| |
| |
| Intel Core i7-4770K et i5-4670K : Haswell en test Processeurs Publié le Samedi 1er Juin 2013 par Guillaume Louel et Marc Prieur URL: /articles/897-1/intel-core-i7-4770k-i5-4670k-haswell-test.html Page 1 - Introduction Un peu plus d'une année après l'introduction des processeurs Core de troisième génération, plus connus sous le nom d'Ivy Bridge, Intel lance aujourd'hui sa quatrième génération de processeurs Core, également connus par leur nom de code, Haswell.  Un lancement qui s'effectue dans un contexte assez particulier pour le monde du PC, quelque peu chahuté par le succès massif des tablettes et par l'accueil timide réservé par une partie des consommateurs à Windows 8. Des tendances qui se traduisent par une baisse du marché global en unités pour l'année 2012 , et un début d'année 2013 préoccupant . Un contexte qui est d'autant plus préoccupant lorsque l'on regarde plus précisément le marché des processeurs de bureau - dont les Core i7-4770K et i5-4670K lancés aujourd'hui font partie. D'abord avec l'annonce du retrait d'Intel du marché des cartes mères de bureau, mais surtout avec les rumeurs indiquant que Broadwell, la prochaine déclinaison côté processeurs chez Intel sera réservé au marché BGA (processeur soudé sur la carte mère). Il faudra, selon toutes vraisemblances, attendre Skylake en 2015 pour voir arriver la relève en desktop - avec socket - d'Haswell. L'arrivée d'Haswell est donc particulièrement importante, y compris pour Intel qui, comme nous le verrons, à placé une emphase toute particulière sur les versions mobiles. Tick tock à deux vitesses ? 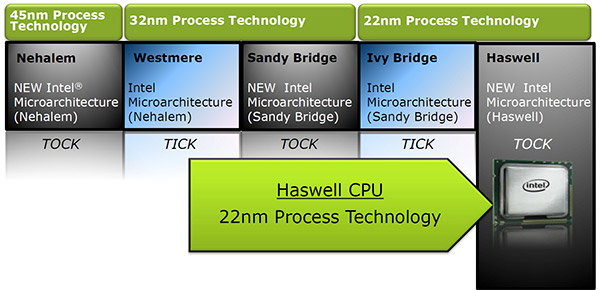 Depuis quelques années, Intel emploi une stratégie baptisée Tick Tock pour ses lancements de processeurs. Le principe est relativement simple, il s'agit de décaler les grands changements architecturaux côté processeurs des changements côté procédé de fabrication. Ainsi, tous les 24 mois environ (voir un peu plus), Intel lance un nouveau procédé de fabrication. A l'occasion de ce lancement, le processeur précédent est repris, adapté à la nouvelle finesse de gravure, et lancé sur ce nouveau process. On parle alors de "die shrink", même si les constructeurs en profitent généralement pour corriger certains problèmes ou améliorer certaines fonctionnalités. Intel parle alors de "Tick", c'était le cas l'année dernière pour le lancement d'Ivy Bridge sur le procédé de fabrication 22 nm. Ce processeur était en effet très proche de Sandy Bridge, gravé précédemment en 32nm, avec une amélioration surtout située du côté de la partie graphique du processeur. Pour cette année, le process 22nm étant mature, Intel propose des changements architecturaux un peu plus importants, c'est ce que propose Haswell, qualifié de "Tock". L'année prochaine cependant, le "Tick" Broadwell sera probablement réservé au BGA, et plus précisément aux processeurs basse consommation qui auront le plus à profiter de l'arrivée du 14nm. Si Intel confirme sur cette voie, la stratégie du Tick Tock va se retrouver scindée en deux avec d'un côté les puces "mobilité" qui profiteront des Tick et des Tock, et les plateformes LGA (desktop et portables "classiques") ne bénéficieront que des Tock. Haswell Revenons sur Haswell. Dans sa version pour Socket LGA, il embarquera dans sa version 4 curs associé à un iGPU à 20 EU (GT2) 1,4 milliards de transistors gravés en 22nm Tri-gate sur 177mm². Bizarrement, le chiffre annoncé par Intel pour les transistors est identique à celui d'Ivy Bridge, qui était par contre plus petit (160mm²). Le fondeur a-t-il pu compenser certains ajouts, comme les 4 EU supplémentaires, par d'autres optimisations ? A titre de comparaison, Sandy Bridge intégrait pour sa part 1,16 milliards de transistors sur 216mm². Sandy Bridge, Ivy Bridge et Haswell sont illustrés dans l'ordre ci-dessous :  Haswell reprend une grande partie les bases posées par Sandy Bridge et Ivy Bridge, et intègre notamment un contrôleur PCI-Express Gen3 16 lignes (pouvant adresser jusqu'à 3 périphériques) et un contrôleur mémoire DDR3 double canal, un iGPU intégré, trois niveaux de caches on-die dont le dernier est partagé avec l'iGPU via un ring bus, un Turbo Boost permettant de pousser les fréquences CPU et/ou iGPU dans la limite de l'enveloppe thermique globale. Les nouveautés sont toutefois nombreuses, tant au niveau des curs processeurs avec de nouvelles instructions et des améliorations de l'efficacité des curs, qu'au niveau de l'iGPU avec surtout l'arrivée d'une déclinaison GT3 deux fois plus puissante qui peut être associé à de la mémoire eDRAM placée au sein du packaging à côté du processeur afin d'être moins limité par la bande passante de la DDR3, on parle alors de GT3e. 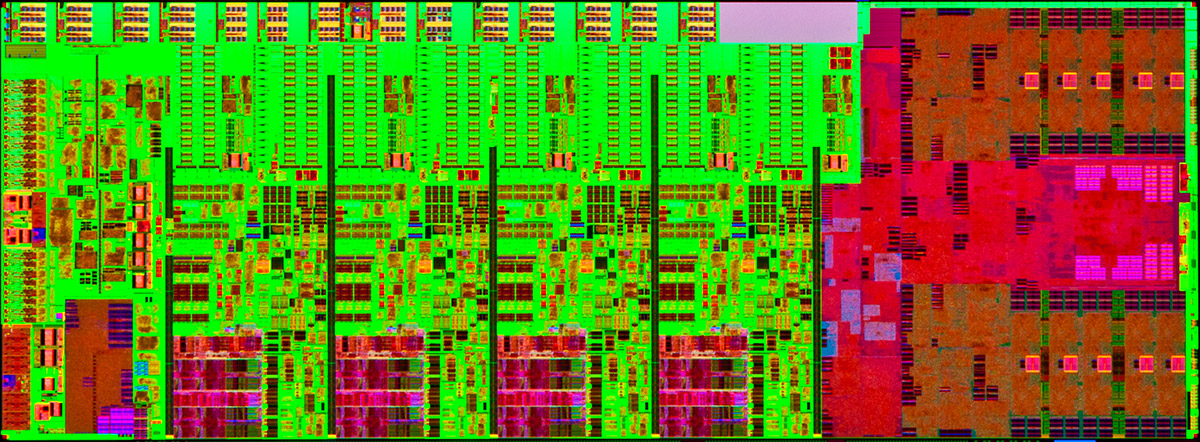 Un nouveau Socket, le LGA 1150, est nécessaire notamment du fait de l'intégration d'un régulateur de tension sur le processeur qui permet de simplifier l'étage d'alimentation carte mère et d'alimenter chaque partie du processeur de manière plus fine. Il est associé avec une nouvelle gamme de chipset, les Serie 8, qui permettent désormais de gérer jusqu'à 6 SATA 6 Gb /s et 6 USB 3.0 (contre 2 de chaque en Serie 7) et dont une version vient s'intégrer directement au sein du packaging pour les Ultrabook. Intel a également amélioré certaines fonctions d'overclocking, avec notamment la possibilité d'overclocker par le bus au-delà des quelques % laissés sur plate-forme LGA 1155, et mis le paquet sur les économies d'énergies lors que le processeur est inactif. Nous reviendrons d'ailleurs longuement sur les inquiétudes quant à l'incompatibilité que ces économies entraîneraient avec les alimentations, ainsi que sur un bug touchant l'USB 3.0 sur la première révision des chipsets Serie 8. Les nouvelles sont de ce côté plutôt bonnes ! Page 2 - Les améliorations du jeu d'instruction x86 : TSX et AVX2 Si le marketing parle souvent de "nouvelle architecture", dans la pratique les constructeurs capitalisent sur leurs acquis et font évoluer au fur et à mesure leurs architectures existantes. Dans le cas d'Haswell, on ne s'étonnera donc pas de retrouver un grand nombre de similarités, mais aussi des différences avec l'architecture de Sandy Bridge. Vous pouvez retrouver notre présentation de Sandy Bridge dans cet article pour rappel. Jeu d'instruction : TSX Avant d'entrer dans les détails sur les changements effectués au niveau de l'architecture, il faut noter qu'Intel a effectué deux additions assez importantes au jeu d'instruction d'Haswell. La première est baptisée TSX, une série d'instructions qui permettent d'accéder de manière différente à la mémoire et que nous avions détaillées l'année dernière. L'idée est d'ajouter un concept de transaction, qui sera peut être familier à ceux qui connaissent les bases de données : les instructions TSX permettent de marquer un bloc d'instruction comme atomique, c'est-à-dire dont l'exécution doit être réalisé en intégralité avant que quiconque d'autre touche à la mémoire utilisée par le bloc. Le problème que résout TSX est complexe, en effet les architectures processeurs modernes partagent un espace mémoire commun. Cela permet à tous les curs de travailler sur des données identiques, mais n'est pas sans inconvénient. Des problèmes de synchronisation, assez pénibles à débuguer pour les développeurs, arrivent assez vite. Imaginez deux curs qui lisent une donnée dans le but de la réécrire quelques secondes après : l'un va écraser le résultat de l'autre.  Des mécanismes de sémaphores ou d'exclusion mutelles (mutex ) ont donc été mis au point côté algorithmique, ce sont les développeurs qui doivent les implémenter dans leur code avec tous les problèmes que cela peut poser. TSX apporte deux réponses, avec tout d'abord le mode Hardware Lock Elision (HLE). Il s'agit de deux nouvelles instructions (XACQUIRE et XRELEASE) que l'on doit placer autour de blocs que l'on souhaite considérer comme atomiques. Attention cependant : le programmeur devra toujours implémenter manuellement son système de "lock", il sera cependant désormais accéléré et surveillé par le processeur.  Quel intérêt ? La réalité est que tous les locks ne sont pas utiles, ils sont juste là pour éviter les cas de collisions. En indiquant au processeur quels sont les blocs qui peuvent poser problème, Haswell pourra décider d'effectuer les opérations non mutuellement bloquantes en simultanée, le lock inutile étant alors omis ("elision" en anglais) sur Haswell. On notera que dans le cas ou une transaction est impossible (par exemple, le programmeur a oublié d'utiliser le lock a un endroit de son programme avant d'utiliser une ressource partagée, créant un conflit), Haswell exécutera le code atomique de manière non transactionnelle. HLE n'apporte donc pas de bénéfice direct côté sécurité ou facilité de programmation, mais permet d'améliorer les performances dans certains cas (les programmeurs tendant très souvent à abuser des locks lorsque cela n'est pas nécessaire) sur Haswell tout en laissant le code fonctionnel sur d'autres plateformes. L'autre mode de fonctionnement proposé par Intel est baptisé Restricted Transactional Memory (RTM). Il s'agit cette fois ci d'une implémentation complète de mémoire transactionnelle. Trois instructions sont disponibles, XBEGIN, XEND et XABORT.  Contrairement au mode HLE où le programmeur devait toujours créer ses propres locks, RTM permet de s'en passer et d'entourer simplement les blocs que l'on souhaite devenir atomiques : ils seront alors exécutés comme des transactions. Cependant, dans le cas où une transaction est impossible, le programmeur doit impérativement proposer un plan de secours. L'implémentation du plan de secours (une adresse où l'on reroute le programme) n'est pas optionnelle car de nombreuses choses peuvent faire rater une transaction. La première est le programmeur lui-même qui peut utiliser l'instruction XABORT pour l'arrêter. La seconde concerne des opérations à l'intérieur du bloc qui ne sont pas compatibles. Dans certains cas, mixer des instructions SSE et AVX (qui utilisent les registres XMM et YMM du processeur) peut causer un arrêt de la transaction. D'autres instructions sont définies dans la documentation d'Intel comme dépendant de l'implémentation, mais la question de la cohérence de la mémoire cache (seule la ligne est vérifiée et non la donnée précise) risque de générer un certain nombre d'arrêts également. Bien entendu si ces instructions supportées par le processeur sont disponibles manuellement en assembleur, dans la majorité des cas c'est le compilateur qui devra implémenter les instructions. Intel, en collaboration avec IBM et Sun avait définit un modèle mémoire transactionnel pour la norme C++11 qui sera implémenté entre autre par GCC (à partir de la version 4.7). Intel proposera également dans son compilateur C/C++ des intrinsèques (des fonctions C qui indiquent au compilateur d'utiliser une instruction assembleur donnée). En soit le mécanisme HLE pourrait être implémenté assez rapidement et de manière bénéfique pour les performances sur Haswell. Cependant en ce qui concerne RTM, il faut plus y voir un travail préparatoire. En attendant la standardisation, côté langages de programmation, d'extensions transactionnelles, l'utilisation de TSX se fera au cas par cas et il ne faudra pas espérer voir une généralisation rapide. D'autant plus qu'Intel est pour l'instant le seul à proposer une telle accélération, AMD ne s'étant pas encore prononcé sur le sujet. Ce travail préparatoire, qui résout un vrai problème concret se doit cependant d'être salué, même si l'on en observera pas forcément les résultats de suite. Attention, à l'instar de VT-d, Intel a eu la "bonne" idée de pas activer ces instructions TSX sur une partie de la gamme, notamment les processeurs K. Jeu d'instruction : AVX2 Si TSX est l'extension la plus originale du jeu d'instruction, AVX2 est la plus pragmatique. Annoncée dès 2011 par Intel, AVX2 ajoute un grand nombre d'instructions vectorielles, c'est-à-dire capables de s'appliquer à plusieurs données en simultanées (on parle d'instructions SIMD : Single Instruction, Multiple Data). 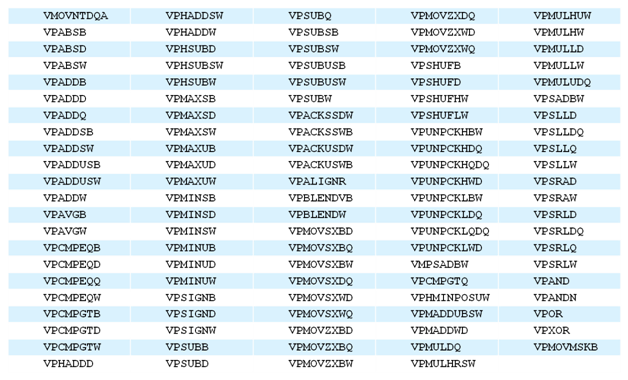 Une grande nouveauté d'AVX2 est l'arrivée d'instructions entières vectorielles 256 bits, Intel offre ainsi un pendant vectoriel aux instructions x86 classiques, ce qui peut être intéressant. 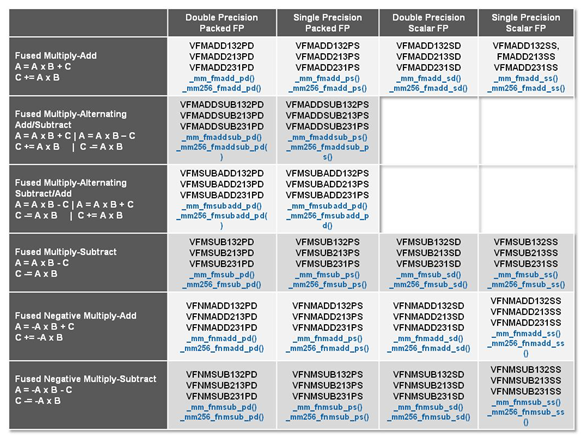 Un autre changement concerne l'ajout d'instructions dites FMA (Fused Multiply Add). Plutôt issues du monde GPU, ces opérations fusionnent une multiplication et une addition, c'est-à-dire une opération de la forme A = A x B + C. Celles utilisées par Intel sont de type FMA3 (trois opérandes) quand AMD avait lancé avec Bulldozer une implémentation FMA4 (D = A x B + C), avant de proposer également un FMA3 via Piledriver. Notez enfin que ces instructions sont accompagnées d'autres instructions essentielles permettant de charger dans des registres des données mémoires non adjacentes (instructions type gather). Page 3 - Les améliorations de l'architecture CPU Au-delà des extensions apportées au niveau du jeu d'instruction, l'architecture même d'Haswell évolue, à peu près à tous les niveaux de la puce. Nous allons donc passer en revue ces changements avec pour l'occasion quelques rappels sur le fonctionnement interne des processeurs modernes. Front End En amont du processeur, on retrouve toujours ce que l'on appelle le front-end, la partie du processeur qui s'occupe de récupérer et décoder les instructions x86 (macro-op) des programmes qui tournent sur nos machines. Ces dernières sont transformées pour rappel en micro-opérations (micro-op)par les décodeurs, des opérations compréhensibles directement par les unités d'exécution. Cela permet de garder un jeu d'instruction large et extensible (on l'a vu page précédente avec AVX2 et TSX), tout en proposant des unités d'instructions plus simples qui n'ont pas à comprendre toutes les variantes des dernières instructions à la mode. D'un point de vue externe, un processeur x86 est donc considéré comme un processeur de type CISC (Complex Instruction Set Computing) mais fonctionne, en interne, comme un processeur RISC (Reduced Instruction Set Computing). Le rôle du front-end est donc primordial pour une architecture qui dispose d'un très grand nombre d'instructions comme x86 (plus d'un millier !) aussi bien sur les performances que sur la consommation. 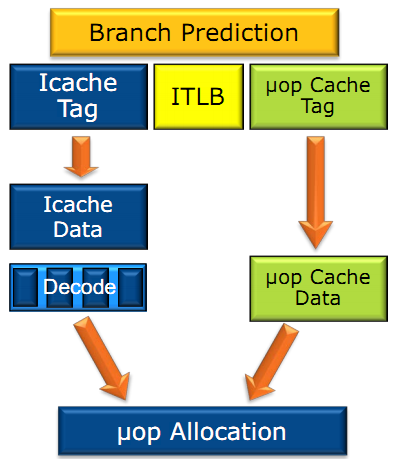 Dans les grandes lignes, on retrouve un front-end identique à celui de Sandy Bridge. Le cache d'instruction L1 de 32 Ko alimente cette partie du pipeline qui se termine toujours par quatre décodeurs. Le premier est capable de décoder des instructions plus complexes qui peuvent générer jusqu'à 4 micro-ops, tandis que les trois autres décodeurs s'occupent des instructions plus simples. En pratique, quatre micro-ops par cycle peuvent être générées par le front end (on parle d'architecture 4-way), avec un cas particulier pour les comparaisons et les sauts qui peuvent être fusionnés en une micro-op (ce qu'Intel appelle une fusion de macro-ops, deux instructions x86 transformées en une micro-op). Notez qu'un cache de 1500 micro-ops est également présent pour gérer le cas particulier des boucles, là encore il ne change pas par rapport à Sandy Bridge. Le code d'une boucle courte peut ainsi rester dans ce cache sans repasser par le début du front-end. Cela permet de gagner un peu en performance (pas besoin de décoder de nouveau, on gagne cinq étapes sur le pipeline) et surtout en consommation. Une fois décodées, les micro-ops sont placées dans une file de 56 instructions. Elle était sous Sandy Bridge partitionnée en deux files de 28 micro-ops, une par thread. Chaque cur gère pour rappel l'HyperThreading : deux files d'instructions se partagent les ressources des unités d'exécution que l'on verra ci-dessous. Depuis Ivy Bridge, cette file peut être utilisée entièrement par un seul des threads matériel si l'autre est inactif. Haswell reprend lui aussi ce changement qui permet de booster les performances sur les applications peu threadées. En parallèle à tout cela, le front-end contient également une unité de prédiction de branchements. Cette dernière évolue, même si Intel est assez peu loquace sur le sujet. On pense au minimum que les modifications apportées servent à gérer TSX. En effet les transactions peuvent être gérées côté processeur comme des branchements et profiter de tous les mécanismes déjà existants. Scheduler Les micro-ops à ce stade restent dans l'ordre de celui du programme original. Une série d'étapes arrive alors pour allouer, renommer et réordonnancer les instructions et leurs registres (des cases mémoires internes sur lesquelles s'appliquent les opérations, en opposition aux adresses mémoires qui font référence à des emplacements en RAM). Pour rappel, x86 dispose d'un nombre de registres accessibles pour les programmeurs en assembleur particulièrement limité : seulement 8 en mode 32 bits et 16 en mode x86-64. Un nombre restreint, certes, et qui limite les compilateurs, mais pour les processeurs la problématique est autre.  En effet comme nous l'avons vu, les unités d'exécution ne travaillent pas directement sur les instructions x86 (macro-ops) mais sur un format interne, les micro-ops. Libre donc auw processeurs d'utiliser plus de registres s'ils le souhaitent, et c'est exactement ce qu'ils font avec les PRF (Physical Register File). Il faut alors renommer/remapper les registres présents dans les instructions x86 vers ceux du processeur. On trouve ici un des premiers changements majeurs d'Haswell par rapport à Sandy Bridge sur le nombre de registres internes, on passe de 160 registres entiers et 144 registres AVX à 168 dans les deux cas pour Haswell. La taille du ROB (Reorder Buffer) qui trace l'ordre initial dans lequel les instructions devait être exécuté dans le programme original augmente également passant de 169 à 192 (en clair, on rallonge le nombre d'instructions qui pourront être mélangées par la suite) et les buffers pour les opérations de lecture passent de 64 à 72 entrées, et les buffers pour les opérations d'écriture passent de 36 à 42 entrées. On notera que c'est ici également qu'Intel effectue certaines optimisations, par exemple les instructions x86 MOV qui déplacent une donnée d'un registre vers un autre peuvent être supprimées. Cette optimisation avait déjà été ajoutée dans Ivy Bridge. Les instructions sont ensuite placées dans le scheduler qui va décider de l'ordre dans lequel seront exécutées les instructions. Son rôle est double, en premier lieu il se doit de déterminer les opérations non dépendantes. Par exemple si le programme original contient ces deux instructions :
La seconde addition ne pourra pas être exécutée avant que la première l'ait été, le scheduler doit donc prendre ceci en considération avant d'envoyer les instructions aux unités d'exécution. Le second problème est de s'assurer que les données nécessaires à la réalisation des opérations soient bel et bien présentes et à jour. Le contenu de A est il correct ? Vient-il d'une information chargée en mémoire (auquel cas, cette lecture est elle terminée ?) ou d'une autre instruction ? Le scheduler doit s'assurer que les instructions soient exécutables avant de se lancer, la taille de son buffer d'instructions (le nombre de micro-op disponible pour augmente légèrement passant de 54 entrées à 60. Unités d'exécutions Ces augmentations du côté du scheduler et de ses ressources associées ont pour but de compléter l'arrivée d'un changement assez majeur dans Haswell : l'ajout de deux nouveaux ports d'exécution (des files pour les unités d'exécution qui vont effectuer le calcul, un port regroupant plusieurs unités de calcul). Ce nombre fixé à 6 depuis la première architecture Core varie pour la première fois avec Haswell, passant à 8. On retrouve pour rappel deux grands types de ports, d'un côté ceux qui calculent, et de l'autre les unités qui travaillent avec la mémoire (lecture/écriture de données en mémoire). On commence d'abord par les ports de calcul. A l'image de Sandy Bridge, on retrouve toujours sur les ports 0 et 1 les "grosses" unités de calcul capables d'effectuer les opérations sur les entier, mais aussi sur les flottants via les unités AVX. Ces dernières sont bien entendues compatibles AVX2 et capables de traiter des opérandes sur 256 bits. 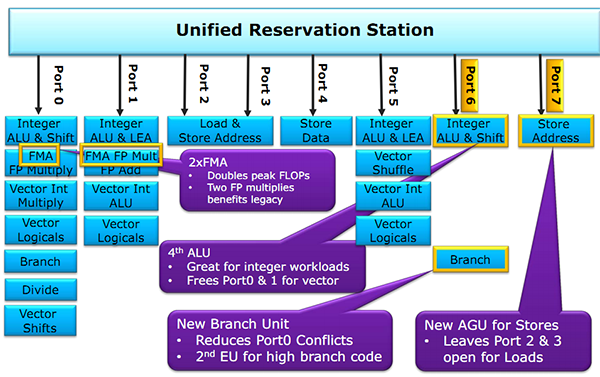 Sur le port 5, on retrouve toujours une unité de calcul sur les entiers simple, qui permet de garder les ports 0 et 1 libres pour les opérations les plus complexes. Intel dédouble ce port avec Haswell, le nouveau port 6 dispose lui aussi d'une unité. Notez que les branchements étaient gérés uniquement sur le port 5 auparavant, il y a désormais deux options, une sur le port 6 et l'autre sur le port 0. De quoi améliorer possiblement les performances dans certaines situations ou le port 5 se retrouvait précédemment bloqué. Du côté des ports mémoires, Sandy Bridge proposait deux ports capables d'effectuer des opérations de lecture et d'écritures en mémoire, et un troisième capable de stocker des données temporaires en cache L1 (port 4). Intel rajoute en sus au port 7 une unité dédiée uniquement aux écritures mémoire. Le choix peut paraitre contre intuitif étant donné que les applications contiennent en général une proportion plus importante de lectures mémoires que d'écritures. Cet ajout permet indirectement d'effectuer deux loads en plus d'un store ce qui représente tout de même un progrès important, tout en améliorant les très rares cas des applications qui reposent fortement sur les écritures mémoires. Mémoire cache Intel a apporté une série d'optimisations intéressantes du côté des systèmes de mémoire cache. Pour rappel, si le processeur à besoin de récupérer des données en mémoire, les ports "addresse" mentionnés plus haut vont interroger le cache de niveau 1 pour voir si l'information est déjà présente. Si ce n'est pas le cas, le cache de niveau 2 sera interrogé, puis le cache de niveau 3 jusqu'à aller en mémoire centrale si nécessaire. 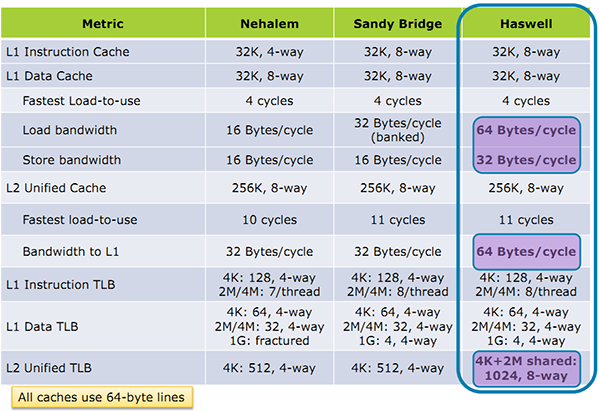 Concernant le cache de niveau 1, Intel annonce que son débit à été doublé. En pratique c'est même un peu mieux que cela. Chaque port peut en effet lire ou écrire 32 octets par cycles sur Haswell, contre 16 sur Sandy Bridge. Avec l'ajout du troisième port en écriture cependant, le cache est capable de lire 64 octets en simultanée d'une écriture de 32 octets et ce de manière continue. Un progrès particulièrement important. Si les données demandées ne se trouvent pas dans le cache L1, c'est le L2 qui est interrogé. Pas de changement sur la latence de ce dernier mais lui aussi voit son débit doubler de 32 à 64 octets par cycle. Ring bus, LLC Si les caches L1/L2 sont lies à chaque core, le cache L3 (également appelé LLC, Last Level Cache) est commun pour tous les curs sur Haswell comme cela était déjà le cas avec Sandy Bridge. Ces processeurs intègrent un bus de communication circulaire (ring bus) qui relie chaque core aux blocs de LLC (il est partitionné en 4 sur les versions de Haswell testées aujourd'hui). Ce ring bus relie également la partie chipset (System Agent) et le GPU intégré. 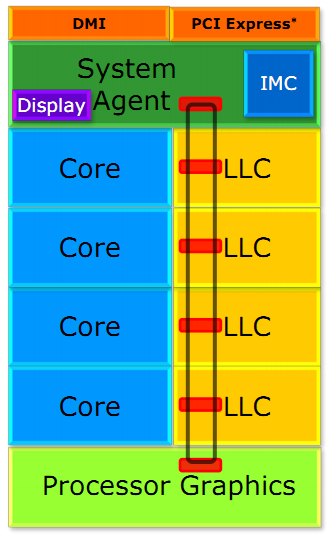 Un premier changement important concerne la fréquence du ring bus et du LLC. Ces derniers se retrouvent désormais dans un domaine de fréquence séparé des cores contrairement à Sandy Bridge. Outre l'aspect consommation, cela permet d'augmenter les performances des applications qui n'utilisent que le GPU et très peu le CPU. Seule conséquence négative, une légère augmentation de la latence du L3. Intel effectue plusieurs autres améliorations en rajoutant en séparant en deux les accès données et instructions dans le LLC pour améliorer la bande passante. Le débit théorique des LLC et du bus n'augmente pas, mais leur efficacité augmente. Notez enfin qu'en bout de chaine, le contrôleur mémoire (qui accède en dernier recours à la mémoire quand les caches ne proposent pas l'information demandée) a été optimisé pour mieux gérer les écritures simultanées avec un meilleur découplage des accès. Page 4 - Les améliorations côté GPU Si les améliorations du côté de l'architecture CPU sur Haswell étaient particulièrement nombreuses, du côté de l'IGP intégré les modifications sont un peu plus légères. Commençons d'abord par les API, on retrouve ici la gestion de DirectX 11.1, d'OpenGL 4.0 et d'OpenCL 1.2. Avec Haswell, Intel a décidé de rendre son architecture GPU un peu plus flexible. En plus des deux versions traditionnelles, GT2 et GT1 qui profitent au passage d'une hausse notable de leurs unités, Intel rajoute une version GT3 qui double le nombre d'unités d'exécution (passant de 20 à 40) : - GT1 : 10 Execution Units (6 sur IVB) - GT2 : 20 Execution Units (16 sur IVB) - GT3 : 40 Execution Units 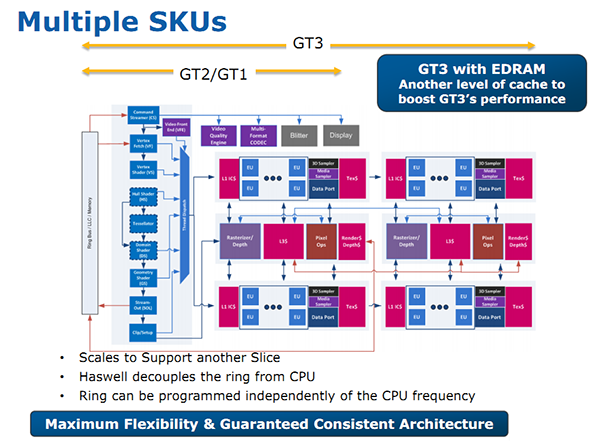 Comme indiqué précédemment, Intel a découplé la fréquence du ring bus de celle des curs processeurs, ce qui permet un peu plus de flexibilité pour le GPU lors des accès mémoire. Connecté au ring bus se trouve le gestionnaire de commandes, tout en haut du pipeline graphique. 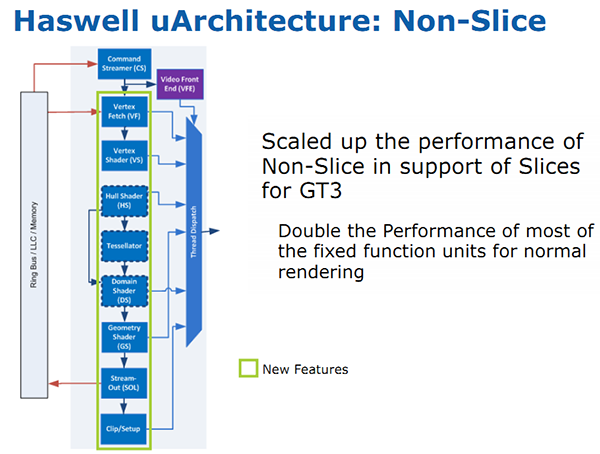 Sur ce dernier, Intel indique avoir ajouté un gestionnaire de ressource qui effectue ainsi un certain nombre de tâches qui étaient effectuée par le pilote précédemment (côté CPU). Les autres parties fixes du pipeline voient également une amélioration de leur performances, certaines étant doublées selon Intel qui ne précise cependant pas lesquelles. 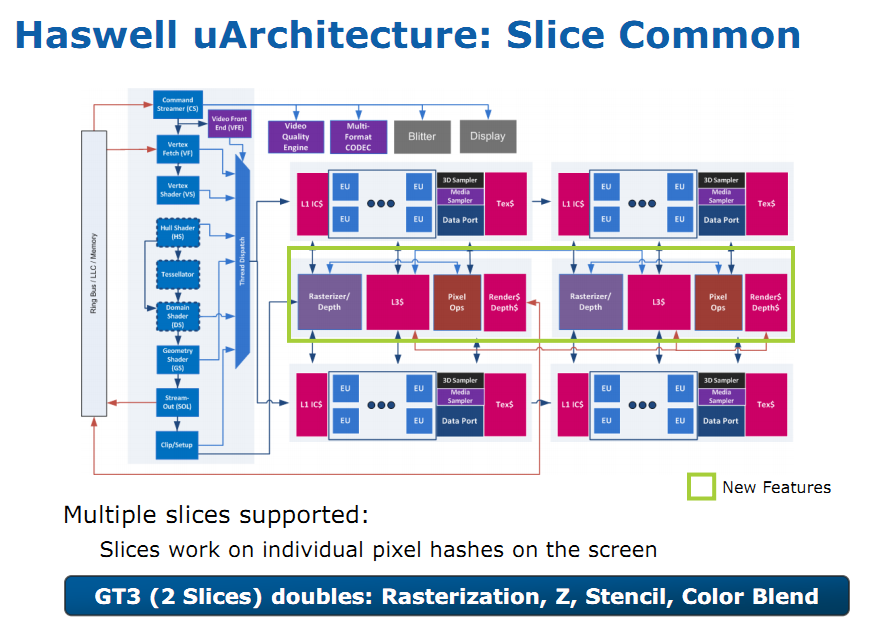 Pour ce qui s'agit des shaders, les diverses étapes de rendues peuvent dispatcher des threads vers le bloc de la puce qui continent les unités d'exécution, ce qu'Intel appelle désormais des slices. Dans le cas de GT3 ou deux slices sont présentes, chaque slice travaillera sur des pixels différents. Les slices disposent de rasterizers et de buffers Z, stencil et color blend indépendants. Le dernier changement majeur concerne les performances du sampler de textures dont le débit à été multiplié par quatre pour certains formats de textures (là encore, non précisés). eDRAM : (trop) peu de détails L'utilisation du nom LLC pour distinguer le cache de niveau trois est légèrement abusive dans Haswell, puisque ce dernier peut être configuré avec un cache de niveau 4. C'est l'une des nouveautés les plus originales, en effet Intel proposera des SKU utilisant GT3e, une version de GT3 accompagnée d'un puce d'eDRAM (de la mémoire DRAM embarquée) ajoutée au package. Sur ce point, Intel est pour le moins muet puisque le constructeur n'a rien confirmé sur les caractéristiques des puces intégrées. Il s'agit en fait de 128 Mo de mémoire interfacée en 512 bits offrant une bande passante de 50 Go /s dans chaque sens (100 Go /s au total). Gravée en 22nm, cette eDRAM mesure 84mm² pour une consommation de 0.5-1w au repos et 3.5-4.5 watts en charge (source ). 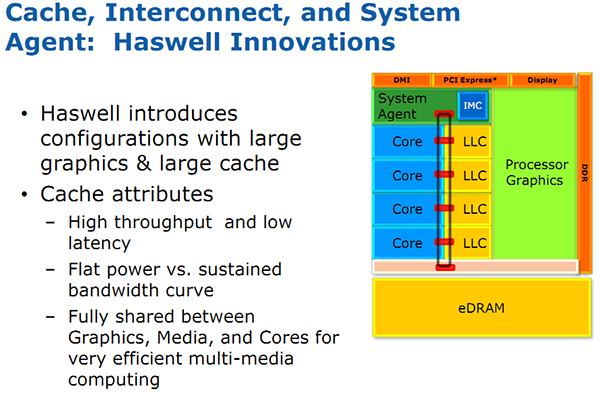 Sur ce rare schéma fourni par Intel on peut voir que le ring bus s'arrêterait sur un bloc d'interface qui vient s'insérer à la place du stop dévolu précédemment à l'IGP. On ne sait pas cependant s'il s'agit d'une simple illustration ou non, mais la logique voudrait que ce bloc serve d'interconnexion directe entre le GPU et l'eDRAM sans devoir passer par le ring bus. Notez cependant que l'eDRAM est considérée comme le système comme un cache de niveau 4, au dessus du LLC, et qu'il est donc directement accessible aux cores CPU, ce qui ne sera probablement pas sans avoir un impact sur les performances CPU dans certains benchs. Intel indique que le cache est complètement partagé entre CPU et IGP, même si l'on ne sait pas quelle sera le niveau de priorité respectifs qui leur seront donnés. Si Intel reste peut loquace sur le sujet, c'est avant tout parce que ces versions se retrouveront exclusivement dans des puces au format BGA (directement soudées sur la carte mère), que ce soit dans le but d'être intégrées dans des PC portables (plutôt haut de gamme) ou alors dans des machines tout en un (type iMac). On ne peut donc qu'être déçu de ne pas avoir plus de détails sur le sujet pour l'instant, on peut penser que cela ne durera pas forcément longtemps et qu'Intel devrait annoncer plus de détails, par exemple autour du lancement d'un de ses partenaires. QuickSync Au sein du GPU, on retrouve toujours QuickSync, la technologie de décodage et encodage vidéo d'Intel. Il s'agit de blocs d'unités fixes qui prennent en charge une grande partie des tâches de décodage et d'encodage vidéo et qui peuvent également envoyer des tâches de traitements vidéo sur les unités d'exécution (par exemple pour réduire le bruit ou désentrelacer les vidéos).  Du côté des décodeurs, Intel ajoute la gestion du format MJPEG surtout utilisé dans les appareils d'entrée de gamme. Côté encodage, deux nouveaux formats à noter, la première est l'arrivée du MPEG-2 (le standard utilisé sur les DVD) mais aussi celle du SVC, une version "scalable" du codec AVC/H.264. On retrouve avec SVC un container prévu pour le streaming de vidéo, et surtout au niveau du contenu, la possibilité de dégrader progressivement la qualité en fonction de la bande passante. L'autre nouveauté notable concerne la gestion du 4K à tous les niveaux, aussi bien niveau décodage, encodage qu'affichage.  Côté post processing, Intel étend les possibilités offertes avec l'ajout de nouveaux filtres, les plus notables sont la conversion de frame rate et la stabilisation d'images. Qu'il s'agisse des filtres ou des codecs, Intel expose toutes les possibilités de QuickSync pour les développeurs au sein de son MediaSDK. Il est à noter qu'Intel dit proposer un peu plus d'options pour les développeurs dans le but d'améliorer la qualité, ce sur quoi nous reviendrons en pratique. Autre point, Intel dit travailler avec différents acteurs de l'open source, notamment les développeurs de HandBrake pour proposer un support de QuickSync dans leur logiciel. Une licence spécifique Open Source est proposée par le constructeur pour la version 2013 de son MediaSDK, un bon point. Gestion des écrans La gestion des écrans sur les plateformes précédentes d'Intel était relativement complexe puisque le signal vidéo était retransmis du processeur vers le chipset par un lien FDI, le chipset disposant d'une gestion interne. Tout ceci évolue dans Haswell, le processeur propose désormais quatre brins DDI qui pourront être utilisés pour configurer trois écrans au maximum. Il est possible de mutualiser les brins en effet pour atteindre des résolutions plus élevées (comme le support du 4k). Ces brins DDI sont uniquement utilisables pour des sorties numériques, à savoir DisplayPort, HDMI et DVI. En parallèle, Intel utilise toujours un brin FDI qui est relié au chipset, ce brin étant utilisé pour une éventuelle sortie VGA (analogique) gérée directement par le chipset.  Côté nombre d'écrans, Haswell dispose de trois "Display Pipe" qui pourront être utilisés en simultanée pour piloter trois écrans physiques. Il est désormais possible en effet d'utiliser trois sorties en simultanée, y compris de mixer VGA et deux sorties numériques, ou trois sorties numériques. Sur ce dernier point, la datasheet d'Intel est quelque peu cryptique indiquant que toutes les permutations sont autorisées, sauf un mélange de HDMI et de DVI. Ce que nous en comprenons, c'est que pour utiliser trois sorties numériques, au minimum l'une d'entre elle doit être de type DisplayPort. Côté résolutions maximales, on peut atteindre 3840x2160 en 60Hz en DisplayPort, et 4096x2304 en 24 Hz (4k) et 2560x1600 à 60 Hz en HDMI/DVI. Notez enfin que le contrôleur HD Audio gère deux streams audio simultanés qui peuvent être assignés sur n'importe lequel des trois ports DDI. Page 5 - LGA 1150, Régulateur de tension intégré LGA 1150, Régulateur de tension intégréContrairement à ce qui s'est passé avec le "Tick" Ivy Bridge, ce "Tock" Haswell n'est pas compatible avec le Socket précédent LGA 1155. Un nouveau Socket, le LGA 1150, fait donc son apparition. Les processeurs sont toujours de la même taille, 37.5*37.5mm, mais les détrompeurs sont placés différemment afin d'empêcher tout insertion d'un processeur dans un Socket qui ne lui est pas adapté.  La mauvaise nouvelle, c'est donc qu'il faudra changer de carte mère pour passer à Haswell, aucune rétrocompatibilité n'étant assurée si ce n'est celle des refroidissements : les fixations les LGA 1150 sont toujours les mêmes que sur LGA 1155 et 1156.  Pourquoi (encore) un nouveau Socket ? Intel a procédé avec Haswell à une simplification importante de l'étage d'alimentation du côté de la carte mère. Auparavant, six tensions principales (il y'a également VPLL et VCCIO) étaient fournies par la carte mère au processeur : - VCC pour les curs CPU, le cache LLC et le bus d'interconnexion - VDDQ qui transite par le CPU pour alimenter la DDR3 - VCCPLL pour l'alimentation de la PLL - VCCSA pour le System Agent (contrôleur mémoire, DMI, PCI-E, unité d'affichage) - VCCAXG pour l'iGPU - VCCIO pour l'alimentation des I/O Les trois tensions principales, VCC, VCCSA et VCCAXG sont fournies par l'étage d'alimentation de la carte mère depuis l'ATX12V, avec un nombre de phase défini pour chacune de ses tensions. En entrée de gamme on avait par exemple respectivement 4/1/1 phases pour VCC/VCCSA/VAXG.  Sur LGA 1150, les choses évoluent puisque la carte mère n'a plus qu'à transformer l'ATX12V en une seule tension, VCCIN (1.8V par défaut), avec en sus VDDQ qui provient d'un étage d'alimentation connecté à la prise ATX principale. Cela simplifie donc l'étage d'alimentation de la carte mère, et son efficacité est accrue puisque toutes les phases sont communes. Si vous n'utilisez pas l'iGPU par exemple, vous n'aurez plus une phase qui ne sert à rien. 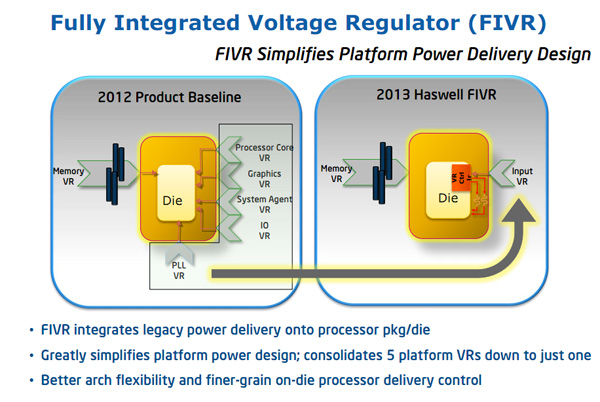  Pour autant, les différents éléments du CPU ne sont pas alimentés avec une seule tension, ce qui serait contre-productif du point de vue du rendement énergétique. Intel a en effet intégré directement au sein de Haswell un régulateur de tension intégré (IVR), ce qui lui permet au processeur d'avoir un meilleur contrôle des tensions afin d'optimiser afin d'améliorer encore l'efficacité énergétique. Les 1.8V du VCCIN sont ainsi transformées en 5 tensions, avec pour principale nouveauté une tension supplémentaire pour le Ring bus, le bus en anneau qui interconnecte les différentes parties du processeur devant accéder au cache de dernier niveau et celui-ci. Ce régulateur de tension est assez flexible et il est possible de faire dévier chacune des tensions de sa valeur par défaut afin d'augmenter ou de diminuer l'alimentation du processeur, pour l'overclocking ou l'undervolting par exemple.  Cette modification de tension peut-être obtenu de plusieurs façon, que ce soit via une tension fixe selon la fréquence, via un décalage (offset) par rapport à la tension par défaut ou même une tension plus importante uniquement lorsque le processeur fonctionne aux fréquences overclockées. Le fait d'avoir un IVR intégré permettra à tous les constructeurs de cartes mères d'offrir les mêmes possibilités de réglage sur la tension du processeur, ce qui sera par contre un point de moins pour distinguer les modèles entre-eux. Il est noter qu'Intel ne donne aucune indication sur le rendement de cet IVR. Page 6 - Overclocking plus libre sur K, plus strict par ailleurs Overclocking plus libre sur K, plus strict par ailleursIntel profite de ce changement de plate-forme pour introduite une plus grande liberté pour l'overclocking qui avait déjà fait son apparition sur LGA 2011. Pour rappel, sur LGA1155 et LGA1156 les différentes fréquences internes du processeur sont obtenues en appliquant des coefficients multiplicateurs à une fréquence de base, la DMICLK (où fréquence du bus, également appelée BCLK). Seul problème, cette DMICLK est directement liée aux fréquences des bus DMI (qui relient le processeur au chipset) et PCI-Express, qui sont très sensibles à toute modification. Au-delà de +/- 5-7%, la stabilité de la machine est compromise ce qui interdit tout overclocking par ce biais, il fallait donc se contenter jusqu'alors de jouer sur les coefficients multiplicateurs.  Désormais des ratios DMICLK:PEG/DMI permettront de maintenir la fréquence des bus DMI et PCI-E dans un intervalle de +/- 5-7% par rapport à leur fréquence initiale tout en augmentant le DMICLK. Les ratios sont de 5:5, 5:4 et 5:3, ce qui permettra d'utiliser des fréquences de bus de 100, 125 et 167 MHz, avec pour chacune de ses fréquences une marge de 5 à 7% supplémentaire. Le coefficient multiplicateur maximal des curs passe de plus de x59 sur Sandy Bridge et x63 sur Ivy Bridge à x80 sur Haswell, de quoi attendre 8 GHz sans toucher au bus et même 13,36 GHz avec une DMICLK à 167 MHz. Si les overclockeurs de l'extrême apprécieront, les autres resteront de marbre. Enfin la mémoire DDR3 voit ses ratios étendus puisqu'il est officiellement possible d'aller jusqu'en DDR3-2933 par saut de 200 ou 233 Hz, contre DDR3-2133 sur SNB et DDR3-2667 sur IVB. En pratique toutefois les cartes mères proposaient ce mode et même jusqu'en DDR3-3200 sur LGA 1155, c'est également le cas en LGA 1150. 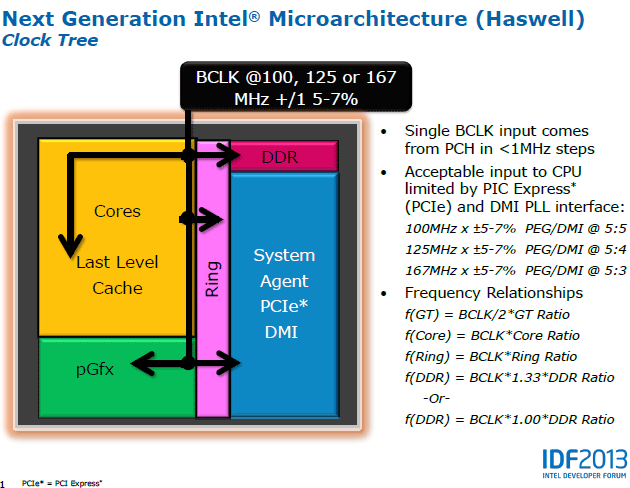 Revenons-en à l'overclocking par le bus. Quel est son utilité ? Du côté des performances pures, aucune, comme nous l'avions vu lors du test sur la plate-forme LGA 2011 il n'y a pas vraiment de gain à attendre d'une DMICLK plus importante si les fréquences internes aux processeurs qui en découlent restent identiques : nous ne sommes plus à l'époque du Socket 775 avec une vitesse du bus qui joue sur la vitesse d'interconnexion avec le contrôleur mémoire qui est essentielle pour les performances. Sur les processeurs K, les différents coefficient appliqué à la DMICLK pour ces fréquences internes étant modifiables, l'intérêt est donc nul, si ce n'est à donner un peu de grain à moudre aux overclockeurs de l'extrême. L'intérêt d'overclocker par le bus c'est bien évidemment de pouvoir overclocker un processeur malgré un coefficient multiplicateur bloqué, comme c'est le cas sur les processeurs non K. Est-ce enfin la possibilité d'overclocker les processeurs d'entrée de gamme, qui a disparue depuis le LGA 1155 ? Que nenni ! Toute tentative d'utiliser les ratios DMICLK:PEG/DMI de notre part s'est soldée par un échec, et on est donc limité par le bus comme sur LGA 1155 à un overclocking de 5-7% par la DMICLK. Mais il ne s'agit là que de la première déception pour les processeurs non K. En effet, sur Sandy Bridge et Ivy Bridge, Intel laissait tout de même une petite liberté d'overclocking, il était possible d'ajouter 400 MHz aux fréquences Turbo. Sur Haswell, il n'est désormais plus possible que d'aligner la fréquence du Turbo avec 4 curs actifs sur celle du Turbo avec 1 curs actif. Voici en pratique ce que cela donne sur 2 processeurs non K de chaque gamme :  On perd donc entre 200 et 400 MHz selon le niveau de Turbo. Côté overclocking c'est donc la douche froide pour Haswell, puisque les nouveautés apportées pour les processeurs K ne sont pas vraiment utiles pour des overclockings utilisables sur des machines de tous les jours, et que pour les autres processeurs l'overclocking est plus limité qu'auparavant ! Reste à savoir si les Haswell montent plus haut en fréquence, nous y reviendrons plus loin. Page 7 - Chipsets Intel Serie 8, Lynx Point et Lynx Point-LP Chipsets Intel Serie 8 (Lynx Point)  Comme d'habitude, Intel lance en même temps que les Intel Core de 4è génération une nouvelle ligne de chipset, les Serie 8 (nom de code Lynx Point). Les principales améliorations se situent au niveau des ports SATA 6 Gb/s et USB 3.0, puisqu'on passe de 4 à 6 ports USB 3.0 et de 2 à 6 ports SATA 6 Gb /s (le nombre total de SATA restant à 6). 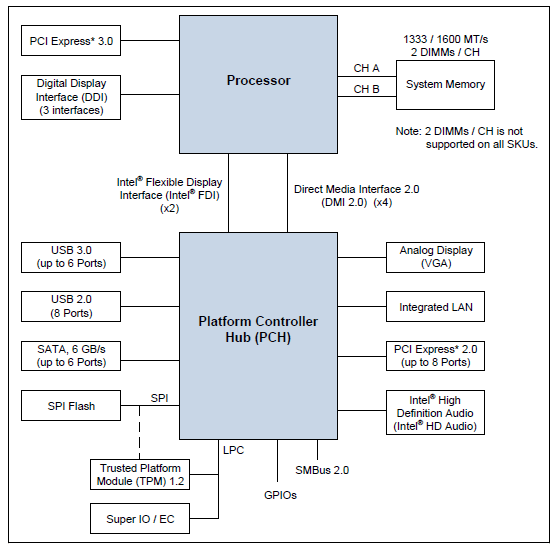 Attention il y'a toutefois une subtilité, c'est ce que Intel nomme I/O Port Flexibility ci-dessus : 2 ports SATA 6 Gb /s et 2 ports USB 3.0 partagent des ressources avec des lignes PCI-Express. Intel précise que le nombre total de PCIe, SATA 6 Gb/s et USB 3.0 peut atteindre 18, soit 6+6+6, ce qui signifierait que seules 2 lignes PCI-Express en sont plus fonctionnelles si on utilise l'intégralité des ports additionnels. Le bus d'interconnexion avec le processeur reste un DMI Gen2 x4, offrant une bande passante de 1 Go /s dans chaque sens qui n'est pas assez large pour permettre une pleine utilisation de tous les ports proposés en simultanés, il est vraiment dommage que Intel ne soit pas passé en Gen3 à ce niveau. On notera par ailleurs la disparition de la gestion du PCI des chipsets Intel Serie 8, il faudra donc passer obligatoirement par une puce PCI vers PCI-Express si nécessaire, alors que la gestion des sorties vidéos numériques passe du chipset au processeur.  Lynx Point est gravé en 32nm, contre 65nm pour les chipsets Serie 7, ce qui permet par exemple de passer le TDP des versions mobiles de 4,1 à 2,7 watts. Il sera décliné en de multiples versions intégrant plus ou moins de fonctionnalités selon qu'Intel vise le grand public, les professionnels, le marché desktop ou mobile : - Intel Q87 Express - Intel Q85 Express - Intel H87 Express - Intel Z87 Express - Intel B85 Express - Intel QM87 Express - Intel HM87 Express - Intel HM86 Express 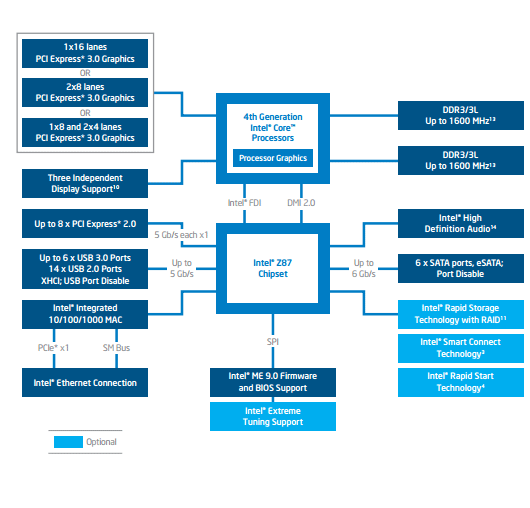 [ Z87 Express ] [ H87 Express ] [ B85 Express ] Les chipsets grand public sont les Z87 Express, H87 Express et B85 Express. Le Z87 Express est le plus complet. Passer sur un H87 Express bloque la possibilité d'overclocker le CPU, et les lignes PCI Express Gen3 de ce dernier ne peuvent plus être réparties entre plusieurs ports (en x8/x8 ou en x8/x4/x4). Le B85 Express perd par rapport à ces deux chipsets la gestion du RAID et du SRT, et si il conserve 6 SATA seuls 4 sont en 6 Gb /s. Le nombre de ports USB 3.0 passe également de 6 à 4. Lynx Point-LP : le chipset dans le CPUPour les processeurs Haswell qui viseront les plus bas TDP et destinés aux Ultrabook (Haswell-ULT), Intel propose une autre déclinaison de Lynx Point qui a la particularité d'être intégré au sein du même packaging que le processeur ! Les puces restent séparées, en haut le CPU et en bas le PCH sur la photo, une première étape avant on l'imagine une intégration totale dans une ou deux générations.  Cette déclinaison diffère légèrement des autres Lynx Point en termes de fonctionnalités. Le nombre de ports USB est ainsi revu à la baisse (8 USB 2.0 et 4 USB 3.0), tout comme les SATA (4 SATA dont 3 SATA 6 Gb/s). La gestion du VGA est abandonnée, par contre Intel pousse l'intégration plus loin en ajoutant par exemple un contrôleur SDIO (pour les cartes SD) et un codec HD Audio ou encore deux contrôleurs I²C et UART, ce qui permettra de se passer de puces additionnelles à ce niveau. 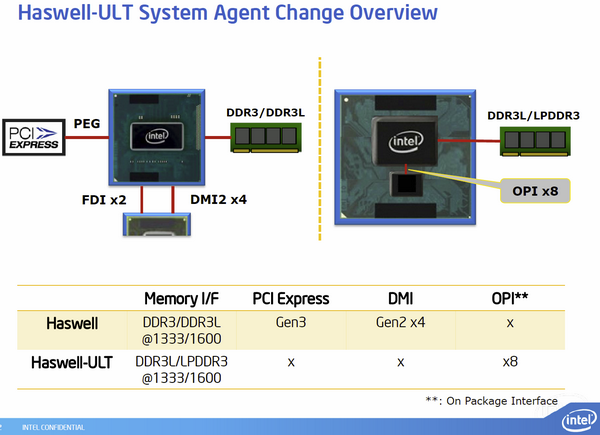 Le lien entre le processeur et le chipset n'est plus assuré par le traditionnel bus DMI Gen2 x4 à 1 Go /s dans chaque sens mais par un bus appelé OPI x8 (pour On Package Interface) dont on imagine la bande passante doublée. Il faut par contre noter que le processeur ne dispose pas d'une interface PCI-Express Gen3 contrairement aux autres versions : Intel bloque donc la possibilité d'associer Haswell-ULT avec un GPU externe, de quoi faire plaisir à AMD et Nvidia même si ce n'est pas totalement illogique. Intel profite de cette intégration plus poussée entre chipset et processeur. Premièrement, l'enveloppe de consommation n'est plus uniquement pour le processeur mais comprends également le chipset. Le processeur réduira donc sa vitesse en charge si la consommation cumulée des deux vient à dépasser le TDP. Au niveau de la veille système maintenant, les Haswell ULT intègrent au niveau de la plate-forme modes d'économies d'énergie S0ix. A l'heure actuelle on passe généralement du mode ACPI S0 (actif) au mode S3 (Suspend to Ram, la vielle simple), après plus ou moins longtemps selon les réglages de l'OS ou en fermant par exemple l'ordinateur portable. Intel introduit de nouveaux sous-modes S0ix qui permettront d'abaisser la consommation d'énergie pour un ordinateur au repos sans qu'il soit pour autant en mode veille. Toujours dans le but d'économiser de l'énergie, les Haswell ULT intègre au niveau du processeur seul de nouveaux modes d'économies d'énergies, les C-States. En C0 le processeur est complètement actif, puis il passe dans des modes de plus en plus économes mais desquels il est plus "long" de ressortir. Sur Haswell ULT, Trois nouveaux états, C8, C9 et C10 seraient ainsi ajoutés par Intel avec la particularité pour la première fois de pouvoir éteindre la BCLK externe cadencée par défaut à 100 MHz pour économiser encore plus d'énergie au niveau de la plateforme. Une nouvelle horloge additionnelle fonctionnant à 24 MHz serait alors ajoutée : elle servira à recalibrer la BCLK à 100 MHz lorsque le processeur deviendra de nouveau actif. Intel annonce que la combinaison de ces nouveautés devrait permet de baisser d'environ 16x la consommation des Haswell-ULT lorsque le PC est inactif sans être en veille par rapport aux Core de 3è génération. Page 8 - Les gammes Haswell Les gammes Haswell  Intel va décliner les Intel Core de 4è génération sous de nombreuses formes. Pour PC de bureau, on a ainsi droit aux gammes suivantes : - "K" : LGA 1150, 4 curs + iGPU GT2, TDP 84 watts - "Classique" : LGA1150, 4 curs + iGPU GT2, TDP 84 watts - S : LGA 1150, 4 curs + iGPU GT2, TDP 65 watts - T : LGA 1150, 2-4 curs + iGPU GT2, TDP 35-45 watts - R : BGA, 4 curs + iGPU GT3e, TDP 65 watts En attendant la rentrée, le seul processeur à 2 curs est l'i5-4570T, il s'agit probablement d'une version 4 curs avec 2 désactivés . La gamme est assez standard si ce n'est l'apparition d'une nouvelle série R au format BGA (soudée à la carte mère), qui intègre la version la plus musclée de l'iGPU. En dehors de cette série, il faudra se contenter du GT2. Notez que pour les versions boites, comme les LGA 2011 les processeurs K pourront désormais être vendus sans ventirad Intel. Une bonne idée sur le principe, mais pour le moment le prix des deux versions semble identique.  Côté mobile on retrouve d'autres gammes : - "H" : 4 curs + iGPU GT3e, TDP 37 et 47 watts - "M" : 2 à 4 curs + iGPU GT2, TDP 37, 47 et 57 watts - "U" : 2 curs + iGPU GT3 + Lynx Point LP, TDP 15 watts - "Y" : 2 curs + iGPU GT3 + Lynx Point LP, TDP 11.5 watts, SDP 6 watts Cette fois les versions 2 coeurs sont déjà là. Sur les versions U et Y, le TDP comprends désormais à la fois CPU et PCH (chipset), on passe donc de 17+3 watts sur les Ivy Bridge U à 15 watts sur les Haswell U côté TDP. Sur les Y le SDP (consommation dans des scénarios plus légers que le TDP) passe de 7+3 watts à 6 watts. Des ensembles à 28W sont également prévus, on ne sait pas encore dans quelle gamme.  Côté iGPU il faut noter que le GT2 prendra la dénomination de HD graphics 4600/4400/4200 (selon sa fréquence), le GT3 sera un HD graphics 5000 ou un Iris graphics 5100 (idem, la fréquence du 5000 étant moindre puisque le TDP global des processeurs l'utilisant plus réduit) et le GT3e est l'Iris Pro graphics 5200. Voici ci-dessous le détail des différents processeurs lancés ce jour tel donné par Intel, attention les gammes ne sont que partielles en attendant le lancement d'autres déclinaisons. On notera qu'Intel a toujours la mauvaise idée de ne pas proposer VT-D sur les processeurs K, et qu'en sus les instructions TSX-NI ne sont pas supportées sur PC de bureau par les K mais aussi les R et les Core i5-4430 et 4430S. Ce Core i5-4430 , similaire au 4570 mais avec une fréquence de 3 GHz et un Turbo à 3.2 GHz, est d'ailleurs bizarrement absent des présentations officielles, tout comme l'i5-4430S (65W, 2.7 à 3.2 GHz). A noter que sur les gamme Desktop, Intel en profite pour faire grimper de 7 à 8$ le prix des Haswell par rapport aux Ivy Bridge, à une exception près, le Core i5-4670K qui voit carrément son prix augmenter de 17$ (+7,6%) par rapport au Core i5-3570K. 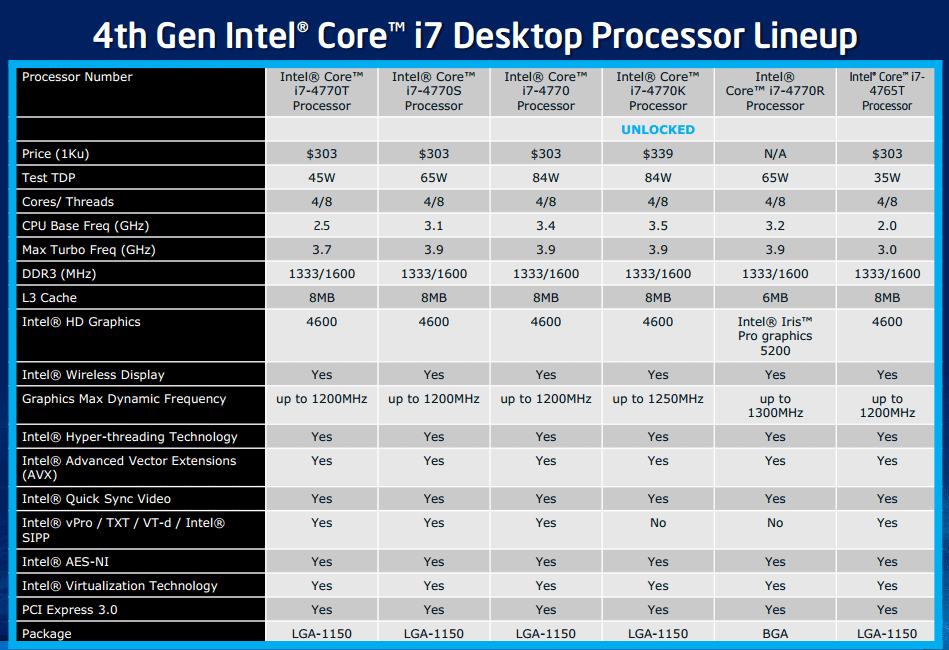 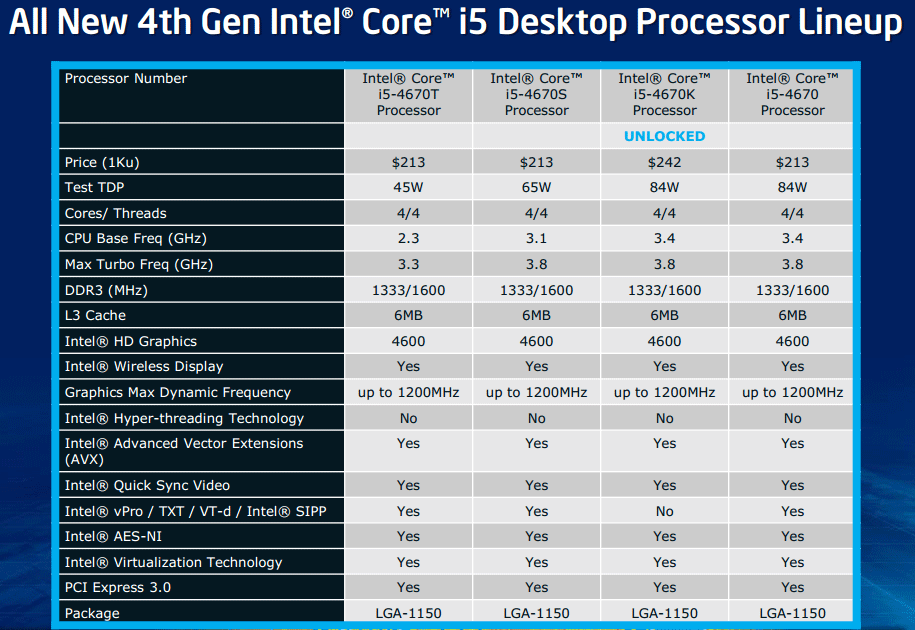 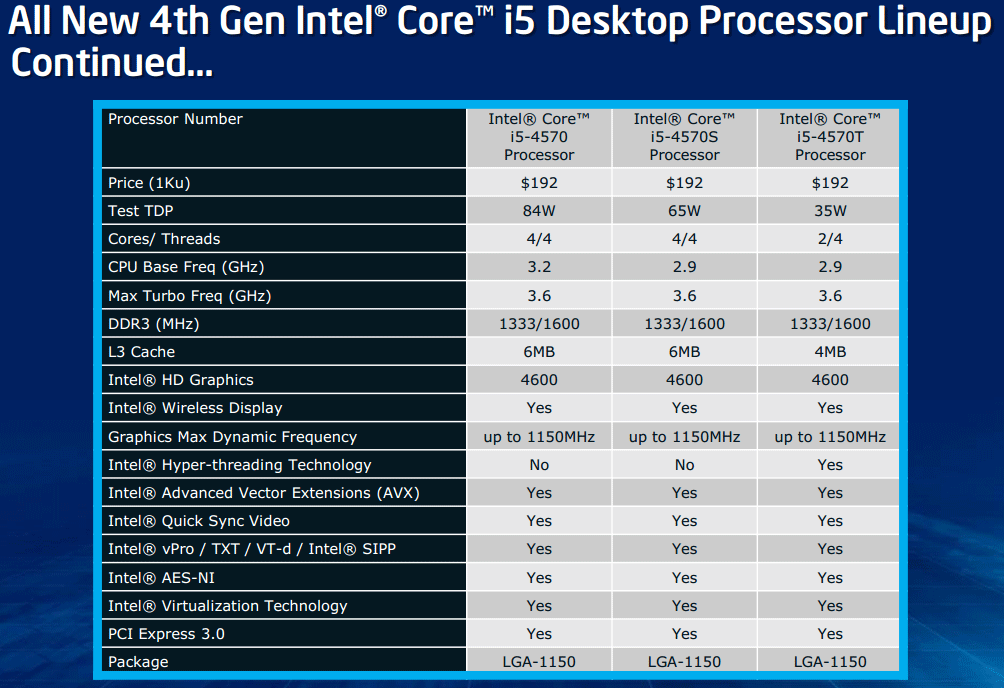 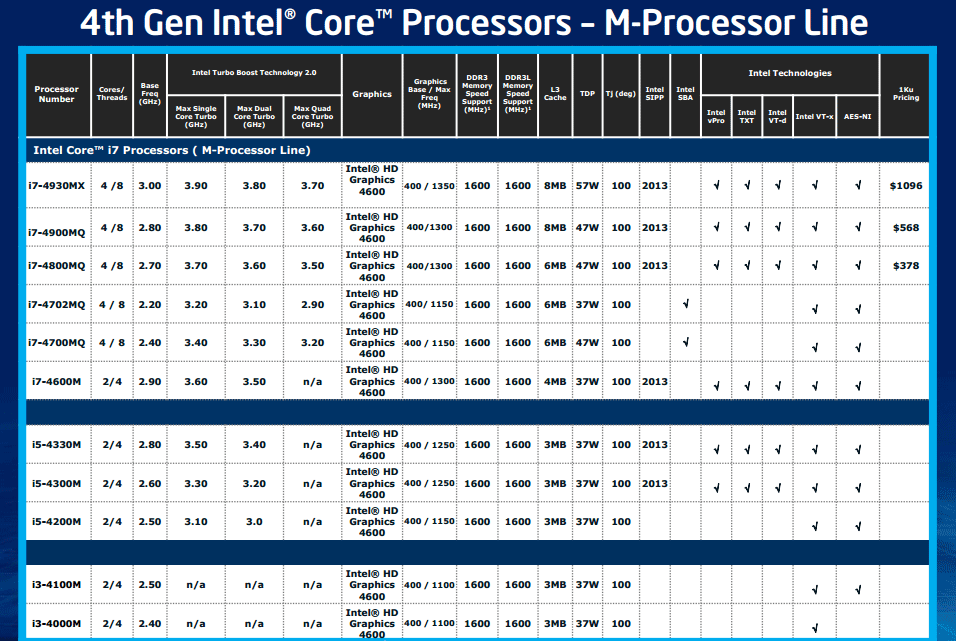 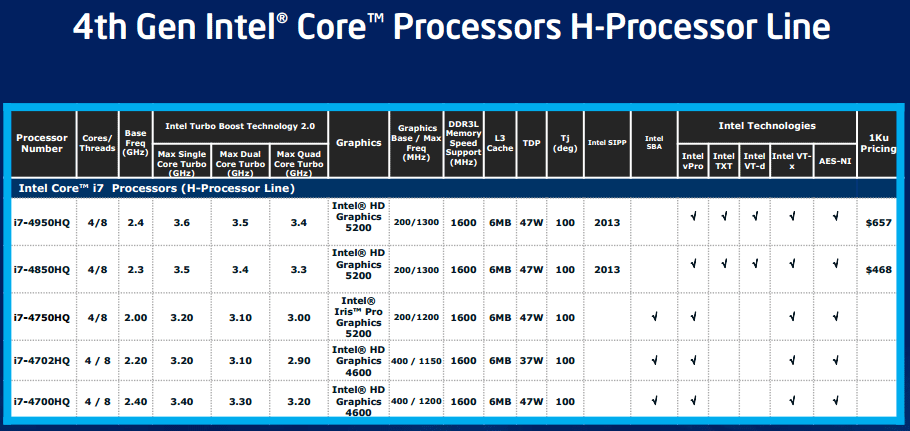 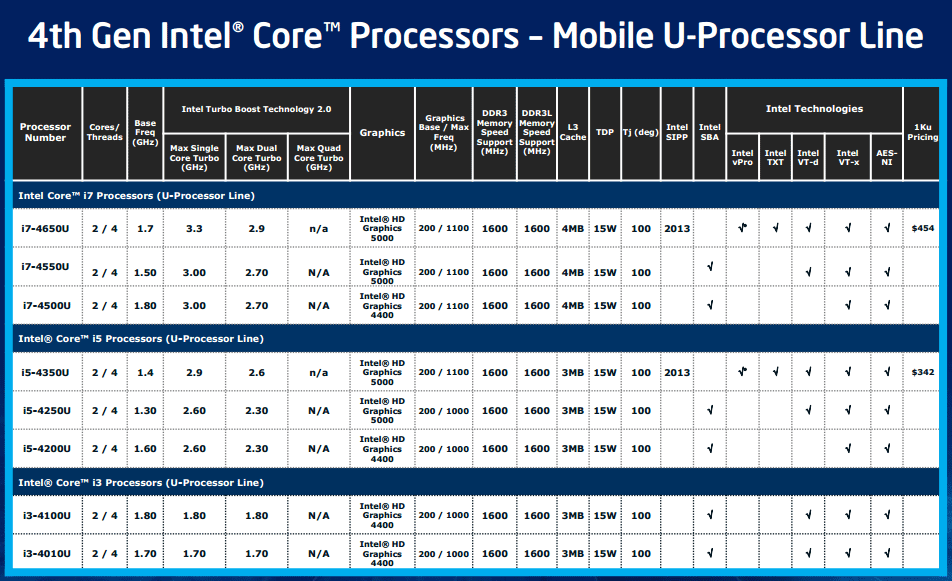 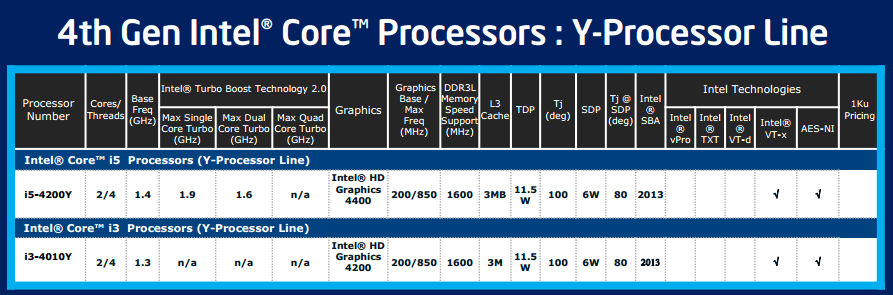 Page 9 - Core i7-4770K, i5-4670K, i5-4430 et cartes mères Core i7-4770K, i5-4670K, i5-4430 et cartes mères  Pour ce test nous avons mis la main sur trois processeurs Intel Core de 4è génération : - Intel Core i7-4770K : 3.5 GHz et Turbo à 3.9 GHz, 8 Mo de L3, Hyperthreading - Intel Core i5-4670K : 3.4 GHz et Turbo à 3.8 GHz, 6 Mo de L3 - Intel Core i5-4430 : 3.0 GHz et Turbo à 3.2 GHz, 6 Mo de L3 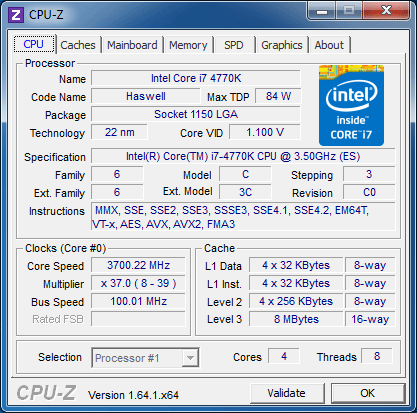 [ Core i7-4770K ] [ Core i5-4670K ] [ Core i5-4430 ] Ces processeurs sont en fait strictement identique côté fréquence, taille du cache et présence de l'Hyperthreading à leurs équivalents Ivy Bridge de 3è génération (i7-3770K, i5-3570K et i5-3330), ce qui nous permettra de voir quels sont les gains à fréquence égale. Le TDP est par contre en hausse, passant de 77 à 84 watts. Vous noterez que l'i5-4430 ne demande que 0.94v en charge, contre 1.1v pour le 4770K et 1.0V pour le 4670K. Pour le test nous avons utilisé trois cartes mères, à commencer par l'Intel DZ87KL-75K qui est une des dernières cartes mise au point par la branche carte mère d'Intel qui va bientôt être arrêtée.  Intel a fait le choix d'une alimentation 8 phases pour le processeur, ce dernier étant relié à 3 ports PCI Express utilisables en x16/x0/x0, x8/x8/x0, ou x8/x4/x4. En sus du Z87 Express on trouve une multitude puces additionnelles. Intel n'utilise ainsi que 4 ports USB 3.0 du chipset afin d'économiser les lignes PCI-Express de ce dernier, pour autant en sus d'un port interne en proposant on retrouve à l'arrière de la carte 6 USB 3.0. En fait on trouve sur la carte deux Hubs GL3520-10 qui permettent d'obtenir 3 ports à partir d'un seul. Deux contrôleurs réseaux Intel Gigabit Ethernet, reliés chacun en PCI-Express x1, sont présents alors qu'un lien x4 assure la connexion avec un contrôleur Intel Thunderbolt. Un autre lien PCI-Express x1 est utilisé pour un port mini PCIE/mSATA, et un autre pour une puce PLX8606 qui permet d'avoir 5 lignes supplémentaires. Une est utilisée pour un pont PCI IT8892E auxquels se connectent un port PCI classique et une puce IEEE 1394a TI TSB43AB22A. Trois autres ports issus du PLX sont utilisés pour les trois connecteurs PCI-Express x1 de la carte, et un dernier pour une puce ASM1061 qui ajoute 2 ports SATA 6G aux 6 déjà supportés par le Z87. L'audio est confié à une puce HD Audio Realtek ALC898. Résolument haut de gamme cette carte pleine de fonctionnalités est celle qui nous a servi de carte principale pour les tests. Le Visual Bios d'Intel est très agréable à l'usage et ergonomique. Afin de confirmer nos résultats d'overclocking, nous avons également essayé l'o/c sur une autre carte mère, l'ASUS Z87-Pro.  Cette fois ASUS fait appel à une alimentation à 12 phases alors que le processeur n'est relié qu'à 2 slots PCI-Express utilisables en x16/x0 ou en x8/x8. Côté Z87 Express celui-ci est relié à 4 ports PCI-Express x1 et en x1 par défaut au dernier PCI-E x16 qui peut être configuré en x4 ce qui désactive alors 3 ports x1. Un des port x1 qui sera désactivé partage d'ailleurs sa ligne PCI-Express avec une puce ASM1061 qui permet de passer de 6 à 8 SATA 6 Gb/s. Côté réseau ASUS intègre tout d'abord un PHY Intel I217V qui vient se connecter avec le contrôleur réseau intégré au Z87, mais aussi une carte WiFi GO! placée au niveau des sorties et qui intègre un contrôleur Wi-Fi 802.11n a/b/g/n interfacé en PCI-Express et un contrôleur Bluetooth 4.0 en USB 2. 5 des 6 ports USB 3.0 du Z87 Express son utilisés, 4 directement via le connecteur interne et deux connecteurs arrières, 1 indirectement via un hub ASM1074 qui permet d'obtenir 4 ports supplémentaires à l'arrière. Le son est pris en charge par un codec Realtek ALC1150, ASUS indique avoir apporté un soin particulier de ce côté avec un SNR annoncé à 112 dB en sortie et de 104 dB en entrée. Là encore pas de souci particulier à noter sur cette carte, le bios UEFI ASUS étant toujours aussi agréable à l'usage.  Enfin pour les tests iGPU nous avons fait appel à une troisième carte mère, la MSI Z87-G65 Gaming pour la simple et bonne raison que cet article a été écrit à deux, 650 Km nous séparant. Sur cette carte MSI intègre pas moins de 16 phases pour alimenter le processeur et toutes possibilité du processeur en terme de PCI-Express sont utilisées, x16/x0/x0, x8/x8/x0 ou x8/x8/x4 sur trois ports. 3 autres ports PCI-Express x1, reliés eux au Z87 Express sont intégrés. Ce dernier est utilisé cette fois de manière directe au niveau de l'USB 3.0 ce qui n'est pas plus mal même si la carte ne propose du coup "que" 6 ports dont 4 à l'arrière. En sus des 6 SATA 6 Gb/s du chipset, 2 sont gérés par un ASM1061 pour un total de 8. Comme chez ASUS le codec audio est un Realtek ALC1150 alors que la partie réseau est, gamme Gaming oblige, animée par une puce PCI-E Killer E2205 qui a la particularité de permettre via son pilote de donner la priorité aux jeux si vous jouer et télécharger en même temps afin de ne pas augmenter le lag, un choix qui entraine un surcoût pas forcément utile. A l'usage la carte mère n'a pas non plus posé de problème et on notera les progrès fait par MSI au niveau de l'ergonomie de son bios UEFI Click Bios 4 par rapport aux gammes précédentes, les doubles clics superflus n'étant plus de mise par exemple. Page 10 - Bug de l'USB 3.0 sur C1, compatibilité des alimentations Au cours de ces derniers mois deux sujets concernant ces processeurs Intel de 4è génération ont suscité l'inquiétude, nous nous devions donc de revenir dessus. L'USB 3.0 buggé ?Premier point, Intel a averti dès mars les constructeurs d'un bug sur la gestion de l'USB 3.0 de ses chipsets Intel Serie 8. Rapidement l'information est apparue sur la toile et bien que mineur, le bug annoncé pouvait être gênant pour certains puisqu'il était question d'une inaccessibilité des périphériques USB 3.0 après une veille de type S3 (Suspend-To-Ram).  Si Intel a confirmé en avril via un PCN qu'une nouvelle version des chipsets Intel Serie 8, dénommée C2, corrigeant ce défaut serait disponible fin juillet, aucun détail sur le bug en lui-même n'était donné. Est-ce systématique ? Faut-il redémarrer la machine pour récupérer l'accès au périphérique USB 3 ? Ou alors le fait de le rebrancher est-il suffisant ? Nous attendons encore d'avoir la description exacte du bug, mais selon Intel France le problème n'est pas systématique, n'arrive qu'avec un faible nombre de périphériques USB 3.0 (il est même uniquement question de clefs USB 3.0 dans la description qui nous en a été faite) et entraîne un redémarrage de la machine pour avoir de nouveau accès au périphérique si il disparaît après une veille. D'après un contact chez un fabricant de cartes mères, il suffirait de débrancher et rebrancher, mais que ce soit Intel ou les fabricants de cartes mères il ne faut pas perdre de vue qu'ils ont une intérêt commun dans l'éventuelle minimisation du problème.  La dernière version de CPU-Z indique quelle est la révision de votre chipset Lynx Point Qu'en est-il en pratique ? Nous avons bien entendu essayé de reproduire le problème sur notre machine de test équipée d'un chipset Intel Serie 8 de révision C1, mais ne l'avons pas rencontré que ce soit avec un adaptateur SATA vers USB 3.0 ou une clef USB 3.0 (Kingston DataTraveler 100 G3 32 Go) malgré de multiples tentatives, que ce soit sur des ports reliés directement au chipset ou via l'entremise d'un Hub USB 3.0 intégré à la carte mère. A défaut de plus, nous pouvons donc seulement confirmer qu'effectivement ce problème n'est pas systématique, ce qui vas dans le sens des dires optimistes des fabricants de cartes et d'Intel.Mise à jour : Nos confrères de Hardware.info on pu reproduire le problème sur certaines clés USB 3.0 et des disques externes. En pratique, en sortie de veille le logiciel dans lequel un fichier présent sur le périphérique était ouvert indique le fichier est introuvable, il suffit simplement de le ré-ouvrir ! Des alimentations "incompatibles" Haswell ?Fin avril cette fois, Intel a envoyé aux différents intégrateurs de PC un document afin d'attirer leur attention sur la nécessité d'utiliser une alimentation capable de supporter une intensité plus basse que celle demandée par la norme ATX 2.3 sur le rail 12V2, sous peine de voir le l'alimentation se couper lorsque le processeur rentre dans ces états les moins énergivores.  Petit retour en arrière, depuis la norme ATX12V 2.3 introduite en mars 2007 les alimentations doivent être capable de fonctionner lorsque seulement 0,5 A est demandé sur leur rail 12V2 utilisé pour les prises ATX12V/EPS12V qui alimentent l'étage d'alimentation de la carte mère destiné au processeur. Cette valeur était avant l'ATX12V 2.3 de 1A, ce qui du coup pouvait entraîner une coupure de l'alimentation lorsque l'on utilisait un processeur moderne avec une alimentation ancienne. Les alimentations ATX12V 2.3 semblent pouvoir atteindre des valeurs inférieures puisque les processeurs Core de 2è et 3è génération (Sandy Bridge et Ivy Bridge) sont plus économes : nous avons déjà relevé des valeurs de l'ordre de 0,2 A sur le 12V2 et à notre connaissance il n'y a pas de problèmes à ce sujet à ce jour. Les processeurs Core de 4è génération (Haswell) vont encore plus loin, c'est pourquoi Intel a indiqué aux fabricants d'alimentations dès août 2012, mais sans publier de nouvelle norme ATX12V, qu'il serait désormais nécessaire d'atteindre 0,05A sur le 12V2. 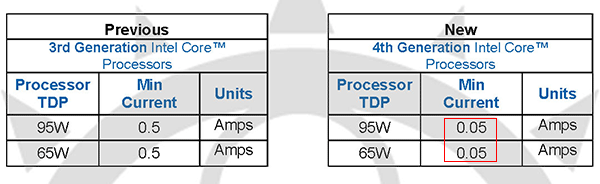 Cette fois on passe donc de 0,5 A à 0,05 A ! Cette limite ne pourrait être atteinte qu'avec les C-States les plus bas. Un C-State correspond à un état plus ou moins actif d'un cur du processeur, C0 correspond à l'état classique en charge et au fur à mesure que le processeur est au repos il coupe certaines fonctionnalités pour arriver progressivement aux modes C6/C7 qui sont les plus bas sur PC de bureau. 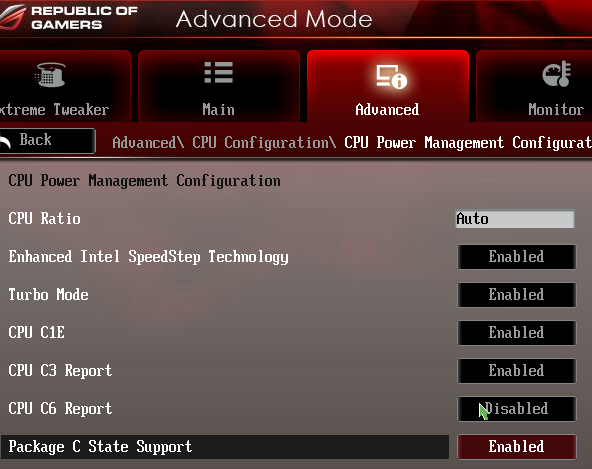 Exemple d'un bios permettant de désactiver individuellement les C-States Il n'est pour autant pas nécessaire de changer votre alimentation pour passer à Haswell, ceci pour quatre raisons. La première, c'est que de nombreuses alimentations modernes supportent déjà cette spécification comme nous l'avons déjà indiqué au travers de news. La seconde, c'est que sur beaucoup d'alimentations le rail 12V2 n'a pas sa propre source, voir n'est qu'un rail fictif. Dès lors, il suffit d'une autre charge sur le 12V, comme ce sera le cas de ventilateurs, d'un disque dur ou d'une carte graphique pour que la charge soit suffisante. La troisième, c'est que sur demande d'Intel les constructeurs de cartes mères devraient intégrer de manière systématique dans leurs bios la possibilité de désactiver les modes C6/C7, voir les désactiver par défaut, ce qui augmente la consommation au repos de 2 à 3 watts seulement. Il est à noter que sur sa propre carte mère Intel Z87 et un bios d'avril la seule option concernant les C-States désactivait également le mode C3, hors pour qu'un cur soit considéré comme inactif pour que le Turbo fonctionne comme prévu il doit être en C3. Il aura fallu un bios de mai pour que les C6/C7 soit réglables individuellement, ils sont d'ailleurs désactivés par défaut. La quatrième, c'est que même si les C-State C6/C7 sont actifs et si le processeur demande une faible charge, les étages d'alimentations des cartes mères n'offrent pas un assez bon rendement à faible charge pour faire descendre l'intensité demandée à l'alimentation sur le 12V2 en dessous d'un certain seuil. Ainsi, sur un Core i5-4570T à très basse consommation, nous n'avons pas pu mesurer moins de 0.25A sur le 12V2 sur une Intel DZ87KLT-75K, 0.4A sur une ASUS Z87-Pro et 0.6A sur une Z87-C d'entrée de gamme, malgré un monitoring logiciel annonçant une consommation de l'ordre de 1 watts pour l'intégralité du processeur (la mesure sur l'ATX12V est double si on désactive les C-State C6 et C7 sur la DZ87KLT-75K, la consommation grimpe donc de 3W au repos). C'est certes jusqu'à deux fois moins que les 0.5A de l'ATX12V 2.3, mais nous avions déjà relevé des chiffres de cet ordre sur des plates-formes précédentes qui alimentaient par ailleurs le processeur par d'autres biais. Au final, vous l'aurez compris, l'incompatibilité des alimentations avec les modes d'économies d'énergies C6/C7 des processeurs Intel Core de 4è génération est un faux problème. En pratique nous n'avons d'ailleurs pas rencontré de problèmes avec une Seasonic S12-II 430 watts "non compatible" malgré l'activation des modes C6/C7 sur des cartes mères Intel et ASUS, par contre avec une BQT-E6 400 watts et une carte MSI le système était très (très) lent, ne serait-ce que pour le boot Windows, dès lors que les modes C6/C7 étaient actifs et que nous n'étions pas sur l'iGPU mais avec une carte graphique additionnelle. Une simple désactivation des modes C6/C7, comme c'était le cas par défaut, nous a permis de remettre les choses dans l'ordre. Page 11 - Consommation, efficacité énergétique Consommation, efficacité énergétiquePour le test de consommation nous essayons d'utiliser un logiciel qui est pour toutes les architectures assez représentatif de ce que nous obtenons dans les applications en termes de performances et de consommation. Notre choix se porte actuellement sur Fritz Chess Benchmark, qui a de plus l'avantage de pouvoir facilement fixer le nombre de threads à utiliser. Les mesures de consommation ne sont donc pas à prendre comme des valeurs maximales absolues mais plutôt typiques d'une charge lourde, puisque des logiciels spécialisés dans le stress processeur tels que Prime95 peuvent consommer environ 20% de plus. Toutes les fonctionnalités d'économie d'énergie, y compris celles des cartes mères comme l'EPU d'ASUS, sont activées pour ce test du moment qu'elles n'impactent pas négativement les performances. Nous donnons pour rappel deux types de relevés, la première à la prise 220V via un wattmètre pour la configuration de test dans son intégralité, et la seconde sur l'ATX12V via une pince ampèremétrique. Cette mesure permet d'isoler le gros de la consommation du processeur, mais elle n'est malheureusement pas exactement comparable d'une plate-forme à une autre puisque dans certains cas une petite partie de la consommation du CPU est issue de la prise ATX 24 pins standard. Voici les configurations utilisées : - Intel DP67BG (LGA1155) - Intel DZ87KL-75K (LGA1150) - Intel DX79SI (LGA2011) - ASUS M5A99X EVO (AM3+) - Gigabyte F2A85X-UP4 (FM2) - 2x4 Go DDR3-1600 9-9-9 - 4x4 Go DDR3-1600 9-9-9 (LGA 2011, environ 1 watts de plus au repos et 3 en charge) - GeForce GTX 680 + GeForce 306.97 - SSD Intel X25-M 160 Go + SSD Intel 320 120 Go - Alimentation Corsair AX650 Gold - Windows 7 SP1 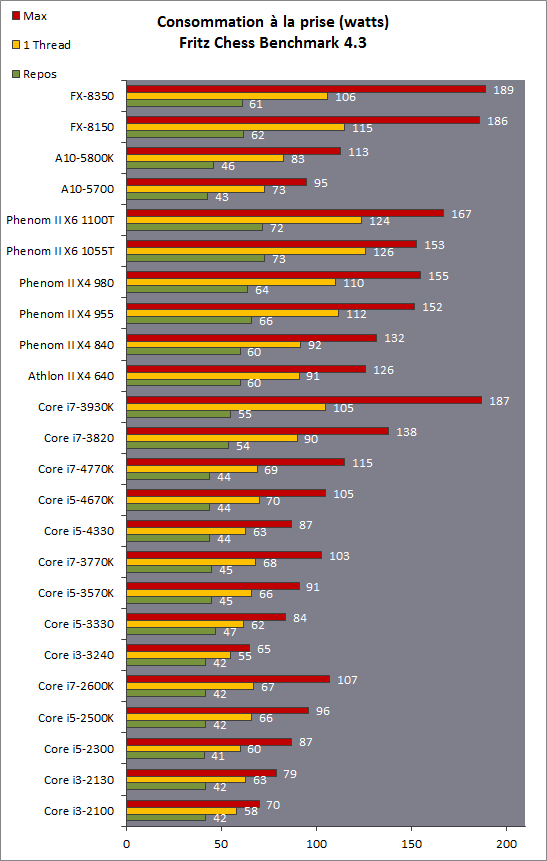 [ Prise 220V ] [ ATX12V ] Au repos, la consommation globale est assez similaire entre les plates-formes LGA 1155, LGA 1150 et FM2 et assez basse malgré la présence d'une GTX 680 ajoute à elle seule environ 18W de consommation à la prise. Les plates-formes LGA 2011 et AM3+ sont un cran derrière. Si on regarde plus précisément l'ATX12V on peut voir que si les chiffres sur LGA 1150 sont légèrement meilleurs que sur LGA 1155 + Ivy Bridge, le couple LGA 1155 + Sandy Bridge reste meilleur, mais il s'agit d'écarts marginaux. En charge la consommation est par contre en hausse notable sur Haswell, et l'i5-4670K consomme un peu plus qu'un i7-3770K. L'i7-4770K demande à 68 watts sur l'ATX12V sous Fritz, un chiffre qui monte jusqu'à 79 watts sous Prime95 à titre d'information. Attention toutefois, les mesures ne sont pas faites sur les mêmes cartes mères, changement de Socket oblige, ce qui peut donc avoir un impact. Si l'on se fie au monitoring du processeur seul on obtient ainsi par exemple sur un i7-2600K une consommation au repos rapportée à 5 watts pour la totalité dont 2W pour les curs CPU (pour 3W mesurés sur l'ATX12V, une partie de l'alimentation CPU provient donc d'une autre source). Sur Haswell par contre on obtient 1 watts dont 0,01 watts (!) au repos pour les curs, pour 3,6 watts mesurés au niveau de l'ATX12V, une surconsommation probablement lié au faible rendement de l'étage d'alimentation de la carte mère combiné à celui de l'IVR avec ce type de charge. Une consommation d'Haswell seul plus basse qui est probablement compensée par ailleurs par une carte mère un peu plus complexe et donc gourmande. En charge également la carte mère peut avoir son importance, puisque l'écart eut être amplifié par la propension d'un étage d'alimentation à faire laisser par défaut plus ou moins de vDrop. Une simple baisse de 0.05v de la tension fait en effet baisser la consommation de quasiment 10%. Il parait néanmoins clair que les Core i7 de 4è génération ne sont pas révolutionnaires du côté consommation. Au repos, les plates-formes LGA 1150 et 1155 étaient déjà peu énergivores et les gains enregistrés au niveau du processeur seul par les outils de monitoring ne feront vraiment la différence que sur les plates-formes mobiles. En charge ils consomment un peu plus que leurs prédécesseurs, sachant qu'en plus ils intègrent une partie du régulateur de tension (et donc des pertes d'énergies qui lui sont propres) est intégré, ils pourraient donc êtres un peu moins facile à refroidir, nous y reviendrons en page suivante. Reste maintenant à représenter l'efficacité énergétique d'un processeur. Pour se faire il s'agit de diviser la performance obtenue sous Fritz Chess Benchmark par la consommation du CPU. Seul problème, il n'est pas possible de connaitre exactement celle-ci : la mesure sur l'ATX12V n'est pas 100% comparable d'une plate-forme à une autre, et la mesure à la prise ne permet pas complètement d'isoler tout ceci. Nous avons donc fait le choix d'utiliser deux méthodes de calcul pour isoler la consommation de processeur : - Consommation sur l'ATX12V - 90% du delta de consommation à la prise entre charge et repos Nous utilisons les 90% afin d'exclure le rendement de l'alimentation à proprement parler. Il faut noter que si la première mesure favorise les processeurs tirant une petite partie de leur énergie via la prise ATX classique, la seconde favorise ceux qui ont une consommation élevée au repos. Malheureusement aucune méthode n'est parfaite. 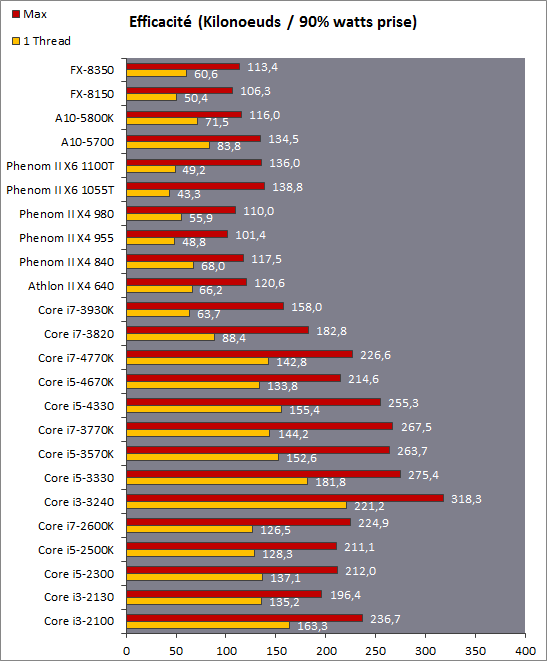 [ Prise 220V ] [ ATX12V ] Fritz n'est pas le logiciel qui profite le plus de l'architecture Haswell, avec un gain moyen de 8% en mono et multithread sauf pour l'i7-4770K qui n'a qu'un avantage de 3,7% sur l'i7-3770K (les scores complets sont ici pour les curieux). Combiné à la hausse de la consommation, on obtient une efficacité énergétique qui stagne voir baisse par rapport à Ivy Bridge. L'avance sur les processeurs AMD reste toutefois énorme. Page 12 - Températures, overclocking et undervolting TempératuresNous avions expliqué en long et en large la "problématique" de la température sur Ivy Bridge lors de notre dossier qui lui était consacré. Quid du comportement de Haswell de ce côté ? Comme nous l'avons vu en page précédente, la consommation en charge est en légère hausse, et même si les die sont forcément un peu plus gros bien que l'on reste en 22nm, par ailleurs le processeur intègre un régulateur de tension qui a forcément un rendement inférieur à 100%, bien que non documenté, ce qui induit quelques watts de plus à dissiper qui l'étaient auparavant au niveau de l'étage d'alimentation de la carte mère. L'interface thermique avec l'IHS du CPU (la coque métallique) est comme sur Ivy Bridge de la pâte, et non plus un joint métallique en indium plus performant comme auparavant. 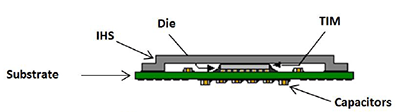 Avant de passer à la pratique il faut savoir que la température maximale que le processeur va essayer de ne pas atteindre, en abaissant sa fréquence (c'est le Throttling) si nécessaire, a été revue à la baisse. Elle est en effet de 100°C sur les Haswell Desktop, contre 105°C sur Ivy Bridge et 98°C sur les Sandy Bridge. Voici les valeurs relevées sur différents processeurs en charge sous Prime95 avec une température ambiante de 25°C en charge sous Prime95 avec un Noctua NH-U12P SE2 (tests hors boîtier). Nous effectuons la moyenne des 4 sondes ce qui permet de réduire l'influence de la marge d'erreur par sonde : - Core i5-2500K : 48°C (23°C de delta T, 50°C de marge vs Tjmax) - Core i7-2600K : 51°C (26°C de delta T, 47°C de marge vs Tjmax) - Core i7-2700K : 53°C (28°C de delta T, 45°C de marge vs Tjmax) - Core i5-3570K : 56°C (31°C de delta T, 49°C de marge vs Tjmax) - Core i7-3770K : 59°C (34°C de delta T, 46°C de marge vs Tjmax) - Core i5-4670K : 58°C (33°C de delta T, 42°C de marge vs Tjmax) - Core i7-4770K : 64°C (39°C de delta T, 36°C de marge vs Tjmax) La température de notre i5-4670K est en légère hausse de 2°C par rapport à celle de notre i5-3570K. La marge par rapport au Tjmax est par contre réduite de 7°C du fait de la baisse de celui-ci. Sur l'i7-4770K c'est plus délicat puisque la température est en hausse de 5°C par rapport à notre i7-3770K et 11°C par rapport à notre i7-2700K. La marge par rapport au Tjmax est réduite à 36°C, ce qui malgré tout reste très confortable : un NH-U12P SE2 n'a heureusement pas de problème pour refroidir ces nouveaux processeurs sans overclocking, et même avec un overclocking à condition de conserver une tension raisonnable. Avec un ventirad Intel de base on devrait par contre se rapprocher dangereusement de la limite en charge lourde dans un boitier. Overclocking et undervoltingNous reportons nos résultats obtenus avec les Core i5-4670K et i7-4770K, refroidis par un Noctua NH-U12P SE2, hors boitier avec une température ambiante de 25°C. Pour chaque combinaison nous rapportons la fréquence, le VID du processeur qui nous a permis de la stabiliser (modifiée par pas de 0,05v), la consommation à la prise et sur l'ATX12V sous Prime95, comme lors du test d'Ivy Bridge. Les tests ont été effectués sur la DZ87KL-75K d'Intel, mais nous avons essayé également dans un second de les reproduire sur l'ASUS Z87-Pro. Nous avons obtenu les même résultats (fréquence / tension) sur l'ASUS, avec seulement une petite différence de consommation globale de 1 watts en charge comme au repos. C'est le VID (tensions demandée) et non pas le VCORE (tension mesurée à la sonde) qui est remonté comme tension CPU par les outils de monitorings sous Haswell, comme l'explique Franck Delattre l'auteur de CPU-Z : Un des soucis majeurs avec le Haswell est la mesure de son VCORE. Sur les processeurs précédents, il est lu généralement sur la puce de monitoring de la carte mère. Dans le cas du Haswell, l'entrée VCORE de ces puces renvoie en général VCCIN et non le VCORE. C'est pourquoi CPU-Z affiche le CPU VID dans le cas du Haswell. D'après les tests menés, le VID correspond bien au VCORE, et ce dans tous les modes de contrôle du VCORE. 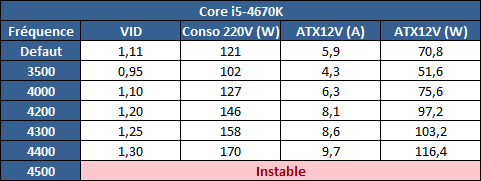 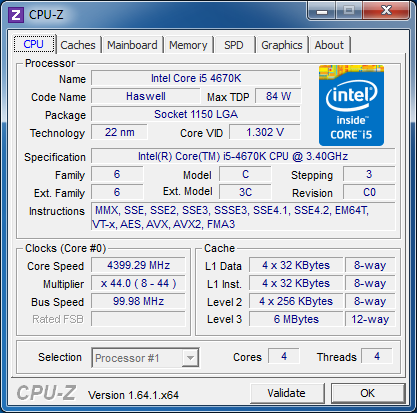 On commence donc par le Core i5-4670K, qui demande par défaut 70,8 watts sur l'ATX12V pour une fréquence en pratique de 3.6 GHz et un VID de 1.11v. A 3.5 GHz nous avons pu le passer à 0.95v, on tombe alors à 51,6 watts, alors que les 4 GHz ont été atteint avec 1.1v avec une consommation à peine supérieur à celle par défaut. Chaque augmentation de 100 MHz au-delà demande par contre une hausse de 0.05v de la tension, et on atteint finalement 1,3v pour 4.4 GHz stables, un chiffre peu glorieux. La température du processeur est de 77°C, soit 21°C de plus que par défaut. 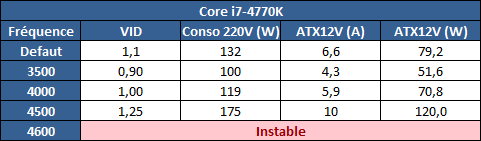 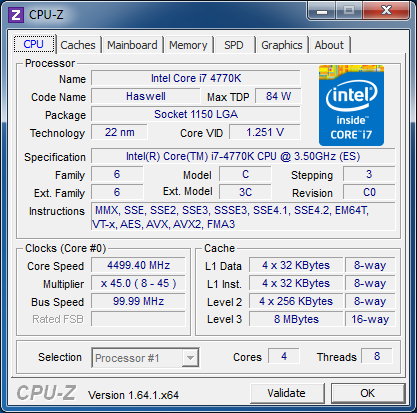 Le Core i7-4770K s'est montré un peu plus coopératif sans pour autant atteindre des sommets. En undervolting les résultats sont bons, avec 0.9v à 3.5 GHz (contre 1.10v aux 3.7 GHz par défaut) ce qui lui permet de passer de 79,2 à 51,6 watts. Les 4 GHz sont tenables avec 1v ce qui permet d'avoir une consommation inférieure à celle par défaut, et nous sommes ensuite passé directement à 4.5 GHz qui ont pu être stabilisés à 1,25v. La consommation est alors à 120 watts, et la température en charge passe de 64°C à 82°C (+18°C). Même si il reste 18°C par rapport au Tjmax et que Prime95 charge notablement plus que de "vrais" logiciels, il ne faut pas oublier que ces tests sont hors boitiers. Au final les résultats de cette première séance d'overclocking avec Haswell est assez décevante, puisque les fréquences stables obtenues sont 200 MHz inférieures à celles que nous avions obtenues sur Ivy Bridge, et que ce dernier était déjà en recul par rapport à Sandy Bridge. De ce côté il faut donc espérer que les choses s'améliorent avec le temps ou que nos exemplaires soient en bas de fourchette. Page 13 - HD Graphics 4600 : Consommation, Overclocking, Jeux HD Graphics 4600 en pratique Nous avons bien évidemment voulu évaluer les performances de la partie graphique d'Haswell, aussi bien côté jeu, OpenCL qu'encodage vidéo. Côté OpenCL les pilotes graphiques fournis par Intel pour ce test se sont montrés assez capricieux, provoquant des plantages durant nos tests avec des applications comme Folding@Home. Autre petite déconvenue, WinZip. La version 16 proposait une accélération OpenCL pour les Radeon, et la version 17.5 semblait enfin apporter le support des processeurs Intel. C'est le cas dans l'interface, qui permet bel et bien d'activer OpenCL avec un processeur Intel, mais sur aucune de nos plateformes de tests l'accélération OpenCL n'a apporté un quelconque gain de performances, produisant un résultat identique au score en mode CPU. A défaut d'une incompatibilité avec toutes les plateformes, nous penchons plutôt sur le fait que WinZip n'active pas l'OpenCL s'il estime le processeur plus rapide. Quelque chose qui rappellera par exemple le fonctionnement de DxO Pro Optics en version 7.5 dans nos derniers benchs. La bonne nouvelle est que les auteurs de DxO permettent désormais d'activer OpenCL même si le processeur est censé être plus rapide. L'utilisateur est averti au cas où son GPU risque de ralentir les calculs, ce qui nous semble une très bonne solution ! LuxMark complète nos tests OpenCL. Côté jeu nous avons évalué les performances dans deux résolutions, en 1080p et 720p, dans des modes graphiques relativement peu gourmands. Nous avons choisi trois titres de gourmandise variable, à savoir F1 2011, Batman Arkham Asylum et Battlefield 3. F1 2011 est testé en mode DX9 et DX11. Pour pouvoir comparer le HD 4600 nous avons mis en place les plateformes suivantes, afin de le comparer au HD 4000 (Ivy Bridge) et à l'A10 5800k, l'actuel haut de gamme en APU desktop chez AMD : - Carte mère MSI Z87-GD65 Gaming, Intel Core i7 4770K - Carte mère Asus P8Z77-V Pro, Intel Core i5 3570K - Carte mère Gigabyte GA-F2A85X-UP4, AMD A10 5800K Notez que si nous utilisons un Core i5 3570K pour les tests graphiques de la plateforme Ivy Bridge, en pratique nous sommes (très) loins d'être limités par le processeur et les résultats seraient identiques avec un Core i7 3770K. Nous avons également voulu comparer les performances à deux cartes graphiques d'entrée de gamme, les Radeon HD 6670 d'AMD en version DDR3 et GDDR5, deux cartes que l'on retrouve respectivement aux alentours de 55 et 70 euros. Notez pour terminer que nous avons testé nos trois plateformes avec trois timings mémoires différents : - DDR3-1600 9-9-9-24 - DDR3-1866 10-10-10-28 - DDR3-2133 11-11-11-30 Dans tous les cas le command rate est à 1. Avant de parler des performances, nous avons évalué la consommation des différentes plateformes. Consommation Nous avons mesuré la consommation de nos configurations dans quatre scénarios : - Au repos - En lecture d'un fichier H.264 720p sous MPC-HC (avec toutes les accélérations activées) - Sous F1 2011 en 1080p DX11 - Sous Furmark Nous avons réalisés trois types de mesures différentes, à la fois à la prise 220V avec un wattmètre, mais aussi via le logiciel HWinfo qui permet de lire les sondes internes de consommation des processeurs. Ces dernières ne sont pas forcément fiables (par exemple la sonde Package sur notre Ivy Bridge) et comparables d'un processeur à l'autre, il faudra donc surtout regarder les écarts sur un même CPU. Il en va de même pour les mesures de consommation à la prise : nous utilisons des plateformes assez différentes et non comparables. Notez en prime que nous avons laissée désactivé les C6/C7 sur la plateforme Haswell, ces derniers nous ayant posé un problème avec une carte graphique dans le système sur la carte MSI. Il faut donc comparer les écarts et non les valeurs entre elles. Si vous cherchez une comparaison des consommations des plateformes, nous vous renvoyons page 11 de cet article. Voici les résultats obtenus : 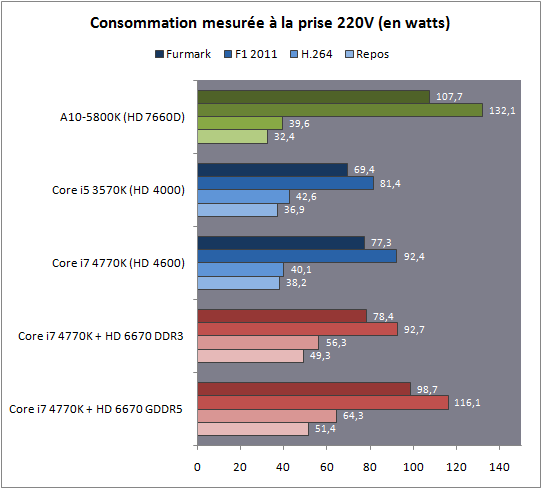 [ Prise 220V ] [ Sonde package ] [ Sonde GPU ] Plusieurs tendances à noter. D'abord en lecture vidéo, la consommation d'Haswell est particulièrement basse. Le fait d'avoir placé le ring bus sur un plan de fréquence différent semble payant ici. Trinity dispose de loin du GPU le plus gourmand et l'on le ressent très vite sur la consommation, particulièrement sous Furmark. La consommation sous F1 2011 est plus élevée, bien entendu ,mais il faut garder en tête que la charge graphique n'est pas la même : Trinity est ici significativement plus rapide dans ce bench, entrainant une consommation GPU et CPU plus forte. Overclocking Intel permet l'overclocking de son iGPU. On peut jouer sur deux leviers, d'abord d'un côté le multiplicateur turbo, et de l'autre sur la tension de l'iGPU. Sur notre Core i7 4770K, le multiplicateur turbo est fixé de base à 12.5x, donnant une fréquence de 1.25 GHz. Pour rappel, le HD 4000 est cadencé par défaut en turbo à 1.15 GHz sur Ivy Bridge. Sans changer la tension, nous avons obtenu une fréquence maximale de 1.4 GHz. En poussant la tension de +0.2V nous avons pu atteindre les 1.55 GHz. En pratique, nous pouvions même atteindre les 1.6 GHz un court instant mais assez rapidement la fréquence de l'iGPU throttle et redescend à 1.55. Notez que nous avons mesuré un gain de 10.8% de performances sous Batman en 720p à 1.55 GHz par rapport à la fréquence de base. Passons maintenant aux performances ! F1 2011  Nous utilisons le niveau graphique intermédiaire, le jeu est testé en mode DX9 et DX11 : 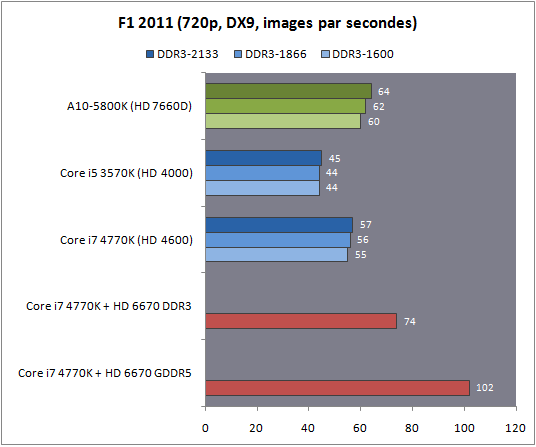 [ 720p DirectX 9 ] [ 1080p DirectX 9 ] [ 720p DirectX 11 ] [ 1080p DirectX 11 ] En mode DirectX 9, on peut noter qu'Intel progresse relativement fortement par rapport au HD 4000. Le gain en 720p est de 25% et de 18% en 1080p. L'écart avec Trinity reste cependant encore élevé, 9% en 720p mais surtout 33% en 1080p. Passer sur le mode de rendu DX11 change la donne puisque avec de la mémoire DDR3-1600 en 720p, le HD 4600 des Haswell arrive a faire jeu égal avec Trinity, un écart qui passe à la faveur du Core i7 4770k sur les timings mémoires supérieurs. Un écart qui reste de courte durée puisqu'en 1080p, Trinity repasse devant. Par rapport à nos cartes graphiques, on notera une fois de plus que c'est en mode DX9 qu'Intel souffre d'un gros manque d'efficacité, possiblement lié à ses pilotes. En DX11, le HD 4600 n'est en effet pas si éloigné que cela de la Radeon HD 6670 DDR3. Le modèle GDDR5 met cependant tout le monde d'accord ! Batman Arkham City  Nous utilisons le mode graphique minimal DX9 dans ce jeu : 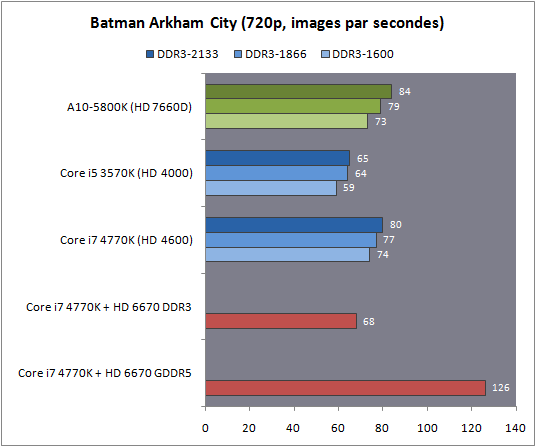 [ 720p ] [ 1080p ] Une fois de plus on note un gain assez conséquent pour le HD 4600 par rapport au HD 4000 en basse résolution, + 25% et seulement +10% en 1080p. En 720p, le HD 4600 talonne Trinity qui ne s'en sort qu'avec de la mémoire plus rapide. La HD 6670 DDR3 est même derrière. En 1080p le Core i7 4770K fait jeu égal avec la modeste HD 6670 DDR3, Trinity est un peu plus à l'aise et la version GDDR5 de la HD 6670 continue de mettre à mal toutes les solutions intégrées. Battlefield 3  Nous utilisons le mode graphique minimal dans ce jeu : 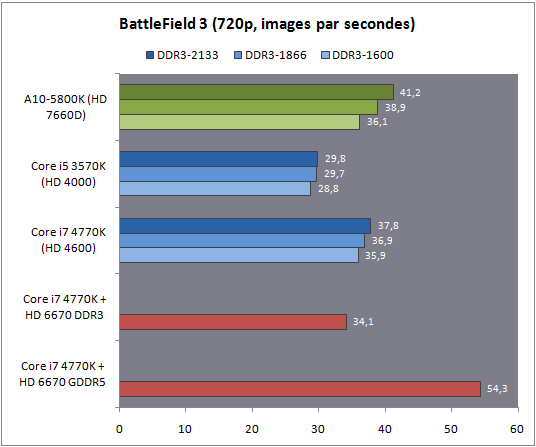 [ 720p ] [ 1080p ] On retrouve dans Battlefield 3 une situation relativement similaire : le gain par rapport au HD 4000 est toujours fort en 720p, un peu plus tassé en 1080p et le 4770K arrive à passer sur ce titre devant la HD 6670 DDR3. Globalement on reste assez loin d'un niveau de jouabilité mais l'on ne peut que constater qu'Intel comble petit à petit son écart par rapport à son concurrent sur le graphisme intégré. Page 14 - HD Graphics 4600 : OpenCL, Quicksync Passons maintenant aux performances OpenCL. DxO Optics Pro 8.1.6  Nous utilisons la version 8.1.6 de ce logiciel de traitement photo pour réaliser des exports RAW vers JPEG sur une série de 48 fichiers. La version 8.1 permet d'activer et désactiver à la volée l'OpenCL, ce qui est une bonne chose pour nos tests ! 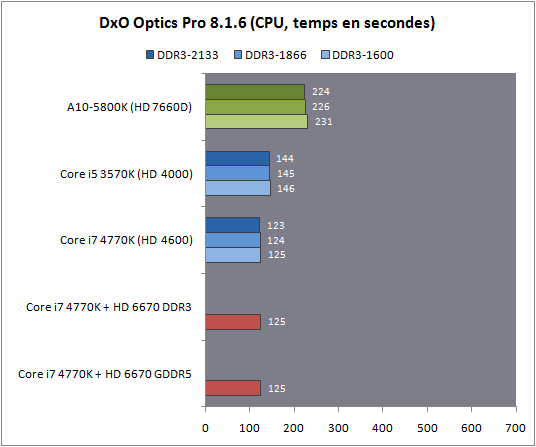 [ CPU ] [ OpenCL GPU ] Notez que nous n'avons pas réussi a faire tourner le mode OpenCL de DxO sur Ivy Bridge, que ce soit avec les pilotes beta fournis par Intel ou les derniers pilotes officiels. Ceci mis à part, les performances en OpenCL restent ici bien inférieures à ce que proposent les processeurs, y compris pour le 5800K d'AMD qui n'en profite pas. LuxMark 2.0  Nous utilisons LuxMark, benchmark du moteur de rendu 3D open source LuxRender . Il a l'avantage de permettre de comparer les modes OpenCL "CPU" (le rendu des kernels OpenCL s'effectue sur le processeur), GPU, et CPU + GPU mélangés. 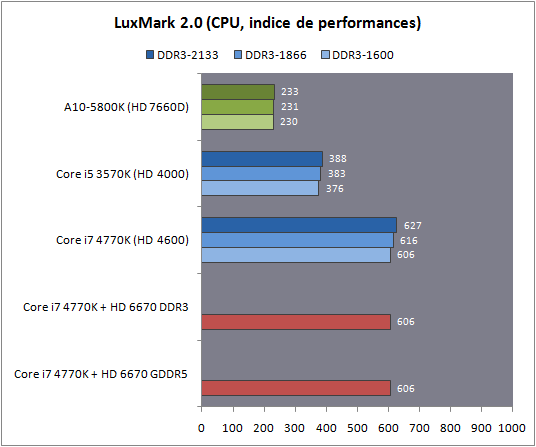 [ OpenCL CPU ] [ OpenCL GPU ] [ OpenCL CPU+GPU ] Ici on peut noter que les derniers pilotes Intel boostent assez sauvagement les performances en OpenCL, le Core i7 4770K dominant sur le résultat GPU pur. Un écart qui se creuse même par rapport aux cartes graphiques quand on cumule CPU et GPU. Encodage vidéo Intel nous a fourni une version de Media Espresso, logiciel de Cyberlink qui implémente la toute dernière version du MediaSDK compatible Haswell.  Nous avons voulu regarder ce que proposait le logiciel en terme de rapidité et de qualité. Nous avons testé Media Espresso à plusieurs reprises, dans cet article sur x264, et dans cette mise à jour. Notez que la version fournie par Intel est la version 6.7.3521.45765 (!). Rapidité d'encodage Media Espresso propose toujours deux modes d'encodage distincts lorsque l'on utilise l'accélération QuickSync, un mode rapide (fast) et un mode de meilleure qualité (better). Nous avons relevé le temps de compression pour notre fichier extrait, sa durée est de 9 minutes et 20 secondes :  On notera tout d'abord un petit gain de rapidité sur l'encodage rapide, ce qui en soit n'est pas forcément intéréssant tant sa qualité est généralement faible. Sur Ivy Bridge, les modes Fast et Better prennent le même temps, ils sont légèrement différents en pratique mais d'une qualité comparable, nous pensons donc à un bug de cette version. Le temps de compression "Better" sur Haswell est un peu plus long, tout en restant bien au dessus de celui d'Ivy Bridge, ce qui nous laisse penser que nous allons comparer un mode rapide sur Ivy Bridge à un mode optimisé sur Haswell. Voyons cela en pratique ! Qualité d'encodage Intel indique proposer plus d'options dans son MediaSDK pour améliorer la qualité. Nous avons donc voulu vérifier cela en pratique. Malheureusement, MediaEspresso conserve toujours les mêmes limitations qu'il y a deux ans lors de notre premier test à savoir : - profil baseline uniquement - GOP fixe - pas de B frames Pour les non-initiés, tout cela se traduit en pratique par un niveau de qualité non optimal, et par des "sauts" de qualité toutes les trente images (une image complète - une keyframe - est insérée toutes les 30 images, et entre deux la quantité d'information pouvant varier de l'une à l'autre est fixe). Résultat, si une transition (changement de plan, etc) arrive durant ces 30 images, l'encodeur lutte pour "rattraper son retard" jusqu'à la prochaine keyframe. Cela peut donner des sensations de clignotements visibles et, très franchement, pénibles. MediaEspresso n'est pas le logiciel qui exploite le mieux le MediaSDK d'Intel, et il est dommage que le constructeur n'ait pas fourni un autre logiciel pour tester les performances d'Haswell qui se retrouvent bridées par le logiciel. Le futur travail pour pousser à l'utilisation de MediaSDK dans des projets open source comme HandBrake ne peut arriver trop vite ! Alors, quid de la qualité ?  Cette image est typique du problème de changement de scène. Si vous comparez la source aux différents encodages vous verrez comme un voile lumineux. Le plan précédent, bien que ressemblant, étant un peu plus lumineux et l'encodeur n'arrive pas à proposer quelque chose de proche de ce à quoi devrait ressembler la scène. L'encodage processeur, réalisé lui aussi avec MediaEspresso surclasse tous les autres en matière de netteté et de détails bien qu'il ne soit pas au niveau de ce que peut proposer un encodage avec x264 par exemple. Haswell ne fait pas mieux qu'Ivy Bridge, il optimise des zones différentes.  Sur cette seconde scène plus fixe, on peut voir que tous les encodages s'en tirent un peu mieux. L'avantage d'Haswell n'est cependant pas forcément évident par rapport à Ivy Bridge, si vous comparez par exemple le pouce. Globalement il n'y a pas de miracles apportés par l'itération Haswell de QuickSync, en tout cas utilisée avec MediaEspresso. Il sera bon de voir si avec un logiciel un peu plus au point dans quelques semaines on peut voir d'autres gains de qualité. Page 15 - Protocole CPU, Rendu 3D : Mental Ray et V-Ray Protocole de test CPU Pour ce test nous avons repris le protocole de test utilisé lors du test de l'AMD FX-8350.  Pour rappel les évolutions apportées à l'époque étaient diverses, avec côté applicatif tout d'abord, une évolution la version de x264 de la build 2085 à la build 2216 qui intègre diverses optimisations utilisant entre autres les instructions introduites par Bulldozer. En pratique les processeurs Intel profitent également de gains de performances, les gains variant entre 3 et 5% selon le processeur. Tant qu'à faire nous avons également mis à jour le codec H.264 de MainConcept en passant de Reference 2.2 à TotalCode 2.5, le nouveau nom du logiciel. Cette fois il n'y a pas vraiment de modification des performances. Depuis, x264 a intégré des optimisations AVX2 et nous avons tout de même également effectué des mesures additionnelles avec la build 2310 de x264 sans qu'il nous soit possible de repasser tous les processeurs en test faute de temps.  Nous avions également refait les tests jeux avec une GeForce GTX 680 en lieu et place d'une GeForce GTX 580, tous les patchs à jour en date de la mise en place du protocole. Nous avions changé de scène pour Rise Of Flight, celle utilisée à la base étant trop lourde et posant des soucis à la dernière version du moteur. F1 2011 était remplacé par F1 2012, Anno 1404 par Anno 2070 et Skyrim intégré en tant que 8è jeu. Comme auparavant, nous testons ces jeux en 1920*1080 avec les détails (hors antialiasing) au niveau maximum, tout en cherchant des scènes lourdes nous permettant d'être limité en performance par le processeur. Voici les différentes configurations de test : - Intel DP67BG (LGA1155) - Intel DZ87KL-75K (LGA1150) - Intel DX79SI (LGA2011) - ASUS M5A99X EVO (AM3+) - Gigabyte F2A85X-UP4 (FM2) - 2x4 Go DDR3-1600 9-9-9 - 4x4 Go DDR3-1600 9-9-9 (LGA 2011) - GeForce GTX 680 + GeForce 306.97 - SSD Intel X25-M 160 Go + SSD Intel 320 120 Go - Alimentation Corsair AX650 Gold - Windows 7 SP1 (avec patchs pour architecture CMT si nécessaires) 3d Studio Max 2011 - Mental Ray  Nous passons aux tests pratiques avec pour commencer un rendu 3d sous 3d Studio Max 2011 en utilisant le moteur de rendu Mental Ray sur une scène d'Evermotion . Le rendu est effectué en 600*375 afin de garder un temps de test raisonnable. 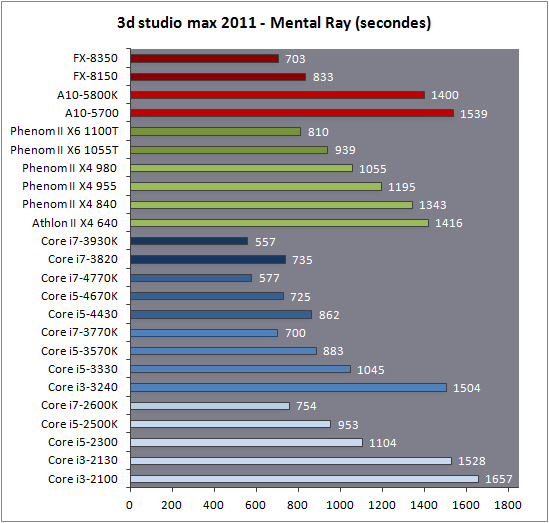 On commence fort pour Haswell avec un gain de 21 à 22% à fréquence égale par rapport à Ivy Bridge qui permet au Core i7-4770K de se rapprocher d'un Sandy Bridge-E à 6 curs, l'i7-3930K en LGA 2011. L'i5-4670K est pour sa part proche des FX-8350 et i7-3770K. 3d Studio Max 2011 - V-Ray 2.0  Toujours sous 3d Studio Max 2011, on change de moteur pour le moteur tiers le plus populaire, V-Ray 2. On utilise une autre version de la même scène préparée par Evermotion pour ce moteur, le rendu étant toujours effectué en 600*375. Les temps de rendu sont nettement plus rapides, toutefois il ne s'agit pas de comparer les moteurs entre eux puisqu'il faudrait également observer de manière très attentive la qualité des fichiers finaux. 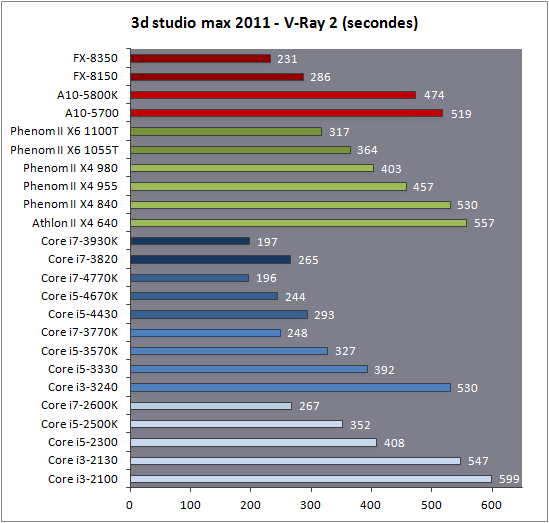 Sous ce second moteur de rendu c'est encore plus impressionnant avec 34% de gain sans Hyperthreading et 27% avec. Du coup l'i7-4770K fait jeu égal avec l'i7-3930K, alors que l'i5-4670K est au niveau de l'i7-3770K mais le FX-8350 reste plus rapide. Page 16 - CPU Compilation : Visual Studio et MinGW/GCC Visual Studio 2010 SP1  Nous compilons sous Visual Studio 2010 SP1 le code source du moteur 3D Ogre. 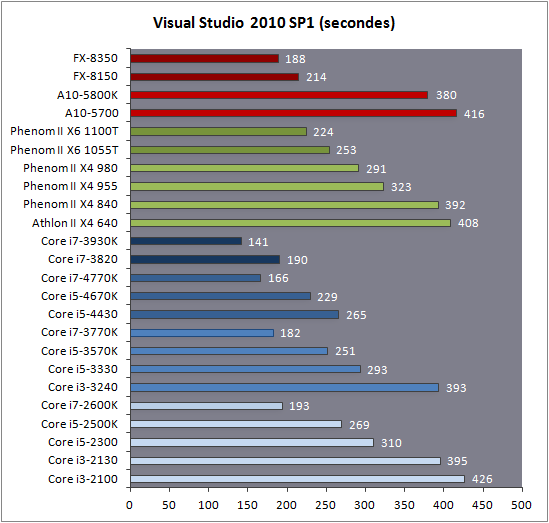 Les gains sont cette fois plus modérés avec 11 à 10% de mieux pour Haswell par rapport à Ivy Bridge. La hiérarchie habituelle n'est donc pas remise en cause, mais l'i7-4770K creuse l'écart par rapport au FX-8350 alors que l'i5 en reste loin. MinGW / GCC 4.5.2  Le même code source est cette fois compilé sous MinGW / GCC 4.5.2. 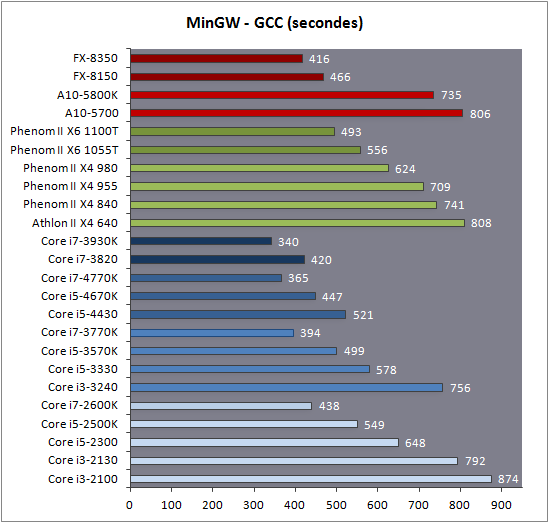 Sous MinGW le surplus de performance est de l'ordre de 8% avec Hyperthreading et 11-12% sans. Le FX-8350 est du coup pris en sandwich entre les deux derniers K, alors qu'il était plus proche de l'i7 sur la précédente génération. Page 17 - CPU Compression : 7-zip et WinRAR 7-zip 9.2  7-zip rejoint notre protocole de test. Contrairement à WinRAR ce logiciel est fortement multithreadé si on utilise son algorithme le plus performant, LZMA2. Nous mesurons le temps nécessaire pour compresser un volume important de fichiers. 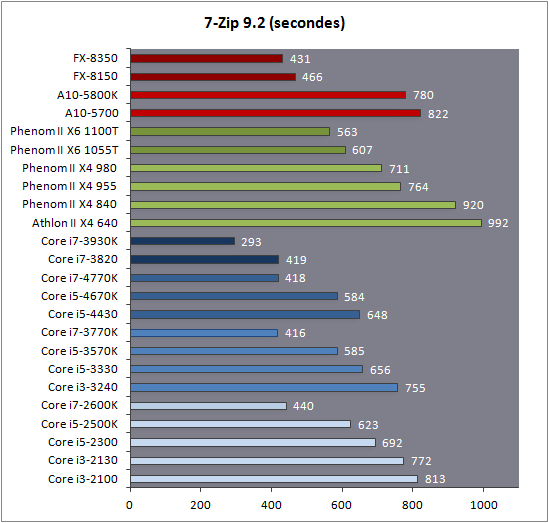 On se retrouve ici dans la situation inverse aux chiffres enregistrés pour le rendu 3D puisque les gains sont quasi nuls via Haswell, 0 à 1%. Rien ne change donc sous ce test, ce qui semble être lié à un cache L3/LLC légèrement plus lent - 21 cycles contre 18 sur Ivy Bridge. WinRAR 4.01  Les mêmes fichiers sont compressés sous WinRAR en utilisant l'algorithme RAR le plus poussé ("Best"). 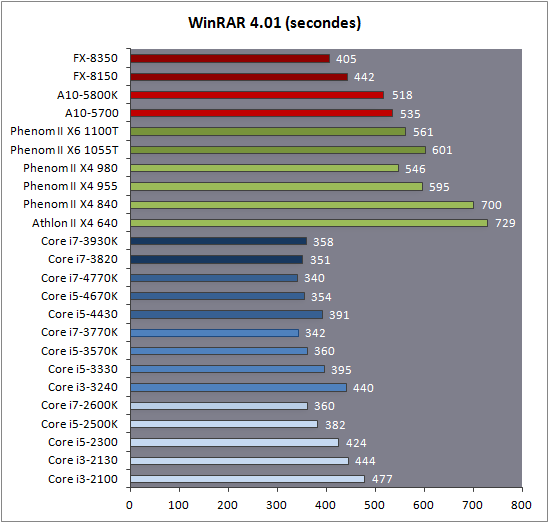 WinRAR bénéficie peu de la présence de multiples curs, ce qui n'aide pas les processeurs AMD à être bien classés. Là aussi vous pouvez circuler, il n'y a rien à voir côté Haswell, avec 1 à 2% de "mieux", le L3 n'y étant a priori pas étranger. Page 18 - CPU Encodage : x264 et Rovi H.264 StaxRip - x264 build 2216  Pour l'encodage vidéo nous avons conservé le célèbre x264, ici dans sa build 2216. Nous utilisons l'interface StaxRip pour transcoder un extrait 1080p tiré du Blu-ray du film Avatar en utilisant 2 passes en mode fast avec un bitrate de 10 Mbits /s. Les temps des deux passes sont reportés, la 1ère ne profitant pas de vraiment de plus de 3 à 4 curs, x264 étant limité par la vitesse du serveur de frame utilisé faiblement multithread (AviSynth). 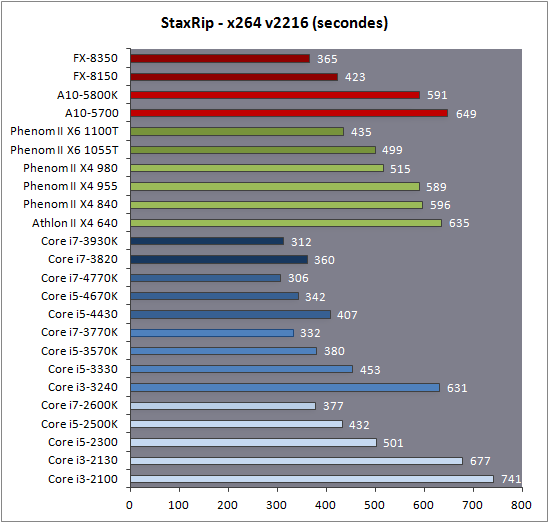 [ Total ] [ 1ère passe ] [ 2nde passe ] Le gain global apporté par Haswell par rapport à Sandy Bridge est de 8% avec HT et 11% sans, avec respectivement 3 et 5-6% sous la 1ère passe et 12 à 14% sous la seconde qui seule représente les gains auxquels ont peut également s'attendre avec un encodage à une passe. On notera que sur cette dernière, l'i7-4770K est très proche de l'i7-3930K. Le FX-8350 vient s'intercaler entre l'i7-4770K et l'i5-4670K. Bien qu'il ne nous était pas possible de refaire les benchs sur tous les processeurs, nous avons tout de même essayé la dernière build 2310 de x264 sur quelques processeurs. Depuis la 2216, les développeurs ont notamment intégré des optimisations AVX2. Voici nos relevés pour la seconde passe et les gains avec les preset Fast et Slow : - Core i5-2500K : Fast 288s (+1,7%), Slow 573s (+1,6%) - Core i5-3570K : Fast 250s (+2,4%), Slow 484s (+2,7%) - Core i5-4670K : Fast 212s (+5,7%), Slow 412s (+7,5%) - FX-8350 : Fast 199s (+1,5%), Slow 366s (+1,9%) Comme attendu, le gain est plus important sur Haswell. Du coup si en 2216 nous avions 14% de mieux en Slow et 12% en Fast pour Haswell face à Ivy Bridge, l'écart passe à 18 et 17% en 2310 grâce aux optimisations spécifiques à cette architecture. Par rapport à Sandy Bridge les gains sont de 36 et 39%, mais il faut prendre en compte le delta de fréquence (3.6 GHz contre 3.4 GHz, soit +5,9%). Rovi TotalCode 2.5 H264 Pro  On passe maintenant à un autre codec H.264, celui de Rovi (ex MainConcept). Nous utilisons l'interface Rovi TotalCode H.264 pour effectuer le même type de transcodage que sous x264. Il faut noter que la 1ère passe est mieux multithreadée et nous ne reportons cette fois que le score global. 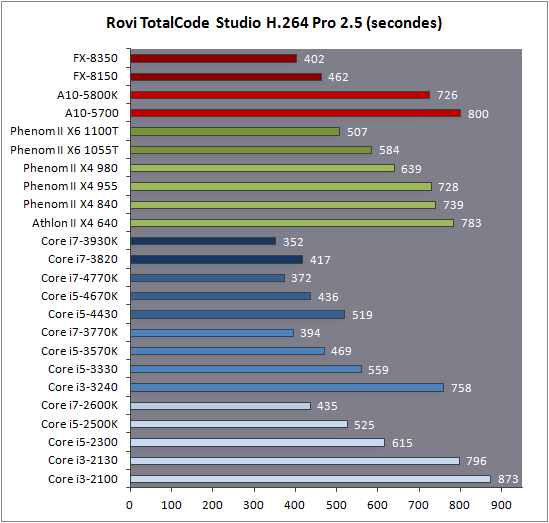 Haswell augmente les performances de 7 à 9% par rapport à Ivy Bridge alors que ce dernier augmentait déjà de manière notable les performances depuis Sandy Bridge. L'i7-3930K à 6 curs garde malgré tout une petite avance, et le FX-8350 s'intercale entre les i7-4770K et i5-4670K. Page 19 - CPU Traitement photo : Lightroom et Bibble Adobe Lightroom 3.4  Le traitement des photos par lot fait son apparition au sein de notre protocole. On commence par Lightroom au sein duquel nous exportons en JPEG un lot de 96 photos RAW issues d'un 5D Mark II tout en leur appliquant divers effets, tels que des corrections colorimétriques, d'objectif ou encore le traitement du bruit. 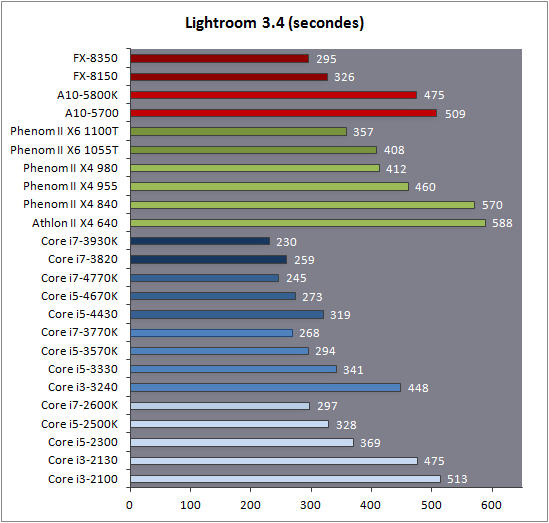 Haswell augmente les performances de 7 à 9% par rapport à Ivy Bridge alors que ce dernier augmentait déjà de manière notable les performances depuis Sandy Bridge. L'i7-3930K à 6 curs garde malgré tout une petite avance, mais le FX-8350 s'intercale seulement entre les i5-4670K et i5-4430. Bibble 5.2.2  Sous Bibble nous traitons un lot de 48 photos RAW. Vous noterez que Bibble est plus lent que Lightroom, mais comme pour les moteurs de rendu ce test n'est pas là pour comparer les logiciels entre eux d'autant qu'il faudrait alors comparer minutieusement la qualité des sorties : un export plus lent peut aussi être plus qualitatif. 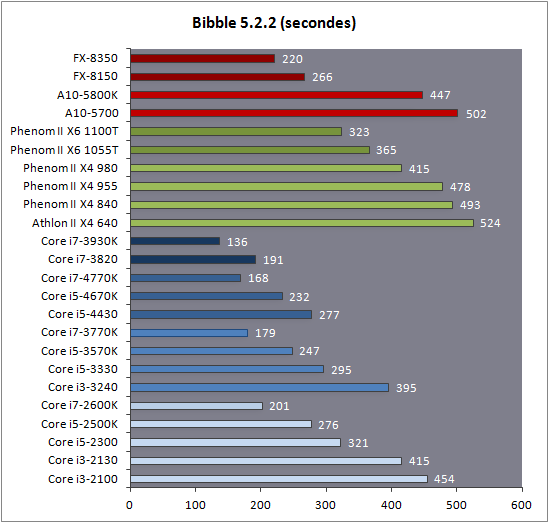 Cette fois le gain est de 6-7%, et l'avantage plus évident pour l'i7-3930K. Le FX-8350 est mieux placé puisque plus rapide que l'i5-4670K. Page 20 - CPU IA d'échecs : Houdini et Fritz Houdini 2.0 Pro  Enfin nous terminons ce tour d'horizon applicatif par un type d'application assez particulier, à savoir des algorithmes d'intelligence artificielle destinée aux échecs. On commence par Houdini Pro 2, utilisé via l'interface Arena 3. La version 1.5 trustait les 1ères places des classements des moteurs d'échecs et la version 2 semble promise au même avenir. Nous laissons tourner le moteur jusqu'au 24è tour en début de partie et notons la vitesse exprimée en Kilonoeuds par secondes. 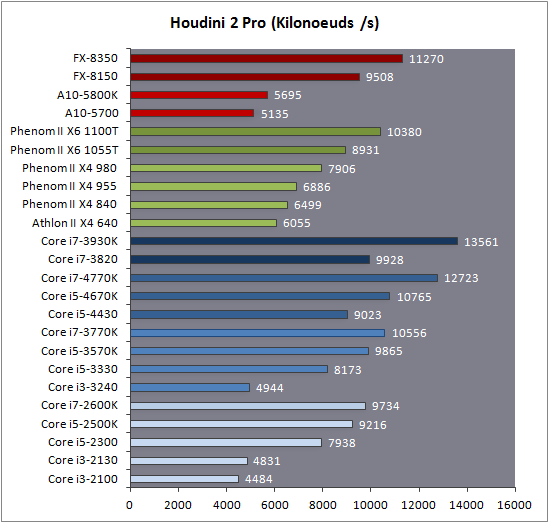 Sans Hyperthreading le gain est de 9-10%, et il grimpe à 21% en sa présence. Du coup l'écart entre du coup l'avance de l'i7-3930K fond comme neige au soleil alors que leFX-8350 est entre les i5 et i7 "K". Fritz Chess Benchmark 4.3  Nous passons maintenant à Fritz Chess Benchmarking, de l'éditeur Chess Base. Là encore les chiffres sont exprimés en Kilonoeuds par secondes. 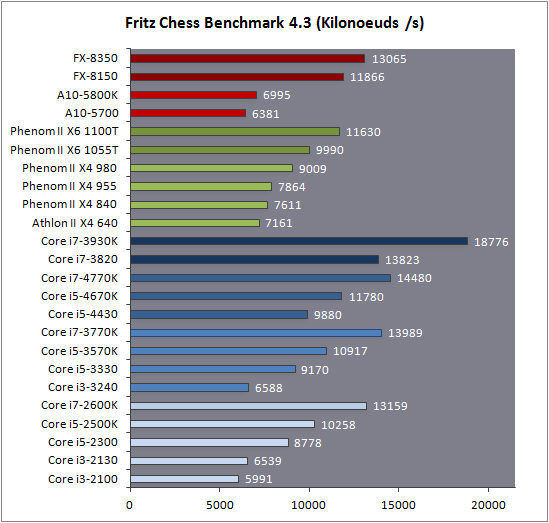 La situation s'inverse sous Fritz par rapport à Houdini et c'est cette fois sans Hyperthreading que le gain est double : 8%, contre 4% avec. L'i7-3930K est intouchable alors que le FX-8350 s'intercale entre les i5-4670K et i7-4770K. Page 21 - CPU Jeux 3D : Crysis 2 et Arma II : OA Crysis 2  Crysis 2 inaugure la partie jeux 3D de ce comparatif. Nous utilisions la dernière version 1.9 en DirectX 11 et mesurons le framerate obtenu en 1920*1080 Ultra à un emplacement précis au cours d'une fusillade. 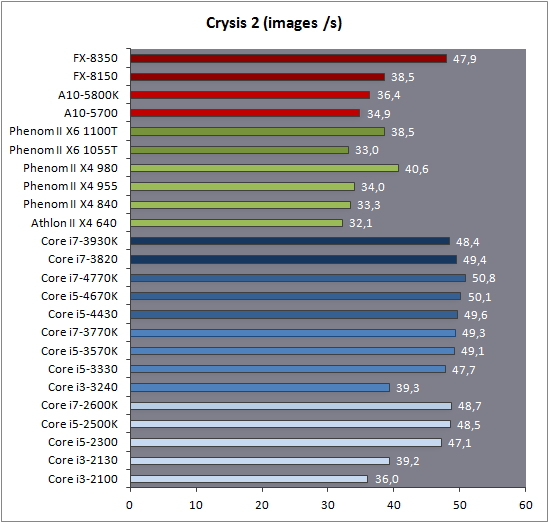 Malgré le passage à une GeForce GTX 680 nous continuons sur notre scène de test à nous heurter à un "mur" autour de 50 fps. Il ne s'agit a priori pas d'une limite liée au GPU, d'autant que lors du test d'Ivy Bridge nous avions pu voir des gains lié au passage en DDR3-2133. Le gain offert par Haswell est de fait limité à 2-4% selon les versions, avec des performances qui sont dans le groupe de tête. Arma II : Operation Arrowhead  Sous Arma II : Operation Arrowhead nous mesurons le framerate lors de la traversée d'un village lors de la première mission solo, toujours en 1920*1080 et toutes options poussées au maximum, y compris la distance de visibilité. 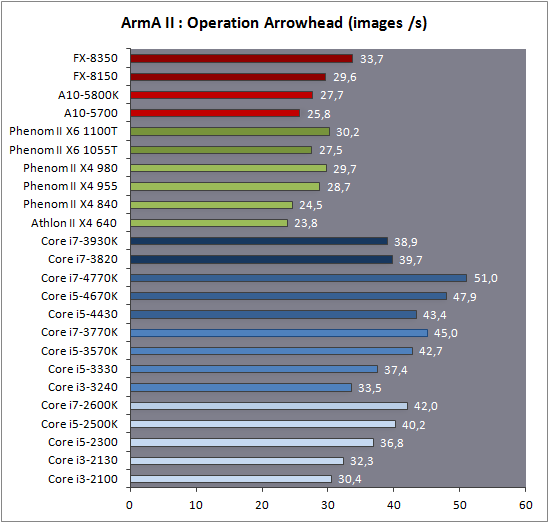 Notre test sous Arma II ne souffre pas des mêmes limitations et cette fois les Haswell permet de gagner 12 à 16% de fps par rapport à Ivy Bridge. L'avantage est donc net, tout comme l'écart face aux Sandy Bridge et Sandy Bridge-E, sans parler des processeurs AMD. Page 22 - CPU Jeux 3D : Rise of Flight et F1 2012 Rise Of Flight  Rise Of Flight, simulateur d'avions de chasses de la 1ère guerre mondiale, est utilisé en 1920*1080 avec un niveau de détail élevé. Pour ce test nous lançons une mission rapide avec un combat de 15 contre 15 appareils, le framerate étant mesuré en vue arrière sur le combat entre nos acolytes et nos adversaires. 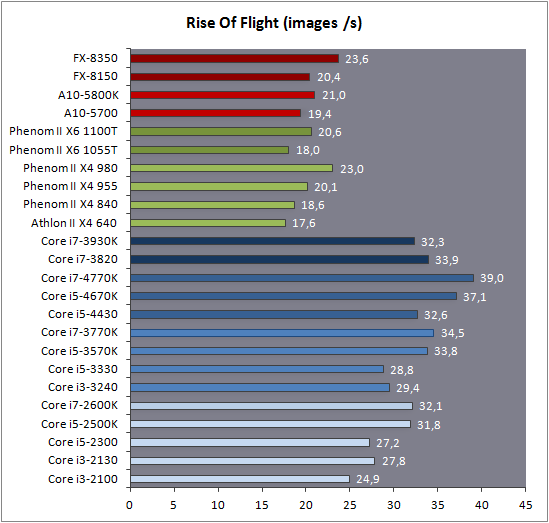 Le gain est cette fois de 10 à 13%, ce qui permet de conforter l'archi domination d'Intel sur AMD sous ce jeu. F1 2012  Le tout nouveau F1 2012 est utilisé en 1920*1080 avec les détails poussés au maximum. Nous mesurons le framerate durant le départ du GP d'Abu Dhabi. 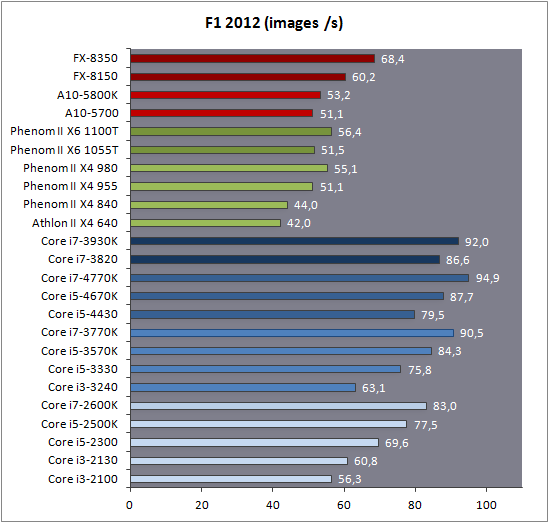 F1 2012 profite moins de Haswell avec seulement 4 à 5% de gains. Là encore les processeurs AMD sont archis dominés, et on notera par contre que le moteur tire légèrement partie de la présence de plus de 4 curs comme le montre la hausse de performance lié à l'Hyperthreading sur les 4 curs (supérieure au delta de fréquence) ou le bon positionnement de l'i7-3930K. Cela ne permet par contre pas au FX-8350 de faire mieux qu'un "vieil" i5-2300, il faut toutefois noter qu'il est rare d'avoir des scènes plus chargées que celle de test dans le jeu et que le niveau de framerate obtenu est donc déjà suffisant pour une bonne fluidité. Page 23 - CPU Jeux 3D : Total War Shogun 2 et Skyrim Total War : Shogun 2  Pour Total War : Shogun 2 nous utilisons une partie de l'immense bataille du test "DX9 CPU" modifiée pour utiliser DX11 en 1920*1080 avec un niveau de détail élevé. 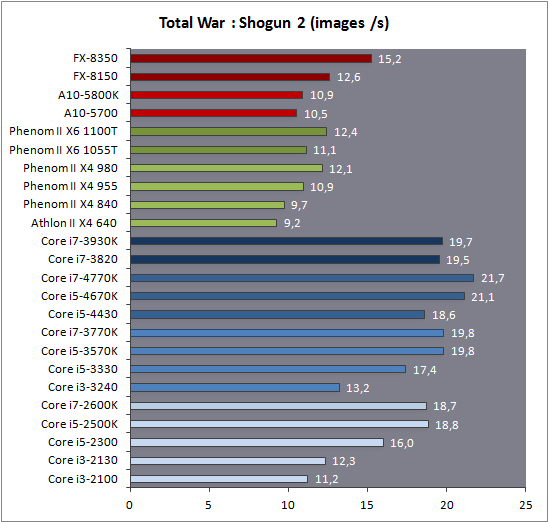 Avec 7 à 10% de mieux l'apport d'Haswell est significatif. Skyrim  Pour Skyrim nous utilisons une sauvegarde près de Faillaise (Riften) et mesurons le framerate en un endroit assez gourmand en CPU. Les détails graphiques sont poussés à leur maximum en 1920*1080 (sauf l'anti aliasing) avec également uGridsToLoad passé à 7. 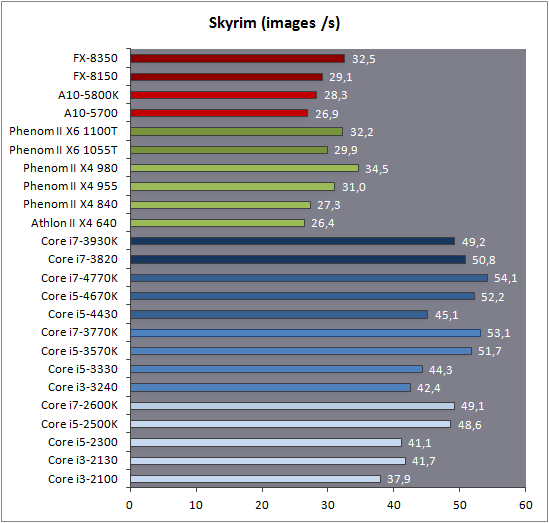 Ici l'avantage d'Haswell n'est que de 1 à 2%. Encore une fois les processeurs Intel sont largement supérieurs aux AMD sur ce jeu peu multithreadé qui demande donc surtout un bon niveau d'IPC. Page 24 - CPU Jeux 3D : Starcraft II et Anno 2070 Starcraft II  Sous Starcraft II, nous utilisons un replay spécialement enregistré par des utilisateurs du forum que nous remercions. Ce replay contient une attaque très (très) importante et nous mesurons le framerate durant cette dernière en 1920*1080 avec les détails poussés au maximum. 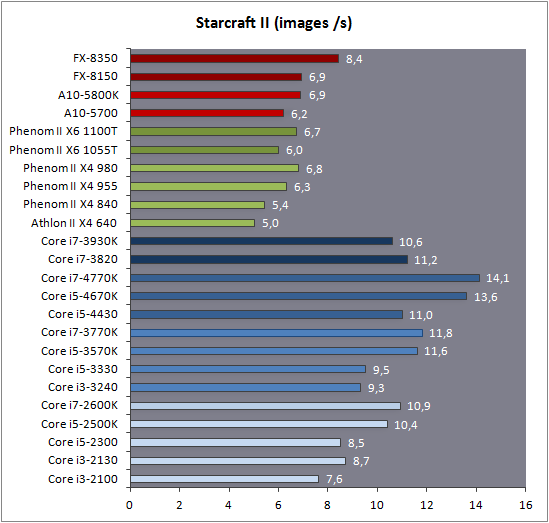 Starcraft 2 est le jeu qui profite le plus de Haswell avec 16 à 19% de mieux qu'Ivy Bridge, alors que Ivy Bridge offrait déjà des performances en hausse de 6% par rapport à Sandy Bridge. L'écart est donc important, et même si le niveau de framerate reste bas dans l'absolu il ne faut pas perdre de vue que pour ce type de jeu ne nécessite pas le même niveau d'images/s qu'un fps. Comme Skyrim, Starcraft II n'est que faiblement multithreadé et ne profite pas vraiment de plus de 2 curs, ce qui désavantage complètement les processeurs AMD. Anno 2070  Enfin pour Anno 2070 nous chargeons une sauvegarde d'une cité de 220 000 habitants que nous visualisons depuis une vue éloignée, le tout en 1920*1080 détails poussés au maximum. 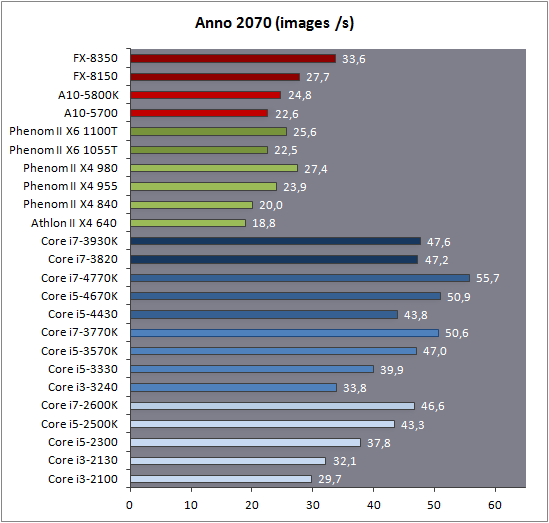 Haswell offre des gains de 8-10% ici. Là encore l'avantage est net pour la gamme Intel par rapport à la gamme AMD. Page 25 - Gains et Moyennes CPU Gains et Moyennes CPUOn commence par un récapitulatif des gains offerts par Haswell par rapport à Ivy Bridge, à fréquence égale, selon les processeurs et les tests : 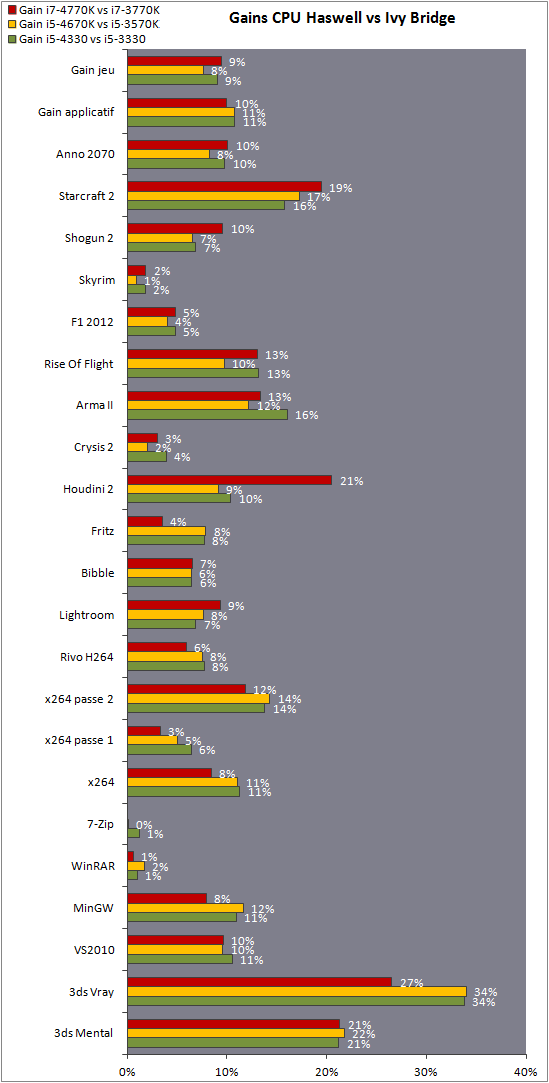 Au final le gain applicatif est de 10 à 11%, avec une absence de gain en compression de fichiers et des gains très importants dans le domaine du rendu 3d. Pour les jeux Haswell apporte 8 à 9% de mieux, les écarts étant cette fois moins important bien que sur certains titres l'apport soit minime. Passons maintenant aux moyennes. Bien que les résultats de chaque application aient tous un intérêt, nous avons calculé des indices de performances en nous basant sur l'ensemble de résultats et en donnant le même poids à chacun des tests. Nous présentons deux moyennes, l'une applicative intègre tous les tests en dehors des jeux 3D et l'autre est spécifique aux jeux 3D qui sont généralement moins multithreadés. Malheureusement nous n'avons pas eu le temps d'intégrer les plates-formes LGA 775 / 1156 / 1366 sur la mise à jour du protocole de test, néanmoins vous pouvez vous reporter à cette page pour voir les écarts à l'époque de la sortie de Ivy Bridge. 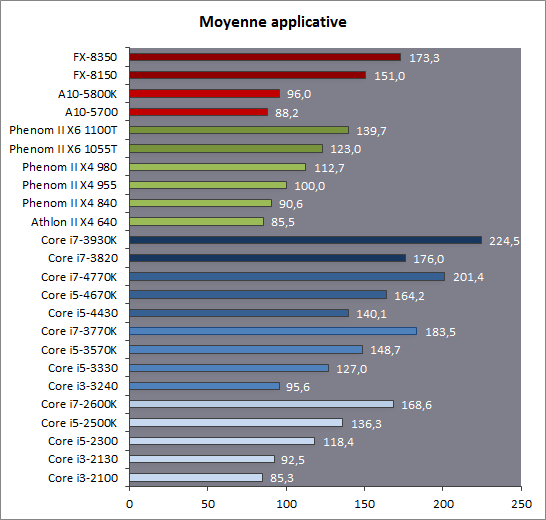 [ Standard ] [ Par performance ] Avec l'i7-4770K Intel réduit encore l'avantage de la plate-forme LGA 2011 qui est pour rappel encore en architecture Sandy Bridge. Le nouvel i5-4670K est par ailleurs quasiment au niveau d'un i7-2600K. L'offre AMD reste malgré les apparences compétitives en terme de rapport performance / prix grâce à un positionnement agressif, avec bien entendu comme défaut une efficacité énergétique inférieure. 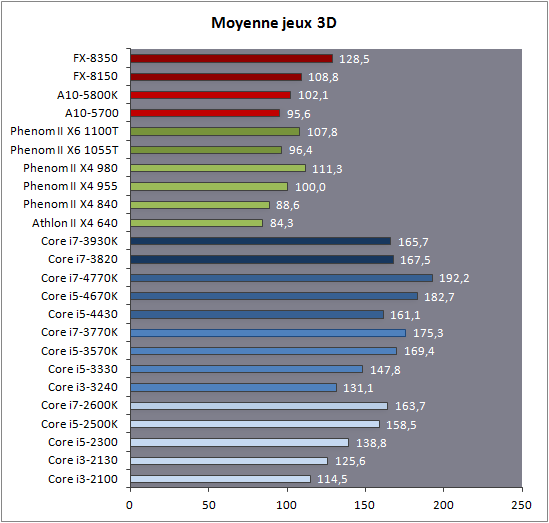 [ Standard ] [ Par performance ] Dans les jeux 3D le fait de disposer de plus de 4 curs n'apporte sauf exceptions pas de gain, ce qui permet du coup à la nouvelle gamme Intel Core de 4è génération d'être la plus performante dans ce domaine, devant les processeurs LGA 2011. L'écart par rapport à la gamme AMD est énorme, pour les mêmes raisons, et si l'usage principal de votre machine est ludique il vaut donc mieux rester chez Intel, sauf à compter sur l'arrivée en masse de moteurs de jeux mettant plus l'accent sur le multithread que sur les performances unitaires d'un nombre de curs limités, chose que pourrait favoriser les consoles de nouvelle génération. Bien entendu nous avons cherché au travers de nos tests des cas où les performances ludiques sont limitées par le CPU et non pas le GPU, ceci malgré l'utilisation du 1920*1080 et de détails élevés. Forcément, si on utilise des scènes moins lourdes côté CPU et/ou on augmente encore les réglages graphiques impactant uniquement le GPU de manière à ne plus permettre d'atteindre les framerates rendus possibles sur les CPU les plus performants (via l'AA ou la résolution ... ou en baissant la puissance du GPU !) il est possible de resserrer les rangs. Page 26 - Conclusion ConclusionL'arrivée d'un "Tock" chez Intel est toujours un événement important, et les Intel Core de 4è génération n'échappent pas à la règle. Avec ces Haswell, le géant de Santa Clara introduit de nombreuses nouveautés, dont certaines sont cependant quasiment exclusivement destinées aux portables et ultra-portables. On pense notamment aux iGPU les plus musclés, qui ne sont même pas disponibles en LGA 1150, à l'intégration du chipset sur le même packaging ainsi qu'aux efforts destinés à encore abaisser la consommation du processeur voir de la plate-forme lorsqu'elle est inactive. Sur nos chers PC de bureau, on retiendra bien entendu les améliorations de l'architecture qui entrainent un gain de performance pratique de l'ordre de 10% à fréquence égale en moyenne par rapport au "Tick" Ivy Bridge. Cela n'a rien de révolutionnaire donc, mais l'avancée est à saluer tant l'architecture était déjà efficace. Bien entendu dans le passé nous avons connu des sauts de performance plus spectaculaires, mais le gain d'IPC était associé soit à une augmentation du nombre de cur, de la fréquence, ou à l'intégration du contrôleur mémoire dans le processeur. L'intégration du régulateur de tension simplifie pour sa part le design des cartes mères et permet de mieux en utiliser les phases et uniformise les possibilités de modification de tension, ce qui est toujours bon à prendre. Par contre les avancées dans le domaine de l'overclocking tel que la possibilité d'augmenter la fréquence DMICLK ne sont d'aucune utilité en pratique puisque limitées aux processeurs "K", et au contraire les processeurs non "K" sont plus limités qu'ils ne l'étaient auparavant. De plus nos i7-4770K et i5-4670K ne se sont pas montrés particulièrement à l'aise en overclocking, et un meilleur refroidissement est nécessaire du fait d'une augmentation de la consommation qui reste néanmoins mesurée.  Les chipsets Intel Serie 8 permettent enfin de disposer d'un nombre de ports USB 3.0 et SATA 6 Gb /s plus conséquent, 6 chacun, mais Intel reste malgré tout frileux puisque ceci se fait au dépend du nombre de lignes PCI-Express qui peuvent être gérées. Ces dernières sont de plus encore en PCI-Express Gen2, tout comme le lien DMI reliant processeur et chipset qui mériterait d'être musclé. A défaut d'être le plus rapide de la gamme Haswell, l'iGPU HD Graphics 4600 (GT2) offre pour sa part un niveau de performances un peu plus proche de ce que propose AMD avec Trinity. Le gain par rapport à l'HD 4000 d'Ivy Bridge est relativement variable en fonction de la résolution mais n'est pas négligeable, au point que les cartes d'entrée de gamme (particulièrement celles équipées de DDR3) deviennent de plus en plus inutiles. Bien entendu, sur plateforme desktop la question des performances de l'iGPU peut passer pour secondaire, quelque chose que l'on doit aussi à Intel qui n'aura pas fait l'effort de proposer une déclinaison de ses GPU les plus véloces. C'est particulièrement regrettable et il faudra garder un oeil attentif sur les performances des déclinaisons GT3 et GT3e sur les futures machines portables qui en seront équipées, GT3e devant offrir en pratique des performances 50 à 75% supérieures au GT2, de quoi être au niveau d'une 6670 GDDR5. En ce qui concerne QuickSync, malgré quelques améliorations supposées, nous n'avons pas pu constater de gain de qualité. Un problème qui n'est peut être pas totalement lié à Haswell, mais surtout au logiciel fourni par Intel. En attendant de voir la nouvelle version des APU MediaSDK déployées sur d'autres logiciels, nous resteront sur notre faim, en gardant a l'esprit la volonté d'Intel de travailler avec le monde open source, et notamment les développeurs de HandBrake. Nous tenons à revenir sur la segmentation détestable mise en place par Intel. Si c'est au niveau de l'iGPU qu'elle est la plus voyante, les versions les plus musclées étant réservées aux secteur mobile ce qui peut néanmoins avoir du sens vu l'intérêt limité d'un iGPU "moins lent" sur desktop, Intel continue sur sa lancée et le VT-d, qui permet la virtualisation des I/O, n'est toujours pas disponible sur les K. Pire, Haswell introduit de nouvelles instructions TSX-NI qui ne sont pas disponibles sur les K ainsi que d'autres modèles, tels que la gamme R ainsi que les i5-4430 sur Desktop et certains processeurs mobiles...  Au final, faut-il céder aux charmes de Haswell, alors que comme d'habitude dans un premiers temps les cartes mères LGA 1150 devraient être plus chères que les LGA 1155 à caractéristiques égales et qu'Intel en a profité pour légèrement augmenter ses tarifs (7 à 8$ de plus par rapport à Ivy, voir 17$ pour l'i5 K) ? Si vous visez le moyen et le haut de gamme, nous répondons par la positive, mais si votre budget est serré vous aurez tout intérêt à profiter des tarifs plus avantageux de la gamme précédente. Mais sauf exceptions le changement n'en vaudra vraiment la peine que si vous disposez d'une plate-forme antérieure à LGA 1155 + Sandy Bridge ! Copyright © 1997-2026 HardWare.fr. Tous droits réservés. |