| |
| |
| Nvidia GeForce GTX 750 Ti & GTX 750 : Maxwell fait ses débuts Cartes Graphiques Publié le Mercredi 26 Février 2014 par Damien Triolet URL: /articles/916-1/nvidia-geforce-gtx-750-ti-gtx-750-maxwell-fait-ses-debuts.html Page 1 - Introduction Une fois n'est pas coutume, c'est par le bas de la gamme que Nvidia a décidé d'introduire sa nouvelle architecture GPU, nom de code Maxwell. Au menu, un nouveau bond en avant sur le plan de l'efficacité énergétique. De quoi permettre aux GeForce GTX 750 Ti et GTX 750 de se démarquer face à une rude concurrence sur le segment 100-150 ? C'est ce que nous allons vérifier à travers nos tests complets, sans oublier de nous pencher en détails sur cette nouvelle architecture.  Consommation divisée par 4 en 4 ansNvidia a pour habitude de positionner ses nouveaux GPU par rapport à un modèle précédent, comparaison toujours savamment choisie pour mettre en avant le nouveau venu. Cela fait partie des éléments de communication que nous avons l'habitude d'ignorer, mais ils peuvent dans certains cas ne pas être totalement dénués d'intérêt. Nvidia compare ainsi la petite GeForce GTX 750 Ti à la grosse GeForce GTX 480 de 2010 pour illustrer l'évolution du rendement énergétique. La première est annoncée avec des performances proches de celles de la seconde pour un TDP divisé par 4. Nous avons bien entendu cherché à obtenir nos propres chiffres : 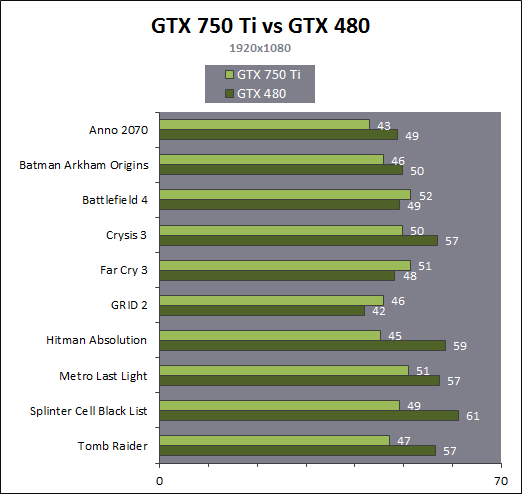 Avec 92% des performances d'une GeForce GTX 480 pour la GTX 750 Ti, et un TDP réduit de 250W à 60W (notez que dans les deux cas Nvidia prend ses aises par rapport à la définition du TDP), l'affirmation de Nvidia est bel et bien correcte. Pour en tirer le point intéressant de l'histoire, il faut cependant s'intéresser aux conditions dans lesquelles cette affirmation est vérifiée : en 1080p avec des options graphique adaptées au niveau de performances de ces solutions dans les jeux actuels. Avec un bus mémoire 3x plus large et 3x plus de ROP pour écrire les pixels en mémoire et traiter l'antialiasing de type MSAA, il ne fait aucun doute que la GeForce GTX 480 n'aurait aucun de mal à pouvoir écraser la GeForce GTX 750 Ti dans d'autres conditions. Il se trouve cependant que depuis 4 ans les alternatives au MSAA se sont développées et que, par ailleurs, quand les cartes graphiques commencent à souffrir en termes de performances, il s'agit d'une option graphique qui se retrouve désactivée par de nombreux joueurs. En d'autre terme, ce qu'il faut comprendre, ce n'est pas que le nouveau petit GPU GM107 de la GeForce GTX 750 Ti est aussi performant que le gros GPU GF100 de la GeForce GTX 480, mais qu'il représente un rééquilibrage de l'architecture de manière à l'optimiser pour les charges qu'un tel GPU doit généralement traiter en 2014, en plus de continuer dans la voie logique vers plus d'efficacité énergétique. C'est également pourquoi avec une puce seulement 25% plus large que celle des GeForce GTX 650 (le GK107), Nvidia va doubler ses performances, comme nous allons le voir. Mais avant cela, nous allons tout d'abord nous pencher en détails sur l'architecture Maxwell de première génération Page 2 - Maxwell 1st gen: 28nm, aperçu global 1.9 milliards de transistors pour le premier GPU MaxwellAvec Maxwell, nom de code sa nouvelle architecture, Nvidia continue l'effort entrepris lors du passage de Fermi vers Kepler, pour une meilleure efficacité énergétique. C'est d'autant plus nécessaire que pour ce premier GPU, pour lequel Nvidia précise "Maxwell de première génération" (ce qui implique qu'il y en a une seconde), le procédé de fabrication n'évolue pas et reste la même variante du 28 nanomètres de TSMC (HP) que pour l'ensemble des GPU Kepler. Les GPU Maxwell de seconde génération devraient présenter quelques retouches au niveau de l'architecture et surtout exploiter un process plus évolué qui sera probablement le 20 nanomètres de TSMC. Pour rappel, voici la liste des GPU actuellement fabriqués par Nvidia en 28 nanomètres : GK110 : 7.1 milliards de transistors pour 551 mm² GK104 : 3.5 milliards de transistors pour 294 mm² GK106 : 2.5 milliards de transistors pour 214 mm² GM107 : 1.9 milliards de transistors pour 148 mm² GK107 : 1.3 milliards de transistors pour 118 mm² GK208 : 1.0 milliards de transistors pour 79 mm²  Le GM107 de Nvidia. Un petit calcul rapide montre que les 3 GPU les plus récents de Nvidia, à savoir les GK110, GK208 et GM107, affichent une densité de transistors un peu plus élevée que celle de ses premières puces fabriquées en 28 nm. Ceci peut s'expliquer par une petite évolution des règles de design et sur un effort d'optimisation plus poussé mais aussi par la proportion de mémoire SRAM (plus dense que les autres circuits) qui peut être plus élevée, ce qui est particulièrement le cas pour les GPU GM107 et GK208. Le GM107 se place ainsi logiquement entre les GK107 et GK106. Grâce à l'évolution de son architecture, ce GM107 est cependant plus proche du GK107 en terme de taille de puce, de coûts de fabrication et de consommation mais est par contre plus proche du GK106 sur le plan des performances, sans toutefois pouvoir égaler celui-ci. A noter que pour ce lancement, Nvidia a décidé de ne communiquer d'une manière générale qu'un nombre très limité de détails, tout en nous donnant l'opportunité de creuser le sujet en envoyant des questions aux responsables techniques. Ainsi, dans cette analyse de l'architecture, les détails découlent en partie de ces échanges et en partie de tests ciblés qui nous permettent d'observer le comportement des différents GPU. Le cache L2 du GM107 explose : 2 MoAlors que les GPU Kepler reposaient sur des blocs fondamentaux appelés SMX (Streaming Multiprocessor), qui contiennent unités de calcul et autres unités de texturing, ceux-ci sont appelés SMM dans le cas de la génération Maxwell. Ils ont subi un régime assez drastique afin de les simplifier suffisamment pour pouvoir en augmenter significativement le nombre. Tout comme les SMX, les SMM sont organisés en petits groupes, appelés GPC (Graphics Processing Cluster). Chaque GPC inclus un moteur de rastérisation qui reçoit les triangles traités par les SMX/SMM, les découpes en pixels avec lesquels il forme de petits groupes qui sont renvoyés vers les SMX/SMM en vue de leur calcul. Alors que sur Kepler, les GPC sont formés de 1, 2 ou 3 SMX suivant les produits, le GM107 se contente d'un seul gros GPC équipé de 5 SMM. Voici une représentation visuelle des différents GPU d'entrée / milieu de gamme de Nvidia (notez que la représentation miniature des SMX/SMM est basée sur la version officielle qui n'est pas tout à fait correcte comme nous le verrons par la suite) : 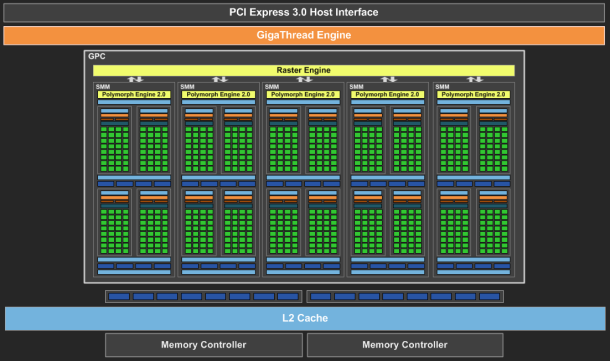
Si nous comparons le GM107 au GK107, nous pouvons observer que Nvidia conserve la même structure de base du GPU, à savoir 1 GPC et 2 contrôleurs mémoire 64-bit, mais passe de 2 SMX à 5 SMM et de 256 à 2048 Ko de cache L2. Un dernier point intéressant à observer, voici pour comparaisons les spécificités de tous les GPU 28 nm de la marque : GK110 : 5 GPC, 15 SMX, bus 384-bit, 1536 Ko de L2 GK104 : 4 GPC, 8 SMX, bus 256-bit, 512 Ko de L2 GK106 : 3 GPC, 5 SMX, bus 192-bit, 384 Ko de L2 GM107 : 1 GPC, 5 SMM, bus 128-bit, 2048 Ko de L2 GK107 : 1 GPC, 2 SMX, bus 128-bit, 256 Ko de L2 GK208 : 1 GPC, 2 SMX, bus 64-bit, 512 Ko de L2 Nous pouvons constater que Nvidia est passé d'un cache L2 de 128 Ko par contrôleur mémoire 64-bit sur les premiers GPU Kepler à 256 Ko sur le GK110 puis à 512 Ko pour le GK208 et enfin à 1024 Ko pour le GM107. Auparavant, nous avions interrogé Nvidia (mais également AMD) sur les raisons qui faisaient qu'ils n'optaient pas pour un cache L2 plus important. Leur réponse avait été similaire : cela a un coût élevé pour un rendement réduit dans le cas d'un GPU. Une explication logique : puisque les GPU sont des machines prévues pour masquer une énorme latence, plusieurs centaines de cycles, et qui effectuent des accès plutôt séquentiels qu'aléatoires, les caches généraux ont moins d'importance. Du coup qu'est-ce qui a changé avec le GM107 ? Pourquoi celui-ci bénéficierait-il plus d'un gros cache L2 ? Nvidia nous a répondu que pour ce GPU GM107, compte tenu de la non-évolution du bus mémoire par rapport au nettement moins véloce GK107, le compléter par un plus large cache L2 était une bonne idée. Le plus large cache L2 viendrait donc en quelque sorte compenser pour le manque d'évolution des interfaces mémoire. De notre côté nous rajouterons qu'il y a probablement d'autres arguments en jeu tels qu'une réduction progressive du coût du cache L2 avec l'évolution des procédés de fabrication et un intérêt grandissant pour celui-ci dans le cadre du GPU computing. 1.66 triangles et 16 pixels par cycleLe GM107 intègre un GPC et par conséquent un seul moteur de rastérisation, ce qui signifie que le débit de triangles affichés à l'écran est de 1 par cycle, tout comme pour le GK107, un point qui peut être important avec un niveau de tessellation élevé. N'exploiter qu'un seul GPC pour ce GPU Maxwell de première génération permet de simplifier le design de la puce, notamment au niveau du tissu d'interconnexion global du GPU, ce qui autorise probablement des gains sur le plan de la consommation. Cela fait partie des points sur lesquels Nvidia a travaillé dans le cadre du GPU GK20A du Tegra K1, qui pousse par contre la simplification plus loin en n'intégrant qu'un seul SMX. Un second GPU Maxwell serait en préparation, le plus petit GM108, et reprendrait évidemment ce même principe d'un seul GPC, peut-être avec 2 ou 3 SMM et bus 64-bit. Sur Kepler, chaque moteur de rastérisation est capable de débiter jusqu'à 8 pixels par cycle, si le triangle en couvre au moins autant. Pour autoriser un débit de 16 pixels par cycle pour le GM107, équipé de 16 ROP, Nvidia a poussé son moteur de rastérisation à un débit équivalent, mais nous ne savons pas s'il s'agit d'une particularité spécifique à l'architecture Maxwell ou au GM107. A noter que tout comme les SMX, les SMM sont capables de débiter 128 bits de pixels par cycle, ce qui équivaut à 4 pixels 32-bit ou à 2 pixels HDR. Avec 5 SMM, et même avec 4 SMM dans le cas de la version castrée du GM107 utilisée sur la GeForce GTX 750, le débit de 16 pixels par cycle peut donc être soutenu. Du côté du traitement de la géométrie, les SMX sont capables de charger un vertex tous les deux cycles, mais ce débit a été réduit à un vertex tous les 3 cycles pour chaque SMM (ce qui correspond au chargement de 1 triangle par cycle quand le maillage des objets est optimisé). Comme nous le disions plus haut, le débit de triangles affichés à l'écran est de 1 par cycle et 3 SMM permettent donc de le maintenir. Par contre, dans le rendu 3D en temps réel, il n'y a pas que des triangles qui sont réellement rendus et affichés, nombreux sont ceux qui sont masqués parce qu'ils sont en dehors du champ de vision ou parce qu'ils tournent le dos à la caméra (c'est le cas statistiquement de la moitié des triangles qui composent personnages et autres objets). Le débit du culling, qui consiste à éjecter du pipeline de rendu ces triangles masqués, est donc important lui aussi. Cette opération est traitée au niveau des SMX ou des SMM avec le débit maximal de ceux-ci. Le SMX pouvait donc éjecter du rendu un triangle tous les 2 cycles, contre un tous les 3 cycles pour le SMM. Une GTX 750 Ti, avec 5 SMM peut ainsi traiter jusqu'à 1.67 triangle/cycle quand ceux-ci ne poursuivent pas leur chemin jusqu'au rendu final, contre 1.33 triangle/cycle pour la GTX 750, 1 triangle/cycle pour le GK107 et jusqu'à 2.5 triangles/cycle pour le GK106. Moteur vidéo boostéLes GPU Maxwell de première génération reprennent le bloc vidéo NVENC introduit sur Kepler mais boosté pour l'occasion. L'encodage H.264 qui pouvait être traité à 4x la vitesse qui équivaut au temps réel (1080p30 ?) sur Kepler est 50 à 100% plus rapide, alors que le décodage est 8 à 10x plus rapide. La consommation se retrouve réduite d'une part grâce à un nouveau cache local pour le décodeur, et d'autre part à travers un nouveau power state, le GC5, qui a été calibré spécifiquement pour les charges GPU légères. Page 3 - Maxwell 1st gen: le SMM en détails Le SMM en détailDans sa communication globale, Nvidia présente Kepler comme architecturé autour de SMX monolithiques face à Maxwell dont les SMM ont été partitionnés pour plus d'efficacité : 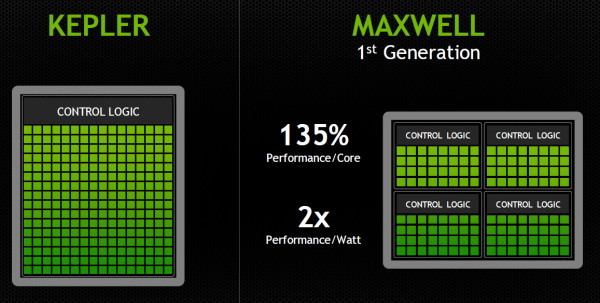 Cette présentation des choses n'est cependant pas tout à fait correcte. Plus que d'une réalité technique, il s'agit en fait d'une histoire technique simplifiée, facile à vendre et préparée par les services de marketing et de communication de Nvidia pour aider les journalistes à illustrer leurs différents articles, quitte à les induire en erreur. La réalité est différente et plus complexe puisque les SMX des GPU Kepler sont en fait eux-aussi partitionnés en 4, avec à chaque fois un fichier registre et des ordonnanceurs distincts. Si les SMX des GPU Kepler sont déjà partitionnés en 4 comme les SMM Maxwell, la différence principale à leur niveau est alors à chercher du côté des ressources que se partagent ces partitions. Nvidia a en effet revu l'organisation interne des SMM de manière à augmenter leur rendement aussi bien énergétique que par unité de surface. Pour cela, le ratio d'unités de calcul par unité de texturing augmente, une évolution logique depuis quelques années qui permet de s'adapter aux algorithmes de rendu graphique de plus en plus complexe sur le plan arithmétique. Ensuite, Nvidia se sépare de certains blocs d'unités de calcul qui en pratique étaient peu utilisés, ce qui fait mécaniquement augmenter le rendement des unités restantes. Au final nous passons de 24 flops par unité de texturing sur Kepler (excepté GK208) à 32 flops par unité de texturing sur Maxwell, avec, qui plus est, une meilleure utilisation de cette puissance de calcul. Pour représenter cela plus en détail, nous avons modifié des diagrammes d'architecture de Nvidia de façon à nous rapprocher de la réalité, au mieux de nos connaissances actuelles des différentes architectures : 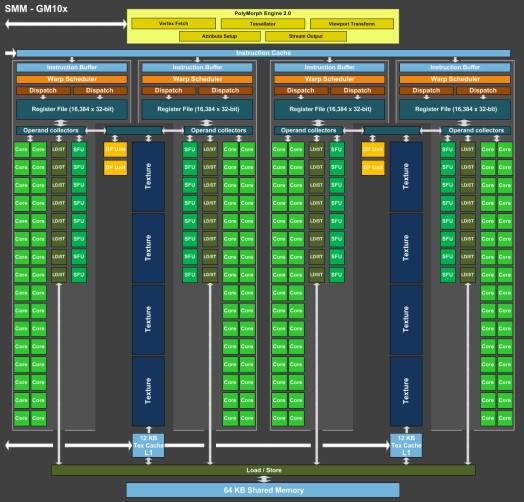
En plus grand : Comme le montrent ces illustrations, Nvidia a en réalité simplifié le SMM sur 2 points principaux. Premièrement, les blocs de 4 unités de texturing ont été mis en commun par paire de partitions, comme c'était déjà le cas sur le GK208 et le GK20A (Tegra K1) et contrairement aux autres GPU Kepler pour lesquels chaque partition d'un SMX dispose de son propre bloc. C'est ce point qui fait augmenter automatiquement le ratio d'unités de calcul par unité de texturing. Ces dernières sont gourmandes notamment parce qu'elles ont besoin de voies d'accès royales au sous-système mémoire du GPU. Deuxièmement, le nombre d'unités de calcul est réduit, mais dans une moindre mesure. Pour rappel, chaque paire de partitions d'un SMX Kepler dispose de trois unités vectorielles SIMD 32-way (ou SIMT en langage Nvidia), capables de traiter les opérations simples de type FMA, FADD, FMUL etc. Une unité SIMD 32-way correspond à "32 CUDA cores" dans le langage marketing officiel, une notion du "core" bien entendu questionnable, mais ce n'est pas nouveau. Nous présumons que l'une de ces unités SIMD est rattachée à une partition et donc à un ordonnanceur particulier alors que la troisième est partagée. Il est cependant possible que physiquement les 3 SIMD 32-way soient en fait partagées, Nvidia ne veut pas communiquer ce détail, mais dans tous les cas il semble évident que compilateurs et ordonnanceurs ne profitent pas réellement de cette flexibilité, d'où notre supposition. Exploiter ces unités de calcul SIMD 32-way supplémentaires s'est avéré difficile sur Kepler, probablement parce que le fichier registre n'offre pas suffisamment de bande passante et/ou de flexibilité au niveau des accès à ses différentes banques. Il est dès lors difficile de pouvoir obtenir toutes les opérandes nécessaires pour alimenter l'ensemble de ces unités, et en pratique elles le sont rarement. D'après les chiffres communiqués par Nvidia, ces 50% d'unités de calcul supplémentaires, qui permettent d'afficher une puissance de calcul brute en nette hausse, n'apportent qu'un gain pratique d'un peu plus de 10%. C'est donc logiquement que Nvidia a supprimé cette SIMD 32-way supplémentaire des SMM. Ainsi quand Nvidia annonce un rendement par "cur" en hausse de 35% pour Maxwell, cela ne veut pas dire que les unités de calcul principales ont été améliorées, mais que ce bloc mal utilisé a été supprimé. Le travail de l'ordonnanceur et du compilateur s'en trouve simplifié, ce qui permet des gains énergétique du côté du premier et la possibilité de pousser plus loin certaines optimisations du côté du second. Par ailleurs, Nvidia laisse penser - mais sans vouloir le confirmer clairement - que les SIMD SFU 16-way d'assistance pour le traitement des opérations spéciales, qui déchargent les SIMD 32-way principales lorsqu'il s'agit de traiter des opérations de type SINCOS, EXP, LOG etc., étaient partagées sur Kepler mais ont été scindées en deux sur Maxwell. Chacune des partitions du SMM disposerait ainsi de sa propre SIMD SFU 8-way. Les unités LD/ST (load/store) qui s'occupent des chargements / écritures de données (typiquement des registres supplémentaires via le L1 quand le fichier registre principal déborde, de la mémoire partagée ou des constantes) ont elles aussi été scindées en deux et liées à une partition particulière. Nvidia nous précise cependant que seule la première partie de ces unités, celle qui initie les commandes, est locale aux partitions, l'autre partie de ces unités étant globale et plus proche du sous-système mémoire. Enfin, Nvidia nous indique que dans le SMM, les unités de calcul double précision sont distinctes des SIMD 32-way principales et se trouvent sur le côté, ce qui nous laisse penser qu'il s'agit d'un bloc de 2 unités 64-bit partagé entre 2 partitions. Le débit en double précision est donc équivalent à 1/32ème du débit en simple précision, un ratio inférieur à celui de 1/24ème des SMX Kepler et qui par ailleurs ne prend pas en compte le fait que les SFU n'assistent pas les unités principales en 64-bit. Au final, en passant du SMX au SMM nettement plus petit, Nvidia a donc supprimé la moitié des unités de texturing, la moitié des unités de calcul 64-bit et un tiers des unités de calcul 32-bit. Malgré cela, en ne conservant que le plus utile aux charges modernes, le SMM conserverait des performances proches de celles du SMX, de l'ordre de 90% selon Nvidia. Bien entendu, en jeu et quand le texturing prend beaucoup d'importance, ce nouveau SMM pourra être amené à se contenter de 50% des performances du SMX. Page 4 - Maxwell 1st gen: du mieux pour le GPU computing GPU computing : des petites retouches qui font la différenceAprès avoir atteint une limite thermique avec Fermi, Nvidia a fait le choix de donner la priorité à l'efficacité énergétique. Des travaux d'optimisation qui ont posé les bases de Kepler et nous ont amenés vers Maxwell. Un choix qui a entraîné des compromis, notamment une rationalisation des possibilités offertes au GPU computing. A l'inverse, AMD a mis en place une architecture GCN très flexible à ce niveau, ce qui lui a permis par exemple d'être très performante dans le cadre des algorithmes liés aux crypto-monnaies (Litecoin etc.). Ce n'était pas un choix spécifique d'AMD de viser cet usage potentiel, mais une heureuse incidence de ses choix de flexibilité. Dans ce même domaine, les GPU Kepler souffrent, Nvidia n'ayant pas pris en compte cet usage lors du design de son architecture. Mais progressivement, l'architecture de ses GPU reçoit de petites retouches plus ou moins spécifiques pour "débloquer" des situations jugées importantes. C'est de toute évidence le cas des crypto-monnaies (mais en fait de tout ce qui est cryptage en général). Voici en résumé les améliorations : - augmentation du débit des opérations logiques et sur les entiers - réduction de la latence des unités de calcul - possibilité d'utiliser plus de 63 registres par thread (jusqu'à 255) - la mémoire partagée totale passe de 48 à 64 Ko par SMM - le texture cache peut faire office de L1D comme sur le GK110 - support du Dynamic Parallelism comme sur le GK110 Nous avons pu réaliser quelques tests synthétiques avec différents outils, dont ceux de SiSoft Sandra, et observer de nets gains (x2, x3, x5!) dans certains cas, notamment dans certains algorithmes liés aux crypto-monnaies. Rien ne nous garantit cependant que l'optimisation de ces algorithmes est poussée de la même manière pour toutes les architectures et il est difficile d'en tirer des conclusions si ce n'est qu'il semble bel et bien qu'il y ait une amélioration importante en pratique dans certains domaines. Notez également à ce sujet que Sandra met en avant une réduction significative de la latence mémoire, mais sans contrôle sur ce test il est difficile de savoir ce qu'elle représente et ces résultats pourraient être mal interprétés. Contrairement à un CPU, un GPU est conçu pour masquer de fortes latences et travaille de manière à le faire. Quand un logiciel montre une latence en baisse, cela ne veut pas dire obligatoirement qu'il y a une amélioration des caches ou de l'interface mémoire, mais peut être simplement que pour une raison x ou y le GPU s'est préparé à masquer une latence moindre. Plus en détails pour les plus courageuxNvidia nous a expliqué avoir boosté significativement le débit de certaines opérations logiques et sur les entiers. Par exemple, les multiplications 32-bit (et MAD) sur les entiers étaient traitées avec un débit équivalent à la moitié de celui des calculs flottants sur Fermi mais était tombé à 1/6ème sur Kepler, soit 32 par cycle par SMX. Nvidia ne spécifie pas le débit sur Maxwell mais indique qu'il est plus élevé. La seule possibilité logique semble être de passer le SMM de 32 à 64 multiplication entières par cycle soit un débit de 1/2, comme sur Fermi. Nvidia précise avoir également accéléré certaines instructions de type shift (comme le funnel shift), très utiles aux crypto-monnaies et avoir ajouté de nouvelles instructions spécifiques pour accélérer les opérations arithmétiques sur les pointeurs. Toujours sur le plan des unités de calcul, Nvidia a revu leur latence à la baisse (soit la longueur du pipeline qu'elles représentent), mais ne communique pas de valeur précise. Pour rappel, les unités de calcul des GPU Nvidia depuis Kepler travaillent sur des vecteurs de 32 éléments ou threads appelés warps (contre 64 éléments appelés wavefronts du côté d'AMD). Les SIMD 32-way ont un débit d'une opération FP32 par cycle, exécutée simultanément sur les 32 threads qui composent le warp, mais la latence est plus élevée, elle est de 11 cycles sur Kepler. L'ordonnanceur jongle entre plusieurs warps pour masquer cette latence et en la réduisant sur Maxwell, Nvidia réduit le nombre d'éléments qui doivent résider dans le SMM pour maintenir le débit maximal de celui-ci. Il fallait par exemple au minimum 352 pixels ou threads, organisés en 11 groupes de 32 (les warps) par partition de SMX Kepler pour exploiter ses unités de calcul à pleine vitesse, et il en faudra moins dans un SMM. Etant donné que la taille des différents caches présents dans le SMM reste identique à ceux du SMX, cela signifie que leur disponibilité par élément pourra augmenter dans certains cas. Par exemple, le fichier registres de 64 Ko par partition correspond à 16384 registres 32-bit ou 512 entrées de 1024-bit (largeur des SIMD 32-way) que doivent se partager les différents warps qui résident dans le SMX/SMM. Moins il y en a, plus grosse est la part du gâteau. Sur Kepler, avec 11 cycles de latence, le nombre maximal de registres 32-bit par thread pour autoriser une puissance de calcul maximale est de 46. C'est un peu plus élevé sur Maxwell. Par ailleurs comme sur le GK110, mais cette fois au mépris de la puissance de calcul utilisable, il est possible d'utiliser jusqu'à 255 registres 32-bit par thread (contre 63 sur les autres GPU Kepler). C'est principalement important dans le cadre du GPU computing puisqu'en rendu 3D le compilateur va très souvent privilégier un code qui fait appel à moins de registres de manière à maximiser le nombre de vertices ou de pixels qui résident dans le SMX/SMM de manière à mieux masquer les latences élevées, par exemple du texturing. Enfin, sans changer leur taille, Nvidia a revu le fonctionnement de deux caches importants pour les GPU modernes : le cache de textures (12 Ko) qui dispose d'une voie royale en lecture vers le sous-système mémoire et la mémoire partagée (64 Ko) qui permet d'échanger des données entre threads. La fonction de cache L1 était ainsi combinée à la mémoire partagée sur Kepler alors qu'elle est combinée au texture cache sur Maxwell. Il faut bien comprendre que dans le cadre d'un GPU Nvidia, le cache L1 ne correspond pas réellement à une espèce de L1D de type CPU qui cacherait les lectures/écritures en mémoire globale. Celles-ci ne sont en cache que via le L2. Le L1 dans le contexte de Kepler est exploité tout d'abord en tant que buffer utilisé lorsque le fichier registre déborde (register spilling). Le compilateur ne peut pas toujours s'assurer que le fichier registre est suffisant et n'a de toute manière pas toujours envie de s'y astreindre pour des raisons de performances. Cette utilisation disparaît cependant avec Maxwell première génération, les registres supplémentaires seront exclusivement en cache via le L2. En d'autres termes, mieux vaut ne pas y avoir recours. Ensuite, le cache L1 fait office de buffer de regroupement pour les accès mémoire, il y rassemble les données en avance pour qu'elles puissent être délivrées en blocs lors du traitement des warps. Cette utilisation est d'application pour Maxwell comme pour Kepler. Sur Kepler, la mémoire partagée de 64 Ko accueillait ce L1 avec une répartition qui pouvait être de 16/48, 32/32 ou 48/16, au choix du développeur qui devait le configurer dans le cadre du GPU computing. Sur Maxwell, la mémoire partagée ne remplit que ce seul rôle, ce qui veut dire que la totalité de ses 64 Ko sont disponibles et ce qui simplifie son design. Que ce soit sous CUDA, OpenCL ou DirectCompute, son principe de fonctionnement est le suivant : une partie ou la totalité de la mémoire partagée est attribuée à un bloc de threads et fait office de mémoire pilotée par le programmeur. La part de mémoire partagée qui peut être réservée par un bloc de threads (de 32 à 1024 threads) reste limitée à 48 Ko pour des raisons de compatibilité. Mais le SMM pourra par exemple accueillir 4 blocs de threads avec 16 Ko chacun, contre 3 blocs pour le SMX. De quoi mieux masquer les latences. A noter que Nvidia avait introduit sur Kepler un accès à pleine vitesse à la mémoire partagée pour les données 64-bit, soit 32x 64-bit par cycle. Jugée peu utile, cette possibilité est passée à la trappe avec Maxwell qui divise donc par deux la bande passante maximale du cette mémoire, ce qui reste suffisant pour débiter 32x 32-bit par cycle. Si le L1 n'est plus associé à la mémoire partagée, il intègre sur Maxwell les texture caches. Autant sur Kepler que sur Maxwell, chaque bloc de 4 unités de texturing dispose d'un petit cache de 12 Ko qui dispose d'une voie royale vers le sous-système mémoire mais en lecture uniquement. Y intégrer la fonction de L1, d'autant plus limitée au regroupement de données (coalescing) simplifie le design. De 16, 32 ou 48 Ko de L1 Par SMX sur Kepler, Maxwell, tout du moins en première génération, doit se contenter de 2x 12 Ko par SMM. Nvidia estime que cela est suffisant dans le cadre de ces GPU. A noter qu'avec le GK110, Nvidia a introduit la possibilité, toujours dans le cadre du GPU computing et quand les unités de texturing ne sont pas utilisées, d'exploiter le texture cache en tant que L1D en lecture uniquement. Les accès à la mémoire globale (mémoire vidéo / système) profitent alors d'un "vrai" L1 en plus du L2. Ce mode, qui doit être activé par le développeur s'il le juge utile, est proposé sur Maxwell première génération. Il ne fait aucun doute selon nous que cette structure des caches sera différente dans le cadre des GPU Maxwell de deuxième génération (GM20x). Enfin, il faut noter que le niveau de "Compute Capability" fait un bond en avant. Il représente le niveau de fonctionnalité CUDA / OpenCL reporté par le GPU, sur lequel peuvent se baser les développeurs pour des optimisations poussées et sur lequel le compilateur se base pour en sortir le code (au format cubin) adapté à chaque GPU. Le Compute Capability est pour rappel de 3.0 pour les GPU Kepler GK10x et de 3.5 pour le GK110 et le GK208. Il passe à 5.0 pour le GM107 et pour Maxwell de première génération. Un bond en avant difficile à comprendre puisque les différences restent subtiles, tout du moins en apparence. Des différences plus fondamentales dans la manière dans les instructions sont présentées aux GPU existent probablement. Il faut d'ailleurs préciser qu'un code cubin compilé pour les niveaux 3.0 ou 3.5 ne pourra pas être exécuté sur Maxwell alors qu'un cubin 3.0 reste compatible 3.5, Nvidia ayant fait en sorte de conserver une rétrocompatibilité à l'intérieur d'une même révision majeure. De quoi justifier le passage en 4.0, mais pourquoi en 5.0 ? Mystère, à moins que Nvidia ne se soit inspiré de la culture asiatique dans laquelle le chiffre 4 porte malheur. Certains programmes devront donc être recompilés, raisons pour laquelle Nvidia conseille aux développeurs de toujours inclure une version PTX de leurs kernels, le langage intermédiaire maison de type pseudo-assembleur. Page 5 - Performances théoriques : pixels Notez que par rapport à nos précédentes mesures théoriques, nous avons allongé la durée de nos tests de manière à ce que la fréquence GPU puisse se stabiliser en terme de consommation. Ils restent cependant suffisamment brefs pour ne pas être influencés par la température de manière à représenter les débits bruts des différents GPU. Nous avons repris leurs versions les plus performantes, excepté pour Tahiti pour lequel nous avons opté pour la Radeon R9 280X de manière à ce que tous les GPU AMD soient représentés à 1 GHz. Performances texturingNous avons mesuré les performances lors de l'accès aux textures avec filtrage bilinéaire activé et ce, pour différents formats : en 32 bits classique (8x INT8), en 64 bits "HDR" (4x FP16), en 128 bits (4x FP32), en profondeur de 32 bits (D32F) et en FP10, un format HDR introduit par DirectX 10 qui permet de stocker des textures HDR en 32 bits avec quelques compromis. 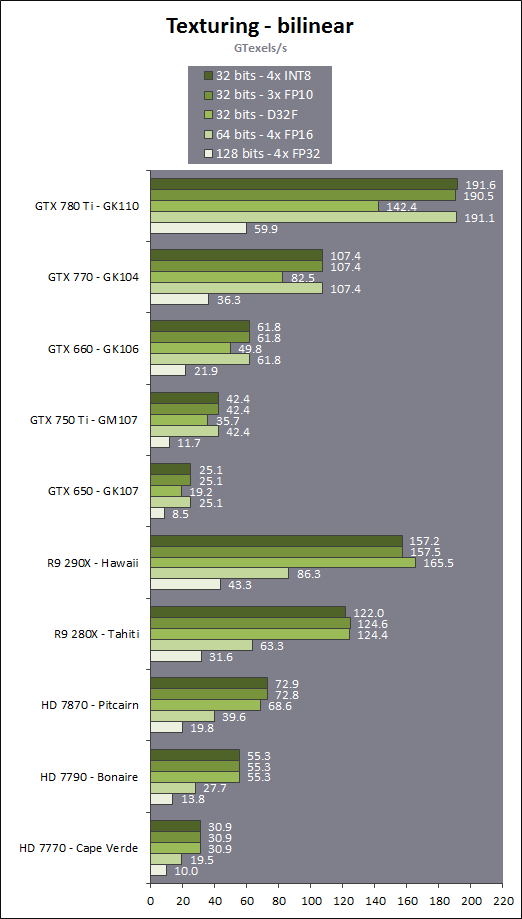 Les GeForce GTX sont capables de filtrer les textures FP16 à pleine vitesse contrairement aux Radeon, ce qui leur donne un avantage considérable sur ce point. C'est d'ailleurs à ce niveau que le GM107 se démarque de Bonaire puisque sur les autres formats il reste en retrait en termes de débits bruts par rapport à son concurrent direct. Notez que dans ce test, les GeForce à base de GK104/106/107 ont du mal à atteindre leur débit maximal alors que le GM107 en est très proche, une efficacité en hausse des unités de texturing qui est probablement lié au fait que leur proportion réduite permet de plus facilement les saturer. Les Radeon peuvent également s'éloigner plus ou moins de leur maximum théorique, cette fois parce que PowerTune les en empêche en réduisant la fréquence GPU, estimant ou mesurant que le niveau de consommation est trop élevé lorsque leurs unités de texturing sont saturées. Ce n'est pas le cas pour les Radeon HD 7900 ni pour les Radeon HD 7800 (depuis la mise à jour de PowerTune en automne 2012), ni pour la Radeon HD 7790. La Radeon HD 7770 et la Radeon R9 290X sont par contre quelque peu limitées. La GeForce GTX 780 Ti, contrairement à ce que laissent penser ses spécifications, a ici du mal à se détacher de la GeForce GTX Titan, car dans ce cas elle atteint sa limite de consommation. FillrateNous avons mesuré le fillrate sans et puis avec blending, et ce avec différents formats de données : 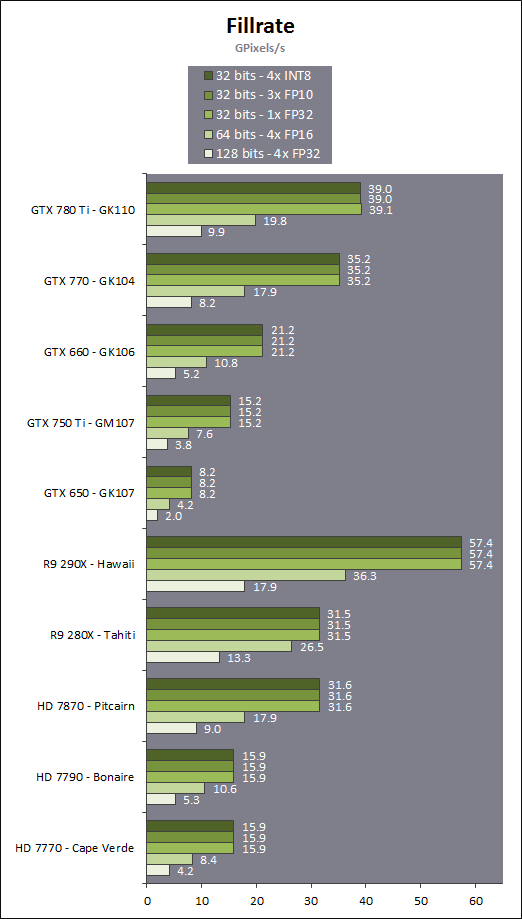 [ Standard ] [ Avec blending ] Le fillrate est l'un des points forts du GPU Hawaii qui intègre pas moins de 64 ROP chargés d'écrire les pixels en mémoire. Tout comme pour Bonaire, ces ROP profitent qui plus est d'une efficacité supérieure avec blending. De quoi permettre un gain massif dans un exemple aussi simple que notre test qui tombe pour ces GPU dans le cas idéal. À l'inverse, le fillrate peut être vu comme le point faible du GK110. Ainsi, il n'augmente que très peu par rapport au GK104, un peu plus de 10% en théorie pour la GTX Titan et un petit peu moins en pratique. Pour rappel, les 14 SMX de la GeForce GTX Titan sont capables de transférer 56 pixels par cycle vers les ROP et ceux-ci sont capables d'en écrire 48 en mémoire par cycle, contre 32 et 32 pour une GeForce GTX 680. La limitation se situe en fait au niveau des rasterizers : le GK110 en dispose de 5 contre 4 pour le GK104. Chacun de ceux-ci étant capable de générer 8 pixels, le GK110 est en réalité limité à 40 pixels par cycle contre 32 pour le GK104. La différence de fréquence réduit encore cet écart. Suivant sa configuration, la GeForce GTX 780 peut être limitée au niveau des rasterizers soit à 32, soit à 36, soit à 40 pixels par cycle. Notre échantillon de test était dans le premier cas et se retrouve donc avec un fillrate légèrement inférieur à celui d'une GeForce GTX 680. Les GeForce depuis Kepler sont enfin capables de transférer les formats FP10/11 et RGB9E5 à pleine vitesse vers les ROP, mais le blending de ces formats se fait toujours à demi vitesse. Si les GeForce et les Radeon sont capables de traiter le FP32 simple canal à pleine vitesse sans blending, seules ces dernières conservent ce débit avec blending, Nvidia n'ayant pas jugé utile de prévoir plus de performances au niveau des ROP pour ce format. Bien que les Radeon 7800 disposent du même nombre de ROP que les Radeon HD 7900, leur bande passante mémoire inférieure ne leur permet pas de maximiser leur utilisation avec blending ainsi qu'en FP16 et FP32 sans blending. En passant du GK107 au GM107, Nvidia propose une architecture qui permet d'alimenter les ROP à pleine vitesse (tant au niveau du rasterizer que des SMM), raison pour laquelle ce premier GPU Maxwell voit son débit de pixels progresser nettement, excepté en FP32 avec blending, mode dans lequel les ROP semblent limités à 1/16ème de leur débit maximal. Page 6 - Performances théoriques : géométrie Notez que par rapport à nos précédentes mesures théoriques, nous avons allongé la durée de nos tests de manière à ce que la fréquence GPU puisse se stabiliser en terme de consommation. Ils restent cependant suffisamment brefs pour ne pas être influencés par la température de manière à représenter les débits bruts des différents GPU. Nous avons repris leurs versions les plus performantes, excepté pour Tahiti pour lequel nous avons opté pour la Radeon R9 280X de manière à ce que tous les GPU AMD soient représentés à 1 GHz. Débit de trianglesÉtant donné les différences architecturales des GPU récents au niveau du traitement de la géométrie, nous nous sommes évidemment penchés de plus près sur le sujet. Tout d'abord nous avons observé les débits de triangles dans deux cas de figure : quand tous les triangles sont affichés et quand ils sont tous rejetés (parce qu'ils tournent le dos à la caméra) : 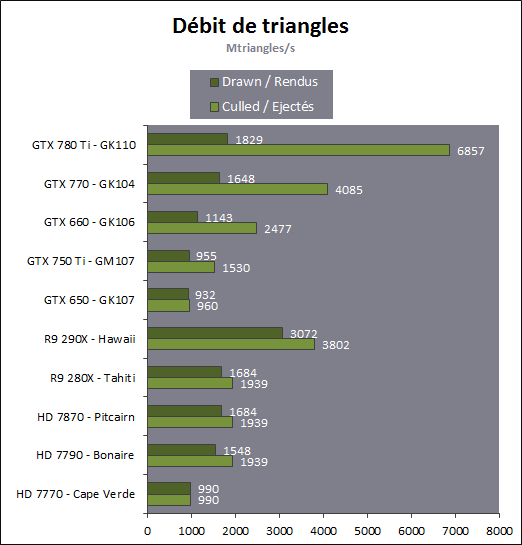 Quand les triangles peuvent être éjectés du rendu, les GeForce GTX 780 Ti, GTX 770 et GTX 660 profitent pleinement de leur capacité de prise en charge de 7.5, 4 ou 2.5 triangles par cycle pour se démarquer des Radeon. Bonaire se comporte ici exactement comme Tahiti et Pitcairn, avec 2 triangles par cycle, alors que Hawaii passe à la vitesse supérieure mais sans pouvoir égaler le GK104. Le GM107, 1.67 triangles par cycle, se retrouve dans une position particulière puisque pour la première fois pour un GPU Nvidia récent, il n'a pas l'ascendant sur son concurrent direct, Bonaire, en termes de puissance géométrique brute. Une fois que les triangles doivent être rendus, le débit maximal théorique des GeForce chute sur certains modèles alors que leur efficacité est plus généralement en baisse, peut-être parce que ces GPU sont engorgés à un endroit ou à un autre, ou encore parce que leurs performances ont été réduites artificiellement pour différencier les Quadro des GeForce. La Radeon R9 290X prend ainsi la tête sur ce point alors que le débit de la GTX 780 Ti est plus affecté que celui des autres GeForce, mais cette fois la limite de consommation n'est pas en cause.. Ensuite nous avons effectué un test similaire mais en utilisant la tessellation : 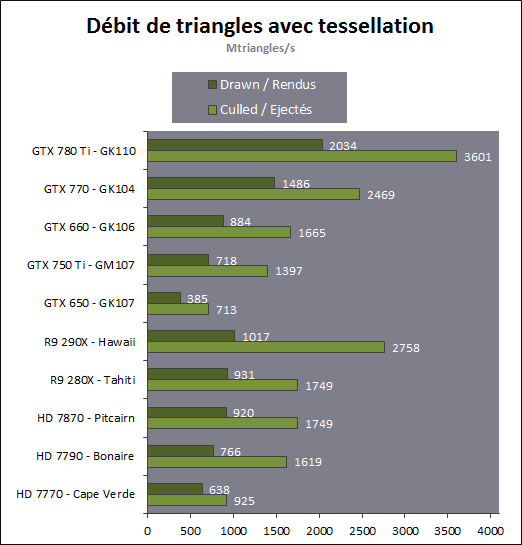 Avec les GeForce GTX Kepler, Nvidia réaffirmait sa supériorité lorsqu'il s'agit de traiter un nombre important de petits triangles générés par un niveau de tessellation élevé. Cet avantage ne concerne par contre que le haut de gamme. Le premier GPU Maxwell de première génération n'en profite pas, ses performances se situant quelque peu derrière celles de Bonaire, tout en représentant malgré tout un net gain par rapport au GK107. Les Radeon HD 7900/ R9 280X ne se démarquent pas des Radeon HD 7800 et de la Radeon HD 7790 qui disposent du même nombre d'unités fixes dédiées à cette tâche. L'architecture des Radeon fait qu'elles peuvent être engorgées plus facilement par la quantité de données générées, ce qui réduit drastiquement leur débit dans ce cas. AMD fait évoluer progressivement les différents buffers liés à la tessellation, et la manière de les utiliser, pour éviter autant que possible de se trouver dans ce cas. Les derniers pilotes apportent d'ailleurs des gains significatifs à ce niveau pour l'ensemble des GPU GCN. Hawaii affiche un gain important au niveau du débit brut, soit lorsque les triangles générés ne doivent pas être rendus. Lorsque c'est le cas, il se contente par contre dans notre test d'une progression de +/- 10% par rapport à Tahiti. Notre test étant relativement lourd en termes de données générées par triangles, nous supposons que le GPU souffre d'un embouteillage à un endroit ou à un autre, peut-être au niveau du canal de transfert de ces données vers les contrôleurs mémoire (mais pas directement au niveau de la bande passante globale qui est loin d'être saturée). Page 7 - Spécifications, la GTX 750 Ti de référence Spécifications 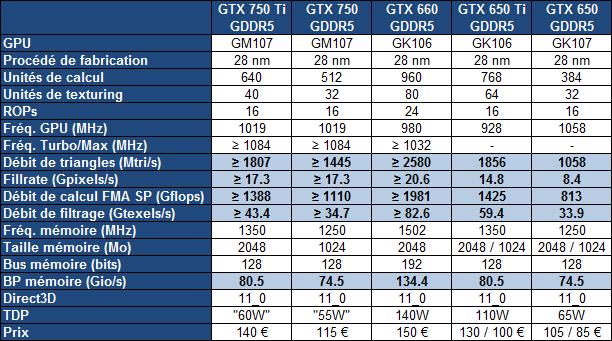 La comparaison la plus évidente entre ces cartes graphiques est à chercher entre la GeForce GTX 750 Ti et la GeForce GTX 650 Ti. La nouvelle venue affiche une bande passante identique et une puissance de calcul brute similaire. Elle profite d'un fillrate légèrement plus élevé mais d'une puissance de texturing en net retrait. Sur base de ces spécifications, il peut être difficile d'imaginer comment la GeForce GTX 750 Ti va pouvoir battre sa devancière, mais il faut garder en tête qu'elle profite d'une architecture réorganisée, débarrassée des unités de calcul au rendement pratique peu élevé. Si nous ne prenions en compte que la part des unités de calcul réellement efficaces, la GeForce GTX 750 Ti afficherait une puissance de calcul brute près de 50% plus élevée que celle de la GTX 650 Ti. A noter que les GTX 750 Ti et GTX 750 supportent GPU Boost dans sa version 2.0 soit avec monitoring de la consommation et limite de la température GPU à 80 °C. Contrairement à ce que nous pensions, Nvidia nous a indiqué que sa technique de monitoring ne profitait pas d'une intégration plus poussée avec Maxwell et se comporterait comme sur Kepler. GeForce GTX 750 Ti de référencePour ce test, Nvidia nous a fourni une GeForce GTX 750 Ti de référence :    La carte de référence est pour le moins compacte, 14.5cm de long. Elle se contente d'un TDP officiel de 60W ce qui lui permet de se passer de connecteur d'alimentation et simplifie le PCB puisque seules 2 phases sont nécessaires pour alimenter le GPU. Notez qu'en pratique le vrai TDP est plutôt de 65W, Nvidia oubliant de compter le courant 3.3V dans ses spécifications officielles. Si cet oubli est négligeable sur les cartes haut de gamme, il représente +/- 10% dans le cas d'une carte aussi peu gourmande que la GeForce GTX 750 Ti. Le système de refroidissement est très simple, un petit bloc d'aluminium surmonté d'un petit ventilateur de 58mm de diamètre. Sur banc de test, le GPU n'a pas dépassé 68 °C et s'est contenté de 71 °C en charge lourd dans un boîtier fermé. La GTX 750 Ti de référence est par ailleurs relativement discrète puisque nous avons mesuré sur notre protocole habituel 23.2 dBA au repos et 30.6 dBA en charge lourde. Au niveau de la connectique, le PCB de référence fait malheureusement l'impasse sur le DisplayPort, ce qui rend la carte incompatible avec certains écrans 4K et avec les écrans G-Sync. Un choix dicté par la volonté de conserver 2 sorties DVI et de se contenter d'un seul slot. Le PCB est prévu pour accueillir différentes configuration de mémoire, avec 4 emplacements pour puces GDDR5 de chaque côté : - 1 Go avec 4 puces 2 Gbits (GTX 750 de référence) - 2 Go avec 4 puces 4 Gbits (GTX 750 Ti de référence) - 2 Go avec 8 puces 2 Gbits - 4 Go avec 8 puces 4 Gbits Dans un premier temps, seules les configurations de référence sont proposées, mais nul doute qu'un infâme modèle 4 Go va finir par arriver. A noter que nous avons également testé des échantillons commerciaux de GTX 750 Ti et de GTX 750 obtenus via un partenaire de Nvidia que nous ne nommerons pas puisque nous avons obtenu ces cartes avant la date d'envoi autorisée par Nvidia, très pointilleux sur le respect de ces détails. Ces cartes étaient basées sur le PCB de référence. Page 8 - Consommation, efficacité énergétique ConsommationNous avons utilisé le protocole de test qui nous permet de mesurer la consommation de la carte graphique seule. Nous avons effectué ces mesures au repos sur le bureau Windows 7 ainsi qu'en veille écran de manière à observer l'intérêt de ZeroCore Power. Pour la charge, nous avons opté pour des mesures dans Anno 2070, en 1080p avec tous les détails poussés à leur maximum, ainsi que dans Battlefield 3, en 1080p dans le mode High. Pour la consommation et le rendement énergétique, les GeForce GTX ont été testées telles quelles , c'est-à-dire sans limitation de la capacité de leur turbo, dont la limite varie d'un échantillon à l'autre. 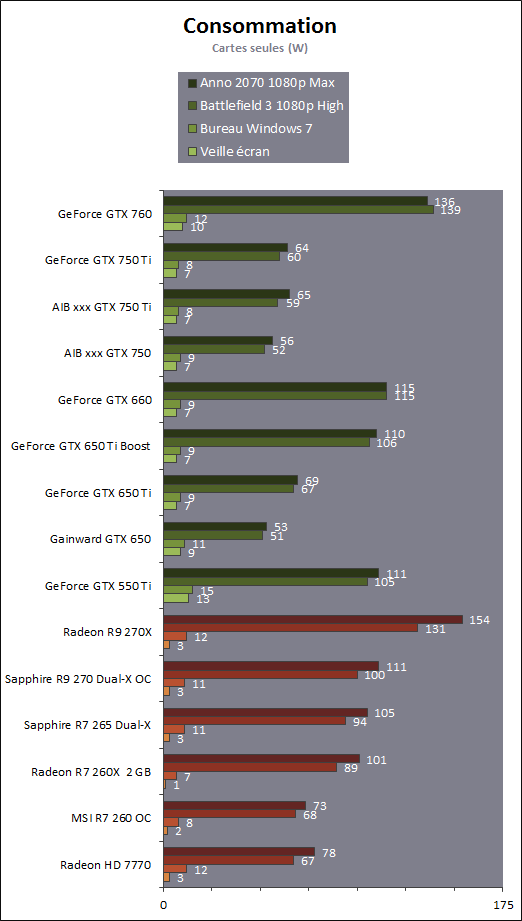 La consommation des GeForce GTX 750 et GTX 750 Ti est similaire à ce qui a été annoncé par Nvidia au niveau du 12V lors de charges lourdes comme c'est le cas dans Anno 2070 en qualité maximale. Il faut cependant y ajouter quelques W liés au canal 3.3V. La fréquence maximale pour nos 3 GeForce GTX 750 était de 1163 MHz, fréquence maintenue dans tous les cas sous Battlefield 3. Seule la GeForce GTX 750 y est cependant parvenu dans Anno 2070, les autres cartes atteignant leur limite de consommation. La fréquence de la GeForce GTX 750 Ti de référence oscillait alors entre 1110-1162 MHz contre 1123-1162 MHz pour notre seconde carte. Bien que ces données soient approximatives, compte tenu de la variation entre échantillons d'un même modèle, nous avons mis en relation ces mesures de consommation avec les performances, en retenant des fps par 100W pour que les données soient plus lisibles : 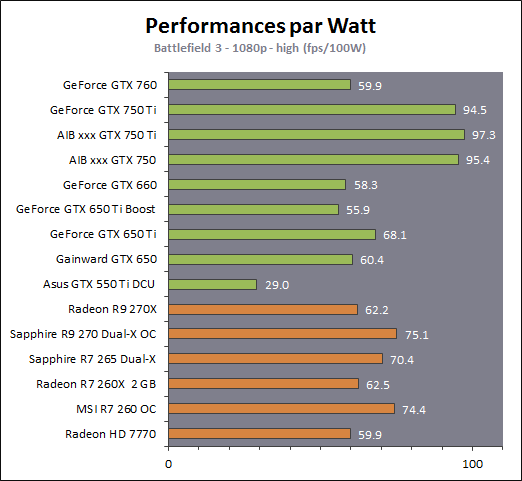 [ Anno 2070 1080p Max ] [ Battlefield 3 1080p High ] Ces chiffres, aussi approximatifs soient-ils, mettent clairement en lumière le gain d'efficacité énergétique apporté par la première génération Maxwell par rapport aux précédents GPU Kepler. Si nous poussons plus loin l'approximation en mélangeant le résultat de ces 2 jeux, nous obtenons grossièrement un indice de rendement énergétique de 50 pour Fermi, de 100 pour Kepler et de 160 pour Maxwell première génération. Une jolie progression ! Page 9 - Protocole de test Protocole de testPour ce test, nous avons retiré Alan Wake, BioShock Infinite, Max Payne 3, et Sleeping Dogs de notre protocole, de manière à nous contenter de 10 jeux. Tous ces jeux sont testés avec leur dernier patch au 15/02/2014, la plupart étant maintenus à jour via Steam/Origin/Uplay. Nous avons opté pour un niveau de qualité moyen à élevé en 1920x1080, de manière à viser un niveau de performances entre 40 et 50 fps sur les cartes testées. Pour rappel, nous n'utilisons plus le niveau de MSAA (4x et 8x), comme critère principal pour segmenter nos résultats. De nombreux jeux au rendu différé proposent d'autres formes d'antialiasing, la plus courante étant le FXAA développé par Nvidia. Cela n'a donc plus de sens d'organiser un indice autour d'un certain niveau d'antialiasing, ce qui nous permettait par le passé de nous focaliser sur l'efficacité du MSAA. Nous n'affichons plus les décimales dans les résultats de performances dans les jeux pour rendre les graphiques plus lisibles. Ces décimales sont néanmoins bien notées et prises en compte pour le calcul de l'indice. Si vous êtes observateur vous remarquerez que c'est également le cas pour la taille des barres dans les graphes. Toutes les cartes ont été testées ou retestées avec les pilotes Catalyst 14.1beta V1.6 et GeForce 334.69 beta. Nous avons forcé l'activation du PCI Express 3.0 sur la plateforme X79 pour les GeForce. Comme pour nos précédents tests, nous faisons en sorte de tester les différentes solutions en prenant en compte leur système de gestion de la consommation/fréquence/température de manière à vous proposer des résultats intéressants et pertinents. Notre approche à ce niveau n'est bien entendu pas rigide et nous l'adaptons suivant le produit testé. Pour ce test, nous avons opté pour donner la priorité aux performances garanties, Nvidia nous ayant indiqué qu'il était possible que certains échantillons ne puissent jamais aller au-delà de la fréquence turbo officielle. Nous avons donc limité les différentes GeForce à cette valeur. Nous avons également testé les GeForce GTX 750 Ti et GTX 750 telles quelles, c'est-à-dire avec une fréquence GPU capable de monter au-delà des 1085 MHz officiels pour atteindre 1162 MHz dans les deux cas. Cette fréquence était maintenue en permanence, excepté dans le cas d'Anno 2070 dans lequel la GTX 750 Ti s'est contenté de 1149 MHz. Bien entendu, les GeForce GTX 760, GTX 660 et GTX 650 Ti Boost peuvent elles aussi, suivant la qualité de l'échantillon, profiter de ces quelques points de performances supplémentaires, nous vous référerons pour cela à leurs tests respectifs.  Configuration de testIntel Core i7 3960X (HT off, Turbo 1/2/3/4/6 cores: 4 GHz) Asus P9X79 WS 8 Go DDR3 2133 Corsair Windows 7 64 bits Pilotes GeForce 334.69 beta WHQL Catalyst 14.1beta V1.6 Page 10 - Benchmark : Anno 2070 Anno 2070  Anno 2070 reprend une évolution du moteur d'Anno 1404 qui intègre un support de DirectX 11. Nous utilisons le mode de qualité très élevée du jeu et effectuons un déplacement sur une carte en mesurant les performances avec Fraps. 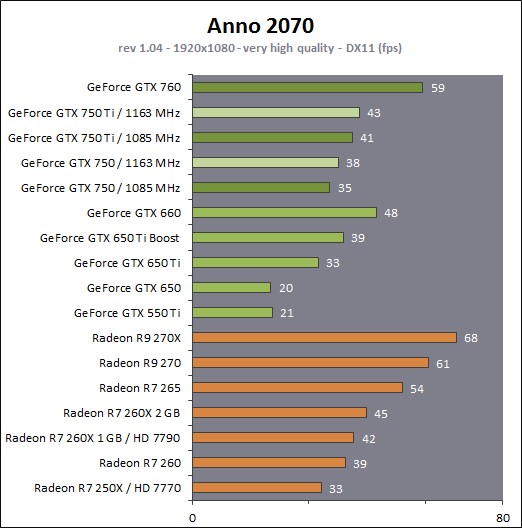 Dans Anno 2070, c'est avant tout la puissance de calcul qui compte et les GPU sont mis à rude épreuve par rapport à leurs limites de consommation ou de température. Les Radeon ont généralement l'avantage dans ce jeu et la R7 260X devance la GTX 750 Ti, cette dernièrement se plaçant cependant devant la GTX 650 Ti Boost avec un gain de près de 30% sur la GTX 650 Ti classique qui affiche pour rappel une puissance de calcul brute similaire. Page 11 - Benchmark : Batman Arkham Origins Batman Arkham Origins  Dernier opus de la série, Batman Arkham Origins est toujours basé sur l'Unreal Engine 3 mais pousse un petit peu plus loin les effets graphiques dont certains ont été implémentés sur PC en collaboration avec Nvidia. C'est le cas du TXAA et d'effets GPU PhysX réservés aux GeForce (il n'est plus possible d'activer une version CPU de tous ces effets), mais également de l'occlusion ambiante de type HBAO+, d'un effet de Depth of Field plus évolué (NVDOF), d'ombres adoucies (PCSS) et de la tessellation (pour la cape et la neige) qui sont utilisables sur tous les GPU DirectX 11. Nous utilisons le mode de qualité maximale du jeu, avec du MSAA 2X. Nous relevons les performances avec Fraps, sur un parcours bien défini. Le jeu est maintenu à jour via Steam. 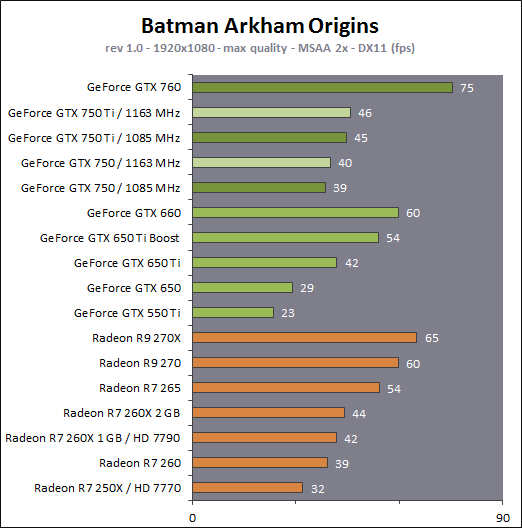 Dans Batman, la puissance de texturing et la bande passante mémoire prennent plus d'importance. L'écart entre la GeForce GTX 760 et la GeForce GTX 750 Ti est alors énorme. Les performances des cartes à base de GPU GM107 et Bonaire sont similaires. Page 12 - Benchmark : Battlefield 4 Battlefield 4  Battlefield 4 repose sur le moteur Frostbite 3, une évolution de la version 2 présente dans Battlefield 3. La base du rendu reste très proche (rendu différé, calcul de l'éclairage via compute shaders) et les évolutions visibles sont mineures, DICE ayant principalement optimisé son moteur pour les consoles de nouvelle génération. Parmi les petites nouveautés, citons un support plus avancé de la tessellation et une amélioration du module "destruction" du moteur. Sur PC, un mode Mantle spécifique aux Radeon et qui permet de réduire le coût CPU du rendu est proposé mais nous ne l'avons pas utilisé pour ce test. Pour rappel, il s'agit d'une API propriétaire de plus bas niveau dédiée aux Radeon HD 7000 et supérieures, qui a été développée par AMD et DICE. Nous testons le mode High en 1920x1080 et relevons les performances avec Fraps, sur un parcours bien défini. Le jeu est maintenu à jour via Origin. 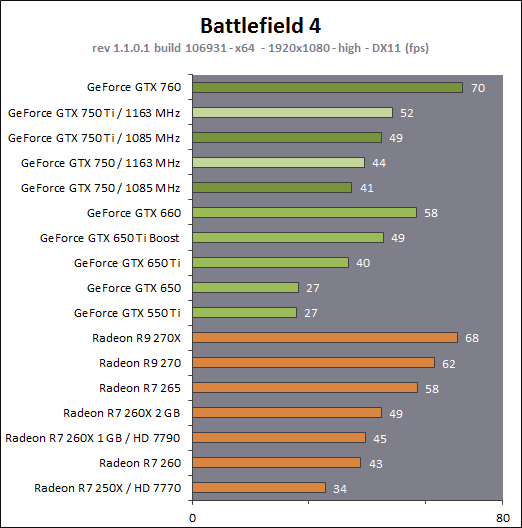 Ici aussi, les GeForce GTX 750 affichent un niveau de performances similaire à celui des Radeon R7 260. La GTX 750 Ti est au niveau de la GTX 650 Ti Boost et la GTX 750 au niveau de la GTX 650 Ti. Page 13 - Benchmark : Crysis 3 Crysis 3  Crysis 3 reprend le même moteur que Crysis 2 : le CryEngine 3. Ce dernier profite cependant de quelques petites évolutions telles qu'un support plus avancé de l'antialiasing : FXAA, MSAA et TXAA sont au programme, tout comme un nouveau mode appelé SMAA. Ce dernier est une évolution du MLAA qui permet, optionnellement, de prendre en compte des données de type sous-pixels soit à travers la combinaison avec du MSAA 2x, soit avec une composante temporelle calculée à partir de l'image précédente. Le SMAA 1x est la simple évolution du MLAA, le SMAA 2tx utilise une composante temporelle et le SMAA 4x y ajoute le MSAA 2x. Notez qu'il ne faut pas confondre le SMAA 2tx proposé en mono-GPU avec le SMAA 2x proposé en multi-GPU, ce dernier utilisant du MSAA 2x sans composante temporelle. Nous mesurons les performances avec Fraps et le jeu est maintenu à jour via Origin. 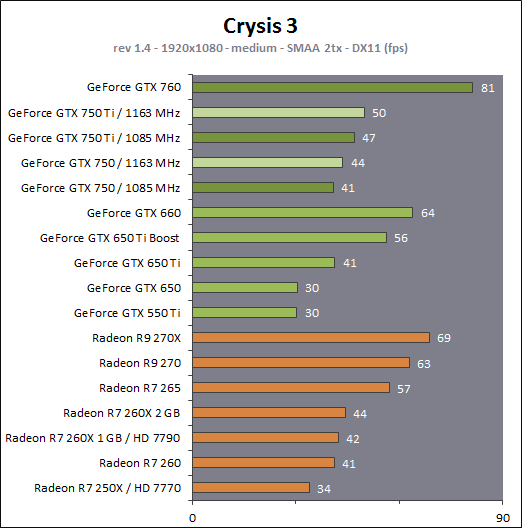 Dans ce jeu très gourmand, les GeForce s'en sortent un petit peu mieux que les Radeon, ce qui donne une légère avance à la GTX 750 Ti par rapport à la R7 260X 2 Go. Page 14 - Benchmark : Far Cry 3 Far Cry 3  Far Cry 3 est relativement lourd, notamment à travers les effets d'occultation ambiante, de filtrage des surfaces alpha et bien entendu à travers la MSAA 4x ou 2x.Pour mesurer les performances, nous activons le HDAO et poussons le niveau graphique au niveau élevé. Notez que le SSAO, moins gourmand, propose un rendu immonde, alors que le HBAO produisait des artefacts par endroit avant le patch 1.5 et, même une fois corrigé, affiche un résultat qui se rapproche du SSAO, inférieur au HDAO. Le HBAO ayant été développé à l'origine par Nvidia alors que le HDAO l'a été par AMD, certains testeurs, incités dans ce sens par Nvidia, préfèrent comparer les GeForce avec HBAO aux Radeon avec HDAO. Nous estimons cependant que cette approche n'est pas correcte, le HBAO étant moins gourmand et offrant un résultat inférieur, tout du moins dans ce jeu. Nous utilisons Fraps sur un parcours bien défini. 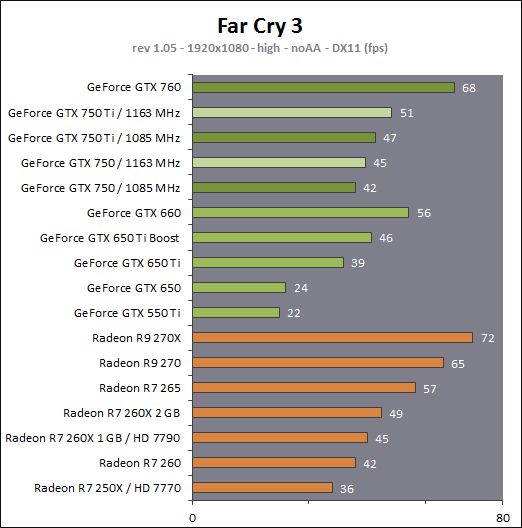 Nous retrouvons une nouvelle fois un niveau de performances similaires entre les dérivés du GM107 et de Bonaire alors que les GTX 750 et 750 Ti prennent une petite avance sur les GTX 650 Ti et 650 Ti Boost. Page 15 - Benchmark : GRID 2 GRID 2  Dernier né chez Codemaster, GRID 2 reprend une évolution légère du moteur DirectX 11 maison exploité par DiRT Showdown. Pour rappel, en partenariat avec AMD, les développeurs avaient mis en place un éclairage avancé qui prend en compte de nombreuses sources de lumière directes et indirectes ainsi qu'une approximation du rendu de type illumination globale. Ces techniques sont toujours exploitées, même si le partenaire principal de Codemaster est cette fois Intel qui a aidé à la mise en place d'optimisations spécifiques aux GPU intégrés à Haswell. Pour mesurer les performances, nous poussons toutes les options graphiques à leur maximum, à l'exception de l'adoucissement de l'effet d'occlusion ambiante. Nous utilisons Fraps sur l'environnement de Barcelone, le plus lourd dans le jeu. 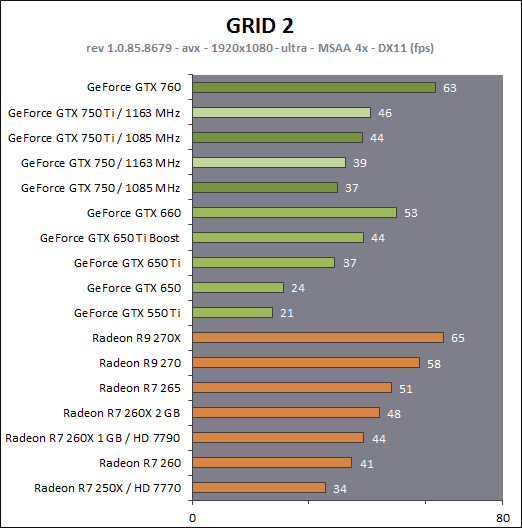 Dans ce jeu, les Radeon ont l'avantage et la R7 260X 2 Go dépasse la GTX 750 Ti. Page 16 - Benchmark : Hitman Absolution Hitman Absolution  Hitman Absolution utilise un moteur plutôt lourd et qui manque probablement d'optimisations. La charge CPU est par ailleurs relativement élevée dans certaines scènes dans lesquelles une foule importante peut être animée. Différents effets DirectX 11 ont été intégrés avec la coopération d'AMD. Pour mesurer les performances, nous poussons les options graphiques au niveau ultra et utilisons fraps dans le jeu. 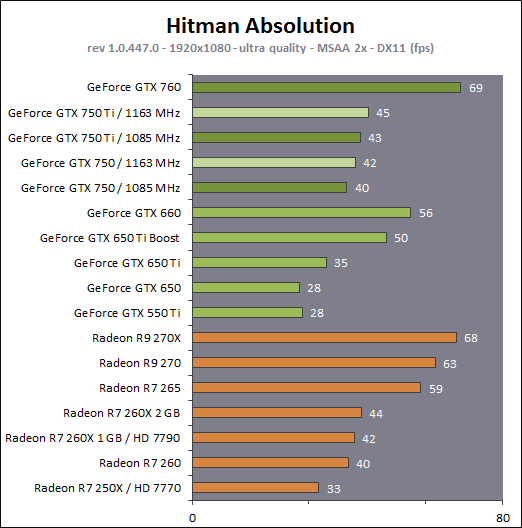 Dans ce jeu et avec MSAA 2x, le débit de pixels est important, ce qui explique la segmentation très claire dans les résultats de toutes les cartes testées, suivant le nombre de ROP et la largeur du bus mémoire qui leur permet de fonctionner. Par rapport à la GTX 650 Ti qui est configurée de la même manière que la GTX 750 Ti à ce niveau, le gain reste significatif, d'une part parce que la puissance de calcul pratique compte quand même en partie et d'autre part parce que son gros cache L2 permet probablement de soulager un bus mémoire qui n'a pas évolué. Page 17 - Benchmark : Metro Last Light Metro Last Light  Tout comme Metro 2033, sa suite Last Light développée par 4A Games est très gourmande. Elle repose sur une petite évolution du moteur DirectX 11 maison, le 4A Engine, ainsi que sur des environnements et éclairages plus riches. Le jeu pousse par ailleurs plus loin l'utilisation de la tessellation, mise en place en collaboration avec Nvidia, autant sur les personnages que sur les objets ou les sols, même si dans bien des cas la différence n'est cependant pas transcendante. Au niveau de l'antialiasing, le 4A Engine support l'AAA, un algorithme maison similaire au FXAA/MLAA/SMAA, ainsi que le SSAA extrêmement gourmand en mode 2x, 3x et 4x. Un mode 0.5x est également proposé et consiste alors à rendre le jeu dans une résolution inférieur qui est par la suite étendue. Le support de GPU PhysX est toujours de la partie. A ne pas confondre avec PhysX, qui gère globalement la physique au niveau du CPU, il s'agit d'effets accélérés par le GPU à travers une librairie propriétaire de Nvidia, ce qui implique qu'ils ne peuvent pas être accélérés sur une Radeon. Ils sont alors traités par le CPU, d'une manière non-optimisée, ce qui rend leur utilisation difficile en pratique. Nous avons testé le jeu via Fraps sur un parcours bien défini. Nous avons dû faire l'impasse sur le SSAA, bien trop gourmand et nous contenter du mode de qualité normale. 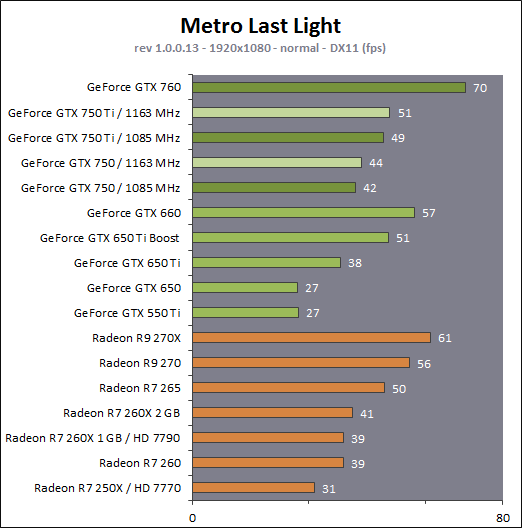 Les GeForce s'en sortent mieux que les Radeon dans ce jeu et la GTX 750 Ti se place pour une fois au niveau de la R7 265. Page 18 - Benchmark : Splinter Cell Blacklist Splinter Cell Blacklist  Notez au niveau de l'occlusion ambiante que le jeu propose de nombreuses options dont les plus avancées représentent l'effet le plus lourd du jeu, mais nous avons dû ici nous contenter de variantes plus simples en mode de qualité élevée. Nous mesurons les performances avec Fraps sur un parcours bien défini et le jeu est maintenu à jour via Uplay. 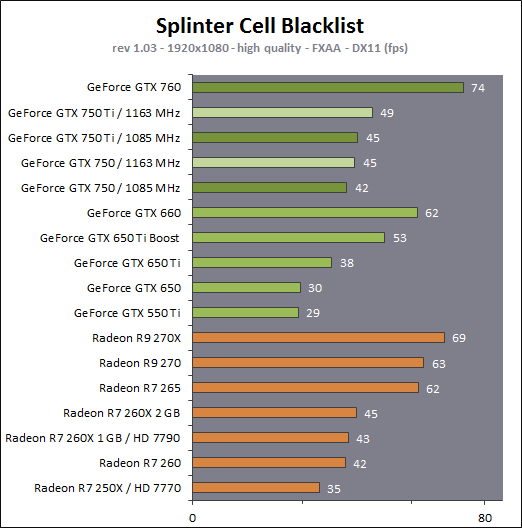 Les GeForce GTX 750 Ti et GTX 750 se placent au niveau des Radeon R7 260, mais s'en détachent quelque peu dans le cas d'échantillons dont le turbo variable offre beaucoup plus de marge de manuvre au GPU. Page 19 - Benchmark : Tomb Raider Tomb Raider  Tomb Raider a été l'une des meilleures surprises de 2013. Le rendu graphique est plutôt réussi, AMD ayant collaboré avec les développeurs pour s'assurer d'une version PC de bon niveau. C'est particulièrement le cas pour TressFX, l'option de rendu avancé des cheveux de Lara qui apporte une bonne dose de réalisme. Nous avons testé Tomb Raider en mode de qualité High en y ajoutant l'effet TressFX. Nous avons mesuré les performances avec Fraps, sans utiliser le bench intégré qui correspond plus aux cinématiques qu'aux scènes de jeu classiques. 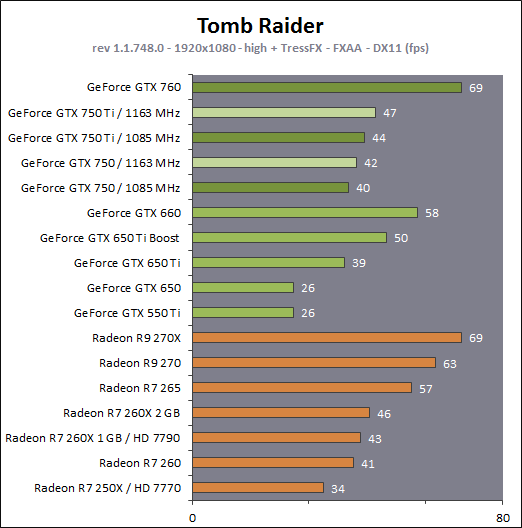 Dans ce jeu, les performances des dérivés du GM107 sont similaires à celles des dérivés de Bonaire. Page 20 - Récapitulatif des performances RécapitulatifBien que les résultats de chaque jeu aient tous un intérêt, nous avons calculé un indice de performances en nous basant sur l'ensemble de résultats et en attachant une importance particulière à donner le même poids à chacun des jeux. Nous avons attribué un indice de 100 à la GeForce GTX 650 Ti : 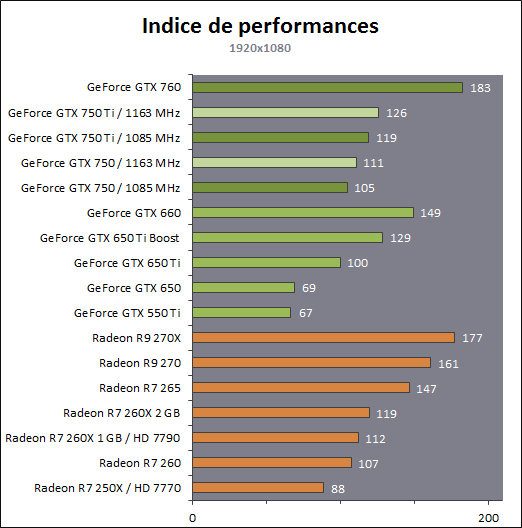 En moyenne, la GeForce GTX 750 Ti, à sa fréquence turbo garantie, termine à égalité avec la Radeon R7 260X 2 Go tout du moins quand il s'agit d'un modèle qui respecte bien les fréquences de référence, ce qui n'est pas le cas, pour rappel, de nombreux modèles 1 Go. Si l'échantillon de GTX 750 Ti dispose de plus de marge au niveau de son turbo, comme c'était le cas de nos échantillons, les performances progressent de +/- 5%, de quoi, cette fois, devancer la Radeon R7 260X 2 Go. La GeForce GTX 750, de son côté, se place plutôt au niveau de la Radeon R7 260, mais si son turbo est généreux, elle se rapproche des R7 260X 1 Go dont les fréquences se contentent de celles de l'ancienne Radeon HD 7790. Par rapport aux GeForce GTX 600 qu'elles remplacent, la GeForce GTX 750 Ti se place légèrement en retrait par rapport à la GeForce GTX 650 Ti Boost alors que la GeForce GTX 750 devance de quelques points la GeForce GTX 650 Ti. La GeForce GTX 660 et la Radeon R7 265 affichent des performances moyennes similaires et nettement devant les GTX 750, avec une avance de 20 à 25% sur la GTX 750 Ti. Page 21 - Overclocking OverclockingComme toutes les cartes graphiques, les GeForce GTX 750 peuvent être overclockées. Elles reprennent pour cela les mêmes interfaces que pour les autres GeForce GTX 700. Il est donc possible de modifier : - la fréquence GPU - la fréquence mémoire - la limite de température - la limite de consommation Les partenaires de Nvidia sont libres de proposer eux aussi des modèles overclockés d'usine, il n'y a que la limite de température par défaut de 80 °C à laquelle ils ne peuvent pas toucher. Ils peuvent par ailleurs modifier les limites d'overclocking manuel, celle-ci était particulièrement peu élevée dans le cas des GTX 750 de référence : +135 MHz. Nvidia nous a par ailleurs indiqué qu'ils devaient conserver un même ratio entre les fréquences de base et GPU Boost sur lesquelles ils communiquent. Ainsi, un fabricant ne peut pas se contenter de sélectionner les exemplaires qui montent le plus haut en fréquence, ne rien changer et annoncer une fréquence GPU Boost énorme sans toucher à la fréquence de base. Par contre, et nous avons déjà pu l'observer sur certaines GTX 700, certains fabricants peuvent être tentés de faire l'inverse. C'est-à-dire sélectionner les échantillons dont la fréquence turbo réelle est la plus faible pour proposer un très gros overclocking d'usine officiel, sans atteindre la limite d'instabilité au niveau de la fréquence maximale réelle. 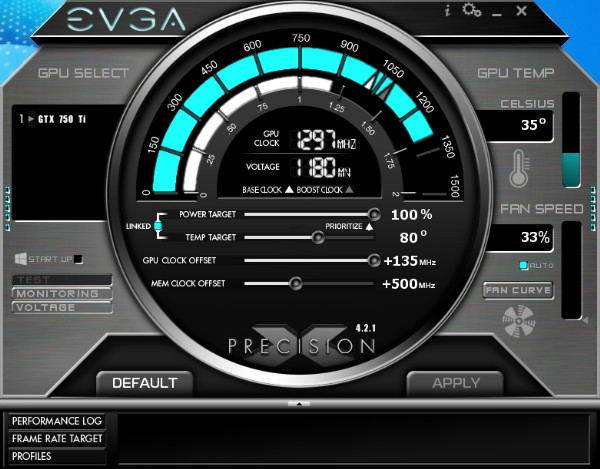 Dans le cas d'un overclocking manuel, toucher à la limite de température n'a que peu d'intérêt compte tenu du fait que ces cartes restent en-dessous dans tous les cas, à moins qu'un partenaire de Nvidia n'arrive à sortir un design de piètre qualité. Augmenter la limite de consommation pourrait par contre être utile, mais Nvidia a fait le choix de ne pas l'autoriser sur ses cartes de référence, en grande partie parce qu'elles sont déjà très proches de la limite de courant qui peut être délivré par le bus PCI Express en restant dans ses spécifications. Libre aux partenaires de Nvidia de placer un connecteur d'alimentation et d'augmenter cette limite. Voici les overclocking que nous avons pu obtenir pour les 3 GTX 750 en notre possession : GTX 750 Ti de référence : +135 MHz pour le GPU, +250 MHz pour la mémoire GTX 750 Ti AIB xxx : +135 MHz pour le GPU, +300 MHz pour la mémoire GTX 750 AIB xxx : +135 MHz pour le GPU, +300 MHz pour la mémoire Comme vous pouvez le voir, nous avons atteint à chaque fois la limite d'overclocking autorisée. A noter un nouveau détail avec les GeForce Maxwell : elles conservent une table de fréquences qui évolue par pas de 13 MHz, mais son dernier niveau, la fréquence turbo maximale réelle, peut être paramétrée au MHz près. Par exemple, un overclocking de +135 MHz sur une GTX 660 est identique à un overclocking de +130 MHz. Sur les GTX 750, ces 5 MHz de plus seront par contre bien appliqués mais uniquement pour le dernier niveau de fréquence. Notre GTX 750 Ti passe ainsi à 1297 MHz une fois overclockée de la sorte et si une limite est atteinte, elle redescend à 1279 MHz, 1266 MHz, 1253 MHz etc). Voici l'impact que peut avoir cet overclocking sur les performances :  Le gain de performances lié à l'overclocking atteint 10% dans Battlefield 4 et près de 15% dans Anno 2070. Page 22 - Conclusion ConclusionA l'issue de ce dossier, il nous semble opportun de scinder notre analyse des GeForce GTX 750 en deux parties, en nous intéressant tout d'abord à l'architecture Maxwell ou tout du moins à sa première génération incarnée par le GPU GM107. Tout en restant fabriqué sur le même procédé de fabrication 28nm que l'ensemble des GPU Kepler précédents, ce nouveau petit GPU affiche un gain important en termes d'efficacité énergétique. Nos propres observations mettent en avant une progression d'environ 60% à ce niveau, ce qui témoigne de l'excellent travail réalisé par les ingénieurs de Nvidia.  Une efficacité énergétique qui devrait permettre à Nvidia de très bien se positionner dans le monde mobile et il est d'ailleurs étonnant que ce GPU GM107 ait été introduit en primeur en version desktop. Nvidia a probablement raté de peu le cycle de renouvellement des plateformes mobiles de cet hiver et est sans aucun doute en ce moment en train de préparer activement l'arrivée de Maxwell dans le cycle suivant. Via de nombreuses petites touches mais sans bouleversement majeur, Nvidia améliore les performances du GPU computing, notamment en ce qui concerne les algorithmes liés aux crypto-monnaies. Les gains peuvent dans certains cas être très élevés, mais il est difficile d'en tirer une conclusion générale autre que celle-ci : l'efficacité énergétique conserve la priorité mais Nvidia n'oublie pas le GPU computing. Les résultats du GM107 nous permettent-ils d'extrapoler vers les résultats des futurs GPU Maxwell, de seconde génération ? Difficilement puisque ceux-ci sont attendus sur un autre procédé de fabrication, le 20nm, et devraient selon nous présenter des différences non-négligeables au niveau de leur architecture : par exemple un tissu d'interconnexion plus complexe pour autoriser l'élargissement de leur architecture ou encore une révision des petites mémoires internes, notamment des caches L1, pour aider encore un peu plus le GPU computing. Il faudra encore patienter quelques mois pour en savoir plus à leur sujet puisque nous les attendons pour cet automne, au mieux pour la fin de l'été. Passons maintenant à l'aspect "produits" avec les GeForce GTX 750 Ti et GTX 750. Celles-ci profitent bien entendu du rendement énergétique élevé du GM107 à plusieurs niveaux : format compact, nuisances réduites, facilité d'installation Ce dernier point, qui peut sembler anecdotique, est important pour le marché de l'upgrade grand public. Sans connecteur d'alimentation, ces GeForce GTX 750 sont simples à installer, sans avoir à trop se soucier de la puissance de l'alimentation ou de la disponibilité d'un connecteur d'alimentation PCI Express, ce qui en fait un conseil d'achat sans risques. Elles trouveront également aisément place dans les PC les plus compacts, d'autant plus que les partenaires de Nvidia vont pouvoir en sortir des versions low profile. Mais attention, PC compact ou pas, il faut bien garder en tête qu'il s'agit de cartes d'entrée de gamme. Elles sont suffisantes pour jouer en 1080p avec des détails modérés, mais elles ne sont pas prévues pour satisfaire les joueurs exigeants qui visent de plus hautes résolutions ou des détails maximums dans leurs jeux. Par ailleurs, elles se trouvent sur un segment sur lequel l'argument de l'efficacité énergétique n'est pas jugé prioritaire par tous, d'autant plus face à un autre argument important : le rapport performances/prix. Comme à son habitude, Nvidia profite de l'effet nouveauté, de son image de marque et d'un écosystème un peu plus fournis pour ne pas chercher à attaquer la concurrence sur ce point.  Une concurrence qui l'a bien compris et qui a d'ailleurs annoncé juste avant l'arrivée de ces nouvelles GeForce une Radeon R7 265, au tarif proche de celui de la GTX 750 Ti mais avec des performances 20% supérieures. Ces Radeon R7 265 n'ont par contre toujours pas d'existence commerciale, mais cela ne devrait plus tarder selon AMD... un point qu'il faudra vérifier puisque les R7 260 sont peu disponibles alors qu'elles ont été annoncées en fin d'année passée ! Typiquement, la GeForce GTX 750 Ti, 140, se place plutôt tout juste au-dessus de la Radeon R7 260X 2 Go, 20 moins chère. La GeForce GTX 750, 115, se positionne de son côté au niveau de la Radeon R7 260, qui devrait également être 20 moins chère quand elle sera vraiment disponible. Ces prix sont assez variables d'une marque à l'autre et il s'agit de moyennes, mais 20 semble donc être le juste supplément estimé par Nvidia pour profiter d'une plus faible consommation et des avantages qui y sont liés. Si certains estimeront ce supplément adapté, nous pensons que la plupart des joueurs au budget limité préféreront cependant opter pour un modèle concurrent un peu plus performant. Et pas uniquement concurrent d'ailleurs, puisque pour quelques euros de plus qu'une GTX 750 Ti, la GeForce GTX 660 affiche des performances 25% plus élevées et reste une valeur sûre. Pour conclure, après avoir testé de nombreuses cartes sur un moniteur classique avec des paramètres de qualité qui entraînent un framerate de l'ordre de 40-50 fps, nous ne pouvons qu'espérer que la technologie G-Sync, FreeSync, FRV ou peu importe le nom générique qu'elle prendra, se répande au plus vite ! Copyright © 1997-2026 HardWare.fr. Tous droits réservés. |