| |
| |
| Intel Core i7 et Core i5 LGA 1155 Sandy Bridge Processeurs Publié le Lundi 3 Janvier 2011 par Damien Triolet, Franck Delattre, Guillaume Louel et Marc Prieur URL: /articles/815-1/intel-core-i7-core-i5-lga-1155-sandy-bridge.html Page 1 - L'architecture Sandy Bridge En novembre 2008, Intel introduisait ses premiers processeurs basés sur sa nouvelle architecture Nehalem, les Core i7 LGA 1366. Après avoir été déclinée sur Socket LGA 1156 en septembre 2009, Nehalem fut ensuite déclinée en versions dual core et hexa core 32nm en janvier et mars 2010. Après plus de deux ans de bons et loyaux services, larchitecture Nehalem laisse aujourdhui place à Sandy Bridge. L'architecture Sandy Bridge 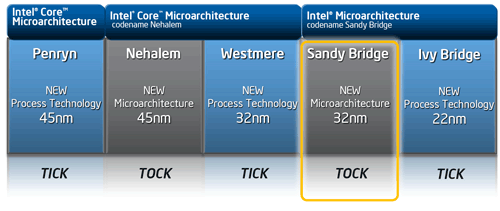 Sandy Bridge est le nom de code donné par Intel à sa nouvelle architecture et aux processeurs lutilisant. Cette nouvelle génération est un « tock », dans le langage Intel cela désigne une nouvelle architecture utilisant un process de fabrication déjà utilisé précédemment. Les Sandy Bridge sont donc fabriqués en 32 nanomètres, à limage de Westmere, déclinaison 32nm de larchitecture Nehalem. En version quad core, ils disposent d'un die de 216mm² comprenant 995 millions de transistors, contre 296mm² et 774 millions de transistors pour un quad core Lynnfield LGA1156 45nm. 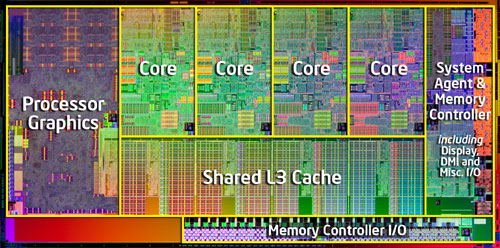 Parmi les nouveautés introduites par les processeurs Sandy Bridge, les plus notables sont : - Un nouveau Socket LGA 1155 - Un IGP intégré partageant le cache L3, désormais appelé LLC (Last Level Cache) - Une amélioration de lIPC et des performances par watt - Un nouveau jeu dinstruction AVX (Advanced Vector Extension) - Une nouvelle version du Turbo Boost Hormis ces caractéristiques qui distinguent Sandy Bridge de son prédécesseur, celui-ci conserve les choix technologiques introduits ou réintroduits durant Nehalem, à savoir : - Le contrôleur mémoire DDR3 intégré (double canal et DDR3-1333) - Le contrôleur PCI-Express intégré (2 fois 8 lignes PCI-E 2.0) - LHyper-Threading - Une architecture de cache à trois niveaux Les premiers modèles de Sandy Bridge débarquent dès ce mois, avec pas moins de 29 modèles desktop et mobiles confondus, équipés de deux ou quatre curs. Seuls les modèles quatres curs seront disponibles dès le 9 janvier, il faudra en effet patienter jusquau 20 février pour voir débarquer les versions deux curs. La sortie de ces processeurs est accompagnée de 10 nouveaux modèles de chipset capables de les gérer, dont les P67 et H67, nom de code "Cougar Point". Page 2 - Les améliorations du core Les améliorations du core Sandy BridgeSandy Bridge repose principalement sur l'architecture Nehalem, mais apporte son lot d'améliorations, dont certaines sont reprises de la micro-architecture Netburst du Pentium 4. Netburst a eu cela de bénéfique de ne pas reposer sur une architecture existante, et son étude a ainsi pu déboucher sur une multitude de concepts inédits dans le monde du x86. L'Hyper-Threading réapparu avec Nehalem est l'une d'elles, et la micro-architecture Sandy Bridge remet également au goût du jour certaines "innovations" de Netburst. Un cache "L0"Lors de notre étude de l'architecture Nehalem, nous avons vu que ce processeur inclut un mécanisme de gestion optimisé des boucles qui repose sur un buffer contenant les micro-opérations (c'est-à-dire les instructions déjà décodées), évitant ainsi de décoder plusieurs fois le même code d'une boucle lorsque celle-ci est correctement prédite. Nous avions d'ailleurs évoqué la ressemblance avec le principe du trace cache du Pentium 4. 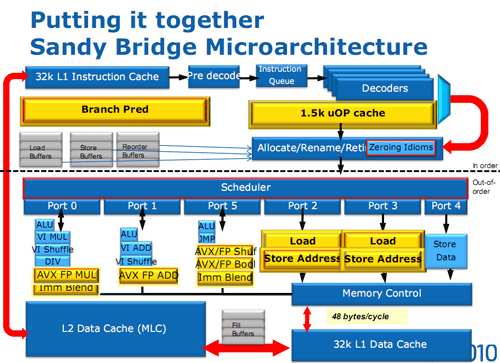 Sandy Bridge va un cran plus loin en introduisant un cache de micro-opérations (uop cache) de 1,5 Ko, recevant ses données des unités de décodage des instructions. L'unité de branchement y accède dès lors qu'une nouvelle branche est prédite et en cas de succès, la majeure partie du traitement "front end" (de la récupération des instructions au décodage) devient inutile. Cela résulte en une utilisation moindre des unités du front end, et au final une amélioration sensible du niveau de performance par watt consommé. A noter que le uop cache du Sandy Bridge n'est pas véritablement comparable au trace cache du Pentium 4 : en effet le Sandy Bridge conserve son cache L1 dédié aux instructions et les deux caches fonctionnent de concert ; au contraire du Pentium 4 dont le trace cache se substituait intégralement au L1I et était donc d'un fonctionnement plus complexe. Une gestion des registres inspirée du Pentium 4Pour Sandy Bridge, les ingénieurs d'Intel ont choisi d'utiliser un fichier de registres physiques (PRF ou Physical Register File) comme c'était le cas sur le Pentium 4. Pour comprendre en quoi cela consiste exactement et les motivations de ce choix, il faut rappeler quelques concepts inhérents à la gestion des registres par un processeur x86. Les processeurs x86 se caractérisent par un faible nombre de registres : 8 en mode 32-bits, et 16 en mode 64-bits (à titre de comparaison, un processeur IA64 comme l'Itanium en possède 128). Ce sont les fameux registres eax, ebx, familiers pour qui a déjà vu du code assembleur x86, et qui constituent le fichier de registres (register file en anglais). Or, les processeurs modernes utilisent des moteurs d'exécution out-of-order (OOO), c'est-à-dire capables de traiter les instructions dans un ordre différent de celui du code assembleur écrit par le programmeur ou généré par un compilateur. Afin de faciliter le travail de l'OOO, les processeurs possèdent en interne bien plus de 8 registres, et ont donc recours au renommage de registres (register renaming) pour maintenir la cohérence entre les registres physiques du processeur (internes, et non visibles par les programmeurs), et les registres architecturaux (ceux exploitables par le programmeur : eax, ebx ) auxquels ils font référence.  En pratique, le processeur a recours à un buffer de réordonnancement des instructions, appelé Reorder Buffer ou ROB, dont la fonction est de restaurer l'ordre des instructions telles qu'elles apparaissent dans le programme après que celles-ci aient été exécutées, éventuellement dans un ordre différent. Sur les architectures dérivées du P6 (Core 2, Nehalem et Westmere), le ROB contient les résultats de chaque micro-opération en cours, accompagné d'un index de registre permettant de rétablir la correspondance entre les registres physiques et les registres architecturaux. Au final, ces résultats sont copiés vers un fichier de registres de retrait, ou Retirement Register File (RRF), qui correspond à l'ensemble des registres architecturaux après le traitement. En son temps, l'architecture Netburst a modifié ce schéma par l'utilisation d'un fichier contenant les registres physiques (internes) du processeur (Physical Register File, ou PRF). Le ROB ne contient alors plus les données des micro-opérations en cours, mais uniquement une référence vers ce fichier de registres. L'intérêt est évident : chaque entrée du ROB occupe moins de place, et à capacité égale, le ROB peut donc contenir plus d'entrées (le ROB de Sandy Bridge en contient 168, et celui de Nehalem / Westmere 128). Le RRF n'existe plus, et la cohérence avec les registres architecturaux passe par une table appelée Register Alias Table (RAT), dont les entrées pointent également vers le PRF. Ces références vers le PRF évitent ainsi les phases de copies de données que l'on rencontre dans le schéma ROB + RRF, qui est d'autant plus pénalisante que ces données sont larges. L'utilisation d'un PRF sur le Pentium 4 a ainsi été motivée par l'optimisation de Netburst pour les jeux d'instructions tels que SSE et SSE2, qui manipulent des données de 128 bits. Sandy Bridge inaugure quant à lui le nouveau jeu d'instructions AVX dont les opérandes peuvent atteindre 256 bits, ce qui a poussé Intel à équiper sa nouvelle architecture d'un PRF également. Page 3 - Les améliorations du core, suite Un anneau pour les gouverner tousNotre étude de Nehalem avait soulevé les problèmes engendrés par la présence d'un cache L3 partagé entre plusieurs cores, notamment : - la difficulté à répondre aux requêtes simultanées de quatre cores. Nous avions vu que les caches L2 permettaient d'intercepter une bonne partie de ces requêtes, soulageant d'autant le cache partagé ; - laugmentation avec le nombre de cores du temps nécessaire au maintien de la cohérence entre le LLC et les caches intermédiaires, appelée « cache snooping ». Sur Sandy Bridge, le problème est aggravé par le partage supplémentaire avec le GPU, sans compter l'annonce de modèles 8 coeurs prévus pour le second semestre 2011 (les Sandy Bridge-EP). 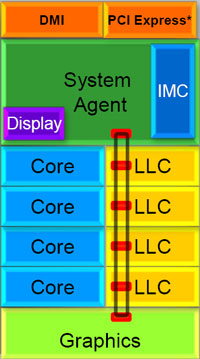 La solution imaginée par les ingénieurs d'Intel consiste en l'implémentation d'une interconnexion de type bus en anneau (ring bus) entre les agents susceptibles d'accéder au cache partagé. L'anneau joue un rôle d'arbitre au design simple et aux avantages multiples : chemins courts, et augmentation facile du nombre d'agents qui peuvent s'y connecter. Un arbitrage de ce type se rencontre parfois sur les processeurs graphiques, dont certaines ressources sont partagées entre beaucoup d'unités. L'avantage du système de ne pas se complexifier avec l'augmentation du nombre d'acteurs promet ainsi de futurs modèles avec un cache partagé entre plus que 4 cores et un GPU, et le rend parfaitement adapté aux plateformes multiprocesseurs. L'anneau relie les quatre principaux éléments du processeur : les cores, le GPU, le cache LLC, et l'agent système qui regroupe la partie uncore du processeur (contrôleur mémoire, contrôleur PCI-Express, interface DMI et moteur graphique). Etant donné que chaque étape davancement dans le bus nécessite un cycle, le GPU, peu sensible à la latence des accès mémoire, est positionné à lopposé de lagent système. L'anneau est composé de quatre voies, qui se distinguent par la nature des informations qui y transitent : données, requêtes, validation, et snoop. En pratique, bien quIntel mentionne spécifiquement un bus en anneau unidirectionnel, celui-ci se comporte plutôt comme un bus linéaire bi-directionnel. Ceci est dû à deux points : dune part, les cores CPU disposent chacun de deux accès au bus en anneau et dautre part, les transferts empruntent toujours le chemin le plus court. Au niveau de limplémentation physique, Intel profite de sa maîtrise du procédé de fabrication pour câbler lanneau par-dessus le cache LLC. Ce positionnement qui demande quelques petites optimisations au niveau des interconnexions, permet déviter daugmenter la taille de la puce. Le sous-système de cachesLa hiérarchie des caches de Sandy Bridge est directement héritée de celle de Nehalem, tout en apportant son lot d'améliorations. La plus notable est, comme nous l'avons vu précédemment, l'ajout du uop cache de 1,5 Ko, épaulant les 32 Ko du cache L1 d'instructions. Celui-ci voit son associativité passer à 8 voies (4 sur Nehalem). Lors de notre étude du Nehalem, nous avons expliqué que l'associativité à 4 voies permettait au L1I de garder une faible latence (car la gestion des voies consomme des cycles). La présence du uop cache tire la latence globale de l'ensemble du cache code vers le bas, ce qui a permis d'augmenter l'associativité du L1I sans impact négatif sur la latence constatée. Les caches L1 de données et L2 du Sandy Bridge, de 32 et 256 Ko, sont quant à eux identiques à ceux du Nehalem.  En ce qui concerne le cache L3 / LLC, celui-ci voit son organisation bouleversée. Les contraintes de partage ont conduit à la présence de l'anneau qui modifie la communication entre le L3 et les différents éléments du processeur (cores et GPU). La gestion par l'anneau simplifiant les contraintes de maintien de cohérence entre les caches, le L3 est désormais découpé en sous blocs (4 sous blocs de 2 Mo pour les versions à 8 Mo de L3). Les avantages sont multiples : - les sous-blocs étant accessibles en même temps, le L3 offre une bande passante accrue ; - la latence d'accès aux blocs de taille réduite est inférieure à celle du L3 monobloc du Nehalem ; A noter que le L3 appartient désormais aux mêmes domaines de fréquence et de tension que les cores, à la différence de celui de Nehalem qui tournait à la fréquence uncore. Toutes ces améliorations rendent le L3 de SandyBridge significativement plus performant que celui de Nehalem. Les mesures de latence révèlent une latence moyenne de 31 cycles, à comparer aux 42 cycles de celui du Nehalem. La latence varie bien entendu suivant la position des données par rapport au core CPU qui y accède puisque chaque étape sur lanneau nécessite un cycle. Page 4 - Advanced Vector Extension (AVX) Advanced Vector Extension (AVX)Sandy Bridge inaugure un nouveau jeu d'instructions vectoriel, l'AVX. AVX s'inscrit dans la famille des jeux d'instructions SIMD (Single Instruction, Multiple data) et opère sur des nombres flottants. Les opérandes peuvent atteindre 256 bits, mais AVX supporte également les opérandes 128 bits des jeux d'instructions SSE. La difficulté lorsqu'un nouveau jeu d'instructions apparaît consiste à le faire adopter par les développeurs. Pour cela, Intel a particulièrement soigné son nouveau jeu d'instructions, et compte bien sur une adoption rapide et massive. La première condition que doit remplir un jeu d'instructions pour séduire les développeurs est un gain de performance notable. Intel a ainsi porté ses efforts sur la vitesse de traitement des instructions AVX sur son nouveau processeur : - la gestion des registres a été optimisée pour la manipulation des opérandes 256 bits, comme nous l'avons vu plus haut. - les opérations les plus courantes s'enchaînent avec une latence de 1 cycle sur des opérandes 256 bits : multiplication, addition, réordonnancement de données (shuffle). - ajout d'un second port de lecture 128 bits afin de doubler la capacité d'alimentation des unités en opérandes 256 bits. Il est intéressant de noter que la présence de ce second port accélère le traitement de certaines routines qui n'utilisent pas l'AVX. La seconde condition réside dans la capacité des instructions proposées à faciliter le travail des développeurs, et notamment la mise en forme des données. En effet, les jeux d'instructions SIMD fournissent les performances maximales lorsqu'ils sont utilisés sur plusieurs données simultanément, c'est-à-dire en mode « vectoriel ». A contrario, dans le mode « scalaire », le registre ne contient qu'une seule donnée, ce qui réduit bien entendu l'intérêt du jeu d'instructions. Hélas, la vectorisation, qui consiste à grouper les données de façon optimale dans les registres, est encore mal effectuée de manière automatique par les compilateurs, et les meilleurs résultats sont toujours obtenus par un travail manuel, long et souvent compliqué. Afin de faciliter cette mise en forme, AVX introduit de nombreuses nouvelles instructions (appelées primitives) dont le rôle est de faciliter ce travail de regroupement : déploiement de données, insertion, extraction, lectures et écritures conditionnelles . 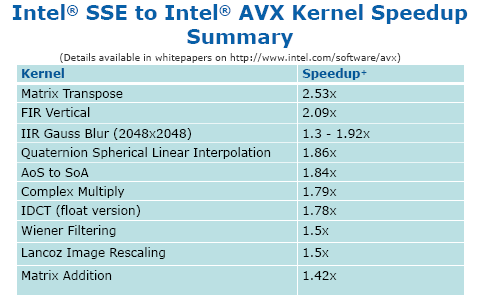 Intel a fait beaucoup d'efforts pour mettre en avant AVX, et les résultats dans les premiers benchmarks supportant le nouveau jeu d'instructions semblent très prometteurs. A noter que le support de l'AVX nécessite Windows 7 Service Pack 1, qui n'est encore disponible qu'en version release candidate. Page 5 - Turbo Boost version 2 Turbo Boost version 2La technologie Intel Turbo Boost repose sur l'augmentation de la fréquence d'un ou de plusieurs cores, en fonction de leur utilisation. En effet, lorsque tous les cores ne sont pas utilisés pleinement, le processeur tourne en deçà de ses spécifications thermiques. Turbo Boost met cette marge à profit pour accélérer les cores sollicités. La gestion du Turbo est confiée à une unité intégrée dans le system agent et appelée PCU (Power Control Unit). La PCU affecte les accélérations en fonction de l'enveloppe thermique globale du processeur, celle-ci ne devant pas dépasser un seuil spécifique au modèle et appelé TDP (Thermal Design Power). 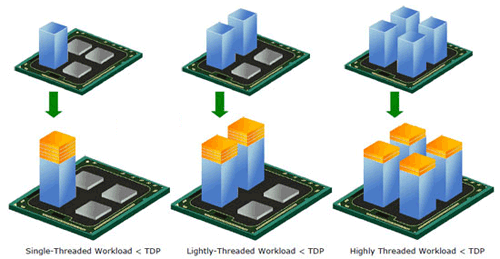 Introduite sur certains modèles de Core 2 Mobile Penryn sous l'appellation « IDA » (Intel Dynamic Acceleration), la technique a surtout été développée sur les architectures Nehalem et ses dérivées. Sandy Bridge bénéficie d'une version améliorée du Turbo Boost, upgradée pour l'occasion en version 2. Notons tout d'abord que le GPU intégré de Sandy Bridge profite également de l'accélération turbo. Certes, le GPU intégré sur le PCB des Arrandale profitait également de l'accélération, mais de façon moins efficace du fait de la séparation du GPU du reste du processeur. Sur Sandy Bridge, CPU et GPU partagent le même die, ce qui permet d'affiner considérablement la mesure de l'enveloppe thermique globale. Turbo Boost 2 innove surtout par la possibilité offerte au processeur de dépasser son TDP pendant un certain temps (jusqu'à 25% de plus, soit 120W pour les modèles à TDP égal à 95W), allouant ainsi plus de marge au mode Turbo. Si l'intérêt est évident en termes d'accélération, on peut se demander comment cela est possible sans faire sortir le processeur de ses spécificités thermiques, et risquer ainsi de voir les mécanismes de protection (throttling) se déclencher. En effet, le TDP est défini pour que la température de fonctionnement du die ne dépasse pas un plafond au-delà duquel l'intégrité du circuit n'est plus garantie. Intel exploite en réalité un phénomène physique : l'inertie thermique du processeur. Le principe repose sur un constat très simple : lorsque le processeur est sollicité, il commence à chauffer ; or, la montée en température n'est pas instantanée, et il faut un certain temps à l'ensemble du package pour atteindre la température de croisière - si tant est que la charge dure assez longtemps. Ainsi, même si la puissance dissipée par le processeur est supérieure au TDP pendant cet instant de « chauffe », la température induite par ce TDP surévaluée n'a pas le temps de s'installer dans le package. Bien entendu, toute la difficulté réside dans la durée d'application de ce mécanisme. Plus il est appliqué longtemps, plus l'accélération est notable, mais plus le processeur chauffe au delà de ses spécifications, ce qui est susceptible de déclencher les mécanismes de protection. Difficile de statuer sur une valeur optimale, car la montée en température du processeur dépend bien évidemment du mécanisme de refroidissement utilisé, un paramètre externe au seul processeur et donc non quantifiable de façon unique. En pratique Intel a décidé que les versions mobiles bénéficieraient d'un temps d'application nettement plus élevé que les modèles desktop, 28 secondes contre 1 seconde sur un modèle de bureau ! Cela peut sembler paradoxal, car les ordinateurs de bureau bénéficient en général de solutions de refroidissement plus efficaces que les laptops. Pour cette raison, et bien que TB2 concerne les plateformes desktop et mobiles, c'est surtout sur ces dernières que la technique sera utilisé pleinement. Reste quun délai de 28 secondes peut sembler significativement élevé par rapport au temps nécessaire à léchauffement dun processeur, on pourrait également penser quIntel se sert de cette fonctionnalité pour réduire artificiellement le TDP annoncé de ses processeurs mobiles, particulièrement des modèles quadruples curs. En résumé, TB2 apparaît comme une technique innovante, mais dont l'efficacité variera fortement suivant la plateforme. Avec un temps d'application volontairement limité, TB2 n'aura que peu d'effet sur les plateformes de bureau, alors qu'il prendra toute sa mesure sur les ordinateurs mobiles. Page 6 - Socket LGA 1155, P67 et H67, LGA 2011 Socket LGA 1155, P67 et H67, LGA 2011Les nouveaux processeurs Sandy Bridge prennent place dans un nouveau Socket LGA 1155. Par rapport au 1156, on perd donc un point de contact et les deux sont complètement incompatibles. Les processeurs 1156 et 1155 sont de taille identique, à savoir 37.5x37.5mm, mais les détrompeurs sont différents ce qui empêche tout montage dun CPU LGA 1155 sur une carte mère LGA 1156 et vice-versa.  Voilà une mauvaise nouvelle dautant que le LGA 1156 na été lancé quen septembre 2009 ! Seule consolation, les fixations pour le système de refroidissement CPU sont communes entre les deus Sockets. 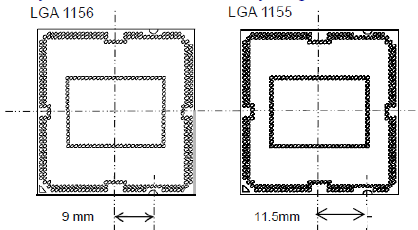 Le Socket LGA 1155 peut être accompagné de 4 chipsets, deux destinés aux entreprises, les Q67 et B65, et deux destinés au grand public, les H67 et P67. La plate-forme P67 est la seule à ne pas gérer le HD Graphics intégré au CPU, mais en contrepartie elle est la seule à permettra laccès aux réglages permettant loverclocking CPU. En dehors de ceci, H67 est identique au P67. 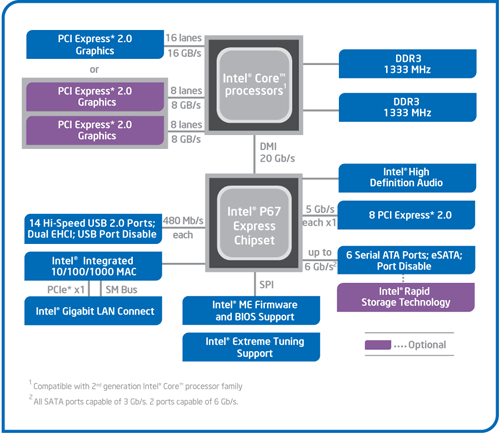 Ces deux chipsets se distinguent de leur prédécesseur de part la gestion du SATA 6 Gb/s, 10 mois après son intégration sur lAMD 890GX. Attention toutefois, sur un total de 6 ports SATA gérés, seuls 2 sont à cette vitesse, les 4 autres étant SATA 3 Gb/s. L'USB 3.0 est le grand absent de cette génération de chipset, et il faudra donc toujours que les fabricants de cartes mères intègrent un contrôleur externe, Intel le fait dailleurs sur sa propre carte mère P67, la DP67BG. La bande passante entre le chipset et le CPU est par ailleurs doublée du fait d'un DMI fonctionnant à 5 GT /s, soit 2 Go /s dans chaque sens. Les lignes PCI-Express gérées par le chipset passent également de 2.5 à 5 GT /s, ce qui était le gros défaut du P55. Par rapport au H67, le Q67 gagne la gestion du bon vieux bus PCI (on note toutefois la présence sur certaines cartes mères P67/H67 de ports PCI gérés par des puces additionnelles). Par rapport au Q67, le B65 perd 2 ports USB 2.0 et passe à 12, ne gère quun port en SATA 6 Gb/s et le contrôleur SATA ne fonctionne plus quen mode IDE ou AHCI et perds donc le RAID. Si le LGA 1155 remplace le LGA 1156, pour linstant le LGA 1366 reste en place. Aucun processeur darchitecture Sandy Bridge nest toutefois prévu dessus, et il faudra en fait attendre une nouvelle plate-forme haut de gamme qui narrivera pas avant le second semestre. Intel aurait pour se faire deux projets dans ces cartons, le LGA 1356 dune part, et le LGA 2011 dautre part, cette dernière piste étant privilégiée. Les CPU LGA 1356 et LGA 2011 partagent daprès les rumeurs des caractéristiques impressionnantes, à savoir jusquà 8 curs et 20 Mo de cache LLC, et se distinguent par : - La mémoire : triple canal sur 1356, ou quadruple canal sur 2011 - Le PCI Express : trois PCI-E 8x Gen3 sur 1356, cinq sur 2011 - Le QPI : 1 sur 1356 (bi-Socket), 2 sur 2011 (quadri-Socket) Page 7 - Les Core i7 & i5 Sandy Bridge Les Core i7 & i5 Sandy BridgeSi Intel annoncera dès le CES pas moins de 29 processeurs Sandy Bridge dont 14 sur desktop, seuls les modèles quad core seront disponibles dès le 9 janvier. Il faudra attendre le 20 février prochain pour voir débarquer les modèles dual core, sur lesquels nous reviendrons donc à cette date. Après avoir débuté la production de processeur en 32nm avec larchitecture Nehalem selon sa stratégie "Tick-Tock", Intel utilise maintenant ce process maitrisé pour ces nouveaux Sandy Bridge. En version quad core, on a donc un die de 216mm² comprenant 995 millions de transistors, contre 296mm² et 774 millions de transistors pour un quad core Lynnfield LGA1156. La gamme quad core est décomposée de la sorte : - Core i7 : 8 Mo de cache L3, avec HyperThreading - Core i5 : 6 Mo de cache L3, sans HyperThreading  La dernière lettre permet ensuite de distinguer les gammes de processeur : - K : Coefficient libre en montée, Intel HD Graphics 3000 - S : TDP de 65 watts - T : TDP de 45 watts - Pas de lettre : TDP de 95 watts 6 processeurs affichent un TDP de 95 watts : - Core i5-2300 : 2.8 GHz, 3.1 GHz Turbo, 177$ - Core i5-2400 : 3.1 GHz, 3.4 GHz Turbo, 184$ - Core i5-2500 : 3.3 GHz, 3.7 GHz Turbo, 205$ - Core i7-2600 : 3.4 GHz, 3.8 GHz Turbo, 294$ - Core i5-2500K : 3.3 GHz, 3.7 GHz Turbo, 216$ - Core i7-2600K : 3.4 GHz, 3.8 GHz Turbo, 317$ Voici le fonctionnement exact du Turbo Boost en fonction du nombre de coeurs actifs : 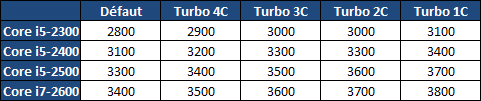 On trouve également des version 45 et 65 watts, réservées aux intégrateurs : - Core i5-2500T : 2.3 GHz, 3.3 GHz Turbo - Core i5-2400S : 2.5 GHz, 3.3 GHz Turbo - Core i5-2500S : 2.7 GHz, 3.7 GHz Turbo - Core i7-2600S : 2.8 GHz, 3.8 GHz Turbo Il faudra à nen pas douter quelques temps pour shabituer à cette nouvelle nomenclature. Voici pour rappel le positionnement tarifaire des processeurs quad core LGA1156 : - Core i5-750 : 2.66 GHz, 3.20 GHz Turbo, 196$ - Core i5-760 : 2.80 GHz, 3.33 GHz Turbo, 205$ - Core i7-860 : 2.80 GHz, 3.46 GHz Turbo, 284$ - Core i7-870 : 2.93 GHz, 3.60 GHz Turbo, 294$ - Core i7-880 : 3.06 GHz, 3.73 GHz Turbo, 583$ Le Core i7-2600 est au prix du Core i7-870, alors que sa fréquence de base est 16% plus élevée. Le Core i5-2500 est au prix du Core i5-760, pour une fréquence 18% supérieure. Page 8 - Intel HD Graphics 2000 & 3000 Un IGP sur le même dieDébut 2010, Intel avait été le premier à intégrer un cur graphique dans un processeur desktop avec ses processeurs Clarkdale (Core i3 et Core i5 double curs) introduits en janvier 2010. Intel étend sa stratégie dintégration puisque tous les processeurs Sandy Bridge introduits aujourdhui sont équipés dun cur graphique. Premier changement de taille, contrairement à Clarkdale ou lntel avait accolé son IGP dans le packaging du processeur (un IGP gravé en 45 nm tandis que le CPU létait en 32 nm), sur Sandy Bridge CPU et IGP sont fusionnés sur le même die (et donc en 32 nm). La gestion de lénergie est peut ainsi être unifiée par le biais de la Power Control Unit. Elle surveille la consommation complète de la puce et adapte en fonction les modes Turbo du CPU et de lIGP. 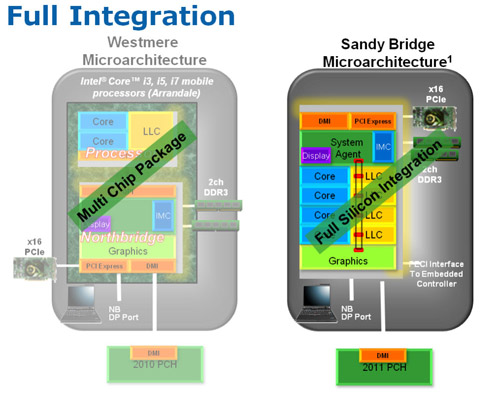 Mieux, par le biais du ring bus décrit précédemment, lIGP utilise le LLC du processeur lorsquil le juge nécessaire. Intel précise que le pilote graphique se charge de donner des indications sur les flux qui peuvent exploiter le cache, cest le cas des textures et des buffers de rendu, mais pas des données géométriques. Ceci permettrait déconomiser en pratique 50% de la bande passante mémoire nécessaire au rendu 3D. Pour éviter que le LLC ne soit complètement monopolisé par lIGP, Intel a mis en place une protection qui correspond grossièrement à une limitation de la quantité de LLC utilisable par lIGP. Cette protection est fixée par défaut pour chaque modèle de CPU via le microcode, mais elle peut être modifiée par Intel pour certaines applications à travers les pilotes graphiques. En pratique, le fabricant nous a indiqué que sur les versions équipées dun gros cache LLC (8 et 6 Mo ?), la protection nentre jamais en action, ce qui laisse cores CPU et IGP se battre à armes égales pour lutilisation du cache. La limite serait par contre nécessaire pour les modèles équipés de moins de cache (3 Mo ?). ArchitectureDu côté de larchitecture, lIGP de Sandy Bridge reprend les grandes lignes de la génération précédente disposant de jusqu'à douze unités dexécutions de type vec4. On suppose, même si Intel ne la pas précisé que le GPU conserve quatre unités de texture et deux unités ROPs. Le support de DirectX est par contre étendu de DX 10 à DX 10.1. Etant donné le niveau de performances visé, supporter les nouveautés matérielles de DirectX 11 nétait pas une priorité, dautant plus que cette API permet aux composants DX 10/10.1 de profiter malgré tout des avantages de sa nouvelle structure logicielle. Il est à noter également que si les IGP dIntel peuvent traiter en hardware les Vertex Shaders, les pilotes du constructeur disposent dun moteur logiciel pour les traiter sur le CPU. Une possibilité qui est utilisée au cas par cas dans les pilotes par le biais dune liste préétablie (et désormais cachée ?) par le constructeur. 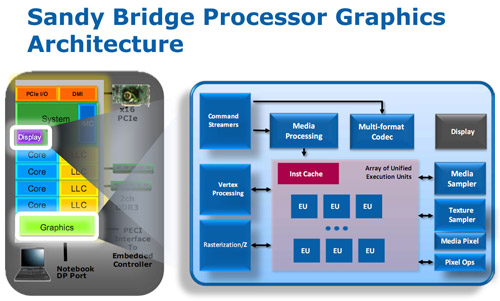 Quelques changements sont tout de même évoqués en ce qui concerne les unités dexécution comme nous lavions rapporté lors de lIDF en septembre dernier. Laugmentation du nombre de registres gérés, une meilleure gestion des branchements complexes et un support natif dun plus grand nombre dinstructions. Un choix important fait par Intel est dans la multiplication des unités fixes partout où cela était possible (partie 3D et vidéo). Un choix qui tranche fortement avec les choix effectués par exemple par AMD sur ses derniers GPUs où les unités fixes tendent à disparaitre. Intel gagne dabord en efficacité énergétique, les unités fixes ont un meilleur rendement, mais aussi dans sa gestion des pilotes en réduisant limpact du driver sur le processeur. Notez enfin quOpenGL est pris en charge en version 3.1, tout comme OpenCL et DirectCompute 4.1. HD 2000 et HD 3000Pour la génération précédente, Clarkdale, Intel utilisait un même GPU (le HD Graphics) cadencé à différentes fréquences selon les modèles (de 533 à 900 MHz). En ce qui concerne la nouvelle génération Sandy Bridge, Intel a effectué un choix différent en proposant deux GPU distincts, le HD 2000 et le HD 3000. Ils se différencient simplement par le nombre dunités dexecution activées sur le GPU, 6 sur le HD 2000 et 12 sur le HD 3000. La répartition HD 2000/HD 3000 dans les processeurs est assez particulière. Sur mobile cest relativement simple puisque le HD 3000 est présent dans tous les processeurs. Seule la fréquence maximale varie en fonction des modèles : - Core i5 2520M, 2540M, Core i7 2620M, 2720QM, 2820QM, 2920XM : 1300 MHz - Core i5 2410M, Core i7 2635QM : 1200 MHz - Core i3 2310M, Core i7 2629M, 2630QM, 2649M : 1100 MHz - Core i7 2647M : 1000 MHz - Core i7 2617M : 950 MHz - Core i7 2537M : 900 MHz Difficile de déceler une logique nette, même si lon notera que les trois derniers processeurs de la liste sont des ULV, ce qui justifie la fréquence plus basse de leurs GPU. Sur desktop on retrouve les HD 3000 uniquement sur les modèles K, dédiés à loverclocking, tandis que les HD 2000 équipent tous les autres modèles. Un choix pour le moins curieux puisque les cartes mères H67 (qui disposent des sorties vidéo nécessaires à lutilisation de la partie graphique de Sandy Bridge) ont justement pour limitation de ne pas permettre loverclocking en changeant les coefficients multiplicateurs Turbo des curs. Il est par contre possible de changer le coefficient Turbo du cur graphique. Intel justifie ce choix en disant vouloir réserver son HD 3000 aux modèles les plus haut de gamme. De notre point de vue cela ne fait pas sens. Notez enfin que côté fréquences, seuls les Core i7 2600 (classique, S et K) disposent dun IGP capable datteindre 1350 MHz. Les IGP de tous les autres modèles desktop sont cadencés eux à 1100 MHz, sauf pour le Core i5 2500T cadencé à 1250 MHz ! Intel a résolument pratiqué la segmentation à outrance. Du côté des plateformes, les cartes mères H67 (tout comme leurs pendant mobiles) gèrent toutes les connectiques standards y compris le DVI, Display Port et HDMI. Dans le cas de ce dernier, la version 1.4 est supportée autorisant la lecture de BluRay 3D. Le DVI nest lui toujours supporté quen mode single channel. Page 9 - Intel HD Graphics, conso, oc, perfs ConsommationUne des nouveautés apportés par Sandy Bridge est la possibilité de lire en temps réel la consommation de la puce et de ses différents blocs fonctionnels (cores et IGP). Si Nehalem proposait déjà une telle lecture, il sagissait dune estimation donnée à partir de tables en fonction de la fréquence et de la tension. Ici la lecture est basée sur les sondes dont se sert la Power Control Unit pour gérer entre autre le nouveau mode Turbo. Voici les valeurs relevées, via hwinfo32, sur un i7-2600K : 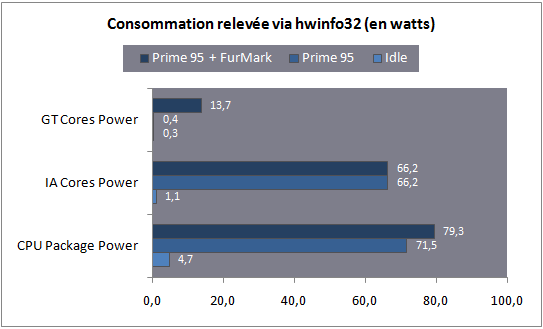 La consommation au repos du GPU est impressionnante, dautant plus quAero (linterface graphique accélérée 3D de Windows 7) était activée. A titre de comparaison, une Radeon HD 5450 consomme 14.5 watts en charge et 7 watts au repos. La différence venant en grande partie des puces mémoires et autre composants présents sur la carte graphique. OverclockingSil nest pas possible de changer les coefficients multiplicateurs des cores CPU sur plateforme H67, on peut tout de même changer librement le coefficient multiplicateur du GPU. A limage des curs CPU sur P67 (ou auparavant sur Nehalem), on ne change pas le coefficient multiplicateur réel du GPU, mais uniquement sa fréquence turbo maximale. Par défaut, le 2600K fonctionne au repos sur le bureau Windows à 850 MHz. Le GPU peut alors, sous contrôle de la Power Control Unit augmenter sa fréquence dans les limites autorisées par lunité. Petite nuance cependant, la PCU nassure pas que la partie GPU ainsi overclockée sera pleinement stable. Sous FurMark, nous avons réussi à atteindre à la tension dorigine les 1.75 GHz pour la partie GPU. FurMark a en effet la particularité davoir une charge nulle sur le processeur, laissant une large marge de TDP disponible. A 1.75 GHz, dans un jeu comme Far Cry 2 on peut apercevoir du throttling de la fréquence du GPU par la Power Control Unit, réduisant jusqu'à 1.55 GHz la fréquence dans le moment le plus complexe de la scène graphique. A cette fréquence cependant la stabilité nétait pas optimale, les applications graphiques quittant parfois alors inopinément. 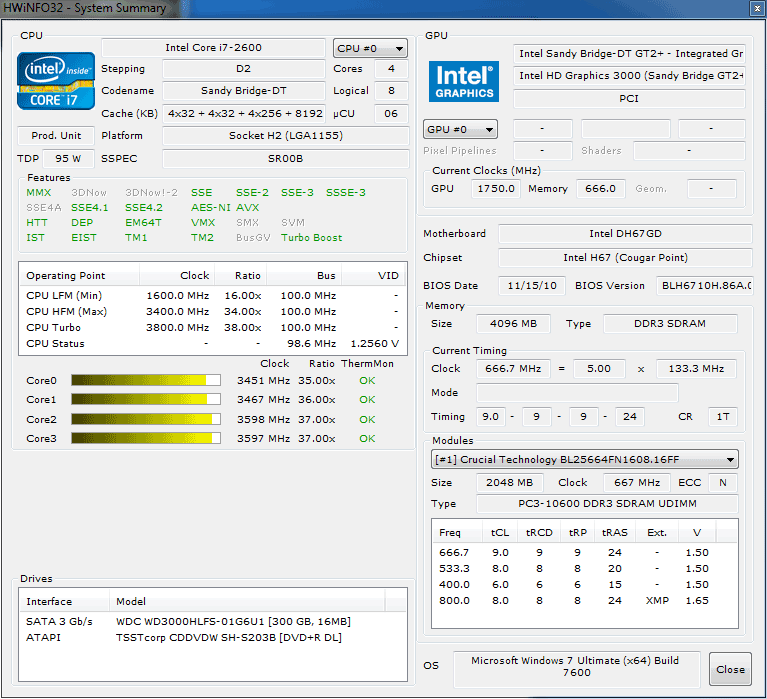 Une fréquence de 1.65 GHz à la tension dorigine était parfaitement stable dans nos tests. A cette fréquence le throttling était encore présent. Une limite que lon ne peut malheureusement pas faire disparaitre puisque, même avec un processeur K, ce quIntel appelle « Unlocked power » (la capacité de changer les limites de TDP) nest pas autorisé sur les cartes mères H67. Une bizarrerie de plus de cette segmentation. Performances 3DNous avons mesuré les performances en 3D des nouveaux IGP. Nous les avons comparés à la génération précédente du HD Graphics ainsi quaux performances du chipset graphique intégré dAMD, le 890GX. Pour compléter, nous avons intégré deux cartes graphiques, les Radeon HD 5450 (GDDR3) et Radeon HD 5670 512 Mo. Des cartes que lon trouve dans le commerce pour respectivement 40 et 90 euros environ. Dans le cas de la plateforme H55, nous avons simulés les performances du cur graphique à partir dun Core i5 661 cadencé respectivement à 900, 733 (Core i5 660) et 533 (Pentium G9650) MHz. Cela nous permet de garder une fréquence processeur constante durant ces tests. Si nous avons voulu utiliser la même méthode pour les Sandy Bridge, nous avons finalement testé individuellement les processeurs, il nous était en effet impossible de downclocker la fréquence des GPU (pour simuler les 2500/2500K à partir des 2600/2600K). La manipulation bien quautorisée dans le BIOS étant sans effet en pratique. Voici les plateformes utilisées, lOS étant Windows 7 64 bits pour toutes les plateformes : - Intel Core i5 661, Asus P7H55M, 4 Go DDR3 1333 Crucial - Intel Core i5 2500/2500K et i7 2600/2600K, Intel DH67GD, 4 Go DDR3 1333 Crucial - AMD Phenom II X4 3.6 GHz, Gigabyte 890GPA-UD3H, 4 Go DDR3 1333 Crucial Far Cry 2Pour nos tests de jeux, nous avons utilisé trois niveaux de performances différents : - 1280 x 720 low - 1280 x 720 medium - 1680 x 1050 medium Dans le cas de Far Cry 2, les modes graphiques utilisés correspondent aux modes low et medium proposées dans le jeu. Ces modes utilisent exclusivement DirectX 9. 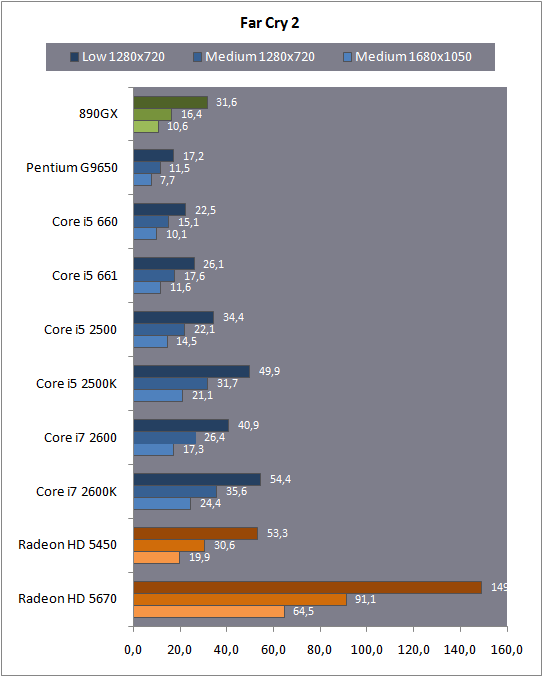 Lambition dIntel était de doubler les performances de son IGP précédent, cest le cas quand lon compare le Core i7 2600K au Core i5 661 dans Far Cry 2. Laugmentation est identique dans les trois modes testées. La différence de performances entre une version HD 3000 et HD 2000 se situe aux alentours de 33% en 1280 par 720 pour monter à 41% en 1680 par 1050. La charge graphique pour les unités dexécution (6 supplémentaires sur le HD 3000 des processeurs K pour rappel) augmentant en fonction de la résolution. Quand a lécart de fréquence (1350 MHz contre 1100), il varie entre 9 et 15% pour les processeurs équipés dun HD 3000. La différence est beaucoup plus sensible avec les processeurs équipées dun HD 2000, 19% dans chaque cas. Notez que par rapport au GPU intégré dAMD, le 890GX, un Core i5 2500 (HD 2000, 1100 MHz) fait systématiquement mieux. AMD a perdu plusieurs occasions de mettre à jour le cur graphique utilisé par ses chipsets et cela se ressent. Du côté des cartes graphiques, notre entrée de gamme à 40 euros est devancée légèrement par le 2600K. La Radeon HD 5670, pourtant modeste à de nombreux égard, remet cependant tout le monde à sa place ! Crysis WarheadA limage de ce que nous avions fait pour notre test des solutions graphiques à moins de 100 euros, nous avons retenu les modes « mainstream » et « gamer » pour nos modes low et medium. 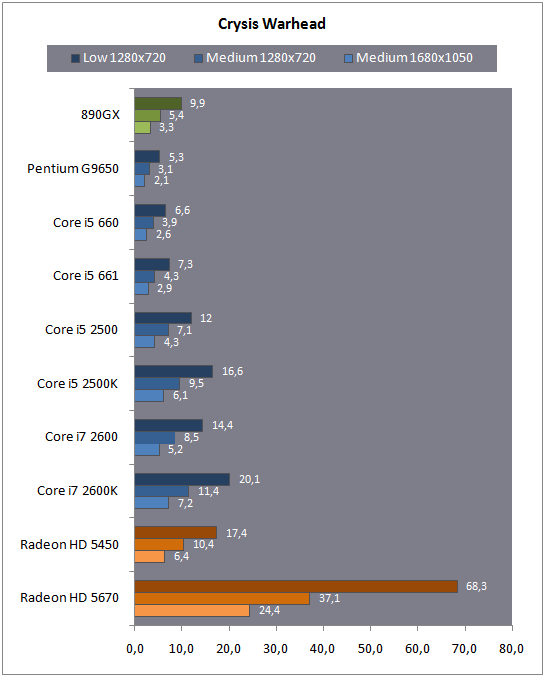 Crysis Warhead reste un calvaire pour nos IGP. Les gains atteints par le HD 3000 par rapport au HD Graphics dancienne génération sont les plus elevés ici, jusque 2.7x dans le mode graphique le plus simple. Le passage de 1.1 à 1.35 GHz apporte 20% de performances en plus dans tous les cas ici, preuve si lon en doutait que lon est limité par les unités dexécution. Le reste des constatations effectuées sous Far Cry 2 restent vrai sous Crysis (positionnement relatif à la concurrence). La correction quinflige la HD 5670 au reste des modèles nous permet de relativiser la puissance de ces solutions graphiques dentrée de gamme. Page 10 - Intel HD Graphics, CPU vs IGP Impact CPU vs IGPNous avons également tenté de voir limpact éventuel des choix réalisés par Intel au niveau de lintégration de son GPU. Car si le contrôleur mémoire est partagé (cétait déjà le cas auparavant), la mémoire cache de dernier niveau (LLC, le L3 pour les curs CPU) lest aussi par le biais du ring bus. Nous avons tenté dobserver les performances respectives de la partie processeur et IGP de Sandy Bridge en utilisant simultanément une application stressant fortement le processeur dun côté, et de lautre un jeu stressant la partie GPU. Nous avons opté pour le couple Cinebench + H.A.W.X. Nous avons effectué trois tests sur chaque plateforme en faisant varier le nombre de threads utilisés par Cinebench. Les valeurs correspondent au pourcentage de threads par rapport au nombre de curs physiques de la puce. A 200%, cela représente 8 threads sur un processeur quadruple cur avec Hyper Threading comme le 2600K. Sur un processeur double cur avec Hyper Threading (le Core i5 661) cela représente 4 threads. Nous avons regardé lévolution des performances sur trois plateformes : - Core i7 2600K + Radeon HD 5450 - Core i7 2600K + IGP - Core i5 661 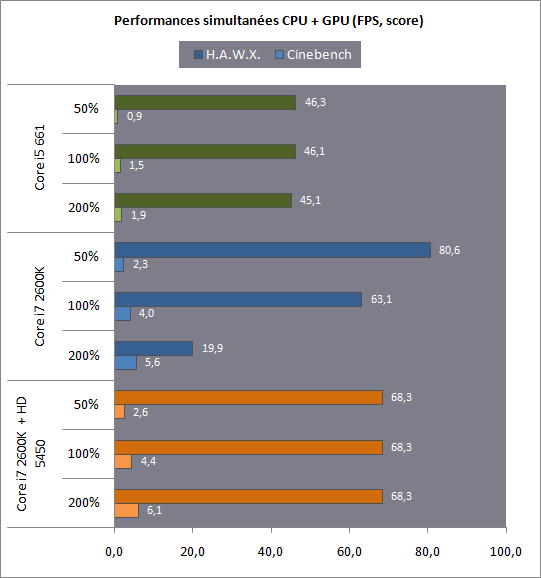 Intéressons nous particulièrement aux performances sous H.A.W.X en fonction du nombre de threads. Linfluence est nulle lorsque lon utilise une Radeon HD 5450 (le scheduler Windows donnant correctement la priorité au jeu, qui est en premier plan). Sur un Core i5 661, une légère baisse se fait sentir de 2.5%, que lon peut expliquer facilement par lutilisation partagée du contrôleur mémoire. Mais que dire des performances avec la partie IGP du 2600K ? Il est a noter, à titre indicatif, que nous avons pu répéter le problème avec un autre couple jeu/application (FarCry 2 et Prime95). Nous avons trouvé, au moins pour partie une des causes de la baisse de performances en suivant la fréquence de fonctionnement de lIGP. Avec 8 threads logiciels dans Cinebench, nous avons pu observer via hwinfo32 le throttling du cur graphique dont la fréquence passe en quelques secondes de 1350 MHz à 850 MHz (fréquence 2D). Si cela peut expliquer une perte de performances, cela nexplique cependant pas tout. Plusieurs hypothèses sont possibles et il est probable que de multiples facteurs jouent. Dabord il est normal que, à limage du Core i5 661, une partie de limpact relevé tienne du partage du contrôleur mémoire. Cette partie peut même être plus importante du fait du partage du LLC et déventuels problèmes qui y seraient liés (ring bus saturé, snooping, etc). Dernier point, nous ne savons pas exactement à quel niveau la lecture de la fréquence du GPU est effectuée par le logiciel de monitoring que nous avons utilisé. Il est probable que, selon le registre lu, il soit impossible de détecter un throttling qui irait en dessous de 850 MHz. On doit également noter quà défaut dêtre une cause, le throttling que nous avons observé pourrait très bien aussi être une conséquence dun autre problème. En effet, la fréquence réduite pourrait tout à fait être la résultante dune charge graphique insuffisante (limite en amont, par exemple au niveau du LLC) qui ne forcerait pas le cur graphique à monter à sa fréquence maximale. Indépendamment de la cause, il est anormal de voir un tel impact dune charge processeur sur la partie graphique, tout comme il est anormal de relever un throttling aussi élevé quand nos mesures de consommation semblent placer les processeurs dIntel assez loin de leurs TDP annoncés (voir page suivante). La Power Control Unit joue probablement un rôle dans cette situation. Page 11 - Intel HD Graphics, Vidéo et Quick Sync Lecture vidéoA limage des autres solutions du marché, les IGP dIntel prennent évidemment en charge de manière matérielle le décodage des vidéos. Le but nétant pas daider les processeurs - même les modèles double curs dentrée de gamme peuvent décoder de manière logicielle le flux AVC HD dun BluRay - mais surtout de permettre de réduire la consommation de la puce (et donc daméliorer lautonomie sur les portables). La génération précédente gérait déjà les décodages MPEG2, VC1 et AVC (H.264) de manière matérielle. Cependant Intel a poursuivi ici son implantation dunités fixes. Là où les opérations de Motion Compensation et de Deblocking étaient traitées par les unités dexécution, les Sandy Bridge utilisent désormais des unités fixes pour ces étapes de décodage. Les modifications matérielles apportées par Intel à son architecture Sandy Bridge ne sont pas transparentes et nécessitent des changements dans les logiciels de lecture. A titre dexemple, la version publique de Media Player Classic HomeCinema qui permet le décodage H.264 par lIGP sur les générations précédentes détecte ici correctement notre Sandy Bridge, mais le résultat est un amas dartefacts. Intel nous a cependant fourni deux applications compatibles Sandy Bridge, PowerDVD 10 et Total Media Theater 5 dans des versions beta adaptées. Nous avons pu vérifier sur la première le bon fonctionnement du décodage accéléré de divers formats, y compris H.264 sur des fichiers MKV 720p et 1080p. A noter quIntel semble avoir corrigé lun des défauts que lon avait constaté précédemment, laccumulation temporaire de fourmillements dans certaines zones sombres. Soit le bug à été corrigé, soit le denoising activé par défaut dans les drivers dIntel est beaucoup plus efficace. Son réglage par défaut est un peu agressif, avec pour contrepartie de très légèrement flouter les scènes très bruitées comme nous avons pu le constater dans HD HQV. La majorité des options liées au décodage vidéo tiennent à une gestion correcte de lentrelacement, un faux problème pour les BluRay dont les pistes principales sont heureusement progressives. Sur des sources de très bonne qualité, les différences sont imperceptibles et tiennent plus au choix du réglage du denoising que dautre chose. A noter quIntel propose dans ses pilotes une correction automatique des tons de peau. Désactivé par défaut, loption nous semble assez peu efficace. Son intérêt lest dautant moins, une fois de plus, quavec des sources de bonne qualité la nécessité deffectuer des corrections est limité. On classera dans la même catégorie loption de correction dynamique du contraste, similaire à ce que lon trouve sur certains téléviseurs LCD. Parmi les bugs précédemment relevés, une dégradation de limage lors de la lecture accélérée dun BluRay dans une résolution inférieure à sa résolution native (downscaling). Il semble ici corrigé sous Total Media Theater 5. Par contre, comme le note nos confrères de Home Media , la lecture vidéo reste imparfaite sur des sources à 23,976 img/s puisque ces dernières sont lu à 24 Hz et non 23 Hz, ce qui entrainera un micro-saccade, pas forcément visible pour les non avertis, toutes les 40 secondes. Encodage vidéo : Intel Quick SyncDerrière le nom marketing Quick Sync, Intel met en avant la possibilité offerte aux développeurs dutiliser leur IGP pour réaliser des tâches dencodage vidéo. A limage de ce qui est possible de réaliser via CUDA sur un GPU Nvidia ou Stream sur un GPU AMD, il est possible dutiliser une partie des unités matérielles pour réaliser un encodage vidéo. Léquivalent de Stream/CUDA pour Intel dans le cas de lencodage et du décodage vidéo passe par le MediaSDK . Il sagit dune API permettant aux développeurs dutiliser les fonctions codec aussi bien de manière logicielle que matérielle. Libre aux développeurs dutiliser les morceaux qui les intéressent. Dun point de vue technique, lorsque lon utilise laccélération IGP, Sandy Bridge se démarque dabord par son décodage de limage source (dans le cas dun transcodage) qui seffectue par ses nouvelles unités fixes, donc rapides. Du point de vue de lencodage, si certains blocs fixes existent, le gros du travail (Motion Estimation, etc) reste effectué sur les unités dexecution de lIGP. Intel nous a fourni deux applications compatibles avec la dernière version de son MediaSDK, tout du moins en ce qui concerne la partie accélération matérielle. Il sagit de version beta de MediaEspresso de Cyberlink et de Media Converter dArcsoft, des applications de transcodage qui servent principalement à convertir un fichier volumineux (BluRay, etc) en un format adapté à un périphérique (téléphone portable, tablette, etc ). Il ne sagit pas deffectuer un encodage de très haute qualité dans les deux cas. Nous avons utilisé MediaEspresso afin de comparer les temps dencodage tout en regardant les différences de qualité éventuelles. Le logiciel ne permet pas une très grande marge de manuvre lorsquil sagit de configurer les options dencodage avancé. Impossible de choisir entre une ou plusieurs passes ou du niveau de profil H.264 utilisé, les options se limitent à un simple choix du bitrate. Pour notre test nous avons réencodé une vidéo 720p (1280x720) en 640x480 (en gardant laspect ratio 16/9) à un bitrate de 3 Mbps. Il est possible dans MediaEspresso de choisir le niveau daccélération que lon souhaite. Aucun, décodage accéléré, encodage accéléré, et décodage + encodage accéléré. Nous avons testés ces quatre scénarios, en désactivant les options damélioration de la qualité dimage proposées par MediaEspresso afin de ne pas désavantager lune ou lautre des solutions. Avant dintroduire les résultats, nous devons insister sur le fait que nous avons obtenus quatre fichiers dune taille à peu près comparable mais non identique. Il en va de même pour la qualité, chose que nous allons décrire ci après. Les temps dencodages doivent donc être considérés avec circonspection. 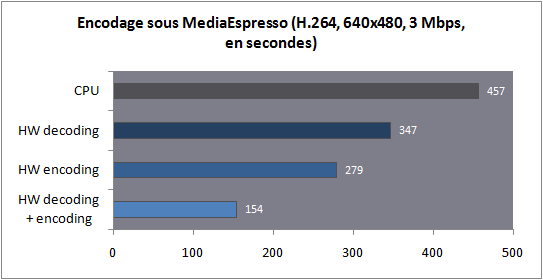 A lire le graphique, on peut entendre que lusage de laccélération matérielle de Sandy Bridge permet de diviser le temps dencodage par trois sur le Core i7-2600K. Notez également que si lon parle dencodage accéléré, le processeur est toujours mis à contribution. Le temps processeurs dans les trois modes accélérés était pour information de 83%, 38% et 23%. Qualitativement parlant, les résultats ne sont définitivement pas identiques. Nous avons effectué un crop sur une frame encodée, de haut en bas vous trouverez limage source, encodée en mode CPU, décodage IGP, encodage IGP, et décodage + encodage IGP.  Sachant que la vidéo originale disposait dun bitrate à peine supérieur à celui choisi, dans les quatres cas on ne peut pas dire que la qualité de limage finale soit au niveau attendue (on passe tout de même de 1.1 Go sur la vidéo source en 720p à « seulement » 990 Mo en 480p !). Ensuite, il semble net à nos yeux que MediaEspresso utilise un path logiciel complètement différent lorsque lon utilise une version purement processeur ou accélérée (complètement ou partiellement). Des aberrations chromatiques tirant sur le rouge apparaissent sur la partie droite de limage (première planche en partant du milieu) dans les trois versions accélérées. On suppose que le MediaSDK dIntel nest utilisé quen cas daccélération (partielle ou complète) et quun autre path est utilisé pour la version processeur. Mais même si lon isole les cas « MediaSDK », les trois images ne sont pas strictement identiques. Au final, la version purement processeur nous semble clairement dun autre niveau. Même si lon peut la trouver légèrement plus floutée, la différence est sensible en lecture vidéo avec beaucoup moins dartefacts. En clair, si effectivement Intel propose avec Sandy Bridge une accélération apparente de lencodage vidéo, en pratique la bibliothèque sur laquelle elle repose ne semble pas forcément au niveau des meilleures options logicielles présentes, y compris celle, pourtant modeste, intégrée dans MediaEspresso. Page 12 - Consommation ConsommationPour le test côté CPU a proprement parler, nous avons pu avoir 4 processeurs :  - Core i5-2300 - Core i5-2400 - Core i5-2500K - Core i7-2600K 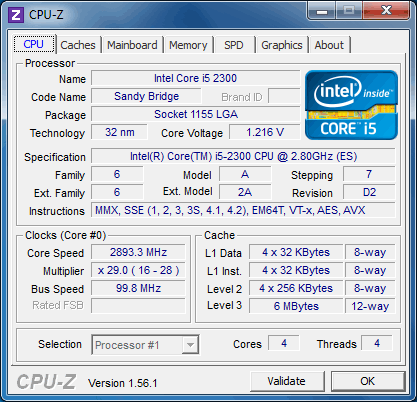 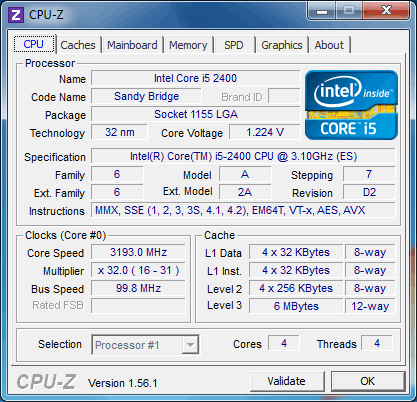 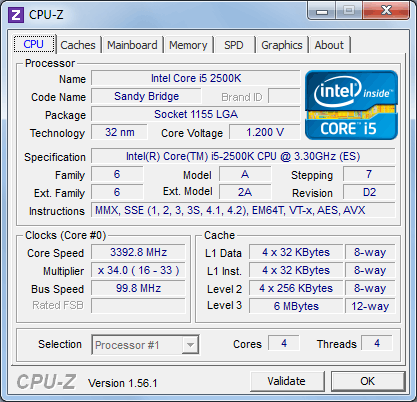 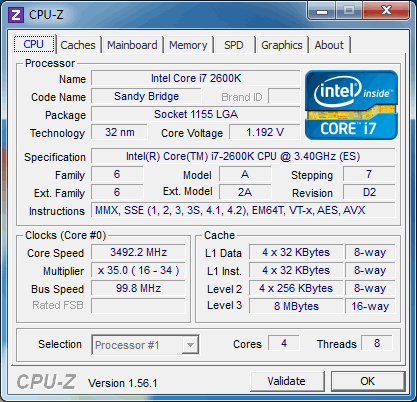 Tous ces processeurs ont un TDP de 95w et fonctionnent avec une tension dalimentation de 1.2V par défaut, contre 1.1V pour un processeur de la gamme S qui on un TDP de 65w. En pratique, notre Core i5-2500 fonctionne à ce propos très bien à la fréquence dune version S et à sa tension, et offre alors un comportement thermique similaire. Nous les avons testés sur une carte mère Intel, la DP67BG :  Nous mesurons la consommation de la configuration à la prise lalimentation utilisée ayant un rendement de lordre de 80%. Pour le test en charge, nous avons utilisé Prime95. Attention donc, d'autres composants tels que la carte graphique ou le disque dur sont donc au repos pendant ces mesures.  32nm oblige, la consommation des nouveaux Core i5 et i7 est très bien maitrisée. Voici maintenant le relevé de la consommation sur la prise ATX12V, via une pince ampèremétrique. Nous ne reportons ici que les CPU LGA 1155, ces résultats nétant pas directement comparables dune plate-forme à lautre, la partie uncore étant alimentée par la prise ATX standard sur LGA 1366 par exemple.  Intel sest laissé beaucoup de marge avec un TDP à 95 watts sur ces processeurs, et leur consommation réelle est une bonne surprise par rapport à leurs spécifications. Du fait de lHyperthreading, le Core i7 consomme notablement plus en charge que les Core i5. Page 13 - Un overclocking contrôlé Un overclocking contrôléLes premiers chanceux qui ont pu voir le Sandy Bridge en action ont rapidement dévoilé les problèmes d'overclocking rencontrés par la plateforme. En cause la fréquence de bus, fixée à 100 MHz d'origine, et qui peine à dépasser 108 MHz sans provoquer le plantage de la machine. Tout le monde a naturellement d'abord pensé à une limitation volontaire de la part d'Intel, ce dernier n'étant pas fermé à la pratique d'overclocking, mais uniquement par le biais de modèles vendus dans ce sens (les versions « extrêmes » XE, puis par la suite les série K à multiplicateur débloqué). L'overclocking par augmentation de la fréquence de bus est applicable sur tous les modèles, et échappe ainsi totalement au contrôle du fondeur. La cause de cette limitation a été rapidement découverte : sur Sandy Bridge, la fréquence des différents bus est calée sur celle du bus processeur de façon synchrone : PCI Express, PCI, SATA, USB utilisent tous une fréquence directement proportionnelle aux 100 MHz du bus. A la différence des plateformes précédentes, pour lesquelles ces fréquences sont générées de façon asynchrone, c'est-à-dire indépendamment de celle du bus. La désynchronisation des fréquences, adoptée jusqu'alors, est source d'une baisse de performance globale, car la logique derrière cette technique se paie par de nombreux cycles d'attente lors des accès aux bus concernés. Utiliser des fréquences synchrones se justifie donc par un gain de performance, mais au prix d'une dépendance entre ces fréquences. A partir de là, on peut se poser des questions. Intel certifie que la plateforme n'était pas censée être validée avec une gestion synchrone des fréquences, et qu'il s'agit d'une erreur malheureuse, et non d'un choix volontaire. D'ailleurs, le fondeur assure que les futures plateformes (notamment les versions haut de gamme sur LGA 2011) reviendront à une gestion asynchrone des fréquences. A voir ! Cela étant, volontaire ou non, cette limite d'overclocking peut coûter cher à Intel, on a déjà vu des modèles de processeurs boudés par les utilisateurs à cause de leur manque de propension à prendre des MHz. Intel a donc lâché un peu de lest, afin de mieux faire passer la pilule.  Les modèles les plus puissants (Core i7-2600 et Core i5-2500) existent ainsi en version K, dont le coefficient multiplicateur peut être librement fixé jusqu'à 57 x (soit une fréquence théorique maximale de 5,7 GHz), et dont le prix est à peine supérieur à la version classique (+ $23 pour le 2600K, et + $11 pour le 2500K). Notez que pour modifier le multiplicateur des modèles K, ceux-ci devront être impérativement installés sur un chipset P67, et non H67.  Quant aux modèles classiques non K, ceux-ci permettent quand même quelques fantaisies : choix des fréquences mémoire (DDR3 1067, 1333 mais aussi 1600, 1867 et 2133), du GPU (diviseurs libres) et réglage du seuil de puissance régulant le mode turbo. De plus, il est possible daugmenter de 4 crans le coefficient multiplicateur du Turbo, ce qui permet ainsi datteindre 500 MHz de plus avec 4 core utilisés comme précisé dans le tableau suivant. 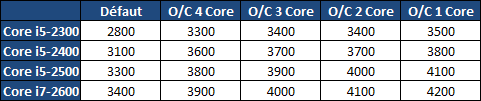 L'overclocking n'est donc pas mort mais il est désormais sous le contrôle total d'Intel. Même si le constructeur dément formellement le caractère volontaire de cet événement. Quoiqu'il en soit, il sera intéressant de se pencher sur les choix d'Intel en ce qui concerne la future plateforme socket 2011 : restaurera-t-il les fréquences asynchrones comme il l'a annoncé ? Et si oui, reviendra-t-il en arrière sur les concessions faites sur les versions non K, ainsi que sur les prix des versions K sur LGA 1155 ? Page 14 - Loverclocking en pratique Loverclocking en pratiquePour commencer, nous avons voulu tester loverclocking par le la DMICLK, sur une carte mère Intel DP67BG et un Core i7-2600K, qui est de base à 100 MHz. Comme prévu, la marge de manuvre est très faible puisque nous navons pas pu dépasser les 106 MHz de manière stable. On se retrouve donc quasiment limité au bon vouloir dIntel du côté des coefficients. 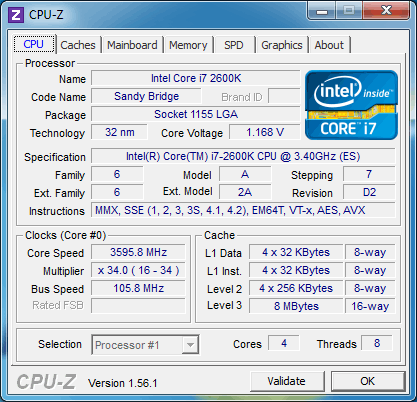 Sur la carte Intel DP67BG tout du moins, le coefficient de base nest pas modifiable en montée et il faut donc overclocker en augmentant les coefficients du mode Turbo. Pour passer à 4 GHz, il "suffit" de tous les régler à 40, c'est à dire pour 1, 2, 3 et 4 core actifs. Ceci entraine une petite subtilité par rapport à un overclocking classique, puisque si le processeur dépasse son TDP il reviendra à son coefficient de base après y avoir passé une seconde du fait du Turbo 2. Même si ce délai dune seconde est réglable jusquà 32 secondes, le mieux est en fait daugmenter le seuil de puissance du mode Turbo en le passant de 95 à 120 watts par exemple. On commence par le Core i7-2600K, que nous avons pu faire stabiliser jusquà 4.1 GHz sous Prime95 à sa tension de base de 1.2v, contre 3.4 GHz par défaut et 3.5 GHz en Turbo sur 4 core. A 1.3v nous avons pu atteindre les 4.4 GHz, puis les 4.7 GHz a 1.4v. Avec ce réglage, on atteint les 155w, contre 74w dans sa configuration de base. 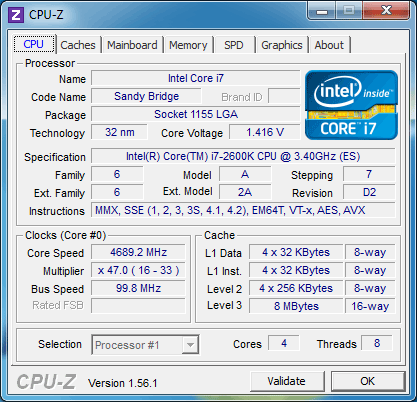 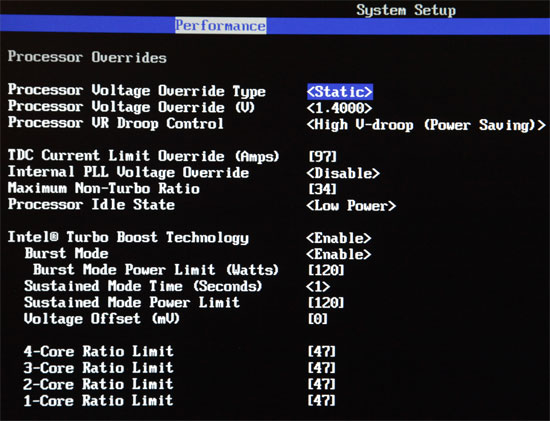 Le 2500K a pu pour sa part atteindre de manière stable les 4 GHz à 1.2v, 4.3 GHz à 1.3v et 4.6 GHz à 1.4v, en activation la fonction Internal PLL Voltage Override après 4.4 GHz. A 4.6 GHz et 1.4v, le CPU consomme 130w en charge, contre 61w par défaut. 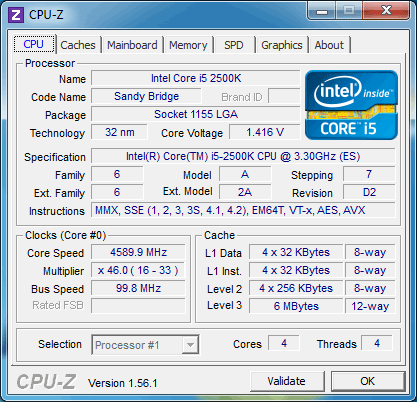 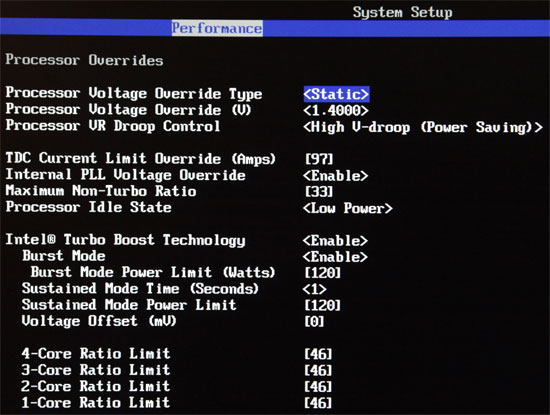 Comme tous les processeurs non K, le Core i5-2400 nest que partiellement débridé au niveau de son coefficient multiplicateur (limite à +4). Ce dernier est à 31 par défaut, mais peut grimper à 32, 33, 33 et 34 en Turbo avec 4, 3, 2 ou 1 cur actif. Avec 4 curs actifs, il est donc possible de le cadencer à 3.6 GHz à sa tension par défaut de 1.2v, et même 3.81 GHz en passant la DMICLK à 106 MHz. Sa consommation est alors de 75w, contre 60w par défaut. Enfin le Core i5-2300, cadencé de base à 2.8 GHz, peut atteindre les 3.3 GHz avec 4 curs actifs en jouant uniquement sur son coefficient multiplicateur, et 3.49 GHz en jouant en sus sur le bus. On conserve sa tension de 1.2v et la consommation est alors de 69 watts, contre 54,5w par défaut. Page 15 - Lynnfield vs Sandy Bridge à 2.8 GHz Lynnfield contre Sandy Bridge à 2.8 GHzAvant de commencer les tests des processeurs dans leur configuration commerciale, nous avons voulu isoler les gains offerts par un Sandy Bridge (Core i5/i7 quad core 32nm LGA1155) par rapport au Lynnfield (Core i5/i7 quad core 45nm LGA1156). Pour ce faire, nous avons cadencé les deux processeurs à 2.8 GHz, et avons mesuré lécart de performances obtenu. Les résultats sont présentés sous forme d'indice pour plus de lisibilité. 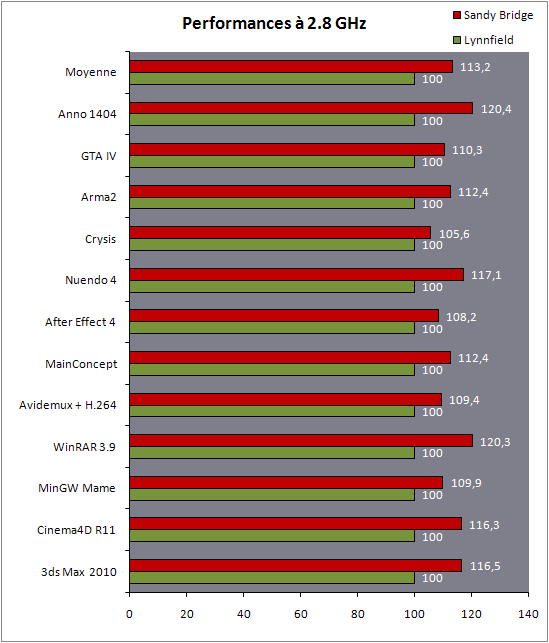 Sans HyperThreading, les gains varient entre 5,6 et 20,4%, pour une moyenne de 13,2%. Avec HyperThreading, Sandy Bridge est 5,6 à 19,3% plus rapide, pour une moyenne de 11,3%. Combiné à la hausse de fréquence à tarif égal mentionnée précédemment, on peut donc sattendre à des gains notables de rapport performance / prix. Influence de lHyperThreadingToujours à 2,8 GHz, nous mesurons limpact de lHyperThreading sur les performances. 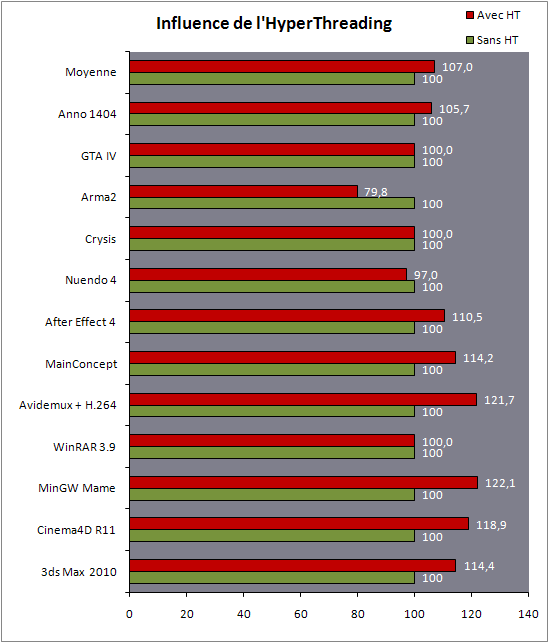 Le gain moyen est de 7%, avec jusquà 22% de mieux sous MinGW et Avidemux. Seuls Nuendo 4 et surtout Arma 2 voient leurs performances impactées négativement par cette technologie. Influence du TurboNous mesurons enfin linfluence du Turbo Boost sur un des processeurs, le Core i5-2500K. 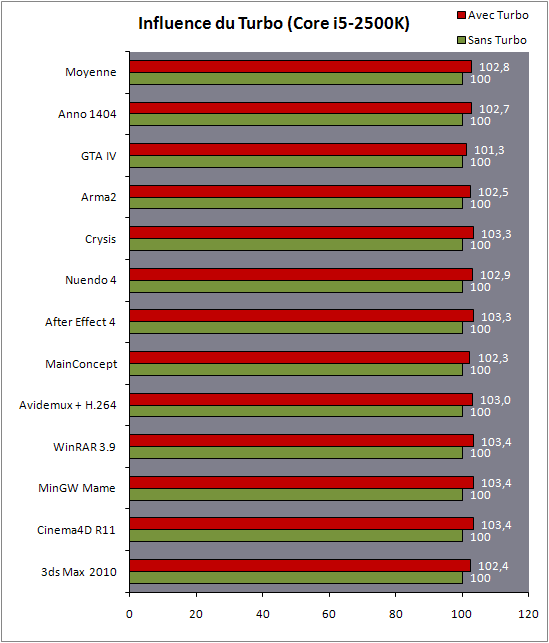 Le gain moyen est de 2,8%. Le test  Pour ce test, nous avons repris notre protocole de test processeur habituel. Nous avons pour rappel profité de la dernière mise à jour pour passer à Windows 7 en version 64 bits, ce qui implique que tous les logiciels disponibles en 64 bits sont testés dans ce mode. Pour ce test, nous avons repris notre protocole de test processeur habituel. Nous avons pour rappel profité de la dernière mise à jour pour passer à Windows 7 en version 64 bits, ce qui implique que tous les logiciels disponibles en 64 bits sont testés dans ce mode.Les logiciels sont mis à jour, ainsi 3ds max passe de la version 2009 à la version 2010, MinGW est mis à jour tout comme WinRAR (3.8 vers 3.9), After Effects (CS3 vers CS4) et Nuendo (4.2 vers 4.3). Les combos VirtualDub/DiVX et AutoMKV/x264 laissent leur place aux combos Avidemux/x264 et MainConcept Reference/H.264, alors que les fichiers de tests de quasiment tous les tests changent ou sont modifiés (résolution de rendu plus importante par exemple). Côté jeu, nous avons décidé de conserver Crysis 1.2 et son test CPU ultra-lourd, mais de retirer World In Conflict au profit de nouveaux jeux plus récents et plus gourmands : Arma 2, Grand Theft Auto IV et Anno 1404. Afin de mettre en évidence au maximum les écarts lié au processeur, nous mettons toutes les options graphiques au maximum histoire de le charger plus que de raison, tout en limitant la résolution à 800*600 afin déliminer un éventuel lissage par la puissance de la solution mono-GPU utilisée sur la configuration de test. Les matériel utilisé avec les processeurs est le suivant : - ASUSTeK P5QC (LGA775) - Intel DP55KG (LGA1156) - Intel DX58SO (LGA1366) - Intel DP67BG (LGA1155) - ASUSTeK M4A79-T (AM3) - 2x2 Go DDR3-1333 7-7-7 - 2x2 Go DDR3-1066 7-7-7 (si 1333 impossible) - GeForce GTX 280 + GeForce 190.62 - Raptor 74 Go + Raptor 150 Go - Creative Audigy - Windows 7 64 bits Page 16 - 3D Studio Max, Cinema 4D 3D Studio Max 2010  Nous débutons par le célèbre logiciel dimage de synthèse, en version 2010 et x64. La scène de test utilisée provient de SPECapc pour 3ds max 9 (space_flyby_mentalray) et elle utilise le moteur de rendu Mental Ray. 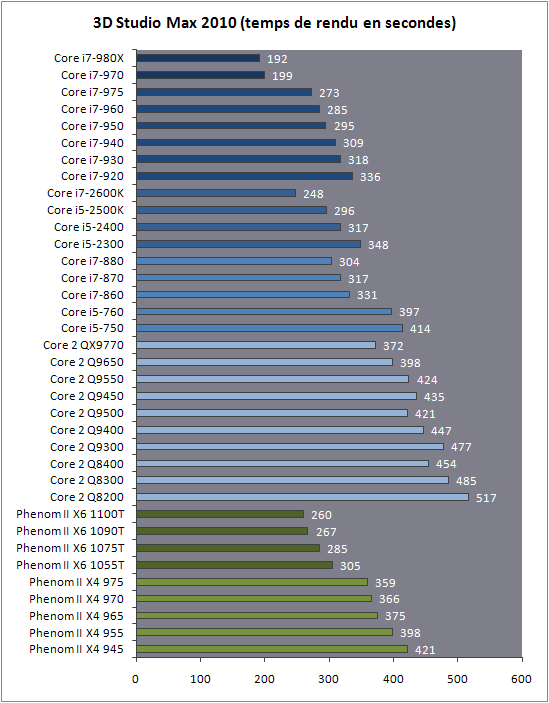 Dès ce premier test les nouveaux Sandy Bridge mettent les choses au point. Certes, les hexa core LGA 1366 gardent lavantage, mais à tarif égal un i5-2500 est 34% plus rapide quun i5-760 et il se rapproche même du Phenom II X6 1075T qui est dans une tranche tarifaire similaire alors quil a deux curs de moins. Le Core i7-2600K le quatre cur le plus performant toute plate-forme confondue. Cinema 4D R11  Le logiciel de rendu de Maxon est célèbre auprès de la communauté des overclockeurs via Cinebench, qui permet de comparer facilement les performances de processeurs. Nous utilisons la version R11 de C4D en version en 64 bits, avec la scène de Cinebench R10 rendue dans une résolution plus importante afin dallonger les temps de rendu. 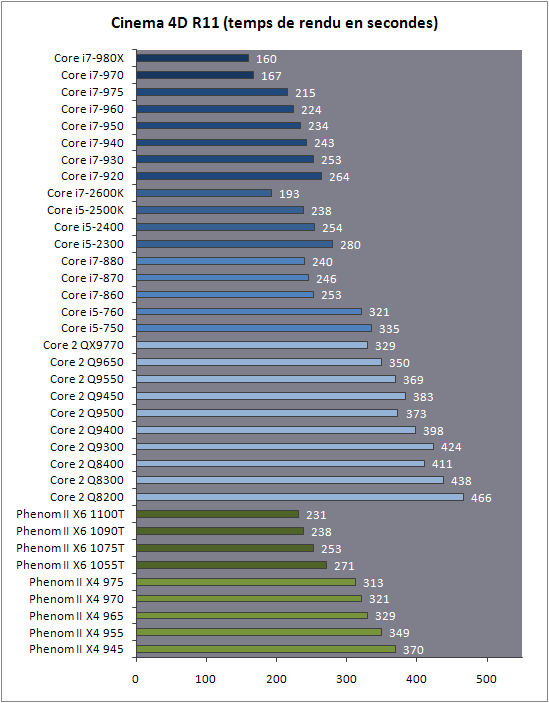 La première impression est confirmée sous Cinema4D. Le Core i7-2600 vient sintercaler entre les Core i7 LGA 1366 quatre et six curs alors que li5-2500 est devant un i7-880, avec un gain de 35% par rapport à li5-760, et au niveau dun Phenom II X6 1090T. Page 17 - MinGW/GCC, WinRAR MinGW / GCC  Voici un test applicatif mettant en uvre la compilation du code source de MAME via GCC sous lenvironnement MinGW. Nous utilisons désormais la version 5.1.4 de MinGW alors que cest le code source de Mame 0.133 qui est compilé. 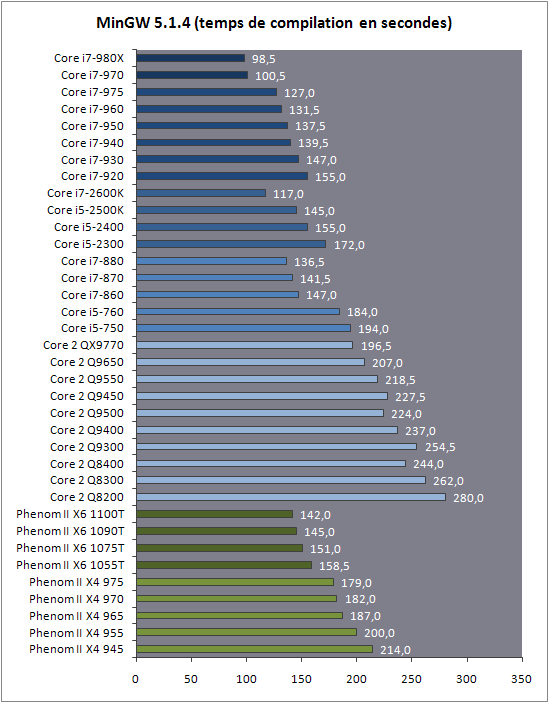 Comme sous 3ds et C4D, li7-2600 se place juste derrière les six curs LGA 1366. Li5-2500 se place pour sa part au niveau des Core i7 LGA 1156 et des Phenom II X6, ce qui nest pas une maigre performance. WinRAR 3.9  Nous utilisons la version 3.9 64 bits de WinRAR, qui introduit de nouvelles optimisations multithread, pour compresser un ensemble de fichiers. 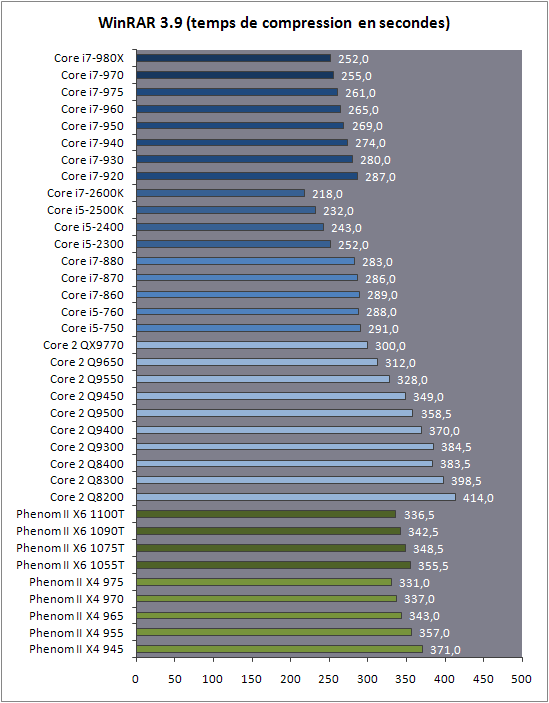 Même dans cette version, WinRAR ne tire guère partie de plus de 2 curs. Grâce à la latence réduite de leur cache L3, les nouveaux Sandy Bridge creusent lécart et savèrent être les CPU les plus véloces à lheure actuelle. Page 18 - H.264 : Avidemux, MainConcept Avidemux + x264  Nos tests vidéos sont utilisent exclusivement l'encodage H.264. Pour commencer, nous utilisons Avidemux dans sa version 2.5.2, qui améliore les performances au delà de 4 thread par rapport à la version 2.5.1, pour compresser via le codec x264 en qualité intermédiaire un fichier vidéo HD 1920*1080. 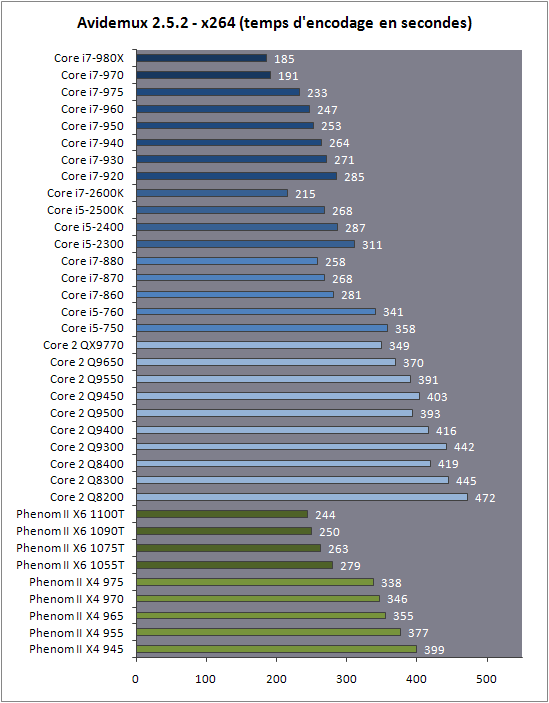 Une fois de plus li7-2600 se place juste derrière les six curs LGA 1366. Li5-2500 est 27% plus rapide que li5-760 et il se place entre les Phenom II X6 1055T et 1075T. MainConcept Reference + H.264/AVC Pro  Pour ce deuxième encodage H.264 nous utilisons MainConcept Reference et son codec H.264/AVC Pro en profil « High », toujours sur la même vidéo. 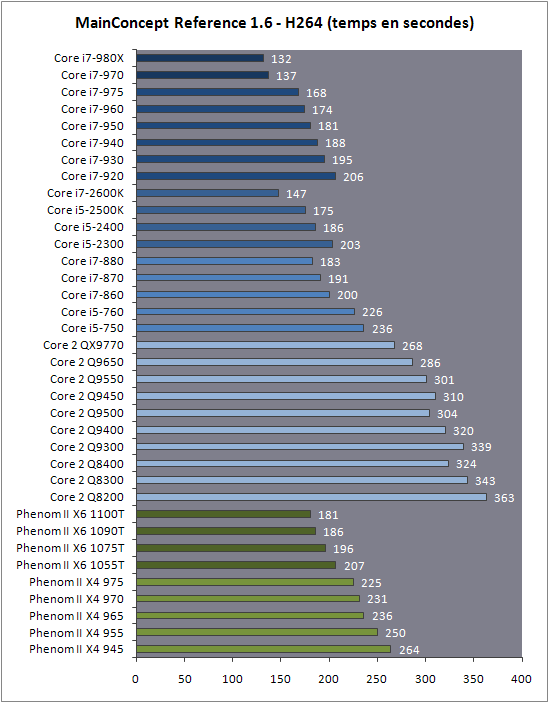 Li7-2600 sapproche une fois de plus des performances des Westmere, alors que li5-2500 offre un gain de 29% par rapport à li5-760. Il soffre le luxe dêtre plus performant que le Phenom II X6 1090T. Page 19 - After Effects CS4, Nuendo 4.3 After Effects CS4  Adobe After Effects est utilisé en version CS4, nous utilisons une composition utilisant divers effet afin de rendre une animation en 3D, le multitraitement étant activé afin de pouvoir profiter au maximum du nombre de core disponibles. 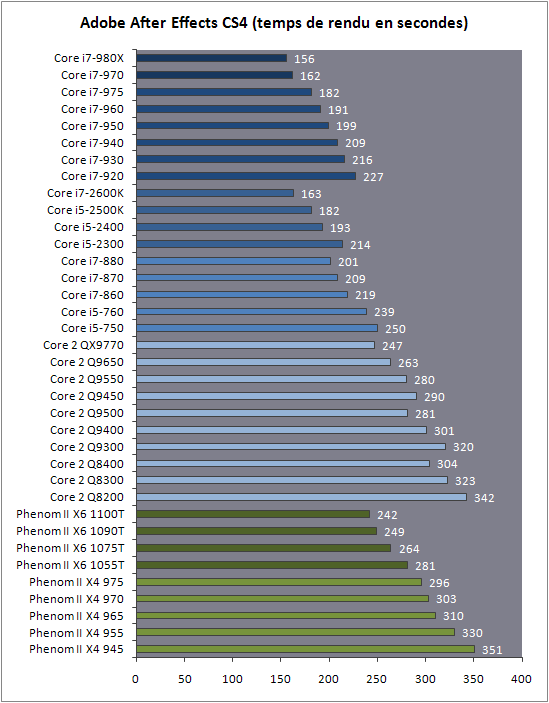 Les processeurs Intel dominent largement les AMD sous ce test, si bien quun i5-2300 est déjà bien plus véloce quun Phenom II X6 1090T. Les autres Sandy Bridge creusent lécart, avec un i7-2600 au niveau dun i7-970 hexacore. Nuendo 4.3  Voici la version 4 de Nuendo, avec la dernier patch 4.3, le tout en 64 bits. Un projet musical utilisant divers plugin natifs ainsi que 2 instances dinstruments virtuels HalionOne est exporté en fichier wave (merci à Draculax). 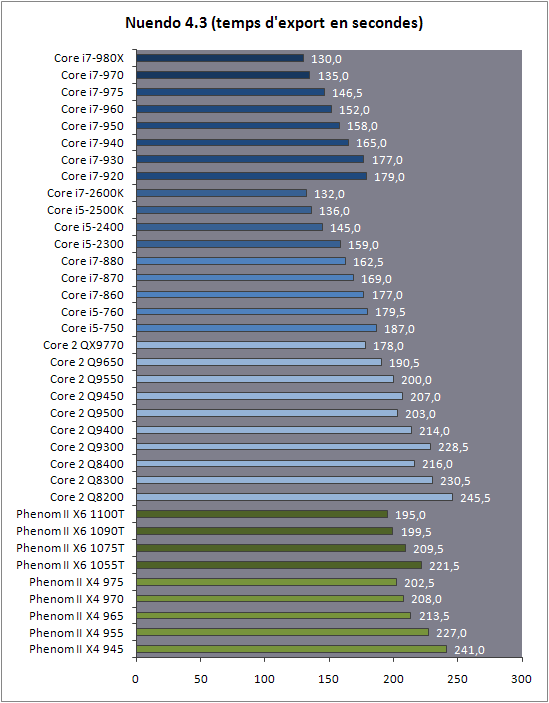 Comme sous After Effects les CPU AMD sont assez mal placés ici. Page 20 - Crysis, Arma 2 Crysis 1.2  Avec le patch 1.2, Crysis propose un bench CPU (trouvable dans les répertoires Bin32/Bin64) très lourd. Le test est effectué avec les détails très élevés, mais en 800*600 afin de limiter la dépendance à la carte graphique. 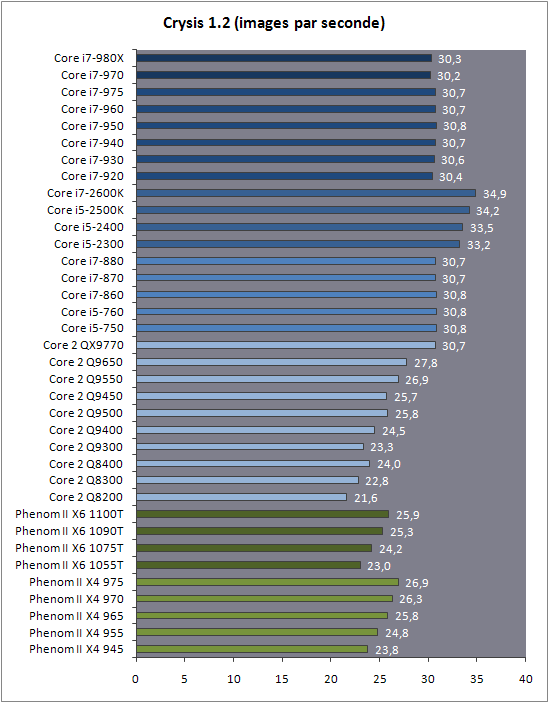 Alors que nous pensions être limités jusqualors uniquement par le GPU, les processeurs Sandy Bridge permettent daller au delà de la limitation à un peu moins de 31 images par secondes sous cette scène très lourde rencontrée jusqualors. La cause réelle de cet écart reste toutefois difficile à déterminer. Arma 2  Arma 2 est configuré avec tous les détails au maximum dont une visibilité au maximum soit 10 km, ce qui a pour dont de mettre à genoux les configurations. La résolution reste par contre à 800*600 pour éviter de lisser les performances par la carte graphique. Pour mesurer les performances, nous mesurons le framerate durant un déplacement bien défini après avoir chargé une sauvegarde. 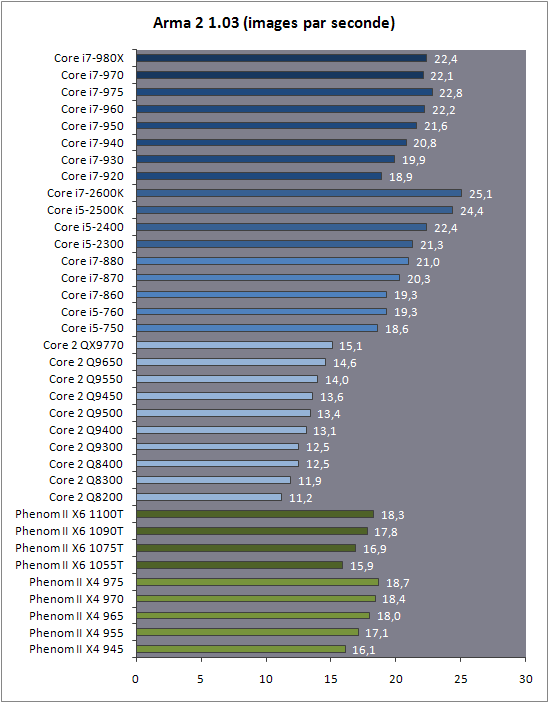 Dès le Core i5-2400, les Sandy Bridge sont au niveau des processeurs LGA 1366 les plus rapides. Les 2500 et 2600 creusent lécart. Page 21 - GTA 4, Anno 1404 Grand Theft Auto IV  GTA IV fait parti de nos tests du fait de sa lourdeur ainsi que de ses optimisations multithread. Encore une fois tous les détails sont poussés au maximum, exception faite des textures pour ne pas dépasser la mémoire vidéo disponible, le tout en 800*600. Nous utilisons le benchmark intégré mais sur une scène faite maison plus lourde que celle proposée par défaut.  Sous GTA IV les Sandy Bridge confirment leur avantage dans le domaine ludique, avec un avantage moins net toutefois. Laugmentation des performances assez faible avec laugmentation de la fréquence laisse toutefois penser à une limite autre que le CPU dans cette scène à la géométrie très lourde. Anno 1404  Anno 1404 est un jeu de gestion ici testé en détail maximums tout en conservant une résolution de 800*600. Nous utilisons une sauvegarde comportant une cité de 46 600 habitants que nous visualisons en partie depuis une vue éloignée.  Rares sont les jeux à tirer partie de six curs et Anno 1404 en fait partie, comme le montre les écarts entre Phenom II X4 et X6 ainsi que les écarts entre les quatres curs avec et sans HyperThreading. Les Sandy Bridge apportent un gain significatif et creusent lécart sur des solutions AMD qui étaient déjà mises à mal. Page 22 - Moyenne MoyenneBien que les résultats de chaque application aient tous un intérêt, surtout avec des processeurs offrant un nombre de curs élevé, nous avons calculé un indice de performances en se basant sur l'ensemble de résultats et en donnant le même poids à chacun des tests. L'indice 100 a été attribué à lIntel Core 2 Q8200. En combinant une fréquence et une efficacité supérieure, les nouveaux processeurs Core i5 et i7 LGA 1155 affichent une belle progression face à leurs prédécesseurs LGA 1156 : li5-2300 est ainsi 15% plus rapide que li5-750, et lécart grimpe à 20% si on compare li7-880 et li7-2600. Cette dernière version se rapproche dailleurs de très près du Core i7-970 malgré ses six curs. A tarif égal, li7-2600 est 24% plus rapide que li7-870, et li5-2500 26% au dessus de li5-760 ! Cette hausse du rapport performance / prix chez Intel rend la situation encore plus délicate quelle ne létait pour AMD sur le haut de gamme. En moyenne, un simple i5-2300 (177$) suffit à contrarier un Phenom II X6 1100T (265$) pourtant placé entre les i5-2500 et 2600 dun point de vue tarifaire (205 et 294$). Bien entendu cette moyenne cache des écarts en fonction de lutilisation, et si le li7-2600 est quelle que soit lapplication systématiquement devant le X6 1100T, le plus gros CPU AMD parvient sous 4 applications à être devant li5-2500 (3ds max, Cinema 4D, MinGW et Avidemux).  Page 23 - Conclusion ConclusionAvec ces nouveaux Core i7 et Core i5 basés sur larchitecture Sandy Bridge, Intel nous propose les processeurs quatre curs qui sont à la fois les plus performants et les moins énergivores. Cest bien entendu la combinaison de la nouvelle architecture Sandy Bridge, plus efficace à fréquence égale que Nehalem tout en offrant une plage de fonctionnement plus élevée en termes de fréquence, avec une gravure en 32nm quIntel reste le seul à maitriser chez les fabricants de CPU x86 qui permet aux CPU Sandy Bridge de réaliser ce tour de force. Déjà confiné à un marché de niche du fait de prix prohibitifs, les six curs LGA 1366, perdent une grande partie de leur intérêt avec cette sortie. Bien sûr, dès lors quils sont utilisés à leur plein potentiel ils sont toujours les plus rapides, mais le Core i7-2600 sen approche pour un coût bien moindre. Les Phenom II X6 sont également mis à mal par cette nouvelle gamme Intel si bien que le Phenom II X6 1100T, fer de lance de la gamme AMD, nest en moyenne quau niveau dun i5-2300, soit le plus petit des quatre curs Sandy Bridge ! Il parvient toutefois à battre un i5-2500 dans 4 cas sur 12, mais nest jamais devant le li7-2600K, tout en ayant moins de marge en overclocking et en consommant plus. Intel a par ailleurs profité de Sandy Bridge pour étendre sa stratégie dintégration dun cur graphique au sein de ces CPU. Ce dernier est désormais présent au sein du même die, et le nouveau HD Graphics offre des performances qui sont jusquà doublées par rapport à la génération précédente, désormais du niveau dune carte graphique de type Radeon HD 5450 pour la version la plus rapide. Cest bien entendu insuffisant pour jouer, mais cela permet de se passer dun GPU dans les autres cas, y compris pour un HTPC. On regrettera par contre la segmentation à outrance dIntel qui entraine certaines incohérences, comme la présence du HD Graphics 3000 uniquement sur les modèles K, soit les plus chers, alors même que la plate-forme H67 ne permet pas lovercloking. Aussi bon soit-il, un IGP reste un IGP et vouloir faire payer la "meilleure" version au prix fort na que peu de sens. Deux autres points viennent entacher les excellents résultats de ces processeurs. Tout dabord, la nécessité de passer au niveau Socket, le LGA 1155, et donc la mort dun LGA 1156 pourtant pas si vieux, met à mal une notion dévolutivité qui nous tiens à cur. Espérons quil ne sagit là que dune (nouvelle ) erreur de parcours dIntel dans ce domaine. La prise de contrôle dIntel sur la marge doverclocking des Sandy Bridge est également une mauvaise nouvelle. Certes, Intel fait pour le moment assez bon usage de ce contrôle, en laissant une petite marge de manuvre de 500 MHz par rapport à la fréquence de base sur les modèles standard et en permettant dacquérir à des tarifs raisonnables des modèles K débloqués, mais rien ne dit que cette situation perdurera à terme. Ces quelques couacs ne remettent toutefois pas en cause lexcellence de ses nouveaux Core i7 et Core i5 qui à défaut dêtre parfaits sont sans aucun doute possible les processeurs moyen et haut de gamme offrant le meilleur rapport performance / consommation / prix à lheure actuelle. Cher Bulldozer, Sandy Bridge vous attends le pied ferme ! Copyright © 1997-2024 HardWare.fr. Tous droits réservés. |