| |
| |
| Nvidia CUDA : plus en pratique Cartes Graphiques Publié le Jeudi 9 Août 2007 par Damien Triolet URL: /articles/678-1/nvidia-cuda-plus-pratique.html Page 1 - Introduction, rappel  Depuis notre première analyse de CUDA, de nombreux éléments ont évolués. Nvidia a lancé une gamme de produits dédiés, l'API s'est améliorée, nous avons eu l'occasion de nous entretenir avec les responsables principaux de ces technologies et avons pu tester avec une application pratique ce dont sont capables les GPUs face aux CPUs. Il était donc temps de proposer une suite à ce premier article que vous pouvez retrouver ici puisque nous ne reviendrons pas sur les détails qui ont déjà été expliqués en long et en large. Depuis notre première analyse de CUDA, de nombreux éléments ont évolués. Nvidia a lancé une gamme de produits dédiés, l'API s'est améliorée, nous avons eu l'occasion de nous entretenir avec les responsables principaux de ces technologies et avons pu tester avec une application pratique ce dont sont capables les GPUs face aux CPUs. Il était donc temps de proposer une suite à ce premier article que vous pouvez retrouver ici puisque nous ne reviendrons pas sur les détails qui ont déjà été expliqués en long et en large.Nous rappellerons simplement que derrière CUDA se cache une couche logicielle destinée au stream computing et une extension au langage de programmation C qui permet d'identifier certaines fonctions comme destinées à être traitée par le GPU au lieu du CPU. Ces fonctions sont alors compilées par un compilateur spécifique à CUDA ce qui leur permet d'être exécutées par les nombreuses unités de calcul des GPUs de classe GeForce 8 et supérieurs. Le GPU est ainsi vu comme un coprocesseur massivement parallèle qui est donc très bien adapté au traitement d'algorithme qui se parallélisent bien et très mal adapté aux autres. 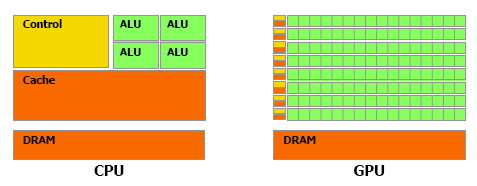 Une énorme proportion du GPU est dédiée à l'exécution, contrairement au CPU Contrairement à un CPU, un GPU dédie une part importante de ses transistors aux unités de calcul et très peu à la logique de contrôle. Autre différence significative, que nous avions trop négligée lors de notre précédent article (comme le montrerons les tests GPU vs CPU publiés dans cet article) : la bande passante mémoire. Un GPU moderne dispose ainsi de +/- 100 Go/s contre +/- 10 Go/s pour un CPU. Assemblages de processeursAutre rappel, la manière de nommer ce qui se passe dans un GPU à la façon de Nvidia. Un GeForce 8 est ainsi un assemblage de multiprocesseurs indépendants équipés chacun de 8 processeurs généralistes (appelés SP), qui effectuent toujours une même opération à la manière d'une unité SIMD, et de 2 processeurs spécialisés (appelés SFU). Un multiprocesseur se sert de ces 2 types de processeurs pour exécuter des instructions sur des groupes de 32 éléments. Chacun de ces éléments est appelé thread (à ne pas confondre avec un thread CPU!) et les groupes de 32 sont appelés warps. 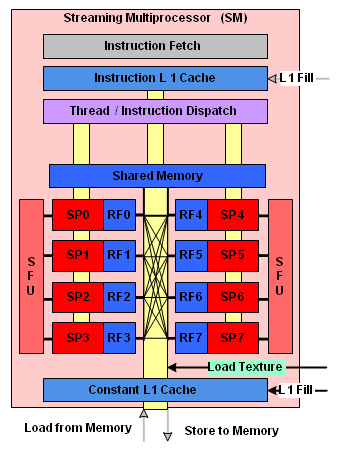 La représentation d'un multiprocesseur, le G80 en possède 16. Les unités de calcul (SP et SFU) fonctionnent à une fréquence double de la logique de gestion et atteignent 1.5 GHz avec la GeForce 8800 Ultra. Pour une opération simple qui ne nécessite qu'un seul cycle du point de vue de l'unité de calcul (et donc 0.5 cycles du point de vue du reste du multiprocesseur), il faudra donc 2 cycles pour qu'elle soit exécutée sur l'ensemble d'un warp. Un programme, appelé kernel, est exécuté dans un multiprocesseur sur un assemblage de blocs de warps qui peuvent en contenir jusqu'à 16 soit l'équivalent de 512 threads. Les threads d'un même bloc peuvent communiquer entre eux via une mémoire partagée. Page 2 - Exploiter le GeForce 8 Exploiter les GeForce 8Exploiter un GPU comme une unité de calcul peut sembler très complexe. Il ne s'agit pas de diviser la tâche à exécuter en une poignée de threads comme cela est nécessaire pour tirer partie d'un CPU multicore. Il sera plutôt question de milliers de threads ! Autrement dit essayer d'exploiter un GPU n'a aucun sens si la tâche à réaliser n'est pas massivement parallèle. C'est pour cette raison que les GPU s'opposent plutôt aux supercalculateurs qu'aux CPU multicores. Une application qui tourne sur un super calculateur est forcément prévue pour être divisée en un nombre énorme de threads. Un GPU peut donc être vu comme un supercalculateur bon marché qui est dépouillé de toute leur structure complexe. Le GPU, surtout chez Nvidia, conserve énormément de secrets puisque beaucoup de détails ne sont pas dévoilés, ce qui pourrait à priori laisser penser qu'on avance à l'aveuglette en essayant de développer un programme efficace pour ce type d'architecture. Bien que plus de détails seraient utiles dans certains cas, il ne faut pas oublier qu'un GPU est conçu dans l'optique de maximiser le débit de ses unités et par conséquent s'il est suffisamment alimenté il se charge tout seul d'exécuter le tout efficacement. Ce qui ne veut pas dire qu'avec plus de détails en tête il n'est pas possible de faire mieux, mais en se contentant au départ de connaître ce qui permet d'alimenter au mieux un GPU, il est possible d'obtenir des résultats satisfaisants. Ainsi il ne faut pas se dire qu'un GeForce 8800 dispose de 128 unités de calcul et donc qu'il a besoin de 128 threads pour être exploité. Il en faut bien plus, justement pour permettre au GPU de maximiser ses débits comme il le fait quand il travaille sur des milliers de pixels par exemple.  Lorsque l'on désire exploiter correctement un GPU de type GeForce 8 il faut structurer son programme et les données à traiter de manière à donner au GPU un nombre le plus élevé possible de threads tout en restant dans les limites du hardware qui sont :
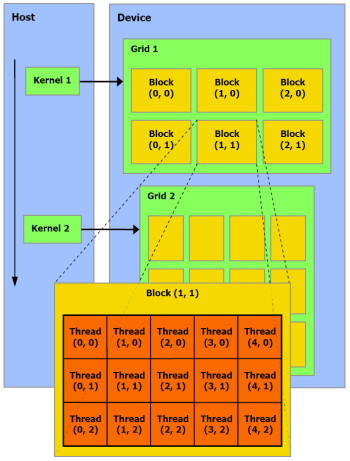 L'arrangement des threads en blocs et des blocs en grille de blocs (de 65536x65536x65536 blocs maximum) est à la charge du développeur. Un GPU de type GeForce peut ainsi exécuter un programme de maximum 2 millions d'instructions sur près de 150 billiards (10^15) de threads ! Ce ne sont bien entendu que des maximums. Chaque multiprocesseur peut disposer de 768 threads, autrement dit pour les remplir au maximum il faudra par exemple utiliser 2 blocs de 384 threads (soit 2x 12 warps). 10 registres pourront alors être utilisés par thread et chaque bloc pourra utiliser 8 Ko de mémoire partagée. Si plus de registres sont nécessaires, il faudra alors diminuer le nombre de threads par SM ce qui aura pour conséquence de réduire potentiellement le rendement du multiprocesseur vu qu'il disposera de moins de possibilités de maximiser le débit de ses unités de calcul.  Il faut également que le programme à exécuter représente un nombre suffisant de blocs puisque un GeForce 8800 dispose de 16 multiprocesseurs. Dans l'exemple précédent qui utilise 2 blocs de 384 threads par multiprocesseur, il faudra donc au moins 32 de ces blocs pour alimenter toutes les unités de calcul du GPU. Cela représente près de 25 000 threads. Pour exploiter plusieurs GPUs il faudra encore multiplier ce nombre par celui des GPUs. Le mieux étant bien entendu d'en prévoir beaucoup plus pour pouvoir profiter des futurs GPUs qui disposeront de plus d'unités de calcul etc. Prévoir une centaine voire un millier de blocs de threads n'est donc pas un luxe. Selon nous, le côté complexe qui est souvent donné à l'utilisation d'un GPU comme unité calcul provient avant tout du fait qu'on a du mal à visualiser comment faire tourner dessus un programme qui ne se parallélise pas bien. Mais c'est un faux problème et une perte de temps, cela ne sert à rien de chercher à faire tourner ce genre de chose sur un GPU. Page 3 - CUDA évolue CUDA évolueIl est maintenant évident que CUDA n'a pas simplement été une annonce de Nvidia de manière à remplir les documents marketing et/ou à voir si le marché y prête un intérêt, mais bien d'une stratégie à long terme basée sur le sentiment qu'un marché des accélérateurs est en train de se former et devrait grandir rapidement dans les années à venir. L'équipe qui s'occupe de CUDA travaille donc d'arrache pied pour faire évoluer le langage, améliorer le compilateur, rendre l'utilisation plus flexible etc. Depuis la version 0.8 beta du mois de février, les versions 0.9beta et finalement 1.0 ont permis à CUDA de rendre viable l'utilisation des GPUs comme coprocesseurs. Plus de flexibilité et une meilleure robustesse étaient nécessaires bien que la version 0.8 était déjà très prometteuse. Ces évolutions régulières permettent également d'augmenter le capital confiance dont commence à bénéficier CUDA. 2 évolutions principales sont à retenir. La première est le fonctionnement asynchrone de CUDA. Comme nous l'expliquions dans notre précédent article, la version 0.8 souffrait d'une grosse limitation puisque une fois que le CPU avait envoyé le travail au GPU, il était bloqué le temps que celui-ci envoie les résultats. Le CPU et le GPU ne pouvaient donc pas travailler en même temps. Un gros frein aux performances. Un autre problème se posait dans le cas d'un système de calcul équipé de plusieurs GPUs. Il fallait un core de CPU par GPU pour pouvoir profiter de ceux-ci. Pas très efficace ni pratique. Nvidia le savait bien entendu et ce fonctionnement synchrone des premières versions de CUDA avait probablement été utilisé pour faciliter la mise en place rapide d'une version fonctionnelle de CUDA sans devoir se soucier des points délicats. Avec CUDA 0.9 et donc 1.0, ce problème disparaît et le CPU est libéré une fois qu'il a envoyé le programme à exécuter au GPU (sauf quand l'accès aux textures est utilisé). Dans le cas de l'exploitation de nombreux GPUs, il reste cependant nécessaire de créer un thread CPU par GPU puisque CUDA n'autorise pas le pilotage de 2 GPUs à partir d'un même thread. Ce n'est cependant pas un gros problème. Notez qu'une fonction est présente de manière à forcer un fonctionnement synchrone si cela s'avérait nécessaire. La seconde nouveauté principale sur le plan fonctionnel est l'apparition de fonctions atomiques. Une fonction atomique est une fonction qui va lire une donnée en mémoire, s'en servir dans une opération et écrire le résultat, sans qu'un autre accès à cet espace mémoire ne soit autorisé tant que l'opération n'est pas bouclée. Cela permet d'éviter ou tout du moins de réduire certains problèmes courants tels un thread qui essayerait de lire une valeur dont on ne sait pas si elle a déjà été modifiée ou pas. 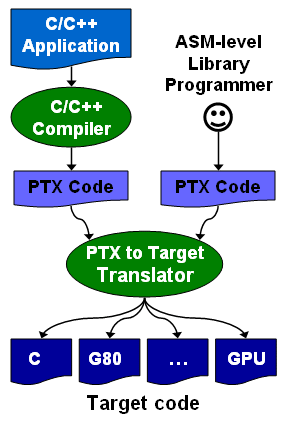 Enfin, avec CUDA 1.0, Nvidia distribue une documentation du PTX (Parallel Thread eXecution) qui est un langage assembleur intermédiaire entre le code de haut niveau et le code envoyé au GPU. Le PTX était déjà utilisé et les développeurs pouvaient y accéder, mais il n'était pas documenté. Probablement parce que le comportement des différents niveaux de compilations n'était pas encore défini clairement. Le PTX peut être utilisé pour optimiser certains algorithmes ou librairies ou tout simplement pour débuguer le code. Page 4 - La gamme Tesla La gamme TeslaAprès la gamme GeForce destinée au grand public et aux joueurs, la gamme Quadro destinée au professionnel de l'image, la gamme Tesla s'attaque au marché de la puissance de calcul.  Dans un premier temps, Nvidia a annoncé 3 produits. Le premier, le Tesla C870 est en quelque sorte une GeForce 8800 GTX dépourvue de sorties vidéo et donc destinée uniquement à servir d'accélérateur. La carte est par ailleurs équipée de 1.5 Go de mémoire vidéo au lieu de 768 Mo. Son prix est fixé à 1299$ ce qui reste raisonnable puisqu'une Quadro FX 5600 équipée elle aussi de 1.5 Go de mémoire coûte 2999$. La TDP est de 170W.  Le second élément de la gamme est le Tesla D870 qui reprend le concept des Quadro Plex. 2 cartes Tesla C870 prennent ainsi place dans un boîtier externe qui se raccorde au PC via une carte PCI express spéciale ainsi qu'un câble adapté. La TDP passe à 350W et le prix fait un bond à 7500$ ce qui reste malgré tout "bon marché" face au Quadro Plex de Quadro équivalentes proposé à 17500$. 2 de ces boîtiers peuvent prendre place dans une baie et occupent alors ensemble 3U.  Enfin le 3ème produit de la gamme est un rack 1U, le Tesla S870, équipé de pas moins de 4 Tesla C870, soit 4 G80 et 6 Go de mémoire vidéo en tout. Le rack se connecte à un système principal également en PCI Express et est déjà prêt pour le PCI Express 2.0 et ainsi booster les transferts entre le ou les CPU et les GPUs. La TDP est de 800W bien que Nvidia annonce une consommation qui en pratique se situe en général autour de 550W. Ce rack 1U est commercialisé au prix de 12000$.  Ces 3 produits sont annoncés avec une disponibilité prévue pour le courant de ce mois et Nvidia précise qu'un rack 1U équipé cette fois de 8 GPUs est en préparation. Concernant la stratégie à plus long terme de CUDA, Nvidia nous a rassuré sur le fait qu'il restera proposé sur toute la gamme de produits, Quadro et GeForce et ne sera pas réservé aux Tesla. CUDA devrait d'ailleurs bientôt faire partie intégrante des drivers grand public. Cependant, à l'avenir, certaines fonctions de CUDA ou des futurs GPUs pourraient être réservées à Tesla. Ce sera notamment le cas de la précision de calcul de 64 bits sur les flottants qui sera introduite avec le G92 et réservée aux Tesla (et à quelques Quadro haut de gamme). Page 5 - Et AMD ? Et AMD ?Si vous avez un petit peu suivi l'actualité autour du stream computing, vous devez savoir qu'AMD a été le premier à en parler. Tout d'abord en annonçant un accès bas niveau (langage machine) à ses GPUs lors du lancement des Radeon X1800 en octobre 2005. Cet accès, appelé DPVM pour Data Parallel Virtual Machine et renommé en CTM pour Close To Metal, n'a été détaillé que près d'un an après, soit en août 2006. Quelque mois après, lors de la concrétisation du rachat par AMD, les équipes d'ATI ont présenté quelques applications plus pratiques, une annonce qui tombait bien pour alimenter les discussions sur l'intérêt de ce rachat. Ces présentations ont été complétées par le lancement d'une version accélérée via Direct3D par les X1900 de Folding@home. Mais la CTM n'était toujours pas disponible et bien qu'ATI nous ait alors indiqué qu'une version CTM de Folding@home arriverait bientôt, nous n'en avons encore rien vu. A la mi-novembre 2006, AMD a lancé le premier produit spécifique à ce marché avec le Stream Processor qui est une Radeon X1900 dépourvue de sorties vidéos. Reste que contrairement à ce qui nous a toujours été dit, à savoir que CTM concernait toutes les cartes graphiques grand public, le driver CTM n'est livré qu'aux seuls utilisateurs de ces cartes qui doivent être en contact direct avec les développeurs d'AMD puisqu'il est introuvable sur le site du fabricant. De quoi finir par freiner notre enthousiasme et par agacer puisqu'en dehors des effets d'annonce systématiques au lancement des cartes grand public (ou pour justifier le rachat d'AMD) nous n'avons pas vu grand-chose de concret Du neuf avec les GPUs R6xx ?Avec le lancement des Radeon HD 2000, AMD est revenu sur le sujet en présentant toute une série d'évolutions. L'accès bas niveau CTM se verrait ainsi compléter par l'AMD Runtime qui est en quelque sorte l'équivalent du runtime de CUDA et est donc un accès plus haut niveau. La différence est que cet AMD Runtime pourrait exploiter aussi bien les CPU multicores que le ou les GPUs. Ensuite, la librairie de fonctions mathématiques d'AMD, ACML , optimisée pour ses CPUs, intègrerait des équivalents GPUs. Et enfin AMD proposerait des extensions aux langages C et C++ pour piloter le tout comme Nvidia le fait avec CUDA. 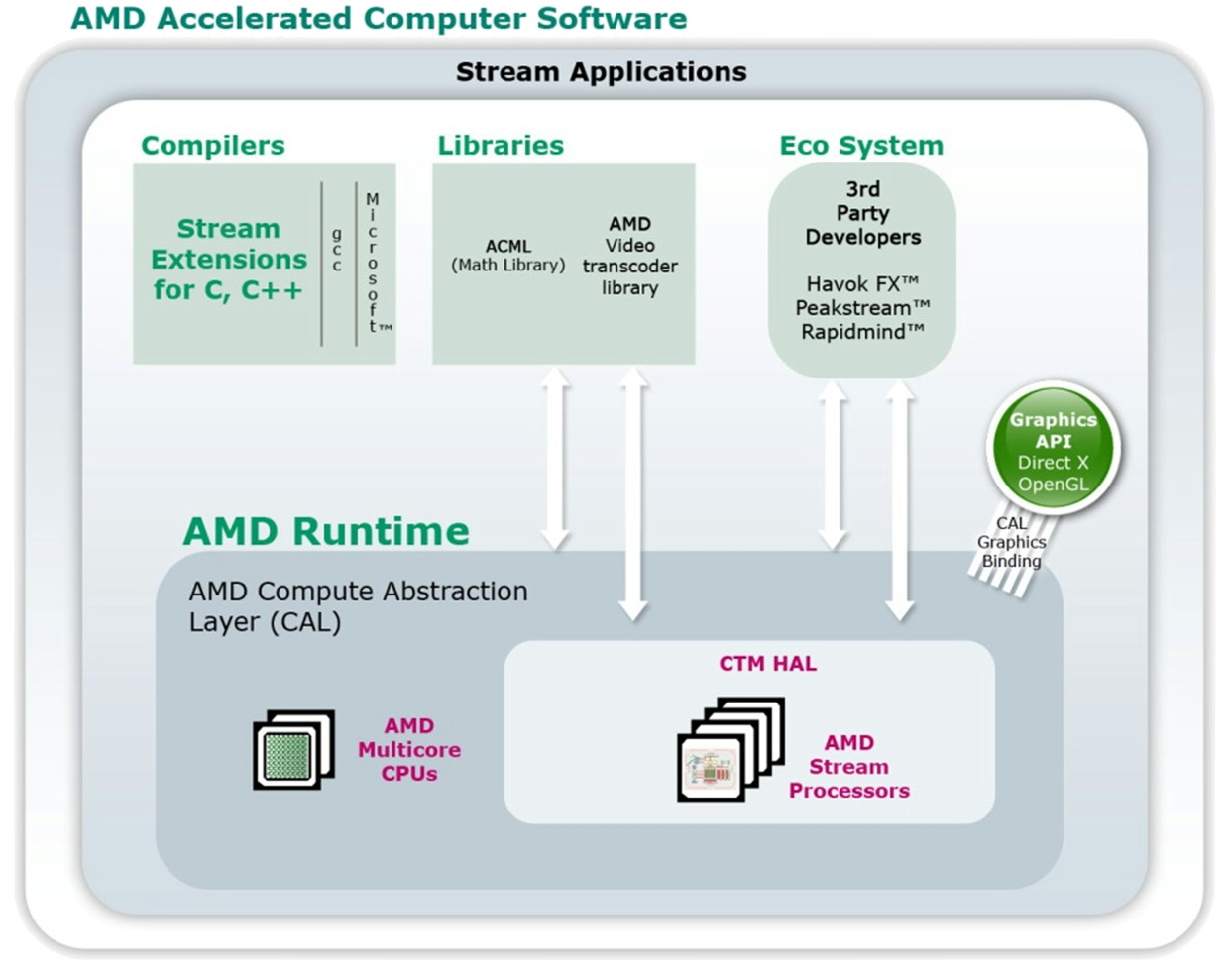 AMD semble donc emboîter le pas de Nvidia en passant à un mode d'utilisation de plus haut niveau. Pourtant AMD n'est pas avare de critiques envers CUDA présenté comme une solution "bonne à rien", c'est-à-dire trop complexe pour la plupart des développeurs et trop éloignée des spécificités exactes du GPU que pour pouvoir développer des librairies efficaces. Des critiques envers CUDA qui ne sont pas totalement fausses et on peut d'ailleurs supposer que cela a incité Nvidia à documenter le PTX. Avec CUDA Nvidia a fait le choix de proposer rapidement quelque chose d'utilisable quitte à ne proposer que plus tard des possibilités d'optimisation supplémentaires. Alors qu'AMD a été d'abord vers un langage bas niveau très complexe avant de proposer plus. Ou tout du moins avant de proposer des documents marketing qui disent que le constructeur va proposer plus que ce que nous n'avons toujours pas vu. Après plus de 2 ans sans rien voir venir, nous attendrons donc de voir du concret avant d'aller plus loin, c'est d'ailleurs pour cette raison que nous avons utilisé le conditionnel pour présenter les nouveautés et ne l'avons fait que très brièvement. Nous terminerons ce chapitre consacré à AMD par parler de l'architecture Radeon HD 2000 qui dispose de quelques avancées intéressantes dans le cadre d'une utilisation comme unité de calcul. Premièrement le Thread Generator est capable de générer des threads optimisés pour un traitement rapide (faible latence) ou optimisés pour maximiser le débit du GPU, ce qui permet en théorie de rendre plus efficaces certaines utilisations bien qu'AMD ne donne pas réellement de détails à ce niveau. Ensuite l'architecture mémoire des Radeon HD 2000 est beaucoup plus avancée que celle des GeForce 8. Nous citerons d'une part un accès généraliste caché à la mémoire vidéo tant en lecture qu'en écriture alors que ces accès ne le sont pas avec les autres GPUs. Et d'autre part un moteur indépendant pour gérer les transferts PCI Express parallèlement au reste du GPU. Sur un GeForce 8, le GPU est bloqué durant ces transferts. 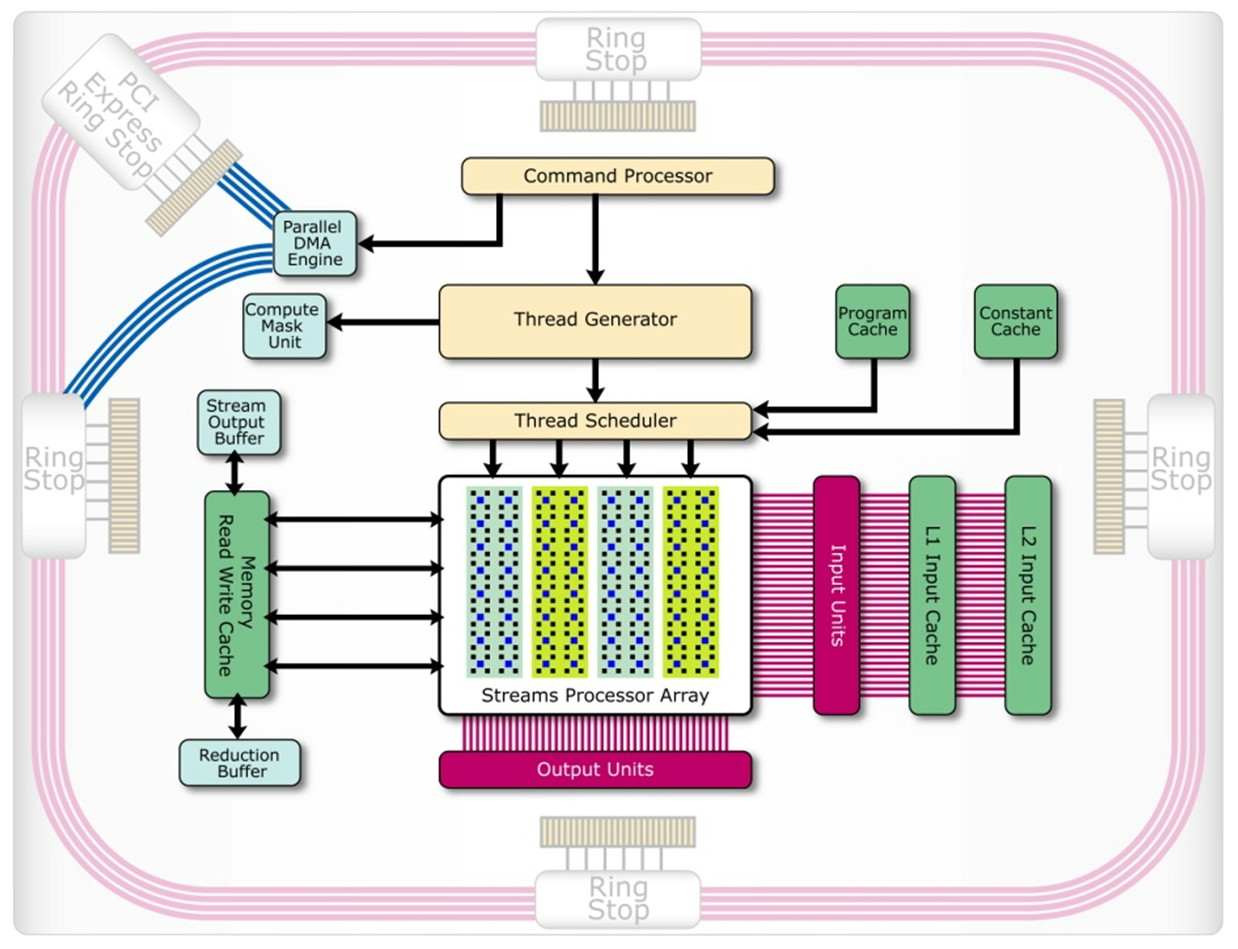 Les puces de génération R600 semblent donc bien armées pour le Sream Computing et pourraient permettre à AMD de prendre l'avantage sur Nvidia. Mais comme le dit si bien AMD, le matériel ce n'est que la moitié de l'histoire et l'autre moitié, on n'en a pas encore vu grand-chose Page 6 - Autres concurrents, utilité D'autres concurrentsNvidia et AMD ne sont pas les seuls à essayer de s'engager sur le marché des processeurs massivement parallèles. IBM (ainsi que Sony mais probablement plus pour faire parler de la PS3 qu'autre chose) propose ainsi un BladeCenter basé sur 2 processeurs Cell. Pour rappel, le Cell est composé d'un core généraliste accompagné d'un bloc de 8 cores destinés au calcul parallèle. IBM propose déjà tout un environnement de développement autour de cette plateforme. Par rapport à une GeForce 8800, un Cell dispose de moins d'unités de calcul et de moins de bande passante mémoire, mais d'une fréquence plus élevée et de plus de mémoire locale aux unités de calcul (256 Ko contre 8-16 Ko dans un GeForce 8).  IBM commercialise un BladeCenter équipé de 2 processeurs Cell Intel planche lui aussi sur le problème avec le projet Larabee qui est une puce massivement parallèle destinée à faire office de GPU mais également de coprocesseur. Dans ses présentations censées être confidentielles, Intel fait mention de 16 à 24 cores qui disposeraient d'unités SSE 512 bits (soit 16 opérations 32 bits par cycle et par core !). Chacun de ces cores disposerait d'un cache L1 de 32 Ko et d'un L2 de 256 Ko, le tout accompagné par un cache global de 4 Mo. Larabee est attendu pour 2009 ou 2010 et aura comme gros avantage d'être basé sur l'architecture x86. 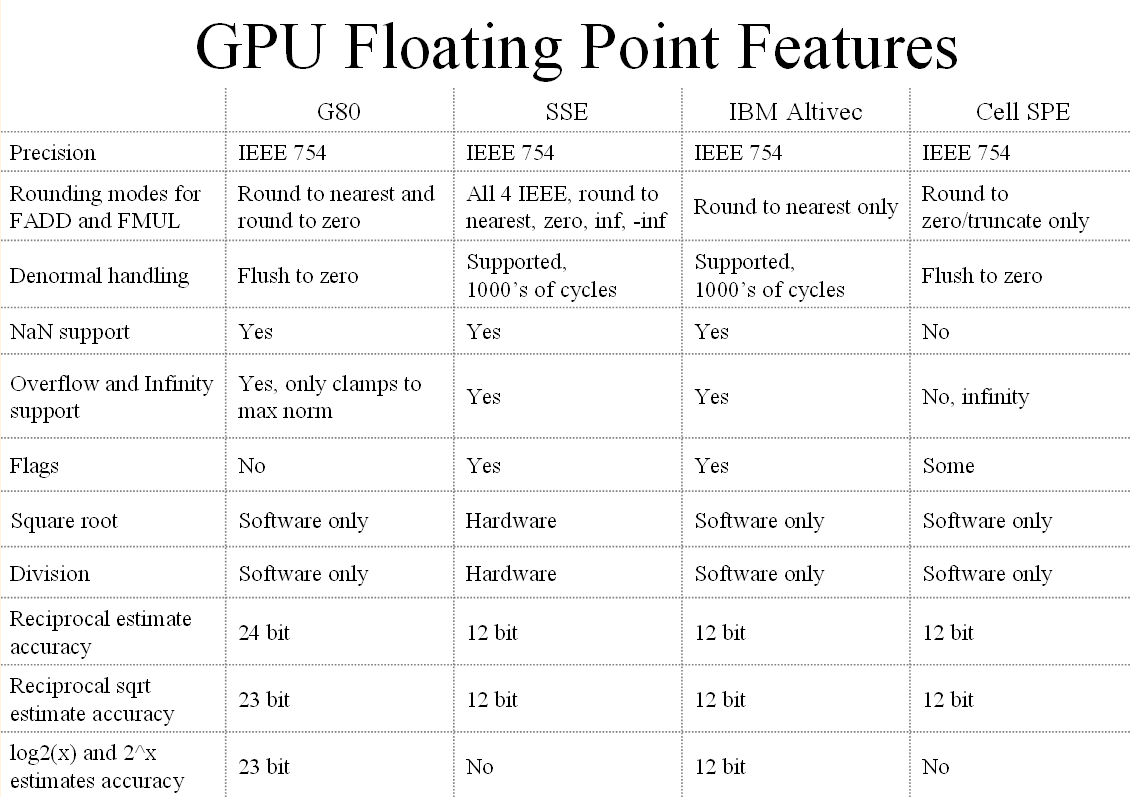 Les unités de calcul de chaque architecture se comportent d'une manière différente. Quelle utilité ?Mais à quoi peuvent bien servir ces unités de calcul ? Ni à jouer, ni à accélérer internet. Entendez par là qu'il ne s'agit pas, tout du moins à l'heure actuelle, d'une utilisation grand public mais bien d'une utilisation professionnelle. De nombreuses applications scientifiques ont besoin d'une puissance de calcul énorme qu'aucun processeur généraliste ne peut fournir. La solution est donc de créer d'énormes supercalculateurs à base de centaines voire de milliers de processeurs. La conception de ces calculateurs est très complexe très longue et très coûteuse. Là où un processeur massivement parallèle est efficace, il permet à un coût / encombrement identique d'offrir bien plus de puissance de calcul ou d'offrir la même prestation à moindre frais. Selon nous, il n'est pas envisagé dans l'immédiat de construire un immense supercalculateur à base de GPUs. Ils devront d'abord faire leurs preuves et gagner en maturité puisqu'il n'est pas question de prendre des risques à ce niveau. Il serait d'ailleurs intéressant que Nvidia fournisse plus d'informations sur la fiabilité de ses puces, taux d'erreur (la mémoire n'est pas ECC par exemple), taux de pannes etc. Interrogé à ce sujet à chaque annonce liée au stream computing, Nvidia n'a jamais pu y répondre, un point qui semble donc négligé actuellement, peut-être volontairement puisque le marketing préfère ne pas rendre public ce genre de données. Il ne faudrait pas qu'on arrête de penser que les GeForce ne tombent jamais en panne et ne font jamais d'erreur.  L'utilisation actuelle concerne plutôt la mise en place de systèmes qui étaient irréalisables sans de telles puces. On imagine bien entendu mal placer un supercalculateur dans chaque service des hôpitaux par exemple. Un accélérateur tel que Tesla peut permettre à une station de travail de réaliser des tâches qui étaient impensables auparavant. Ou de réaliser presque en temps réel des opérations qui peuvent être très longues. Lors d'une présentation à la presse fin mai, Nvidia avait invité quelques partenaires qui nous ont fait la démonstration de plusieurs utilisations pratiques des GPUs. Acceleware est une société qui développe des plateformes à base de GPUs destinées à accélérer un certain nombre de fonctions. Cette plateforme est utilisée par les clients d'Acceleware pour accélérer leur application. Acceleware nous a fait la démonstration d'une simulation de l'impact des radiations émises par un GSM sur les tissus humain mais a cité d'autres utilisations de sa plateforme, par exemple pour aider au dépistage rapide du cancer du sein ou pour réaliser des simulations liées aux pacemakers.  Evolved Machine est une société qui essaye de comprendre le fonctionnement des neurones de manière à pouvoir en reproduire les circuits et créer des systèmes capables par exemple d'apprendre et de reconnaître des objets ou des odeurs, comme nous le faisons naturellement. Simuler un seul neurone représente l'évaluation de 200 millions d'équations différentielles par seconde. Quand on sait qu'une structure basique de neurones en représente des milliers on imagine facilement la masse énorme de calcul à traiter. Evolved Machine indique avoir constaté un gain de 130x en vitesse de traitement en utilisant des GPUs et travaille sur le développement d'un rack de GPUs qui sera capable de rivaliser les meilleurs supercalculateurs du monde pour 1/100ème de leur coût.  Headwave développe des solutions destinées à l'analyse des données géophysiques. Les compagnies pétrolières ont de plus en plus de mal à trouver de nouvelles réserves de pétrole et de gaz. Les gisements détectés à une grande profondeur sont difficiles à analyser. Une quantité énorme de données doit être récoltée et ensuite traitée. Le traitement est d'ailleurs tellement lourd que les données récoltées s'accumulent à une vitesse vertigineuse et ne peuvent pas être analysées par manque de puissance de calcul. L'utilisation des GPUs permet d'accélérer significativement ces analyses notamment un rendant possible un affichage en temps réel. D'après Headwave l'infrastructure pour profiter des GPUs est déjà en place et les compagnies pétrolières sont prêtes et impatientes d'utiliser cette technologie.  Page 7 - VMD : le test 1/2 John Stone , Senior Research Programmer dans le département Theorical and Computanional Biophysics du Beckman Institute for Advanced Science and Technology de l'université d'Illinois (UIUC), développeur principal de VMD, et que nous remercions au passage pour son aide, a pu nous fournir de quoi tester les GPUs et les CPUs dans une application pratique et massivement parallèle. VMD, pour Visual Molecular Dynamics, est un outil qui permet de visualiser, animer et analyser des molécules biologiques énormes. Il est bien entendu capable d'utiliser un GPU pour le rendu de ces molécules, mais également pour la partie analyse et simulation.  Pour étudier une molécule biologique, il faut en général la placer dans un environnement réaliste, c'est-à-dire entourée d'eau et d'ions. Le placement de ces ions est une tâche relativement lourde avec les grosses molécules. La partie la plus exigeante de cette opération est le calcul d'une carte de potentiel coulombique autour de la molécule. C'est cette opération que nous avons testée sur les GPUs et sur les CPUs. Protocole de testAprès avoir réalisé quelques tests initiaux avec les versions beta de VMD fournies par John, nous avons utilisés les dernières builds compilées pour CUDA 1.0 d'un côté et compilée avec les outils Intel et donc optimisée SSE de l'autre côté. Les algorithmes ont été optimisés pour chaque plateforme et varient donc légèrement. La version CPU fait ainsi appel à plus de précalcul que la version GPU. VMD en version CUDA a tout d'abord été développé sur base de CUDA 0.8 qui avait besoin d'un core de CPU par GPU piloté. Cette limitation est restée d'application puisqu'elle est à la base même de la structure du code. Qui plus est, l'application divise la tâche à accomplir d'une manière fixe entre les différents CPUs/GPUs. Si l'application détecte 2 GPUs (et assez de cores CPUs pour les gérer), elle va diviser la tâche par 2, peu importe la puissance des GPUs. Autrement dit, un GPU plus rapide qui aurait terminé son travail plus vite devra attendre son collègue plus lent. Utiliser une GeForce 8800 Ultra et une GeForce 8400 GS revient à utiliser 2 GeForce 8400 GS. Les tests ont été réalisés sous Linux, avec Fedora Core 7. Nous avons testé toute la gamme GeForce 8 (+ le modèle Superclocked d'eVGA) avec un Core 2 Extreme QX6850 équipé de 2 Go de mémoire DDR2 800 MHz, le tout prenant place sur la carte-mère eVGA à base de nForce 680i. Pour les tests du QX6850 et du E6850 nous avons utilisé la même plateforme avec une GeForce 8400 GS.   3 GeForce 8800 contre le V8 d'Intel. D'autre part, nous avons effectués les mêmes tests sur la plateforme V8 d'Intel qui repose sur 2 Xeon X5365 (quadcore, 3 GHz, identique au QX6850) et le chipset 5000X qui supporte 4 canaux FBDIMM et des FSB distincts pour chacun des CPUs. Les 4 Go de mémoire utilisés reposant sur de la DDR2 à 667 MHz, nous obtenons 5.33 Go/s par canal, soit une bande passante de 21.33 Go/s au total. Notez que cette valeur n'est valable que pour la lecture puisque la bande passant en écriture est réduite de moitié. La GeForce 8400 GS est utilisée ici aussi pour l'affichage. Nous reportons les résultats obtenus sur la première partie traitée, le traitement de la molécule entière prenant trop de temps. Les résultatsNous reportons tout d'abord le temps de calcul et le nombre de milliards d'évaluations d'atomes par seconde. Il s'agit des mêmes valeurs mais mises en forme différemment de manière à ce que les performances des extrêmes soient représentées plus clairement.  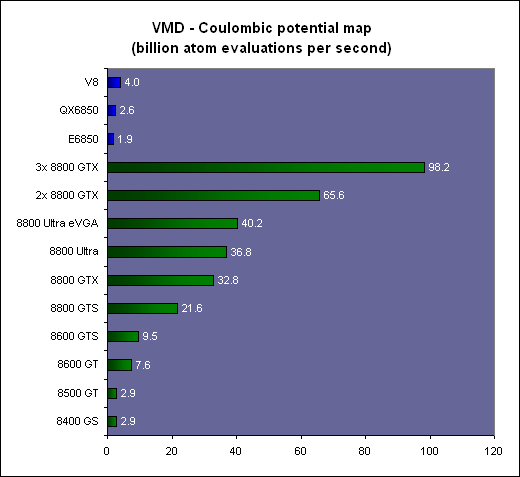 Là où il faut près de 4 minutes à une GeForce 8800 Ultra pour terminer le travail, il faut près d'une heure au Core 2 Extreme QX6850 qui est ici plus lent qu'une GeForce 8400 GS ! Le V8 fait un petit peu mieux mais reste loin de ce que permettent les GPUs haut de gamme dans une application massivement parallèle telle que celle-ci. Comme vous pouvez le remarquer, les performances scalent presque parfaitement lorsque l'on utilise plusieurs GeForce 8. Par contre ce n'est pas le cas CPUs. Pourquoi ? Nous allons y répondre. Page 8 - VMD : le test 2/2 CPU ScalingLe logiciel est prévu pour scaler presque parfaitement mais d'après nos résultats ce ne serait pas le cas avec les CPUs. Etrange. Nous avons décidé de tester le QX6850 avec 1, 2 et 4 cores pour observer ce qui se passe : 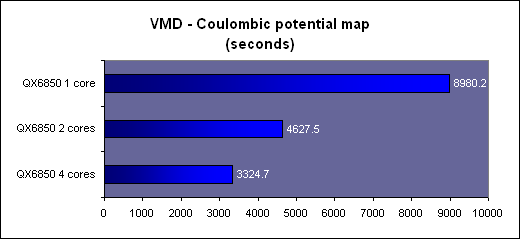 Entre 1 et 2 cores, les performances scalent très bien puisque les performances augmentent de 93%. Par contre en passant de 2 à 4 cores, le gain n'est que de 39% et pourtant tous les 4 cores tournent à plein régime. Que se passe-t-il ? A ce moment nous nous rappelons que chaque GPU ajouté dispose de sa propre mémoire et donc de sa propre bande passante alors que les cores CPUs ajoutés doivent se partager une même bande passante mémoire. Afin de vérifier que ces gains limités sont bien dus à une insuffisance de bande passante mémoire, nous avons réalisé un test supplémentaire, cette fois sur la plateforme V8 en retirant des modules mémoire de manière à tester les performances avec 1, 2 et 4 canaux FB-DIMM soit avec 5.33, 10.66 et 21.33 Go/s de bande passante mémoire. Il s'agit de modules de 1 Go or la consommation mémoire totale du système ne dépasse pas les 900 Mo quand le test tourne, nous ne sommes donc pas limités par la présence de seulement 1 Go. 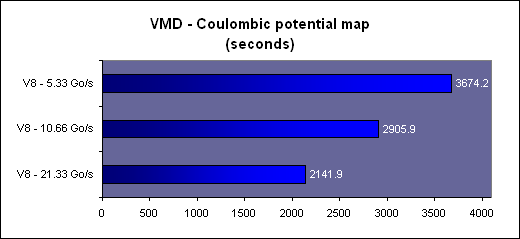 La bande passante mémoire a bien une influence conséquente sur les performances et est donc un facteur limitant, surtout sur les CPUs multicores dont les cores doivent se la partager. ConsommationNous avons mesuré à la prise la consommation des systèmes en charge avec une alimentation Enermax Galaxy 850 Watts : 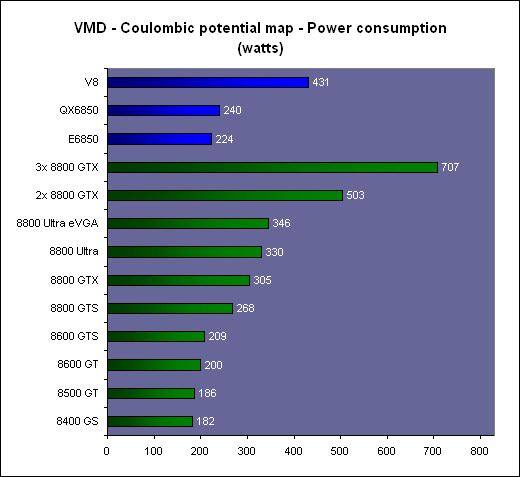 Les 3 GeForce 8800 affichent plus de 700 Watts au compteur ! Notez que un core CPU est utilisé par GPU et donc que la différence entre 2 et 3 cartes par exemple ne consiste pas uniquement en la consommation d'une 8800 mais bien d'une 8800 + d'un core CPU au travail. Si la différence entre le QX6850 et le E6850 est faible, c'est parce que le QX6850 passe beaucoup de temps à attendre de récupérer des données de la mémoire. 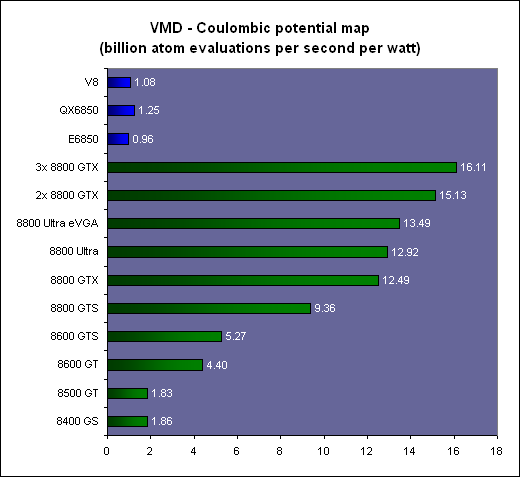 Une fois que nous mettons la consommation en relation avec les performances, nous pouvons constater un net avantages dû à l'utilisation des GPUs. Plus le ratio puissance GPU / puissance CPU est élevé, plus le rendement par watt augmente. Tout du moins sur la plage de données testée puisqu'il est évident que ce rendement ne continuera pas d'augmenter à partir du moment où le/les CPUs ne seront plus capables d'alimenter correctement les GPUs. Page 9 - Conclusion ConclusionCette seconde approche de CUDA a été fort intéressante. CUDA a gagné en performances, en flexibilité et en robustesse et bien que la liste des fonctions à ajouter et des petits bugs à corriger représente probablement de quoi occuper les ingénieurs de Nvidia pendant quelques temps, CUDA est réellement utilisable et exploitable. Nous avons pu évaluer les performances des GPU de classe GeForce 8 de Nvidia dans une application pratique et ainsi constater un net avantage face aux CPUs sur un algorithme qui leur était pourtant initialement destiné. De quoi ouvrir de nouvelles perspectives pour ce type d'application. Des résultats qui tranchent avec notre précédente conclusion sur CUDA dans laquelle nous indiquions que la puissance déployée par le GeForce 8800 n'était pas encore suffisante pour réellement justifier un nouveau développement face aux systèmes multi-CPUs. Nous avions alors sous-estimé 2 points importants.  Le premier est qu'un GPU haut de gamme va disposer d'une bande passante mémoire de 100 Go/s là où les quatre cores d'un CPU doivent se partager 10 Go/s. Une différence significative qui limite les CPUs dans certains cas. Le second point est qu'un GPU est conçu pour maximiser le débit. Il va donc automatiquement utiliser un nombre très élevé de threads pour maximiser son rendement là où un CPU passera beaucoup plus souvent de nombreux cycles à attendre. Ces 2 raisons permettent aux GPUs de prendre un avantage énorme sur les CPUs dans certaines applications telles que celle testée. Exploiter un GPU à travers CUDA peut sembler très difficile voire hasardeux au premier abord, mais est en réalité plus simple que ce que la plupart des gens ne le pensent. La raison est qu'un GPU n'est pas destiné à remplacer un CPU mais bien à l'épauler pour certaines tâches spécifiques. Il ne s'agit pas d'essayer de paralléliser une tâche pour exploiter plusieurs cores (comme c'est le cas actuellement avec les CPUs) mais d'implémenter une tâche qui est, de part sa nature, massivement parallèle, et elles sont nombreuses. On n'utilise pas une voiture de course pour transporter un troupeau de bétail et on n'utilise pas un tracteur pour concourir en F1. C'est la même chose avec les GPUs. Il s'agit donc avant tout de rendre efficace un algorithme massivement parallèle par rapport à une architecture donnée.  Une erreur serait de se limiter à voir un GPU tel que le GeForce 8800 comme un amas de 128 cores qu'il faudrait essayer d'exploiter en segmentant son algorithme. Un GeForce 8800 ce n'est pas simplement 128 processeurs mais avant tout jusqu'à 25.000 threads en vol ! Il faut donc fournir au GPU un nombre énorme de threads, en essayant qu'ils restent dans les limites du hardware pour un rendement maximal, et laisser ce GPU se charger de les exécuter efficacement. Il faut ainsi laisser de côté certains points pourtant très importants lorsque l'on développe sur un CPU et se concentrer sur d'autres. Un changement de manière de travailler qui est malheureusement encore très peu enseigné dans les universités. Nvidia est conscient de ce problème et sait qu'il s'agit d'un élément clé dans le succès de l'utilisation des ses puces comme unité de calcul. David Kirk, Chief Scientist chez Nvidia, s'est ainsi chargé de donner un cours dédié à l'apprentissage de la programmation massivement parallèle à l'université d'Illinois à Urbana-Champaign et Nvidia a soutenu et sponsorisés d'autres cours similaires. Le cours de David Kirk, très intéressant, est disponible en ligne et présenté comme un kit d'apprentissage libre d'utilisation. Si le cours utilise l'exemple de la GeForce 8800, les concepts qui y sont présentés ne sont pas réellement spécifiques à une architecture donnée, à l'exception des optimisations bien entendu. Vous pouvez le retrouver ici : ECE 498 AL : Programming Massively Parallel Processors Par ailleurs, si le sujet vous intéresse, nous vous conseillons les retranscriptions publiées par Beyond3D des interviews de David Kirk , d'Andy Keane et de Ian Buck , respectivement Chief Scientist, General Manager du GPU Computing Group et CUDA Software Manager. Copyright © 1997-2026 HardWare.fr. Tous droits réservés. |