| |
| |
| Nvidia Fermi : la révolution du GPU Computing Cartes Graphiques Publié le Jeudi 1er Octobre 2009 par Damien Triolet URL: /articles/772-1/nvidia-fermi-revolution-gpu-computing.html Page 1 - Introduction Au début de ce mois de septembre, Nvidia nous a invités dans ses quartiers généraux ŕ Santa Clara pour nous présenter une future architecture. Une invitation que nous n’avons bien entendu pas pu refuser ! L’architecture dont voulait nous parler Nvidia se nomme Fermi et correspond au GT300 ou GF100 généralement utilisé dans les rumeurs sur le futur GPU DirectX 11 de la société. Nvidia a profité de l’ouverture de son forum technologique, la GPU Technology Conference pour lever le voile ŕ son sujet.  Priorité au computingPour cette présentation de son futur GPU, Nvidia a décidé de se concentrer sur l’aspect computing de l’architecture, sans rentrer dans les détails qui concernent la partie graphique, bien que la base soit la męme et permette déjŕ de se faire une petite idée ŕ ce sujet. Pour cela, nous avons pu nous entretenir avec les architectes de Fermi, Jonah Alben, Senior VP of GPU Engineering, et Michael Shebanow, Senior GPU Architecture Manager. Nous avons également pu nous entretenir avec Ian Buck, Director of GPU Computing Software, pour le côté logiciel, et avec Ujesh Desai, VP of Product Marketing, pour le côté commercial. Si Nvidia a décidé de s’attaquer en force au computing avec ses GPUs, bien plus qu’AMD par exemple, c’est parce qu’il s’agit d’un point stratégique trčs important pour le futur de la compagnie. Par rapport ŕ Intel et AMD, Nvidia ne dispose pas de CPU et a donc tout intéręt ŕ tout faire pour essayer de lui grignoter des parts de marché rapidement alors que ces derniers peuvent hésiter ŕ créer trop de concurrence envers leurs produits phares. C’est également un moyen de sécuriser son futur puisqu’il est évident que se cantonner ŕ la 3D quand Intel et AMD peuvent proposer une plateforme complčte est risqué. Les études de Nvidia montrent qu’entre la séismologie, les supercomputers, les stations de travail pour les universités et les chercheurs, la défense et la finance, qui sont les 5 grands créneaux visés, il y plus d’un milliard de chiffre d’affaire annuel supplémentaire ŕ aller chercher. Fermi succčde ŕ TeslaPour ses derničres générations de GPUs, Nvidia utilise le nom de physiciens célčbres comme nom de code pour ses architectures. Le GT200 était ainsi Tesla, en référence ŕ Nikola Tesla. Un nom qui est également devenu la marque de Nvidia pour sa gamme de produits destinés au marché du calcul massivement parallčle. Il ne faut donc pas confondre le nom de code, qui change avec chaque génération de GPU, et la marque qui va rester, Tesla. Pour cette future génération de GPU, Nvidia a rendu hommage ŕ Enrico Fermi, un célčbre physicien spécialiste du nucléaire. Page 2 - Du G80 ŕ Fermi Du G80 ŕ FermiEn introduisant le G80 et les GeForce 8, Nvidia a ouvert la voie des architectures GPUs conçues dans l’optique de faciliter le computing. Certes, le GPU Computing existait déjŕ auparavant, mais ŕ travers le pipeline de rendu 3D. Nvidia a introduit un accčs computing ŕ son GPU, en plus du mode rendu classique et a introduit une mémoire partagée qui permet un niveau de communication entre les threads. Il aura fallu attendre les Radeon HD 4800, 2 ans aprčs, pour voir AMD opérer une orientation similaire. Le GPU Computing est destiné ŕ accélérer les algorithmes massivement parallčles en profitant des nombreuses unités d’exécution présentes au sein d’un GPU. Ces algorithmes doivent ętre conçus de maničre ŕ se décomposer en une multitude de petits threads qui seront exécutés en parallčle, par groupes, sur le GPU. Nous parlons ici de milliers de threads, en contraste avec les quelques threads d’un CPU. Une façon de penser et de programmer totalement différente donc qui a demandé ŕ Nvidia de concevoir un langage adapté : C pour CUDA. Celui-ci a été écrit par Ian Buck, qui était déjŕ ŕ l’origine de Brook GPU, un langage destiné ŕ exploiter le pipeline de rendu 3D, et non directement le cśur de calcul du GPU, ce qui le rendait plus rigide et moins performant. Nous ne reviendrons pas sur le fonctionnement de l’architecture CUDA et sur C pour CUDA puisque nous avons déjŕ traité en long et en large ce domaine dans différents articles. Rappelons simplement qu’elle repose sur le principe de l’exécution d’un kernel (programme) sur une grille de blocs de threads, chacun des blocs disposant d’une mémoire partagée spécifique ŕ ses threads et ceux-ci étant exécutés par petits groupes de 32, les warps. 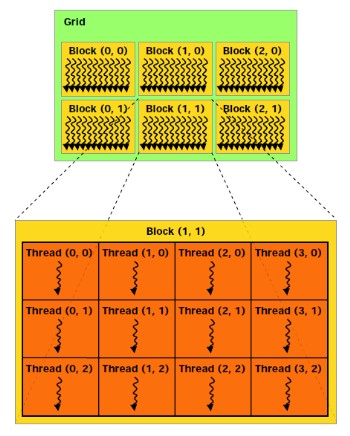 Depuis le G80, Nvidia a progressivement amélioré les capacités de ses GPUs pour tout ce qui concerne le calcul massivement parallčle. Tout d’abord, les opérations atomiques ont fait leur apparition avec les dérivés du G80. Avec le GT200, Nvidia a été encore un petit peu plus loin en doublant le nombre de registres généraux, en passant le nombre maximal de threads par groupe de 768 ŕ 1024 et en ajoutant le support, certes limité, du calcul en double précision. Reste que tout cela ne représentait que des évolutions mineures de son architecture, qu’il n’était pas possible de modifier plus en profondeur ŕ ce moment. C’est quelques temps seulement aprčs l’arrivée du G80 que Nvidia a commencé ŕ poser les bases de sa future architecture, ce qui lui a permis d’avoir une bonne idée des points ŕ améliorer, au-delŕ des petites nouveautés intermédiaires : - Plus de puissance de calcul en général - Un support performant des doubles (FP64) - Un sous-systčme mémoire plus efficace et protégé - Une compatibilité C++ - Un meilleur rendement avec des petits kernels Nvidia s’est donc exécuté. Page 3 - CUDA 3.0 et PTX 2.0 CUDA 3.0 et PTX 2.0Si Nvidia a voulu conserver le modčle de programmation de base de CUDA, pour des raisons de compatibilité avec le code actuel destiné ŕ CUDA et pour ne pas imposer un modčle trop différent aux développeurs, de sérieuses améliorations ont été apportées ŕ l’ISA. Si le PTX 1.x sera compatible avec Fermi, le PTX 2.0 spécifique ŕ cette nouvelle architecture ne sera, lui, pas compatible avec les GPUs actuels. Les améliorations concernent autant le hardware que le software compte tenu des interactions ŕ ce niveau. Tout d’abord, Nvidia a voulu apporter un support de CUDA en C++, ce qui n’était pas trivial puisque plusieurs limitations des précédentes architectures l’empęchaient. Ainsi, Nvidia a unifié l’espace mémoire adressable par Fermi. S’il reste de 40 bits comme sur le GT200, il regroupe les espace mémoire locaux, partagés et globaux. Cet espace unifié permet de gérer les pointeurs et les références qui sont nécessaires au support d’un langage de haut niveau tel que C++. 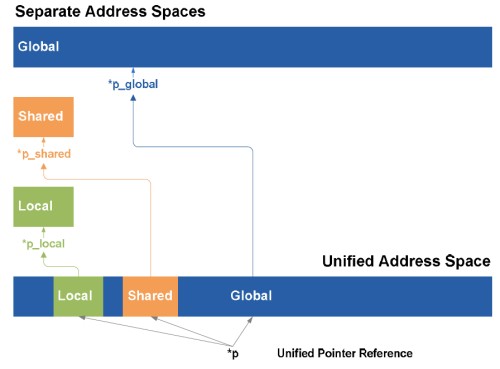 Ce n’est pas tout puisque Nvidia a rendu sa gestion des branchements plus flexible pour supporter les fonctions virtuelles et les appels récursifs. La prédication est également au menu pour toutes les instructions pour éviter de devoir recourir aux branchements dynamiques dans un maximum de cas. L’ISA de Fermi supporte les appels systčmes ainsi que les exceptions avec des primitives telles que try et catch. Alors que les GPUs actuels sont capables de traiter plusieurs types de kernels en mode graphique (pixel shaders, vertex shaders etc.), ce n’est pas le cas en mode computing. Dans celui-ci, ils ne peuvent envoyer qu’un seul kernel ŕ la fois et le suivant ne peut pas l’ętre avant que le premier n’ait été entičrement traité. Le problčme est que si le kernel est petit, c’est-ŕ-dire qu’il ne rempli pas tout le GPU, de la puissance de calcul est perdue. 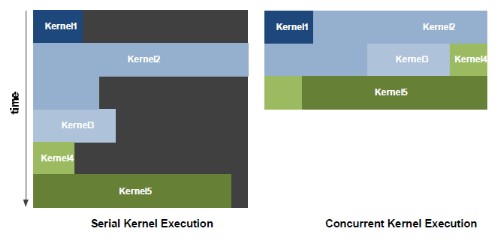 Avec Fermi, Nvidia propose d’exécuter jusqu’ŕ 16 kernels (mais peut-ętre un petit peu moins en pratique) en concurrence, s’il n’y a pas de dépendance bien entendu. De quoi faire exploser le rendement de ce futur GPU et de rendre enfin viables certains algorithmes sur celui-ci. Passer d’un contexte ŕ l’autre sera également beaucoup plus rapide, Nvidia parle d’un gain de 10x par rapport au GT200, ce qui permettra des interactions plus efficaces entre un rendu 3D et le calcul de la physique par exemple.  Enfin, Nvidia va introduire Nexus, un environnement de développement qui s’intčgre ŕ Visual Studio de Microsoft et facilitera le développement et le débogage du code destiné au GPU en permettant de suivre le moindre thread ŕ la trace. Toutes ces nouveautés changent complčtement la donne pour les développeurs qui vont gagner en liberté et pouvoir profiter du GPU plus simplement et dans plus de cas. Page 4 - 3 milliards de transistors 3 milliards de transistorsTout comme pour ses précédents GPUs haut de gamme, Nvidia n’a pas fait dans la dentelle et a conçu une puce énorme. De 1.4 milliards de transistors avec le GT200, nous passons ainsi ŕ 3 milliards avec Fermi, de quoi faire passer Cypress et ses 2.15 milliards de transistors qui nous impressionnaient il y a encore quelques jours pour un petit joueur ! Nvidia n’a pas voulu communiquer sur la taille de la puce mais il est évident qu’elle sera énorme, malgré la fabrication en 40 nanomčtres.  Avec tous ces transistors, Nvidia a pu passer de 240 « cores » ŕ 512, organisés cette fois en groupes de 32 au lieu des groupes de 3 groupes de 8. Fermi contient donc 16 multiprocesseurs (SM, streaming multiprocessors) alors que le GT200 en contenait 30 (10x3), mais ils sont maintenant plus musclés. La nomenclature est ici problématique selon nous. Ce n’est pas nouveau, nous n’aimons pas l’appellation « core » utilisée par Nvidia et AMD pour représenter une ligne d’exécution dans une unité vectorielle. Vous vous en doutez il s’agit lŕ d’une utilité commerciale puisque cela permet de parler d’un grand nombre de cores, 1600 chez AMD et maintenant 512 chez Nvidia… contre seulement 4 chez Intel. Une représentation plus juste serait de nommer « core » chaque multiprocesseur chez Nvidia et chaque SIMD chez AMD, mais nous passerions alors ŕ seulement 16 et 20. Qui plus est cela pourrait réduire le nombre de cores de Fermi de 30 ŕ 16 par rapport au GT200, inacceptable pour le marketing. Nvidia tente de nous aider ŕ accepter son concept de « cores » en les nommant dorénavant « cores CUDA », mais en effaçant SP, son autre nom que nous utilisions. Nous ne sommes toujours pas convaincus. 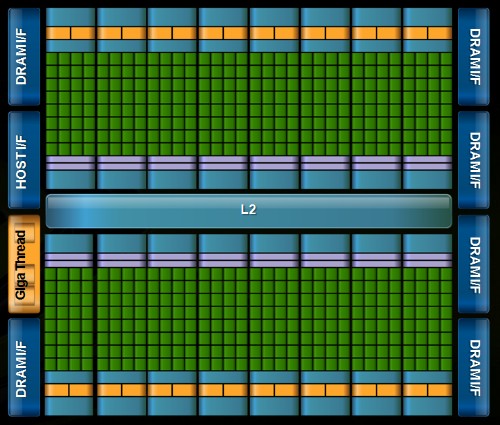 Contrairement ŕ ce que beaucoup pensaient, c’est vers 6 contrôleurs mémoire 64 bits que s’est tourné Nvidia, pour former un bus de 384 bits et non de 512 bits. Avec ces 6 contrôleurs, Fermi pour ętre accompagné de 6 Go de mémoire avec la GDDR5 (en mode clamshell). Si elle va compenser le passage ŕ un bus plus petit, par rapport au GT200, cela signifie que la bande passante mémoire ne va pas augmenter autant que le reste. Le passage du GT200 ŕ Fermi sera en ce sens similaire ŕ celui du RV770 vers Cypress : une puissance de calcul qui explose pour une bande passante mémoire qui n’augmente que modestement. Elle devrait cependant ętre mieux exploitée grâce ŕ une nouvelle architecture de caches. Page 5 - Parallel DataCache Parallel DataCacheLe sous-systčme mémoire de Fermi a été entičrement revu. Dans le GT200 et les GPUs précédents, Nvidia ne disposait pas de véritables caches L1 et L2. Il s’agissait en réalité de texture caches dédiés uniquement ŕ l’accčs aux textures. Les opérations de type Load / Store ne bénéficiaient d’aucun cache, contrairement ŕ ce qui se fait chez AMD depuis le RV770. 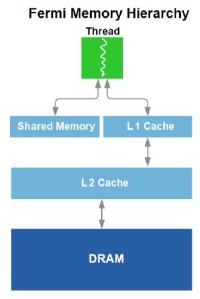 Nvidia se devait donc de revoir sa structure de caches et d’abandonner les textures caches au profit de caches L1 et L2 plus généralistes. Chaque multiprocesseur de Fermi dispose donc d’un cache L1 programmable qui va servir autant de L1 que de mémoire partagée. Ce cache de 64 Ko va fonctionner avec 48 Ko pour l’un et 16 Ko pour l’autre, au cas par cas. 64 Ko en mode L1 ou en mode mémoire partagée ou encore 32 Ko et 32 Ko ne sont pas permis, nous ne savons pas pourquoi, Nvidia n’ayant pas voulu détailler ce point. La mémoire partagée des GPUs Nvidia actuels est limitée ŕ 16 Ko. Avec de tels codes, il sera donc possible soit de profiter de 48 Ko de L1, soit de se limiter ŕ 16 Ko de L1 et de disposer de plus de groupes de threads (chacun ayant besoin de sa propre mémoire partagée) dans le multiprocesseur pour mieux masquer les latences. C’est également le cas avec DirectX 11 qui requiert la possibilité d’utiliser une mémoire partagée de 32 Ko, mais c’est bien entendu un maximum. Si un développeur n’en utilise que 16 ou 24 Ko, ce sont 3 ou 2 groupes de threads qui pourront résider dans le multiprocesseur. Notez que la configuration du L1 sera décidée par le compilateur et non par le développeur. Nvidia se devait donc de revoir sa structure de caches et d’abandonner les textures caches au profit de caches L1 et L2 plus généralistes. Chaque multiprocesseur de Fermi dispose donc d’un cache L1 programmable qui va servir autant de L1 que de mémoire partagée. Ce cache de 64 Ko va fonctionner avec 48 Ko pour l’un et 16 Ko pour l’autre, au cas par cas. 64 Ko en mode L1 ou en mode mémoire partagée ou encore 32 Ko et 32 Ko ne sont pas permis, nous ne savons pas pourquoi, Nvidia n’ayant pas voulu détailler ce point. La mémoire partagée des GPUs Nvidia actuels est limitée ŕ 16 Ko. Avec de tels codes, il sera donc possible soit de profiter de 48 Ko de L1, soit de se limiter ŕ 16 Ko de L1 et de disposer de plus de groupes de threads (chacun ayant besoin de sa propre mémoire partagée) dans le multiprocesseur pour mieux masquer les latences. C’est également le cas avec DirectX 11 qui requiert la possibilité d’utiliser une mémoire partagée de 32 Ko, mais c’est bien entendu un maximum. Si un développeur n’en utilise que 16 ou 24 Ko, ce sont 3 ou 2 groupes de threads qui pourront résider dans le multiprocesseur. Notez que la configuration du L1 sera décidée par le compilateur et non par le développeur.Aprčs ce cache L1 programmable, se trouve un cache L2 cohérent et unifié de 128 Ko par contrôleur mémoire, soit de 768 Ko au total. Pour comparaison, Cypress se contente ici de 512 Ko. Les opérations Load/Store passeront par ces 2 caches avant de se résoudre ŕ aller voir en mémoire vidéo. L’avantage est bien entendu de pouvoir récupérer ces données plus rapidement si elles sont en cache, mais pas uniquement. Cette structure permet également d’éviter les problčmes de lecture aprčs écriture puisqu’il est trčs couteux de gérer cela d’une maničre sűre quand ces 2 opérations se font via des canaux différents. Un autre avantage de cette structure de caches est de pouvoir réduire l’incidence sur les performances d’un dépassement du nombre de registres disponibles en interne. Auparavant les registres supplémentaires devaient résider en mémoire vidéo, avec une latence en complet décalage avec le rôle d’un registre. Dorénavant, ces registres pourront ętre cachés. Le cache L2, en combinaison avec un nombre plus élevé d’unités dédiées, va permettre d’accélérer le traitement des opérations atomiques qui protčgent une zone mémoire le temps qu’un thread puisse la lire, la modifier et écrire le résultat. Avec le cache L2, il est maintenant possible de traiter des opérations atomiques qui se succčdent sur une męme zone mémoire en opérant les modifications dans le cache L2 sans faire des aller-retours vers la mémoire vidéo. Nvidia parle de gains allant de 5x ŕ 20x, mais sans préciser dans quelles conditions ils peuvent ętre obtenus. Enfin, Nvidia a ajouté une fonction trčs attendue dans le monde professionnel : l’ECC. Ce support permet de détecter les erreurs dans les différentes mémoires et éventuellement de les corriger. Nous ne connaissons pas l’implémentation exacte qu’en a faite Nvidia puisque le fabricant a préféré éviter de rentrer dans ces détails. Nous savons par contre que les registres, les caches L1 et L2 sont protégés au męme titre que la mémoire vidéo GDDR5 ou DDR3. La premičre n’existe cependant pas encore en version ECC mais sera une mémoire de choix pour Fermi puisqu’en plus d’offrir nettement plus de bande passante que la DDR3, avec laquelle Fermi risque d’ętre ŕ l’étroit, elle sécurise également le transfert des données. Notez que nous parlons ici de DDR3 et non de GDDR3, la premičre étant la seule compatible avec l’ECC. Page 6 - 16 multiprocesseurs musclés 16 multiprocesseurs musclésNous entrons maintenant dans la partie consacrée au cśur de calcul, qui a lui aussi subit de gros changements. Dans le GT200 et les puces précédentes, les multiprocesseurs étaient groupés par 3 (ou 2) dans une partition nommée TPC. Une organisation liée au mode graphique puisque les unités de texturing se retrouvaient ŕ ce niveau. Nous avions donc en tout 3 niveaux pour le scheduler hiérarchique, le GPU, le TPC et le multiprocesseur. Une structure complexe que Nvidia a décidé de remettre ŕ plat. Le TPC disparait ainsi et ne restent que les multiprocesseurs. Une autre maničre de voir les choses est de se dire que le TPC contient maintenant un unique multiprocesseur. Alors que le GT200 disposait de 10 TPC équipés chacun de 3 multiprocesseurs, Fermi dispose de 16 multiprocesseurs. 16 contre 30, la catastrophe ? Pas du tout puisqu’ils sont totalement différents. Dans le GT200 et tous les GPUs G8x, chaque multiprocesseur dispose d’un unique scheduler qui fonctionne ŕ une fréquence basse, 1x (différente de la fréquence de base du GPU !) et de 4 blocs d’exécution qui fonctionnent ŕ la fréquence haute, 2x (la fréquence des « shaders ») : - une unité SIMD 8-way (les 8 « cores ») : 8 MAD FP32, 8 ADD INT32 ou 8 MUL INT24 - une unité SFU double : 2 fonctions spéciales FP32, 8 interpolations ou 8 MUL FP32 - une unité FMA FP64 (GT200 seulement) - une unité Load/Store 8-way 32 bits Etant donné que les multiprocesseurs travaillent sur des warps de 32 threads, il faut, par exemple, 4 cycles pour traiter une opération de type MAD FP32 et 16 cycles pour une fonction spéciale. Du point de vue du scheduler qui fonctionne ŕ une fréquence réduite de moitié, cela veut dire 2 et 8 cycles, ce qui lui donne la possibilité de faire du dual issue entre une instruction FP32 et une fonction spéciale qui peuvent donc ętre traitées en parallčle. Théoriquement il est également possible de traiter en MAD FP32 et un MUL FP32 en męme temps, mais en pratique ce n’est pas évident compte tenu de limitations au niveau du nombre d’opérandes qui peuvent ętre transmises ŕ chaque cycle. Nvidia utilisait cependant cette possibilité pour booster sa puissance de calcul théorique de maničre ŕ ętre moins largué par AMD ŕ ce niveau. Une unité FMA FP64 a été ajoutée avec le GT200. Celle-ci permet de traiter des opérations en double précision mais 8x moins vite que la simple précision puisqu’elle est seule et unique. 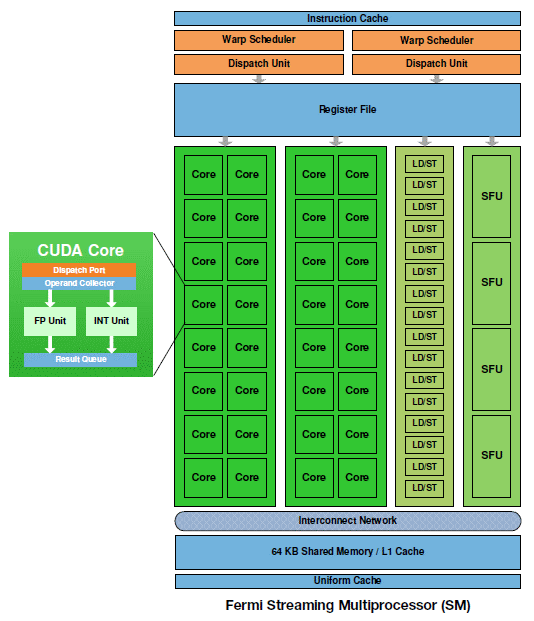 Dans Fermi, chacun des 16 multiprocesseurs dispose d’un double scheduler qui fonctionne toujours ŕ la fréquence basse et de 4 blocs d’exécutions qui fonctionnent ŕ la fréquence haute : - deux unités SIMD 16-way (les 32 « cores ») : 32 FMA FP32, 32 ADD INT32, 16 MUL INT32, 16 FMA FP64 - une unité SFU quadruple : 4 fonctions spéciales FP32 ou 16 interpolations - une unité Load/Store 16-way 32 bits Les deux unités SIMD 16-way sont distinctes et travaillent sur un warp et une instruction différents. La premičre unité peut ainsi exécuter 16 FMA FP32 alors que la seconde traite 16 ADD INT32. Etant donné que les warps sont toujours de 32 threads, ils sont exécutés en 1 cycle du point de vue du scheduler qui a donc dű ętre doublé pour pouvoir profiter du dual-issue. L’unité SFU quadruple est découplée et le scheduler peut donc émettre des instructions aux 2 unités SIMD une fois qu’elle est au travail, ce qui permet donc de faire travailler les SFUs en męme temps que les SIMDs sur un maximum de cycles. Il semblerait cependant que les SIMDs ne soient pas découplées et donc que le scheduler ne soit pas libéré aprčs une instruction plus lente, en 64 bits. Nous devrions cependant préciser les schedulers puisque Nvidia précise qu’alimenter les instructions 64 bits monopolise l’ensemble des ressources au niveau de l’accčs aux registres, ce qui veut dire que le dual-issue n’est pas possible en double précision. Nous ne savons cependant pas si au niveau de l’implémentation une seule SIMD se charge de toutes les opérations sur les doubles ou si les 2 SIMDs travaillent de concert ŕ demi vitesse, Nvidia se refusant ŕ rentrer dans ces détails. Pour les opérations sur les entiers, Nvidia a implémenté un pipeline dédié ŕ l’intérieur de chaque SIMD. Il a été implémenté de maničre ŕ pouvoir calculer des précisions supérieures efficacement, par étapes successives. Les nouvelles instructions de DirectX11 ont également fait leur apparition ŕ ce niveau. Comparer Fermi ŕ Cypress est compliqué compte tenu des architectures complčtement différentes. Cypress dispose de 20 SIMDs chacun équipés de 16 unités vec4+1. La partie vec4 est capable de traiter 4 FMA FP32, 4 ADD INT24, 4 MUL INT24, 2 ADD FP64, 1 MUL FP64 ou 1 FMA FP64 alors que la partie +1 prend en charge une fonction spéciale ou un FMA FP32 par cycle. Il n’y a pas de multi-issue géré ici au niveau du scheduler, mais il revient au compilateur d’essayer de trouver 5 instructions non dépendantes qui peuvent s’exécuter dans ce modčle vec4+1, ce qui n’est pas toujours possible et réduit l’efficacité de ce type d’architecture, qui permet cependant de placer plus d’unités de calcul et donc de puissance de calcul brute dans une męme surface. Des registres en hausse… et en baisseParadoxalement, si le nombre de registres 32 bits passe de 16384 ŕ 32768 du GT200 ŕ Fermi, leur nombre est en fait divisé par 2 par rapport au nombre de « cores ». Cela signifie que la latence que Fermi est capable de masquer sera 2 ŕ 3x plus faible que dans le GT200, malgré le fait que 1536 threads peuvent y résider contre 1024 auparavant. Difficile de dire cependant si ces latences maximales qu’il est possible de masquer vont jouer un rôle dans les performances, d’autant plus que la nouvelle structure de cache et la GDDR5 plus rapide va compenser. Du côté de Cypress, le nombre de registres par SIMD reste identique par rapport au RV770 : 16384 registres de 128 bits. Page 7 - IEEE754-2008 et puissance de calcul IEEE754-2008Les SIMDs de Fermi ne reposent plus sur une instruction de type MAD (multiply add) mais sur une instruction de type FMA (fused multiply add). La différence se situe au niveau de la précision. MAD se comporte réellement comme une multiplication flottante suivie d’une addition flottante, c’est-ŕ-dire que le résultat est arrondi ŕ chaque étape. FMA par contre conserve la précision intermédiaire et n’effectue l’arrondi qu’ŕ la fin. Fermi, tout comme Cypress, supporte complčtement la norme IEEE754-2008 et donc les nombres dénormalisés et les 4 modes d’arrondis. Par contre une grosse différente entre Cypress et Fermi est que ce dernier n’est plus capable de traiter les MADs classiques tant en simple qu’en double précision. Nvidia nous a indiqué, par défaut, remplacer tous les MADs par des FMAs. Cette solution ne produit cependant pas un résultat équivalent, męme si plus précis, ce qui peut ętre source de problčmes. Il sera cependant possible de préciser lors de la compilation de ne pas utiliser le FMA mais de scinder les MADs en MULs + ADDs, une solution qui sera presque identique. Pour obtenir un résultat parfaitement identique il faudra cependant se passer du MAD sur les architectures actuelles et du FMA sur la nouvelle. De son côté, Cypress est capable de traiter autant les MADs que les FMAs, en simple et en double et ŕ la męme vitesse, ce qui est probablement facilité par son émulation des doubles ŕ partir des unités FP32 et des produits partiels. Nvidia nous a indiqué que l’abandon du MAD a été décidée par rapport au coűt trčs important qu’il aurait nécessité par rapport ŕ son architecture. L’utilisation de l’instruction FMA permet d’accélérer certaines fonctions comme les divisions et les racines carrées. Nvidia nous a indiqué qu’il fournira une nouvelle bibliothčque de fonctions mathématiques qui sera utilisée automatiquement lors de la compilation pour Fermi et exploitera l’instruction FMA pour les accélérer. Du côté d’AMD, Cypress utilise déjŕ l’instruction FMA en double précision pour accélérer les divisions (DIV) et les racines carrées (SQRT). Puissance de calcul maximaleNous avons mis en graphique la puissance de calcul maximale des différentes architectures avec quelques instructions courantes. Pour Fermi nous avons pris en compte un MAD séparé en MUL + ADD et une fréquence conservative de 1600 MHz pour les unités de calcul. Nous avons ajouté, pour information, la puissance de calcul maximale autorisées par les unités SSE d’un Core i7 975. 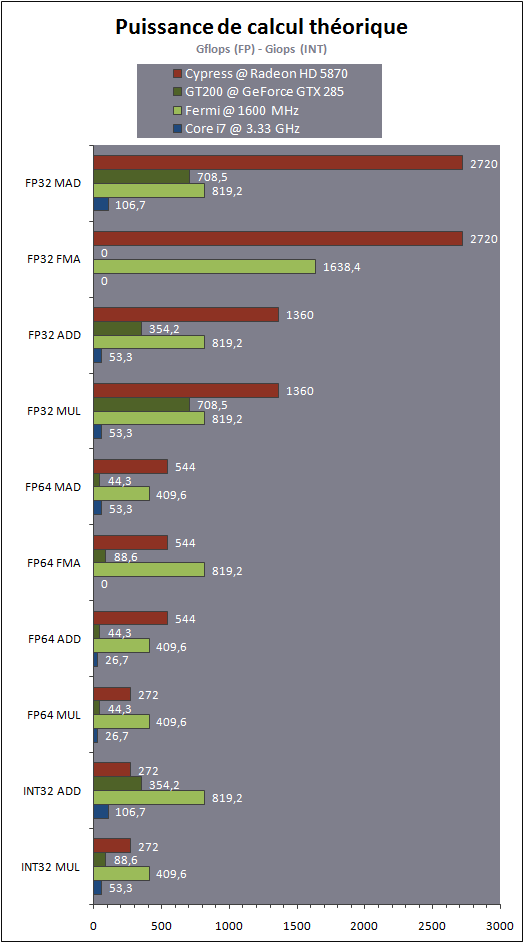 Par rapport ŕ la génération précédente, les gains apportés par Fermi sont énormes, surtout en double précision. Si Cypress affiche une puissance de calcul supérieure en simple précision flottante, il faut garder en tęte qu’il est plus difficile de l’atteindre en pratique compte tenu de son architecture. En double précision, Fermi prend la tęte avec 50% de puissance supplémentaire, sauf avec les additions. Etant donné qu’un seul MUL, MAD ou FMA est traité par cycle il n’y a dans ces cas-lŕ pas de perte d’efficacité liée ŕ l’architecture vectorielle. Page 8 - Conclusion ConclusionLe GPU Computing a encore beaucoup de détracteurs et de fanatiques qui jugent hérétique de programmer pour autre chose qu’un CPU. Avec l’arrivée de Fermi, et si ses promesses se vérifient, ceux-ci devraient fondre comme neige au soleil et les individus restants rater le train du calcul massivement parallčle qui est, de toute évidence, en route et n’est plus un jouet limité ŕ quelques chercheurs et doctorants. L’architecture que nous dévoile aujourd’hui Nvidia, en plus d’ętre plus élégante et d’améliorer sensiblement la puissance de calcul, corrige toutes les grosses critiques qui pouvaient ętre faites au GPU Computing. Elle propose un niveau de programmabilité inédit pour un GPU, une vraie structure de caches, le support de la mémoire ECC pour plus de fiabilité, un profil de performances en double précision similaire ŕ celui des CPUs et un meilleur rendement sur les bouts de code qui se parallélisent moins.  Avec Fermi nous nous approchons de la fin de la distinction entre CPU et GPU, ce dernier prenant de plus en plus la forme d’un co-processeur massivement parallčle. Bien entendu, l’argument de l’absence d’un support du x86 semble encore faire mouche, tout du moins Intel le pense et continue de l’avancer. Mais en réalité le jeu d’instruction n’a que peu d’intéręt par rapport au modčle de programmation et au rendement qu’il permet de tirer d’un co-processeur massivement parallčle. Et ŕ ce petit jeu, Nvidia est en train de prendre une avance considérable. Reste que, s’il ne fait aucun doute que le petit monde du High Performance Computing sera séduit, il est encore trop tôt pour parler des avantages de cette architecture pour le grand public par rapport aux solutions actuelles. Nvidia s’est d’ailleurs refusé ŕ rentrer dans les détails qui concernent la 3D ce qui laisse ŕ Fermi encore quelques secrets importants ŕ nous dévoiler. Si nous ne nous attendons pas ŕ ce que Nvidia ait négligé cette part cruciale de l’architecture, il ne faut pas oublier qu’AMD vient de lancer un nouveau GPU trčs performant pour la 3D, męme s’il n’a pas apporté d’évolution importante pour le computing. Le match n’est donc pas gagné d’avance et le combat ŕ ce niveau risque d’ętre intense d’autant plus qu’il est évident que Fermi arrivera tard, en décembre si tout se passe bien, et en 2010 dans le cas contraire. Copyright © 1997-2025 HardWare.fr. Tous droits réservés. |