| |
| |
| Intel Core 2 Duo Processeurs Publié le Jeudi 22 Juin 2006 par Franck Delattre et Marc Prieur URL: /articles/623-1/intel-core-2-duo.html Page 1 - Introduction  Netburst est mort, vive Core ! Intel lavait annoncé il ya maintenant plus dun an, larchitecture Netburst introduite avec le Pentium 4 en novembre 2000 laisse désormais place à une nouvelle architecture, Core, qui est déclinée sur les plate-formes desktop, mobile et server. Netburst est mort, vive Core ! Intel lavait annoncé il ya maintenant plus dun an, larchitecture Netburst introduite avec le Pentium 4 en novembre 2000 laisse désormais place à une nouvelle architecture, Core, qui est déclinée sur les plate-formes desktop, mobile et server.Ainsi, Intel va lancer dans les jours à venir de nouveaux Xeon, et lancera fin juillet les processeurs Core 2 Duo au format LGA 775. Loccasion pour HardWare.fr de faire le tour du sujet, que ce soit au niveau de larchitecture Core à proprement parler quau niveau des performances de la gamme Core 2 Duo en pratique. « The Core legacy »  Pour bien comprendre les choix techniques retenus dans le design de larchitecture Core, un petit coup dil en arrière est nécessaire. Remontons donc le temps de quelques années pour nous arrêter fin 2000, date à laquelle toute la gamme des processeurs Intel (desktop, server et mobile) repose sur larchitecture P6. P6 a été introduite près de 6 ans auparavant avec le Pentium Pro, et malgré des améliorations au fil des versions elle commence à montrer quelques signes dessoufflement. Surtout face à AMD et son Athlon, qui a remporté la très symbolique et médiatique course vers le Gigahertz. Il était donc urgent pour Intel de dévoiler larchitecture succédant au P6. Pour bien comprendre les choix techniques retenus dans le design de larchitecture Core, un petit coup dil en arrière est nécessaire. Remontons donc le temps de quelques années pour nous arrêter fin 2000, date à laquelle toute la gamme des processeurs Intel (desktop, server et mobile) repose sur larchitecture P6. P6 a été introduite près de 6 ans auparavant avec le Pentium Pro, et malgré des améliorations au fil des versions elle commence à montrer quelques signes dessoufflement. Surtout face à AMD et son Athlon, qui a remporté la très symbolique et médiatique course vers le Gigahertz. Il était donc urgent pour Intel de dévoiler larchitecture succédant au P6.Lintroduction dune nouvelle architecture nest pas une mince affaire. Elle doit, dès son introduction, fournir des performances au moins égales aux modèles les plus évolués basés sur larchitecture précédente, mais aussi (et surtout) posséder un potentiel dévolutivité pour les cinq ou six années à venir, durée moyenne de rentabilisation des budgets investis en R&D. Cest en tout cas le schéma adopté par Intel depuis toujours, bien que la présence dun concurrent dangereux constitue une nouvelle donnée qui tende à accélérer la succession des modèles. Il sagit en tout cas de ne pas reproduire la mésaventure du Pentium III EB 1,13 GHz qui poussait larchitecture P6 dans ses retranchements dune telle façon que le modèle a du être rappelé et retiré de la vente. Cest certainement ce souci dévolutivité qui a prévalu lors de la définition de larchitecture Netburst. Netburst a en effet été conçue pour fournir des performances croissantes pendant plusieurs années dexistence. Voyons de quelle façon. Page 2 - IPC et fréquence IPC et fréquenceLa performance dun CPU peut être évaluée par la quantité dinstructions quil exécute à chaque seconde, soit le rapport i/s. Cette donnée peut se décomposer comme suit : où c correspond au nombre de cycles processeur, i/c correspond au nombre moyen dinstructions exécutées à chaque cycle (cest lIPC) et c/s est le nombre de cycles par seconde, soit la fréquence dhorloge, notée F. Ainsi : Cette formule simple nous montre que lIPC et la fréquence sont les deux principaux facteurs de performance. Or, IPC et fréquence sont intimement liés à larchitecture du processeur, et notamment à la profondeur du pipeline de traitement. Considérons par exemple un processeur définit de telle manière que linstruction la plus rapide seffectue en 10 ns. Sil utilise un pipeline de traitement composé de 10 étapes, une étape seffectue en 1 ns (10 ns / 10 étapes), ce qui correspond au temps de cycle minimal. La fréquence maximale atteignable est alors linverse de ce temps de cycle, soit 1 GHz. Si le pipeline comporte 20 étapes, le temps de cycle vaut alors 0,5 ns (10 ns / 20 étapes), soit une fréquence maximale de 2 GHz. Comme on le voit, la fréquence maximale de fonctionnement augmente avec la profondeur du pipeline. LIPC est quant à lui une donnée intrinsèque à larchitecture du processeur, et dépend notamment des capacités des unités de calcul. Par exemple, si le processeur possède une seule unité de traitement des additions, il pourra fournir un débit maximal de une addition par cycle. Sil en possède deux, ce sont deux additions qui seront susceptibles de seffectuer en un cycle. « Susceptibles », car ce scénario optimal implique que le pipeline de traitement fournisse un débit constant et maximal. Or, en pratique, le flux dinstructions qui est traité par le pipeline comporte des dépendances qui imposent des états dattente au pipeline, brisant ainsi son débit, et qui tendent à faire baisser lIPC. Deux types de dépendances sont particulièrement néfastes pour le pipeline : les branchements, et surtout les accès à la mémoire. Voyons par exemple le cas dun processeur possédant deux unités de calcul sur les entiers, lui conférant ainsi un IPC maximal de 2 sur ces instructions. Ajoutons lui un sous-système de cache qui présente un taux de succès de 98%, et une mémoire centrale affichant un temps daccès de 70 ns. Un code x86 comporte en moyenne 20% dinstructions accédant à la mémoire. Parmi ces instructions, 98% trouveront la donnée dans le sous-système de cache, et 2% devront accéder à la mémoire centrale. Pour les 80% de code restant et pour les 98% dinstructions accédant avec succès au cache, nous allons supposer que le processeur peut fournir son IPC maximum de 2, ce qui représente 0,5 cycle par instruction. Le nombre de cycles moyen par instruction vaut alors : où M représente le temps daccès à la mémoire centrale en cycles. Les branchements ont un impact un peu moins important, mais il dépend également de la profondeur du pipeline. En effet, en cas de mauvaise prédiction de branchement, le contenu du pipeline est erroné car il contient les instructions de la mauvaise branche. La pénalité est alors égale, en cycles, à la profondeur du pipeline. Si lon part avec les hypothèses de 10% dinstructions de branchements et un taux de succès du mécanisme de branchement de 96%, on obtient : où P est la profondeur du pipeline.
 LIPC qui découle des pénalités dues aux branchements et aux accès mémoire tombe ainsi à 1,19 pour le pipeline à 10 étapes, et 0,82 pour celui à 20 étapes. Ce qui nous intéresse nest pas tant lIPC que son produit par la fréquence, qui fournira le nombre dinstructions traitées à chaque seconde.  On saperçoit alors que la fréquence maximale permise par lutilisation dun pipeline à 20 étapes compense la baisse de lIPC, si tant est quau final le pipeline à 20 étapes se montre plus rapide que la version à 10 étapes. Il nen a pas fallu plus à Intel pour que le constructeur fasse des longs pipeline sa nouvelle philosophie, et Netburst était née. Page 3 - Le plan et les problèmes Netburst Le plan NetburstLarchitecture Netburst a donc été motivée par des considérations réelles de performances, même si les fréquences importantes nétaient certainement pas pour déplaire au service marketing dIntel. Le plan de développement de Netburst était relativement simple : augmenter la profondeur du pipeline au fur et à mesure des versions. Doublée de la réduction de la finesse de gravure, cette stratégie était censée permettre datteindre et de dépasser 7 GHz : Bien sûr laugmentation du découpage du pipeline a ses limites. Au delà de 55 étapes, la baisse de lIPC engendrée par les dépendances nest plus compensée par laugmentation de la fréquence dhorloge, et le nombre dinstructions par seconde, et donc la performance, commence à décliner. 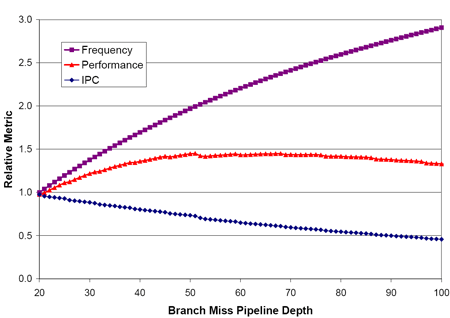 (source Intel) Les premiers Pentium 4 Willamette ne se sont hélas pas montré très performants, hormis peut-être la version à 2GHz. En effet, le modèle théorique révèle que la performance nest au rendez-vous que si la fréquence dhorloge est assez élevée pour compenser la baisse dIPC, et les versions entre 1,3 et 1,5GHz du Willamette ne remplissaient que partiellement cette condition. La déclinaison Northwood a cependant redressé la barre de façon spectaculaire. Dune part par lutilisation de fréquences plus élevées, mais également par lemploi dun cache L2 plus gros et plus performant que celui du Willamette, ce qui a eu pour effet daugmenter le succès du sous-système de cache et de réduire ainsi les pénalités liées aux accès mémoire. Les versions à partir de 2,8GHz du Northwood ont réellement donné ses lettres de noblesse au Netburst, et les modèles à 3,2 et 3,4GHz sont encore aujourdhui des modèles de performance, dailleurs très recherchés sur le marché de loccasion. En juin 2004 Intel passe à la seconde phase du plan Netburst et introduit le Prescott. Bien que possédant plus de mémoire cache que le Northwood, le Prescott surprend doublement ses premiers testeurs : les performances sont dans certains cas inférieures à celles du Northwood, et le nouveau processeur, bien que gravé en 90nm, tend à chauffer exagérément. La baisse de performance par rapport au Northwood sexplique par laugmentation de la profondeur du pipeline à 31 étapes. Léchauffement excessif est en revanche une très mauvaise surprise, dont le Prescott ne se débarrassera jamais complètement malgré une sensible amélioration du phénomène au fil des steppings. Mais ce sont au final les problèmes de dissipation thermique qui casseront la progression du Prescott. Dès lors les choses ont tourné au vinaigre pour Netburst. Le Prescott bloqué dans sa montée en fréquence, cest tout lintérêt de larchitecture Netburst qui est remis en cause. Les problèmes du NetburstNorthwood souffrait déjà dune dissipation thermique importante, bien que le problème fût moins conséquent que sur le Prescott. Si la dissipation restait acceptable pour une plate-forme de bureau ou un server, elle représentait un réel problème pour la plate-forme mobile, tant en terme de chaleur dégagée que dautonomie. Bien que le Pentium 4 existe en version Mobile, larchitecture Netburst nest réellement pas adaptée à la mobilité, ce qui a nécessité le développement dune architecture dédiée à une utilisation basse consommation. En parallèle de Netburst sest ainsi développée larchitecture Mobile, dérivée de P6, et dont le premier représentant, le Pentium M Banias, est sorti dès mars 2003. Bien quelle fut un succès, alliant performances et économie dénergie, Mobile a représenté un coup dur pour Netburst, imposant à Intel la production de deux architectures distinctes pour couvrir toutes les plate-formes PC. Ce qui bien sûr signifie des coûts de production plus élevés en comparaison à une architecture multi-usage. Premier revers pour Netburst. La raison pour laquelle Netburst est en proie à une dissipation thermique élevée tient dans les fréquences utilisées, mais ce nest pas la seule raison. A fréquences égales, Prescott dissipe bien plus dénergie que Northwood, et ce malgré une finesse de gravure inférieure. La différence réside en réalité dans la profondeur du pipeline. Augmenter le nombre détapes tend en effet à augmenter la puissance dissipée, pour une raison liée au découpage. Pour comprendre, il faut savoir que certaines étapes critiques dans le traitement des instructions nécessitent de seffectuer en un cycle dhorloge, sous peine de ralentir considérablement le fonctionnement du pipeline. Cest par exemple le cas de la prédiction de branchement ou du moteur out-of-order, responsable de gérer les dépendances. Ces étapes clés ne sont pas de bonnes candidates au découpage, et doivent terminer leur travail sur un temps de cycle. Or, plus le pipeline est long, plus le temps de cycle est faible. Afin de compenser cette diminution, il est nécessaire de paralléliser les algorithmes utilisés par ces étapes afin quelles puissent effectuer leur travail dans le temps imparti. Cette parallélisation complexifie considérablement létape, et notamment le nombre de transistors quelle requiert. De plus, si le seul changement de lalgorithme ne suffit pas à boucler lopération en un cycle, il est alors nécessaire dutiliser des transistors plus rapides, donc plus gros et plus gourmands. Tout ceci se traduit bien évidemment par une augmentation de la dissipation thermique, et est dautant plus critique que le temps de cycle visé est faible, et donc le pipeline profond. Un exemple illustre particulièrement bien cette contrainte. Le Northwood possède des unités de calcul entier de type « double vitesse », qui permettent en pratique de boucler deux opérations entières par cycle. Lallongement de la longueur du pipeline sur le Prescott na pas permis dimplémenter de telles ALUs. Afin de garder le même débit dinstructions, chaque ALU double vitesse a donc été transformée en deux ALUs simple vitesse. Ceci a bien entendu doublé le nombre de transistors utilisé par les unités concernées.  Le Prescott a transformé chaque ALU double vitesse du Northwood en deux ALUs simple vitesse. On peut se demander où en serait Netburst aujourdhui si lon fait abstraction des problèmes de dissipation, cest-à-dire si le refroidissement cryogénique remplaçait le ventirad standard Intel. Prescott tournerait alors à 4,8 GHz, et la version Cedar Mill permettrait de franchir la barrière des 5 GHz. Le Tejas serait à nos portes, introduisant son jeu dinstruction SSE4 (initialement appelé TNI pour « Tejas New Instructions ») et un pipeline à 45 étapes. Le but de cette projection nest pas de dresser un tableau idyllique de larchitecture Netburst, mais de constater que labandon de Netburst na pas été motivé par un problème de performances absolues de larchitecture mais bel et bien de dissipation thermique ce qui au final na pas permis d´atteindre les fréquences nécessaires à la performance ciblée. Page 4 - L'après Netburst : Intel Core Laprès NetburstLors de labandon de Netburst, Intel sest retrouvé dans une situation très proche de celle de 2001 lors de la définition du successeur à larchitecture P6. Le passage par la case Netburst a cependant changé les impératifs de 2001. Le nouveau cahier des charges qui en a découlé constitue le fondement même de Core. A la lecture de ces nouvelles spécifications, les regards se sont naturellement tournés vers larchitecture Mobile. Elle a le mérite dexister et davoir évolué en parallèle au Netburst, intégrant ainsi à P6 les innovations introduites par Netburst sur desktop (bus quad-pumped, SSE2). En outre, lemploi dun pipeline court la rend économe en énergie. Tout est là ou presque pour faire de Mobile le successeur idéal de Netburst. De plus, Mobile bénéficie dune très bonne réputation auprès des utilisateurs, qui ne regrettent que le cantonnement de son utilisation sur la plate-forme du même nom. A tel point que les tentatives pour ladapter sur les ordinateurs desktop se multiplient, et ce malgré la volonté dIntel de protéger Netburst dune chute trop rapide, le temps que la relève arrive. En application du nouveau cahier des charges, Mobile va ainsi bénéficier de quelques améliorations pour la rendre plus performante afin de la rendre capable de mener la barque Intel sur les trois plate-formes PC. Larchitecture Core est née ! Retour à une architecture unifiéeSi le choix de Mobile comme fondation de la nouvelle architecture Core répond à lexigence de créer une architecture économe en énergie, il reste à ladapter aux conditions déconomie de production, ce qui signifie la rendre capable de subvenir aux besoins des plate-formes non mobiles. La démarche est originale, car jusqualors les processeurs mobiles étaient adaptés des versions desktop et non linverse. Le retour à une architecture unifiée pour les trois plate-formes représente bien sûr un intérêt économique de production pour le fondeur, mais aux dires dIntel facilite également le travail des développeurs qui nauront dès lors plus à se soucier doptimiser leurs programmes pour plusieurs micro-architectures aux exigences différentes du moins tant quils restent dans la gamme Intel ! Et de fait, une architecture commune signifie des optimisations génériques et non plus spécifiques à tel ou tel processeur. A titre dexemple, la non généralisation des extensions 64 bits a certainement représenté un frein dans lutilisation de ce nouveau mode dexploitation, jusqualors non présent sur larchitecture Intel Mobile. Core offre ainsi en standard aux développeurs : Il aurait été bienvenu dajouter le dual-core dans cette liste, hélas Intel prévoit de décliner larchitecture Core sur des modèles mono-core. Dommage !  Architecture Core au sein du Conroe Priorité à lIPCBien que performante, Mobile ne creuse pas un écart assez important dans ce domaine face aux derniers modèles basés sur Netburst, et surtout face à lAthlon 64. Core a pour ambition de reprendre la palme de la performance sur plate-forme desktop, et doit donc faire évoluer Mobile dans ce sens. Core bénéficie dun découpage du pipeline de traitement en 14 étapes, là où Mobile en comporte 12. Une telle profondeur limite la fréquence maximale de fonctionnement, et à défaut daller chercher la performance sur la longueur, cest sur la largeur quon été portés tous les efforts afin dobtenir un IPC élevé. Core hérite du moteur dexécution dynamique Out-Of-Order de Mobile, mais innove en étendant sa capacité de traitement. Chaque noyau dexécution de Core permet ainsi de charger, de décoder, dexécuter et de sortir jusquà 4 instructions par cycle, là où Mobile ne peut en fournir que 3. Core introduit ainsi le 4-wide dynamic execution engine. Laugmentation du débit dinstructions constitue un facteur daccélération en soit, mais offre également au moteur OOO une fenêtre dinstructions plus large, facilitant ainsi son travail de gestion des dépendances, et par là-même son efficacité. Cest, rappelons-le, ce même souci doptimisation du travail de lOOO qui a motivé limplémentation de lHyper-Threading au sein de Netburst. Un moteur dexécution plus large sous-entend des unités de calcul en mesure de digérer un débit dinstructions supérieur en comparaison à Mobile, et à ce titre les unités de calcul de Core ont fait lobjet de toutes les attentions. Page 5 - Les unités de calcul Les unités de calculVoici une rapide comparaison des unités de calcul des architectures actuelles :  ... et les bandes passantes théoriques en instructions qui en découlent : 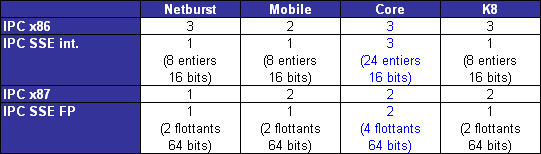 Core possède trois unités de calcul sur les entiers, soit une de plus que Mobile, le plaçant ainsi au niveau du K8 avec une capacité de trois instructions x86 par cycle. A noter que Netburst conserve sa suprématie en capacité de traitement des entiers avec ses unités double vitesse qui lui permettent de traiter jusquà 4 instructions entières par cycle (et non pas 5 comme le laisserait supposer la présence dune ALU supplémentaire en simple vitesse, car celle-ci partage son port avec une des deux ALUs double vitesse). Hélas, cette capacité de traitement nest pas exploitable en pratique car les unités de décodage de Netburst ne permettent pas de fournir un tel débit, limitant ainsi lIPC à 3. Il nous a semblé intéressant détudier le comportement de Core sur des instructions courantes x86 telles quopérations arithmétiques, décalages, rotations... Nous avons pour cela utilisé un outil intégré à Everest qui fournit latence et débit de quelques instructions choisies parmi x86/x87, MMX, SSE 1, 2 et 3. Ce petit outil est présent dans la version dévaluation : il suffit de cliquer droit dans la barre détat dEverest, et sélectionner « CPU Debug » puis « Instructions latency dump » dans le menu qui apparaît. A titre de rappel, la latence dune instruction représente, en nombre de cycles processeur, le temps quelle passe dans le pipeline de traitement. En pratique, le moteur OOO sefforce de traiter le flux dinstructions de telle façon que ces latences soient masquées, mais les dépendances entre instructions tendent à générer des attentes, dautant plus importantes que les latences de ces instructions le sont. Le débit dune instruction correspond au temps minimal, en cycles processeur, séparant la prise en charge de deux instructions similaires. Ainsi, par exemple, la division entière possède un débit de 40 cycles sur K8, ce qui signifie que le processeur ne pourra traiter, et donc fournir le résultat dun telle division entière quà raison dune tous les 40 cycles. 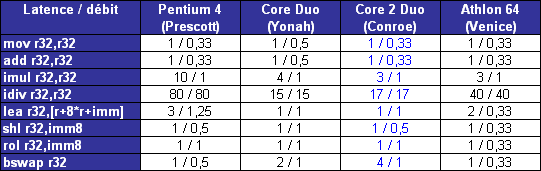 Sur certaines instructions, dont laddition, Core affiche un débit correspondant à son IPC maximal théorique (0,33 cycle par instruction, soit 3 instructions par cycle). La multiplication affiche une latence légèrement inférieure à celle obtenue sur le Yonah, et se place ainsi au niveau du K8. La division entière a subi en revanche une légère baisse de performance, quoiquelle reste beaucoup plus rapide que sur K8 et Netburst. En ce qui concerne les manipulations de registres, Core reste en dessous de K8, bien que le décalage (shl) ait été amélioré en comparaison au Yonah. Ce quil faut retenir de ce tableau est que les efforts sur les unités de Core semblent avoir été portés sur les instructions pour lesquelles le K8 possédait jusque là une certaine avance sur Mobile et Netburst (addition et multiplication entières par exemple), alors quun peu de lest a été lâché sur les instructions pour lesquelles K8 ne brille pas (la division entière). Performances SSE théoriquesUne des améliorations les plus notables des unités de calcul de Core consiste en la présence de trois unités SSE dédiées aux opérations SIMD entières et flottantes. Alliée aux unités arithmétiques concernées, chacune delles est capable deffectuer en un seul cycle des opérations paquées 128 bits (cest-à-dire agissant simultanément sur quatre données 32 bits ou deux données 64 bits), là où Netburst, Mobile et K8 nécessitent deux cycles. Sont concernées notamment les opérations arithmétiques courantes telles que la multiplication et laddition. 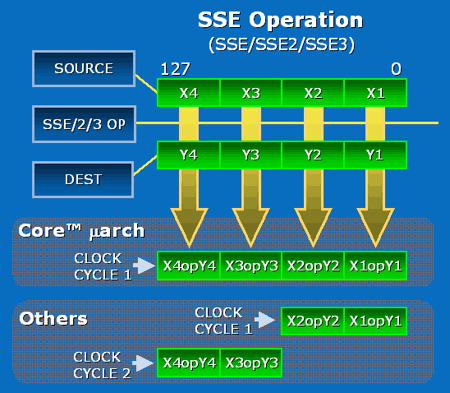 Chacune des trois ALUs est associée à une unité SSE, permettant ainsi de traiter jusquà trois opérations SSE entières 128 bits par cycle (soit 12 instructions sur des entiers 32 bits, ou encore 24 sur des entiers 16 bits). En comparaison, Mobile et K8 ne possèdent que deux unités SSE, et celles-ci ne peuvent traiter que 64 bits par cycle dhorloge. La capacité de Mobile et de K8 en SSE entier nest donc que de 2 x 64 bits, soit 4 instructions sur des entiers 32 bits (ou encore 8 instructions sur des entiers 16 bits). Core possède deux unités de calcul flottant, une dédié aux additions et lautre aux multiplications et aux divisions. La capacité de calcul théorique atteint donc deux instructions x87 par cycle, et deux instructions flottantes SSE 128 bits par cycle (soit 8 opérations sur des flottants simple précision 32 bits, ou 4 opérations sur flottants double précision 64 bits). Core se montre ainsi en théorie deux fois plus rapide sur ce type dinstructions que Mobile, Netburst et K8. Voyons cela sur quelques instructions SSE2. 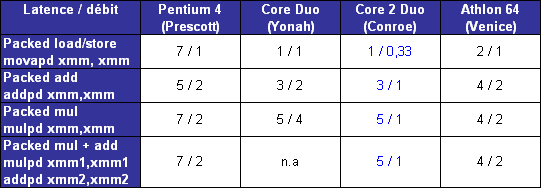 Le packed mov se montre particulièrement véloce sur Core, qui atteint là son pic de débit de 3 opérations 128 bits par cycle. Les débits affichés sur les opérations arithmétiques isolées sexpliquent par la prise en charge de ces opérations par une seule des unités FP, qui utilisée seule offre son débit maximal dune opération 128 bits par cycle. Lopération combinée mul + add exploite en revanche les deux unités conjointement, et sexécute alors avec un débit de 1 cycle pour les deux opérations, soit deux opérations 128 bits par cycle. Intel communique beaucoup sur cette nouvelle capacité de calcul introduite par Core, et la désigne sous le terme de Digital Media Boost. On notera au passage que Core introduit une nouvelle extension du jeu dinstructions SSE. Initialement prévue pour sortir sur le Tejas, SSE4 consiste en 16 nouvelles instructions SIMD, la plupart opérant sur des données entières. Elles sont essentiellement destinées à accélérer le traitement dans les algorithmes de compression et de décompression vidéo. A titre dexemple, linstruction palignr permet deffectuer un décalage à cheval sur deux registres, opération qui est souvent utilisée dans lalgorithme de prédiction de mouvement dans le décodage MPEG. Les capacités des unités dexécution de Core sont pour le moins impressionnantes. Intel a doté sa nouvelle architecture dun potentiel de calcul entre deux et trois fois supérieur à celle de ses prédécesseurs et de la concurrence. Mais posséder un IPC élevé sur le papier est une chose, et lexploiter en pratique en est une autre. Comme nous lavons vu un peu plus haut, un code x86 tend à faire chuter lIPC par les branches et des accès mémoire. Intel a ainsi logiquement apporté quelques améliorations destinées à réduire les effets néfastes de ces deux types de dépendances. Page 6 - Caches, mémoire et prefetch Les caches de CoreLarchitecture Core introduit de nouvelles contraintes à son sous-système de cache. De fait, lIPC élevé nécessite dune part un sous-système de cache présentant un de taux de succès élevé, et ce afin de masquer efficacement les latences mémoire ; mais également un débit élevé afin de faire face à laugmentation en demande de données qui accompagne celle de lIPC. Le tableau ci-dessous regroupe les principales caractéristiques des caches de la nouvelle architecture, et inclut les latences daccès ainsi que les débits obtenus avec le test de bande passante SSE2 (128 bits) de RightMark Memory Analyzer (RMMA) : 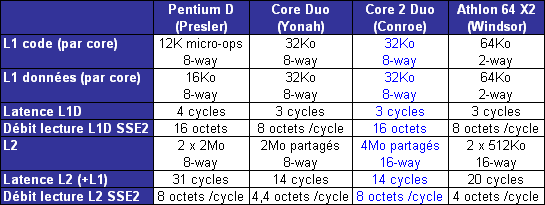 Les caches L1 de larchitecture Core partagent les mêmes caractéristiques de taille et dassociativité que ceux qui équipent Mobile. En revanche, la bande passante offerte est doublée, comme le montre le test de débit en lecture 128 bits de RMMA. Nous retrouvons ce résultat si nous regardons le débit de linstructions de lecture mémoire 128 bits SSE2 movapd : une lecture 128 bits par cycle, soit 16 octets / cycle.  Laccès au cache L2 nécessite un cycle supplémentaire, ce qui porte son débit à 8 octets par cycle. A la différence des Pentium D et Athlon 64 X2, Core utilise la technique de lAdvanced Smart Cache inaugurée sur le Yonah et qui consiste à partager le cache L2 entre les deux cores dexécution. En comparaison à un cache L2 dédié à chaque core, cette méthode présente le principal avantage de partager des données entre les deux cores, et ce sans passer par le bus mémoire. Cela réduit les accès mémoire (et les latences qui laccompagnent) et optimise le remplissage du L2 (les redondances disparaissent). 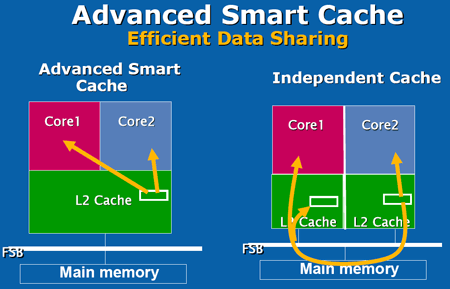 Le cache partagé offre également la possibilité dêtre dynamiquement alloué par chacun des deux cores, jusquà devenir accessible dans son intégralité par un seul des deux cores. Ainsi, cette technique développée spécifiquement pour une implémentation dual core savère paradoxalement plus efficace que les caches séparés lorsquun seul des deux cores est utilisé, cest-à-dire pour toutes les applications mono-thread. Un accès intelligent à la mémoireEn plus des améliorations apportées sur les mémoires caches, Intel a développé de nouvelles techniques visant à améliorer les accès à la mémoire, techniques que le fondeur regroupe sous le terme un peu pompeux de Smart Memory Access. Lidée consiste à répondre à deux critères visant, encore et toujours, à masquer les latences daccès à la mémoire : La contrainte du « quand » réfère à la façon dont un processeur planifie les opérations de lecture et décriture mémoire. En effet, lorsque survient une instruction de lecture mémoire dans le moteur out-of-order, celui-ci ne peut la mener à terme avant que toutes les instructions décriture en cours soient complétées. Sil ne le faisait pas, le risque serait de lire une donnée qui na pas encore été mise à jour dans la hiérarchie mémoire. Cette contrainte impose donc des états dattente, et donc un ralentissement. Core a donc introduit un mécanisme spéculatif visant à prédire si une instruction de lecture est susceptible de dépendre des écritures en cours, cest-à-dire si elle peut être traitée sans attendre. Le rôle du prédicateur est ainsi de lever les ambiguïtés, et donne son nom de Memory Disambiguation à la technique utilisée. Outre la réduction des attentes, lintérêt de la méthode est de réduire les dépendances entre instructions, augmentant par là-même l´efficacité du moteur out-of-order. Prefetch hardwareRépondre à la contrainte du « où », cest-à-dire sefforcer de rapprocher les données du noyau dexécution, est la fonction du sous-système de cache. Afin de lui donner un coup de pouce dans cette tâche, Core a recours au prefetch hardware. Cette technique, rappelons-le, consiste à mettre à profit les moments dinactivité du bus mémoire afin de précharger code et données de la mémoire vers le sous-système de cache. Le prefetch hardware nest pas une technique inédite, loin sen faut. Elle a été inaugurée sur le Pentium III Tualatin, mais cest surtout Netburst qui la fondamentalement améliorée. De fait, la différence importante entre la fréquence du processeur et celle du bus rend Netburst particulièrement sensible aux effets néfastes dun cache miss, augmentant ainsi lintérêt dun prefetch performant. Une fois nest pas coutume, Core hérite ainsi des techniques de prefetch de Netburst, et les améliore quelque peu. Plusieurs types de prefetcher équipent Core : Ce qui nous donne un total de pas moins de 8 prefetchers sur un Core 2 Duo.  Les petits soleils représentent les huit prefetchers du Core 2 Duo. Les mécanismes de prefetch hardware se montrent généralement très efficaces, et se traduisent en pratique par une augmentation du taux de succès du sous-système de cache. Hélas, il peut arriver que le prefetch se traduise par leffet inverse de celui escompté, car si les erreurs sont fréquentes elles tendent à polluer le cache avec des données inutiles, donc réduire son taux de succès. Pour cette raison la plupart des mécanismes de prefetch hardware sont désactivables. Intel préconise même de désactiver le prefetch DCU sur les processeurs destinées à un usage dans un server (en loccurrence le Woodcrest), son utilisation étant susceptible de réduire la performance dans certaines applications. Page 7 - Branchements et fusion Les branchementsLes branchements constituent, après les accès mémoire, le second plus important facteur de ralentissement dans le fonctionnement du processeur en cas de mauvaise prédiction. Un branchement consiste, dans un flux dinstructions, en un saut vers une nouvelle adresse dans le code. Deux types de branchements existent : Quils soient directs ou indirects, les branchements constituent un obstacle dans le fonctionnement optimal du pipeline de traitement. Dès lors que linstruction de saut entre dans le pipeline, celui-ci ne peut, en théorie, plus accueillir de nouvelle instruction tant que ladresse de destination nest pas calculée, cest-à-dire lorsque linstruction de saut atteint les dernières étapes de traitement. Le pipeline insère alors des bulles, ce qui nuit fortement à son rendement. Le rôle du prédicateur de branchement est donc dessayer de deviner ladresse de destination, afin que les instructions suivant le saut soient chargées sans tarder. Il nexiste en fait pas un mais plusieurs prédicateurs. Le plus simple et le plus ancien est le prédicateur statique, dont le fonctionnement repose sur lassertion que la branche sera toujours prise ou à linverse jamais prise. Ainsi, dans une boucle, le mécanisme statique prédit correctement tous les sauts, sauf le dernier ! Son taux de succès dépend bien entendu du nombre ditérations. Le prédicateur statique montre ses limites dans les branchements de type si alors sinon, pour lesquels il a une chance sur deux de se tromper. Le processeur a alors recours à une prédiction dynamique, qui consiste à stocker un historique des résultats des branchements dans une table (la BHT : branch history table). Lorsquune branche est rencontrée, la BHT stocke le résultat du saut, et si la branche est prise ladresse de destination est stockée dans un buffer dédié, le BTB (branch target buffer) (si la branche nest pas prise aucune adresse nest évidemment stockée, car la destination est alors linstruction suivant la branche). Deux types de prédicateurs dynamiques existent au sein dun processeur, qui se différencient par la portée des branches dont ils stockent lhistorique, et ce afin daméliorer la granularité du mécanisme de prédiction. Laction combinée des prédicateurs statiques et dynamiques offrent, selon la taille des buffers de stockage, un taux de succès de la prédiction entre 95 et 97% sur les branches directes. En revanche leur efficacité tombe à environ 75% de prédictions correctes sur les branches indirectes, qui, du fait de la multiplicité des destinations possibles, ne sont pas adaptées au stockage de linformation binaire « pris / non pris » des BHT. Mobile a ainsi inauguré un mécanisme de prédiction de branchements indirects. Le prédicateur stocke dans le BTB les différentes adresses auxquelles le branchement a abouti, ainsi que le contexte qui a conduit à cette destination (cest-à-dire les conditions qui ont accompagné le saut). La décision du prédicateur nest donc plus limitée à une adresse en cas de branche prise, mais en une série de destinations « préférées » de la branche indirecte. La méthode donne de bons résultats mais est très consommatrice de ressources, le BTB contenant alors plusieurs adresses par branche. Mobile a également introduit une technique innovante appelée « détecteur de boucle ». Ce détecteur scrute les branches à la recherche du schéma typique de fonctionnement dune boucle : toutes les branches prises sauf une (ou linverse, selon la condition de sortie). Si ce schéma est détecté, une série de compteurs est affectée au branchement concerné, assurant ainsi un taux de succès de 100%. Core bénéficie bien entendu de tous ces raffinements, en plus de petites améliorations diverses, mais sur lesquelles aucune information na filtré. Les mécanismes de fusionCore comporte un certain nombre de techniques qui visent, pour un nombre dinstructions donné, à réduire le nombre de micro-opérations générées. Effectuer la même tâche avec moins de micro-opérations, cela signifie la faire plus rapidement (augmentation de lIPC) tout en consommant moins dénergie (augmentation de la performance par watt consommé). Initialement introduite sur Mobile, la micro-fusion est lune de ces techniques. Voyons en quoi elle consiste sur un exemple, linstruction x86 : add eax,[mem32]. Cette instruction effectue en réalité deux opérations distinctes : une lecture mémoire, et une addition. Elle sera ainsi décodée en deux micro-opérations : load reg1,[mem32]Cette décomposition suit également la logique de lorganisation du processeur : la lecture et laddition sont prises en charge par deux unités différentes. Dans un schéma classique, les deux micro-opérations seront traitées dans le pipeline, le moteur OOO sassurant de gérer les dépendances. La micro-fusion consiste dans notre cas en lexistence dune « super » micro-opération se substituant aux deux précédentes, en loccurrence : add reg1,[mem32]Ce nest ainsi plus quune unique micro-instruction qui traversera le pipeline de traitement. Lors de lexécution proprement dite, une logique dédiée à la gestion de cette micro-opération sollicitera de façon parallèle les deux unités concernées. La méthode présente en outre lintérêt de nécessiter moins de ressources (un seul registre interne est désormais nécessaire dans notre exemple). Core ajoute à cette technique celle de la macro-fusion. Là où la micro-fusion transforme deux micro-opérations en une seule, la macro-fusion décode deux instructions x86 en une seule micro-opération. Elle intervient donc en amont de la phase de décodage, à la recherche de paires « fusionnables » dans la file dattente des instructions. A titre dexemple, la séquence dinstruction : cmp eax,[mem32]est détectée comme telle, et se décode en la seule micro-opération : cmpjne eax,[mem32],targetCette micro-opération bénéficie dun traitement de faveur car elle est prise en charge par une ALU améliorée, capable de la traiter en un seul cycle (si la donnée [mem32] est dans le cache L1). 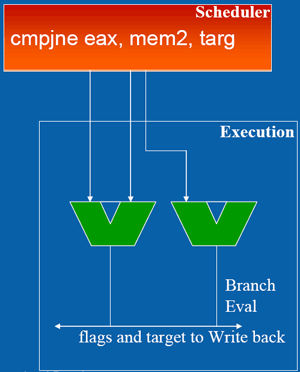 Une unité de calcul améliorée de Core est en charge des micro-opérations issues de la macro-fusion. Il est assez délicat de quantifier le gain de performance apporté par ces mécanismes de fusion. Cela étant, nous avons pu mesurer sur Yonah quen moyenne 10% des instructions sont micro-fusées ce qui réduit dautant le nombre de micro-opérations à traiter. On peut estimer sans trop de risque que lutilisation simultanée de la macro-fusion étend cette proportion à plus de 15%. Page 8 - Gamme & plates-forme Intel Core La gamme Intel CoreComme nous vous lindiquions précédemment, larchitecture Intel Core est commune aux gammes desktop, server et mobile. Dans un premier temps, ce sont les Xeon qui sont servis avec les nouveaux processeurs de la gamme 51xx qui sortent dans les jours à venir : Le TDP des modèles jusquà 2.66 GHz est de 65 Watts, contre 80 Watts pour la version 3 GHz Les processeurs pour PC de bureau, les Core 2 Duo, seront pour leur part lancés officiellement fin juillet dans les déclinaisons suivantes :
 Le X6800 fait partie de la gamme « Extreme Edition » doù un prix assez élevé. On notera dailleurs que son homologue Xeon cadencé à 3 GHz et utilisant un FSB plus élevé est moins cher, ce qui est assez peu cohérent.  Les portables verront enfin le Core 2 Duo débarquer dans le courant de lété : Les prix indiqués ici sont issus du tarif officiel et correspondent aux prix annoncés par Intel pour 1000 pièces. Généralement avec les tarification réduites au délà de ce chiffre, le taux de change et le TVA on arrive à une certaine équivalence (300$ en prix officiel Intel = environ 300 dans le commerce en France). Les plates-formes Intel CoreQuelle que soit la plate-forme pour laquelle ils sont destinés, les processeurs basés sur larchitecture Core utilisent des Socket déjà existant. Côté serveur, il sagit du Socket LGA771 introduit il y a peu avec les Xeon 50xx de type « Dempsey » (dérivé du Presler), alors que pour le desktop et le mobile il sagit des Socket LGA775 et Socket mPGA479M. Attention toutefois, ceci ne veut pas dire que les processeurs sont pour autant compatibles avec les plates-formes existantes. Si côté portables presque toutes les cartes mères supportant le Core Duo devraient être compatibles avec le Core 2 Duo, les cartes mères desktop doivent quant à elles être conformes à la 11è version du VRM (Voltage Regulation Module) dIntel. Du coup, alors que li975X supporte officiellement les Core 2 Duo (dailleurs on peut penser que cest également le cas de tous les autres chipsets FSB1066), les cartes mères i975X vendues depuis septembre 2005 ne sont pas compatibles. Il faut donc sorienter vers de nouvelles révisions, comme la rev.304 de lIntel D975X Bad Axe, ou de nouveaux modèles, comme la P5W DH Deluxe dAsus.  Un moyen relativement simple de sassurer de la compatibilité Core 2 Duo est également de passer directement au P965 Express. Annoncé début juin, ce chipset néquipe que des cartes mères très récentes et qui sont doffice compatibles Core 2 Duo. Par rapport au 975X, il est associé à un ICH8 plus fonctionnel mais le MCH ne peut gérer quun lien de type PCI Express x16 alors que le 975X peut gérer un lien x16 ou deux liens x8 et donc le CrossFire. Le SLI sera pour sa part accessible au travers de la nouvelle gamme nForce 5 de NVIDIA pour Intel, qui sera lancée durant lété. La encore toutes les cartes mères nForce 5 seront doffice compatibles Core 2 Duo, mais on pourra trouver avant des nForce 4 revues et corrigées pour supporter le Core 2 Duo. Page 9 - Les cpu, la mobo, conso et o/c Les processeursPour ce test, nous avons pu mettre la main sur 3 Core 2 Duo pour PC de bureau :
 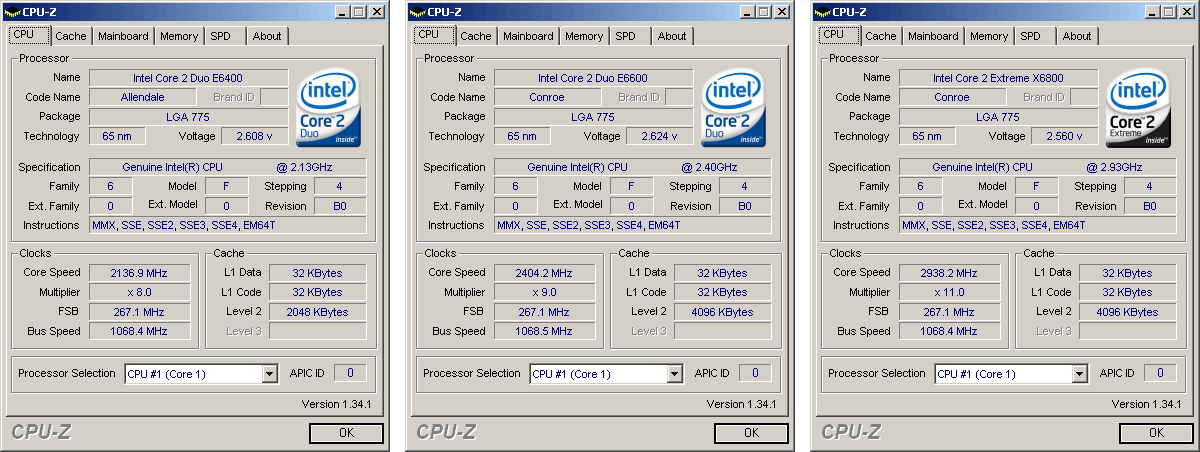 Les trois processeurs sont en révision B0 (stepping 4). Il faut noter que les processeurs commercialisés seront en stepping 6. La carte mère : ASUSTeK P5W DH DeluxeLes tests ont été effectués sur la carte mère i975X + ICH7R ASUSTeK supportant le Core 2 Duo, il sagit de la P5W DH Deluxe. On retrouve les fonctionnalités habituelles implémentées via ce chipset, mais ASUSTeK a bien entendu ajouté des fonctions supplémentaires.  Au niveau stockage tout dabord, lun des ports 4 SATA géré par lICH7R est connecté à une puce Silicon Image 4723 qui splitte ce port en 2. On peut connecter un seul disque sur le premier port, qui pourra être utilisé de manière classique, ou deux afin de les utiliser en RAID 1, RAID 0 ou JBOD. On notera que le réglage de ces deux derniers mode se fait par jumper, le RAID 1 étant celui configuré par défaut, ce qui est pour le moins archaïque. ASUS a également intégré un contrôleur JMicron JMB363 au format PCI Express. Ce dernier gère ici deux Serial ATA (dont un externe) qui peuvent être utilisés en RAID 0 ou 1, ainsi quun port UDMA 100/66/33 supplémentaire qui ne sera pas de trop pour certains utilisateurs, étant donné que lICH7-R nen gère quun. La gestion du réseau est confiée à deux puces Marvel 88E8053. Gérant le réseau Gigabit, elles sont interconnectées au reste du système via le PCI Express. Le WiFi est également de la partie puisque la carte intègre une puce WiFi 802.11a/b/g Realtek RTL8187L empruntant le bus USB. LHD Audio est confié à une puce Realtek ALC882M et la carte est conforme aux spécifications Dolby Master Studio, et le FireWire est également de la partie via un contrôleur Texas Instrument. On notera la présence dune télécommande infrarouge permettant notamment dallumer ou déteindre lordinateur, de le mettre en veille ou en mode silencieux ou encore de contrôler le son ou lavancement dune vidéo. La consommationAvant toute chose nous allons nous intéresser à la consommation de ces processeurs. Le Core 2 Duo étant dérivé dune architecture Mobile, il possède les bases nécessaires à une architecture économe en énergie. Procédé de fabrication, utilisation de transistors à faible perte de charge, les Core 2 Duo bénéficient des derniers procédés de fabrication destinés à réduire la dissipation au niveau électronique. Le SpeedStep est bien entendu implémenté, et a, selon Intel, été amélioré afin dobtenir une réduction des temps de transition. Une nouvelle méthode de gestion de l´énergie existe sur le Core 2 Duo, qui permet au processeur de gérer de façon précise sa consommation même en charge, lUltra Fine Grained Power Control, qui consiste en un découpage très fin des zones susceptibles dêtre mises en sommeil. Ce faisant, les unités non sollicitées restent en mode veille, alors même que dautres tournent à plein régime. Ce qui se produit souvent, car rares sont les cas où toutes les unités du processeur sont requises en même temps. Cette gestion ultra précise permet une meilleure maîtrise de la consommation, et par là-même du dégagement thermique. La dernière innovation de l´architecture Core visant à réduire la consommation du processeur réside dans la capacité de ses bus dadresse et des données à sadapter à la largeur des données qui les traversent. Ainsi, si seulement 64 bits doivent transiter, seule la moitié du bus 128 bits concerné est activée. Quen est-il en pratique ? Nous rapportons ici la consommation totale de la configuration en charge sous Prime95, logiciel lancé autant de fois quil y a de core étant donné quil ne gère pas le multi thread. Dans le cas des Athlon 64 X2 et FX, les mesures ont été faites sur M2N32-SLI Deluxe en AM2 : 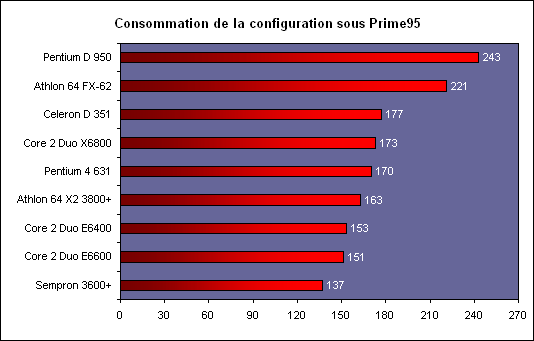 Les résultats sont très bons puisque les Core 2 Duo E6600 et E6400 sont moins gourmands quun Athlon 64 X2 3800+. Bizarrement, notre E6400 consommait dailleurs plus que notre E6600, pourtant la tension était identique soit 1.3V. Le Core 2 Duo X6800 est également assez économe puisque se situant à peine au dessus dun Pentium 4 631 à 3 GHz avec des performances qui nont bien entendu pas grand-chose à voir. On est loin de ce que consomme le FX-62 et surtout le Pentium D 950 (ici en stepping B1). Gravé en 90nm, le Celeron représenté ici consomme plus que le Pentium 4 631 gravé en 65nm. OverclockingQuid de loverclocking ? Certes, nos processeurs ne sont « que » des stepping 4, mais nous avons tout de même voulu voir ce quil en était. Pour ce faire nous nous sommes limités au refroidissement à air, en loccurrence avec un ventirad Intel classique fourni avec les Pentium 4 & D. La température ambiante était de 31°C pour ces tests et nous nous sommes limités à une augmentation de +0,1V des tensions. Sont ici considérés comme réussis les overclockings validés sous 2 Prime95 pendant 15 minutes. 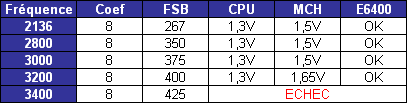 LE6400 monte à 3.2 GHz, toutefois à cette fréquence le FSB est de 400 MHz au niveau de lICH7 et il a fallu augmenter sa tension dalimentation à 1,65V. 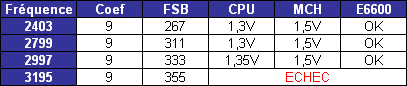 Notre E6600 sest avéré moins bon puisque cette fois les 3.2 GHz nont pas pu être atteints de manière stable, et ce même avec une tension de 1.4V. 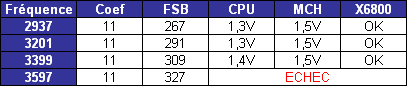 Enfin, le X6800 était le plus overclockable avec 3.4 GHz stables à 1.4V. Il nous faut une nouvelle fois préciser que ces overclockings ne sont valables que pour les Core 2 Duo de stepping 4, les stepping 5 dépassant apparemment aisément les 3.4 voir même 3.6 GHz en air cooling. Partir dun processeur trop bas nécessitera donc un FSB élevé par forcément supporté par toutes les cartes mères, par exemple pour 3.6 GHz un E6400 nécessitera un FSB de 450 MHz. En effet côté coefficient, on peut descendre par pas de 1 jusqu´à 6 quelque soit le CPU grâce à lEIST, par contre nous navons pas pu aller au delà du coef. de base, même sur le X6800.  Overclocking Step 5Peu de temps après la publication de larticle, nous avons pu mettre la main sur un Core 2 Duo E6600 de stepping 5 afin de voir quel était le potentiel doverclocking de ce processeur, toujours dans les mêmes conditions : 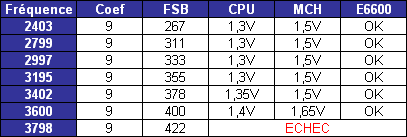 Cette fois les 3.4 GHz sont tenus dès 1.35V, contre 1.4V sur le X6800 step 4. On atteint même 3.6 GHz en 1.4V. Pour aller au delà, il faudra encore augmenter la tension et le processeur commence à dissiper beaucoup dénergie, des solutions telles que le watercooling ne seront pas de trop.  Viser une fréquence comprise entre 3.4 et 3.6 GHz semble donc tout à fait raisonnable pour un Core 2 Duo stepping 5. Performances à 3.6 GHzQuelles sont les performances dun Core 2 Duo overclocké à 3.6 GHz en 9x400, le tout couplé avec de la DDR2-800 en 4-4-4-12 ? Cest ce que nous avons voulu vérifier, et voici les chiffres, comparés notamment à un X6800 en DDR2-800 : 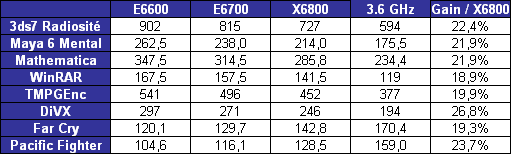 Avec une hausse de fréquence de 22.7%, on a en toute logique des gains proches de ce chiffre, et même parfois supérieurs, du fait de limpact dun FSB plus important sur certains de nos tests. Page 10 - Influence L2, DDR2, FSB Influence du cache L2Avant toute chose nous avons voulu voir quels étaient les gains apportés par 4 Mo de cache L2 unifié par rapport à 2 Mo. Pour ce faire, nous avons comparé un Conroe (4 Mo) et un Allendale (2 Mo) cadencés tous deux à 2.13 GHz : 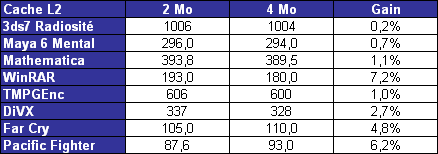 Comme dhabitude, les gains sont très variables selon les applications. On atteint ainsi 7,2% sous WinRAR, 6,2% sous Pacific Fighters et 4,8% sous Far Cry ce qui est appréciable. Mais il y a aussi des applications dans lesquelles les gains ne sont que de 1%, voire moins, avec par exemple 0,2% seulement sous 3ds max. Ces gains sont relativement comparables à ceux obtenus par le passage de 512 Ko à 1 Mo de cache par coeur sur Athlon 64 X2. Influence fréquence et timings DDR2Quelle est linfluence de la DDR2 sur le Core 2 Duo ? Etant donné que Intel a encore amélioré son prefetch hardware afin de limiter les pénalités liées à laccès à la mémoire, on peut penser que limpact sera réduit, cest ce que nous avons voulu vérifier. Pour ce faire nous avons mesuré les performances dans 4 domaines. Nous nous sommes tout dabord concentrés, avec ScienceMark, sur un test de bande passante en lecture et un test de latence. Ces résultats sont respectivement exprimés en Mo /s et en nombre de cycles. Enfin, deux tests applicatifs viennent compléter ceux-ci, à savoir WinRAR et Far Cry, qui sont particulièrement dépendants de la vitesse du sous-système mémoire. 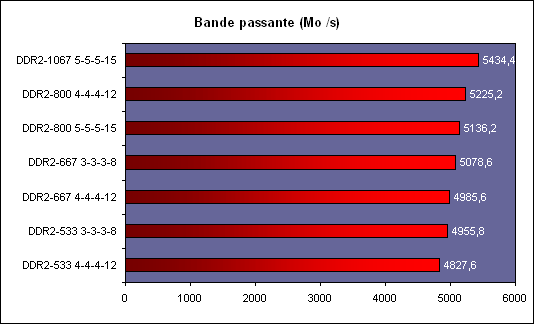 Avec un FSB1066, la bande passante maximale théorique du bus est de 8533 Mo /s. Même si ces valeurs ne sont pas atteintes ici en pratique, il est certain que ceci est limitatif pour des mémoires telles que la DDR2-1066 qui offrent en dual channel jusquà deux fois 8.5 Go /s de bande passante. Cela nempêche pas la DDR2-1066 dapporter un gain en bande passante, lécart étant de 12% par rapport au moins bon réglage, soit DDR2-533 en 4-4-4-12. 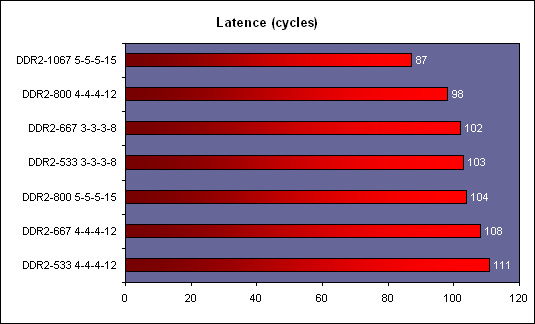 Côté latences, on note un écart assez important entre la DDR2-1067 et dautres types de mémoire. On peut penser que ceci est lié à l´asynchronisme entre la fréquence du FSB et celui du bus mémoire dans les modes DDR2-667 et DDR2-800 alors quen DDR2-1067, le bus mémoire fonctionne pile à deux fois la fréquence du FSB. 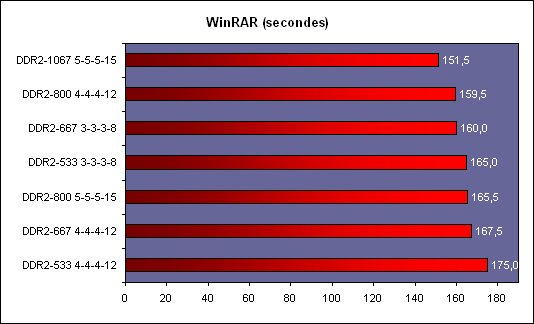 Nous passons maintenant à des résultats plus « pratiques » avec pour commencer un temps de compression sous WinRAR. Comme vous pouvez le voir, la DDR2-1067 en CL5 est ici 15% plus véloce que la DDR2-533 en CL4. DDR2-667 CL4, DDR2-800 CL5 et DDR2-533 CL3 sont pour leur part assez proches. 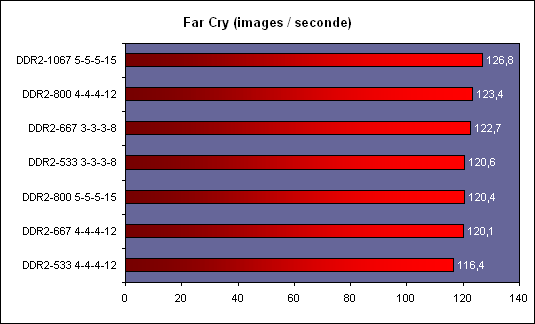 Sous Far Cry lécart se réduit puisque lavantage à la DDR2-1067 nest plus que de 8,9%. Là encore les performances du trio DDR2-667 CL4, DDR2-800 CL5 et DDR2-533 CL3 sont très proches. Quen est-il du comportement du Core 2 Duo face à la DDR2 par rapport à celui dAMD ? Pour ce faire nous avons comparé limpact des timings et de la fréquence sur les deux plates-formes. Nous indiquons ici le % de performance atteint par rapport au meilleur réglage : 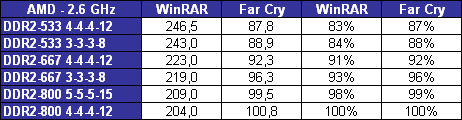 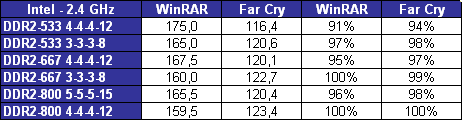 Les résultats parle deux-mêmes, sur AM2 la DDR2-533 CL4 noffrent que 83% et 87% des performances de la DDR2-800 CL4 alors quavec le Core 2 Duo on grimpe à 91% et 94%. Le Core 2 Duo est impacté par une mémoire moins rapide dans des proportions deux fois moins importantes quun Athlon 64 X2. Influence du FSBNous avons également voulu regarder ce quil en était de linfluence du FSB sur les performances du Core 2 Duo. Pour ce faire, nous avons effectué une série de test toujours à 2.4 GHz mais dune part en 9x266 et dautre part en 7x342 MHz. 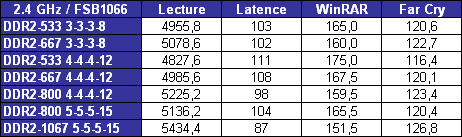 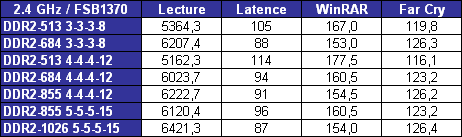  La première chose que lon remarque cest la bande passante mémoire qui augmente fortement et qui profite mieux de laugmentation de la fréquence DDR : le FSB limitait donc cette dernière dans le test précédent. Toutefois, en FSB1370 la DDR2-1026 CL5 se situe au final à un niveau comparable à de la DDR2-684 en CL3, du fait de laction combinée de la fréquence et du léger coup de pouce lié au synchronisme. En FSB1600 les choix ne sont pas très variés : DDR2-600, 800, 1000, 1066, 1200, etc. ... Mais au dessus de DDR2-800 la carte mère ne boote bizarrement plus. Le réglage le plus rapide est ici la DDR2-800 en 4-4-4, et on obtient de meilleures performances que la DDR2-855 4-4-4 en FSB1370 du fait du synchronisme. Reste que dans labsolu le FSB ne joue pas beaucoup sur les performances et quon naura donc pas forcément un grand intérêt à abaisser le coefficient pour laugmenter. Plus quune vitesse de FSB et DDR les plus élevées possibles, on cherchera donc afin davoir des performances optimales à trouver un réglage combinant FSB élevé, timings agressifs et DDR fonctionnant à 1x ou 2x la vitesse du FSB. Dans tous les cas en dehors de quelques réglages les performances sont relativement proches. Page 11 - Windows x64 & EM64T, le test Windows x64 & EM64TIntroduit par AMD en 2003, lAMD64 ISA tarde à faire son chemin sur le marché des PC de bureau. Pour rappel, il sagit dune une extension aux 64 bits du jeu dinstruction x86. Ainsi, les registres généraux, des petites zones mémoires qui stockent de manière temporaire les adresses mémoires et les entiers, passent de 32 à 64 bits. Intel propose depuis début 2005 une fonction comparable et compatible, lEM64T, mais cette fonction nétait disponible que sur Netburst et pas sur Mobile. Avec Core, lEM64T est étendue à toutes les plates-forme. Le fait de traiter des données 64 bits nest pas en soit une nouveauté. Ainsi, depuis son introduction, le x87 qui se charge des calculs en virgule flottante va jusquà travailler en 80 bits en interne. De plus, certaines instructions MMX/SSE/SSE2 permettaient également de travailler sur des entiers 64 bits. Toutefois lusage de ce type de donnée est désormais généralisé à toutes les données stockées dans les GPR ce qui procure deux avantages :
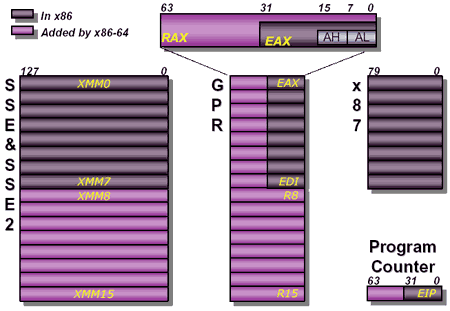 En fait le principal intérêt de lEM64T comme de lAMD64, cest le nombre de registres. En effet, en mode x86, les processeurs disposent de 8 registres x87 80 bits, de 8 registres généraux 32 bits et de 8 registres SSE 128 bits. Avec lAMD64 et lEM64T, on reste à 8 registres x87 80 bits, par contre on passe à 16 registres généraux 64 bits et 16 registres SSE 128 bits. Laugmentation du nombre de registres disponibles permet de limiter le nombre dinstructions destinées à libérer ces derniers et à les copier en mémoire, et donc daugmenter les performances. Enfin, larrivée de lEM64T et de lAMD64 permet de faire une rupture avec la sacro sainte compatibilité x86. De nombreux exécutables sont encore compilés de manière à être compatible avec le jeu dinstruction x86 tel quil était avec le 386. Il a connu des améliorations depuis, qui ne sont pas forcément utilisées par les développeurs lors de la compilation. Désormais, la question ne se posera plus.  Quels sont les gains de performances en pratique ? Pour le savoir, nous avons installé Windows XP x64 sur un Core 2 Duo E6600, un Pentium D 950 et un Athlon FX-60 et avons testé trois logiciels en 32 bits et en 64 bits : Mathematica 5.2 (calculs scientifiques), CineBench 9.5 (rendu 3d) et Far Cry (jeu). 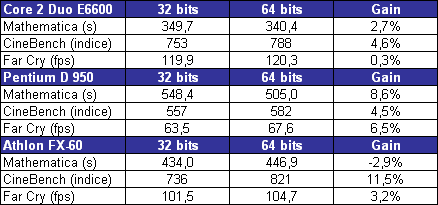 Sous Mathematica, les performances sont très variables puisque lon gagne 2.7% sur Core, 8.6% sur Netburst que sur K8 la vitesse est réduite de 2.9%. Cinebench est plus à lavantage dAMD avec un gain de 11.5% sur la vitesse de rendu, contre 8.6% sur Pentium D et 4.6% sur Core 2 Duo. Cest enfin sur Pentium D que Far Cry profite le plus du 64 bits avec 6.5% de mieux, contre 3.2% de plus sur Athlon 64 FX et 0.3% (!) sur Core. Les performances sont donc très variables dun processeur à lautre et dun logiciel à lautre, et on observe même dans un cas une baisse des performances. Globalement et ironiquement cest le Pentium 4 qui offre les gains les plus homogènes, ceci pouvant sexpliquer du fait de la présence du Trace Cache qui stocke les instructions telles quelles sont décodées. Au contraire dans une architecture plus classique telle que le Core ou le K8 les instructions sont stockées avant le décodage dans le L1I, alors que lAMD64 et lEM64T impacte négative les performances du décodage puisque ces instructions sont codées sur plus d´octets que les instructions x86 classiques, ce qui augmente la charge au niveau du décodage. Dailleurs, il semblerait que sur Core 2 Duo beaucoup de cas de fusions ne sont pas activés en 64 bits. Bien entendu cette charge sur les décodeurs est généralement compensée par la diminution du nombre total d´instructions en 64 bits, mais au final les gains de performances peuvent donc varier dune architecture à une autre. En loccurrence, Core semble moins tirer avantage que les autres architectures du 64 bits, mais dans tous les cas étant donné ses performances 32 bits et les gains globalement faibles offert par le 64 bits quelque soit larchitecture cela na rien de dramatique. Les configurations de testAprès ces tests spécifiques nous avons bien entendu fait passer aux Core 2 Duo notre suite de tests habituelle. Pour toutes les configurations DDR2, nous avons utilisés de la DDR2-667 4-4-4-12, mais également de la DDR2-800 4-4-4-12 pour les solutions les plus haut de gamme en AM2 et Core 2 Duo. Les configurations utilisées étaient les suivantes : Commun : - ATI Radeon X850 XT PE - 2 x Raptor 74 Go - Windows XP SP2 Français Intel Socket 775 Core 2 Duo : - Carte mère ASUSTeK P5W DH (i975X) - 2 x 512 Mo DDR2-667 4-4-4 - 2 x 512 Mo DDR2-800 4-4-4 Intel Socket 775 : - Carte mère ASUSTeK P5WD2-E (i975X) - 2 x 512 Mo DDR2-667 4-4-4 Intel Socket mPGA479 : - Carte mère Gigabyte GA-I8I945GTMF-YRH - 2 x 512 Mo DDR2-667 4-4-4 AMD Socket AM2 : - Carte mère ASUS M2N32-SLI Deluxe - 2 x 512 Mo DDR2-667 4-4-4 - 2 x 512 Mo DDR2-800 4-4-4 AMD Socket 939 : - Carte mère ASUS A8N SLI Premium - 2 x 512 Mo DDR-400 2-2-2 Page 12 - 3ds Max & Maya 3d Studio Max 7Pour 3d studio max, nous effectuons le rendu via le moteur de rendu interne de 3ds (scanline) dune scène mise au point par Studio PC qui fait fortement appel à la radiosité. Ce type de rendu plus réaliste au niveau des éclairages est aussi plus lent, et 80% du temps de rendu est passé sur ce type deffet au sein de cette scène. 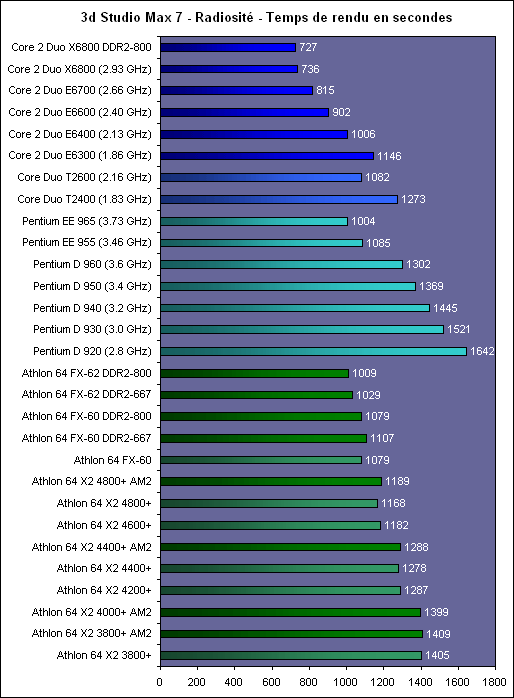 Le Core 2 Duo commence déjà à montrer toute sa puissance, puisquil arrive au niveau des Pentium et Athlon 64 FX les plus rapides, et ce dès le E6400. Bien entendu au delà ce nest que du bonus, et au final la configuration Core 2 Duo la plus performante est de fait 38% plus rapide que les solutions AMD et Intel existantes ! Par rapport au Core Duo, le Core 2 Duo apporte un gain denviron 8-10% à fréquence égale. >Voir les performances des CPU mono core sous ce test Maya 6Nous utilisons une scène mise au point par Yann Dupont de 3DVF que nous remercions, rendue via Mental Ray. 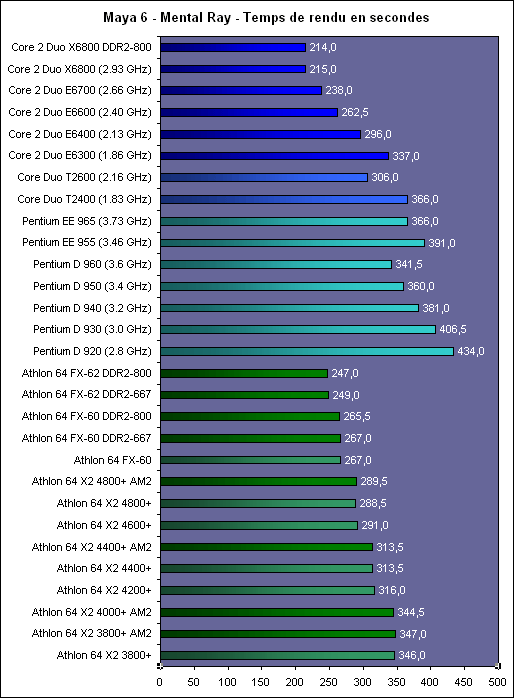 LHyperThreading sur dual core impactant négativement les performances sous Maya, du côté des Pentium cest ici la version 960 qui est en tête. Mais le Core 2 Duo est nettement plus performant puisquil est devant dès sa version E6300 à seulement 1.86 GHz. La résistance est plus forte que sous 3ds du côté dAMD puisquil faut un E6700 pour atteindre les performances dun FX-62 ... mais le Core 2 Duo est annoncé comme deux fois moins cher que ce FX ! Lavantage du X6800 est de 71% comparé au Pentium EE 965, et de 15.4% comparé au FX-62. >Voir les performances des CPU mono core sous ce test Page 13 - Mathematica & WinRAR Mathematica 5.2Voici venue lheure des calculs scientifiques, avec Mathematica 5.2 de Wolfram Research et la suite de tests développée par Stefan Steinhaus. 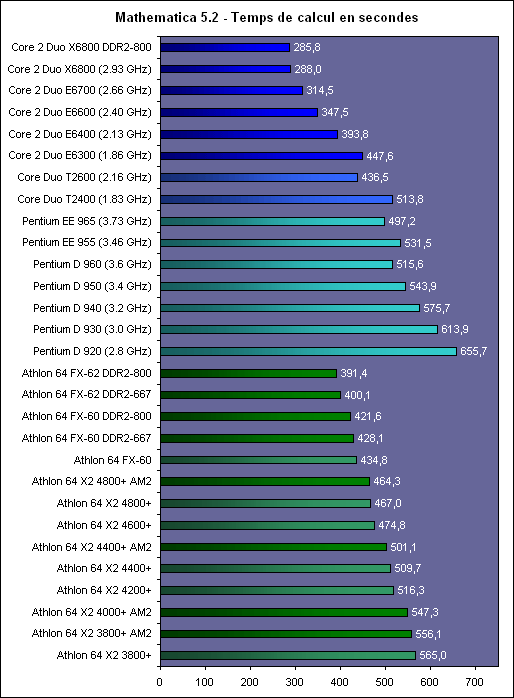 Le Core 2 Duo offre clairement des performances de « nouvelle génération ». Un simple E6400 suffit à atteindre le niveau dun FX-62, et même le E6300 est nettement plus rapide quun PEE 965. Du coup, le X6800 est au final 36,9% plus véloce que son homologue AMD et 74% plus véloce que son ancêtre basé sur Netburst. Par rapport au Core 2 Duo les gains sont denviron 14% à fréquence égale. >Voir les performances des CPU mono core sous ce test WinRAR 3.51Un total de 588 Mo de fichiers, répartis en 493 fichiers Word & Excel (69 Mo), 22 fichiers de boite e-mail Eudora (251 Mo) et 1 fichier audio au format wav (268 Mo), sont compressés via WinRAR 3.51 en utilisant la compression la plus poussée. 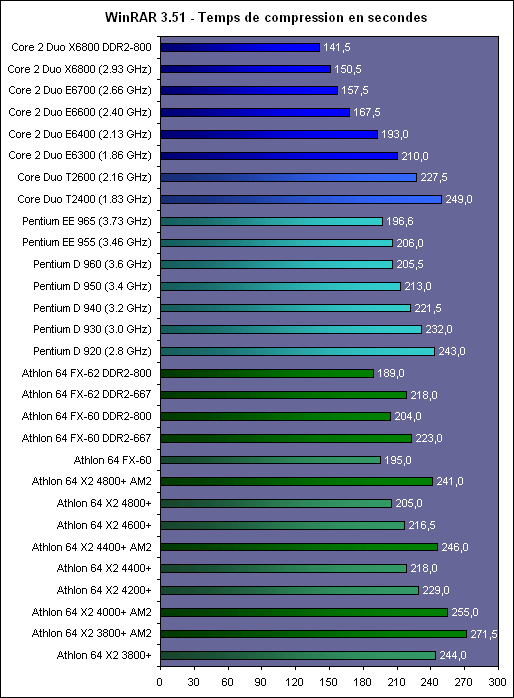 On commence à se répéter mais une nouvelle fois le Core 2 Duo affiche des performances de tout premier ordre puisquun E6400 atteint des performances comparables à celles des FX-62/P EE 965. LAllendale est environ 18% plus rapide que le Yonah à fréquence égale, et au final le X6800 a un avantage de 38,9% sur lancien haut de gamme Intel et 33,6% sur le haut de gamme AMD. >Voir les performances des CPU mono core sous ce test Page 14 - TMPGEnc & Vdub / DiVX 6 TMPGEnc 3.3 XpressSous TMPGEnc 3.3.3.7, nous encodons un fichier DV de 10 minutes et 16 secondes au format MPEG-2, en 720x576 avec un bitrate moyen de 4500 kbits /s et en 2 passes. Laffichage de la vidéo en mode preview est activé pendant ce test et le décodage du fichier DV se fait via un codec Mainconcept, qui est plus rapide que le décodage intégré à TMPGEnc. 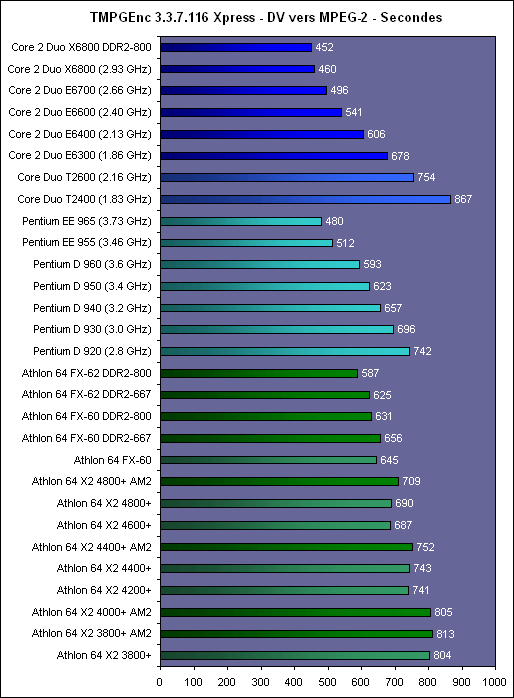 Pour la première fois lavantage du Core 2 Duo est bien moins évident par rapport aux processeurs darchitecture Netbust. Ainsi, le Pentium EE 965 parvient à des performances comprises entre un E6700 et un X6800, ce qui est tout à fait honorable, et lavantage du X6800 sur prédécesseur nest « que » de 6.2%. Par rapport à AMD le trou est par contre toujours aussi important puisque de 29.9% par rapport au FX-62, ce dernier offrant des performances comprises entre E6600 et E6400. Larchitecture Core est ici 25% plus performante que Mobile, preuve que les améliorations apportées au niveau SSE portent leurs fruits. >Voir les performances des CPU mono core sous ce test VirtualDub 6.11 + DiVX 6Nous compressons la même vidéo que sous TMPGEnc en mode Fast recompress et via le codec DiVX 6.1 en une passe avec un bitrate moyen de 1500 kbits /s, b-frame et performance dencodage meilleure qualité. Laffichage de la vidéo en mode preview est activé pendant ce test. 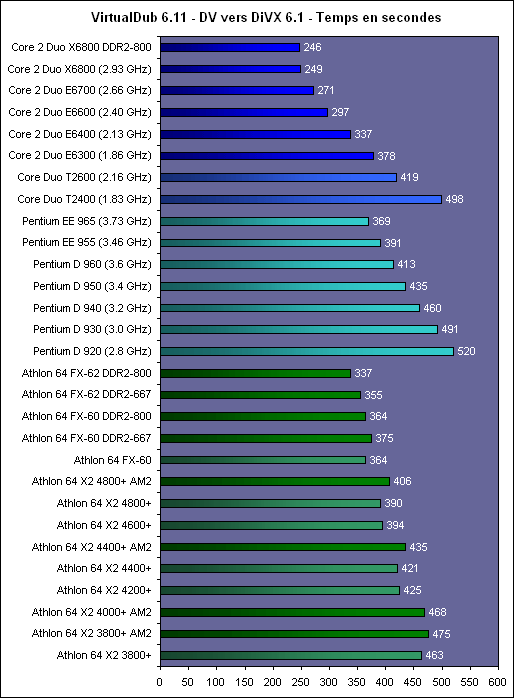 Là encore le gain par rapport à Mobile est de 25% à 2.1x GHz, et même 30% à 1.8x GHz. Les performances atteignent de fait des sommets avec un X6800 50% plus rapide quun Pentium EE 965 et 37% au dessus dun FX-62. Le EE 965 nest du coup que légèrement au dessus dun simple Core 2 Duo E6300 alors que le E6400 fait match égal avec le FX-62. >Voir les performances des CPU mono core sous ce test Page 15 - Far Cry & Pacific Fighters Far CryVoici nos résultats sous Far Cry, sur une scène de test constituée dun parcours sur la map training en extérieur. 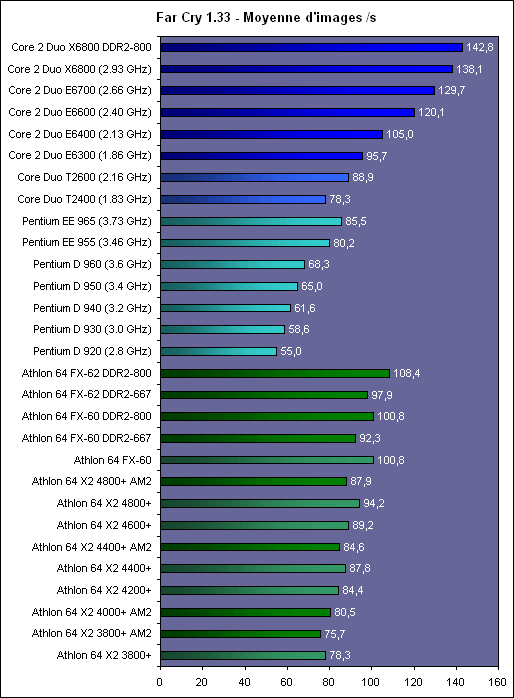 LE6300 parvient ici à faire mieux que le Pentium EE 965, alors que le FX-62 nest quun peu plus rapide quun E6400. Du coup le X6800 met un vent à ses adversaires puisquil est respectivement 67% et 31,7% plus rapide que lancienne solution haut de gamme Intel et que la solution haut de gamme AMD. >Voir les performances des CPU mono core sous ce test Pacific Fighters 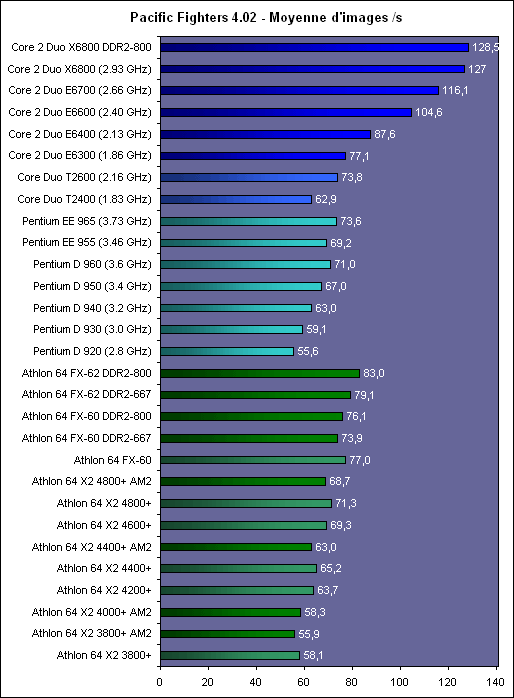 Sous Pacific Fighters lE6300 est de nouveau plus rapide que le Pentium EE 965 alors que le FX-62 se retrouve pris en sandwich entre E6300 et E6400. Le X6800 est donc de nouveau bien plus rapide que ses compères : 74,6% de mieux quun EE 965 et 54,8% de mieux quun FX-62 ! >Voir les performances des CPU mono core sous ce test A propos des tests dans les jeuxBien entendu nous effectuons ici des tests en basse résolution afin de voir quels sont les performances absolues du processeur, en tenant compte au minimum de linfluence que pourrait avoir un facteur limitant tel que pourrait lêtre de la carte graphique. Selon cette carte, selon le jeu utilisé, selon la scène utilisée au sein du jeu et selon la résolution graphique utilisée, les processeur pourra plus ou moins attendre la carte graphique, ou linverse. Les combinaisons sont infinies et cest pour cette raison que nous avons pour leitmotiv de faire nos tests processeurs dans le but de savoir quel sera le processeur le plus rapide, et dans quelle proportion, dans le cas ou cest lui et uniquement lui qui limiterait les performances. En effet le niveau de limitation liée à la carte graphique que lon pourrait introduire dans un test en testant en dans une plus haute résolution ne serait pas forcément représentatif puisquil ne sagirait que de modifier une fois un des paramètres de la combinaison. De plus étant donné que les chiffres sont, afin de garantir une certaine stabilité de la mesure, une moyenne de framerate sur une période de 1 à 2 minutes, cette limitation lissant en moyenne les performances pourrait masquer des écarts qui resteraient important à un moment X où les performances resteraient limitées par le processeur (explosion par exemple). Si vous voulez savoir sur votre configuration, dans vos jeux, dans vos passages préférés, avec vos réglages, qui de votre carte graphique ou de votre cpu fait que vous navez pas la fluidité attendue, nous vous conseillons un test simple : baissez la résolution à 800*600 voir 640*480 ! Si vous nobservez pas de gain notable de fluidité, vous êtes limité par le CPU, sinon cest la carte graphique qui vous limite. Page 16 - Conclusion Conclusion  Avec Core, Intel nous propose une architecture qui est tout le contraire de ce quétait le Netburst en son temps. Alors que le Netburst remettait en cause de nombreux principes et était très innovant, à tort ou à raison, Core est une sorte de pot-pourri, reprenant à son compte le meilleur des technologies existantes et les améliorant. Alors que Netburst noffrait pas vraiment davantage en pratique à sa sortie, Core est dès son lancement pleinement opérationnel. Avec Core, Intel nous propose une architecture qui est tout le contraire de ce quétait le Netburst en son temps. Alors que le Netburst remettait en cause de nombreux principes et était très innovant, à tort ou à raison, Core est une sorte de pot-pourri, reprenant à son compte le meilleur des technologies existantes et les améliorant. Alors que Netburst noffrait pas vraiment davantage en pratique à sa sortie, Core est dès son lancement pleinement opérationnel.Au vu des résultats obtenus en pratique on a tendance à donner raison à Intel sur les choix effectués, au moins à court et moyen terme. En effet, le Core 2 Duo est tout bonnement un processeur dexception ! Par exemple, un simple E6400 affiché à 224$ offre un niveau de performance comparable à un Athlon 64 FX-62 à 1031$, tout en consommant moins quun Athlon 64 X2 3800+ et en offrant une marge doverclocking confortable. Dès lE6600, AMD ne peut plus lutter en terme de performances, sauf sous Maya ou le FX-62 parvient à faire mieux, mais bon ... Quelles sont les armes à la disposition dAMD afin de tenter de freiner la déferlante Core 2 Duo ? Etant donné que la prochaine architecture du père des Athlon ne verra pas le jour avant lannée prochaine, il ny en a quune : les prix ! Le fondeur appliquera ainsi une première baisse sur gamme le 24 juillets prochain, mais celle-ci semble bien insuffisante puisque cest le 4200+ qui sera placé par exemple en face du E6400 (240$ vs 224$) alors que le 4600+ sera à un prix proche du E6600 (301$ vs 316$). Mais dun autre côté on voit mal AMD placer son A64 5000+ à ce tarif, dautant quil est pour le moment limité à une gravure en 90nm.  Reste à savoir quelle est la marge dévolution de Core. Côté fréquence, certes le dernier stepping 5 des Core 2 Duo permet de dépasser facilement les 3.4 voir 3.6 GHz en refroidissement à air, mais on peut penser quon atteindra rapidement les limites découlant dun pipeline court. Lautre solution, favorisée par une dissipation réduite de ces CPU, cest laugmentation du nombre de cores. Le Kentsfield, composé de deux die Conroe intégrés au même packaging devrait être lancé début 2007, les échantillons de test étant déjà disponibles et pleinement fonctionnels. Mais que penser dun Quad Core alors que lon attend encore que certains types de logiciels, tels les jeux, tirent vraiment partie du dual ? Cest certainement une des raisons pour lesquelles Intel attend 2007, mais il nest pas dit que la situation sera nettement plus favorable à cette date. Reste à savoir quelle est la marge dévolution de Core. Côté fréquence, certes le dernier stepping 5 des Core 2 Duo permet de dépasser facilement les 3.4 voir 3.6 GHz en refroidissement à air, mais on peut penser quon atteindra rapidement les limites découlant dun pipeline court. Lautre solution, favorisée par une dissipation réduite de ces CPU, cest laugmentation du nombre de cores. Le Kentsfield, composé de deux die Conroe intégrés au même packaging devrait être lancé début 2007, les échantillons de test étant déjà disponibles et pleinement fonctionnels. Mais que penser dun Quad Core alors que lon attend encore que certains types de logiciels, tels les jeux, tirent vraiment partie du dual ? Cest certainement une des raisons pour lesquelles Intel attend 2007, mais il nest pas dit que la situation sera nettement plus favorable à cette date.Dans tous les cas, Intel ne compte pas sur le Core sur le long terme, puisquil a déjà annoncé une nouvelle architecture pour 2008, Nehalem, et une autre pour 2010, Gesher. En attendant, cest bien Core qui devrait être disponible fin juillet sur tous les étalages et à la vue des performances offertes, on aurait tort de sen priver ! Copyright © 1997-2025 HardWare.fr. Tous droits réservés. |