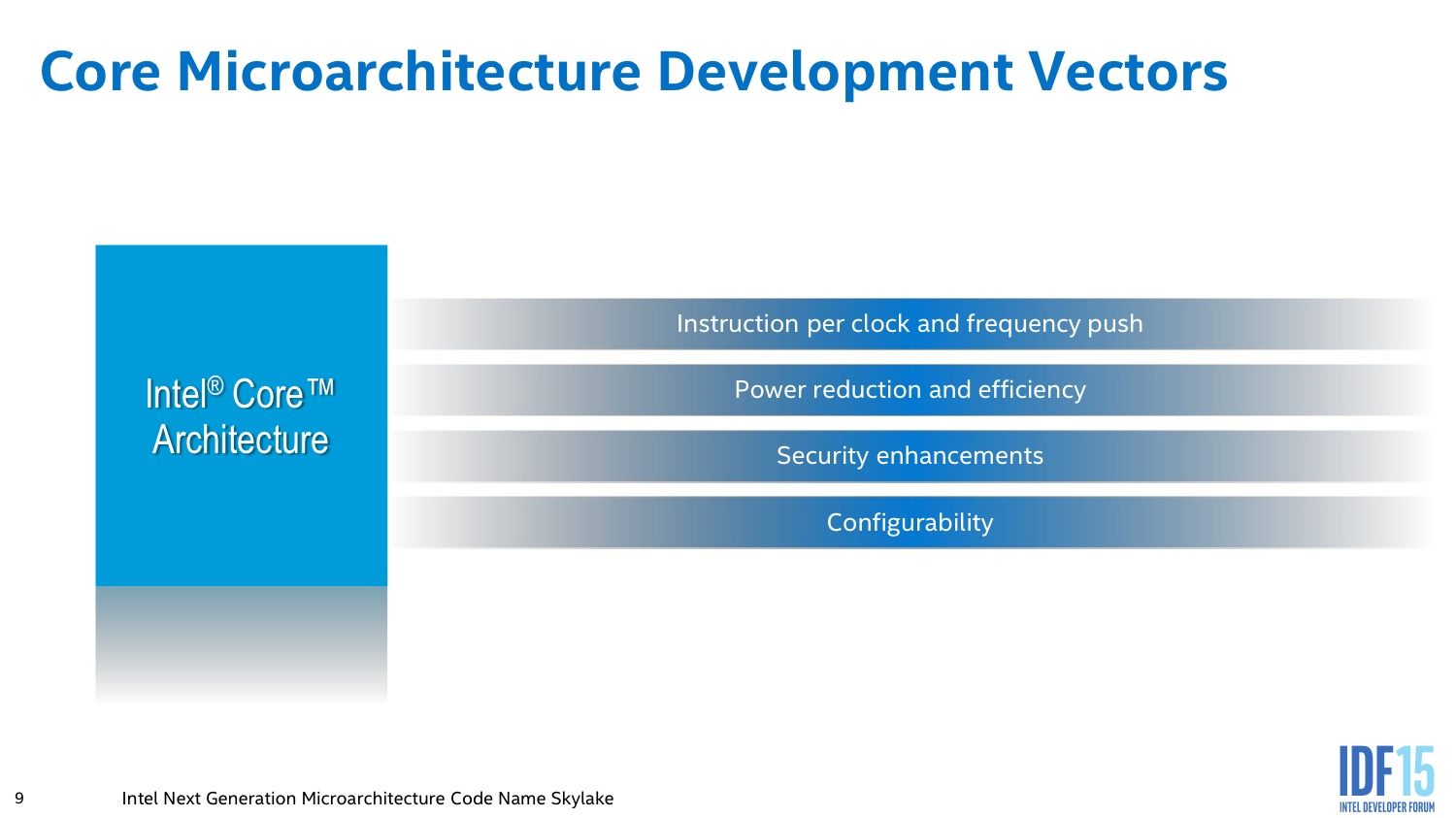 Le point le plus flou pour l'instant concerne les unités d'exécution. Pour rappel, avec Haswell on disposait de 8 ports sur lesquels étaient répartis de multiples unités d'exécution (ALU pour les instructions sur les entiers, des unités AVX/flottants, les chargements/sauvegardes de données en mémoire, les branchements ). Pour l'instant tout ce que l'on sait, c'est que le nombre d'unités a augmenté sans savoir celles qui ont été ajoutées. Deux autres détails ont été donnés par les ingénieurs d'Intel : l'unité en charge des divisions gagne en flexibilité, tandis que la latence de traitement de certaines instructions FPU serait en baisse. Intel nous a promis que nous aurions plus de détails sur ces points dans une session à venir. Globalement les changements sont intéressants dans le sens ou ils permettent en théorie de maximiser un peu plus l'utilisation des unités d'exécution de chaque coeur, ce qui peut se traduire dans certains cas par une augmentation importante des performances. Le constructeur a par ce biais réussi à améliorer significativement ses résultats dans un des benchmarks SPEC sur un coeur (ce qui a valu à nos confrères allemands de ressortir la rumeur - évidemment fausse - d'un hyperthreading inversé en fin de semaine dernière !). Les changements restent cependant très localisés et dans l'absolu, Intel continue d'affiner les grandes lignes d'une architecture Core, certes excellente, mais qui reste la même dans les grandes lignes depuis des années. Jeu d'instruction Lors de notre test de Skylake, nous avions noté la présence d'une nouveauté dans le jeu d'instruction : MPX, Memory Protection Extension. Ces instructions permettent de rajouter des vérifications sur les adresses mémoires accessibles pour éviter les attaques type buffer overflow et empêcher un processus d'accéder a de la mémoire a laquelle il n'a pas droit. Nous n'avons pas encore obtenu plus de détail sur ces instructions.  Par contre, une autre nouveauté complémentaire concerne ce que le constructeur appelle SGX, pour Software Guard Extension. Ces instructions permettent de créer des zones mémoires protégées qui ne sont accessibles qu'au processus qui les a crée, et qui, dans le cas ou les données auraient été tout de même corrompues, couperait le fonctionnement du process concerné afin de maximiser sa sécurité. De la même manière, l'utilisation d'une zone mémoire sécurisée (Secure Enclave) désactive toutes les possibilités de deboguage sur le système.  Si l'on imagine aisément l'utilité de ces extensions dans certaines situations dans le monde de l'entreprise, d'un point de vue grand public on pensera surtout aux implémentations éventuelles de DRM qui pourraient utiliser ces technologies à l'avenir. Gestion de l'alimentation Un gros travail a également été réalisé sur la gestion de l'alimentation avec un usage accru du power gating de certaines unités gourmandes, c'est notamment le cas des unités AVX2 qui sont éteintes lorsqu'elles ne sont pas sollicitées. Des économies ont été réalisées à tout les niveaux, particulièrement celui des interconnexions et des I/O pour limiter au maximum la consommation. Les ingénieurs ont travaillé plus spécifiquement sur les scénarios idle ou « presque » idle comme la lecture vidéo pour augmenter au maximum la longévité de la batterie en usage mobile. Parmi les solutions retenues pour arriver à ce but, on retrouve l'ajout de domaines d'horloges séparés pour le System Agent, le contrôleur mémoire et l'I/O eDRAM (pour les modèles qui en sont pourvus). Un travail important a également été réalisé sur l'unité de gestion de l'énergie (Power Control Unit) pour la rendre un peu plus intelligente dans de multiples scénarios ou elle devient capable d'estimer un risque de throttling et de réduire a l'avance la fréquence pour éviter d'atteindre la température maximale à laquelle un throttling sévère est inéluctable.  L'autre choix concerne l'utilisation du Duty Cycle Control en lieu et place d'un changement de fréquence. Comme indiqué par Intel, réduire la fréquence (via les P-States pour les coeurs) permet de diminuer la consommation de manière linéaire, et il est souvent plus efficace d'éteindre et d'allumer (un peu a la manière d'un contrôleur PWM) les unités tout en gardant une fréquence plus élevée. Speed Shift L'autre changement majeur concernant la PCU est ce qu'Intel appelle Speed Shift, un changement fondamental du fonctionnement des P-States. Pour rappel, la fréquence du processeur est gérée à la fois par le processeur lui même et le système d'exploitation. Le processeur propose une table dite de P-States (via les tables ACPI) qui indique les différents couples de tensions/fréquences qu'il peut utiliser.  Dans un fonctionnement classique, le système d'exploitation, en fonction de la charge qu'il traite, va contrôler explicitement les changements de P-States (ce qui requiert une latence d'environ 30ms selon Intel) en choisissant un niveau (par exemple, P1, la fréquence maximale « non turbo »). Il y a cependant - chez Intel - deux exceptions à cette règle. La première concerne les fréquences Turbo qui varient en fonction du nombre de coeurs actifs. Cette gestion s'effectue directement par le processeur. L'autre est le cas du throttle lorsque l'on dépasse la température de fonctionnement critique. Dans ce cas le processeur effectue seul (heureusement !) le throttling en passant dans les modes dits de contrôle thermique. L'idée de Speed Shift est de changer la relation entre le système d'exploitation et le processeur. D'une, avec Speed Shift le processeur expose désormais la totalité des fréquences disponibles, y compris les modes Turbo gérés jusqu'ici de manière transparente. Ensuite, le système d'exploitation va donner une sorte d'indication globale pour indiquer s'il faut privilégier la performance ou l'économie d'énergie (remplaçant le concept des modes performance/balanced/etc que l'on retrouvait par exemple sous Windows 7, ainsi que le mode batterie/alimentation pour les portables). Enfin, par défaut le PCU est capable de gérer tout seul les P-States en choisissant automatiquement le mode qui semble le plus adapté à la volée et de manière complètement autonome. Par dessus ceci, le système d'exploitation peut décider d'intervenir, mais cela se fait d'une manière nouvelle. En effet, le système définit une fréquence minimale ainsi qu'une fréquence maximale, laissant là encore au PCU une marge de manoeuvre pour optimiser automatiquement au mieux en fonction de la charge. Il est également possible de demander une fréquence précise, de manière optionnelle, mais cela se fait en plus des fréquences mini et maxi et n'est en rien garanti. 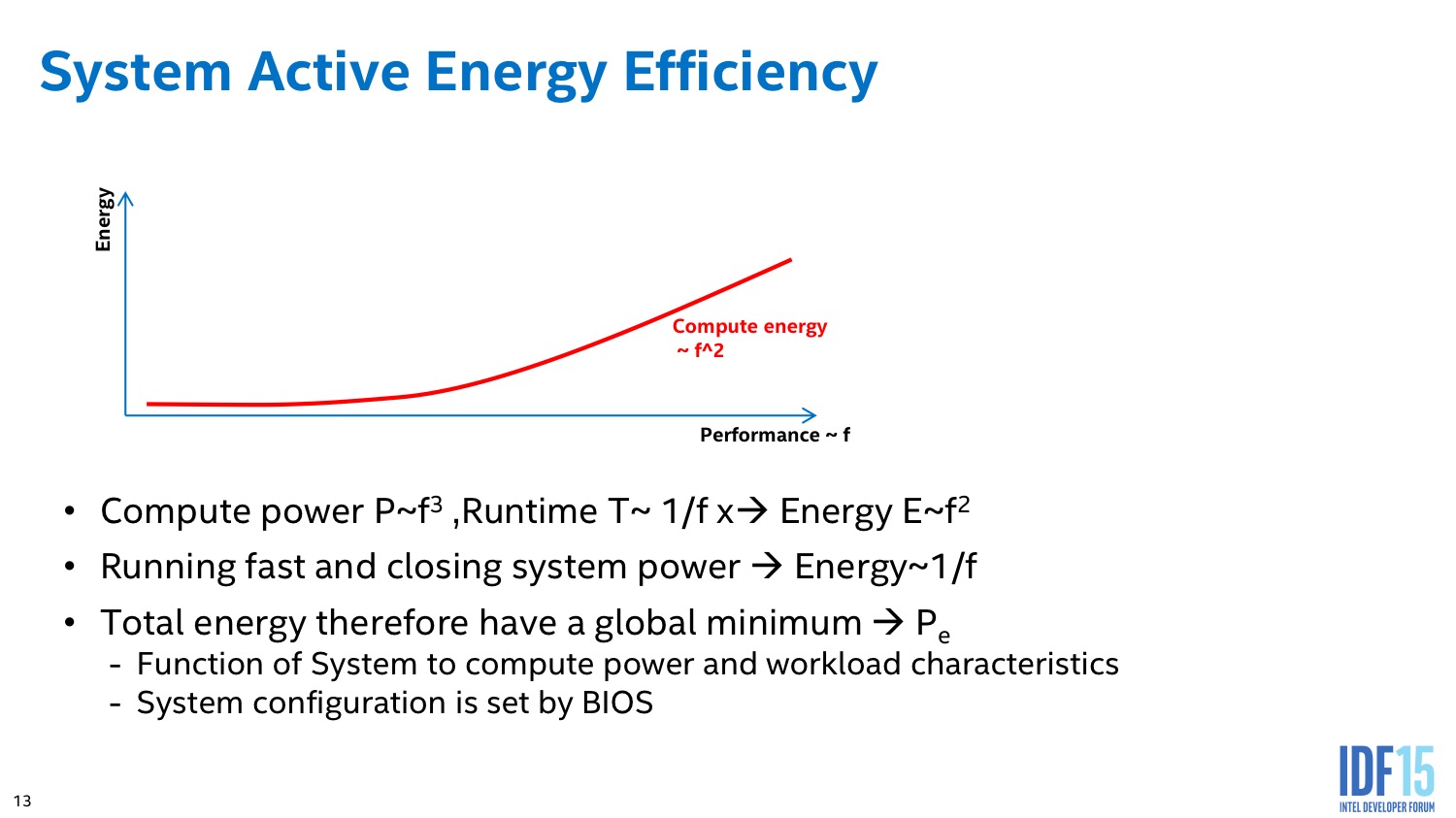 Intel implémente des algorithmes avancés dans son PCU qui tentent d'estimer en permanence s'il est plus intéressant de limiter la fréquence dans le cas d'une charge légère constante, ou au contraire de pousser la fréquence pour pouvoir éteindre le plus rapidement possible les unités et sauver de l'énergie au final. 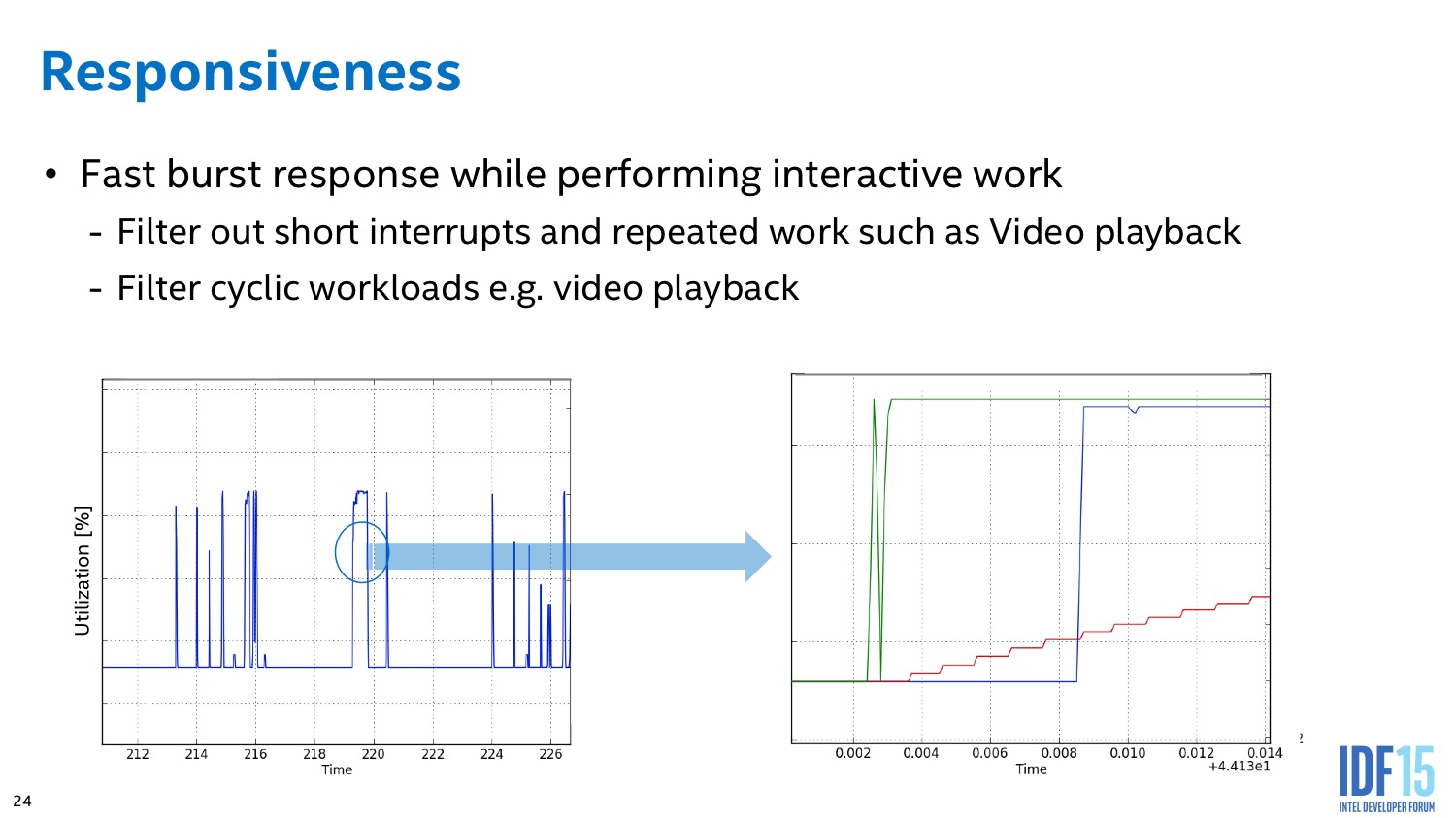 L'algorithme du PCU tente également de détecter les situations ou l'on interagit avec le système pour améliorer le côté responsif du système. L'idée de base telle que voulue par les concepteurs du système était de passer le plus rapidement possible en mode turbo lorsque l'on détecte une interaction (réveil, souris, etc) pour donner l'impression que le système est plus réactif. En pratique le PCU tente de détecter les charges typiques d'une interaction et utilise plusieurs systèmes pour filtrer des charges plus longues (lecture vidéo), ou tellement courtes qu'elles ne mériteraient pas que la fréquence augmente. 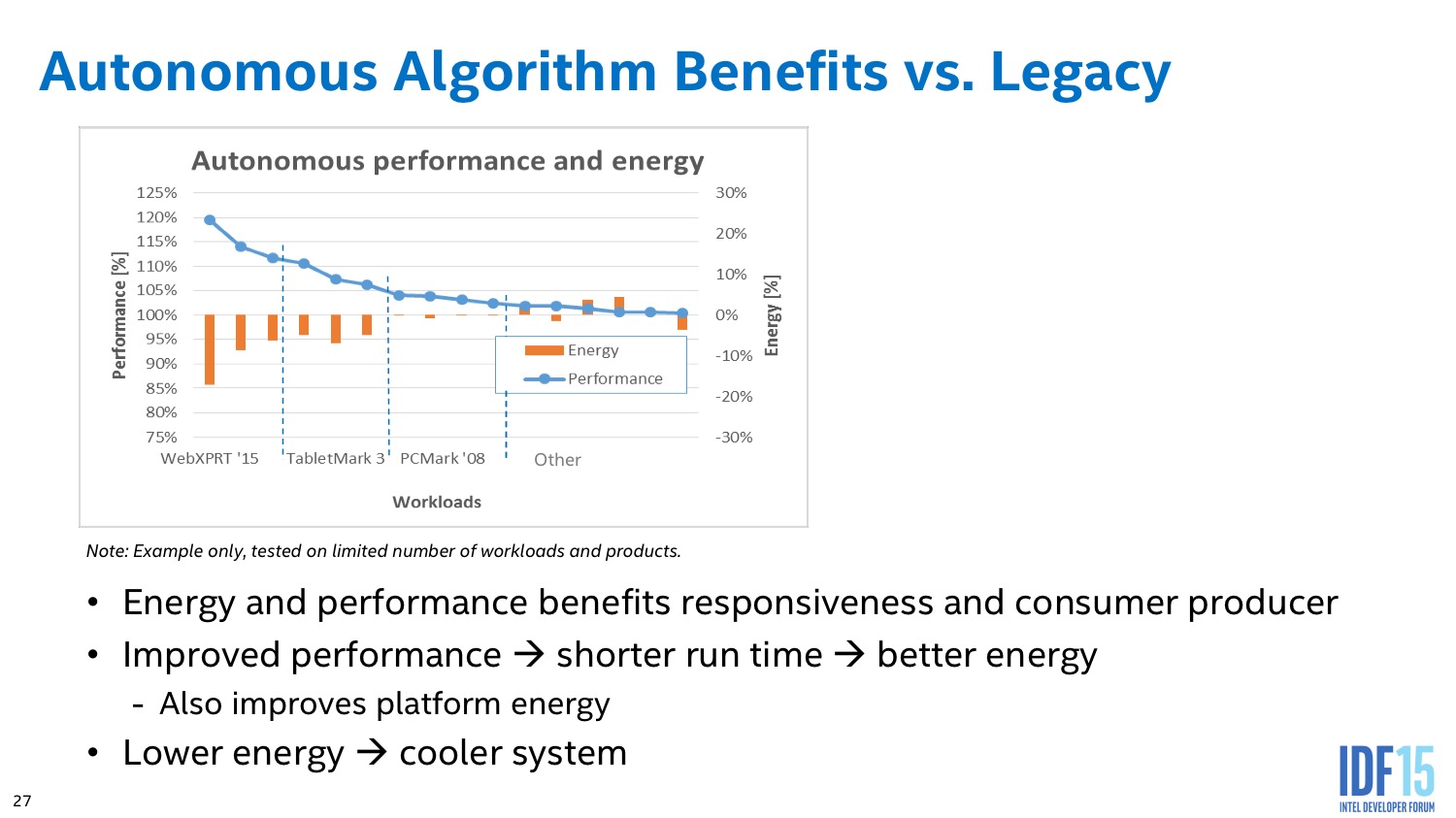 En pratique en tout cas,Intel indique être capable de réduire à la fois la consommation tout en ne sacrifiant pas sur les performances. Vous pouvez voir sur ce slide quelques résultats annoncés par le constructeur même s'il n'est pas rentré plus dans les détails ! Speed Shift changeant fondamentalement le mode d'interaction entre le processeur et système d'exploitation, on ne sera pas surpris d'apprendre que son support doit être explicite, et est donc aujourd'hui limité. Aujourd'hui, seul Windows 10 est capable de l'exploiter. Sur tous les autres OS, le fonctionnement reste à l'ancienne. Il est intriguant de voir qu'Intel n'a pas encore publié de patch pour Linux pour y ajouter le support de Speed Shift. D'autres technologies de Skylake comme MPX ont en effet eu droit à un support dès janvier sous Linux. Malgré tout, l'idée de rénover le concept fort vieux des P-States est une excellente idée, laisser la main au processeur sur sa fréquence parait presque une évidence et il sera très intéressant de voir l'impact pratique qu'aura cette technologie sur la conservation de la batterie sur les versions mobiles de Skylake. eDRAM, IVR, Chipset Un autre changement important concerne la manière dont la mémoire eDRAM est interfacée avec le processeur. Avec Broadwell par exemple, l'eDRAM est interfacée derrière le cache LLC et peut contenir de la mémoire utilisée par l'IGP ou par les coeurs mémoires (des tags dans le LLC marquent qui utilise quoi).  Avec Skylake l'eDRAM se retrouve placée entre le LLC et le contrôleur mémoire, s'intégrant de manière encore plus transparente dans la hiérarchie mémoire. En pratique ce changement permet de mettre en cache des données qui peuvent venir d'un peu partout. Le L4 peut ainsi contenir en cache des requêtes PCI Express ou du chipset. Cette transparence est cependant débrayable dans le cadre d'une utilisation graphique. Le pilote graphique Intel dispose d'un mode d'accès spécifique qui lui permet de demander où il souhaite que soit mises en cache certaines informations. Il peut demander a ce que des informations soient stockées dans le L3, ou dans l'eDRAM au choix, ou au contraire nulle part. Des décisions que le pilote, selon Intel, est plus a même d'estimer correctement. L'impact réel de ce changement est difficile à évaluer même si potentiellement il devrait profiter aux utilisations non graphiques. On notera sur la question de la suppression du régulateur de tension intégrée que les ingénieurs nous ont donné une réponse : la décision de les supprimer a été prise spécifiquement à cause des modèles 4.5W ou l'IVR était inefficace. Une « meilleure » solution, s'ils avaient eu plus de temps selon les ingénieurs d'Intel aurait été de supprimer l'IVR uniquement sur les modèles basse consommation et de les garder sur les autres. Un sous-entendu qui laisse penser que le constructeur pourrait opter pour cette séparation a l'avenir pour Cannonlake.  Notons pour terminer que le chipset, au delà des changements déjà évoqués dans notre article, propose une particularité originale : il est désormais capable d'entrer en mode throttling en cas de surchauffe. L'idée est surtout d'éviter la situation ou, a cause d'une surchauffe de la plateforme, le PCH pourrait mettre en péril le système. Intel gagne surtout un peu de marge pour les puces 4.5 et 15W qui incluent dans le package le PCH, jusque à côté du die cpu/graphique. Page 4 - Nouveautés côté GPU Si Intel utilisait jusqu'ici une stratégie dite de « Tick-Tock » pour ses architectures processeurs, ne changeant l'architecture CPU que tous les deux modèles, ce n'était pas le cas pour les architectures graphiques que le constructeur essaye de faire évoluer à chaque fois. Ainsi après la génération graphique 7.5 dans Haswell, nous avons eu droit respectivement à la génération 8 pour Broadwell, et aujourd'hui à la génération 9 pour Skylake. Quatre déclinaisons Depuis Haswell, Intel a étendu la flexibilité de ses GPU, proposant différents modèles qui se distinguent principalement par le nombre d'unités d'exécution qu'ils embarquent, allant à l'époque de 10 à 40 unités en fonction des modèles. Avec Broadwell, Intel a continué dans sa lancée en augmentant de 20% de nombre d'unités d'exécution, soit de 12 à 48 selon le modèle. Avec Skylake, Intel n'augmente pas le nombre d'unités par modèle, mais rajoute une option supplémentaire en haut de sa gamme avec 50% d'unités en plus. Voici un récapitulatif des modèles proposés : 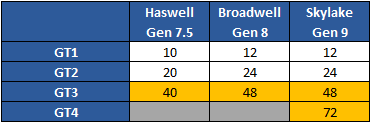 Nombre d'unités d'exécution en fonction des modèles et des architectures Intel. En orange, les modèles déclinés en version eDRAM. Haswell aura permis également pour la première fois de voir l'arrivée d'un cache de niveau 4 sur certains modèles. Il s'agit pour rappel d'une puce mémoire eDRAM additionnelle, rajoutée dans le package de certains modèles de processeurs. Une des particularités de ce cache est qu'il est global, pouvant servir à la fois aux curs CPU et au processeur graphique. Lorsqu'un processeur Intel est pourvu de cette mémoire additionnelle, le constructeur rajoute un « e » au nom du GPU (par exemple, GT3e). 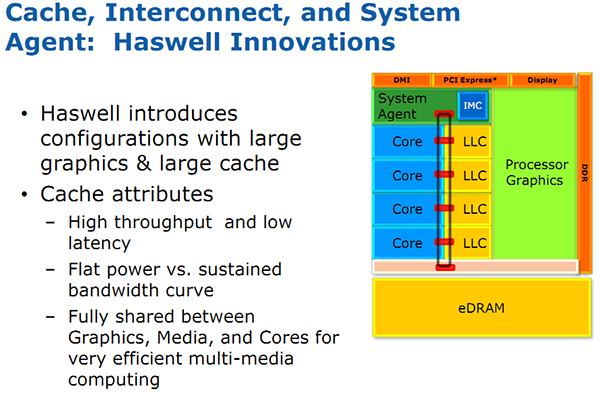 Avec Haswell, Intel avait réservé l'eDRAM à certains modèles pour PC portables haut de gamme, ainsi qu'aux modèles desktop embarqués (pour machines tout en un, type iMac). Avec Broadwell, les choses ont été un peu différentes puisque le constructeur a proposé de l'eDRAM pour les seules puces qu'il aura lancé en version socket, les Core i7-5775C et Core i5-5675C qui embarquaient 128 Mo d'eDRAM. Des puces qui utilisaient le GPU « GT3e ». En ce qui concerne les modèles desktop à socket, Broadwell détonne en étant le seul à utiliser GT3, qui plus est en version « e ». En général, les modèles desktop quadruples curs, et c'est le cas une fois de plus pour les Skylake « K » lancés aujourd'hui, utilisent le GT2 qui prend la nomenclature commerciale HD 530. Le nouveau GT4e devrait de son côté être proposé exclusivement sur les futurs modèles desktop BGA, tandis que les GT3e devraient selon toutes vraisemblances se retrouver sur les modèles mobiles. Architecture graphique D'un point de vue architectural, les changements de Broadwell concernaient principalement une augmentation de 50% du débit du texturing ainsi que 50% de cache de niveau 3 graphique supplémentaire. D'autres détails ont changé dans la microarchitecture pour améliorer les performances de fillrate, de la géométrie ou des opérations de profondeur mais Intel ne les a pas évoqués plus en détails.  Pour Skylake quelques détails commencent à filtrer, notamment sur l'organisation interne. Depuis Haswell Intel dispose d'une partie fixe baptisée Un-slice qui contient la gestion de la géométrie et d'autres fonctions fixes, et les Slices qui contiennent les EU (les groupes d'unités de calculs) ainsi que les sampler de textures (on fera le parallèle côté CPU entre Core et Uncore). Intel fait ainsi varier le nombre de slices pour créer des GPU à nombre d'EU variables. Avec Skylake, Intel aurait choisi d'utiliser deux plans d'alimentation distincts pour l'Un-slice et Slice.  Un autre changement concerne l'ajout d'un « fast path » pour la lecture vidéo, une fonctionnalité que l'on avait déjà vue introduite par AMD dans Carrizo. Il s'agit d'ajouter des blocs fixes capables d'effectuer les tâches les plus basiques comme par exemple mettre à l'échelle les vidéo (scaling). On sait qu'AMD propose également le désentrelacement, ce qui a première vue n'est pas le cas de Skylake. Malgré tout l'utilisation de ces unités permet d'éviter de passer par la mémoire du GPU et donc limiter la consommation en lecture.  On notera enfin au rang des nouveauté l'ajout de petites fonctionnalités comme la compression des couleurs (sans perte) pour réduire l'utilisation mémoire des textures et autres buffers, mais c'est surtout l'ajout de nouvelles extensions propriétaires qui surprend pour utiliser le GPU pour effectuer des tâches de retouche photo (correction de la balance des blancs, correction du vignettage, etc). Intel proposerait cela sous la forme d'extensions DirectX 11 propriétaires. Si le constructeur indique qu'elles sont flexibles, il faudra voir les API pour voir si elles seraient réellement utilisables par des logiciels spécialisés comme par exemple DxO OpticsPro, ou s'il s'agit juste de fonctions basiques. A suivre. On notera enfin que le GPU de Skylake est conforme avec les features 12_1 tier 3 de DirectX12, ce qui en fait le GPU qui dispose du support actuel le plus complet (12_1 tier2 au mieux chez Nvidia, 12_0 tier3 chez AMD). QuickSync Une nouveauté que nous avons réussi à faire confirmer à Intel concerne les blocs de décodage et d'encodage vidéo. Par rapport à Haswell, Broadwell avait apporté l'accélération du décodage des formats VP8 ainsi que SVC (version « scalable » de l'AVC/H.264 destinée principalement au streaming avec possibilité de dégradation) en version High Profile. Pour Skylake, nous avons droit à l'arrivée non seulement du décodage H.265 (mais seulement en mode "Main" 8bit malheureusement, le Main10 qui devrait être a l'avenir le format le plus répandu n'est pas supporté), que nous avions déjà croisé dans Braswell, mais aussi de son encodage ! Egalement connu sous le nom de HEVC, il s'agit d'un nouveau standard de codage vidéo ayant pour but de proposer une qualité équivalente à l'AVC (H.264) avec un bitrate divisé par deux, tout en étant optimisé pour les hautes résolutions (jusqu'au 8K). Intel propose une API (MediaSDK) qui permet aux développeurs d'exploiter l'encodage vidéo accéléré (c'est le cas de logiciels commerciaux comme MediaEspresso de Cyberlink, ou Open Source comme Handbrake) mais malheureusement, aucun de ces logiciels ne proposent le support de l'encodage HEVC/H.265 via QuickSync au moment où nous écrivons ces lignes. Gestion des écrans La gestion des écrans sous Haswell et Broadwell était commune plateforme identique oblige. Ces générations proposaient en interne quatre brins DDI pouvant être utilisés pour gérer jusque trois sorties numériques (DisplayPort 1.2, HDMI ou DVI-D, le VGA étant géré par le chipset) utilisables en simultanées (jusque 3 DP simultanés, jusque 2 HDMI/DVI-D). Il est possible de mutualiser ces brins pour atteindre des résolutions plus élevées. En pratique on pouvait ainsi atteindre le 4K en 24 Hz en DisplayPort 1.2 ou en HDMI 1.4a (le DVI-D restant limité au 1920 par 1200). La résolution maximale offerte en 60 Hz via DisplayPort était le 3840x2160. 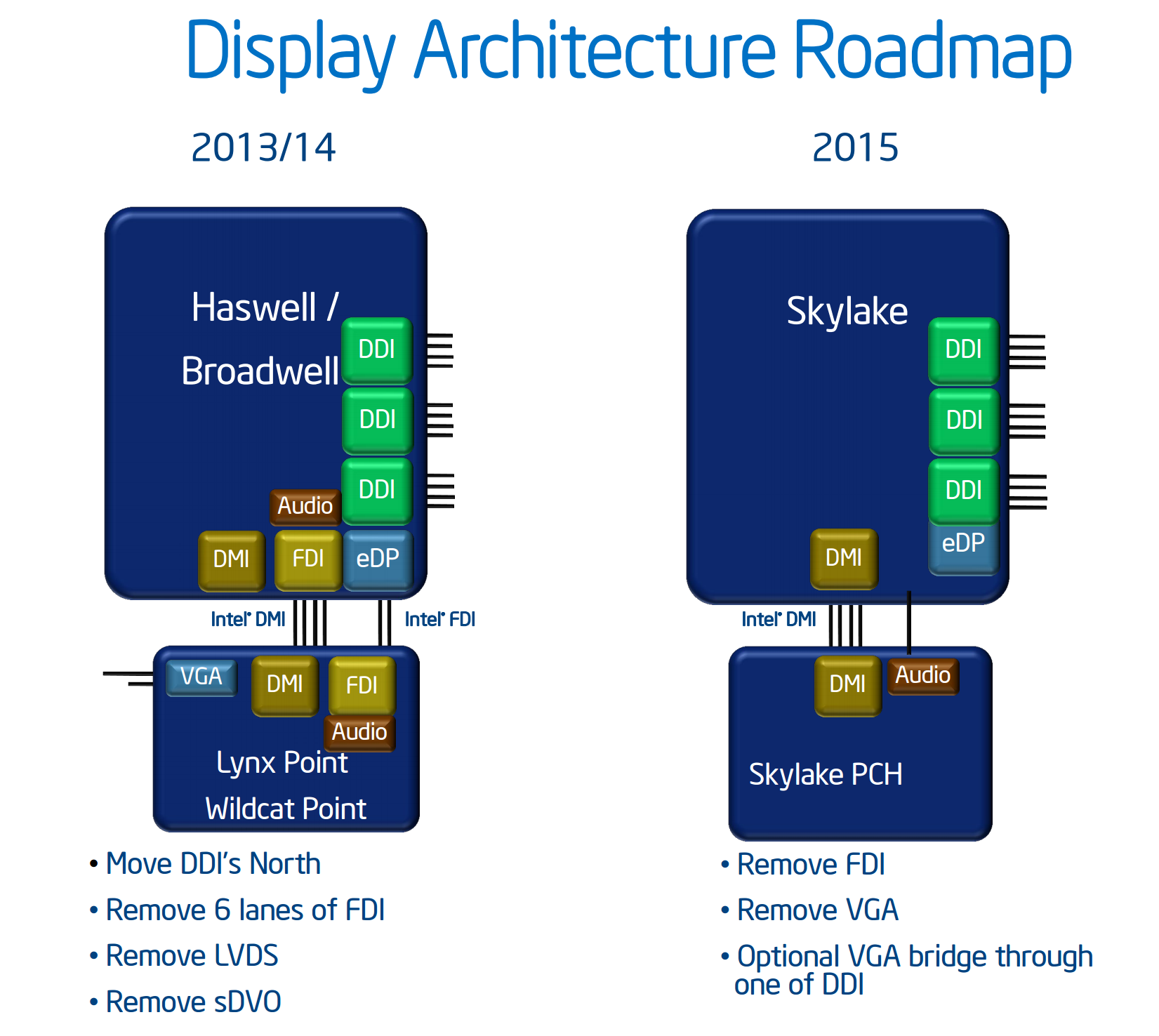 Avec Skylake Intel a revu son système de gestion en supprimant le lien FDI entre le processeur et le chipset qui servait notamment pour l'affichage VGA. Aujourd'hui, pour ajouter une sortie VGA analogique aux cartes mères (c'était le cas de nos Z170-A de test) il faut pour les constructeurs rajouter un pont à la sortie d'un brin DDI. Ces derniers sont également un peu plus performants même si nous n'avons pas beaucoup de détails. Ce que l'on sait, c'est qu'en pratique, Intel gère désormais les écrans 4K (jusque 4096x2304) en 60 Hz en DisplayPort 1.2. Intel ne gère par contre pas le 4K 60 Hz en HDMI, on est toujours limité au 24 Hz, en version 1.4b (pas de gestion du HDMI 2.0, certaines cartes mères pourraient rajouter un convertisseur DP vers HDMI 2.0 cependant). Par rapport à la version gérée par Haswell/Broadwell, HDMI 1.4b rajoute la gestion du 1080p 3D 60Hz par il. Mise à jour du 21/08/2015 : Lors de l'IDF nous avons pu en apprendre plus, vous trouverez ci-dessous notre actualité publiée à cette occasion pour la partie GPU : Lors de notre test de Skylake, nous avions pu publier quelques détails sur le fonctionnement de son architecture graphique. L'IDF a cependant été l'occasion d'obtenir quelques précisions supplémentaires que nous allons essayer de vous détailler. En pratique la grande majorité des modifications a surtout un impact sur la consommation, et non sur les performances comme l'ont montrés nos tests pratiques. Architecture De haut niveau, la génération graphique 9 de Skylake est assez proche de celle de Broadwell. Comme nous l'indiquions à l'époque on retrouve les mêmes concepts de « slices » et d'EU. C'est à l'intérieur de ces unités que l'on retrouve les changements. On notera au niveau de la gestion de la géométrie que toute la partie tessellation a été optimisée pour tenter de diminuer au maximum la génération de géométrie inutile (et donc améliorer les performances). 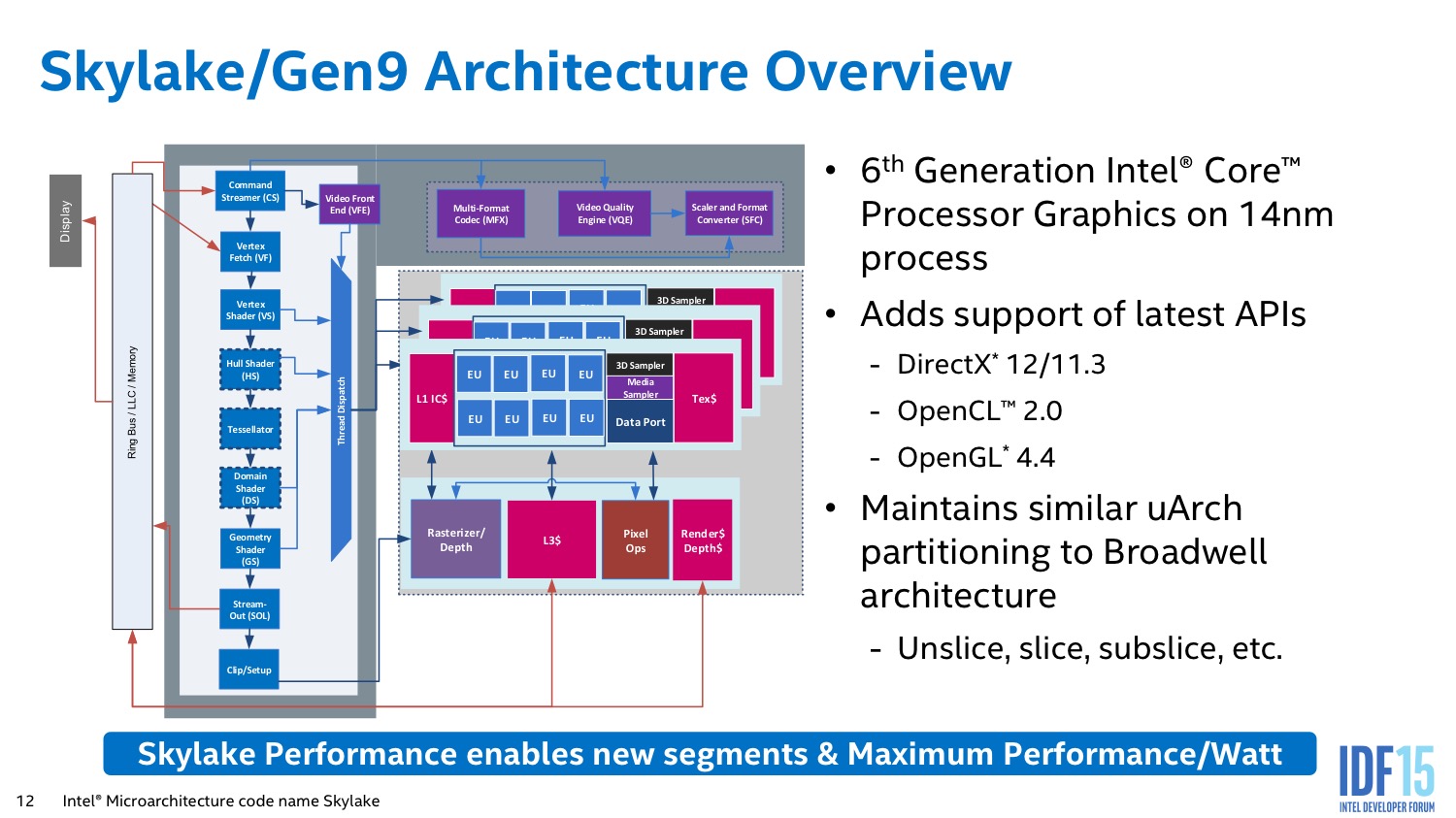 Au niveau du rasterizer on note quelques changements. Côté anti-aliasing un mode MSAA x16 apparait, tandis que les modes inférieurs gagnent en performance et l'on note l'augmentation de la taille du L3 graphique (qui passe de 512 Ko à 768 Ko). La compression ne se limite pas aux buffers de couleurs, mais s'applique également aux Render Target, une compression sans pertes est disponible (jusqu'a un ratio de 2:1) qui permet de réduire l'impact sur la mémoire et le cache. Un changement qui permet de réduire la consommation, et d'augmenter un petit peu les performances. On notera enfin quelques petits changements qui visent plus précisément l'aspect « compute » avec une amélioration des performance de la gestion de la cohérence du cache et de nouvelles instructions atomiques (pour un élément, a l'inverse des instructions vectorielles qui s'appliquent a plusieurs éléments à la fois). QuickSync et media Nous avions dans notre test noté le saut de qualité offert par QuickSync en ce qui concerne l'encodage vidéo H.264. La raison principale de ce changement semble être l'ajout d'une gestion de l'adaptative rate control pour relancer l'encodage de frames jugées comme mal encodées après coup. Au delà de l'amélioration de qualité, nous avons noté que sur les transitions de scènes (hors I-Frame), Broadwell et Skylake se distinguent largement des architectures Intel précédentes, ce qui peut être lié à ce changement. 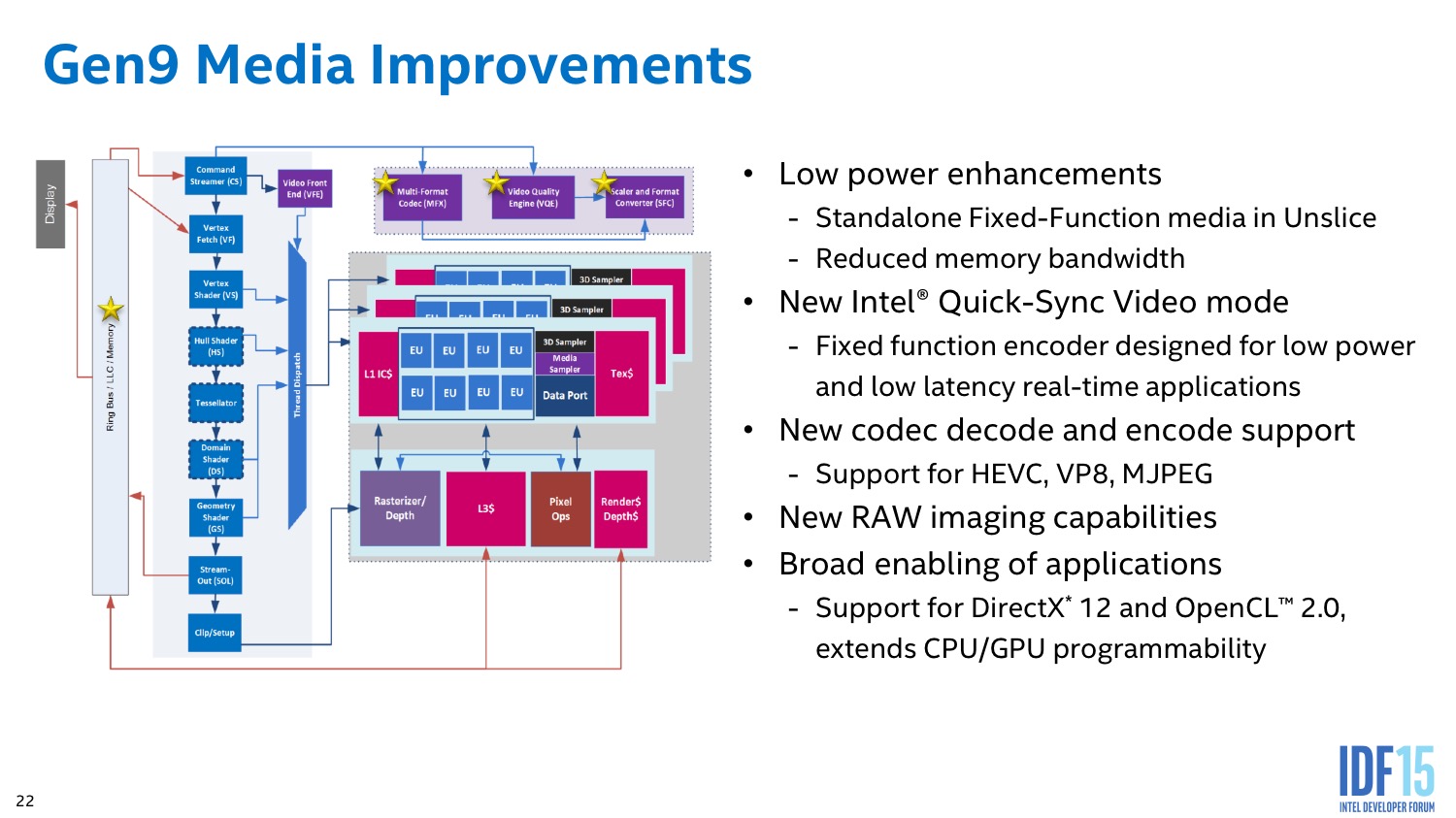 Cette amélioration nette de la qualité d'encodage n'est cependant pas le seul changement apporté. En pratique le GPU de Skylake inclut trois blocs pour ces traitements, un dédiée à l'encodage/décodage (MFX), un aux traitements vidéos (VQE), et un nouveau bloc pour les conversions de formats vidéo (changement d'espaces de couleur) et de scaling (SFC). Du côté du MFX la plus grosse nouveauté concerne l'arrivée du décodage et de l'encodage du format H.265/HEVC 8 bit (le profil main). Intel confirme que pour l'instant, le HEVC 10 bit n'est pas décodé par le MFX, une accélération « GPU » est annoncée mais elle n'est pas transparente comme l'accélération DXVA des autres formats. Intel a également ajouté un encodage des formats JPEG et MJPEG, des formats triviaux à encoder pour le processeur, le but étant surtout de réduire la consommation via des unités fixes. C'est d'ailleurs l'autre nouveauté que l'on retrouve au niveau de l'encodage H.264/AVC, Intel a ajouté des unités fixes pour réaliser un encodage temps réel (FF Mode). Le but de ce mode alternatif est de proposer un encodage d'une qualité un peu inférieure, mais avec un débit et un temps de compression prévisible. 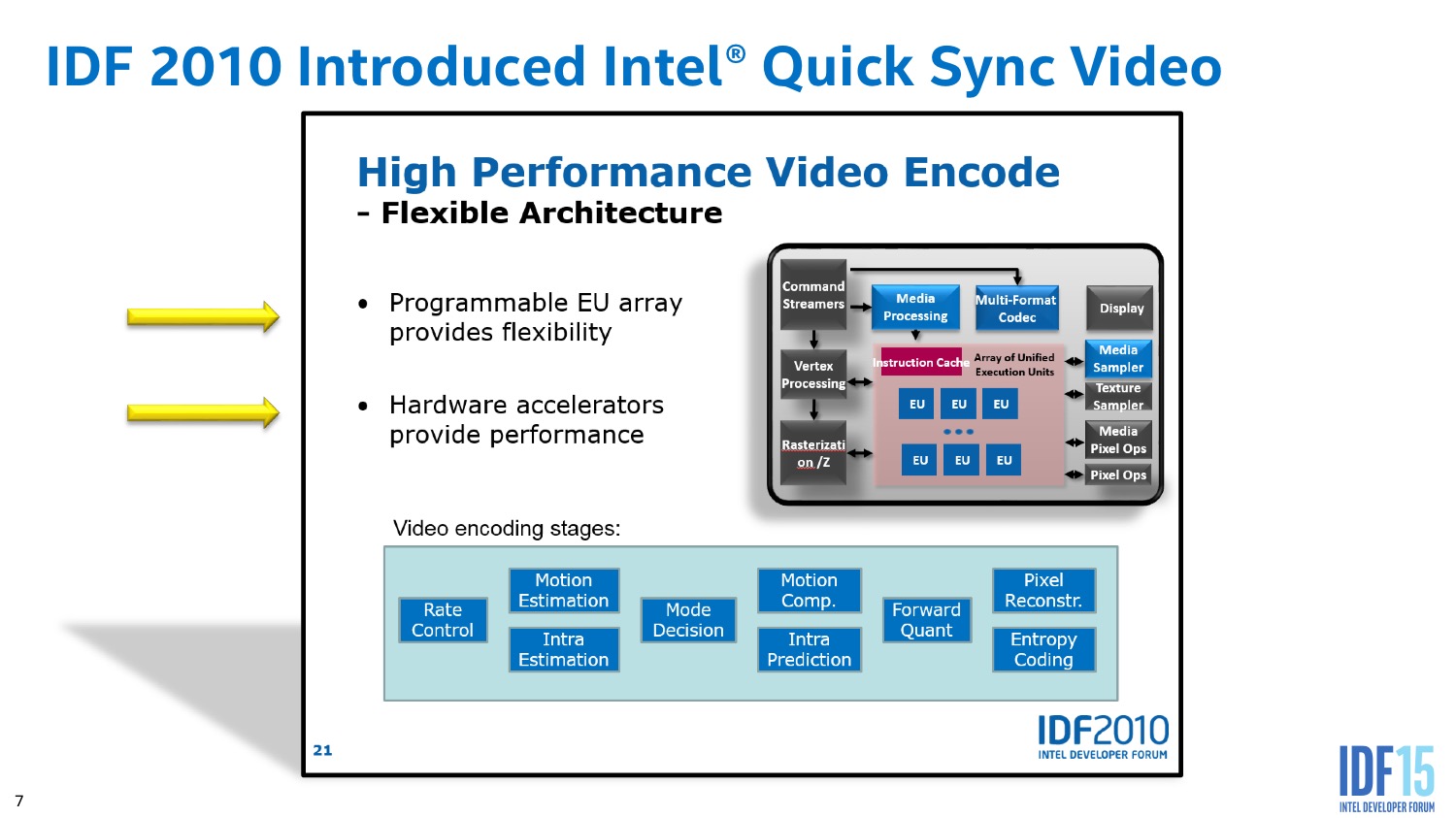 Nous avons pu voir une démo sous Starcraft II, ou l'on pouvait noter une qualité en dessous de ce que l'on obtient via le mode classique, mais tout à fait suffisante pour streamer en temps réel une partie en ligne avec un impact minimal sur la consommation et les performances CPU. Du côté du VQE, c'est le traitement des formats RAW qui est accéléré avec les opérations de correction de balance des blancs, conversions d'espace colorimétrique et correction de gamma nottament. Des traitements qui peuvent s'appliquer non seulement aux photos, mais également aux vidéos RAW en provenance de DSLR/caméras vidéos 4K.  Enfin, le SFC est une nouveauté, c'est lui qui permet la gestion de ce que Microsoft appelle le mode Multi Plane qui permet d'afficher les vidéos en limitant au maximum les interactions avec la mémoire en accélérant en temps réel les opérations de scaling et conversions de couleurs. Les vidéos décodés sont ainsi adaptées directement à l'écran sans avoir besoin de passer par la mémoire centrale ou un cache pour traitement. Une fonctionnalité qui est également implémentée par AMD dans ses APU Carrizo pour rappel. Système d'affichage De ce côté Intel a effectué plusieurs remises à niveau de sa plateforme, en supprimant la liaison FDI entre le CPU et le chipset et en supprimant dans ce dernier la gestion des sorties analogiques VGA. Aujourd'hui, si l'on souhaite ajouter à sa carte mère Skylake une sortie VGA, il faudra rajouter une puce pour convertir le signal numérique en analogique, ce qui explique la rareté des sorties VGA sur beaucoup de cartes mères annoncées par les constructeurs, là ou elles étaient pléthoriques dans les gammes Z87/Z97 ! On retrouve toujours à l'intérieur trois « display pipe » qui peuvent être utilisées en simultané pour gérer jusque trois écrans. En pratique chaque pipe est capable de « composer » les images à partir de plusieurs plans (4 dans Skylake, une nouveauté). Typiquement en plus d'un fond fixe, on peut avoir une ou plusieurs vidéos, ainsi qu'un plan dédié en général à l'affichage du curseur de souris. Les pipes composent ainsi indépendamment jusque trois images. Ces sorties sont enfin multiplexées vers les trois sorties DDI, qui s'occupent de convertir les images générées vers le format de sortie (DisplayPort ou HDMI). 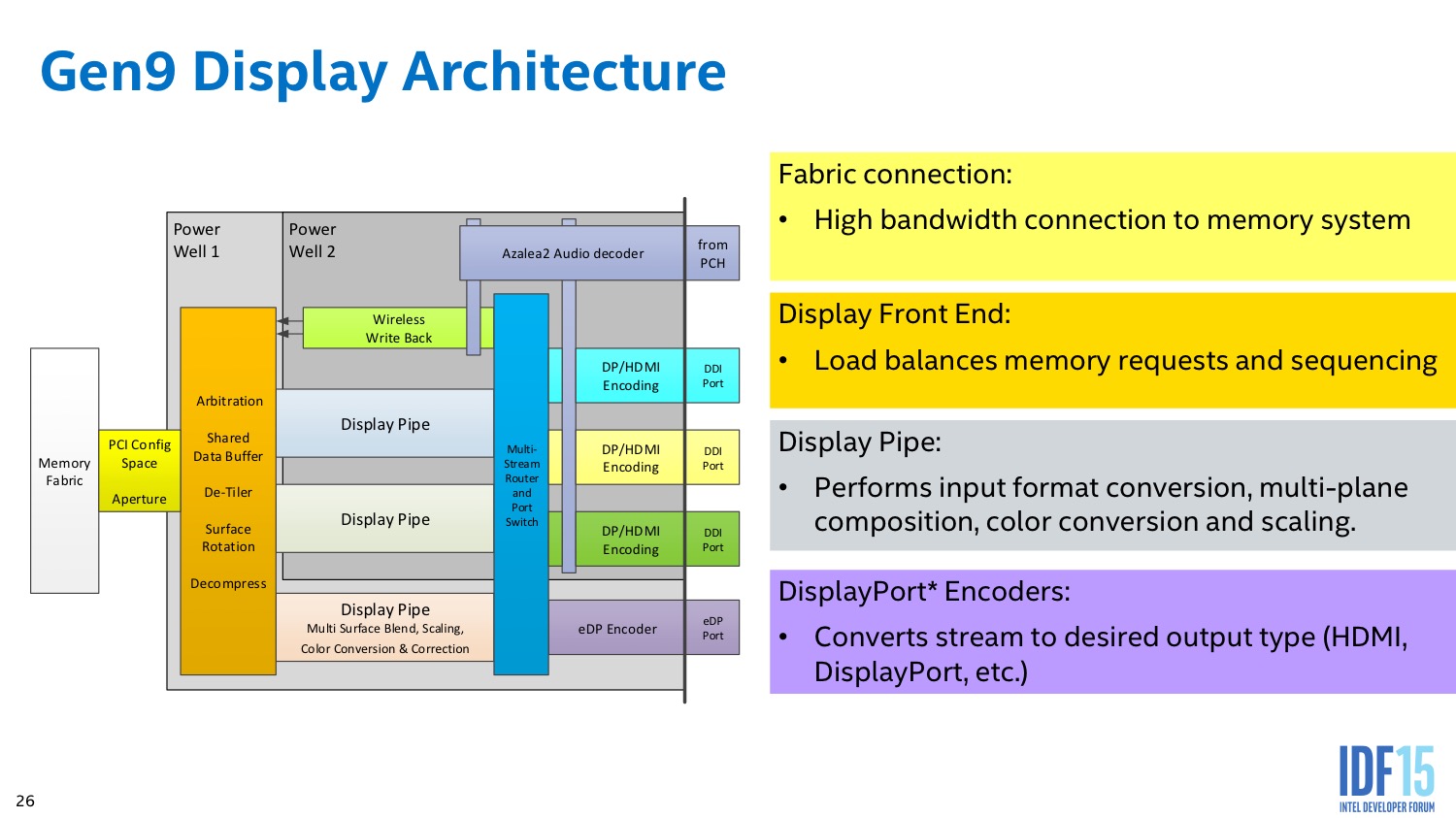 Avec Skylake l'autre nouveauté principale est qu'il est désormais possible d'atteindre le 4K 60 Hz pour les versions desktop. Comme nous l'avions indiqué à l'époque, Intel ne gère pas le HDMI 2.0, même s'il est possible en théorie de convertir la sortie d'un port DP 1.2 vers le HDMI 2.0. Plusieurs cartes mères Z170 avaient été annoncées avec ce support mais comme nous l'avons vu chez Gigabyte, l'annonce de ce support a été retirée des spécifications même si le convertisseur est bien présent sur la carte, sans que l'on sache s'il s'agit d'un problème de firmware ou d'autre chose.  Notez que le support diffère sur les modèles U (15W) et Y (4.5W) ou le constructeur limite la résolution maximale pour limiter la consommation. On note avec attention que certains modes sont autorisés uniquement si l'OEM propose un refroidissement suffisant.  On notera enfin qu'en ce qui concerne l'affichage, Intel a indiqué être prêt à adopter l'extension « adaptive sync » de la norme DisplayPort. Cette extension qui permet de faire varier le taux de rafraichissement à la volée avait été développée pour rappel par AMD. On ne sait pas quand, ni avec quels iGPU l'adaptive sync pourrait être supporté par Intel. Théoriquement le support de la version eDP semble être présent depuis Broadwell mais rien ne dit que cela puisse s'appliquer aux DDI qui gèrent les sorties DP actuellement dans Broadwell et Skylake. Page 5 - Core i7-6700K, i5-6600K, ASUS Z170-A et G.SKILL DDR4-3600 Core i7-6700K, Core i5-6600K, ASUS Z170-A et G.SKILL DDR4-3600  Pour ce test nous avons pu mettre la main sur les deux références lancées ce jour, à savoir un Core i7-6700K et un Core i5-6600K. Ces deux processeurs disposent d'un TDP reporté à 95 watts par les outils, mais bizarrement Intel parle de 91 watts dans la documentation marketing associée au lancement. Physiquement un Skylake est très proche de ses prédécesseurs. 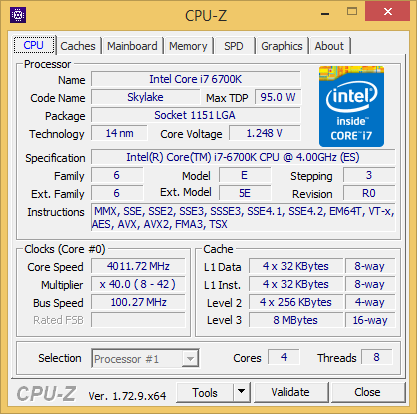 Le Core i7-6700K dispose de 4 curs avec Hyperthreading et d'un LLC de 8 Mo, la fréquence de base des curs x86 est de 4 GHz alors que l'iGPU peut atteindre un maximum de 1.15 GHz. Si le Turbo est de 4.2 GHz, il n'est valable que pour un cur actif alors que dans les mêmes conditions un 4790K était capable d'atteindre 4.4 GHz, et 4.2 GHz avec 4 curs actifs. Un choix probablement guidé par la consommation, la tension par défaut étant déjà de 1.23V à 4 GHz ce qui n'est guère encourageant pour l'overclocking de cette puce 14nm (généralement, plus on abaisse la finesse de gravure moins il faut pousser la tension sous peine d'endommager les transistors). 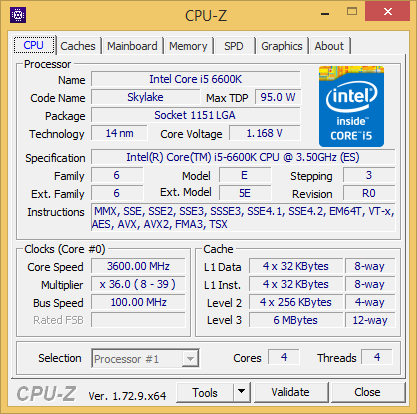 Le Core i5-6600K est dépourvu d'Hyperthreading et son LLC est réduit à 6 Mo. L'iGPU conserve une fréquence de 1.15 GHz alors que les 4 curs x86 ont une fréquence de base de 3.5 GHz. Le Turbo permet par contre cette fois d'aller un peu plus loin avec 3.9 GHz (+400 MHz) sur 1 cur, 3.8 GHz (+300 MHz) sur 2 curs, 3.7 GHz (+200 MHz) sur 3 curs et 3.6 GHz (+100 MHz) sur 4 curs. Cette fois la tension de fonctionnement est plus raisonnable puisque de 1.16v. Les tarifs recommandés sont respectivement de 350$ et 243$, soit à peu de choses près ceux des Core i7-4790K et i5-4690K. Comme souvent sous l'effet de la nouveauté et des approvisionnements qui ne se font que via les canaux officiels il devrait toutefois y avoir un écart de prix, de l'ordre de 10%, durant les premières semaines. Attention, comme les processeurs LGA 2011, ces LGA 1151 en version K ne sont pas fourni avec un ventirad ! En soit ce n'est pas une grosse perte vu les performances de celui fournit jusqu'alors, mais il pouvait dépanner.  Pour le test ASUS nous a fourni une carte mère Z170-A, son nouveau milieu de gamme. Au format ATX elle intègre une alimentation 8 phases pour le processeur et 3 ports PCIe x16, les deux premiers étant reliés au CPU et fonctionnant en x16/x0 ou x8/x8 ce qui permet entre autre de profiter du SLI ou du CrossFire, le troisième est relié en x4 au mieux au Z170 Express. Par défaut il est configuré en x2, l'utiliser en x4 désactivera 2 SATA. 2 autres SATA sont intégrés au sein d'un SATA Express, avec cette fois un partage du SATA avec le port M.2 ce qui n'est pas vraiment problématique puisque tout l'intérêt du M.2 réside dans la possibilité d'utiliser des SSD PCIe. La partie audio est déléguée à un codec Realtek ALC892 associé à une intégration dénommée Crystal Sound 3 par ASUS qui regroupe les artifices habituels afin de garantir une bonne qualité pour le son intégré. Le réseau est pour sa part géré par une puce Intel I219V, un PHY permettant d'utiliser le contrôleur intégré au Z170. En sus de 6 ports USB 3.0 gérés par le Z170 (4 via deux connecteurs internes, 2 à l'arrière), ASUS a décidé d'intégrer une puce ASMedia afin de proposer 2 connecteurs USB 3.1, l'un de Type-A et l'autre de Type-C. A l'usage la carte mère et son bios UEFI, dont ASUS a encore amélioré l'ergonomie déjà très bonne, s'est relevé sans accroc. Le tout est proposé au prix indicatif de 169 , une hausse notable par rapport à la Z97-A qu'on trouve à 139 ! Espérons que ce ne soit que temporaire...  Enfin G.Skill nous a pour sa part envoyé un kit DDR4 très rapide Ripjaws V composé de 2x4 Go DDR4-3600 en 17-18-18-38 à 1.35v. Avec de telles vitesses, l'écart se creusera peut-être face à la DDR3 c'est ce que nous allons voir sous peu ! Page 6 - CPU : DDR4 vs DDR3 en pratique CPU : DDR4 vs DDR3 en pratiqueSi Intel et tous les constructeurs mettent en avant la DDR4 pour ce lancement, nous avons eu la chance de pouvoir mettre la main sur une carte mère Z170 pouvant accueillir de la DDR3. Même si son bios nous a posé quelques soucis au niveau du Turbo nous avons utilisé un Core i7-6700K bloqué à 4 GHz, avec Hyperthreading désactivé afin d'avoir une meilleure stabilité au niveau des résultats, afin de comparer de nombreux réglages mémoire. [ AIDA64 Lecture ] [ AIDA64 Ecriture ] [ AIDA64 Latence ] On commence par les tests théoriques avec les résultats sous AIDA64. En terme de bande passante, la DDR3 se montre sous son meilleur jour en DDR3-2400, au-delà on note une baisse des résultats. A vitesse égale (DDR4-2400 vs DDR3-2400) les bandes passantes sont proches, avec un leger moins bien pour la DDR4. La DDR4-3600, la plus rapide, permet d'obtenir environ 30% de bande passante supplémentaire face à la DDR3-2400. Côté latence c'est moins rose. En effet, si à réglages "équivalents" la DDR4 est 1ns plus rapide environ, bien qu'il faille prendre en compte comme nous l'avons vu précédemment que sur Skylake la latence que nous avons mesurée en DDR3 est moins bonne de quasi 4ns par rapport à Haswell, la DDR4 en vente offre des timings plus relâché au profit de la hausse de fréquence. Du coup pour être au niveau de la DDR3-2400 11-11-11, il faut de la DDR4-2800 comprise entre 16-16-16 et 15-15-15, les DDR3 les plus véloces n'étant dépassées que légèrement et à partir de la DDR4-3000 15-15-15. [ 7-zip ] [ x265 ] [ Arma III ] En pratique c'est encore plus compliqué pour la DDR4. Sous 7-zip, qui est très dépendant de la vitesse mémoire, de la DDR3 rapide permet de gagner jusqu'à 17,9% de performance par rapport à de la DD3-1600, et ce ne sont que les DDR4-3466 et DDR4-3600 qui parviennent à se hisser au même niveau. x265 est par contre à l'opposé et ne bénéficie pas vraiment d'une hausse de la vitesse mémoire. Entre la mémoire la plus lente et la plus rapide du graphique, le gain n'est que de 0.5% et malgré la relative stabilité des résultats on n'est pas loin de la marge d'erreur du benchmark ! On termine avec Arma III qui à l'instar de 7-zip et de nombreux jeux apprécie une mémoire véloce avec 10% de mieux environ entre de la DDR3-1600 et les DDR3 les plus rapides. Le comportement de la DDR4 est ici légèrement meilleur que sous 7-zip puisqu'il ne faut "que" de la DDR4-3000 pour dépasser d'un poil les meilleures DDR3. Si la DDR4 offre un avantage certain en terme de bande passante, ce qui pourrait être utile pour les iGPU, côté CPU son apport est pour le moins limité d'autant que les barrettes les plus rapides ne seront pas données. Si vous disposez déjà de la bonne quantité de mémoire et souhaiter faire une upgrade vers Skylake, vous pouvez partir sur une carte mère en DDR3 sans regret, la seule limitation étant peut-être de s'assurer qu'un kit 1.65v puisse être utilisable à long terme avec un Skylake ce que nous ne savons pas encore. Quoi qu'il en soit, sur desktop la DDR4 nous laisse sur notre faim, mais c'était également le cas de la DDR3 et de la DDR2 à leurs lancements ! Page 7 - CPU : Sandy Bridge vs Ivy Bridge vs Haswell vs Skylake à 4 G CPU : Sandy Bridge vs Ivy Bridge vs Haswell vs Skylake à 4 GHzNous avons bien entendu voulu étudier les gains de performance à fréquence égale offert par cette nouvelle architecture. Pour ce faire, nous avons utilisé des Core i5-2500K, Core i5-3570K, Core i5-4670K, Core i5-5675C et Core i5-6600K, respectivement pour Sandy Bridge, Ivy Bridge, Haswell, Broadwell et Skylake, tous cadencés à 4 GHZ pour leurs curs x86. Depuis Haswell, le ring bus et le cache LLC disposent d'un domaine de fréquence propre, généralement moins propice à la montée en fréquence dans le cadre de l'overclocking. Pour cette raison nous l'avons fixé à 3.5 GHz pour ces tests qui sont effectués avec de la DDR3-2133 11-11-11-31 1T. Nous avons également ajouté les performances de Skylake avec de la DDR4-2800 15-15-35-1T, ce qui lui donne un avantage plus important qu'en page précédente sur l'i7 sous l'action combiné du cache LLC de taille plus réduite et cadencé à une vitesse plus faible. Par rapport à Sandy Bridge, Skylake offre un gain moyen de 22,3% en applicatif, et 1.5 points de plus en passant à la DDR4. Il est par essence assez variable, puisque supérieur à 30% dans certaines applications : les deux moteurs de rendu sous 3ds, x264 et x265. A noter que depuis la version utilisée pour ce test, x265 a de nouvelles versions encore plus optimisées pour les architectures CPU les plus récentes et le gain grimpe alors à 60% ! A contrario sous WinRAR et 7-zip les gains sont inférieurs à 10%. Par rapport à Haswell le gain est de de 5,5%, avec dans le pire des cas 1-3% (Visual Studio, Stockfish et Houdini). En jeu le gain moyen est cette fois de 21,1% face à Sandy Bridge, avec 4.9 points de mieux en DDR4 tout de même. Là encore les gains étant assez variables : seulement 7-8% sous Watch Dogs et F1 2013, mais pas moins de 45% pour X-Plane 10 ! Par rapport à Haswell le gain grimpe à 8 en DDR3 et 13% en DDR4, avec des gains plus stables : 5 à 16% de mieux en DDR3, 8 à 19% en DDR4. Par rapport à Broadwell et son eDRAM les gains sont très faibles, et dans certaines applications les gains liés à la microarchitecture ne permettent pas de compenser la perte de l'eDRAM. A fréquence égale, dans les jeux Broadwell est même devant Skylake ! Page 8 - CPU : Overclocking en pratique CPU : Overclocking en pratiqueNous cherchons, par cran de 0.05v, la tension la plus basse à 4 GHz, puis nous augmentons la fréquence par palier de 200 MHz tant que 0.05v supplémentaires sont suffisants. Si ce n'est pas le cas nous essayons de stabiliser 100 MHz en-dessous puis ré-augmentons la fréquence par palier de 100 MHz. La stabilité est validée à l'aide de Prime95 en FFT 256K pendant 15 minutes, la température reportée étant la moyenne des 4 curs pendant la dernière minute du test sachant qu'il s'agit d'un système de test ouvert avec une température ambiante de 25°C, les CPU étant refroidis par un Noctua NH-U12P SE2. 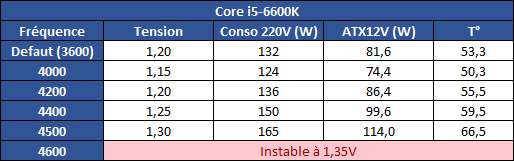 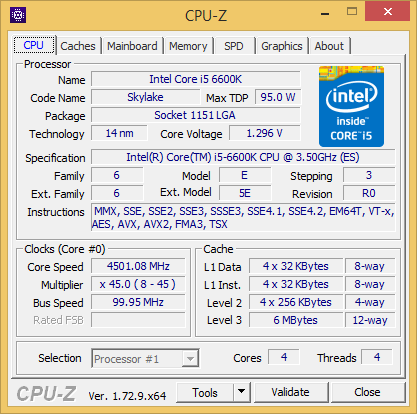 On commence par le Core i5-6600K qui fonctionne par défaut à 3.6 GHz sous Prime95, 100 MHz de plus que sa fréquence de base. Avec ce type de charge sa tension monte à 1.2v par défaut, contre 1.16v sous une charge plus raisonnable telle que Fritz Benchmark. Nous avons pu l'abaisser à 1.15v tout en montant la fréquence à 4.0 GHz, on profite alors d'une consommation moindre malgré des performances en hausse. La montée en fréquence se fait par cran de 200 MHz et 0.05v jusqu'à 4.4 GHz, mais pour stabiliser les 4.5 GHz nous sommes passés à 1.3v alors que les 4.6 GHz n'étaient pas stables à 1.35v, tension à laquelle nous avons décidé de nous arrêter. 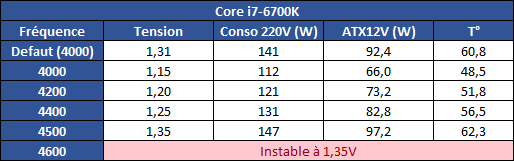 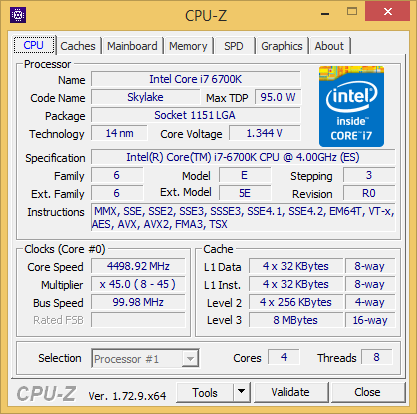 Sous Prime95 le Core i7-6700K fonctionne à 4 GHz, le Turbo n'offrant pas de gain en fréquence. Alors que nous étions à 1.23v sous Fritz, la tension grimpe cette fois à 1.31v sous Prime95 par défaut. Bizarrement malgré cette tension annoncée très haute la consommation est à peine supérieure à celle mesurée sur l'i5-6600K. Il s'agit en fait de l'action de deux facteurs combinés, d'une part sur Skylake la charge est réduite sous Prime95 avec l'HyperThreading, mais reste tout de même supérieure à celle d'applications classiques, d'autre part même à charge égale (4 thread) nous avons noté un avantage de l'ordre de 8 watts à la prise pour l'i7 (à 1.15V et 4 GHz), qui souffre probablement de moins de courants de fuite que l'i5. Revenons à l'overclocking en lui-même. A 4 GHz nous avons pu utiliser une tension de 1.15v sur l'i7-6700K ce qui entraine une baisse plus que notable de la consommation. Pour 4.2 et 4.4 GHz on utilise 1.2 et 1.25v, comme sur l'i5-6600K, par contre les 4.5 GHz n'ont pu être stabilisés qu'avec une tension de 1.35V. Les 4.6 GHz n'ont pas pu être stabilisés à 1.35v, notre limite de tension. Sur la base de ces deux échantillons nous avons donc une limite vers 4.5 GHz, avec la nécessité d'augmenter la tension de 0.05 ou 0.1v par rapport à 4.4 GHz. On semble se situer à peu près au niveau des Haswell pour un OC H.24 (i5-4690K et i7-4790K), mais certains exemplaires notamment en Haswell Refresh étaient capables d'aller plus haut, il faudra voir si c'est également le cas côté Skylake. On reste donc par contre en retrait par rapport à Sandy Bridge qui à maturité permettait de dépasser les 4.5 GHz et même d'approcher les 5 GHz. Page 9 - HD Graphics 530 en pratique : Jeux Nous avons voulu évaluer les performances de la partie graphique intégrée aux Skylake-K, la neuvième génération graphique dénommée pour rappel HD Graphics 530. Nous avons profité de l'occasion pour la comparer aux deux précédentes, y compris la très particulière génération 8 de Broadwell qui comme nous l'indiquions plus tôt, profite à la fois d'un GPU plus large (GT3), mais aussi d'un cache L4 de 128 Mo. Voici en pratique les puces que nous avons utilisées pour ces comparaisons : - Intel Core i5 4690K (Haswell, Gen7.5), GT2 (20 EU) à 1.2 GHz, TDP 88W - Intel Core i5 5675C (Broadwell, Gen8), GT3e (48 EU, 128 Mo L4) à 1.1 GHz, TDP 65W - Intel Core i5 6600K (Skylake, Gen9), GT2 (24 EU) à 1.15 GHz, TDP 95W Nous avons également ajouté deux APU AMD Kaveri, un modèle 65W ainsi que le plus rapide des modèles 95W disponibles : - AMD A8-7600 (Kaveri), 6 CU à 720 MHz, TDP 65W - AMD A10-7870K (Kaveri), 8 CU à 866 MHz, TDP 95W Et afin de voir comment se comportent ces solutions face aux modèles graphiques d'entrée de gamme, nous avons ajouté les trois premiers modèles chez AMD et Nvidia, en version GDDR5 uniquement : - AMD R7 240 GDDR5, Oland 320 unités, 780/1150 MHz, TDP 30W - AMD R7 250 GDDR5, Oland 384 unités, 1050/1150 MHz, TDP 65W - AMD R7 360 GDDR5, Bonaire 768 unités, 1050/1625 MHz, TDP 100W - Nvidia GT 730 GDDR5, GK208 384 unités, 901/1250 MHz, TDP 38W - Nvidia GT 740 GDDR5, GK107 384 unités, 993/1250 MHz, TDP 64W - Nvidia GTX 750 GDDR5, GM107 512 unités, 1019/1250 MHz, TDP 55W Pour les plateformes existantes avant aujourd'hui, nous avons regardé les performances avec de la mémoire DDR3 dans deux déclinaisons : - DDR3-1600 9-9-9-24 - DDR3-2133 11-11-11-31 Pour Skylake, nous regardons les performances à la fois avec de la mémoire DDR3, mais aussi avec de la mémoire DDR4 dans deux timings : - DDR3-1600 9-9-9-24 - DDR3-2133 11-11-11-31 - DDR4-2133 13-13-13-31 - DDR4-2800 16-16-16-36 Nous avons testé les cartes graphiques sur la configuration Haswell en DDR3-1600, comme vous le verrez par la suite nous avons choisi des jeux ou nous ne sommes pas limités par le processeur. Afin d'être complet, notez que nous avons utilisé les pilotes suivants : - APU/CG AMD : Catalyst 15.7.1 - CG Nvidia : GeForce 353.62 - Intel Haswell/Broadwell : 15.36.23.64.2451 - Intel Skylake : pilotes beta fournis par Intel Malheureusement les pilotes graphiques pour Skylake fournis par Intel pour nos tests n'étaient pas capables de fonctionner sur les générations précédentes du constructeur. Notez en prime que ces pilotes étaient particulièrement instables, nous n'avions pas vu autant de redémarrages du pilote WDDM par Windows depuis Vista ! Parlant de Windows, notez que nous avons utilisé 8.1 en version 64 bits pour réaliser nos tests. Pour être complet, les autres composants utilisés sont : - Asus A88XM-Plus (AMD Kaveri) - Asus Z97-A (Intel Haswell/Broadwell, et cartes graphiques) - Asus Z170-A (Intel Skylake DDR4) - 8 Go de DDR3/DDR4 Regardons maintenant les performances que nous avons obtenues pour ces différentes plateformes dans les jeux : F1 2014  Nous avons réalisé l'intégralité de nos tests graphiques en 1080p, nous utilisons pour F1 2014 le mode graphique « intermédiaire » : Plusieurs enseignements à tirer, tout d'abord on notera que dans ce titre, les APU restent devant Skylake, ce qui consolera AMD. Ensuite, on notera qu'avec de la DDR3, l'avantage de 20% d'unités en plus se traduit par 16% de gains. Des gains qui n'augmentent pas lorsque l'on passe à la DDR4. En pratique la DDR4-2133 se comporte au niveau de la DDR3-1600, tandis que la DDR4-2800 peine à faire aussi bien que la DDR3-2133 ! Passer de la DDR4-2133 à la DDR4-2800 améliore les performances de 8.8%. Broadwell, du haut de ses 128 Mo de mémoire embarquée se permet d'aller titiller les APU et les cartes graphiques d'entrée de gamme des constructeurs. League of Legends  League of Legends est un jeu fort peu gourmand, nous utilisons donc le réglage maximal à l'exception de l'anti-aliasing, toujours en 1080p : Sous League of Legends, à mémoire égale en DDR3-2133, Skylake arrive à faire un peu mieux, de 10% environ que notre Core i5 Haswell. On retrouve le même parallèle entre DDR3 et DDR4 que ce que nous avions noté avec F1 2014. Toutes les plateformes permettent ici de jouer dans des conditions extrêmement confortables, on saluera quand même les performances de Broadwell, quasi 70% devant Skylake et qui se place entre le premier et le second échelon des constructeurs graphiques. Chez ces derniers, le R7 240 est 15% plus performant que la GT 730, les autres échelons étant dans un mouchoir. Battlefield 4  Nous regardons les performances graphiques des différentes solutions en 1080p, réglage graphique faible. Les APU restent toujours devant Skylake, même si les scores sont ici un peu plus tassés. En DDR3-2133, Skylake dépasse Haswell d'environ 15%. La DDR4 ne transcende pas les performances. Broadwell est plus rapide de 90%, rendant le jeu confortable. Ses performances s'approchent même du second échelon proposé par Nvidia dont les cartes sont légèrement derrière (entre 5 et 10%) leurs équivalents d'entrée de gamme AMD. The Witcher 3  Nous regardons les performances graphiques des différentes solutions en 1080p, réglages graphiques et postprocessing « Low ». Les APU d'AMD restent devant, de peu, dans ce titre qui met à genoux l'entrée de gamme. Il n'y a bien que R7 360 et GTX 750 qui s'approchent de la jouabilité. Broadwell, malgré 70% de gains par rapport à Skylake ne suffira pas à changer l'équation ! On note quand même - pour la forme plus de 20% d'avance pour Skylake par rapport à Haswell en DDR3-2133, même si la DDR4, graphiquement, ne sert pas à grand-chose. En résumé Si l'on ne sait pas grand-chose d'éventuels changements architecturaux réalisés au niveau de la génération graphique 9 embarquée par Skylake, leur impact pratique dans les jeux reste limité. L'addition des unités supplémentaires (20% depuis Broadwell sur GT2), de la DDR4 et de deux générations apporte un avantage graphique par rapport à Haswell qui varie entre 1 et 11%, ce qui ne changera pas la donne. L'avantage est plus net lorsque l'on compare à mémoire égale, ce qui nous montre qu'ici, c'est bien les unités en plus et les changements d'architectures qui jouent, et non la DDR4 qui, pour l'IGP dans les jeux, n'apporte pas de gains. Les APU AMD, bien que de plus en plus talonnées arrivent à rester devant, seul Broadwell met à mal ces derniers, via l'utilisation de 128 Mo de mémoire embarquée et du double d'unités graphiques. Si Intel souhaite à l'avenir venir marcher sur les plates-bandes des APU dans les jeux, la marque dispose en tous les cas de la solution. Le passage à GT3, (ou même GT3e) sur les modèles K est une piste pour l'avenir, pourquoi pas pour Kaby Lake. En pratique Intel se retrouve dans la même situation qu'AMD avec ses APU. Trouver le curseur exact de performances graphiques à apporter sur desktop est difficile, tant cela est un compromis à mettre en rapport avec la consommation, la taille du die, et le fait que, dans le cas d'Intel, ces puces « K » soient en général plébiscités par les joueurs. Des joueurs qui y ajouteront une carte graphique dédiée, et n'auront que faire d'une solution plus performante comme celle retenue pour Broadwell, un autre placement de curseur qui bien que largement au-dessus de ce que propose Skylake, reste dans l'absolu en dessous du niveau de cartes graphiques vendues aux alentours des 80 euros. Page 10 - HD Graphics 530 en pratique : OpenCL, QuickSync Si la question du jeu reste toujours épineuse, qu'en est-il de l'OpenCL ? C'est ce que nous avons voulu vérifier dans plusieurs tests. LuxMark 2.0 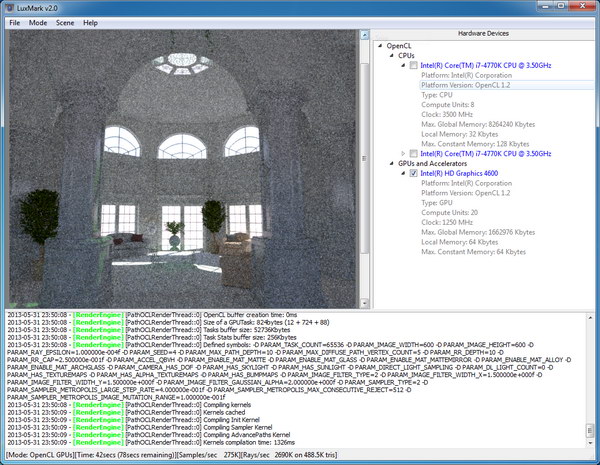 Nous utilisons pour ce test la version 2.0 de LuxMark, un benchmark utilisant le moteur de rendu du logiciel 3D Open Source LuxRender. Une version 3.0 est disponible depuis quelques temps mais le support des pilotes particulièrement chez Intel - reste loin d'être parfait. Ainsi, seul la scène la plus petite tourne sur les pilotes Intel, les deux scènes les plus importantes continuent encore aujourd'hui de planter le logiciel qui fonctionne sans problème sur les autres plateformes. La question des pilotes OpenCL inclus reste un point sur lequel Intel doit travailler, même si l'on saluera le progrès. Le mois dernier, les pilotes Intel ne faisaient même pas fonctionner la première scène de LuxMark 3.0 Nous regardons les performances pour rappel dans trois modes, OpenCL CPU, OpenCL GPU et OpenCL CPU+GPU : [ OpenCL CPU ] [ OpenCL GPU ] [ OpenCL CPU+GPU ] Plusieurs enseignements à tirer de ces graphiques. Tout d'abord on doit noter que Skylake ne change pas drastiquement la donne par rapport à Haswell en mode CPU. En DDR3 les plateformes ont des performances similaires, on se réjouira par contre de voir la DDR4-2133 être au niveau - enfin de la DDR3-2133. Lorsque l'on passe en mode GPU cependant, les écarts sont nets, +59.6% de performances en DDR3-2133 pour Skylake par rapport à Haswell. La DDR4 qui apportait un plus côté CPU freine ici les performances, la DDR3-2133 est 5.7% plus rapide que la DDR4-2133. De quoi permettre tout de même à Skylake de talonner une R7 250 GDDR5. Difficile de placer la raison derrière ce gain sans plus de détails pour l'instant. En pratique, Broadwell est très aidé par son cache L4 dans tous les modes, ce qui lui permet, malgré un TDP plus modeste de rester devant Skylake d'un cheveu en mode CPU+GPU. On notera en tout cas qu'Intel se rapproche furieusement, avec Skylake, des performances de la meilleure APU AMD, même si l'on se doit de rappeler que les problèmes de pilotes Intel mentionnés plus haut sous LuxMark 3.0 sont également rencontrés dans les dernières versions de LuxRender, limitant l'intérêt pratique des gains mesurés. On passera enfin rapidement sur les cartes d'entrée de gamme Nvidia, peu à l'aise ici. Sony Vegas Pro 13  Le logiciel de montage vidéo Vegas Pro 13 de Sony dispose de deux niveaux d'accélération. Un premier concerne les preview et le rendu qui peuvent être accélérés via OpenCL. Le second concerne l'encodage H.264 géré par le codec MainConcept qui peut au choix utiliser un mode CPU, OpenCL ou CUDA. En pratique cependant sur nos tests, l'impact de l'accélération de MainConcept sur notre échantillon de test est négligeable, le gros des gains vient de l'accélération du rendu. Nous effectuons le rendu/compression H.264 d'une scène de test en mode BluRay 1080p24 en modes CPU et accélérés (rendu et MainConcept). [ Mode CPU ] [ Mode OpenCL ] On notera en mode CPU que Broadwell n'est pas massivement aidé par son cache L4, compensant simplement son déficit de fréquence/TDP par rapport à Haswell. Le passage au mode de rendu OpenCL permet de gagner entre 15 et 20% selon les processeurs mais en pratique les trois plateformes Intel restent dans un mouchoir. Les APU d'AMD sont celles qui profitent le plus de l'activation de l'OpenCL, avec des gains de 25% mais elles restent significativement en retrait, limitées par leur processeur. En pratique la puissance graphique ne change pas grand-chose : on le note aux écarts infimes entre les différentes cartes graphiques discrètes que nous avons ajoutés dans notre comparatif. DxO OpticsPro 10.4.2  Nous utilisons la version 10 du logiciel photo de DxO qui dispose à la fois d'une accélération GPU pour l'affichage, mais surtout d'un mode OpenCL pour accélérer certaines parties des traitements. Nous appliquons le traitement DxO Standard qui inclut diverses corrections y compris des aberrations optiques de l'objectif. Nous notons les résultats en mode CPU et OpenCL : [ Mode CPU ] [ Mode OpenCL ] En mode processeur, Skylake est un peu plus rapide qu'Haswell, de l'ordre de 4% lorsque l'on compare en DDR3-2133. L'écart avec les APU AMD est large. En activant l'OpenCL, les gains sont très variables. Le temps de traitement est réduit de plus d'un tiers chez AMD, ce qui sauve les performances des APU. Sur Haswell le gain est infinitésimal, alors que sur Broadwell, le temps de compression baisse de 25%, probablement bien aidé par les unités supplémentaire et surtout le cache L4. Skylake profite un peu plus qu'Haswell, réduisant autour de 6% son temps de traitement. Au final, et c'est suffisamment rare pour être signalé, ce sont les GPU d'entrée de gamme qui apportent ici le plus de gains, particulièrement ceux d'AMD même si la GTX 750 rattrape la donne pour Nvidia par rapport aux modèles d'en dessous. La GT 740 était ici systématiquement plus lente que la GT 730 sans que l'on ne s'explique pourquoi. QuickSync Nous avons voulu regarder ce que proposait l'accélération QuickSync sur les différentes plateformes Intel. Pour rappel, nous avions noté à l'occasion de notre test des plateformes Braswell un gain de qualité notable au niveau de cet encodage H.264 accéléré. Nous avons pour cela utilisé le logiciel MediaEspresso de Cyberlink, nos tests sont réalisés dans le mode « Best Quality » du logiciel. Il est à noter que si théoriquement Skylake apporte l'accélération de l'encodage H.265/HEVC, cela n'est pas géré par les versions actuellement disponibles des logiciels comme MediaEspresso et Handbrake.  Cliquez sur l'image pour ouvrir le comparateur ! Quel changement ! Si les différences entre Haswell et Broadwell sous QuickSync sont minimes, le passage à Skylake fait une vraie différence. Pour une fois, la luminosité de l'encodage est conforme à la source, ce qui est tout de même un plus. La netteté est également améliorée particulièrement sur les visages et sur les textures de peau zébrées dont les motifs apparaissent clairement plus nets. A l'image de ce que l'on avait vu avec Braswell, Intel a progressé de manière importante en qualité sur son encodage H.264 accéléré et, si l'on reste loin de la source, le compromis est bien moindre qu'il n'eut été sur les générations précédentes ! Espérons que l'encodage H.265, lorsqu'il arrivera, sera du même niveau Page 11 - HD Graphics 530 en pratique : H.265, Consommation Nous avons également voulu vérifier l'accélération H.265 annoncée comme une des nouveautés gérées par Intel pour Skylake. Il faut dire que le sujet est un peu nébuleux, nous avions vu par exemple Intel annoncer précédemment dans ses pilotes l'ajout d'une accélération partielle du décodage du H.265 dans ses pilotes pour Haswell et Broadwell, tandis que les constructeurs de cartes graphiques parlent parfois eux aussi d'accélération partielle. Lecture H.265 sous MPC-HC Pour vérifier tout cela, nous avons utilisé une scène de test H.265/HEVC 4K avec un débit de 17 Mb/s (Elecard 4K video about Tomsk, part 3). Nous utilisons le lecteur vidéo MPC-HC en version 1.7.9 qui inclut les filtres LAVFilters basés sur l'excellent ffmpeg. Ces derniers permettent d'activer le décodage matériel H.265 en 4K dans leurs options (ces choix sont désactivés par défaut), via le protocole DXVA2 sous Windows.  Nous avons donc comparé le résultat obtenu en mode CPU et « accéléré » sur toutes les plateformes, en notant d'un côté le taux d'utilisation CPU total de la plateforme, et de l'autre la consommation relevée à la prise, le tout durant la lecture. [ % CPU ] [ Consommation ] Soyons très clairs, il n'y a en pratique qu'une seule plateforme qui gère pleinement l'accélération de la lecture H.265 4K : c'est Skylake. Le résultat est net avec une consommation qui chute de 38% et un taux d'utilisation processeur bien moindre. Ce n'est cependant pas la seule plateforme à « prétendre » gérer le H.265 par DXVA. Parlons de suite du cas de la GTX 750 qui se déclare comme capable de décoder le H.265 via son pilote (ce n'est pas le cas des deux autres). En pratique la lecture saccade et est inutilisable. Quid des Haswell/Broadwell ? Eux aussi se déclarent capable via leur pilote d'une accélération DXVA, mais l'on se demande ce qui est accéléré. Dans les deux cas, nous avons noté une augmentation de 10 à 15 watts de la consommation de la plateforme, et une consommation processeur plutôt en hausse également. S'il y a un support, il est très partiel, et complètement inutile sur notre scène de test. Il est relativement dommage qu'Intel ait activé ces accélérations déficientes pour les plateformes plus anciennes dans ses pilotes, car sauf bug manifeste, cela dessert le constructeur plutôt qu'autre chose, tout en dénigrant ce qu'apporte une vraie accélération matérielle correctement gérée comme cela est le cas sur Skylake ! MAJ : Notez que nous n'avons pas réussi à activer la lecture DXVA avec Skylake avec des vidéos encodées avec le profil "main 10" utilisant 10bit par composante. Nous attendons confirmation de la part d'Intel pour savoir s'il s'agit d'une limitation matérielle ou plus simplement d'un problème logiciel. Consommation graphique Nous avons mesuré la consommation de nos multiples plateformes dans six scénarios : - Au repos - En lecture d'un Blu-Ray 1080p H.264 sous MPC-HC (toutes les accélérations matérielles sont activées) - Sous F1 2014 en 1080p intermédiaire - Sous LuxMark en mode CPU - Sous LuxMark en mode GPU - Sous LuxMark en mode CPU+GPU Nous utilisons un bloc d'alimentation Seasonic 660SP, conforme au standard de rendement 80Plus Platinum, les mesures sont celles de la plateforme totale, à la prise 230V. Les mesures sont effectuées avec le plus petit niveau de mémoire testé, DDR3-1600 et DDR4-2133 respectivement en fonction des plateformes. On notera que globalement, la consommation de Skylake est en retrait par rapport à Haswell, au dela des variations de TDP annoncés. A l'inverse c'est le Core i5 Broadwell qui consomme le plus entre les trois plateformes Intel, un léger comble étant donné que son TDP est annoncé à 65W uniquement. L'écart est marqué dans les charges CPU/GPU cumulées ou, il faut le dire, il est très performant de par son cache L4 (voir nos benchs précédents). Comparativement à la concurrence, c'est de l'A8-7600 65W que Skylake, dans nos tests graphiques, se rapproche le plus d'un point de vue profil de consommation. On notera que les cartes graphiques AMD ajoutent un surcout notable de consommation lors de la lecture H.264 accélérée, quelque chose que l'on retrouve aussi de manière moins prononcée sur les APU. Les cartes Nvidia et les processeurs Intel n'ont pas ce problème. Performances par watts Nous avons enfin croisé nos mesures de performances et de consommation des plateformes sous LuxMark afin de calculer le rapport performances/watts des différentes solutions. Nous utilisons les scores en DDR3-1600/DDR4-2133. Voici les résultats que nous avons obtenus : Sur les scores processeurs purs, on note qu'entre les trois architectures Intel, c'est Broadwell qui s'en tire le mieux ici, notamment grâce à son cache L4 qui améliore les performances sous LuxMark. En mode GPU et CPU+GPU cumulés, Skylake prend par contre le large grâce aux excellents scores qu'il obtient ici, des scores plus élevés que le reste de la moyenne des scores obtenus. On s'approche du très bon rapport obtenu par la R7 360 effectivement. Si dans l'absolu le rapport performances/watts des APU en mode GPU sont corrects, le 7870K faisant jeu égal avec Haswell, en mode CPU on reste très, très loin d'Intel. Afin de donner un contrepoint au cas particulier de LuxMark sous Skylake, nous avons également effectué un rapport performances/watts sous F1 2014 : Ici les scores sont un peu plus dans la logique de ce que l'on a pu voir dans la globalité. Skylake progressant de 10% par rapport à Haswell tandis que Broadwell fait 5% de mieux sur ce terrain. Les GPU les plus haut de gamme sont les plus efficaces ici, et les solutions Nvidia dont les performances OpenCL sont plutôt piètres se retrouvent ici bien plus à leur avantage, dominant le classement. Page 12 - Protocole CPU, Consommation et efficacité énergétique CPU : Overclocking en pratique  Pour ce test nous reprenons le protocole introduit en août 2014 à l'occasion de la sortie de Haswell-E. Il n'y a pas vraiment eu de changements notables d'un point de vue applicatif depuis, si ce n'est de nouvelles versions de x265 qui apportent un surplus de gain important sur de nombreux processeurs, et encore plus sur les architectures les plus récentes (+31% sur Sandy Bridge contre +56-58% sur Haswell/Broadwell/Skylake par exemple). Côté jeu on attend surtout avec Windows 10 que les développeurs tirent pleinement partie des optimisations offertes par Direct3D 12 côté multithreading, mais il faudra encore attendre quelques mois pour voir les premiers résultats. A l'instar des Haswell, les Skylake sont ici mesurés en DDR4-2133 13-13-13, les processeurs en DDR3 étant en DDR3-1600 9-9-9. Consommation et efficacité énergétiqueOn commence par nos mesures de consommation et d'efficacités faites sous Fritz, vous pouvez vous reporter à cette page pour plus de détails sur ce test. Côté performance on note de suite un léger recul des performances pour les Skylake par rapport aux Haswell sur ce test. [ 220V (W) ] [ ATX12V (W) ] La consommation globale à la prise est en légère baisse sur l'i5-6600K par rapport à l'i5-4670K avec 5 à 4w de moins en charge et 2w de moins au repos. Sur l'i7-6700K la consommation est encore inférieure de 4 watts au repos et tombe à 38w, alors que pour rappel nous disposons dans la configuration d'une GTX 780 Ti qui consomme environ 13w au repos. L'i7-4770K reste 2w plus économe en charge sur 1 cur et 1w devant sur 4 curs, mais par contre le 6700K creuse l'écart par rapport au 4790K avec 7w de mieux sur 1 curs et 21w sur 4, son Turbo moins elevé aidant. [ Efficacité (Delta 220V) ] [ ] Au final en termes d'efficacité les résultats sont assez variables selon que l'on regarde le delta à la prise entre repos et charge ou la consommation absolue sur l'ATX12V. Dans le premier cas en charge légère les Skylake sont en net recul et à peu près équivalents en charge maximale, dans le second cas l'i5 est équivalent à son prédécesseur alors que l'i7 fait mieux sur les deux plans. Sachant que les conditions d'alimentation du processeur changent il est difficile de trancher, mais toujours est-il que le 14nm n'apporte pas dans ces déclinaisons LGA "K" de gain important que ce soit en consommation ou en efficacité énergétique. Page 13 - CPU Rendu 3D : Mental Ray et V-Ray 3d studio max 2015 - Mental Ray 3.12  Notre première mesure de performance s'effectue sous 3d Studio Max 2015 en utilisant le moteur de rendu Mental Ray sur une scène d'Evermotion. Le rendu est effectué en 480*300 afin de conserver un temps de test raisonnable, ni trop faible pour ne pas permettre à des mécanismes de Turbo très temporaires d'avoir un impact important, ni trop élevé pour la durée du protocole. Par rapport à ses prédécesseurs i5-4670K et i5-2500K, l'i5-6600K offre des gains de 7 et 47%. L'i7-6700K est pour sa part 7,8% devant l'i7-4790K, et 55% plus rapide qu'un i7-2600K. Intel parvient donc à encore améliorer les performances par rapport à Haswell qui avait apporté un gap important pour ce logiciel, si bien que l'i7-6700K est au même niveau que l'i7-5820K. Ce dernier dispose par contre d'une marge plus importante dans le cadre de l'overclocking. 3d studio max 2015 - V-Ray 3.0 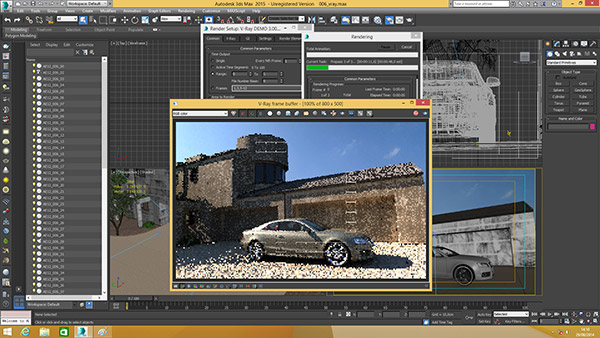 Toujours sous 3d Studio Max 2015, nous changeons cette fois de moteur de rendu pour le moteur tiers le plus populaire, V-Ray 3. On utilise une autre version de la même scène préparée par Evermotion pour ce moteur, le rendu étant cette fois effectué en 800*500. V-Ray est en effet nettement plus rapide pour rendre la scène, mais il ne s'agit pas de comparer les moteurs entre eux puisqu'il faudrait également observer de manière très attentive la qualité des fichiers finaux. Sous V-Ray les gains sont du même ordre, avec en i5 47% de mieux face à Sandy Bridge et 10% de mieux face à Haswell, contre 58% et 9% de plus en i7. Cette fois par contre l'i7-5820K a un peu d'avance sur l'i7-6700K. Page 14 - CPU Compilation : Visual Studio et MinGW-w64/GCC Visual Studio 2013  Nous compilons le logiciel d'animation 3D Open Source Blender sous Visual Studio 2013. Nous utilisons le code source de la dernière version stable au moment de la création de notre protocole, à savoir la version 2.71. Le projet est compilé avec les dépendances par défaut. Visual Studio 2013 est capable de compiler des modules non dépendants en parallèle. Les gains sont cette fois plus réduit avec 3,8% de mieux face à Haswell et 30,6% face à Sandy Bridge sur i5, mais ils sont plus élevés sur i7 avec respectivement 19 et 34%. L'i7-6700K est cette fois plus rapide que l'i7-5820K malgré ses curs en moins. MinGW-w64 - GCC 4.7.1  Nous utilisons une fois de plus le même code source de Blender 2.71, cette fois ci compilé sous MinGW-w64 / GCC 4.7.1. Les dépendances sont identiques à celles utilisées pour Visual Studio. Nous forçons la compilation multithread via la commande make. Un grand merci à Guillaume pour l'élaboration de ces deux tests ! Sous MinGW on gagne 36% de performance en passant d'un i5-2500K à un i5-6600K, un gain qui passe à 12% si on vient d'un i5-4670K. Sur les i7 les gains sont plus importants avec 46,2% et 10%, mais il ne faut pas oublier qu'en i7 Sandy Bridge souffre d'un déficit de fréquence par défaut assez important face aux 4790K et 6700K. Ce dernier est cette fois légèrement derrière l'i7-5820K. Page 15 - CPU Compression : WinRAR et 7-Zip WinRAR 5.10  Environ 7,5 Go de fichiers issus d'une version de Arma II avec ses extensions sont compressés à l'aide de WinRAR. Nous utilisons le format de compression RAR5 en mode Ultra. Introduit avec les dernières versions du logiciel, RAR5 permet entre autre de mieux tirer parti du multithreading. Avec WinRAR l'i5-6600K est 9% plus rapide que l'i5-2500K et 8% plus rapide que l'i5-4670K. Grâce au différentiel de fréquence l'i7-6700K pousse l'avantage à 17% face à l'i7-2600K alors qu'il est de 4% par rapport à l'i7-4790K. Cette fois l'i7-5820K est nettement plus rapide que l'i7-6700K. 7-Zip 9.20  7-Zip est le second logiciel de compression utilisé. Nous utilisons cette fois le mode LZMA2 en compression Ultra, toujours sur une version d'Arma II mais dépourvu cette fois des extensions (3.5 Go) afin de limiter le temps de test. WinRAR est donc plus rapide mais là encore il ne s'agit pas de comparer les logiciels entre eux, ce qui nécessiterait de comparer les tailles des archives obtenues. Sous 7-zip l'i5-6600K n'est que 1,5% plus véloce que son prédécesseur en Haswell contre 10% de mieux par rapport à Sandy Bridge. L'i7-6700K n'est que 2% plus rapide que l'i7-4790K et l'écart grimpe à 14% face à l'i7-2600K. De nouveau l'i7-5820K est hors d'atteinte. Page 16 - CPU Encodage : x264 et x265 x264 v2453  Notre premier test d'encodage vidéo est fait sous x264, plus précisément une build compilée sous GCC 4.9.1 par Komisar, avec la compression d'un extrait de Blu-ray d'une minute en 1080p avec un débit moyen de 23 Mbps. C'est ffmpeg qui fait office de serveur d'image, nous utilisons un encodage d'une passe en mode CRF 20 en profil slower, nous tenons à remercier Sagittaire au passage pour ces échanges sur le sujet. La ligne de commande exacte est --preset slower --tune grain --crf 20 --ssim --psnr. Skylake permet d'obtenir des gains de l'ordre de 9% sur i5 et i7 sous x264 par rapport aux Haswell, et de 44 et 55% face aux Sandy Bridge. Malgré ces gains l'i7-5820K est encore un peu trop rapide pour l'i7-6700K. x265 v1.2+507  On passe ensuite à x265 qui permet d'encoder des vidéos en H.265, un nouveau format de vidéo très performant puisqu'il promet à qualité équivalente au H.264 un débit divisé par deux mais avec en contrepartie une charge de décodage et d'encodage bien plus lourde. x265 est utilisé dans une version compilée avec GCC 4.9.1 par snayper. C'est de nouveau ffmpeg qui fait office de serveur d'image pour un encodage en CRF 16 cette fois, afin de profiter de l'efficacité accrue de x265 pour gagner en qualité, toujours en profil slower mais en l'adaptant quelque peu afin de réduire l'écart par rapport au profil slow tout en profitant des options psychovisuelles. La ligne de commande exacte est --crf 16 --preset slower --me hex --no-rect --no-amp --rd 4 --aq-mode 2 --aq-strength 0.5 --psy-rd 1.0 --psy-rdoq 0.1 --bframes 3 --min-keyint 1 --ipratio 1.1 --pbratio 1.1 --ssim psnr. Cette fois les gains offerts par Skylake sont de 8% environ face à Haswell en i5 comme en i7, ils passent à 41% et 47% si on compare à Sandy Bridge. Avec une build plus récente intégrant des optimisations assembleurs pour AVX2, l'écart se creuse d'ailleurs encore plus puisqu'en i5 les 2500K, 4670K et 6600K passent respectivement à 3.98, 6.22 et 6.81 fps. L'avantage de Skylake sur Haswell est donc alors de 9%, mais il passe 71% par rapport à Sandy Bridge ! Page 17 - CPU Traitement photo : Lightroom et DxO Lightroom 5.5  On passe maintenant au traitement des photos RAW par lot avec pour débuter Lightroom. Nous exportons en JPEG deux lots de 96 photos issues d'un 5D Mark II tout en leur appliquant divers effets, tels que des corrections colorimétriques, d'objectifs ou encore le traitement du bruit. Il faut noter que de base, Lightroom ne tire guère partie de plus de 3-4 curs, ce qui est ici contourné via l'export simultané de deux lots de photos qui permet de gagner un temps significatif. Sous Lightroom le passage d'un i5-2500K à un i5-6600K apporte un gain de 29%, face au 4670K le gain est de 13%. Sur un i7, le gain entre SNB et SKL est de 33% mais tombe à 7% entre SKL et HSW sur la base d'un 4790K. L'i7-5820K est hors d'atteinte pour l'i7-6700K. DxO Optics Pro 9.5  DxO Optics Pro est notre second logiciel de traitement photo. Ce sont cette fois 48 photos issues d'un 5D Mark II qui sont traitées avec notamment de la compensation d'exposition, d'éclairage, de couleurs, la réduction du bruit et les corrections optiques. Nous avons réduit le nombre de photos traitées afin de conserver un temps de test raisonnable, mais là encore il ne s'agit pas de comparer DxO à Lightroom sur la base de la rapidité puisque les effets ne sont pas les mêmes et les fichiers finaux ne sont pas équivalents. A noter que par défaut DxO traite 2 images en parallèle (chaque traitement étant lui-même multithreadé). Afin de tirer pleinement parti des processeurs à plus de curs nous réglons le logiciel pour utiliser 3 images sur les processeurs 6 curs/thread, 4 sur les 8 curs/thread, etc. Le comportement sous DxO est assez proche avec sur i5 des gains de 31% face à Sandy Bridge et 10% par rapport à Haswell. Sur i7 on est à 38 et 7%. Page 18 - CPU IA d'échecs : Stockfish et Fritz Stockfish 5  Enfin nous terminons ce tour d'horizon applicatif par un type d'application assez particulier, à savoir des algorithmes d'intelligence artificielle destiné aux échecs. On commence par Stockfish 5, un moteur open source qui vient de détrôner Houdini qui était considéré jusqu'alors comme le plus efficace. Stockfish est compilé avec GCC 4.8 et dispose de trois versions, une classique, une SSE4 permettant un gain de 3% environ sur processeurs Intel et AMD et une version utilisant les instructions BMI des Haswell qui permet de gagner encore 2%. La version la plus rapide est utilisée. Nous laissons tourner le moteur jusqu'au 31è tour en début de partie et notons la vitesse exprimée en Kilonoeuds par secondes. Stockfish permet à l'i5-6600K d'afficher un gain de 23% face à l'i5-2500K et de seulement 5% par rapport à l'i5-4670K. Sur i7 le gain est de 34% par rapport au 2600K (merci la fréquence) mais tombe à 2% par rapport au 4790K. Houdini 4 Pro  L'autre moteur d'échec utilisé est Houdini dans sa version 4. Il dispose lui aussi de deux exécutables, l'un étant plus rapide sur processeur AMD et l'autre plus rapide sur processeur Intel. La version la plus rapide est utilisée. Nous laissons tourner le moteur jusqu'au 27è tour en début de partie et notons la vitesse exprimée en Kilonoeuds par secondes. Les Skylake ne sont pas plus à l'aise sous Houdini avec des gains de 5 et 3% face aux i5 et i7 Haswell. Le gain est autrement plus notable face à Sandy Bridge avec 24 et 50% de performances en plus. Page 19 - CPU Jeux 3D : Crysis 3 et Arma III Crysis 3  Crysis 3 inaugure la partie jeux 3D de ce comparatif. Nous utilisons une sauvegarde sur une zone particulièrement chargée du jeu dans laquelle nous avançons pendant 20s afin d'avoir un framerate moyen. Les tests sont effectués en 1920*1080 Very High, sans anti-aliasing. Sur des parties lourdes avec beaucoup de végétation comme la scène de test utilisée, Crysis 3 arrive à assez bien exploiter plus de 4 curs. L'i5-6600K est 44% plus rapide que l'i5-2500K, mais le gain n'est que de 3% par rapport à l'i5-4670K. Côté i7, le 6700K affiche 52% de plus qu'un 2600K et 8% de mieux qu'un 4790K. Il faut noter que la version officielle du jeu refuse de se lancer sur Skylake, le DRM renvoyant une erreur "8016" ! Arma III  Pour Arma III nous chargeons une sauvegarde lors d'un entrainement en hélicoptère dans laquelle nous survolons pendant 20s l'ile de Stratis. Les tests sont effectués en 1920*1080 Ultra, sans anti-aliasing. Au contraire Arma III n'est que peu dépendant du nombre de curs. Cette fois l'i5-6600K est 29% plus rapide que l'i5-2500K et 14% au-dessus de l'i5-4670K. Côté i7 Skylake fait respectivement 39 et 9% de mieux que ses prédécesseurs en SNB et HSW. Page 20 - CPU Jeux 3D : X-Plane 10 et F1 2013 X-Plane 10  X-Plane 10 est autant un jeu qu'un logiciel de simulation de vol. Nous utilisons 20s du benchmark intégré qui est un replay d'une approche d'un survol en basse altitude d'une ville et d'un aéroport avec les options fps 3 qui correspondent à un niveau de détail très élevé, en 1920*1080 sans anti-aliasing. Il faut noter que X-Plane n'aime pas du tout l'Hyperthreading sauf sur Sandy Bridge et Skylake, avec des performances en hausse de 15 à 20% lorsque celui-ci est désactivé et assez variables entre les benchmarks, probablement du fait d'une répartition peu optimale des threads sur les curs logiques. Vu cet écart important nous reportons ici les valeurs avec Hyperthreading désactivé sur les autres processeurs Intel. Sur i5 Skylake n'apporte pas de gain notable par rapport à Haswell, il est par contre de 40% par rapport à Sandy Bridge. Sur i7 cet écart passe même à 51%, avec cette fois un gain de 6% par rapport à Haswell, Skylake profitant ici (lui !) d'un léger gain lié à l'Hyperthreading. F1 2013  F1 2013 est notre quatrième jeu, nous utilisons le benchmark intégré qui est modifié afin d'avoir un départ du GP d'Abu Dhabi sous un temps pluvieux. Nous mesurons le framerate moyen durant les 20 premières secondes du départ, en 1920*1080 Ultra sans anti-aliasing. F1 2013 perd un peu en performances du fait de l'Hyperthreading, mais l'écart étant assez faible nous reportons les valeurs avec HT actif cette fois. Le jeu tire légèrement parti de la présence de plus de 4 curs. L'i5-6600K permet d'obtenir des gains respectifs de 15 et 9% face aux Core i5-2500K et 4670K. Par rapport à l'i7-2600K, l'i7-6700K est 25% plus rapide mais face au 4790K on est à +9%. Page 21 - CPU Jeux 3D : Watch Dogs et Total War : Rome 2 Watch Dogs  Le framerate de Watch Dogs est pour sa part mesuré lors d'une course de 20s dans une partie assez chargée du jeu. Nous avons trouvé des scènes avec des framerate 10 à 20% inférieurs mais le système de sauvegarde automatique nous a empêché de les utiliser de manière très reproductible, tout comme l'environnement changeant. Les performances sont mesurées en 1920*1080 avec un niveau de qualité générale à Ultra mais sans anti-aliasing. Watch Dogs permet d'exploiter plus de 4 curs. L'i5-6600K est 14% plus rapide que l'i5-2500K, un écart réduit de moitié face au 4670K. Côté i7 l'avantage est de 25% face au 2600K Sandy Bridge et 9% par rapport au 4790K. Total War : Rome II  Pour Total War : Rome II nous mesurons simplement le framerate lors de la première scène de jeu du prologue, en 1920*1080 Extreme mais en désactivant l'AA et le SSAO. Cette fois le fait d'aller au-delà de 4 curs n'est pas vraiment utile. L'i5-6600K est 32% plus rapide que l'i5-2500K, et 19% devant l'i5-4670K. Côté i7 l'avantage se réduit à 12% par rapport au 4790K mais monte à 40% par rapport au 2600K du fait de l'écart de fréquence. Page 22 - CPU Jeux 3D : Company of Heroes 2 et Anno 2070 Company of Heroes 2  Pour Company of Heroes 2 nous utilisons les 20 dernières secondes du benchmark intégré pour obtenir un framerate moyen en 1920*1080 et qualité maximale exception faite de l'anti-aliasing. CoH 2 ne tire pas vraiment partie de plus de 4 curs. Comme Total War le gain est notable en passant de Skylake à Haswell avec 20% de mieux sur i5 et 12% de mieux sur i7, par rapport à Sandy Bridge les gains montent à 23 et 29%. Anno 2070  Enfin pour Anno 2070 nous chargeons une sauvegarde d'une cité de 220 000 habitants que nous visualisons pendant 20s depuis une vue éloignée, le tout en 1920*1080 avec réglages très élevés et toujours sans anti-aliasing. Dernier jeu de notre suite de test, Anno 2070 n'aime pas l'Hyperthreading dès lors qu'il est présent sur un processeur qui dispose de plus de 4 curs. Le fait de le désactiver permet en effet de gagner 12% de performances environ sur 6 curs, et carrément 30% avec un 8 curs, signe d'un positionnement des thread probablement forcé par le jeu et assez mal fait. Du fait de cet écart important sur les processeurs 6 et 8 curs l'Hyperthreading est désactivé pour ce test. Comme beaucoup des autres jeux la présence de plus de 4 curs n'influence pas beaucoup les perfs d'Anno 2070. L'i5-6600K est 22% plus rapide que l'i5-2500K et fait 11% de mieux que l'i5-4670K. Côté i7, le 6700K affiche un gain de 36% face au 2600K et 8% par rapport au 4790K. Page 23 - Indices de performance CPU Indices de performancePassons maintenant aux moyennes. Bien que les résultats de chaque application aient tous un intérêt, nous avons calculé des indices de performances en nous basant sur l'ensemble de résultats et en donnant le même poids à chacun des tests. Nous présentons deux moyennes, l'une applicative intègre tous les tests en dehors des jeux 3D et l'autre est spécifique aux jeux 3D qui sont généralement moins multithreadés. En applicatif un i5-6600K permet de gagner 30,4% de performance face à un i5-2500K qui a 4 ans et demi, ce qui n'est pas négligeable. Le gain se réduit si on compare à des CPU plus récents bien entendu : 18,7% face au 3570K, 7,9% face au 4670K (alors qu'il existe un 4690K) et 4,1% par rapport au 5675C. Si on compare l'i7-6700K face à un i7-4770K lancé il y a deux ans le gain est de 19.2%, mais dans l'intervalle Intel a sorti le 4790K et là le gain n'est plus que de 6.5%, le déficit de fréquence (4200 vs 4000 MHz en fréquence Turbo sur 4 curs) n'aidant pas. La comparaison avec un i7-2600K cadencé moins haut est forcément plus avantageuse, le gain est alors de 42,2%. Pas si éloigné en tarif même si les cartes mères sont un peu plus chères, l'i7-5820K est en moyenne 7,1% devant l'i7-6700K. Pour les jeux, l'i7-5820K méritera par contre d'être overclocké pour se rapprocher de l'i7-6700K qui est 15.4% plus rapide. Par rapport aux 4770K et 4790K les gains sont de 22.8 et 9.6%, contre 30.6% de mieux face et 40% face à un i7-2600K. L'écart de fréquence étant moins important, le gain entre un i5-6600K et un i5-2500K est se réduit à 25,8%. On gagne 10% depuis un i5-4670K et 16.1% depuis un i5-3570K. A noter que l'i5-5675C reste le plus rapide des i5 dans les jeux du fait de son eDRAM qui fait office de cache L4 pour le CPU ! Page 24 - Conclusion ConclusionLors d'un sondage réalisé il y'a quelques mois, 42% d'entre vous attendaient un gain supérieur à 20% entre Haswell et Skylake pour changer de plate-forme. En pratique on en est loin puisque avec à peine 10% de mieux à fréquence égale, alors même que les fréquences réelles sont légèrement réduites côté Turbo. Bien que flexible puisque désormais possible autant par le bus que le coefficient multiplicateur, l'overclocking n'y change pas grand-chose puisque avec 4.5 GHz atteints sur nos deux échantillons, on ne note pas d'avancée significative en fréquence. Un critère qui sera à prendre en compte car si le gain est d'environ 23% entre Sandy Bridge et Skylake à fréquence égale, Sandy Bridge pouvait atteindre des fréquences supérieures en overclocking. L'autre déception, plus attendue celle-là, se situe au niveau de la DDR4. Seules les versions les plus rapides, DDR4-3000 et supérieures, permettent de lutter face à de la DDR3-2400 alors que ces kits sont à ce jour plus onéreux. L'arrivée du décodage H.265 est une bonne chose côté iGPU mais il est incomplet, ne gérant pas le format "Main10" qui devrait être utilisé largement à l'avenir. Il manque de toute façon la gestion de l'HDMI 2.0 et du HDCP 2.2 pour pleinement exploiter le futur contenu 4K avec DRM. Malgré l'augmentation du nombre d'EUs et le passage à la DDR4 les performances, bien qu'en légère hausse (10% au mieux) sont par contre largement insuffisantes pour autre chose que des jeux à la charge graphique allant de légère à moyenne en 1080p. Seule l'eDRAM permet à l'iGPU Intel de commencer à être intéressant en 3D, et elle n'est pas présente sur ces versions K. Bien entendu le tableau n'est pas complètement noir et il ne faut pas oublier que dans l'absolu les performances de ces i7-6700K et i5-6600K sont excellentes et sans vraie concurrence. Nous sommes avant tout déçus du peu de gains obtenus face à Haswell en 2 ans et Sandy Bridge en 4 ans. En réservant une partie de plus en plus importante du die à un iGPU qui n'est pas forcément convaincant, Intel se prive - et nous prive - probablement de gains d'IPC importants ou à défaut d'une augmentation du nombre de curs qui serait la bienvenue sur ce type de plate-forme : il faudra passer sur LGA-2011 v3 pour avoir 6 curs, l'i7-5820K n'étant d'ailleurs pas beaucoup plus cher qu'un i7-6700K. Une autre piste à terme pour Intel serait bien entendu d'utiliser de l'eDRAM sur ces versions, le gain pouvant être également notable côté CPU puisqu'elle fait office de cache L4. Il faut également saluer les avancées côté plate-forme, car même si la régulation de tension subit un retour en arrière puisqu'elle repasse en externe, la partie chipset est remise au goût du jour avec un Z170 qui dispose d'un lien deux fois plus rapide avec le processeur et de possibilités étendues côté entrées/sorties (plus de lignes PCIe et en Gen3, plus d'USB 3). Au final avec la plate-forme LGA 1151, Intel propose un bon produit mais sans surprise, qui conviendra à ceux qui disposent de machines pré Sandy Bridge. Pour ceux actuellement en Sandy Bridge, la question se pose encore, notamment en fonction de la fréquence atteinte via overclocking, alors que si vous êtes équipés en Haswell vous pouvez passer tranquillement votre chemin pour cette année. Copyright © 1997-2026 HardWare.fr. Tous droits réservés. |