| |
| |
| Kaveri : AMD A10-7850K et A10-7700K en test Processeurs Publié le Mardi 14 Janvier 2014 par Damien Triolet, Guillaume Louel et Marc Prieur URL: /articles/913-1/kaveri-amd-a10-7850k-a10-7700k-test.html Page 1 - APU 3è génération Annoncée à l'été 2006 lors du rachat d'ATI par AMD, la stratégie visant à associer puis fusionner CPU et GPU sur une même puce continue son petit bonhomme de chemin avec une nouvelle itération dénommée Kaveri. Lors du lancement des Llano en juin 2011, nous indiquions en titre que les APU étaient un pari pour le père des Athlon, Kaveri va-t-il enfin permettre à AMD de le gagner ?  APU 3è générationLes APU (Accelerated Processing Unit) AMD sont classés en deux gammes distinctes. En entrée de gamme tout d'abord, on retrouve des puces destinées aux machines d'entrées de gamme et/ou nécessitant des puces base consommation telles que les tablettes, avec Brazos qui est le premier APU AMD à avoir débarqué début 2011, suivi d'une seconde génération dénommée Kabini en 2013. Kaveri fait partie d'une seconde gamme d'APU destinée au cur du marché informatique, le milieu de gamme. Après Llano en 2011 suivi de Trinity en 2012 (et un Trinity "bis", Richland, en 2013), Kaveri fait office de 3è génération pour ce segment. Initialement prévu pour 2013, ce n'est donc qu'en ce début d'année 2014 qu'il débarque. Pour continuer son offensive APU, AMD l'a doté de pas moins de 2,41 milliards de transistors, soit une hausse de 85% par rapport à Trinity. Grâce à un procédé 28nm SHP de GlobalFoundries et l'utilisation de bibliothèques favorisant une densité plus importante de transistors, Kaveri occupe quasiment la même taille sur une galette de silicium avec 245mm², soit 1mm² de moins. Cet afflux de transistors permet à AMD d'intégrer de nombreux nouveautés au sein de Kaveri, avec par exemple : - Une évolution de l'architecture x86 CMT (Steamroller) - Un nouvel iGPU intégrant jusqu'à 8 Compute Units GCN - HSA, qui permet un espace d'adressage mémoire unique entre GPU et CPU - Des DSP TrueAudio - Un contrôleur PCIe Gen3 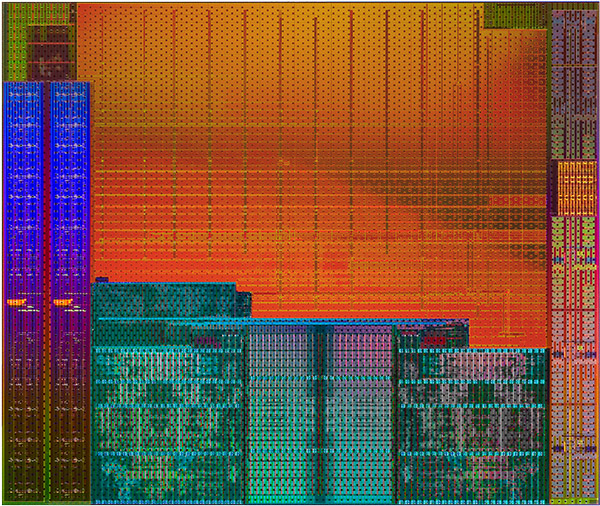 Sur la représentation du die d'AMD on peut voir que c'est le nouveau GPU, en orange à haut, qui occupe la plus grande partie de la puce. Les deux modules Steamroller et leurs caches L2 sont en bas, alors qu'on trouve à droite l'interface mémoire et à gauche l'interface PCIe. Le tout prend place au sein de l'architecture FM2+ déjà déployée depuis quelques mois. En effet, Kaveri n'est malheureusement pas compatible avec les cartes mères FM2, un changement au niveau des broches interdisant un tel montage.  A contrario, les cartes mères FM2+ sont capables d'accueillir les APU Kaveri FM2+ ainsi que les APU Trinity/Richland initialement destiné au FM2. On retrouve la segmentation habituelle de la plate-forme au niveau des chipsets :  Si ce n'est que l'A85X est renommé en A88X et que l'A75 se retrouve parfois nommé A78. Page 2 - Kaveri = Steamroller + GCN L'attrait principal de Kaveri vient des changements architecturaux apportés. Après Richland et Trinity, AMD propose ici des nouveautés un peu partout, aussi bien côté processeur que pour la partie graphique. Steamroller : Bulldozer V3 Tout comme pour Trinity et Richland, AMD continue d'utiliser un dérivé de l'architecture Bulldozer qui avait été introduite à l'occasion des processeurs AMD FX en octobre 2011. Elle a subi un certain nombre de changements, Trinity/Richland utilisant la seconde itération de cette architecture, baptisée Piledriver. Aujourd'hui, AMD propose une troisième itération baptisée Steamroller. Nous avions déjà eu l'occasion de vous parler de cette architecture à l'été 2012 (Kaveri était alors encore prévu pour 2013). Techniquement, AMD continue d'utiliser le concept de modules qui fait la particularité de ces architectures, même si Steamroller réalise quelques aménagements. Rappelons l'idée de base : AMD accole deux curs au sein d'un module et tente de mutualiser ce qui peut l'être. L'idée étant de réduire ainsi le nombre de transistors nécessaires pour obtenir des curs, ce qui réduit la place prise sur la puce (avec la possibilité de placer plus de modules) mais aussi potentiellement la consommation. En contrepartie, chaque choix de mutualisation peut avoir un impact sur les performances. Techniquement, AMD avait choisi jusqu'ici d'utiliser de mutualiser trois choses : - le « front-end » (la partie en amont du processeur qui décode les instructions avant de les envoyer aux unités d'exécutions) ainsi que le cache L1 d'instructions - l'unité de calcule sur les nombres flottants - le cache L2 Pour le reste, on retrouve des caches L1 de données séparés, ainsi que des unités d'exécution entières séparées. AMD annonçait ainsi qu'un module permet d'obtenir 80% des performances de deux curs complets. 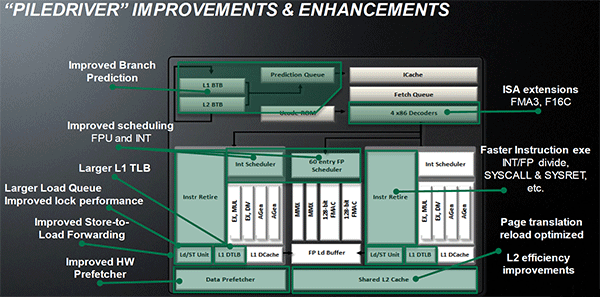 Si Piledriver avait été l'occasion de multiples petits changements, pour Steamroller AMD s'est intéressée plus particulièrement au front-end. Le premier changement évoqué par AMD concernait la taille du cache L1 d'instruction, qui passe de 64 à 96 Ko pour chaque module. L'autre changement important concerne un découplage dans le front end de la partie décodage d'instructions.  C'est un changement majeur puisque Steamroller dispose désormais de deux décodeurs séparés au lieu d'un, chaque décodeur pouvant accéder à ses propres unités entières, ou à l'unité d'exécution flottante partagée. Théoriquement, disposer de décodeurs séparés devrait améliorer les performances sur un thread, tout en améliorant assez significativement l'IPC. En pratique, on passe de quatre ops dispatchables par cycle (avec l'ancienne unité) à huit (quatre par « cur »). Cela se paye par contre du point de vue du nombre de transistors et de la consommation, un sujet sur lequel AMD ne communique pas précisément malheureusement. Que le constructeur le veuille ou non, découpler les décodeurs reste un retour en arrière par rapport aux ambitions initiales du concept des modules CMT. Il sera intéressant de voir en pratique si ce changement est pragmatique et s'il se concrétise par une amélioration notable des performances. AMD a effectué également un certain nombre de modifications annexes en augmentant de ci de là des buffers et autres files d'attentes. C'est le cas par exemple des files d'attentes de lecture/écriture mémoire qui passent de 44 et 24 ops à 48 et 32 respectivement. De la même manière, le Branch Target Buffer de niveau 2 (un buffer utilisé dans le mécanisme de prédiction de branchements pour déterminer les adresses mémoires) voit lui aussi sa taille doubler de 5 à 10 Ko. En pratique, nous avons pu observer quelques changements de comportement au niveau des caches entre Richland et Kaveri. Pour les tests suivants, nous avons cadencés les APU à 3.7 GHz en désactivant le Turbo, afin d'obtenir des résultats comparables. Ces scores sont relevés à l'aide du logiciel Aida64 : 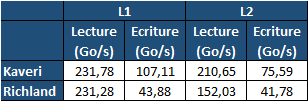 Côté L1, si l'on ne notera pas de changement en lecture, on note une amélioration très nette de la bande passante en écriture qui est plus que doublée. Du côté du cache L2, on note des gains des deux côtés avec +38% en lecture et +80% en écriture. Des changements potentiellement intéressants. Notez que la latence des caches n'évolue pas, on reste à 1.1 ns pour le L1, et environ 10ns pour le cache L2. GCN Kaveri est également l'occasion pour AMD de remettre à niveau la partie GPU de ses APU et l'on retrouve, à l'image de ce que nous avions vus pour Kabini l'année dernière, l'architecture GCN du constructeur. Depuis les Radeon 9700 Pro, AMD utilisait une architecture VLIW, qui a évolué progressivement pour atteindre un niveau de flexibilité très élevé sur les dernières générations. VLIW, ou Very Long Instruction Word, consiste à exécuter des instructions complexes, qui sont en réalité l'assemblage d'une série d'instructions plus simples. Avec GCN, AMD remplace le VLIW par des unités SIMD (Single Instruction Multiple Data) capables d'exeucter des instructions sur 16 éléments en simultanée.  Il s'agit ici de la dernière version en date de GCN, celle que l'on retrouve dans les GPU Hawaii et dont nous vous avions parlé dans cet article. AMD indique avoir consacré 47% de la surface de Kaveri au GPU, ce qui se traduit en pratique par jusque huit Compute Unit. On notera également un peu plus en amont dans le GPU que les Asynchronous Compute Engine sont au nombre de 8, le même nombre que sur les R9 290. Il s'agit de files d'attentes pour les tâches non graphiques, augmenter leur nombre permet en théorie de fluidifier leur utilisation. Au nombre de deux dans la première itération de GCN, on trouvait quatre unités ACE dans Kabini pour aujourd'hui en trouver huit dans Kaveri. On notera en parallèle qu'AMD indique avoir inclus de nouvelles versions de ses blocs UVD/VCE qui permettent respectivement de décoder et d'encoder des formats vidéos via des unités fixes. Au rang des nouveautés annoncées, on notera une meilleure résistance aux erreurs pour le décodage (particulièrement utile en cas de streaming) ainsi qu'une gestion des B-frames pour l'encodage H.264. Pour rappel, les B-frames sont des types d'images particulières dans un flux vidéo H.264 qui sont capables à la fois de faire référence à des images passées (le principe des P-frames) mais aussi des images à venir. Une nouveauté intéressante même si, comme nous nous en plaignons régulièrement, les logiciels d'encodage vidéo qui utilisent les blocs intégrés des processeurs sont souvent extrêmement limités dans leur capacité à exploiter les possibilités offertes par ces blocs. Pour plus de détails, nous vous renvoyons à cet article. TrueAudio Avec Windows Vista, Microsoft a en quelque sorte mis à la retraite tous les accélérateurs audio matériel en imposant l'utilisation d'une pile audio et d'un mixer purement logiciel fourni par Microsoft. Si une technologie comme OpenAL résiste, en pratique les effets sonores restent aujourd'hui une affaire logicielle. 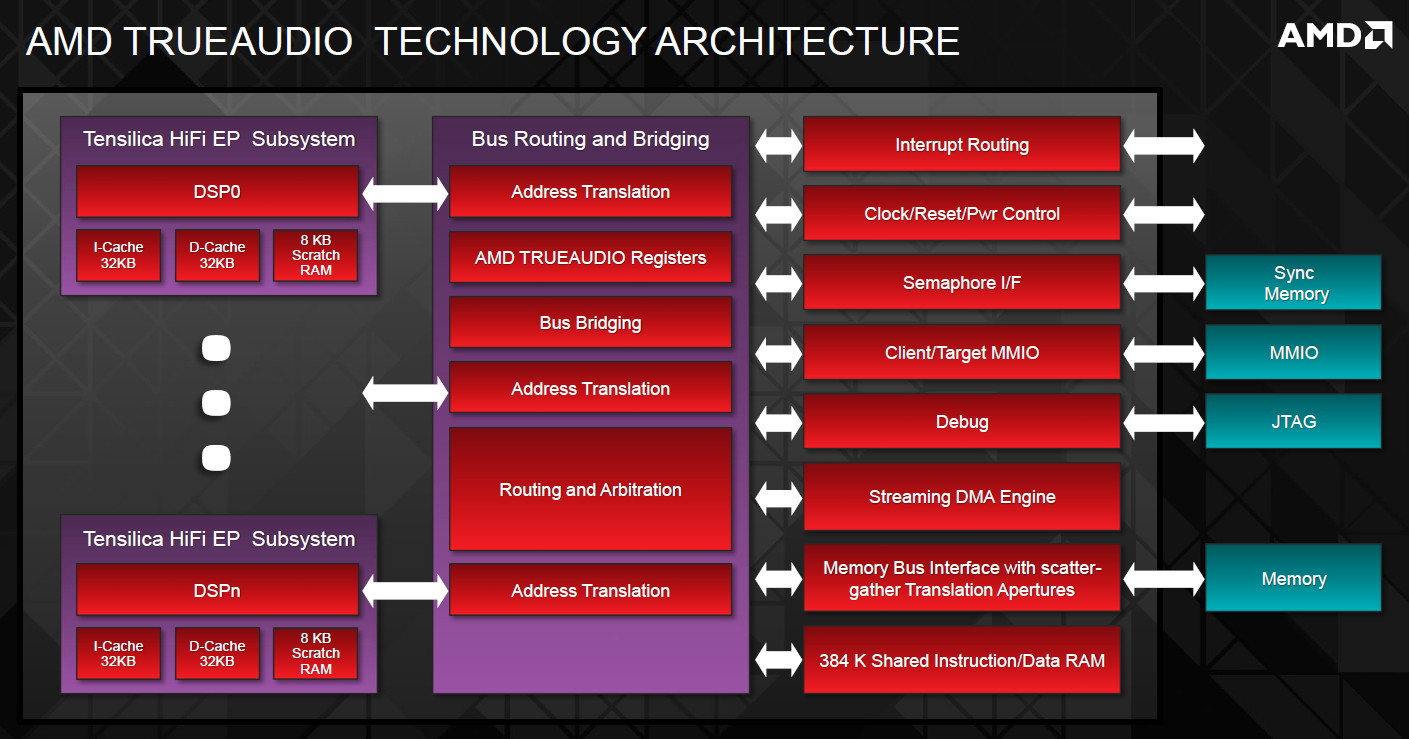 TrueAudio tente de changer la situation en proposant l'ajout de DSP directement dans ses GPU et APU utilisant des blocs HiFi EP de la société Tensilica .  Le nombre de blocs précis intégré dans Hawaii n'avait pas été précisé, et on n'en saura pas plus pour le nombre intégré dans les APU ce qui est fort dommage. En l'absence de plus d'informations, si vous souhaitez plus de détails sur le principe de TrueAudio, nous vous renvoyons vers cet article précédent. Si sur le principe l'intégration de cette technologie est toujours une bonne chose, tenter d'imposer un standard audio supplémentaire et non compatible avec ce que peut proposer Intel ou Nvidia ne sera pas forcément aisé pour le constructeur qui devra convaincre de l'intérêt de cette solution. On imagine qu'AMD pourra s'appuyer sur sa position sur le marché des consoles Next Gen, même si le constructeur se refuse là encore à préciser si oui ou non, TrueAudio est disponible sur les APU des Playstation 4 et des Xbox One. PCI Express 3.0 Un autre changement important concernant les APU Kaveri est le support du PCI Express 3.0. Les générations précédentes étaient en effet bridées en PCI Express 2.0 jusqu'ici. De manière précise, seules les 16 lignes dédiées à un ou deux ports PCI Express graphique sont de type PCI Express 3.0. Kaveri comme les APU précédentes intègrent 8 lignes supplémentaires, quatre d'entre elles permettent de relier l'APU au chipset et quatre lignes GPP (General Purpose Ports) sont également disponibles. Dans les deux cas, ces lignes restent de type PCI Express 2.0. Page 3 - HSA et Compute Cores La HSALa HSA, ou Heterogeneous System Architecture, a pour mission de rendre le calcul hétérogène plus efficace et plus simple à exploiter du point de vues des développeurs. Par calcul hétérogène, il faut comprendre ici l'utilisation combinée de différents types de processeur pour remplir une tâche donnée, par exemple des curs CPU et GPU. Pour rappel, la HSA est un standard ouvert qui découle d'une initiative d'AMD mais qui rassemble maintenant un large pan de l'industrie à travers la HSA Foundation. ARM, Imagination Technologies, Mediatek, Qualcomm, Samsung, Texas Instruments ont ainsi répondu à l'appel d'AMD pour contribuer à définir la HSA, contrairement à Intel et Nvidia qui ont préféré bouder l'initiative. Compte tenu de la diversité de ces acteurs, la HSA peut englober une large variété de curs CPU (x86, ARM, MIPS), GPU (Radeon GCN, Adreno, PowerVR ) ou encore de DSP. Les spécifications de la HSA font en sorte de permettre à tout ce petit monde, appelés "agents HSA" de pouvoir travailler ensemble à travers quelques points communs tant au niveau matériel que logiciel. La HSA n'est pas un langage mais plutôt une manière plus stricte d'implémenter le support d'un langage donné, par exemple OpenCL. Tous les agents HSA doivent respecter la même mécanique de gestion des files d'attente et de lancement des tâches ainsi que le même modèle mémoire. Deux variantes existent, Small Machine Model et Large Machine Model qui se distinguent principalement par le support ou non du 64-bit. Un APU tel que Kaveri supporte bien entendu le second.  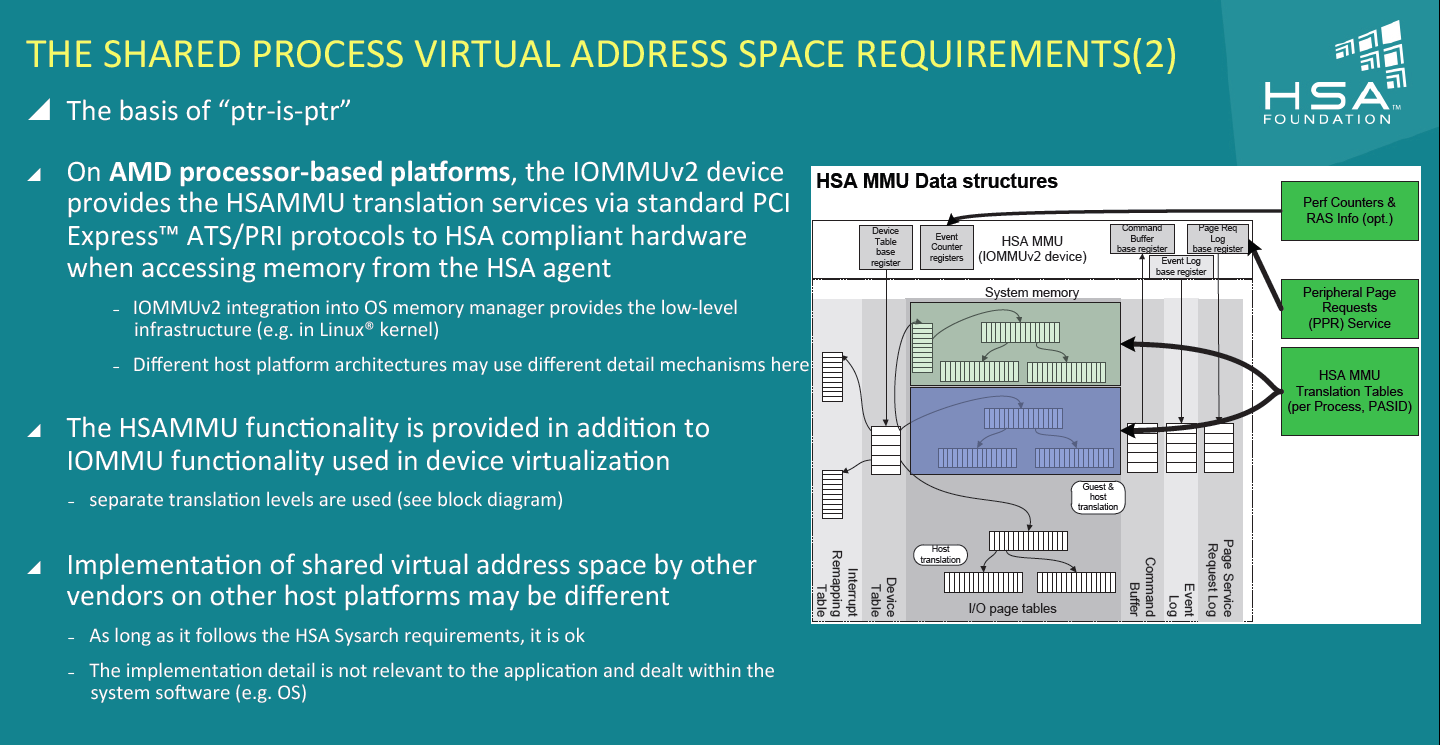  Le modèle mémoire est probablement le premier point essentiel de la HSA. Il impose le support d'une mémoire virtuelle unifiée qui permet aux différents agents de partager des données simplement, sans copies inutiles, coûteuses en termes de performances (et de consommation) et qui rendent le code moins naturel pour le développeur. Pour tous les agents, un pointeur donné fait référence à la même zone mémoire, à laquelle ils peuvent tous accéder. Cela implique la mise en place de mécaniques de préservation de la cohérence des caches entre les différents agents pour éviter tout problème de synchronisation.   Pouvoir exécuter efficacement tout type de tâche via l'agent HSA le plus approprié est le second point essentiel. Les agents HSA doivent pour cela être tous capables de lancer de nouvelles tâches et de supporter de multiples files d'attente. Il revient alors au développeur et/ou au compilateur de profiter au mieux de cette flexibilité.   La HSA définit également la manière dont les agents HSA peuvent interagir avec d'autres agents non-HSA, un horodatage commun à la plateforme et une manière d'exposer la topologie du système. La HSA par AMD et KaveriPour parler des différents points de la HSA, AMD utilise sa propre nomenclature, ce qui lui permet de préserver des marques pour des technologies qui reposent sur des standards ouverts. L'implémentation d'AMD de la mémoire virtuelle unifiée se nomme ainsi hUMA (Heterogeneous Unified Memory Architecture) alors que celle de la gestion des tâches se nomme hQ (Heterogeneous Queuing). 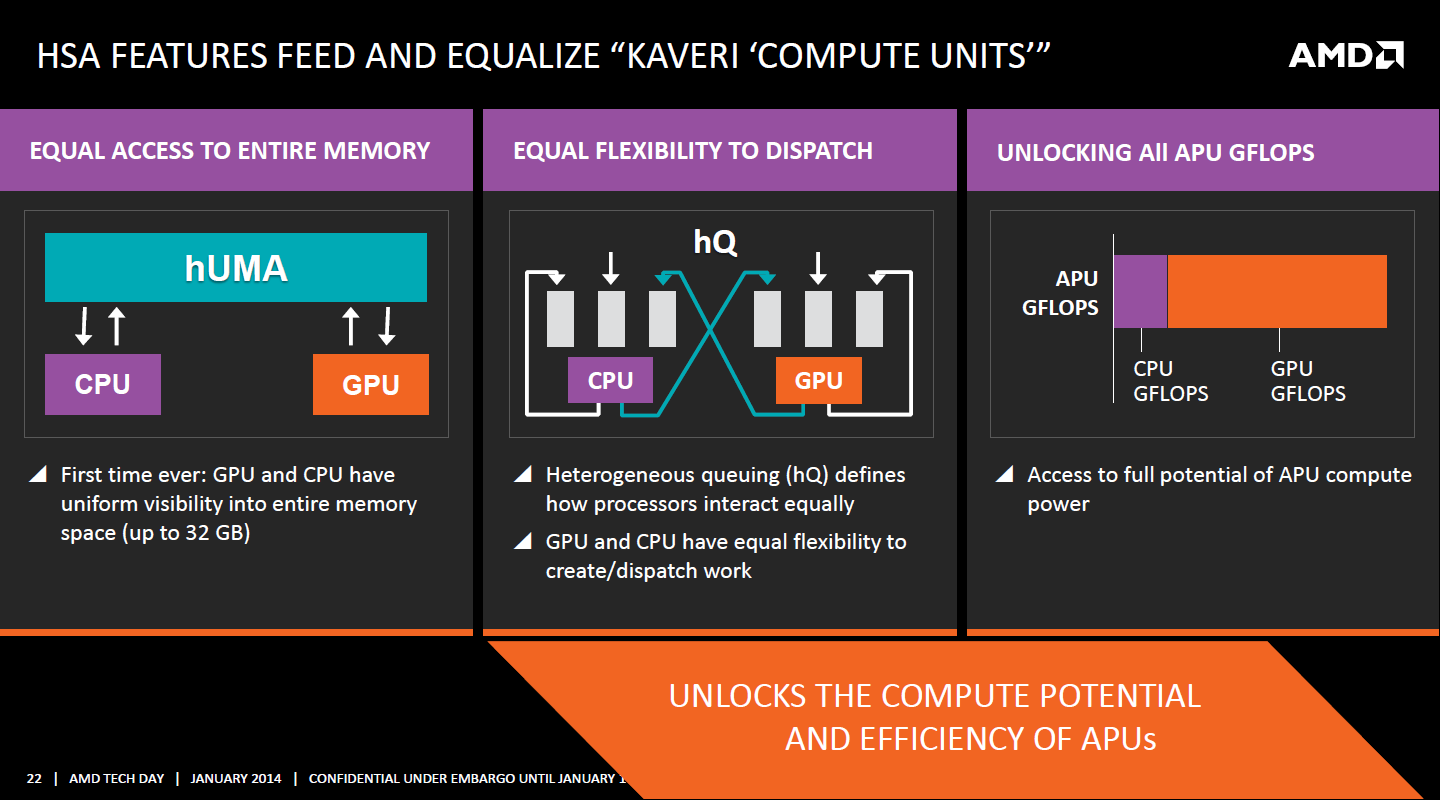 Kaveri est le premier APU d'AMD à implémenter complètement la HSA. Cette évolution s'est faite progressivement, à partir de Llano qui a implémenté des interfaces spéciales pour déplacer les données entre la partie CPU et GPU. Trinity/Richland a été un peu plus loin avec un northbridge unifié et l'arrivée de l'IOMMU alors que Kaveri finalise le support de la mémoire unifiée et cohérente.  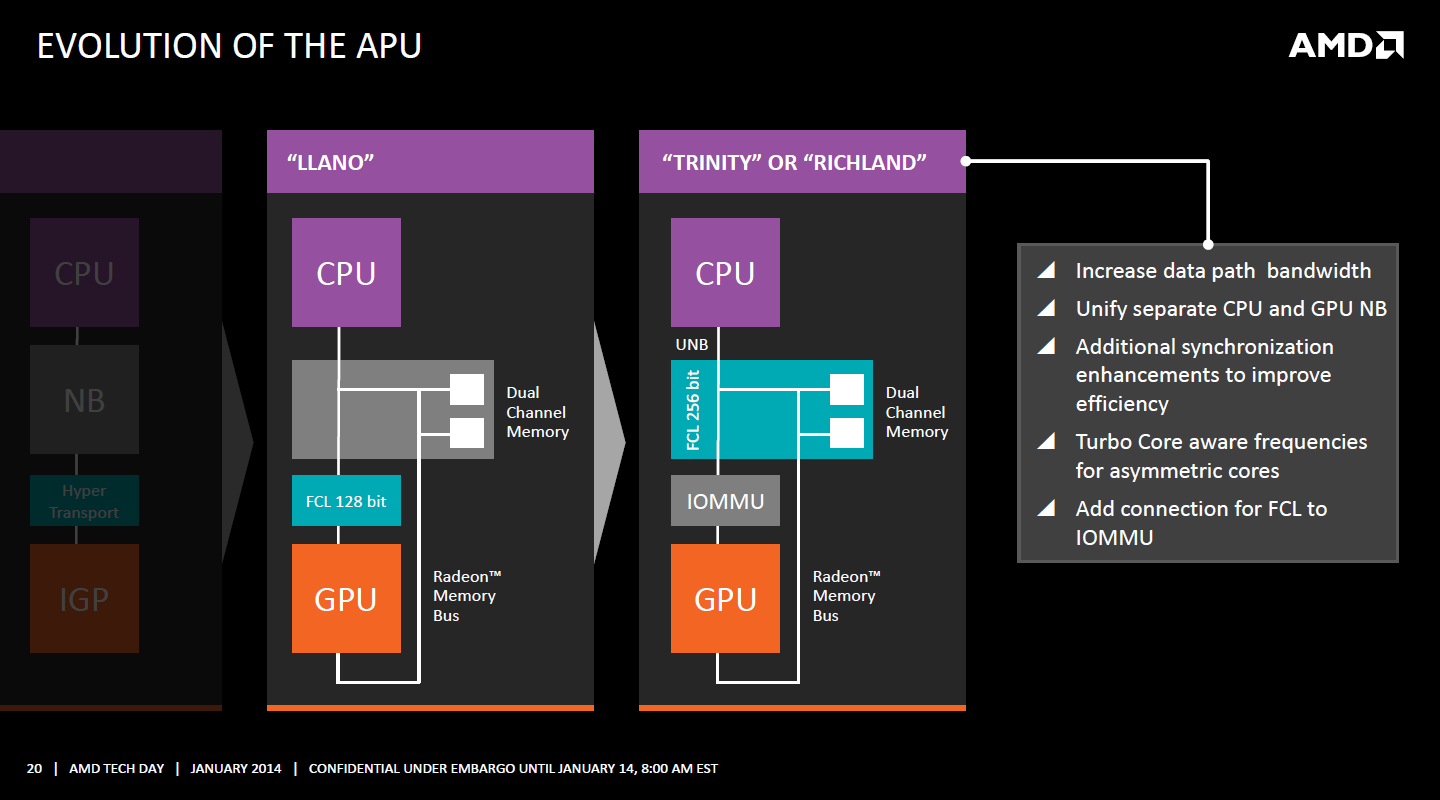 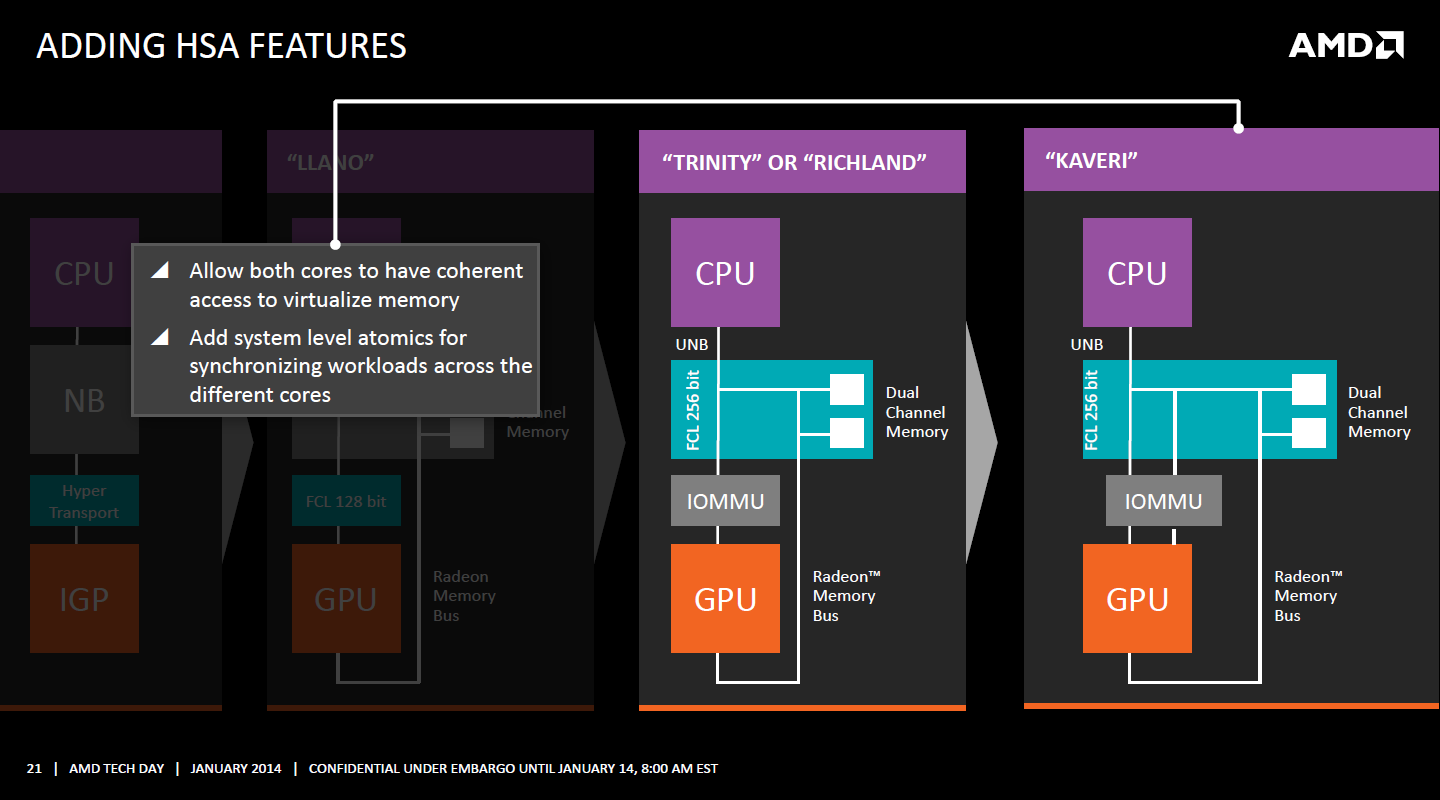 Avec Trinity/Richland, il était déjà possible d'éviter les copies entre les curs GPU et CPU, à travers le mode Zero-Copy optionnel. Le support de la mémoire virtuelle unifiée de Kaveri simplifie l'accès à cette possibilité. AMD conserve l'implémentation de deux bus entre les curs GPU et la mémoire : Garlic (Radeon memory Bus) et Onion (Compute Link Bus). Le bus Garlic est le plus performant, il offre un lien à pleine vitesse vers la mémoire DDR de manière à permettre au GPU dans le cadre du rendu 3D de profiter de la totalité de la bande passante mémoire. Il n'est par contre pas possible d'accéder directement à une zone mémoire exploitée par les curs CPU, une copie est nécessaire. Le bus Onion permet dans la plupart des cas d'éviter ces copies mais se contente avec Kaveri d'une bande passante qui correspond suivant les dérivés à 50-60% de la bande passante maximale. Il s'agit malgré tout d'une nette progression par rapport à Trinity/Richland, puisqu'elle correspond à un débit doublé. La nouveauté avec Kaveri est le mode Onion+ qui rend cohérent ce second bus à travers la possibilité offerte aux curs GPU d'exécuter des opérations atomiques sur la mémoire système. Il souffre cependant d'une limitation importante dans son implémentation sur Kaveri : le cache L2 du GPU se trouve désactivé ce qui peut avoir un impact sur les performances. Pour profiter de performances maximales, il revient toujours au développeur d'utiliser le type de mémoire le plus adapté à chaque utilisation : "Device Memory" pour profiter du bus Garlic dans le cadre de tâches purement graphiques, "Host Memory" (Onion) pour éviter les copies inutiles et "Coherent Host Memory" (Onion+) quand préserver la cohérence est réellement nécessaire. Voici un exemple de gains qui peuvent être rendu possibles en exploitant OpenCL 1.2 sur Kaveri en respectant les spécifications plus strictes de la HSA : 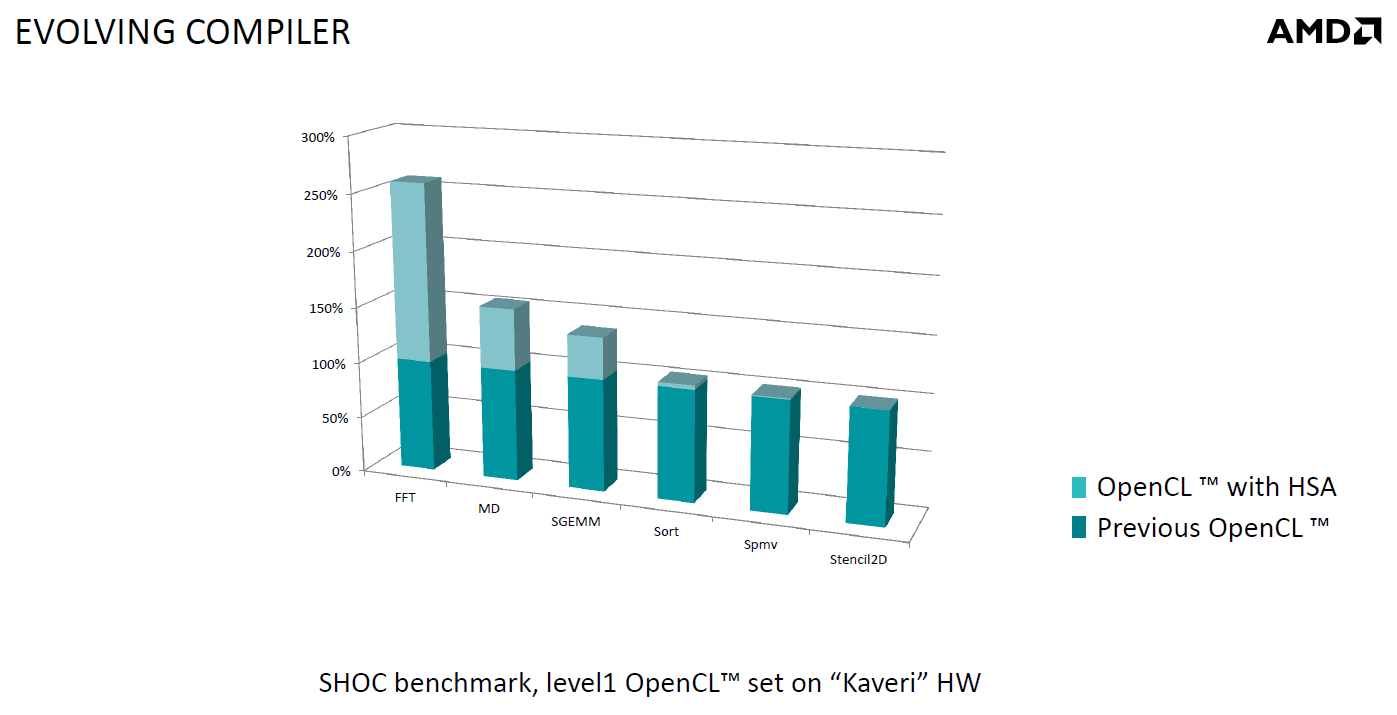 Comme vous pouvez le voir ici, les gains peuvent être inexistants ou très faibles dans certains cas, mais très importants dans d'autres. Typiquement, plus une application est complexe, plus les gains directs ou indirects de la HSA vont pouvoir se manifester, ne serait-ce que parce qu'il sera plus facile pour les développeurs d'optimiser leur code. Représenter cela à travers des benchmarks synthétiques peut ainsi être difficile alors que le support logiciel est actuellement presqu'inexistant. Pour les gains pratiques, il faudra donc attendre encore un petit peu, d'autant plus que le support logiciel n'est pas encore totalement prêt :  AMD parle ainsi du second semestre de cette année pour l'intégration finale de la HSA dans son compilateur OpenCL avec support de la version 1.2 de l'API associé à des extensions propriétaires pour les fonctionnalités additionnelles nécessaires. Pour le support de la HSA via OpenCL 2.0 il faudra attendre début 2015 et c'est probablement à partir de cette version que l'intérêt des développeurs pour la HSA progressera réellement. A l'heure actuelle, AMD fourni une version alpha de son compilateur OpenCL 1.2 avec support de la HSA. Cette version souffre de plusieurs limitations telles que l'utilisation exclusive d'espaces mémoire de type "Coherent Host Memory", les plus flexibles mais également les moins performants puisqu'ils ne peuvent pas profiter du cache L2 du GPU. Les agents HSA d'AMD : les Compute CoresSi pour les développeurs, AMD parle d'agents HSA, pour le grand public, une autre nomenclature vient d'être dévoilée par AMD : les Compute Cores. Chaque Compute Core est une structure capable de supporter la HSA et donc de prendre en charge son modèle mémoire et d'exécution/gestion des tâches.  Dans le cadre d'un APU, chaque module SMT représente 2 Compute Cores et chaque Compute Unit du GPU représente 1 Compute Core. Avec 2 modules SMT (4 curs CPU) et un GPU composé de 8 Compute Units, Kaveri supporte ainsi dans sa configuration maximale 12 Compute Cores. Parler du nombre de curs d'un composant est généralement tendancieux tant il s'agit d'un argument dont abusent de nombreux acteurs de l'industrie pour convaincre l'utilisateur final des bienfaits de leurs produits. Si considérer qu'une Compute Unit correspond à un cur est largement plus pertinent que de parler de GPU de plus de 1000 curs en comptant chaque ligne d'une unité vectorielle, cette façon de simplifier les choses ouvre la porte à de nouveaux abus. Il serait ainsi malvenu qu'AMD simplifie sa communication au point de vendre les APU Kaveri au grand public comme des processeurs à 12 curs c'est pourtant le chemin qui semble être pris quand on regarde une boite d'A10-7850K :  Page 4 - La gamme, conditions de test La gamme3 déclinaisons de Kaveri sont officiellement lancées ce jour, dont seulement 2 sont réellement disponibles : 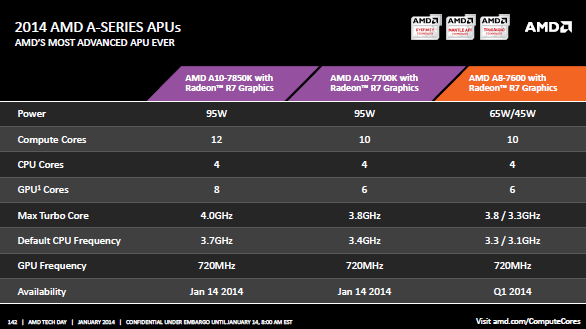 L'A10-7850K est la déclinaison la plus rapide. En sus de 4 curs Steamroller fonctionnant de base à 3.7 GHz avec un Turbo maximal à 4 GHz, il intègre 8 Compute Units GCN à 720 MHz, le tout tenant un dans un TDP de 95 watts. Il est annoncé à 173$, c'est notablement plus que son prédécesseur A10-6800K qui est à 142$. AMD met en avant la présence de 12 Compute Cores même au niveau de la boite : L'A10-7700K reste un processeur au TDP de 95 watts mais les fréquences CPU sont réduites, 3.4 GHz de base et un Turbo pouvant atteindre 3.8 GHz. Seules 6 Compute Units GCN sont actives (soit un total de 10 Compute Cores), avec une vitesse toujours à 720 MHz. Son tarif est fixé à 152$. Enfin l'A8-7600 complète la gamme mais ne sera pas disponible immédiatement. Ce processeur 65 watts propose de base un TDP de 65 watts mais AMD y a intégré la possibilité de le configurer dans le bios avec un TDP de 45 watts. En version 65 watts le processeur navigue entre 3.3 et 3.8 GHz, alors qu'il fonctionne entre 3.1 et 3.3 GHz une fois bridé à 45 watts. On retrouve en sus 6 Compute Units GCN à 720 MHz. Son prix est fixé à 119$, de quoi le positionner de manière intéressante face à ses prédécesseurs 65 watts et surtout 45 watts. En Richland on trouve en effet à 112$ l'A8-6500T mais il est fortement bridé avec un processeur fonctionnant entre 2.1 et 3.1 GHz et seulement la moitié des unités graphiques actives soit 192. Un peu plus cher l'A10-6700T à 142$ a des curs variant entre 2.5 et 3.5 GHz et 256 unités côté GPU. Les plus attentifs auront noté que les fréquences sont en baisse par rapport à Trinity et à son "évolution" Richland. C'est le cas côté CPU, puisqu'un A10-6800K a une fréquence de base de 4.1 GHz et un Turbo à 4.4 GHz, mais aussi côté GPU avec une fréquence qui était à 844 MHz. Alors qu'en juin 2012 AMD annonçait que Kaveri disposerait d'une puissance de calcul pour l'ensemble CPU/GPU de 1 Teraflops, le fondeur a donc dû revoir ce chiffre à la basse avec une puissance théorique maximale de 862 Gflops. A qui la faute ? Il semble facile de pointer du doigt le 28nm SHP de GlobalFoundries, mais AMD se refuse à accuser son partenaire, indiquant que le 28nm a été difficile pour tout le monde. A contrario sur l'A8-7600 configuré pour un TDP de 45 watts les fréquences sont en hausse par rapport aux Richland 45W, signe d'un meilleur comportement de la puce à des fréquences moins haute. AMD prévoit d'ailleurs côté mobile des Kaveri dont le TDP atteindra au plus bas 15 watts. Conditions de testUne fois n'est pas coutume, nous nous devons de revenir sur les conditions dans lesquelles nous avons réalisé ce test. Après de multiples relances afin de savoir si AMD pouvait nous fournir des échantillons de test ou si nous devions nous débrouiller par nous mêmes, ce n'est que vendredi dernier que nous avons reçu de la part d'AMD un kit pour le moins particulier ainsi que les pilotes et documentations afférents à Kaveri.  Alors que nous attendions les APU disponibles aujourd'hui, à savoir les A10-7850K et A10-7700K, nous avons reçu une machine montée complète composée d'un boitier Xigmatek Nebula, d'une carte mère mini-ITX Asrock FM2A88X-ITX+, d'une alimentation Antec 750W, de 16 Go de DDR3-2133, d'un Samsung 840 Pro 256... et surtout d'un APU A8-7600, soit celui qui n'est pas encore disponible. Ce dernier est même, fait rare pour AMD, un Engineering Sample. Un choix étonnant de prime abord de la part d'AMD alors que dans le même temps il a autorisé les précommandes sur les deux modèles disponibles au lancement, et qui sont aussi les plus onéreux, à savoir les A10-7850K et A10-7700K. AMD serait-il pessimiste quant à leurs prestations ? Le plus urgent étant de tester les produits disponibles, nous avons pu toutefois nous procurer par une autre source trois processeurs, 2 A10-7850K et 1 A10-7700K. 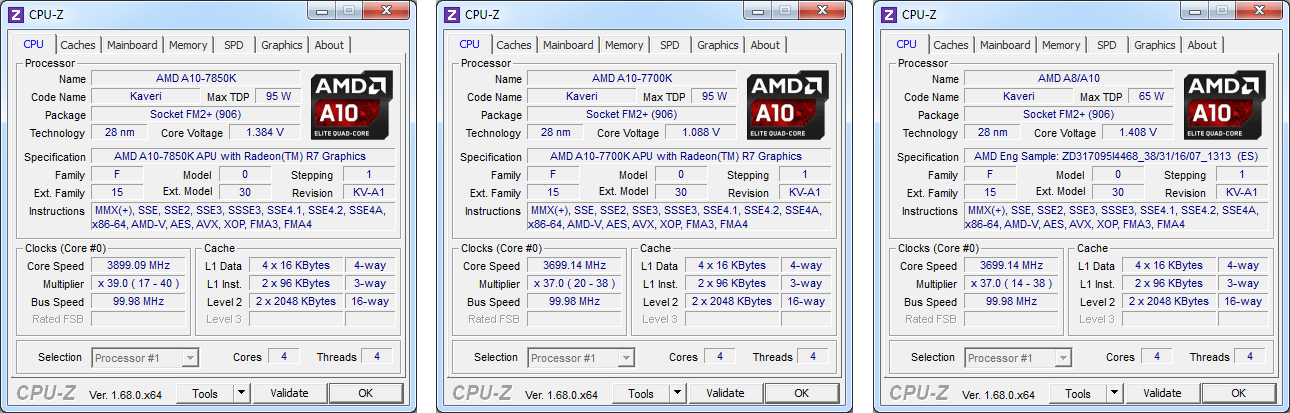 Ce sont ces processeurs qui sont utilisés dans ce test dont la partie benchmark est assurée par deux personnes, Guillaume au Havre pour les parties GPU / OpenCL et Marc à Lyon pour la partie CPU. Il faut noter que les deux processeurs A10-7850K ne disposent pas des mêmes combinaisons de fréquence et tension comme le précise ce tableau récapitulatif : 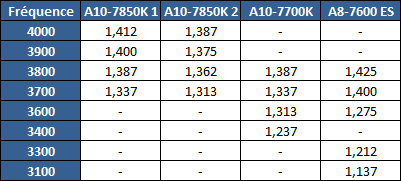 Pour l'heure il est difficile de savoir lequel des deux est le plus représentatif, toujours est-il que c'est le premier A10-7850K qui a été utilisé pour les tests CPU alors que les tests GPU et OpenCL se sont fait sur le second A10-7850K ainsi que l'A10-7700K. Dans l'absolu ces tensions paraissent élevées pour du 28nm.  Pour des raisons évidentes de timings et de localisations géographique il n'a pas été possible de tester l'A10-7700K côté processeur, ni l'A8-7600 au global, ce dernier n'étant de toute façon pas encore disponible. Page 5 - CPU - Protocole, DDR3-2400 Protocole et carte mèrePour tester la partie x86 de l'APU Kaveri nous utilisons notre protocole de test processeur habituel qui est décrit sur cette page. FM2+ oblige, nous changeons de carte mère pour une ASUS A88XM-Plus dotée du bios 1002 de début janvier ajoutant la compatibilité Kaveri. A ce sujet, la carte mère a démarré sans problème avec son bios 503 d'origine datant d'octobre et un Kaveri, un bon point qui évite de passer par un APU FM2 pour flasher.  Comme d'habitude en cas de changement de plate-forme nous avons voulu vérifier nos scores précédents, et il s'avère que cette fois les scores obtenus sur les A10-5800K et A10-6800K sur la carte mère ASUS sont en moyenne 2% plus élevés en applicatif, avec particulièrement une hausse sous WinRAR et 7-zip, et 4% plus élevés en jeux. A ce jour nous n'avons pas trouvé la raison de cet écart assez élevé difficilement explicable par un simple changement de carte mère, avec certes un bios plus récent. De fait seuls sont reportés dans cet articles les nouveaux scores. DDR3-1600 vs DDR3-2400Avant de commencer nous nous intéressons aux performances mémoire avec les résultats obtenus en DDR3-1600 9-9-9 et en DDR3-2400 11-13-13 sur un Kaveri et un Richland à 3.7 GHz dans les deux cas, le tout sous AIDA64 . Nous avons volontairement opté pour de la DDR3-2400 avec des timings "de base", étant donné le positionnement tarifaire de Kaveri il ne nous semblait pas pertinent d'utiliser de la mémoire plus onéreuse. Si le support officiel de la DDR3-2400 est une nouveauté de Kaveri, il faut noter qu'elle fonctionne également sur Richland. Bizarrement, sur notre A10-6800K il était possible de la faire fonctionner avec un Command Rate à 1 au contraire de l'A10-7850K. 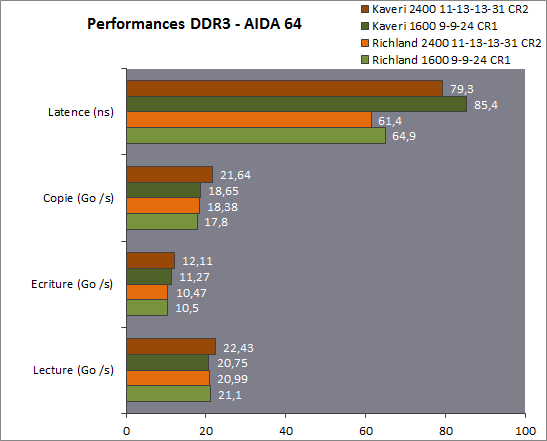 La première chose qui saute aux yeux est la latence mémoire qui est en forte hausse avec 18 à 20ns de plus sur Kaveri. Un chiffre très important que nous avons pu confirmer sur différent exemplaires et avec différentes cartes mères. En l'état il est difficile de connaitre la raison exacte de cette latence mémoire, même si il n'est pas exclu que des modifications nécessaires pour HSA soient en cause. D'après les développeurs de AIDA64, Kaveri perdrait entre autre beaucoup de temps sur les TLB miss, 35 à 40 cycles de plus que Richland. En pratique cette latence devrait avoir un impact non négligeable sur les performances CPU. Au-delà de cette latence on notera que le contrôleur mémoire de Kaveri semble plus à même d'exploiter la DDR3-2400, en effet on observe des gains de performances plus notables qu'avec Richland. Quid de l'impact en pratique de cette mémoire plus rapide sur les performances processeurs ? Voici les gains observés en passant de la DDR3-1600 à la DDR-2400 sous 4 applications.  Les gains sont assez modestes, notablement inférieurs à ceux enregistrés sur Haswell par exemple. Globalement Kaveri gagne un peu plus que Richland dans cet exercice, mais encore une fois c'est donc surtout du côté des performances de l'iGPU qu'il faudra voir l'apport de ce type de mémoire. Page 6 - CPU - Fréquence égale et Turbo Richland vs Kaveri à 3.7 GHzToujours avec une fréquence égale de 3,7 GHz de part et d'autre, voici les performances obtenues sous nos différents tests : 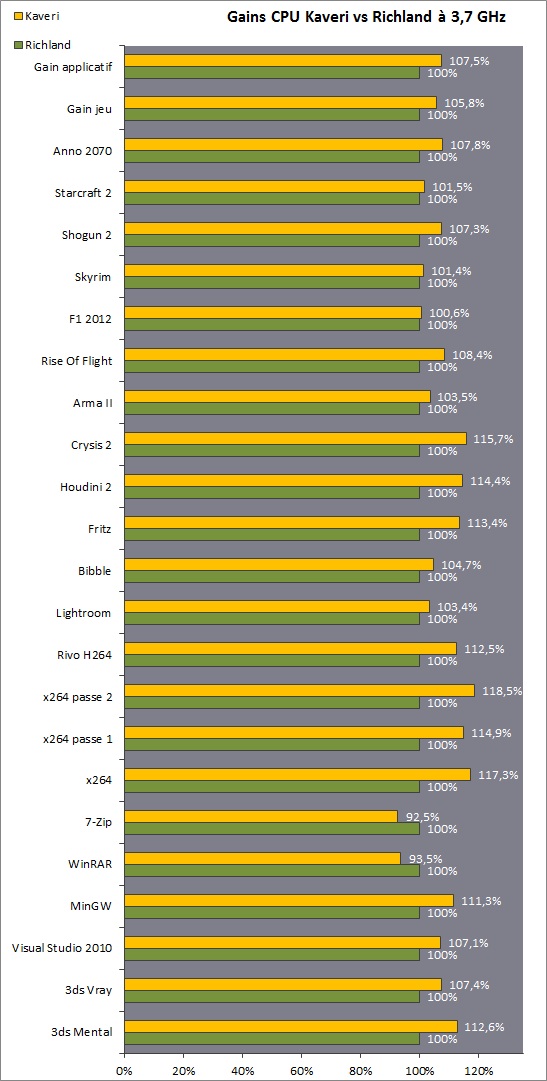 En moyenne, le gain est de 7,5% en applicatif, avec un gain maximal de 18,5% sous la seconde passe de x264. A contrario, c'est la conséquence directe de la latence élevée, les performances sont en net retrait sous WinRAR et 7-zip, et en excluant ces deux tests le gain est en moyenne de 10,4%. Si ces résultats peuvent paraîtres étonnant au premier abord, ils correspondent à peu près à ce que AMD indique, à savoir un gain d'IPC moyen de 10% avec une pointe à 20%. Dans les jeux le gain est plus réduit avec 5,8% en moyenne, et même si on n'enregistre pas de baisse nous aurions été curieux de voir ce qu'aurait donné Steamroller sans cette énorme latence mémoire. Impact du TurboAu passage, l'A10-7850K fonctionnant de base à 3.7 GHz avec un Turbo à 4 GHz, nous avons donc l'occasion de voir les gains offerts par le Turbo sur cet APU : 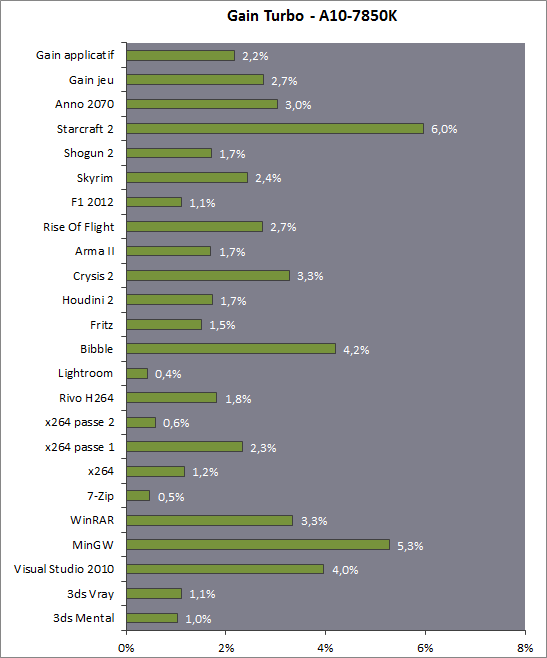 Les gains en pratique sont assez éloignés du gain maximal théorique lié à la fréquence Turbo (8.1%), avec en moyenne 2,2% en applicatif et 2,7% en jeux. En fait dans de nombreux cas avec une charge sur les 4 curs la fréquence est de 3.9 GHz sur les 4 curs au début du test, plus rapidement elle vient à varier entre 3.8 et 3.9 GHz, et enfin après quelques dizaines de secondes entre 3.7 et 3.8 GHz. 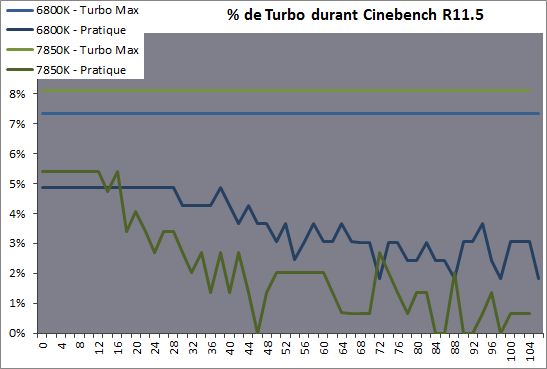 Afin d'illustrer ce phénomène voici un log de la fréquence moyenne des 4 curs pendant les 104 à 106 secondes du bench CPU de Cinebench R11.5. Comme on peut le voir, que ce soit sur l'A10-6800K ou sur l'A10-7850K on est assez loin du gain maximum théorique promis par les spécifications, et en pratique une fois les 15 premières secondes passées le Turbo de l'A10-7850K commence à se réduire comme peau de chagrin. Page 7 - CPU - Performances applicatives CPU - Performances applicatives   [ Mental Ray ] [ V-Ray ] [ Visual Studio ] [ MinGW/GCC ] [ WinRAR ] [ 7-Zip ] [ x264 ] [ Rovi H.264 ] [ Lightroom ] [ Bibble ] [ Fritz ] [ Houdini ] Le protocole de test est identique à celui d'Haswell décrit ici, vous trouverez au sein de cet article une description de chacun des tests. La combinaison de hausse de l'IPC avec une fréquence en baisse et un Turbo assez peu efficace fait que l'A10-7850K a un sort assez variable selon les applications. Face à l'A10-6800K, le gain le plus important est sous x264 avec 5% (et 6,1% sur la seconde passe) suivi de Mental Ray à 4,1%. A contrario on note des baisses, parfois importantes comme sous WinRAR et 7-zip, mais pas seulement puisque les scores sous Lightroom et Bibble sont également en baisse notable. Logiquement la comparaison avec l'A10-5800K qui dispose de fréquence plus proches bien qu'encore supérieures à l'A10-7850K est plus à l'avantage de Kaveri. 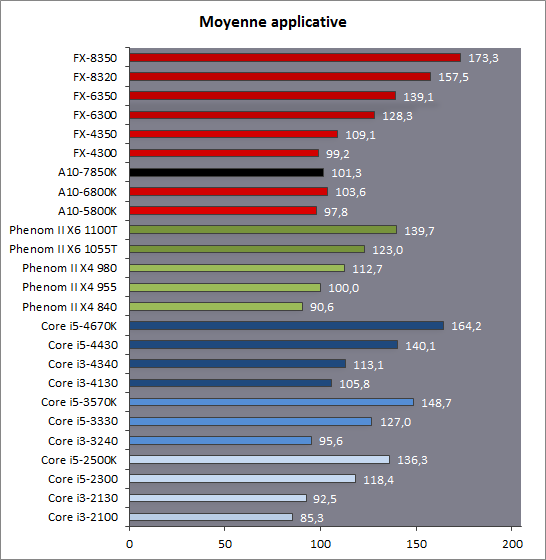 Au final avec un indice de performance à 101, l'A10-7850K ne parvient pas à dépasser son prédécesseur et reste en léger retrait. Même le plus petit des Core i3 Haswell, le 4130, reste légèrement devant. Page 8 - CPU - Performances Jeux 3D CPU - Performances Jeux 3D  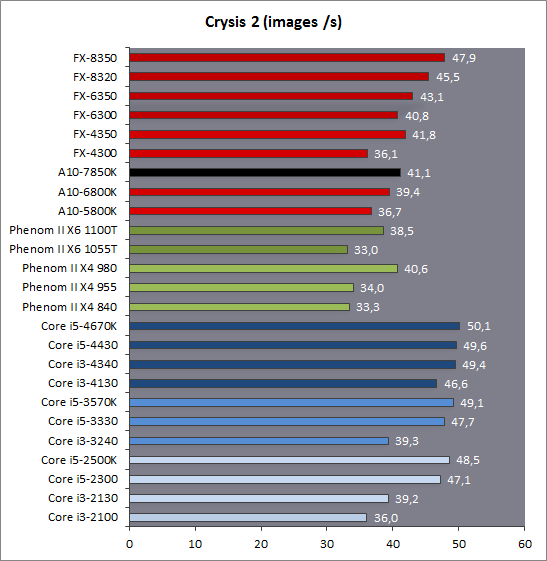 [ Crysis 2 ] [ Arma II ] [ Rise Of Flight ] [ F1 2012 ] [ Skyrim ] [ TW Shogun 2 ] [ Starcraft II ] [ Anno 2070 ] Le protocole de test est identique à celui d'Haswell décrit ici, vous trouverez au sein de cet article une description de chacun des tests. Seul Crysis 2 arrive à tirer profit de l'A10-7850K, avec un gain de 4,3% face à l'A10-6800K pour les autres le gain d'IPC n'est pas suffisant pour compenser la perte de fréquence et la latence mémoire très élevée, les baisses de performances sont notables. 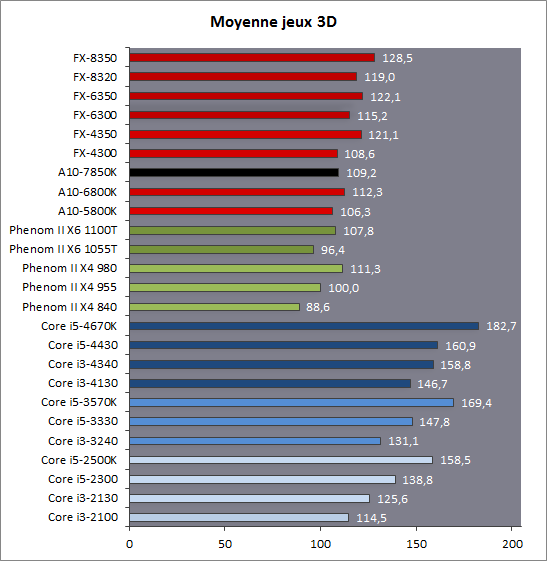 En moyenne l'A10-7850K se hisse entre les A10-5800K et A10-6800K. Les processeurs Intel Core i3 restent intouchables pour un processeur AMD 4 curs dans ces titres qui ne tirent pas pleinement partie de 4 curs mais il faut noter qu'avec un jeu tel que Battlefield 4 vraiment optimisé pour le multithread un A10-7850K sera cette fois devant un i3-4130 comme vous le verrez en page 10, c'est assez rare pour être noté. AMD compte bien entendu sur la démocratisation de ce niveau d'optimisation pour positionner dans les applications ludiques ses CPU et APU aux même niveaux que ceux obtenus en applicatif. Page 9 - CPU - Consommation, overclocking CPU - Consommation et efficacité énergétiquePour le test de consommation nous essayons d'utiliser un logiciel qui est pour toutes les architectures assez représentatif de ce que nous obtenons dans les applications en termes de performances et de consommation. Notre choix se porte actuellement sur Fritz Chess Benchmark, qui a de plus l'avantage de pouvoir facilement fixer le nombre de threads à utiliser. Les mesures de consommation ne sont donc pas à prendre comme des valeurs maximales absolues mais plutôt typiques d'une charge lourde, puisque des logiciels spécialisés dans le stress processeur tels que Prime95 peuvent consommer environ 20% de plus. Toutes les fonctionnalités d'économie d'énergie, y compris celles des cartes mères comme l'EPU d'ASUS, sont activées pour ce test du moment qu'elles n'impactent pas négativement les performances. Nous donnons pour rappel deux types de relevés, la première à la prise 220V via un wattmètre pour la configuration de test dans son intégralité, et la seconde sur l'ATX12V via une pince ampèremétrique. Cette mesure permet d'isoler le gros de la consommation du processeur, mais elle n'est malheureusement pas exactement comparable d'une plate-forme à une autre puisque dans certains cas une petite partie de la consommation du CPU est issue de la prise ATX 24 pins standard. Voici les configurations utilisées : - Intel DP67BG (LGA1155) - Intel DZ87KL-75K (LGA1150) - Intel DX79SI (LGA2011) - ASUS M5A99X EVO (AM3+) - ASUS A88XM-Plus (FM2+) - 2x4 Go DDR3-1600 9-9-9 - 4x4 Go DDR3-1600 9-9-9 (LGA 2011, environ 1 watts de plus au repos et 3 en charge) - GeForce GTX 680 + GeForce 306.97 - SSD Intel X25-M 160 Go + SSD Intel 320 120 Go - Alimentation Corsair AX650 Gold - Windows 7 SP1 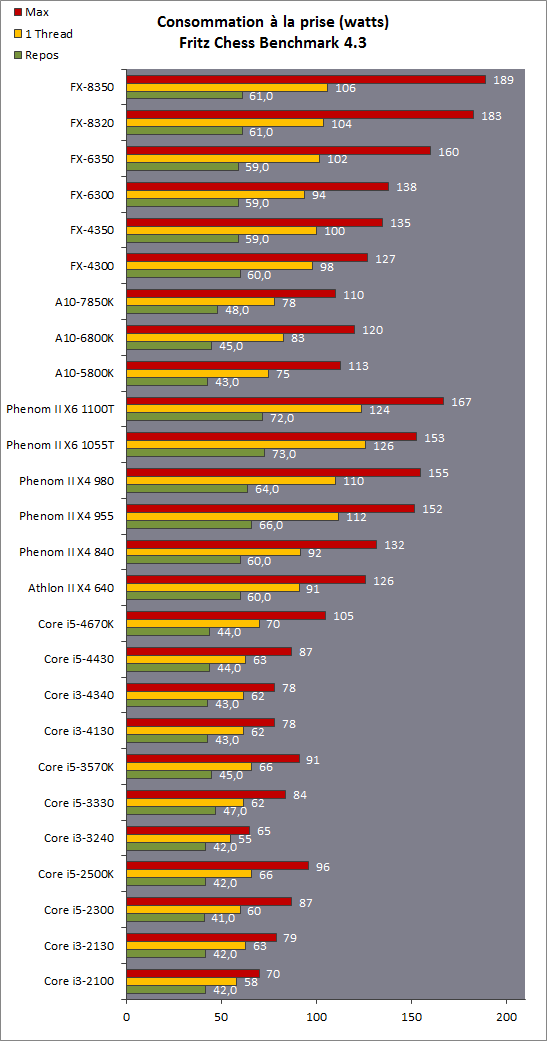 [ Prise 220V ] [ ATX12V ] Comme indiqué dans la configuration de test, la configuration intègre une GTX 680 ce qui entraîne environ 18 watts de plus de consommation à la prise au repos. La consommation de la plate-forme FM2+ est contenue au repos, mais bizarrement c'est notre A10-5800K qui lui permet d'afficher la consommation la plus basse. Avec l'A10-7850K, elle tout de même supérieure de 5 watts à la prise. En charge la consommation de l'A10-7850K 95W est inférieure à ses prédécesseurs 100W, avec une baisse de 7 à 10W à la prise et de 6 à 12W sur l'ATX12V. On est aux environs d'un Core i5-4670K. Passons à l'efficacité énergétique du processeur. Pour se faire il s'agit de diviser la performance obtenue sous Fritz Chess Benchmark par la consommation du CPU. Seul problème, il n'est pas possible de connaitre exactement celle-ci : la mesure sur l'ATX12V n'est pas 100% comparable d'une plate-forme à une autre, et la mesure à la prise ne permet pas complètement d'isoler tout ceci. Nous avons donc fait le choix d'utiliser deux méthodes de calcul pour isoler la consommation de processeur : - Consommation sur l'ATX12V - 90% du delta de consommation à la prise entre charge et repos Nous utilisons les 90% afin d'exclure le rendement de l'alimentation à proprement parler. Il faut noter que si la première mesure favorise les processeurs tirant une petite partie de leur énergie via la prise ATX classique, la seconde favorise ceux qui ont une consommation élevée au repos. Malheureusement aucune méthode n'est parfaite. 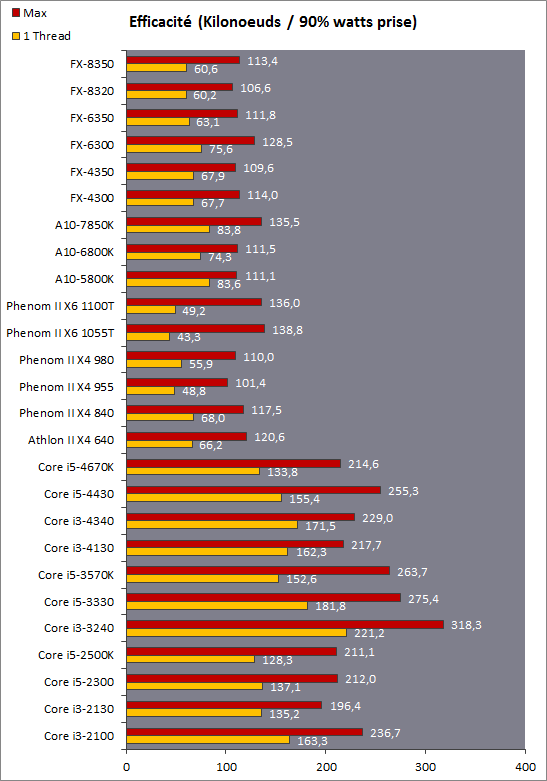 [ Prise 220V ] [ ATX12V ] Si l'efficacité énergétique est en hausse sur l'A10-7850K face au A10-6800K et A10-5800K, on reste malgré tout très loin des niveaux atteints par l'offre Intel. CPU - OverclockingNous avons essayé de voir ce que donnait l'overclocking sur notre A10-7850K, sans l'aide d'OverDrive donc la version fournie par AMD entrainait un redémarrage immédiat de notre système. Ces tests sont fait avec l'APM (et donc le Turbo) désactivés dans le bios afin de garantir le maintien de la fréquence même sous Prime95. En effet avec le Turbo actif sous Prime95 la fréquence des curs varie entre 3.5 et 3.7 GHz, alors que la fréquence annoncée comme celle de base est de 3.7 GHz, ce qui n'a rien d'inédit chez AMD. Voici les résultats que nous avons obtenus : 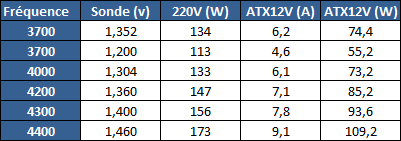 Par défaut à 3.7 GHz le processeur demande 1,3775V et il obtient 1,352V de la part de la carte mère ASUS (sans EPU actif, avec elle lui fournit 1,272v pour 62,4w sur l'ATX12V). Il est possible de nettement abaisser cette tension pour atteindre une consommation inférieure de 21 watts à la prise. On notera que malgré la désactivation du Turbo la consommation reste assez éloignée du TDP, on se demande dès lors pourquoi la fréquence passe en dessous de 3.7 GHz avec le Turbo actif ! La hausse de fréquence nécessite bien entendu une hausse de la tension, qui reste mesurée à 4 GHz et 4.2 GHz. Ensuite il faut augmenter la tension pour chaque gain de 100 MHz, si bien qu'on atteint 1,46v à 4.4 GHz. La consommation est alors en hausse de 39W à la prise et 35W sur l'ATX12V par rapport au réglage par défaut. Nous avons décidé de ne pas pousser nos essais au-delà de cette tension.  A titre de comparaison nous avions pu obtenir durant le test de l'A10-6800K une fréquence de 4.7 GHz à 1,416v. On retrouve donc en overclocking une baisse de fréquence sur les Kaveri par rapport au Richland, comme c'est le cas pour les fréquences officielles. Page 10 - GPU - Dual Graphics, Jeux Pour tester la partie GPU de l'APU Kaveri, nous avons utilisé une plateforme similaire à celle utilisée pour la partie x86, à savoir une carte mère Asus A88XM-Plus équipée du dernier BIOS 1002. Nous utilisons deux barrettes mémoires de 4 Go de DDR3-2666 réglés à différents timings : DDR3-1600 9-9-9-24 1T DDR3-2133 11-11-11-27 2T DDR3-2400 11-13-13-31 2T Le reste de la configuration est composé d'un SSD OCZ Vertex Max IOPS ainsi que d'un bloc d'alimentation Seasonic Platinum 660W. Les tests sont réalisés sous Windows 7 64 bits. Nous avons réalisés une suite de tests dans différents jeux, en 1080p et lorsque c'était possible dans deux niveaux graphiques différents que nous préciserons au cas par cas. Nous avons également évalué avec la même plateforme les performances en OpenCL sur lesquelles nous reviendrons un peu plus après. En sus des performances des GPU intégrés, nous avons également ajouté un certain nombre de cartes graphiques discrètes afin de pouvoir donner un point de comparaison. Il s'agit des cartes suivantes : - Radeon HD 6670 GDDR5 - Radeon HD 7750 GDDR5 - Radeon R7 250 GDDR3 - Radeon R7 250 GDDR5 Nous avons également ajouté à notre test des processeurs Intel aux tarifs relativement proches de ceux des APU testés, il s'agit du Core i5 4430 et du Core i3 4130. Si le premier est équipé du GPU intégré HD 4600 (celui que nous avions testé ici), le 4130 est équipé d'une version plus limitée, le HD 4400. En pratique il s'agit du même GPU (le GT2) dont le nombre d'unités d'exécution a été castré, passant de 20 à 16. Notez que ces processeurs ne supportent officiellement que la mémoire DDR3-1600, nous les avons testés avec cette fréquence mémoire. Kaveri supportant officiellement la mémoire DDR3-2400, nous l'avons également testé dans ce mode ainsi qu'en DDR3-2133. Cela va nous permettre de voir l'impact de la bande passante mémoire sur les performances. Dans le cas de tests avec carte graphique additionnelle, nous utilisons le mode le plus rapide supporté officiellement par la plateforme, DDR3-2400 chez AMD, DDR3-1600 chez Intel. Dual Graphics Le choix des cartes additionnelles que nous avons effectué n'est pas anodin. Pour rappel, les APU AMD disposent d'une possibilité assez originale baptisée Dual Graphics. Il s'agit en pratique d'une version un peu particulière de la technologie CrossfireX qui permet d'additionner les performances du GPU intégré à l'APU avec les performances d'une carte graphique externe. Pour que cela fonctionne, il faut au minimum que le GPU additionnel et le GPU intégré à l'APU disposent d'une architecture similaire. Dans le cas de Richland, il s'agit d'une architecture VLIW4 que l'on retrouve dans la 6670. Pour les nouveaux APU Kaveri, il s'agit bien entendu de l'architecture GCN utilisée dans les autres cartes (HD 7750, R7 250). Cependant, les technologies comme CrossfireX supportent en général assez mal des asymétries trop importantes en termes de performances entre les deux cartes. Résultat, AMD ajoute certaines restrictions sur les modèles utilisables en Dual Graphics : en pratique, seules les Radeon R7 240 et R7 250 peuvent fonctionner avec les APU Kaveri.  Notez enfin que pour pouvoir activer Dual Graphics, il est nécessaire d'activer une option adéquate dans le BIOS. Dans le cas de notre carte mère Asus A88XM-Plus, il s'agit d'IGFX Multi Monitor. Si la description est relativement claire à droite, cela reste tout de même peu intuitif étant donné que cette option est désactivée par défaut. Une fois cette option activée, et si vous disposez de la carte graphique adéquate, Dual Graphics sera activé automatiquement au prochain démarrage Windows, quelque chose que vous pouvez vérifier dans le Catalyst Control Center. Ou est le Frame Pacing ? Si vous suivez l'actualité des cartes graphiques, vous aurez probablement vu passer une évolution assez importante de la technologie CrossfireX : l'arrivée du concept de Frame Pacing que nous avions décrit en aout dernier. L'idée du Frame Pacing est d'améliorer le ressenti de fluidité dans les configurations a multiples cartes graphiques, quitte à sacrifier légèrement sur les performances. AMD a lancé officiellement la technologie dans ses pilotes en décembre dernier et l'on attendait beaucoup du Frame Pacing avec le Dual Graphics. L'asymétrie des GPU tendant à amplifier encore plus les problèmes de fluidité. Il faudra cependant encore attendre, afin de réaliser ce test, AMD nous a fourni une version interne de ses pilotes baptisée Catalyst 13.30 RC2 qui sera rendue disponible sous la forme d'un pilote dédié aux APU aujourd'hui. AMD nous a indiqué que le Frame Pacing apparaitrait pour Dual Graphics dans un pilote beta d'ici à la fin du mois (Catalyst 14.1 beta). Passons, enfin, aux tests ! F1 2013  Nous commençons avec la dernière version en date du jeu de Formule 1 de Codemasters qui est relativement peu gourmand. Nous utilisons deux presets graphiques distincts présents dans le jeu, Medium et High. 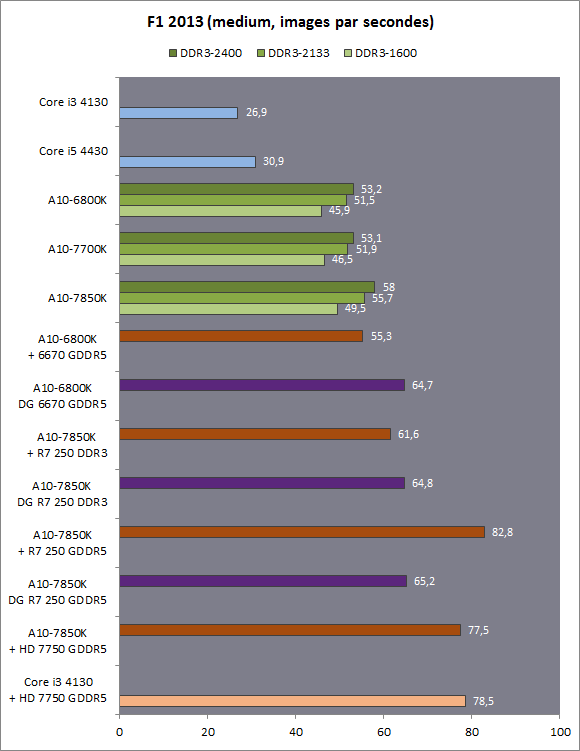 [ Medium ] [ High ] Petit rappel de nomenclature sur nos graphiques, nous avons testés à la fois les cartes graphiques seules (en rouge/orange, notation « + »), et lorsque cela était possible en Dual Graphics (en violet, notation « DG »). Cela nous permet de comparer les performances du Dual Graphics à celles de la carte seule. F1 fait partie des jeux qui posent peu de problèmes aux APU et si l'on sacrifie sur la qualité graphique, on pourra tout de même jouer sur les APU seules. On notera des gains assez limités entre Kaveri et Richland dans ce titre avec seulement de 8 à 9% de performances en medium. En mode High, les gains sont un peu plus importants puisque l'écart approche de 10%. Dans tous les cas, on notera ici une dépendance forte à la bande passante mémoire qui limite fortement les performances en DDR3-1600. Le jeu est ici péniblement jouable avec les configurations Intel, plus particulièrement avec le HD 4400 franchement trop limité. Le mode High est injouable. L'apport de Dual Graphics est relativement variable en fonction des configurations, on notera même une baisse de performances avec le 7850K cumulé à une R7 250 GDDR5. Seule, la Radeon R7 250 GDDR5 fait mieux qu'accouplée à l'APU en Dual Graphics. Dans tous les cas on est loin d'additionner les performances APU + GPU sur ce titre, seulement 5% de gains avec une R7 250 DDR3 par rapport à cette dernière seule. Le couple APU 6800K + HD 6670 GDDR5 la génération précédente - est celui qui profite le plus du Dual Graphics avec 17% de gains par rapport à la HD 6670 seule. En mode high, les gains augmentent un peu plus significativement avec près de 29% de gains pour le modèle DDR3. Le modèle GDDR5 de la R7 250 reste par contre castré par Dual Graphics. Battlefield 4  La dernière version du FPS de DICE est un titre gourmand, mais AMD n'hésite pas à le mettre en avant avec ses APU. Le constructeur a ainsi proposé des bundles outre atlantique pour les précommandes des A10 liées à des cartes mères ou de la mémoire Radeon pour lesquels le jeu est offert. AMD espérait bien entendu que le support de la technologie Mantle soit présent pour le lancement des APU, mais comme nous vous l'indiquions précédemment, le patch Mantle a été repoussé par DICE. Nous testons donc le titre en l'état dans les deux modes graphiques les plus modestes, low et medium. 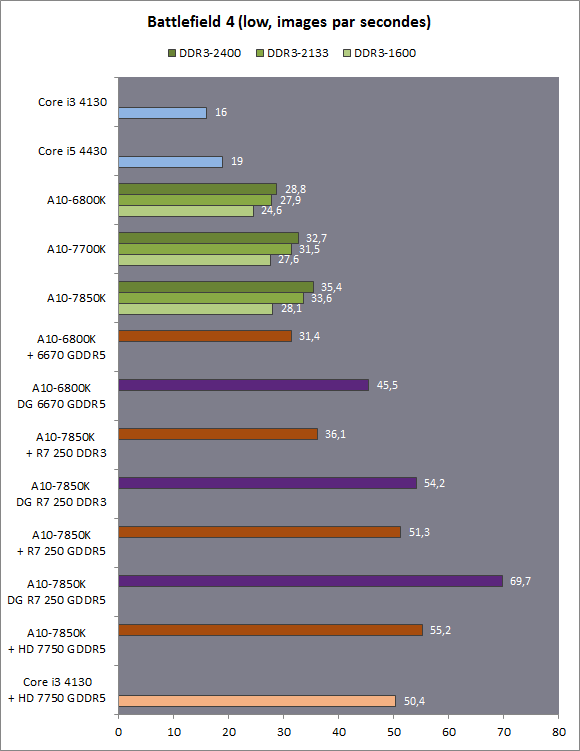 [ Low ] [ Medium ] Les performances des APU sans Mantle sont très loin d'être suffisantes pour que l'on considère le titre comme jouable, même dans le mode graphique le plus faible. Malgré des pourcentages de gains intéressants pour Kaveri (23% par rapport à Richland), on reste dans le domaine de l'injouable avec des saccades trop importantes. Il sera intéressant de voir ce que Mantle apportera dans ces situations. On notera par contre ici que le Dual Graphics marche assez bien avec des bonds en avant importants. Cumuler Kaveri avec une R7 250 DDR3 apporte un gain de 50% de performances par rapport à cette carte graphique seule. Même le modèle GDDR5 profite avec 36% de gains en comparaison. Notez que si les gains sont encore plus importants en mode Medium, nous ne considérons pas ces modes comme suffisamment fluides avec des saccades importantes. Notons un point positif cependant pour l'A10-7850K dans les deux dernières lignes de notre graphique. Nous avons en effet utilisé une Radeon HD 7750 GDDR5 à la fois sur notre Core i3 et sur l'APU haut de gamme Kaveri. On notera ici un petit avantage dans les deux modes pour l'APU d'AMD. Quelque chose d'assez rare et qui semble limité à ce titre qui même en l'absence de Mantle est l'un des seuls à être fortement multithreadé ! Batman Arkham Origins  Nous avons mesuré les performances dans le dernier épisode de la série Batman. Nous désactivons PhysX ainsi que toutes les autres options graphiques pour établir un mode minimal. Nous activons un cran d'options supplémentaires (toujours hors PhysX) pour proposer un mode medium. Voici les performances obtenues : 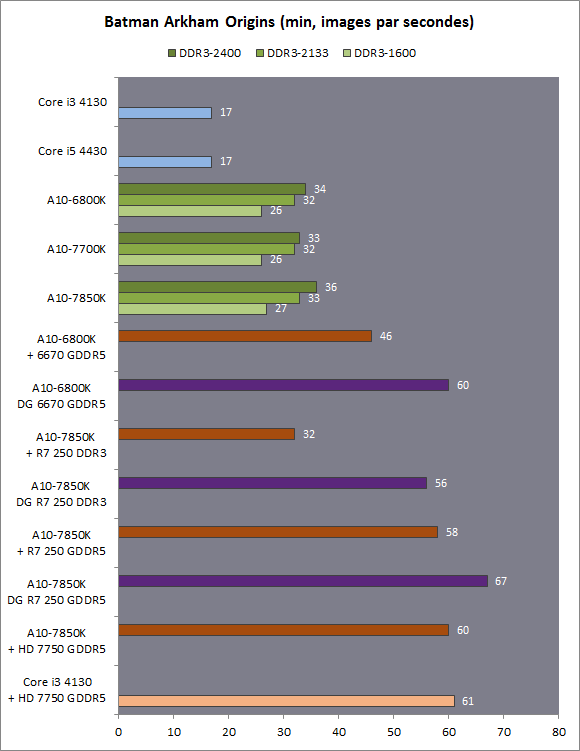 [ Low ] [ Medium ] Si les APU d'AMD font significativement mieux que celles d'Intel, difficile de parler de jouabilité sur ce titre qui même en low reste trop gourmand. On notera des gains assez modestes par rapport à la génération précédente, entre 3 et 6%. Ajouter une carte dédiée améliore les choses, particulièrement dans le cas de la HD 7750 ou de la R7 250 GDDR5. Dual Graphics propose des gains mais si nous avons noté les scores, nous devons indiquer d'importants clignotements sur les textures qui rendent le jeu injouable dans ces configurations. League of Legends  Nous terminons notre tour de jeux avec un titre beaucoup plus léger, le très populaire League of Legends. Ce titre est très peu gourmand et toutes les options graphiques sont réglées au maximum. 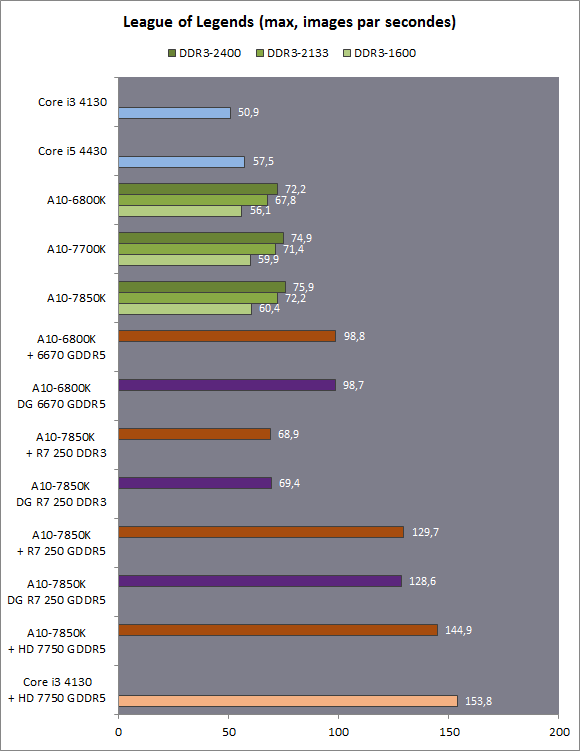 Là encore on notera des gains générationnels relativement faibles, seulement de 5 à 7.5%. Cependant pas de problème de jouabilité, toutes les configurations sont suffisament confortables - même les IGP Intel bien que l'on soit sous les 60 FPS ! Dual Graphics ne semble pas fonctionner sur ce titre, cela semble de toute façon inutile vu le niveau de performances atteint. Page 11 - APU - OpenCL En sus des jeux, nous avons également voulu observer les performances en OpenCL des Kaveri, un point particulièrement poussé en avant par AMD même si l'écosystème applicatif reste modeste. Luxmark 2.0  Nous commençons par LuxMark, benchmark du moteur de rendu 3D open source LuxRender. Il s'agit d'un bon élève au niveau des benchmarks OpenCL puisqu'il est capable de faire tourner du code OpenCL à la fois sur processeur, sur GPU, et même de mélanger les deux. Mieux, dans le cas ou plusieurs GPU sont présents, il est capable de tous les utiliser. Un cas d'école qui, vous le verrez plus loin, se limite à ce bench pour le moment. Notez que pour les tests ou l'on indique « + », nous désactivons l'IGP intégré aux APU (ce qui équivaut au Dual Graphics désactivé dans le BIOS, configuration par défaut de notre carte mère pour rappel). 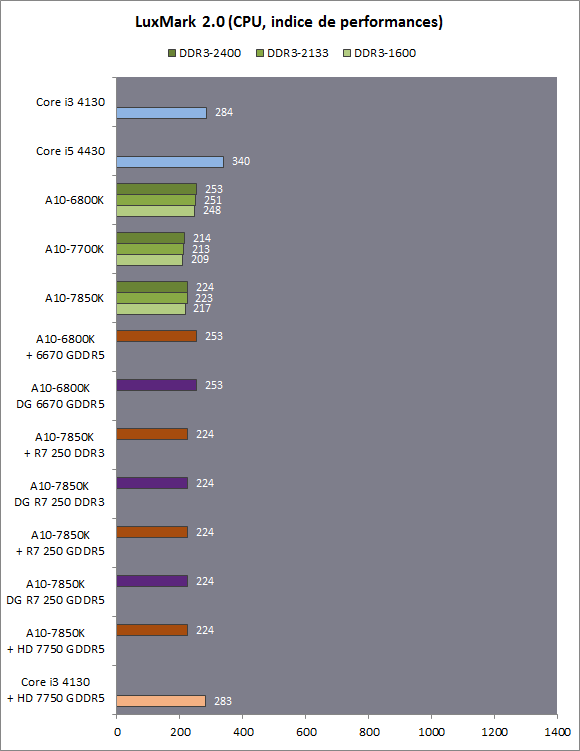 [ CPU ] [ GPU ] [ CPU+GPU ] On notera qu'en mode processeur, les nouveaux APU Kaveri font moins bien que la génération précédente avec 12% de baisse environ. Heureusement pour AMD, les choses sont plus joyeuses dès que l'on active OpenCL sur le GPU puisque les performances sont doublées par rapport à la génération précédente. Notez que si l'on garde la notation Dual Graphics, en pratique cette technologie n'est pas utilisée : c'est la présence des deux GPU qui est détectée par LuxMark pour utiliser OpenCL sur les deux cartes en simultanée. Le cumul de performances est quasi parfait pour ce cas d'école. Ajouter le CPU améliore encore le niveau de performances même si les additions ne sont plus exactes, Turbo oblige. BasemarkCL 1.1  Nous avons également ajouté la suite de tests BasemarkCL qui propose des tests assez variés allant de la physique aux traitements d'images fixes. Nous notons l'indice global de performances rapporté par le titre. Ce dernier ne gère qu'un seul GPU à la fois, nous supprimons donc les configurations Dual Graphics de nos graphiques. 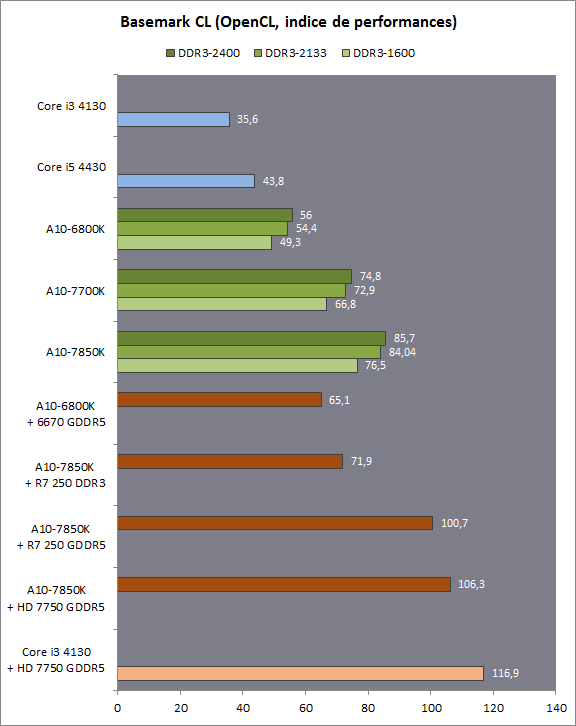 Là encore on retrouve un gain de performances important dans ce test théorique avec un bond en avant de 50% par rapport à la plateforme précédente. L'A10-7850K se place à mi-chemin entre les deux modèles de Radeon R7 250. DxO Optics Pro 9.1.1  Nous utilisons la version 9.1.1 de ce logiciel de traitement photo pour réaliser des exports RAW vers JPEG sur une série de 48 fichiers. Le logiciel permet d'utiliser au choix un mode processeur (x86) ou un mode OpenCL sur un GPU (non sélectionnable). Dans le cas où le périphérique présent est plus lent que le processeur (c'est le cas des IGP Intel, plus lents que les cores processeurs), le logiciel avertit l'utilisateur. Notez avant de commencer que nous avons obtenus des temps de traitements assez erratiques dans ce bench qui plaçait systématiquement le 7700 devant le 7850K. On se contentera de regarder les tendances générales. 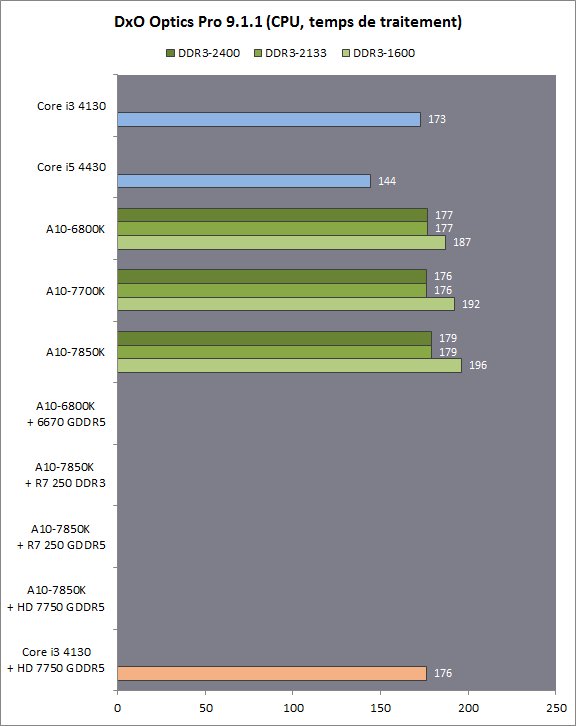 [ CPU ] [ OpenCL ] L'activation du mode OpenCL chez Intel reste une fois de plus un ralentissement, tandis que cela permet de gagner jusque 10% de performances sur nos APU. L'ajout d'une carte additionnel n'apporte quelque chose qu'à partir de la R7 250 GDDR5 ou de la HD 7750. Vegas Pro 12  Nous clôturons ces benchs OpenCL avec un autre logiciel pratique : Vegas Pro 12 de Sony. Ce logiciel est intéressant à double titre puisqu'il propose non seulement une accélération OpenCL de la composition, mais en prime une accélération OpenCL de l'encodage vidéo via l'encodeur H.264 MainConcept. Nous réalisons deux séries de tests, une en mode x86 (OpenCL désactivé partout), et une en mode OpenCL complet. En pratique, l'encodage H.264 n'est pas ici le facteur limitant, la composition des pistes vidéo et les effets sont principalement ce que l'on mesure. 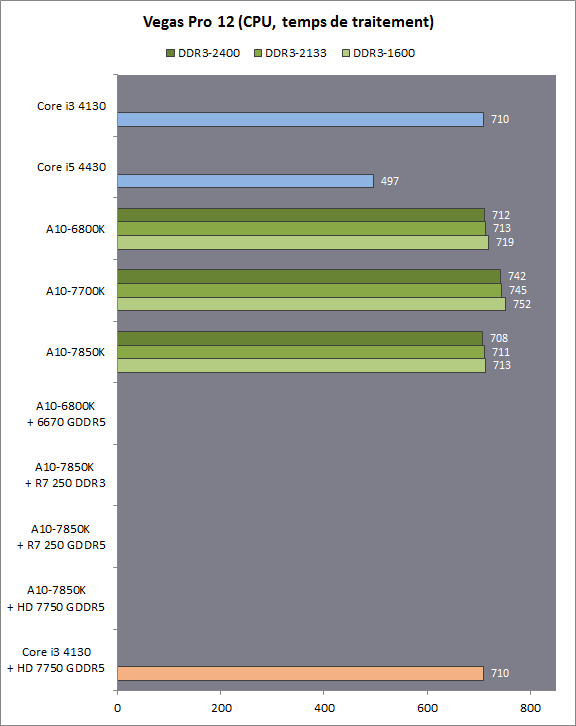 [ CPU ] [ OpenCL ] Commençons une fois n'est pas coutume chez Intel ou l'activation de l'OpenCL est bénéfique avec une réduction du temps de rendu de 35% sur le Core i3, et 55% sur le Core i5. Sur les APU, ces gains sont encore plus élevés avec 60% de gains. L'impact de l'ajout d'une carte graphique est plus mesuré et si l'on note des gains, en pratique ils sont assez réduits par rapport à ce que permet l'APU seule. Il n'y a que la combinaison Core i3 + HD 7750 qui profite significativement de la carte graphique additionnelle. Page 12 - GPU - Consommation Nous avons mesuré la consommation de nos configurations dans quatre scénarios : - Au repos - En lecture d'un fichier H.264 720p sous MPC-HC (toutes les accélérations matérielles sont activées) - Sous F1 2013 en 1080p medium - Sous Furmark La configuration Intel utilise une carte mère Gigabyte GA-Z87X-D3H que nous avions testée dans ce comparatif. Les configurations AMD sont testées en DDR3-2400 et les Intel en DDR3-1600 (voir pages précédentes) Voici les résultats obtenus, mesurés en watts à la prise 230V : 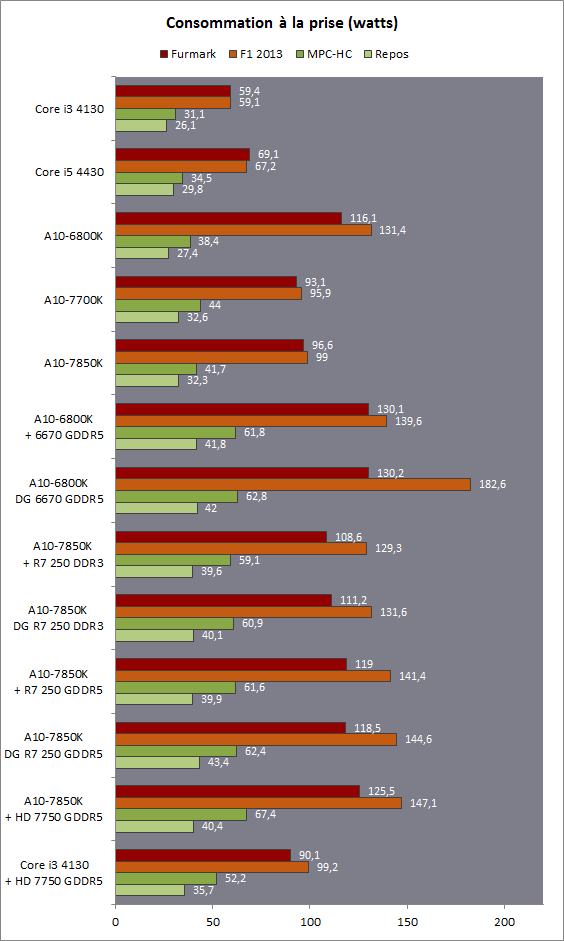 Mise à jour à 20h20 : Nous avons résolu le problème de consommation avec la plateforme Intel, liée à un bug entre les pilotes chipsets Intel et les pilotes graphiques Intel sur notre carte mère de test. Nous avons mis à jour en conséquence les scores de performances, ainsi que les scores de consommation. Si la plateforme FM2+ est efficace au repos, on note un écart de 5 watts tout de même par rapport à la génération précédente avec nos échantillons. La consommation en charge est particulièrement réduite, surtout en jeu ou l'on cumule une charge processeur et une charge graphique. Ici, l'écart est d'un peu plus de 30 watts entre l'A10-6800K et le nouvel A10-7850K. D'un point de vue efficacité énergétique, il est à noter que l'on reste assez proche en charge d'une configuration Core i3 avec HD 7750 pour l'APU haut de gamme Kaveri. Au repos et en lecture vidéo, la solution APU se démarque tout de même avec un très léger avantage. Page 13 - Conclusion ConclusionSur le papier, l'APU Kaveri a tout pour plaire. Sa hausse massive en termes de transistors (+85% !) lui permet d'accueillir de nombreuses nouveautés, que ce soit au niveau des curs x86 qui passent à une architecture Steamroller, de l'iGPU qui est désormais doté d'une architecture GCN plus à jour ou encore des interactions possibles entre toutes ces unités de calcul au travers HSA. La combinaison de ces nouveautés avec l'inauguration du nouveau procédé de gravure 28nm SHP de GlobalFoundries n'aura pas été sans embuches, et c'est avec du retard et des fréquences moins élevées que prévues que nous arrive Kaveri dans ses premières déclinaisons disponibles, les A10-7850K et A10-7700K. 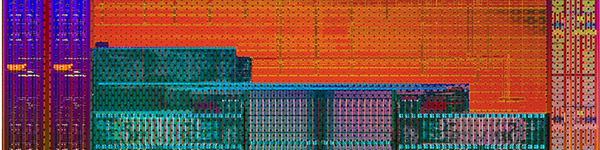 En pratique ces deux déclinaisons sont assez décevantes, notamment du côté du processeur puisque le gain d'IPC ne fait que compenser des fréquences réduites par rapport à leurs prédécesseurs ainsi qu'une latence mémoire en hausse notable. L'iGPU est pour sa part d'un tout autre niveau, avec notamment une efficacité énergétique bien meilleure, mais côté performances en jeu il reste nettement limité par la bande passante, si bien que la version 6 CU / 384 unités (A10-7700K) n'est pas très éloignée de la version 8 CU / 512 unités (A10-7850K). Même avec de la DDR3-2400, l'écart n'est au mieux que de 10% en jeu en faveur de ce dernier, et si il y a parfois des gains notables par rapport à leurs prédécesseurs, avec 23% sous BF4, on observe par moment des gains bien plus modestes. Ces gains ne permettent pas à ces APU de franchir un palier en termes de jouabilité par rapport aux APU Richland, il faudra donc se contenter de jeux à la charge graphique moyenne en 1080p et passer en 720p pour les jeux les plus gourmands. Reste la possibilité du Dual Graphics, qui permet de coupler l'iGPU avec une carte Radeon R7 240 ou 250, mais les résultats obtenus restent trop aléatoires pour que l'alternative soit encore prise au sérieux. L'autre intérêt du nouvel iGPU c'est bien entendu son utilisation au travers d'OpenCL (avec ou sans HSA) afin d'en faire une sorte de coprocesseur pour les calculs parallèles. A ce petit jeu GCN peut offrir des gains significatifs par rapport aux unités VLIW4 des Richland/Trinity, comme le montrent les gains enregistrés sous LuxMark ou Basemark CL. Reste bien entendu à transformer ce gain dans des tests plus pratiques, ce qui n'est pas encore forcément le cas même dans des applications tirant partie de l'OpenCL comme DxO Optics Pro ou Vegas Pro 12. En l'absence d'un écosystème logiciel plus fournit, et à défaut d'un usage spécifique en tirant pleinement partie, les 10 à 12 Compute Cores que met en avant AMD sur les A10-7850K et A10-7700K restent donc à prendre avec une bonne dose de conditionnel.  Pour en revenir à ces deux déclinaisons annoncées aux tarifs respectifs de 173$ et 152$, leur positionnement nous semble assez délicat étant donné leurs prestations. Bien que leur consommation pratique soit moindre en jeu, leur TDP de 95w ne les destinent pas à une intégration dans machines à un format très réduit, alors que leurs performances ne leur permettent pas d'avoir un avantage significatif sur une solution CPU + carte graphique (Athlon 750K + Radeon R7 250 par exemple), au contraire même. En l'état il nous semble plus opportun d'attendre l'A8-7600 qui dispose du même iGPU que l'A10-7700K mais de fréquence CPU réduites (3.3/3.8 GHz à 65W et 3.1/3.3 GHz à 45W), troquant au passage l'overclocking par le multiplicateur pour un TDP configurable et une note bien plus légère de 119$. Ce n'est d'ailleurs certainement pas un hasard si AMD a préféré fournir un échantillon de ce processeur plutôt que les A10, bien qu'il ne soit pas disponible au contraire de ces deux derniers. Au final, si l'APU est un pari, alors ce n'est probablement pas encore Kaveri - et surtout pas leur déclinaison A10 - qui permet à AMD de le gagner. Il ne s'agit toutefois que d'une étape et AMD compte bien continuer à faire progresser les APU tant au niveau matériel que logiciel. Côté logiciel, on attend pour cette année des avancées en terme de support OpenCL et HSA, mais aussi l'API Mantle, alors que côté matériel il faudra a priori attendre 2015 pour ce qui est des nouveautés ! Copyright © 1997-2026 HardWare.fr. Tous droits réservés. |