| |
| |
| ATI Radeon HD 2900 XT Cartes Graphiques Publié le Mardi 15 Mai 2007 par Damien Triolet URL: /articles/671-1/ati-radeon-hd-2900-xt.html Page 1 - Introduction Après de longs mois d'attente, le R600, ou plutôt le Radeon HD 2900 fait enfin son apparition. Qu'apporte cette première puce DirectX 10 signée AMD ? L'évolution vers DirectX 10Comme nous l'avons déjà expliqué lors des tests des différentes générations de cartes graphique ATI et maintenant AMD, leur évolution a été constante depuis le Radeon 9700, sans qu'il y ait de réelle rupture, contrairement à ce que l'on a pu voir chez Nvidia en partie avec les GeForce 6 mais surtout avec les GeForce 8 dont l'architecture est totalement nouvelle.  L'architecture Radeon HD2000 ne déroge pas à cette règle et s'inscrit clairement dans la lignée des précédents Radeon. Petite subtilité cependant : la lignée des Radeon s'est séparée en 2 avec d'une part l'architecture R500 et d'autre part l'architecture du Xenos qui équipe la Xbox 360. Celles-ci ne sont cependant pas si différente que cela; bien que l'une soit unifiée et pas l'autre leurs shaders cores ont des propriétés similaires telles que le traitement des données par petits paquets, les unités de texturing découplée et donc indépendante du reste du shader core etc. L'architecture Radeon HD2000 ne déroge pas à cette règle et s'inscrit clairement dans la lignée des précédents Radeon. Petite subtilité cependant : la lignée des Radeon s'est séparée en 2 avec d'une part l'architecture R500 et d'autre part l'architecture du Xenos qui équipe la Xbox 360. Celles-ci ne sont cependant pas si différente que cela; bien que l'une soit unifiée et pas l'autre leurs shaders cores ont des propriétés similaires telles que le traitement des données par petits paquets, les unités de texturing découplée et donc indépendante du reste du shader core etc.Nous ne reviendrons pas en long et en large sur le principe d'une architecture unifiée qui a déjà été évoqué à maintes reprises. Rappelons simplement qu'il permet, au prix d'une gestion plus complexe, d'attribuer dynamiquement les unités de calcul aux opérations (sur les pixels ou sur les vertices) qui en ont le plus besoin à un moment donné. Le gaspillage des ressources est ainsi fortement réduit et certains cas très spécifiques peuvent être traitées très rapidement vu que l'ensemble des ressources du GPU peuvent leur être attribuées. C'est principalement le cas au niveau géométrique puisque comme vous le savez le nombre d'unités de traitement des vertices est bien plus réduit que celui des unités de traitement des pixels dans les architectures classiques. 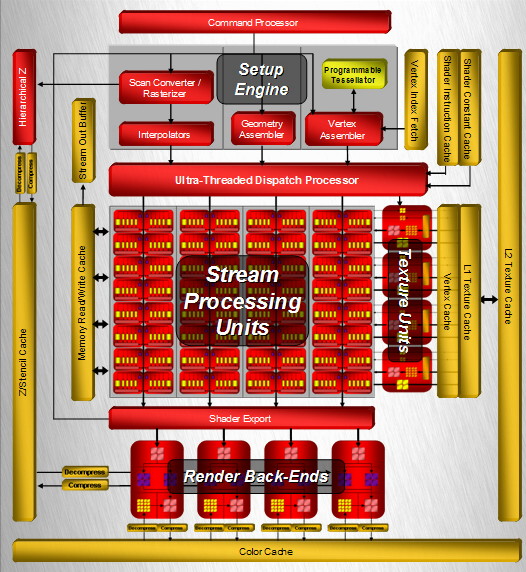 AMD s'est donc basé sur son architecture Xenos unifiée pour créer les Radeon HD2000. D'un point de vue fonctionnalité, la différence principale est l'ajout du support de DirectX 10 grâce à une gestion plus souple des ressources (registres, constantes etc.), au support des opérations sur les entiers et au support des Geometry Shader. Les unités de calcul ont ainsi subit un petit lifting et gagné en flexibilité, ce qui permet à AMD de parler d'architecture superscalaire, nous développerons ce point par la suite. L'unité de tesselation de la Xbox 360 reste dans cette architecture bien qu'elle ne soit pas prise en charge par l'API de Microsoft, nous reviendrons sur ce point. L'architecture a été élargie et passe de 48 processeurs à 64. Que valent ceux-ci face aux 128 du GeForce 8800 ? Nous allons vous l'expliquer.  Le Radeon HD 2900 et ses 700 millions de transistors Page 2 - Architecture scalaire ? Moi aussi je veux être scalaireIl y a des modes, c'est comme cela. Nvidia parle de processeurs scalaires, cela fonctionne très bien donc AMD lui emboîte le pas et parle de 320 processeurs scalaires pour son nouveau GPU. Le GeForce 8800 semble ainsi faire petit joueur puisqu'il n'en dispose que de 128. Mais Nvidia et AMD parlent-ils de la même chose ? Pas réellement. 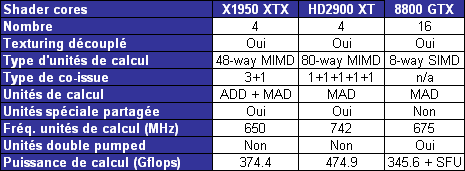 Nous laisserons ici de côté, la vision GPGPU des choses qui avec un peu d'abstraction permet de voir les choses sous un autre angle pour nous concentrer sur l'aspect plus pratique. Un GPU calcule avant tout des vertices et des pixels. Le GeForce 8800 peut calculer 128 de ces éléments en même temps, en décomposant toutes les instructions en instructions scalaires qui vont être exécutées l'une après l'autre. Le Radeon HD2000 pour sa part va traiter 64 de ces éléments en parallèle mais travaille avec des unités 5D c'est-à-dire capables de traiter non pas une seule instruction mais jusqu'à 5. Pour rappel, un Radeon X1000 peut en traiter 4 par élément pour les pixels shaders et 5 pour les vertex shaders. Le nombre de 5 a donc été choisit pour que les développements passés soient toujours d'actualité. Il s'agit d'une unité vectorielle MIMD 5-way. MIMD signifie, contrairement à SIMD que plusieurs instructions différentes peuvent être traitées en parallèle. C'était déjà le cas auparavant avec la co-issue de type 3+1 (et même 2+2 dans les GeForce 6 et 7). Ici AMD pousse ce concept de co-issue jusqu'à son paroxysme puisque le mode 1+1+1+1+1 est possible et donc bien entendu toutes les autres combinaisons. 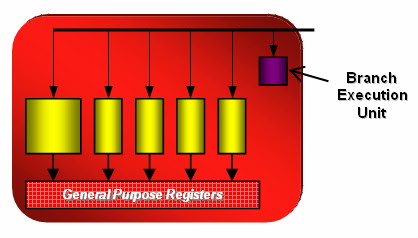 Une des 64 unités de calcul du R600. Elle est composée de 5 unités de calcul, dont une capable de prendre en charge les opérations spéciales et d'une unité de traitement des opérations de branchements. Mais 64x5 est très différent de 320. En effet, ces 5 instructions ne peuvent pas être dépendantes l'une de l'autre. Dans le GeForce 8800 chaque instruction peut être la suite de la précédente. Cela signifie qu'alors que le compilateur du GeForce 8 va casser les opérations vectorielles en opérations scalaires, le compilateur des Radeon HD2000 va faire l'opération inverse et essayer d'assembler des opérations simples entre elles de manière à remplir l'unité MIMD 5D. Ces unités sont ainsi de type VLIW, pour very long instruction word, ce qui signifie que l'instruction envoyé au GPU (qui combine ou plutôt essaye de combiner des instructions plus simples) est longue et complexe : 512 bits ! Ce choix d'architecture permet d'augmenter la densité des unités de calcul mais reporte une grande partie du travail sur le compilateur, ce qui réduit l'efficacité de la puce. Ajoutons à ce sujet qu'il est heureux que Nvidia n'ait pas opté pour ce type d'architecture vu les récents problèmes de drivers ! Concernant les fonctions spéciales (sin, cos, exp, log, etc.) et les opérations sur les entiers 32 bits, du côté GeForce 8 elles sont prises en charge par une unité supplémentaire, qui a cependant un débit effectif 4x plus lent que les autres unités. Du côté d'AMD une des 5 composantes de chaque unité de calcul est capable de traiter ces opérations. Autrement dit, une GeForce 8800 peut traiter 128 opérations classiques + 32 opérations spéciales en même temps alors qu'une Radeon HD 2600 peut traiter 320 opérations classiques ou 256 opérations classiques + 64 opérations spéciales. L'efficacité supérieure de l'architecture de Nvidia permet-elle de compenser cette différence ? Non. Mais Nvidia a fait appel à une technique qu'Intel avait utilisée avec les ALUs du Pentium 4 : les unités douple pumped c'est-à-dire qui travaillent à double fréquence. Vu de la structure du shader core du GeForce 8800 (675 MHz pour le GeForce 8800 GTX, 1350 MHz étant une simplification), les unités sont capables de traiter 256 opérations classiques + 64 opérations spéciales par cycle soit des débits identiques à ceux du Radeon HD 2900. Le Radeon HD 2900 voit donc opposé son débit plus élevé en opérations simples (MAD/MUL/ADD) et sa fréquence supérieure (742 MHz) à une architecture plus efficace. Concernant l'implémentation, du côté de Nvidia les processeurs scalaires sont groupés par paquet de 8 et traitent des blocs de 32 éléments, 8 par 8, ce qui permet de masquer la latence des unités de calcul. Du côté d'AMD, les unités MIMD 5D sont groupées par paquet de 16 et traitent des blocs de 64 éléments, 16 par 16, pour les mêmes raisons. Par ailleurs chacun de ces groupes d'unités dispose en général de 2 paquets de données à traiter de manière à pouvoir passer de l'un à l'autre et masquer aussi efficacement que possible la latence de traitement. Page 3 - Ring bus, unités de texturing Ring bus 2.0Dans son implémentation "carte graphique", pour le R600, larchitecture a vu son sous-système mémoire complètement revu pour (il est basé sur une puce eDRAM sur console) et similaire à celui des Radeon X1000. Le ring bus est donc toujours d'actualité. Plus encore même puisqu'il est maintenant utilisé dans les 2 sens : pour l'envoi et pour la réception des données alors qu'il ne l'était que pour la réception. L'intérêt principal d'un ring bus est de faciliter le design de la puce et d'éviter d'avoir un câblage trop dense au cur du GPU ce qui peut finir par poser de nombreux problèmes. En ce qui concerne le Radeon HD 2900, le ring bus est de 512 bits dans les 2 sens, soit 1024 au total. Notez que les sens de circulation sur le ring bus ne sont pas liés à l'envoi/réception, mais utilisé pour que ceux-ci puissent atteindre leur destination via le chemin le plus court. 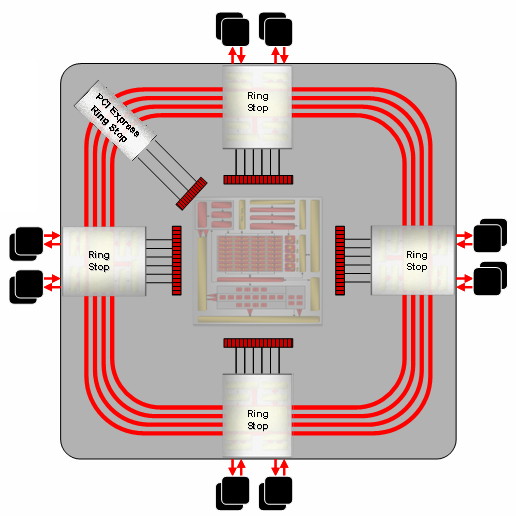 Vous l'aurez par ailleurs compris, ce ring bus se connecte à un bus mémoire 512 bits ce qui est une première et permet à AMD de ne pas devoir utiliser de la mémoire très rapide et donc très chère pour obtenir une bande passante élevée. Autre nouveauté, l'intégration d'un contrôleur d'accès supplémentaires et autonome pour le bus PCI Express. De qui permettre d'éviter que le GPU ne soit bloqué pendant les transferts PCI Express comme c'est le cas actuellement. Une avancée très importante, pour la communication entre le CPU et le GPU, pourquoi pas sur la plateforme Torrenza d'AMD ? Unités de texturingLe bloc d'unités de texturing n'a malheureusement pas été élargit. Il reste donc identique à celui du GPU de la Xbox 360 et contient 16 samplers vec4 raccordés à une unité de filtrage bilinéaire (ce qui correspond à 16 unités de texturing classiques) et 16 samplers scalaires sans filtrage. 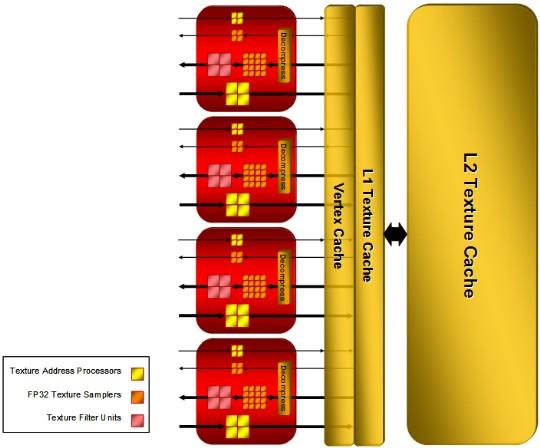 Pour sa part le GeForce 8800 dispose de 32 samplers vec4 raccordés à 2 unités de filtrage bilinéaire. L'avantage est énorme en puissance de filtrage pour le GPU de Nvidia. 16 unités c'est peu, trop peu ? AMD indique avoir optimisé leur rendement mais également que les 16 samplers scalaires permettent de décharger les unités classiques de certaines opérations. Pour notre part, avant même avoir commencé les tests cela nous paraît malgré tout trop faible, surtout pour une carte haut de gamme qui sera en général utilisée avec des filtrages anisotropes qui peuvent monopoliser les unités de filtrage pendant de nombreux cycles. Contrairement aux Radeon X1000, ces unités de filtrages prennent maintenant en charge nativement et à pleine vitesse le filtrage FP16 des textures 64 bits HDR. Le filtrage FP32 est lui aussi supporté mais à demi-vitesse, comme sur GeForce 8. AMD indique que le bus mémoire 512 bits aide à maximiser l'efficacité de ces unités lors de traitement des textures de haute précision gourmandes en bande passante mémoire, ce qui permet ici aussi de compenser en partie le déficit de puissance brute par rapport aux GeForce 8. La structure du texture cache a été revue pour inclure un cache L1 de 32 Ko localisé par group de 4 unités et un gros cache L2 de 256 Ko. Enfin, dernier petit détail : chez Nvidia un groupe de 4 unités de texturing est attribué d'une manière fixe à 2 groupes de 8 processeurs scalaires. Chez AMD ce n'est pas le cas et toutes les unités de texturing peuvent être attribuées à un même groupe de 16 unités MIMD. Cela compense quelque peu la différence dans certains cas. Reste qu'en général lorsque la puissance de texturing joue un rôle important, plus ou moins toutes les unités de traitement en ont besoin. Page 4 - Performances PS, VS, texturing et ROPs Performances Pixel ShaderNous avons testé 2 shaders déclairage relativement simples qui représentent un bon compromis entre des débits de calculs théoriques et pratiques :  Difficile de séparer le Radeon HD 2900 XT du GeForce 8800 GTX lors de l'exécution de ces shaders très simple. Le GeForce 8800 GTS est par contre nettement en retrait, probablement parce que Nvidia n'a pas travaillé énormément ses drivers pour celui-ci dans les conditions extrêmes. Performances Vertex ShaderNous avons testé les performances en T&L, VS 1.1, VS 2.0 et VS 3.0 dans RightMark : 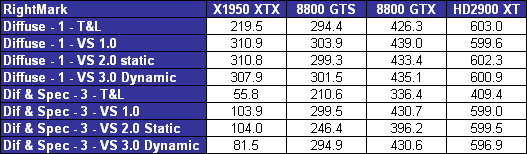 Larchitecture unifiée permet aux GeForce 8800 et Radeon HD 2900 dattribuer toutes les ressources au traitement des vertex shader, ce qui entraîne un gain qui peut être conséquent. Il pourrait dailleurs probablement être plus important mais est limité par le débit en triangle des GPUs qui semble d'un côté comme de l'autre être de 1 triangle par cycle. La fréquence plus élevée du Radeon HD 2900 XT joue donc ici en son avantage et fait de ce GPU le plus puissant que nous ayons pu avoir entre nos mains en matière de traitement géométrique. Performances accès aux texturesNous avons mesuré les performances lors de laccès à des textures de différents formats (32 bits, 64 bits FP16 et 128 bits FP32) et de différentes tailles, avec et sans filtrage. La texture étant affichée en plein écran, en 1920x1440, laccès aux textures de grandes tailles se fait en dehors des limites de pleine efficacité du texture cache.  Contrairement à ce qu'indiquent les documents que Nvidia a distribué à la presse au sujet du Radeon HD 2900, celui-ci est bien capable de filtrer les textures FP16 à pleine vitesse. Le Radeon HD 2900 affiche ici des performances similaires à celles du 8800 GTS. Notez pour information qu'une texture FP16 en 8192x8192 pèse 512 Mo et 1 Go en FP32. Il n'est pas simple de manipuler de telles textures, ce qui explique les limitations rencontrées. Cliquez ici pour voir tous les résultats. ROPsLe GeForce 8800 dispose de 24 ROPs, contre 20 pour le GeForce 8800 GTS et 16 pour les Radeon. Pour rappel les ROPs sont les unités chargées des derniers traitements à effectuer sur les pixels (mélange des couleurs, antialiasing, compression des données et écriture de celles-ci en mémoire). La taille du bus mémoire est en partie liée à cette augmentation. Pour rappel, non content den avoir augmenté le nombre, Nvidia en a amélioré lefficacité sur GeForce 8 lors des passes qui nécrivent que la valeur Z en mémoire. AMD en a fait de même avec le Radeon HD 2900 bien que dans une moindre mesure : 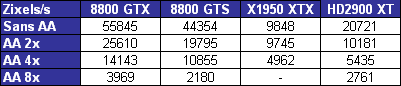 Si le Radeon HD 2900 est bel et ben capable de doubler le débit de zixels sans antialiasing, il reste 2x moins performant que le GeForce 8800 GTS à ce niveau, excepté en FSAA 8x où son bus mémoire 512 bits est probablement très utile. Page 5 - Performances branchements Performances branchementsLune des principales nouveautés qui a été introduite avec les Pixel Shaders 3.0 est le branchement dynamique dans les pixel shaders. Cela permet de rendre lécriture de certains shaders plus naturelle et daugmenter lefficacité dautres shaders en évitant de calculer une partie de ceux-ci sur les pixels qui nen ont pas besoin. Par exemple pourquoi appliquer le filtrage très coûteux de ladoucissement de bordure dune ombre si le pixel est au milieu de lombre ? Un branchement dynamique permet de détecter si le pixel en a besoin ou pas. 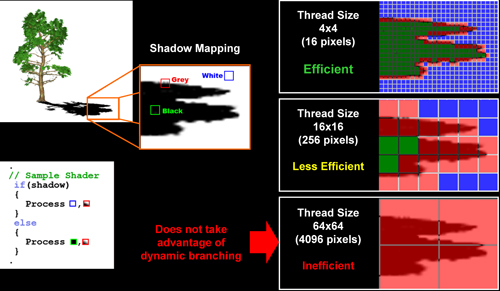 Mais tout nest pas si rose puisque ceux-ci ne sont efficaces que dans des cas bien précis. Les branchements ont une réputation d'être difficile à gérer, c'est particulièrement le cas dans les CPU qui doivent prédire le résultat du branchement à l'avance pour masquer la latence du calcul de celui-ci. Dans un GPU, les pixels sont traités par groupes de dizaines, de centaines voire de milliers de pixels, ce qui permet de masquer automatiquement cette latence. Le problème des CPUs n'existe donc pas réellement. Par contre un autre problème se pose. Lors dun branchement, tous les pixels doivent prendre la même branche sans quoi les 2 branches doivent être calculées pour tous les pixels, avec des masques pour nécrire que le résultat de la branche requise pour chaque pixel. Nous avons développé un petit test qui nous permet de modifier la granularité du branchement, c'est-à-dire le nombre moyen de pixels consécutifs qui vont prendre une même branche. Nous spécifions la branche à prendre par colonne de pixels, une colonne sur 2 doit afficher un shader complexe et l'autre peut passer cette partie du rendu. Des triangles de taille moyenne en mouvement sont affichés à l'écran et traversent ces zones qui utilisent différentes branches, ce qui implique que tant les triangles et leur position que la taille de la colonne influent sur l'efficacité du branchement ce qui est proche d'une situation réelle. 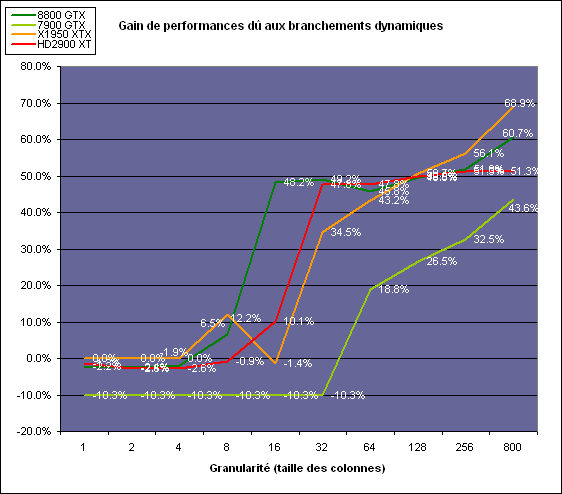 Avec des colonnes étroites, les GPUs ne peuvent pas profiter du branchement pour éviter la partie complexe sur la moitié des pixels, mais par contre doivent traiter les instructions de branchement, ce qui fait baisser les performances au lieu de les augmenter. Tout du moins sur les GeForce 7. Les Radeon et les GeForce 8 disposent d'une unité dédiée aux branchements qui travaille en parallèle des pipelines de pixel shading et de texturing ce qui masque le coût des instructions de branchement. La Radeon X1950 semble cependant la seule à masquer complètement la latence des branchements. Le GPU le plus efficace à ce jour pour traiter ces opérations et le Radeon X1800, le Radeon X1900 étant un peu moins bon et le Radeon HD 2900 encore un peu moins bon. La taille des threads de pixels sur le GeForce 8800 est de 32 pixels contre 48 pour le Radeon X1950 et 64 pour le Radeon HD 2900, ce qui permet à la puce de Nvidia de prendre les devants. Nous précisons threads de pixels puisque dans le cas de threads de vertices, la granularité est de 16 vertices chez Nvidia. Notez que les Radeon X19x0 produisent des résultats moins prédictibles que les autres GPUs sur ce test (le résultat étrange avec une colonne de 16 pixels en témoigne). Nous supposons que cela est dû à une manière complexe de l'architecture de distribuer les pixels aux shader cores qui entraînerait une baisse d'efficacité dans certaines conditions. Globalement le Radeon HD 2900 se comporte donc comme le GeForce 8800, son efficacité étant cependant reculée d'un cran à cause de la taille des groupes de pixels traités. Nous avons ensuite exécuté un second test lié aux branchements dynamiques. Cette fois nous avons rendu une fractale d'une manière classique et ensuite à base de branchements. Cet algorithme utilise un nombre élevé d'itérations identiques qui dans le shader classique se retrouvent les une à la suite des autres. Dans le shader à base de branchements, nous avons utilisé une boucle autour de 2 itérations avec un test qui vérifie si le calcul d'itérations supplémentaires est utile ou pas. Si il n'est pas utile nous sortons de la boucle en laissant tomber les itérations qui ne sont pas nécessaires.  Avant de comparer les performances avec et sans branchements, il est intéressant de s'attarder aux résultats brutes. Ce shader est en effet constitué principalement d'opérations vec2 et profite donc d'une architecture plus flexible au niveau de ses unités de calcul. Le fonctionnement scalaire des GeForce 8 permet d'atteindre ici de très hautes performances. Le Radeon HD affiche ici des performances nettement supérieures à celles du Radeon X1950 mais cela n'est pas dû à son "architecture scalaire", en effet le gain correspond uniquement à l'augmentation de la fréquence et des unités de calcul vectorielles (de 48 à 64). Concernant les branchements, le Radeon HD 2900 est ici peu efficace et semble moins bien masquer le coût des nombreuses opérations de branchement que son prédécesseur et que le GeForce 8800. Page 6 - Performances DX10, Tesselation Performances DirectX 10Comment vont se comporter les GPUs avec cette nouvelle API ? Voilà une question à laquelle nous aimerions tous avoir une réponse. Autant être clair, nous ne vous la donnerons pas dans ce test. Il est encore trop tôt pour en juger. Différentes démos technologiques sont disponibles mais elles sont destinées uniquement à exposer des méthodes de rendu ou de nouveaux algorithmes. Elles ne représentent pas des tests fiables prises telles qu'elles, cela demanderait une analyse minutieuse de la manière dont ces démos utilisent les différentes fonctions de DirectX 10 et des raisons pour lesquelles les résultats sont ce qu'ils sont. Les drivers DirectX 10 sont encore jeunes, tout comme l'API et ces démos. Qui plus est il est très facile d'optimiser une démo technologique pour mettre un avant son produit. En bref vous donner les résultats sous ces différentes démos serait plus de la désinformation qu'autre chose. Nous pouvons par contre vous donner un début d'analyse de l'implémentation de cette API. Contrairement à Nvidia, AMD a intégré un cache généralisé pour les lectures/écritures en mémoire à partir du shader core. Celui-ci peut être utilisé d'une manière classique pour le Stream Output qui consiste, comme le requiert DirectX 10 à pouvoir écrire les données qui sortent du shader core sans passer par les ROPs. Il permet également de virtualiser les registres généraux qui peuvent ainsi être illimités. 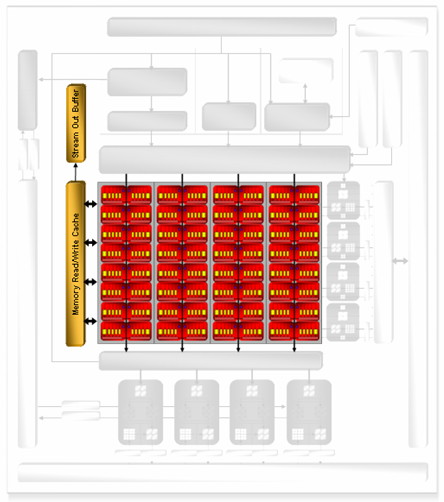 Une autre utilité est d'utiliser la mémoire vidéo à travers ce cache pour stocker temporairement la masse potentiellement énorme de données créées par les Geometry Shaders lors d'amplification de la géométrie sans quoi les unités de calcul pourraient être bloquées par impossibilité de placer le résultat dans les registres généraux ce qui poserait un problème et à priori un plantage puisque les données géométriques doivent pouvoir rester dans le bon ordre. Par exemple imaginez les triangles 1 et 2 en train d'être décomposés. Le triangle 1 doit être rendu avant le triangle 2. Un GPU étant par définition parallèle, ces 2 triangles peuvent être traités en même temps par le geometry shader qui va les décomposer en une série de plus petits triangles. A la sortie, tous les triangles issus du triangle 1 devront être rendu avant les autres. Pas de problème s'il y a assez de mémoire pour tout stocker, il suffit d'attendre que le tout soit terminé et de contrôler que le rendu se fasse dans le bon ordre. Mais si le GPU tombe à court de mémoire alors que les triangles 1 et 2 sont toujours en train d'être décomposés, il est callé. Il ne peut pas encore traiter les petits triangles puisque la décomposition n'est pas terminée ce qui veut dire que l'ordre ne peut pas être contrôlé avec fiabilité, mais ne peut plus continuer la décomposition. Nous sommes donc dans une impasse. AMD évite ce problème grâce à cet accès caché à la mémoire vidéo. Nvidia doit bien entendu l'éviter également, il n'y a pas d'autre solution. Par contre l'approche d'après notre interprétation des explications de Nvidia est très différente. Nvidia prendrait ainsi le problème dans l'autre sens et au lieu de proposer plus de mémoire pour stocker les données avant de rétablir l'ordre, Nvidia réduirait le nombre d'éléments traités en parallèles à un nombre qui permette toujours d'avoir assez de mémoire dans le GPU. Autrement dit au lieu de pouvoir utiliser les 128 processeurs en parallèle pour traiter un geometry shader, si Nvidia détecte qu'il peut y avoir un problème ce nombre doit être réduit. Quel est le cas le moins favorable ? 16 processeurs ? 8 processeurs ? 1 processeur ? Et les autres processeurs peuvent-ils travailler à une autre tâche pendant ce temps ou sont ils en attente ? Difficile de répondre à ces question pour le moment, mais il semble évident qu'il y a là une grosse différence entre Nvidia et AMD, à l'avantage de ce dernier. Reste bien entendu à voir ce que les développeurs feront des geometry shaders. Call of Juarez   A mi chemin entre premier jeu DirectX 10 et démo technologique, le benchmark de Call of Juarez (fourni par AMD) va nous faire déroger à la règle de ne pas donner de résultats de démo DirectX 10, puisque c'est un peu plus que cela. Notez que Nvidia nous a fourni un nouveau driver (158.42), optimisé pour ce test, augmentant de 20% les performances. Ces résultats sont à prendre avec des pincettes puisqu'il ne s'agit pas de la version finale du benchmark et du patch pour le jeu qui ira avec, comme le démontre dailleurs le rendu de la végétation qui pose des soucis quelque soit la carte graphique. 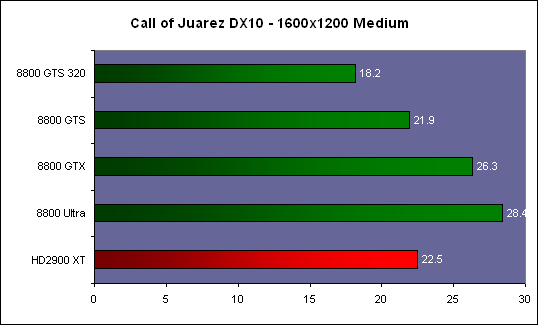 TesselationComme nous vous l'avons indiqué au début de cet article, le Radeon HD 2900 reprend l'unité de tesselation programmable du GPU de la Xbox 360. Le retour du Truform en d'autres mots et ce n'est pas qu'une boutade puisque les clés Truform sont de retour dans la base des registres bien que pas activées.  Malheureusement, la tesselation ne fait pas partie des spécifications de DirectX 10. Cela sera probablement le cas dans une future évolution, mais quand ? En attendant, il faut utiliser de nouveau une détection spéciale via un format de texture pour détecter la présence de cette unité et en quelque sorte tromper l'API, le driver se chargeant alors d'adresser sa tâche à l'unité de tesselation. Cela tranche quelque peu avec l'esprit "les caps c'est fini" de DirectX 10, mais en contrepartie cela permet des portages faciles à partir de jeu Xbox 360. Que feront les développeurs ? Rien dans l'immédiat puisque la tesselation ne fait pas encore partie des drivers et AMD ne sait pas quand ce sera le cas. Cet été ? Dans 6 mois ? Dans 1 an ? Jamais ? AMD ne peut pas répondre à cette question et annonce donc une fonction qui restera virtuelle jusqu'à nouvel ordre. Dommage. 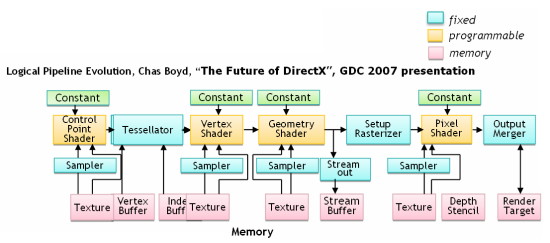 Le futur de DirectX 10 passe par l'intégration d'une unité de tesselation. Mais quand ? Notez que les geometry shader permettent de faire de la tesselation, mais avec des performances bien trop faibles que pour pouvoir généraliser son utilisation comme le permet une unité dédiée. Page 7 - Filtrage Qualité du filtrageDepuis le lancement des GeForce 7, nous avons régulièrement critiqué la qualité du filtrage des textures des cartes de Nvidia. Des optimisations trop agressives entraînaient un fourmillement dans les textures. Problème quil est difficile de montrer sur un screenshot puisquil se voit principalement en mouvement. Avec les GeForce 8 ce problème fait maintenant partie du passé. Les Radeon X1000 produisent même un petit peu plus de fourmillement que ces dernières. Cela reste vrai avec le Radeon HD 2900 qui filtre un petit peu moins bien les textures que son concurrent. Pas de gros problèmes comme c'était le cas avec les GeForce 7, mais il est tout de même important de signaler que les GeForce 8 restent un cran au-dessus à ce niveau. Ce nest pas le seul élément de reproche que lon faisait aux GeForce 7 puisque ces cartes appliquent quoi quil se passe un filtrage anisotrope dépendant de langle de la surface qui le reçoit. Une optimisation qui permet de simplifier les calculs (et les unités qui sen chargent) liés au filtrage et de gagner des performances en appliquant un niveau de qualité moindre à certaines surfaces. ATI qui est à lorigine de cette optimisations a permis avec larrivée des Radeon X1800 de la désactiver ou tout du moins de la remplacer par une version moins agressive. Avec les GeForce 8800 Nvidia en a fait de même mais va plus loin en faisant disparaître cette optimisation par défaut et en appliquant un calcul du LOD bien plus précis que celui du mode HQ dATI. Nvidia sest ainsi offert la nouvelle référence en matière de filtrage et la conserve puisque le Radeon HD 2900 ne fait qu'améliorer légèrement (?) le filtrage des Radeon X1000 en gommant certains petits défauts dans le calcul du lod en mode HQ. Ce mode HQ est par ailleurs l'unique mode proposé par les Radeon HD 2900. 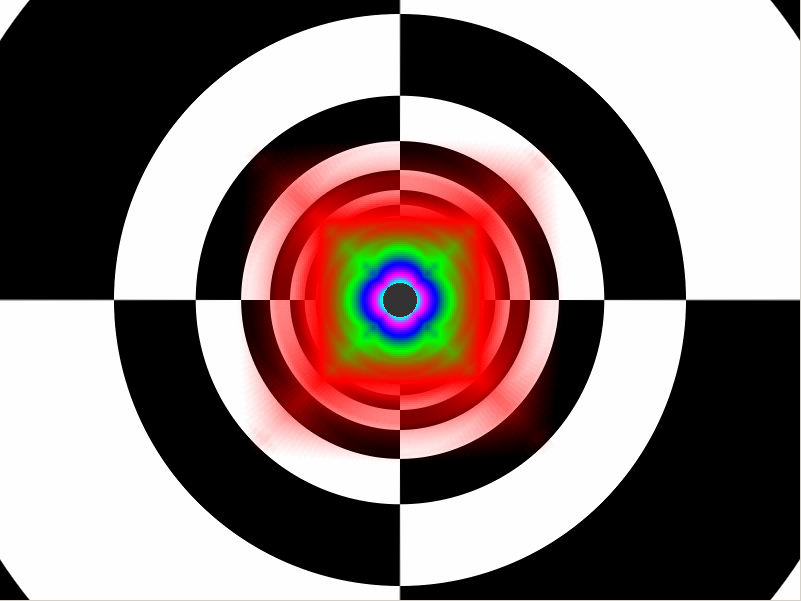 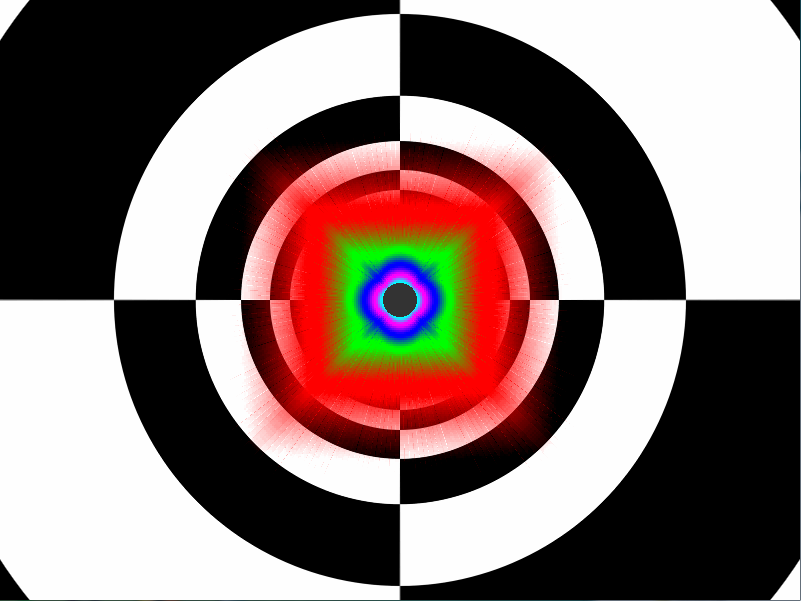  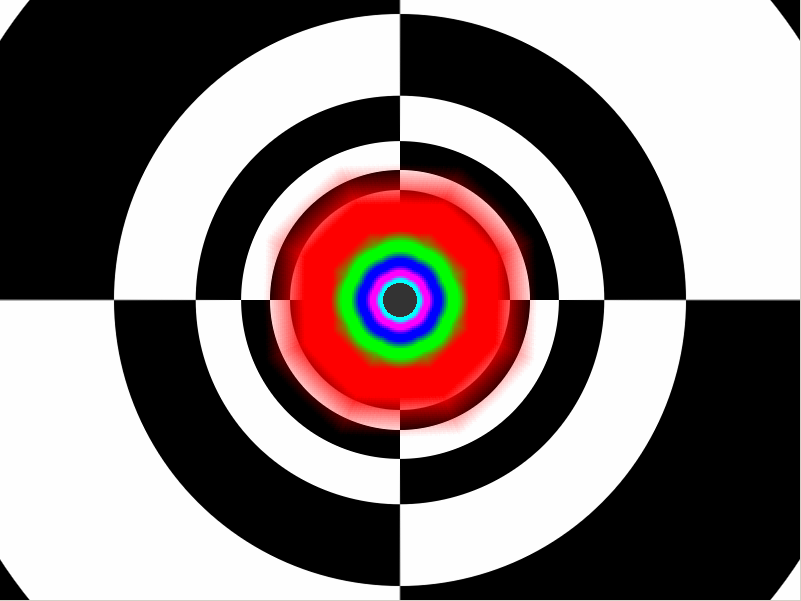 Radeon X1950 XTX HQ, Radeon HD 2900 XT GeForce 7900 GTX, GeForce 8800 GTX Notez que ces screenshots ne représentent pas la qualité du filtrage mais uniquement le niveau de mipmap affiché. Plus les bandes colorées apparaissent tard, plus les textures sont nettes, mais rien ne dit quelles ne fourmillent pas à cause dun mauvais filtrage. Cette partie de la problématique du filtrage, notamment visible dans les simulateurs de vols, ne peut pas se voir avec ce genre de test et sur screenshot. Performances du filtrageNous avons mesuré les performances sous Serious Sam 2 dans un environnement extérieur. 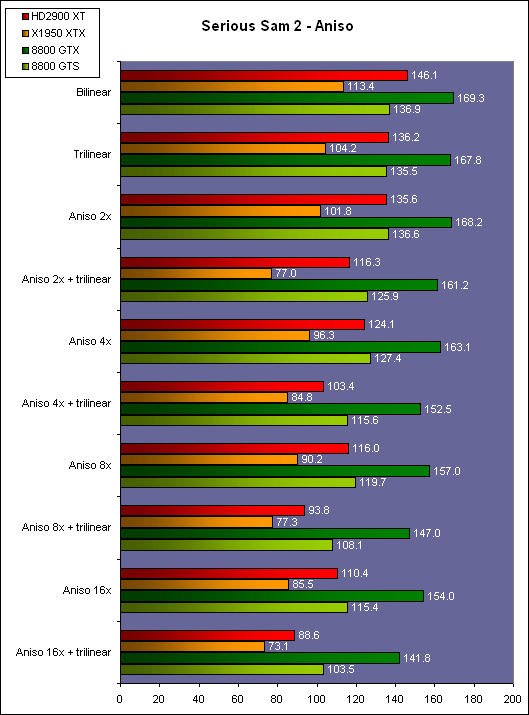 La Radeon X1950 est étrangement moins performante en filtrage anisotrope 2x que 4x ce qui laisse transparaître la présence d'une optimisation qui ne se met en place que en mode 4x. Ce n'est plus le cas avec la Radeon HD 2900. Comme vous pouvez le voir le GeForce 8 est bien moins impacté par lactivation du filtrage anisotrope. Alors que la Radeon HD 2900 perd 40% de ses performances en passant du mode bilinéaire au mode 16x trilinéaire, la GeForce 8800 GTS ne perd que 25% et ce alors que la différence réelle est probablement plus grande puisque la Radeon est plus proche de la limite CPU. Les 64/48 unités de filtrage des GeForce 8 portent donc leurs fruits. Page 8 - Antialiasing AntialiasingAlors que les Radeon sont capables depuis longtemps de gérer un antialiasing de type multisample en 6x, le Radeon HD 2900 passe enfin au mode 8x, tout comme les GeForce 8. Tous les modes restent compatibles avec le HDR FP16. Pour rappel, Nvidia a implémenté un nouveau mode dantialiasing nommé coverage sample (CSAA). Ce mode consiste à améliorer la précision avec laquelle les samples de couleurs différentes sont mélangées pour former limage finale. Par exemple si 2 triangles passent par un même pixel en MSAA 4x, ils peuvent recouvrir soit 25 et 75 % du pixel, 50 % chacun ou 75 et 25 %. Les couleurs sont mélangées dans ces proportions. Le coverage sample se base sur un buffer MSAA classique ainsi que sur un second buffer dune résolution supérieure (8x ou 16x) mais qui ne retient pas de couleur, uniquement une valeur booléenne qui indique si le triangle couvre cette zone ou pas. Cette technique a des limites puisquil nest pas possible via le coverage sample buffer de connaître précisément les interactions entre de nombreux triangles ou entre des triangles qui se touchent ou se coupent. Etant donné que le Z-Buffer reste à la résolution standard, il nest pas possible de savoir quel triangle est au-dessus de lautre etc. Nvidia a donc dû restreindre lutilisation de coverage sample buffer aux pixels qui représentent 2 triangles espacés. Si ce nest pas le cas linformation du CS buffer est ignorée. Quand elle est utilisée, elle offre un résultat en théorie similaire à celui de sa résolution puisque le mélange des samples se fait dans cette résolution. En reprenant lexemple précédant, un triangle qui couvre 30% du pixel naura lors du mélange en MSAA 4x que 25% de poids puisque cest lapproximation la plus proche possible dans ce mode. En MSAA 4x + CSAA 16x, il pèsera alors pour 31% ce qui est une meilleure approximation. Le CSAA ne profitera donc quà certaines arêtes mais en contrepartie il est beaucoup moins gourmand quun mode de MSAA supérieur vu quil consomme moins de bande passante et ne requiert jamais de calcul de couleur supplémentaire. De son côté, avec les Radeon HD2000, ATI a mis en place une évolution au niveau du downsampling (MSAA resolve), cette opération qui consiste à redimensionner le buffer avec MSAA pour former l'image dans la résolution voulue. En règle générale c'est un filtre de type "box" qui est utilisé. Il consiste simplement, dans le cas du mode 4x, à additionner les 4 samples, chacune ayant un poids de 25%. Avec les Radeon HD2000, ATI rend ce filtre de downsampling programmable grâce à une unité de MSAA resolve revue dans les ROPs. Reste que cette unité ne semble pas fonctionnelle! Cela fait plusieurs mois que les bruits de couloir font état de bugs dans les ROPs du R600 et cette partie semble être particulièrement visée. Comment faire donc pour continuer à supporter même le simple MSAA sans cette unité ? La réponse se trouve dans DirectX 10 qui permet de lire un buffer MSAA comme toute autre texture. Autrement dit il suffit d'appliquer le filtre de downsampling via un pixel shader, tel un filtre de post processing. Pour AMD, utiliser cette capacité en dehors de DirectX 10 n'est qu'une question de drivers. Le problème est donc réglé. Bien entendu, selon AMD les ROPs ne sont pas bugués et cette approche a été choisie uniquement parce qu'elle est plus flexible, le surcoût étant annoncé négligeable. Il est très courant de développer de telles unités pour ne pas les utiliser Car si la méthode utilisée est bien très flexible puisque n'importe quel filtre peut être utilisé, ce filtre a un coût plus ou moins élevé selon sa complexité puisqu'il monopolise les unités de calcul le temps de son traitement. AMD utilise cette capacité pour introduire le CFAA pour custom filter antialiasing dans ses drivers en proposant des filtres narrow-tent et wide-tent en plus du mode box classique. Le premier consiste à mélanger 50% de samples supplémentaires issues des pixels adjacents et le second consiste à en mélanger 100% en plus. Ansi en mode MSAA 4x, le filtre wide-tent va filtrer l'image sur 8 samples au lieu de 4. Le principe est similaire à celui du Quincux de Nvidia qui avait été largement critiqué pour rendre les images floues. Les filtres narrow et wide-tent souffrent également de ce défaut, mais dans une bien moindre mesure puisque le filtre étant programmable, le poids donné aux samples issus des pixels adjacents peut être réduit.    De haut en bas : le MSAA 8x, le MSAA 8x + CFAA 12x (narrow-tent) et le MSAA 8x + CFAA 16x (wide-tend) Avec un utilitaire beta, AMD permet d'activer un filtre 12x et 24x qui va en premier lieu utiliser un algorithme de détection des arrêtes et en second lieu appliquer le filtrage adapté. Ce type de filtre peut permettre d'atteindre des qualités très élevées mais monopolisent une partie de la puissance de calcul qui peut grimper en flèche. Nous ne pouvons malheureusement pas commenter ce filtre d'ATI puisque s'il fait effectivement baisser les performances, le résultat ne semble pas être appliqué à l'image. Nous attendrons donc une version fonctionnelle pour juger de son intérêt. Nous avons voulu voir le coût en pratique de tous ces modes de FSAA : 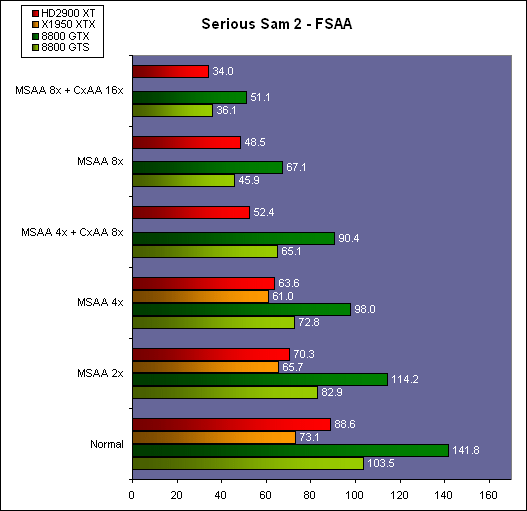 Premièrement, précisons que MSAA 8x correspond au mode 8xQ, MSAA 4x + CFAA 8x au mode 8x et MSAA 8x + CFAA 16x au mode 16xQ dans les drivers Nvidia (on remerciera Nvidia et AMD pour la simplicité introduite par tous ces nouveaux modes). Malgré son bus mémoire 512 bits, la Radeon HD 2900 XT peine à se démarquer de la Radeon X1950 XTX et ne prend les devants que très légèrement sur la GeForce 8800 GTS en MSAA 8x. Etant donné le coût du filtre wide-tent qui atteint 30% en MSAA 8x, nous sommes confortés dans notre idée que le fait qu'AMD n'utilise pas ou ne puisse pas utiliser le downsampling hardware handicape la Radeon HD 2900 au niveau des performances. 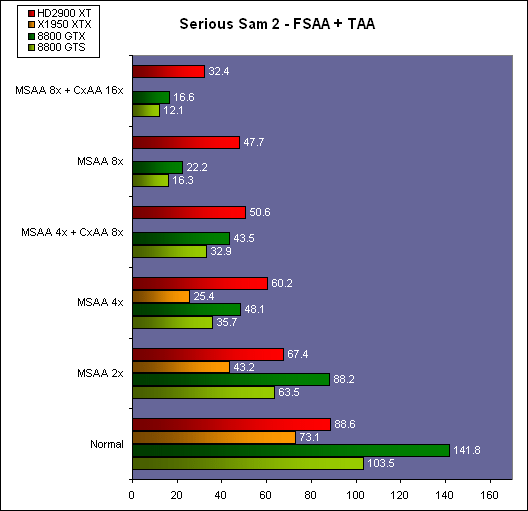 Ce second test est identique si ce nest que nous avons cette activé le Transparency AntiAliasing chez Nvidia et l'Adaptive AntiAliasing chez AMD, qui pour rappel permettent d'appliquer du supersampling sur les surface rendues à base de test alpha, de manière à pouvoir filtrer grillages, végétation etc. Etrangement, avec le nouveau driver, les performances ne baissent que très légèrement chez AMD. L'AAA semble pourtant bel et bien activé et nous ne pouvons pas nous expliquer ce très faible coût. AMD semble avoir trouvé une astuce pour booster les performances dans ce jeu et cela n'a à priori pas de lien avec la nouvelle architecture. Qualité de lantialiasing (sans TAA / AAA)    GeForce 7 : Sans AA, 4x AA, 8xS AA    Radeon X1000 : Sans AA, 4x AA, 6x AA       GeForce 8 : Sans AA, 4x AA, 4x AA + 8x CSAA, 4x AA + 16x CSAA, 8x AA (8xQ), 8x AA + 16x CSAA        Radeon HD 2900 : Sans AA, 4x AA, 4x AA + 6x CFAA, 4x AA + 8x CFAA, 8x, 8x AA + 12x CFAA, 8x AA + 16x CFAA Dun point de vue qualitatif, on peut dire que les MSAA 4x des Radeon HD 2900 et des GeForce 8800 se valent, chacun prenant lavantage sur lautre en fonction des angles à filtrer. Par contre, le MSAA 8x dATI est notablement supérieur dun point de vue qualitatif. Les nouveaux modes introduits par ATI via le CFAA sont peu convaincants en pratique : certes il ya moins daliasing mais ceci se fait au détriment dun léger flou général, le tout pour un impact sur les performances non négligeable. Quitte à choisir daller plus loin que le MSAA de base, nous vous conseillons plutôt dopter pour le Transparency/Adaptative Anti-aliasing. Afin de vous faire votre propre opinion, voici une suite de screenshots dans les différents modes : Qualité de lantialiasing (avec TAA / AAA)   GeForce 7 : Sans AA, 4x AA, 8xS AA   Radeon X1000 : Sans AA, 4x AA, 6x AA      GeForce 8 : Sans AA, 4x AA, 4x AA + 8x CSAA, 4x AA + 16x CSAA, 8x AA (8xQ), 8x AA + 16x CSAA       Radeon HD 2900 : Sans AA, 4x AA, 4x AA + 6x CFAA, 4x AA + 8x CFAA, 8x, 8x AA + 12x CFAA, 8x AA + 16x CFAA Page 9 - Spécifications, la carte, consommation Spécifications 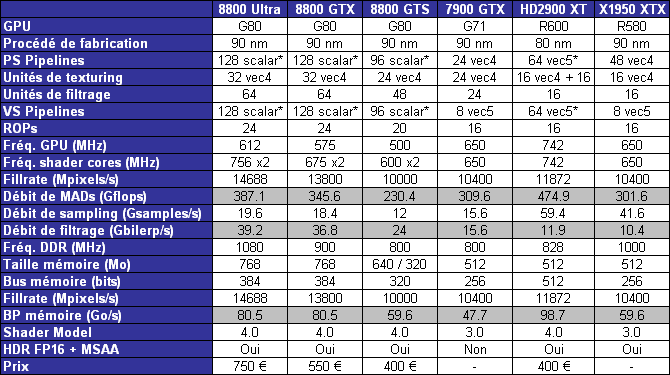 La carteAMD nous a fourni une carte de référence :      Avec 24cm de longueur, la carte est plus grande dun centimètre quune GeForce 8800 GTS ou une Radeon X1950 XTX, mais plus courte qu'une GeForce 8800 GTX et ses 27cm. Le système de refroidissement double slot est équipé d'un bloc de refroidissement en cuivre qui est très lourd, si bien que la carte atteint 950g, cest 200 de plus que la GTX.  En mode 2D, la carte est plus ou moins discrète. Pas autant que les GeForce 8800 mais rien de bien inquiétant tout du moins la plupart du temps puisque de temps en temps, le ventilateur s'emballe. Il semblerait en effet que la vitesse ne puisse être que minimale ou maximale ce qui veut dire que dès que la température du GPU dépasse un certain seuil, le ventilateur passe en pleine vitesse alors que pour afficher le bureau de Vista une vitesse légèrement supérieure mais continue devrait suffire. AMD nous a indiqué avoir constaté le problème et que celui-ci et en partie lié aux engineering samples et d'autre part aux drivers qui devraient rapidement corriger cela. Tout du moins nous l'espérons. En mode 2D, la carte est plus ou moins discrète. Pas autant que les GeForce 8800 mais rien de bien inquiétant tout du moins la plupart du temps puisque de temps en temps, le ventilateur s'emballe. Il semblerait en effet que la vitesse ne puisse être que minimale ou maximale ce qui veut dire que dès que la température du GPU dépasse un certain seuil, le ventilateur passe en pleine vitesse alors que pour afficher le bureau de Vista une vitesse légèrement supérieure mais continue devrait suffire. AMD nous a indiqué avoir constaté le problème et que celui-ci et en partie lié aux engineering samples et d'autre part aux drivers qui devraient rapidement corriger cela. Tout du moins nous l'espérons.Vous l'aurez compris, en 3D la Radeon HD 2900XT se fait entendre. Pas autant que les Radeon X1800 XT et X1900 XTX tristement célèbres pour leurs nuisances sonores, mais ont est au dessus dune X1950 XTX. La comparaison à la gamme GeForce 8800 nest pas du tout à lavantage dATI puisque la GTS sait se faire assez discrète même en charge, alors que la GTX reste notablement moins bruyante. Un désagrément qui rebutera donc les amateurs de PC discrets. En overclocking, nous avons pu passer le core de 742 à 850 MHz et la mémoire de 828 à 1020 MHz soit des gains respectifs de 14.5 et 23%, ce qui est correct sans être impressionnant pour autant. Alimentation & Consommation  Vous aurez remarqué que la Radeon HD 2900 XT embarque deux connecteurs dalimentation PCI Express distincts, un 6 broches et un 8 broches. Ces connecteurs sont respectivement prévus pour fournir 75 watts et à 150 watts à la carte graphique, exclusivement en 12V. Vous aurez remarqué que la Radeon HD 2900 XT embarque deux connecteurs dalimentation PCI Express distincts, un 6 broches et un 8 broches. Ces connecteurs sont respectivement prévus pour fournir 75 watts et à 150 watts à la carte graphique, exclusivement en 12V.On notera que du point de vue électrique rien nempêche de fournir plus de 75 watts via un connecteur 6 broches à partir du moment où lalimentation suit, mais cest toutefois la limite fixée lors de la définition de la norme « PCI Express x16 Graphics 150W-ATX Specification 1.0 » mise au point par le PCI-SIG dès 2004. Sachant que le port PCI Express est également capable de fournir jusquà 75 watts, on arrive donc à un total de 300 watts dans la configuration utilisée sur le Radeon HD 2900 XT. Cette enveloppe est-elle justifiée ? Pour le savoir nous avons mesuré la consommation des différentes cartes. Ces données sont obtenues à partir des mesures effectuées à la sortie de la prise de courant : il sagit donc de la consommation totale de lalimentation de la machine, ici une Galaxy 850W d'Enermax qui est vous allez le voir très largement surdimensionnée : 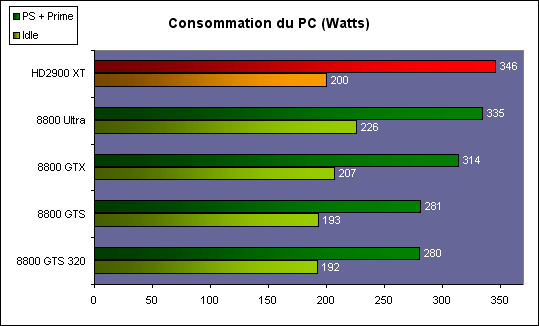 Nous reportons les chiffres obtenus sous le bureau Windows, puis en charge sous le test de Pixel Shader de 3DMark06 couplé avec Prime95, ce dernier permettant davoir une utilisation processeur constante quelles que soient les performances des solutions graphiques. On aurait aimé avoir une bonne surprise au niveau de la consommation en 2D malheureusement il ny en a pas. Ainsi, la HD 2900 XT se situe entre une GTS et une GTX de ce côté, ce qui na rien de très glorieux. En effet par exemple une 8800 GTX consomme 50 watts de plus quune X1950 Pro en 2D au repos sur le bureau Windows. En 3D la consommation de ces cartes est plus compréhensible mais la HD 2900 XT atteint un nouveau record, la configuration consommant 32 watts de plus quune 8800 GTX et 11 de plus quune Ultra. On notera toutefois que ces chiffres ne justifient pas à eux seuls la présence dun connecteur dalimentation PCI Express 8 broches. En effet, une 8800 GTX nécessite environ 130 watts en charge de la part de lalimentation (soit 162.5 watts au niveau de la prise avec un rendement de 80%), alors quelle peut tirer 75 watts du port PCI-E, et 2x75 watts de chacun des connecteurs PCI Express 6 broches. En pratique, selon nos mesures elle tire environ 23 et 107 watts par ces moyens, ce qui laisse de la place pour les 25 à 26 watts supplémentaires de la HD 2900 XT au niveau de lalimentation. De fait, la HD 2900 XT fonctionne très bien avec deux connecteurs PCI-Express 6 broches, et même en overclocking via des logiciels tiers malgré quATI désactive la fonction Overdrive intégrée à ces drivers. Labsence dune connexion pourrait nêtre pénalisante quen cas de gros overclocking qui feraient appels à des modifications des tensions du GPU et de la mémoire. Nécessitant environ 155 watts de puissance au niveau de lalimentation, la Radeon HD 2900 XT établi donc un triste record. On pouvait toutefois sattendre à pire étant donné la présence du connecteur 8 broches PCI-E, mais en pratique beaucoup de configurations sauront se contenter dune bonne alimentation 400 watts capable de fournir 300W sur le +12V. On notera qu'une fois overclockée à 850 Mhz pour le core et 1020 MHz pour la mémoire, la consommation de la configuration grimpe de 21 watts pour atteindre 367 watts. On peut alors estimer que la carte nécessite environ 172w de la part de lalimentation. Page 10 - AVIVO HD, le test AVIVO HDPour ce test, nous avions prévu un nouveau protocole vidéo, armé d'un lecteur HD-DVD et de média en VC-1 et en MPEG4-AVC (H.264). Malheureusement, il s'est avéré que l'accélération matérielle n'était pas fonctionnelle avec les drivers fourni et la version spéciale de Power DVD elle aussi fournie par AMD, qui visiblement n'a pas pris la peine de vérifier si le tout fonctionnait. Nous n'avons donc pas encore de résultat à vous communiquer. Notez qu'AMD annonce l'UVD avec les Radeon HD2000. Il s'agit d'un moteur dédié à l'accélération vidéo et certifié capable de prendre en charge tous les médias Bluray et HD-DVD. Cependant l'UVD n'est pas intégré au Radeon HD 2900 XT, et se limite donc aux HD2600 et 2400, un peu comme le Pure Video 2 qui n'est pas présent sur 8800 mais sur 8600. Il n'y a donc probablement pas beaucoup mieux à en attendre que des Radeon X1000. Espérons qu'AMD éclaircira cela rapidement puisqu'il serait utile de savoir si ce GPU est oui ou non certifié capable de prendre en charge ces médias de manière efficace. Aucune des GeForce 7, 8800 et Radeon X1000 ne l'est, malgré le blabla marketing que les fabricants sont arrivés à nous sortir à chaque lancement en laissant penser que leur solution était ce qui se faisait de mieux pour les médias Bluray et HD-DVD. AMD et Nvidia aiment surfer sur la vague du HD mais il serait temps d'afficher clairement ce dont est capable chaque puce.  La Radeon HD 2900 XT intègre un contrôleur son de manière à pouvoir intégrer le son à la vidéo avec la connexion HDMI tout en respectant les normes exigées par Windows Vista pour assurer une protection avancée du contenu HD. La Radeon HD 2900 XT n'est cependant en rien une carte son en tant que telle comme le laissent penser les rumeurs racoleuses qui ont circulé chez certains confrères. Par ailleurs la sortie HDMI est limitée en mode 1.2, ce qui est dommage puisque seul le mode 1.3 permet de profiter de tous les raffinements en matière de son. Un convertisseur DVI/HDMI spécial est requis pour supporter le transfert du son à travers le HDMI. Enfin, contrairement aux GeForce 8800 et comme sur les GeForce 8600, le HDCP est ici géré en dual link sur les sorties DVI : il sera donc possible de profiter des films HD protégés sur un écran 30" 2560*1600. A condition dêtre loin du PC pour ne pas trop lentendre (sic). Le testPour ce test, nous avons fait appel à 9 jeux : Quake 4, Half-Life 2, Serious Sam 2, F.E.A.R., Stalker, Rainbow Six Vegas, Tomb Raider Legend, Oblivion et Age of Empire III. Les tests ont tous été exécutés en 1920x1200 et en 1680x1050 avec le filtrage anisotrope activé, via le jeu quand disponible et via les drivers en mode 16x dans les autres cas. Le HDR a été activé dans tous les cas où il est disponible. Stalker a été testé en mode dynamique complet et Tomb Raider Legend en mode Next Gen. Enfin, le transparency/adaptive antialiasing était activé en mode supersampling. Nous avons dû écarter Need for Speed Carbon de ce test puisqu'un bug fixe le Vsync sur ON chez Nvidia et un autre bug fait planter le jeu au démarrage sur Radeon HD 2900XT. Windows Vista fait maintenant partie de notre plateforme de test. Nous avons utilisé une version beta des drivers AMD fournie en dernière minute. Celle-ci corrige des problèmes de performances importants, notamment dans Oblivion avec antialiasing. Ce driver correspond au driver "presse" (similaire à celui qui sera fourni avec les cartes au lancement) mais avec le composant Direct 3D des Catalyst 7.5. Les performances en Direct 3D obtenues dans ce test sont donc celles qui seront fournies par ce futur driver. ConfigurationIntel Core 2 Extreme X6800 nForce 680i SLI EVGA 2 Go DDR2 Windows Vista Forceware 158.18 Page 11 - Quake 4, Half Life 2 Lost Coast Quake 4Nous avons enregistré une démo qui représente une scène daction. Contrairement à Doom 3, il y a moins dombres et plus de monstres et de textures ce qui change la charge au niveau du rendu. Le filtrage anisotrope 8x est activé automatiquement par le jeu. Les tests ont été réalisés en mode Ultra qualité.  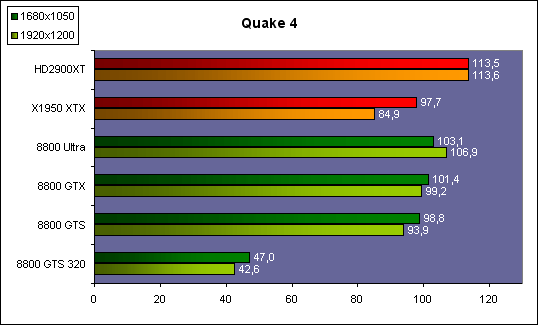 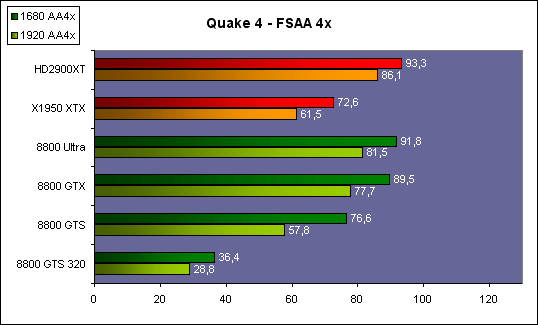 La Radeon HD2900 XT domine dans Quake 4 grâce à un driver OpenGL plus performant. Nvidia a encore du travail à faire au niveau de ses drivers pour Windows Vista. Half-Life 2 Lost CoastPour ce test nous utilisons une démo interne que nous avons enregistrée sur Lost Coast de manière à pouvoir tester le HDR façon Valve qui utilise un format de rendu assez complexe qui ne fait pas usage des possibilités supplémentaires des carte de dernière génération mais tourne sur toutes les cartes DirectX 9 et ce avec MSAA. Le filtrage anisotrope 16x est activé via le jeu  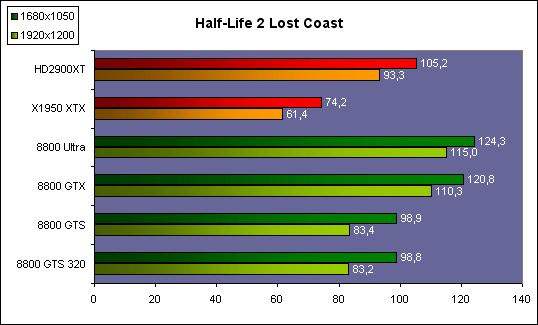 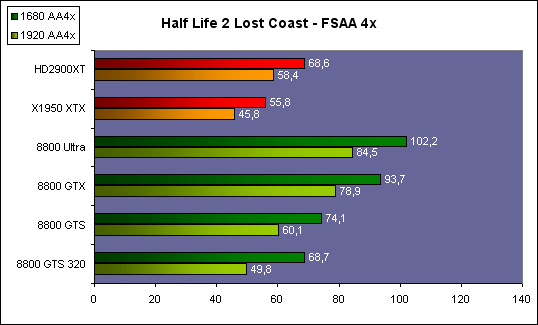 Dans Half-Life 2 avec antialiasng, les gains apportés par la Radeon HD2900 XT sur la Radeon X1950 XTX sont réduits, malgré la bande passante nettement plus élevée, ce qui est décevant. Page 12 - F.E.A.R., Serious Sam 2 F.E.A.R.Nous utilisons la démo intégrée de F.E.A.R. Malheureusement, celle-ci ne donne quun score entier ce qui peut par exemple entraîner une différence dune unité dans les mêmes conditions à cause dune variation normale de 2 dixièmes. Nous avons donc sélectionné pour chaque carte le meilleur de 3 résultats. Toutes les options graphiques sont poussées au maximum, à l'exception des soft shadows qui sont désactivés car ne fonctionnant pas avec AA. Le filtrage anisotrope 16x est activé via le jeu.  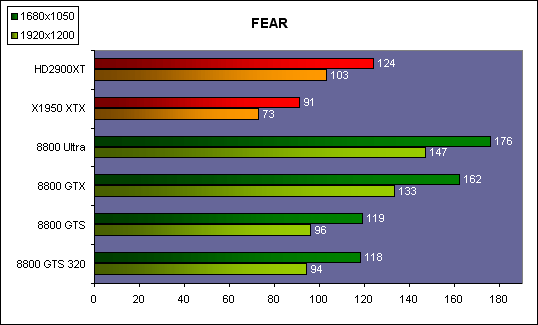  Alors qu'ATI était habituellement très compétitif avec antialiasing dans F.E.A.R., ce n'est plus le cas ici. Un problème semble bel et bien impacter les performances de la Radeon HD2900 XT une fois l'antialiasing activé. Serious Sam 2Nous avons enregistré une démo ici aussi et activé le filtrage anisotrope 16x dans le jeu, tout comme le HDR.   Fortement limité par la puissance de filtrage, c'est tout naturellement que Serious Sam 2 offre un net avantage aux GeForce 8. 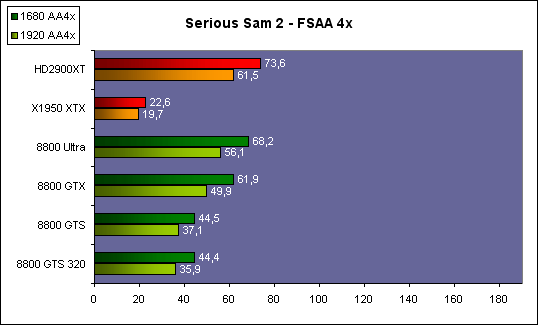 Avec antialiasing et pour une raison qui nous échape, le nouveau driver AMD est très performant dans Serious Sam 2, grâce à un coût presque négligeable de l'Adaptive AntiAliasing. Page 13 - Rainbow Six : Vegas, STALKER Rainbow Six : VegasNous mesurons les performances sur la scène d'introduction, le filtrage anisotrope 16x est activé via les drivers. Le mode HDR est activé et est plus ou moins obligatoire sans quoi le banding est très présent. Les ombres sont réglées sur "bas", les modes supérieurs entraînant une trop forte baisse de performances dans certains endroits.  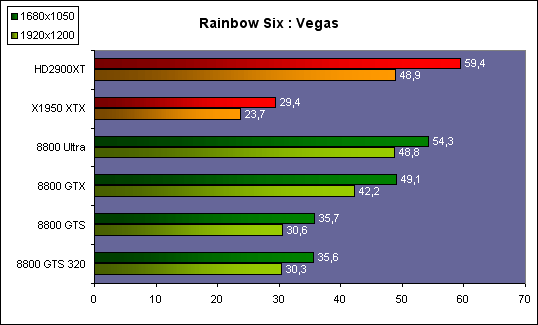 La Radeon HD 2900 XT semble particulièrement apprécier ce premier jeu utilisant, certes d'une manière discutable étant donné le rapport graphismes / performances, l'Unreal Engine 3 ce qui est prometteur, puisqu'elle se permet de devancer la GeForce 8800 Ultra. 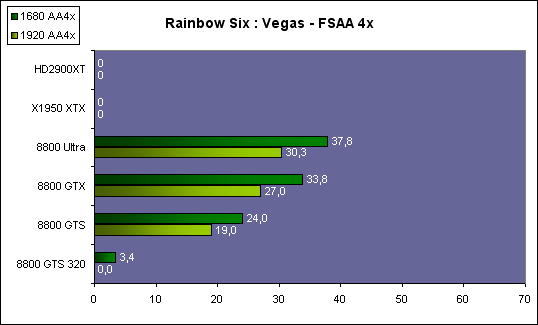 Malheureusement, seul Nvidia a implémenté le support du FSAA pour ce jeu dans ses drivers, chose qui n'est pas proposée dans le jeu. Nous avons informé AMD de ce problème et le célèbre Chuck, auteur du patch pour Oblivion a été mis sur le coup. Cela devrait donc être rapidement intégré dans les drivers d'AMD. S.T.A.L.K.E.R.Nous effectuons un déplacement toujours identique et mesurons le framerate avec fraps. Nous testons le jeu avec un niveau de qualité élevé, éclairage dynamique complet, détails maximums et ombres des herbes. S.T.A.L.K.E.R. utilise un moteur à base de rendu différé ce qui est fondamentalement incompatible avec du MSAA, ce qui rends l'utilisation de l'antialiasing impossible. Une espèce de filtrage des arrêtes réalisé via un shader est activable mais il offre un résultat mitigé. Le patch 1.00001 est utilisé.  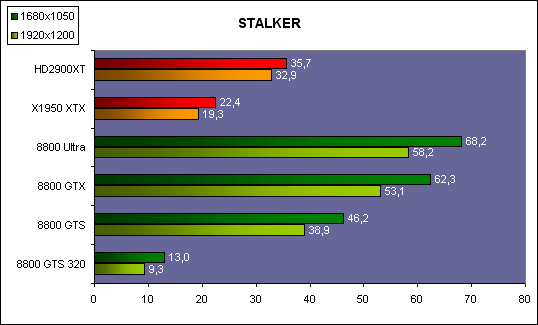 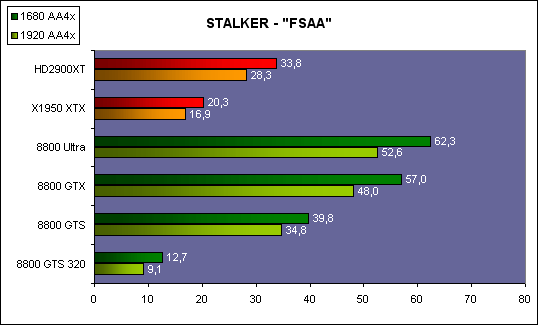 Les Radeon semblent peu efficaces dans ce jeu. AMD nous a indiqué n'avoir eu que très peu accès au beta de ce jeu (massivement sponsorisé par Nvidia) et indique par conséquent être en retard sur l'optimisation par rapport à ce moteur très spécial. Page 14 - Oblivion, Tomb Raider OblivionNous effectuons un déplacement précisément défini afin quil soit toujours identique et que le test soit reproductible. Le HDR est utilisé et le filtrage anisotrope 16x est activé via les drivers.  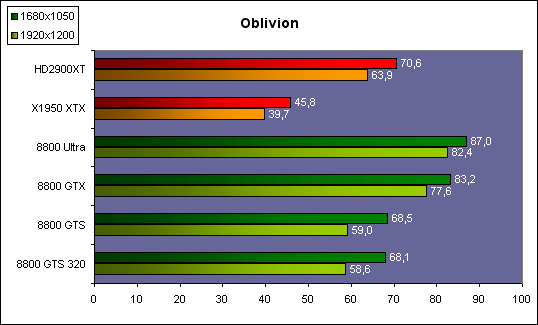  Dans Oblivion avec FSAA, le nouveau driver beta sauve la Radeon HD 2900 XT avec des performances qui font plus que doubler par rapport au premier driver censé être utilisé pour ce test, ce qui lui permet d'approcher la 8800 GTX. Tomb Raider LegendNous avons enregistré une partie et effectuons un déplacement régulier et donc toujours identique. Le filtrage anisotrope 16x est activé via les drivers. Nous utilisons exclusivement le mode Next Gen, le mode classique étant d'une autre époque au niveau de la qualité.  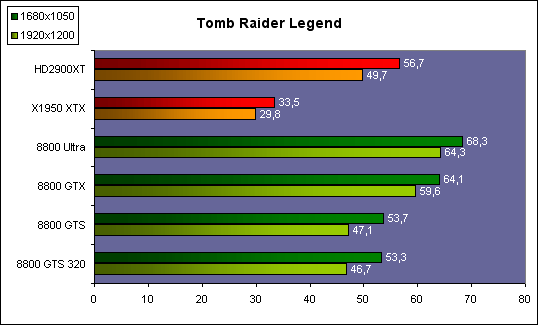 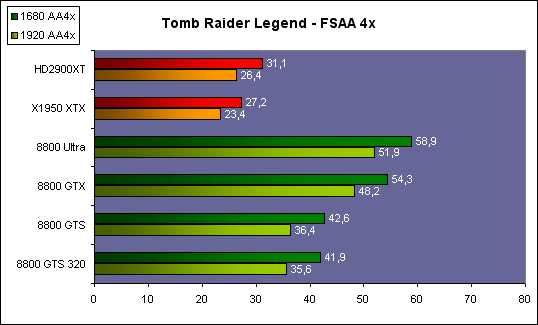 Une nouvelle fois les performances avec FSAA du nouveau Radeon sont particulièrement décevantes. Page 15 - Age of Empire III, récapitulatif Age of Empire IIIPour tester ce jeu, nous avons sauvegardé une partie sur laquelle nous effectuons un déplacement bien défini en mode pause. L'aniso est activé dans le jeu, ainsi que mode HDR mais il faut noter que si il produit un résultat similaire chez ATI et chez Nvidia, il est réalisé différemment. A base de FP16 chez Nvidia, il est en FX10 chez ATI. Ce mode FX10 permet si on ne laisse que 2 bits pour la transparence de tenir dans les 32 bits classiques ce qui est idéal pour les performances.  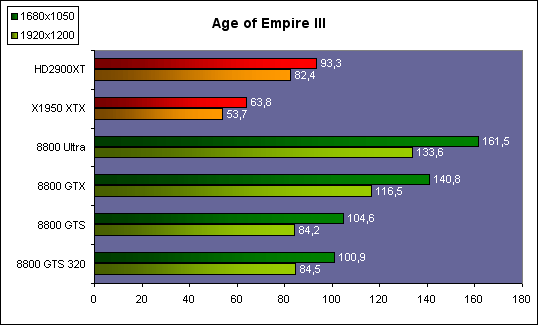 Malgré un rendu moins gourmand du côté d'ATI, Nvidia reste le plus performant dans ce jeu. 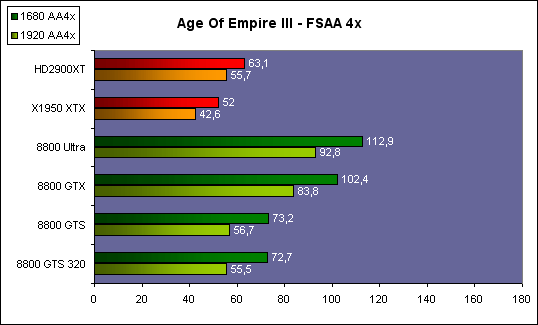 Les performances avec FSAA du Radeon HD 2900 sont une nouvelle fois plus faibles que ce à quoi nous pouvions nous attendre. Récapitulatif Voici un indice de performances que nous avons calculé en donnant la même valeur à chaque jeu et en donnant un indice 100 à la GeForce 8800 GTS en 1680x1050 sans AA : 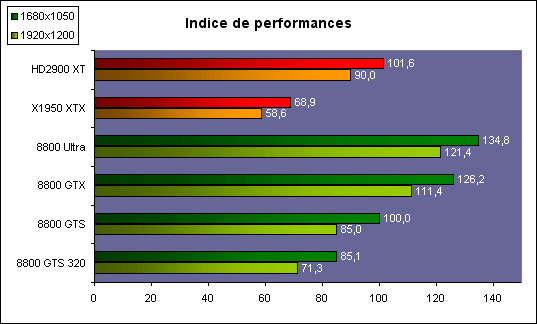 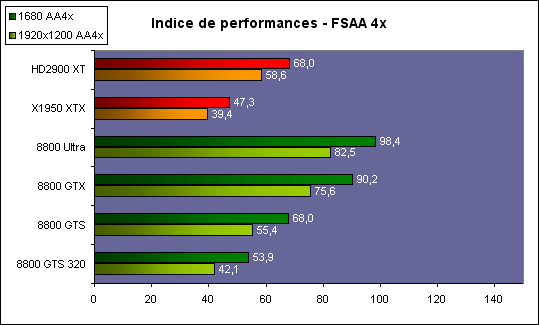 La Radeon HD2900XT se place très légèrement devant la GeForce 8800 GTS. Cependant, le positionnement variant fortement d'un jeu à l'autre, nous vous invitons à consulter les tests détaillés. Page 16 - Conclusion ConclusionLe Radeon HD 2900 XT s'est fait longuement attendre et 6 mois après la sortie du GeForce 8800 GTX, il ne permet pas de le concurrencer sur le plan des performances. Certes AMD l'a repositionné face au GeForce 8800 GTS et a fixé sa tarification en conséquences, ce qui n'est pas réellement un problème mais déroge malgré tout à la règle qui est qu'un nouveau GPU haut de gamme vise toujours la tête. Nous ne franchissons donc pas de nouveau pallier en termes de performances et Nvidia garde le leadership à ce niveau avec les GeForce 8800 GTX et Ultra.  Malgré son bus mémoire 512 bits, très utile en antialiasing, la Radeon HD 2900 XT peine à tirer son épingle du jeu dans ce mode. Problème matériel ? Problème de drivers ? Probablement un peu des deux malheureusement. Reste que en moyenne la carte parvient à se placer légèrement devant la GeForce 8800 GTS 640 Mo pour un prix similaire mais la Radeon est accompagnée d'un coupon Valve qui permettra d'avoir accès à Half-Life 2: Episode 2, Team Fortress 2 et Portal, un bonus non négligeable. Il vous faudra donc en définitive trancher entre ce bonus et une carte moins gourmande et plus discrète telle que la GeForce 8800 GTS. AMD paye ici le prix d'une architecture un petit peu "juste" et poussée dans ses derniers retranchements face à une architecture GeForce 8 extrêmement efficace et équipée d'une puissance de filtrage très élevée.  Bien entendu, les drivers ne peuvent qu'évoluer et l'architecture VLIW laisse beaucoup de place aux optimisations. Encore faut-il qu'AMD s'y investisse. L'architecture HD2000 semble également mieux adaptée aux traitements de geometry shaders lourds dans DirectX 10, tout du moins si notre analyse du GeForce 8800 est correcte à ce niveau. Reste que nous ne savons pas encore ce que les développeurs vont en faire. Si par exemple le Radeon HD 2900 est 10x plus rapide à ce niveau, mais que cela ne représente que 5% de la charge globale d'une scène, la situation ne sera pas dramatique pour le GeForce 8800. Difficile donc sans plus d'information de donner un avantage à la puce d'AMD avec la nouvelle API de Microsoft. Avec le Radeon HD 2900 XT, AMD réintroduit le Truform façon nouvelle génération et entièrement programmable, ce qui est une très bonne chose sauf que le tout n'est pas exploitable pour le moment et AMD ne sait pas quand ce sera le cas. Cet avantage technique est donc réduit à zéro pour AMD, et il en va de même pour la prise en charge du décodage des vidéos HD qui nest pas encore fonctionnel. L'autre nouveauté introduite est la possibilité d'appliquer des filtres personnalisés lorsque l'antialiasing est utilisé. Sur le principe il s'agit là d'une excellente idée, mais en pratique les filtres supplémentaires actuellement proposés par AMD ne nous ont pas convaincus. Nous attendons donc de voir ce qu'AMD va faire de cette possibilité dans le futur. Vous l'aurez compris, si nous reconnaissons certains avantages potentiels au Radeon HD 2900 XT, ceux-ci ne peuvent selon nous pas être validés en l'état actuel des choses. Copyright © 1997-2025 HardWare.fr. Tous droits réservés. |